ご注文はログ調査ですか?~さくらの社内勉強会より~

昨今、全国津々浦々の会社で“勉強会”が開催されており、みなさんも何らかの“勉強会”に参加されたことがあるかもしれません。
さくらインターネットでは、定期・不定期にさまざまな社内勉強会を実施しており、技術職に限らず幅広い分野から、多くの方々が自発的に参加されています。また最近では、社内に対して動画のストリーム配信も行われています。
今回は、さくらインターネット社内で開催された勉強会「ご注文はログ調査ですか?」について紹介します。

勉強会「ご注文はログ調査ですか?」の様子
社内勉強会のはじめかた
まず、今回の勉強会についてご紹介する前に、社内勉強会の開催において留意しておくべき事項があります。以下の4つのポイントを押さえておかないと、ただ社内勉強会を開催しただけのアピールにしかなりません。
- 対象者は誰なのか
どういった立場・部門の人に参加して欲しいのかを明確にし、それに合わせた内容で実施します。今回は、問い合わせを受けているサポート部門、および運用対応を行っている方を対象としています。 - 目的を明確にする
参加することによって、何を得ることができるのかを提示する必要があります。今回はログを調査するための UNIXコマンドの使い方や、apacheとsendmailのログフォーマット、およびUNIXコマンドを使った効率の良いログの抽出方法としました。 - 余裕を持った告知期間
さくらインターネットでは大阪、東京、そして石狩と各拠点が分かれているため、業務上や設備の関係から余裕を持った告知期間を設けます。 - 事前に資料を提示する
いきなり当日に資料を提示するのではなく、事前に提示しておいたほうが参加する側としては予習や質問事項を用意することができます。また業務の都合で参加できない方のために、資料のみで理解できる内容であることが好ましいでしょう。
勉強会開始!
さて、前置きが長くなりましたが、いよいよ勉強会の始まりです。
主にサポートや運用保守に携わっている部門の方々に参加いただき、「ご注文はログ調査ですか?」をテーマに、60分1本勝負の社内勉強会を開催しました。
さくらインターネットではお客様からのお問い合わせにより、さくらのレンタルサーバー内を調査する作業があり「もっと早く正確に調査を進めたい」という要望が多いことから、ログ調査の勉強会を開催することになりました。
今回は実際に行った勉強会の内容として、上位のアプリケーション層を対象とし、WEBとメールのログを調べる方法を2つ紹介します。
また、一般的なUNIXコマンドとシェルの操作が行えることを前提としています。UNIXシェル自体に不慣れな方は、下記の資料を参照してください。
● Bourne Shell自習テキスト
http://lagendra.s.kanazawa-u.ac.jp/ogurisu/manuals/sh-text/index.html
このBourne Shell自習テキストは20年以上前の古いものですが、現在においてもはじめてUNIXシェルを学ぶのに適した内容でオススメの資料です。
まずはログを見てみよう
サーバー上で処理された内容は履歴情報として記録され、これを一般的にログと呼びます。UNIXシステムでは、ログは人間が読むことができる文字(テキスト)のデータとして記録されることが多いです。(一部バイナリデータで記録されるものがありますが、ここでは触れません)
ログには主に下記のような情報が記録されます。
- いつ(日時)
- 誰が(アカウント、メールアドレス、URIなど)
- なにを(処理の内容)
- どうなった(処理の結果)
サーバー上で記録されるログはいくつかありますが、ここでは具体的な例としてWEBサーバーであるApacheのログを挙げてみます。
fps.noob.jp example.sakura.ad.jp - - [17/Jul/2015:17:24:39 +0900] "GET / HTTP/1.1" 200 531 "http://fps.noob.jp/" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36"
一見、文字の羅列のように見えますが、スペースで区切られた各項目(フィールド)にそれぞれの意味があり、これらの内容を理解しておく必要があります。また、フィールドにスペースが含まれる場合はダブルクォーテーション(“)で囲まれていることにも注意してください。
さくらのレンタルサーバーでは、それぞれの項目に下記の表のような情報が記録されます。
| 番目 | 値 | 内容 |
|---|---|---|
| 1 | fps.noob.jp | ドメイン名 |
| 2 | example.sakura.ad.jp | リモートホスト名 |
| 3 | - | リモートログ名(設定時のみ) |
