実践的なGoogle ウェブマスター ツール(Webmaster Tools)運用
Webサイトの運営で必携ツールといえば「Google ウェブマスター ツール」である。Google検索による検索流入が重要というのはもちろんだが、Webサイト運用のチェックツールとしても無償で活用できる点がポイントだ。基本的な使い方はヘルプが用意されているので、ナレッジらしく、このツールのどこを実用的に使うのか、使えるのか、経験上のノウハウを交えながら紹介していこう。
目次
Google ウェブマスター ツールで何ができるか
「Google ウェブマスター ツール」(図1)はWebサイト管理者向けのツールである。名前を聞いたことがある方ならここまでは理解できていると思う。このツールを使ってできることを大別すると、サイトの状態の把握と、Google検索エンジンに対する操作の2つである。2013年12月上旬時点での機能をまとめると表1のようになる。
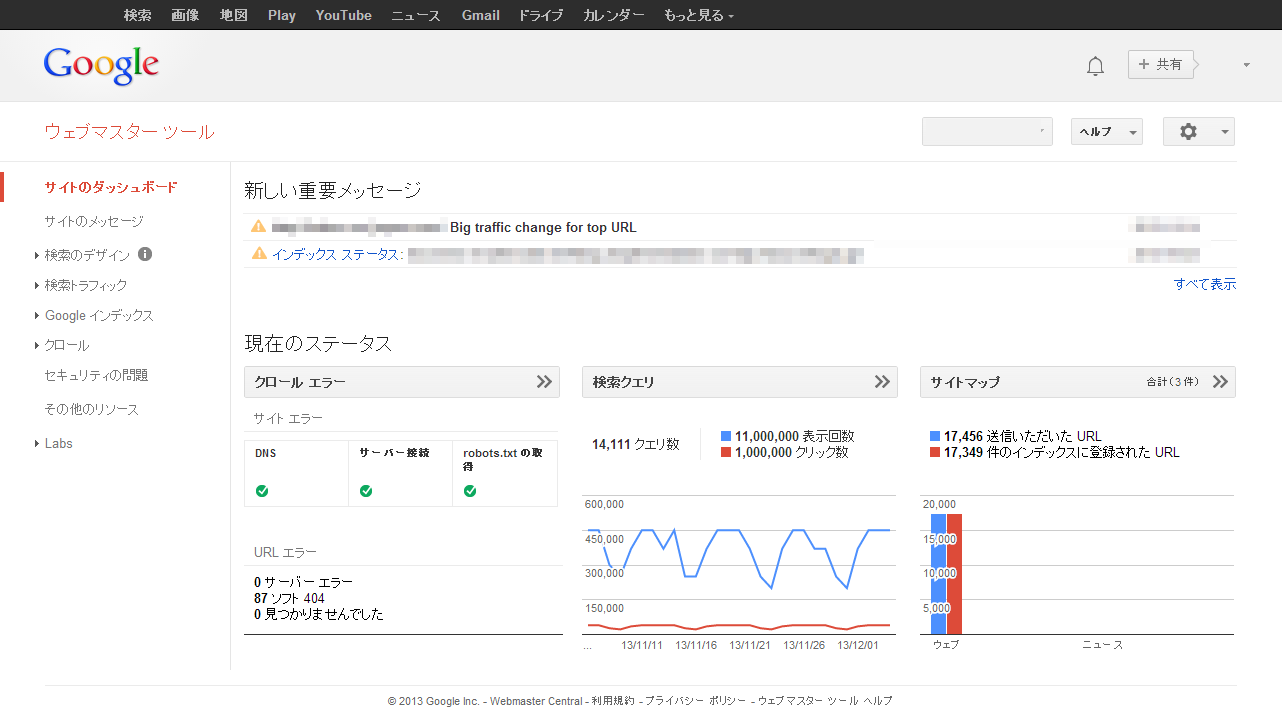
(※イメージのために複数のサイトのデータを合成)
| 項目 | 概要 | 操作 |
|---|---|---|
| サイトのメッセージ | 主にクロールに関する、サイト全般のアラート | |
| 検索のデザイン | ||
| 構造化データ | 構造化文書の認識状況 | |
| データ ハイライター |
構造化文書をWeb UIのクリック操作で設定できる機能。構造化のタグ記述をHTMLソースに記述できない場合に使う | 〇 |
| HTML の改善 | titleタグおよびdescription metaタグの問題点を表示 | 作業 |
| サイトリンク | 検索結果の下部に表示されるリンクで、あまり表示させたくないものを指定する | 〇 |
| 検索トラフィック | ||
| 検索クエリ | Google検索における検索されたキーワード数とクリック数 | |
| サイトへのリンク | 外部サイトからのリンク状況 | |
| 内部リンク | サイト内でのリンク数状況 | |
| 手動による対策 | Googleからの手動ペナルティに関するアラート。2013年8月追加 | |
| Google インデックス | ||
| インデックス ステータス |
Google検索への登録状況 | |
| コンテンツ キーワード |
サイトのキーワード認識状況 | |
| URL の削除 | 検索キャッシュの削除 | 〇 |
| クロール | ||
| クロール エラー | Googlebotによって検出されたエラー | 作業 |
| クロールの統計情報 | 過去90日間のGooglebotのクロール頻度などの統計 | |
| Fetch as Google | 新規ページや修正したページをGoogleにクロールしてもらう | 〇 |