| 4 | - | リモートユーザ(認証時のみ) |
| 5 | [17/Jul/2015:17:24:39 +0900] | 日時 |
| 6 | "GET / HTTP/1.1" | HTTPリクエスト |
| 7 | 200 | HTTPステータス |
| 8 | 531 | HTTPヘッダ以外のデータ量 |
| 9 | http://fps.noob.jp/" | HTTPリファラ |
| 10 | Mozilla/5.0 (Linux; Android 4.4.2; SO-02E Build/10.5.1.B.0.68) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.93 Mobile Safari/537.36" | HTTPユーザエージェント |
※ さくらのレンタルサーバーのコントロールパネルより、アクセスログの設定からアクセスログの保存設定を残す、およびホスト名の情報を残す(複数のドメインが存在している場合など)に設定すると、ホームディレクトリ以下にあるlogディレクトリにログが保存されます。

それぞれの項目がどのような意味を持つのか、またどのような内容が記録されるのかを正しく把握しておく必要があります。
Apacheのログファイルについては、下記URLの文章を参照してください。
http://httpd.apache.org/docs/2.2/logs.html
道具を使えるようになろう
ログを調査するときには、主に下記のコマンドを使用することが多いです。
- less (テキストファイルの中身を見るページャ)
- grep (文字列を検索する)
- cut (特定のフィールドを取り出す)
- wc (文字数や行数を数える)
- uniq (重複を取り除く)
「そんなに少ないコマンドで本当にできるのか?」と思われがちですが、UNIXの流儀として「細かい道具(コマンド)を組み合わせて目的を達成する」といったものがあります。
これらのコマンドを下図のようにパイプで連結して、一種のパズルのように組み合わせて目的を達成することが可能です。
% コマンド1 | コマンド2 | コマンド3 期待した結果出力
また、利用頻度が高いものはシェルスクリプトとしてまとめておくと便利でしょう。
ここではチートシート的な資料を用いて、それぞれのコマンドの使い方を紹介します。
less (テキストファイルの中身を見るページャ)
% less (ファイル名)
ログファイル全体を見るときに使います。簡易的な検索機能があるので、ログファイル全体から文字列の検索を行って、おおよその探りを入れてみる時によく使います。
●操作方法
| キー | 操作内容 | 備考 |
|---|---|---|
| スペース | 1ページ進む | |
| b | 1ページ戻る | |
| ↓ | 1行進む | |
| ↑ | 1行戻る | |
| / | 文字列の前方検索 | nキーで次へ、bキーで前へ |
| ? | 文字列の後方検索 | nキーで次へ、bキーで前へ |
マニュアルを見ると多くの操作方法が記載されていますが、最低限の操作としてはこの程度で問題ありません。
grep (文字列を検索する)
% grep (オプション) (検索したい文字列) (ファイル名)
テキストファイルから特定の文字列を含む行を抽出して表示するコマンドです。
●よく使うオプション
| オプション | 内容 | 備考 |
|---|---|---|
| -E | 正規表現で検索する | egrep でも可 |
| -z | 圧縮されたファイルを扱う(gzip形式) | zgrepでも可 |
| -j | 圧縮されたファイルを扱う(bzip2形式) | bzgrepでも可 |
| -v | 文字列が含まれてない | 否定 |
| -i | 小文字大文字を区別しない | |
| -r | 配下ディレクトリの再帰検索 |
ログの調査ではgrepコマンドの使用頻度が高いので、自分でテキストデータを作って練習してみると良いです。また、正規表現を理解しておくことによって短い手法で完結することもできます。
cut (特定のフィールドを取り出す)
% cut (オプション) (ファイル名)
テキスト行の選択されたフィールド部分を取り出すコマンドです。
●よく使うオプション
| オプション | 内容 | 備考 |
|---|---|---|
| -f 数字,数字 | 取り出すフィールド番号 | 1から開始 |
| -d 文字 | 区切り文字を指定する | 指定なしではタブ(\t) |
grepコマンドの実行結果をパイプで渡す使い方が多いです。特にApacheのログは1に複数の項目が含まれるため、特定のフィールドのみを取り出すためによく使います。
wc (文字数や行数を数える)
% wc (オプション) (ファイル名)
テキスト行の行数、単語数、文字列を数えるコマンドです。
●よく使うオプション
| オプション | 内容 | 備考 |
|---|---|---|
| -l | 行数を表示する | |
| (無指定) | バイト数、行数、単語数を表示する |
主に特定のログパターンを抽出した結果をwcコマンドにて行数を数えることに使います。
また、grep コマンドの c オプションでも一致した行数を表示することができます。
uniq (重複を取り除く)
% uniq (オプション) (ファイル名)
重複した行を表示するコマンドです。
●よく使うオプション
| オプション | 内容 | 備考 |
|---|---|---|
| -c | 出現回数を表示する |
ログファイルから一番多く出現するものを特定するときによく使います。
注意点として比較対象は隣り合った行となるため、多くの場合においてsortコマンドで並び替えた結果をuniqコマンドへ渡す必要があります。
効率よくログを抽出するには
前述のようにログは、基本的に1つの行にスペース区切りのフィールドによって構成されるテキストデータであるため、必要としている文字列を抽出することが主な目的となります。
ここでは例としてWEBのアクセスログから、リクエストが一番多いファイル一覧を求める方法を挙げてみます。
fps.noob.jp example.sakura.ad.jp - - [17/Jul/2015:17:24:39 +0900] "GET / HTTP/1.1" 200 531 "http://fps.noob.jp/" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36"
このようなアクセスログからリクエストされたファイル名を得るには、まずはHTTPリクエストのフィールドを抽出すればよく、これは6番目のフィールドとなります。しかしながら、cutコマンドで6番目のフィールドのみを抽出しようとしても、下記のように期待した結果を得ることができません。
% cut -f 6 -d " " access.log +0900]
これは5番目のフィールドである日時の部分にスペースが含まれているため、cutコマンドでスペース区切りとして抽出すると日時とタイムゾーンの部分で分かれてしまいます。
この時の動作をperlの呪文じみたワンライナーで調べてみると、本来の目的であるHTTPリクエストのフィールドは7~9番目のフィールドに渡っていることが分かります。
% head -1 access.log | perl -lne 'map { ++$i; printf "%2d: %s\n", $i,$_; } split " ", '
1: fps.noob.jp
2: example.sakura.ad.jp
3: -
4: -
5: [17/Jul/2015:17:24:39
6: +0900]
7: "GET
8: /
9: HTTP/1.1"
10: 200
11: 531
12: "http://fps.noob.jp/"
13: "Mozilla/5.0
14: (Windows
15: NT
16: 6.1;
17: Win64;
18: x64)
19: AppleWebKit/537.36
20: (KHTML,
21: like
22: Gecko)
23: Chrome/43.0.2357.134
24: Safari/537.36"
このような場合、どうしたら良いでしょうか。
いくつかの答えがあります。
1. 7~9番目のフィールドを取得する
一番素直な答えですが、二度手間です。
% cut -f 7,8,9 -d " " access.log "GET / HTTP/1.1" % cut -f 7,8,9 -d " " access.log | cut -f 2 -d " " /
2. 8番目のフィールドを取得する
最も効率がよい答えです。
ただし、HTTPのリクエストラインの構成やWEBサーバーの実装を理解していることが前提となります。(詳細についてはRFC2616 のSection 5.1 Request-Lineについて調べてみてください)
% cut -f 8 -d " " access.log /
3. 区切り文字をダブルクオーテーションにする
発送の転換ですが、やはり二度手間です。
% cut -f 2 -d \" access.log GET / HTTP/1.1 % cut -f 2 -d \" access.log | cut -f 2 -d " " /
おそらく人によっては(もっと効率が良い)他の方法があることでしょう。
最終的には下記のようにして抽出します。(今回は簡略化のため、クエリストリングが付与されたURIは対象としていません)