| ブロックされた URL |
robots.txtの認識と検証 | 作業 |
| サイトマップ | サイトマップ作成している場合、その登録と認識状況の確認 | 〇 |
| URL パラメータ | ?xx=123などのパラメータをURLに使っている場合、それを独立したページとして認識させるかさせないかを調整できる | 〇 |
| セキュリティの問題 | マルウェアを配布してしまっているなど問題があれば表示される。2013年10月追加 | |
| その他のリソース | 以前存在し独立したツールなどのリンク集 | |
| Labs | ||
| 著者の統計情報 | Google Plus関連 | |
| カスタム検索 | カスタム検索用のUIラッパー。実体はCSE | |
| インスタント プレビュー |
GooglebotがどのようにHTMLを取得するか、主にモバイル検索とPC検索の表示差異を確認できる | |
| サイトの パフォーマンス |
PageSpeed Insightsへのリンク | |
表1では何かしらの操作を行うものに「〇」を付けた。「作業」と記載したものは状況把握をしながらチェック(マーキング)を行うことができる機能である。そのほかのものは基本的に統計情報などの情報取得である。
サイト開設してからの管理の段階にもよるが、この中でよく使うツールをピックアップすると、
- 開設初期
- ブロックされた URL
- サイトマップ
- (Fetch as Google)
- 運用段階
- サイトのメッセージ
- URL の削除
- Fetch as Google
- クロール エラー
- HTMLの改善
といったところになる。本稿では、ツールの利用開始方法をまとめた後、良く使う機能をピックアップして順番に解説し、最後にSEO的な側面についてもいくつか紹介していく。
なお、「構造化データ」および「データ ハイライター」については、サイトの保守管理と少し性格が異なり、関連ツールも含めた構造化HTMLの詳細を理解していかないと意味がないこともあるので、別の機会で解説できればと思う。
注意:本格的な利用開始には少し時間がかかる
Google ウェブマスター ツールに表示されるデータは、基本的にサイト登録を行い、利用できる状態になってから収集される。そのため利用したいと思って登録直後にいろいろなことができるわけではない。ある程度データが溜まらないと価値を発揮しないツールなので、ひとまずアカウントだけでも作っておく、といった心づもりで作業を進めておくことをお勧めする。
また、各種データはそれぞれ3か月分のデータが保持されており、古いものは表示されなくなる点もあらかじめ留意しておきたい。必要であれば定期的にデータのエクスポートをしていく運用をすることになる。
Google ウェブマスター ツールを使うには?