% cut -f 8 -d " " access.log | sort | uniq -c | sort -nr | head -5 3 /wp-admin/admin-ajax.php 2 /wp-admin/load-scripts.php 2 /index.php 1 /wp-includes/js/tinymce/wp-tinymce.php 1 /wp-includes/js/tinymce/skins/wordpress/wp-content.css
これらのことより、効率よくログを抽出するには下記が必要であると言えます。
- ログの書式と記録される内容を把握していること
求める情報がどのフィールドに、また処理された時にどのような内容が記録されるかを把握しておきます。本項目のようにログ内のフィールド間はスペース区切りであるものの、値として区切り文字であるスペースが含まれる可能性がある場合はどのように対応するかを考慮に入れておく必要があります。 - 他の手法を試してみること
UNIXコマンド単体ではテキストデータの処理は難しいこともありますが、他の手法や複数のコマンドを組み合わせることにより、期待した結果を得ることができます。また、処理するログのファイル容量や更新頻度などから適した方法を選択します。
サーバー内部の処理を把握しよう
次にメールサーバーのログについて触れます。
ここまではWEBのアクセスログについて触れてきました。基本的にHTTPは1アクセスで1行のログが記録されるため、調査はしやすいものとなっています。しかしながら、メールログは1通のメールを配送した時には複数行のログが記録されるため、ログを調べるときには必然的に複数行に渡る記録を扱うことになります。
電子メールの配送について下図に示します。
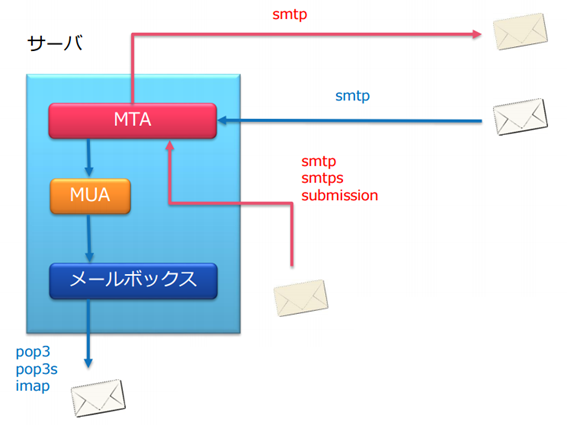
サーバーにメールが配送されるときにはMTA(Mail Transfer Agent) にてメールの配送を受けたのちにMUA(Mail User Agent)に処理が渡され、各ユーザーのメールボックスへと格納されます。
このとき、注意すべき点はMTAとMUAで扱う配送先情報が異なることです。
- MTA
サーバー間の配送となるため、配送情報は送信元メールアドレスとしてenvelope from(MAIL FROM)と送信先メールアドレスとしてenvelope to(RCPT TO)を使用します。 - MUA
配送先のアカウント(envelope to)が確定されたローカルの配送となるため、配送情報はメールヘッダに記載されているFromとToのメールアドレスを使用します。この時点でenvelope fromの内容を確認するにはメールヘッダのReturn-Pathの内容を確認します。
通常のメーラであれば、envelope from とメールヘッダのfrom、envelope toとメールヘッダのtoはそれぞれ同じ内容が設定されますが、メーリングリストなど特殊な配送方法を行っている場合においては、これらが異なることがあります。
このため、メールの配送履歴を調査する際には、送信元と送信先のメールアドレスだけでは特定することができない可能性があるため、メールヘッダの記載情報が必要になることもあります。
メールヘッダの取得方法については、下記URLを参照してください。
▼メールヘッダの取得方法
https://help.sakura.ad.jp/mail/2127/
今回調査するメールヘッダの情報は下記のようになります。
Return-Path: <takamimusubi@example.sakura.ne.jp> Date: Mon, 27 Jul 2015 18:53:52 +0900 From: takamimusubi@examplesakura.ne.jp To: omoikane@example.sakura.ne.jp Message-Id: <20150727185352.C258.1310FDF6@sakura.ad.jp>
ここではMessage-IDに注目してみます。これはメールを特定するためにユニークなIDを値として設定されていますので、これを検索単語としてメールログから抽出してみます。
% grep 20150727185352.C258.1310FDF6@sakura.ad.jp /var/log/maillog Jul 27 18:53:55 www406 MTA_25[24796]: t6R9rtkC024796: from=<takamimusubi@example.sakura.ne.jp>, size=850, class=0, nrcpts=1, msgid=<20150727185352.C258.1310FDF6@sakura.ad.jp>, proto=ESMTP, daemon=MTA4, relay= www231.sakura.ne.jp. [202.181.97.41]