Google ウェブマスター ツールの利用を開始するには、サイトを登録し、自分がそのサイトの管理者であることをツールに伝えられれば良い。具体的には次の手順でOKだ。
- Gmail(Google)アカウントを取得(既存のものでもOK)
- アカウントにログインした状態でhttps://www.google.com/webmasters/tools/home?hl=jaにアクセス
- サイトURLを登録
- 登録したサイトURLがDNSやファイルなどで自分の持ち物であることを証明する
Gmail(Google)アカウントでログインした状態で、https://www.google.com/webmasters/tools/home?hl=jaにアクセスすると、図2のような画面になる。
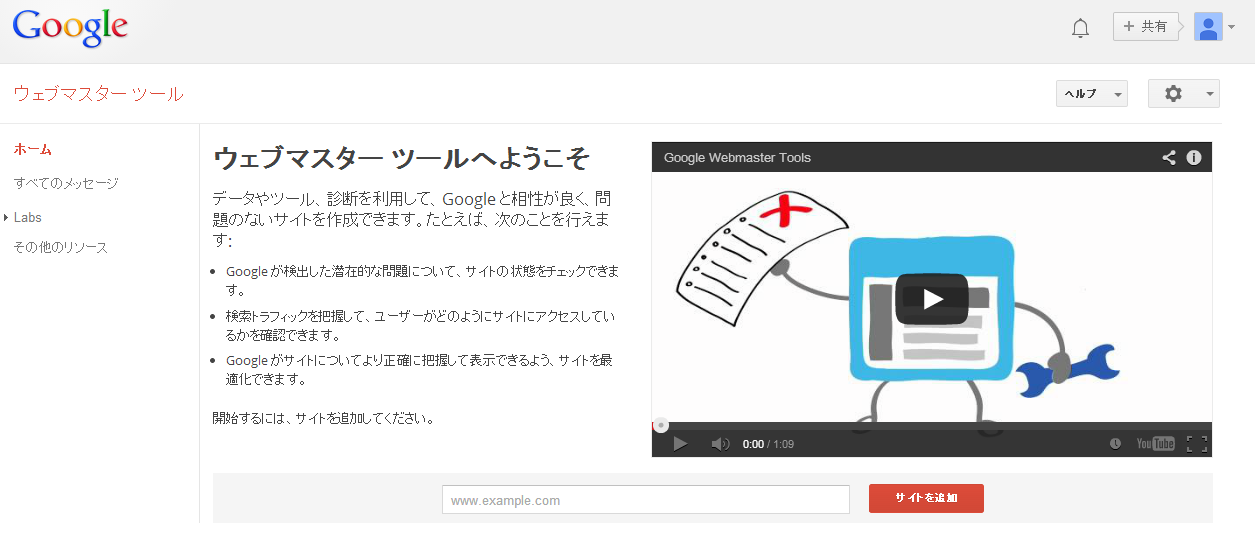
この画面の下部のほうで管理したいサイトのURLを入力し、「サイトを追加」をクリックする。このとき入力するURLはサブドメイン(www.など)も含めたフルドメイン名である。たとえば、www.example.comとexample.comは別のサイトとして認識されるので注意されたい。いまのところ1つのドメイン名登録で各サブドメインのサイトを管理するといった機能はない。それぞれ追加する必要がある。
サイトURLを登録したら、次は認証である。2013年12月時点では表2の認証方法が用意されている。
| 手段 | 操作対象 | 認証方法 |
|---|---|---|
| 1 | DNSサーバー | TXTレコードに固有文字列の記載 |
| 2 | 固有文字列による*.googlehosted.comのCNAMEレコードの作成 | |
| 3 | Webサイト | metaタグに固有文字列を記載 |
| 4 | サイトトップにgooglexxxxxxxx.html形式のファイルを設置 | |
| 5 | 既存のGoogleアカウント | Analyticsアカウント |
| 6 | タグマネージャ |
もっともわかりやすいのは、googlexxxxxxxx.html形式のファイルをサイトトップに設置する方法だろう。設定画面は図3のようになる。
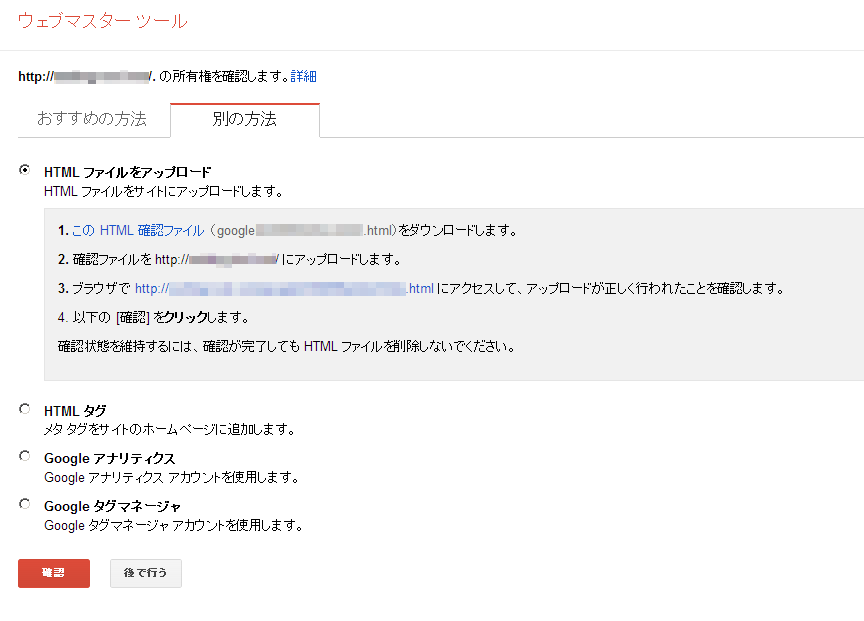
標準では「おすすめ」の方法としてDNS関連の設定が表示されているので、ファイルを置く場合は「別の方法」のタブをクリックして図3の画面を表示させ、認証用ファイルをダウンロード、ダウンロードしたファイルをサイトにアップロードするといった流れになる。サイト側の準備ができたら「確認」ボタンを押して完了である。
認証用のファイルのxxxxxxxxの文字列およびファイルの中身はアカウントに固有である。そのため、多数のサブドメインを1つのWebサーバー(Apache)の名前ベースのバーチャルホストで管理している場合には、認証ファイルへのリクエストをサーバー設定で記述すると楽である。それぞれサイトのドキュメントルートにファイルを置いていったりDNSサーバーに追加していったりする必要はない。一方でアカウントに紐付けられた固有文字列でもあるので、念のため取り扱いには注意したほうが良い。
最初にメールアラートや表示の設定を確認
サイトを登録できたら全体設定を確認しておくことをお勧めする。右上に表示されている「*」(歯車)のボタンをクリックすると全体設定の画面を表示できる。

ここでメッセージの言語とメール送信設定が行える。言語はメッセージの設定であり、メッセージ自体が英語で送られていることもよくあるので日本語のままでとくに変更することはないだろう。
メール通知の内容は2択である。

ここでは「サイトに関する重要な問題」としておいて送付を有効にしておくのをお勧めする。サイトの状態にもよるが、重要な問題としておけばほとんどメールが送られてこないのでうっとうしいということはない。
UIを一時的に英語に切り替える