Message-IDの値でgrepコマンドにて検索をしてみましたが、送信元の情報を示す1行しか一致しませんでした。
このため、次はメールキューID(上記の例では t6R9rtkC024796)を用いて検索をしてみます。このメールキューIDとは、サーバー内部でメールを処理するときに付与されるユニークなIDです。
% grep t6R9rtkC024796 /var/log/maillog Jul 27 18:53:55 www406 MTA_25[24796]: t6R9rtkC024796: from=< takamimusubi@example.sakura.ne.jp>, size=850, class=0, nrcpts=1, msgid=<20150727185352.C258.1310FDF6@sakura.ad.jp>, proto=ESMTP, daemon=MTA4, relay=www231.sakura.ne.jp. [202.181.97.41] Jul 27 18:53:57 www406 MTA_25[24799]: t6R9rtkC024796: to=<omoikane@example.sakura.ne.jp>, delay=00:00:02, xdelay=00:00:02, mailer=vmail, pri=30850, relay=example.sakura.ne.jp, dsn=2.0.0, stat=Sent Jul 27 18:53:57 www406 MTA_25[24799]: t6R9rtkC024796: done; delay=00:00:02, ntries=1
※そもそもメールヘッダのReceivedフィールドにメールキューIDが記載されていますが、内容が複雑になるため今回は使用していません。
メールキューIDで検索した結果、3行ほどのログを抽出できましたので、それぞれについて見ていきます。
- 1行目
送信元のenvelope fromのメールアドレス、ホスト、容量やMessage-IDなどが記録されています。誰かが容量の大きなメールを送信しているかもしれない時は、この部分を見てみます。 - 2行目
送信先のenvelope toのメールドレス、ホスト、処理結果が記録されています。特に確認する部分であり、Statの内容から配送状況を把握することができます。(こちらについては後述します) - 3行目
メールキューの処理結果です。処理が保留された場合はメールキューに残ります。一方、エラーが発生した場合は、エラーメールを送信するため、新たなメールキューを生成して処理します。
Statの内容は以下になります。
| Statの値 | 内容 | 備考 |
|---|---|---|
| Sent | ◯配送に成功した | MXホスト、MUAへ |
| Queued | △メールキューに格納した | 送信できないため一時保留 |
| Deferred | ×配送に失敗した | エラーメールが発生する |
ここで注意しておくべきことはStatがQueuedとなった場合です。これはメールの配送が行えない状態であるが、回復可能な理由であるため一時的に保留とされている状態となります。
これらのように、サーバー内でどの部分で処理が行われ、その結果として記録される内容を理解しておく必要があります。
参加者からの感想
今回は、60分という制限のなかでやや詰め込んだ内容での勉強会となりましたが、参加者からは次のような感想をいただきました。
- 認識に不足していた部分があり、これに気づけた
- 自分の理解が正しかったことを確認できた
- ログの調査においてどこを見るべきなのかが分かった
- シェルだけではなく複雑なデータ加工のためスクリプト言語を身につけたい
- 不正利用時の調査において判断基準を知りたい
参加者のほとんどはサービスの内容を把握しており、また日常的にサーバー内で作業を実施しているため、おおよその動向については理解していただけたようです。また今後、日々の作業において問題となったこと、逆にうまくいったことを正しく記録しておくことをお願いしました。
まとめ
簡単な内容ではありますが、さくらインターネットの社内勉強会の一例を紹介させていただきました。
個人的には、勉強会を開催する目的は人への投資であると考えています。しかしながら、いざ資料作成の段階になると「あれ、この内容で正しいのかな」と苦慮することが多く、勉強会を開催するために、まず自身が再び勉強するといった自己投資もしばしばです(ノイマン型コンピュータの資料を作ろうとしていたら、なぜかx86のリングプロテクションやらIntel VTまで調べることに……)。
このように開催する側、参加する側の双方に利点がある社内勉強会。
ぜひ積極的に取り組んでいただけたら幸いです。