Google関連のツール全般にいえることではあるが、たまに英語に変更したい場面がある。翻訳がおかしかったり、日本語表示だとデザインが崩れたりすることがあり、そのようなときは一度英語表示にしてみると状況を確認しやすい。UI全体を英語に変更するにはURLを直接書き換えることで行える。具体的には、https://www.google.com/webmasters/tools/~で始まるURLでのところで「?hl=ja」となっている部分を「?hl=en」と手で書き換えてブラウザをリロードすればOKだ。たとえば、後述するサイトマップの画面などで日本語表示だとレイアウトが崩れているが、「?hl=en」とすることで「この文字の翻訳が長すぎてテーブルが崩れていただけだな」ということがわかり、以降はそのつもりで日本語画面を見ていくことができる。英語に不自由がなければ「?hl=en」でアクセスし続けることも1つの手である。
利用できるユーザーのアカウント管理
Google ウェブマスター ツールは、ある登録サイトに対して複数のアカウントで利用できる。利用できるアカウントには以下の3種類のタイプが用意されている。
- 所有者:すべての操作
- フル:アカウント管理以外のすべての操作
- 制限付き:基本表示のみ。一部操作可能だがサイトの設定的なものは操作できない
サイトの所有者はサイト承認作業を行ったアカウントであり、このアカウントでアカウントの追加や削除、権限の設定を行う。操作は行ってほしくないが状況は把握してほしい、外部へ管理を委託したいといった場合には、制限付きのアカウントが利用できる。
アカウントの管理作業は、Google ウェブマスター ツールのトップページ(左上の「ウェブマスター ツール」をクリック)で表示されるサイト一覧から、各サイトの右側に表示される「サイトを管理」ボタンから行う。
もしくはダッシュボードや各機能のページを表示した状態で右上の「*」(歯車)ボタンを押すと、「ユーザーとサイト所有者」という項目が表示されるので、そこをクリックして図8の画面を表示させる。

ここで「新しいユーザーを追加」ボタンを押すと、図9のようなダイアログが表示される。メールアドレスとその権限を指定し「追加」ボタンを押せば完了だ。メールアドレスはGoogleアカウントのものになるので、通常は*@gmail.comの形式になるだろう。
アカウントの追加作業は図9のボックスで完了である。この後とくに認証などのやり取りは発生しない。追加は即時に反映され、メールを指定したアカウントでGoogle ウェブマスター ツールにアクセスすると、指定の権限でサイトが追加された状態になっている。
なお、管理者側でアカウントを削除した場合も即時反映されるが、以前許可されていたユーザー側の画面では「未承認」という状態になってサイト一覧にはサイトが残った状態になる。相手側のユーザーでサイトの削除作業が必要となる点(権限をはく奪したことが目立つ点)に注意していただきたい。
所有者のアカウントを増やす
会社やグループで管理作業している場合は、所有者自体も増やしたいこともある。そういった場合は認証作業を行ったアカウントで、「新しいユーザーを追加」ボタンの左隣にある「サイト所有者の管理」のリンク(図8右上)をクリックして行う。デザインがボタンになっていないので見落としがちだが、所有者の追加もここから設定可能だ。

この機能を使えば、管理者アカウントの複数化や権限の移動(ほかのアカウントを管理者にして自分を降格させる)などが行える。このように最低限必要なアカウント管理機能は備わっている。
いくつかのサイトを管理しているアカウント例が図11である。
制限付きの権限で利用しているサイトは「アクセスが制限されています」と鍵アイコンが表示される。サイト一覧はアルファベット順やサイトの状態(何かしらの問題があるものを上に表示)でソートでき、図12のようなURLとアラートの列挙にもできる。

以上で前準備は完了である。利用環境が整ったところで、それぞれの機能について紹介していこう。
ブロックされた URL
最初にチェックしておきたいのは、robots.txtの認識状況である。Googleのクローラ(Googlebot)以外にも各種クローラがrobots.txtを参照しているので、robots.txtを設置していない場合は、Webサーバーが常に404などの応答を返していることになる。ひとまずは空テキストでも設置しておこう。記述方法はGoogleのヘルプなどを参考にするといいだろう。
Googlebotに正しく認識されていれば、Google ウェブマスター ツールの画面上でステータス200として確認できる。

Googlebotでは、クロール頻度を指定するCrawl-Delayが認識されないので、この項目を記述していた場合は「Googlebot によりルールが無視されました」とアラートが表示されているはずだ。この状態でとくに問題はない。
Google向けrobots.txtのテストツールとして使う
上側のテキストボックスにはGooglebotが取得したrobots.txtの内容が挿入されている。このボックスおよび下側のボックスでrobots.txtの簡易動作シミュレーションを行えるようになっており、robots.txtに何かブロックしたいURLを記述したい場合、それがどのように認識されるかここでテストできる。とくにGooglebotではURL指定でワイルドカード表記が使えるので、その確認用として有用である。
また、Googleのクローラには、PC用とモバイル用のクローラ、Adsenseコンテンツマッチ用のクローラ、Googleニュース用のクローラなどいくつかのクローラが存在し、個別に巡回している。たとえば、Googleニュース用にはなるべくブロックする必要があり、Adsense用にはできるだけブロックしないという運用が必要で、クローラそれぞれで挙動を変更することはよく行われている。クローラによる場合分けを記述した際のチェックツールとしても有用だ。
動作確認をするには、上部のテキストボックスに試したいrobots.txtの内容を実際に記述し、下側のボックスに試験したいURLを記載、チェックしたいクローラを指定して「テスト」ボタンを押す。上部のボックスにはあらかじめ本番サイトのrobots.txtの内容が記載されているが、ここで編集しても実際のサイトへは影響はない。気軽に変更してかまわない。
たとえば、上側のボックスに、
User-agent: Googlebot Disallow: /*/test.html User-agent: Googlebot-Mobile User-agent: *
と記載し、http://xxxx/beta/test.htmlのようなURLを下側に記載してボタンを押すと図14のような結果が表示される。
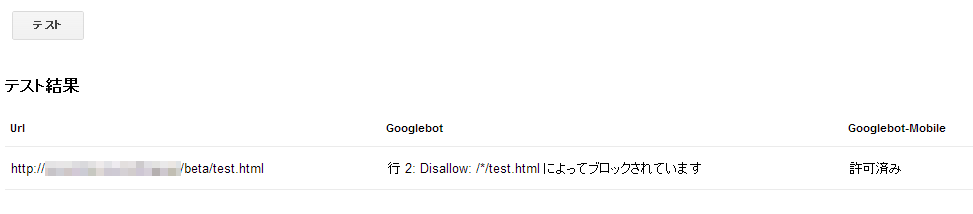
このように動作確認を行ったうえで、実際のサイトのrobots.txtを編集すればちょっとした記載ミスによって検索エンジンに登録されないという事故を防ぎやすくなるといった具合である。
ただし注意点が1つある。このツールは実際のクローラのシミュレーションであり、スペルチェッカーのようなものと捉えておき、登録状況、ブロック状況は実際の状況を確認することをお勧めする。執筆時点ではパーセントエンコードを含むURL(日本語やURL禁止記号を含むURL)のチェックは正しく動作しない問題がある。Webにおけるエンコード処理の問題と思われるが、クローラとツールで挙動が異なってしまっている。
Googlebotのクロール頻度を変更するには?
GooglebotはCrawl-Delayを理解しないので、クロール頻度を変更したい場合には、Google ウェブマスター ツールで設定を行うことになる。左メニューのクロールのところには設定導線がないのでわかりにくいが、サイトの設定のところで設定可能だ。この際、サイト一覧のサイト管理には導線が表示されない。サイトのダッシュボートかいずれかの機能を表示しているところで、右上の「*」(歯車)ボタンを押し、「サイトの設定」を選択する。
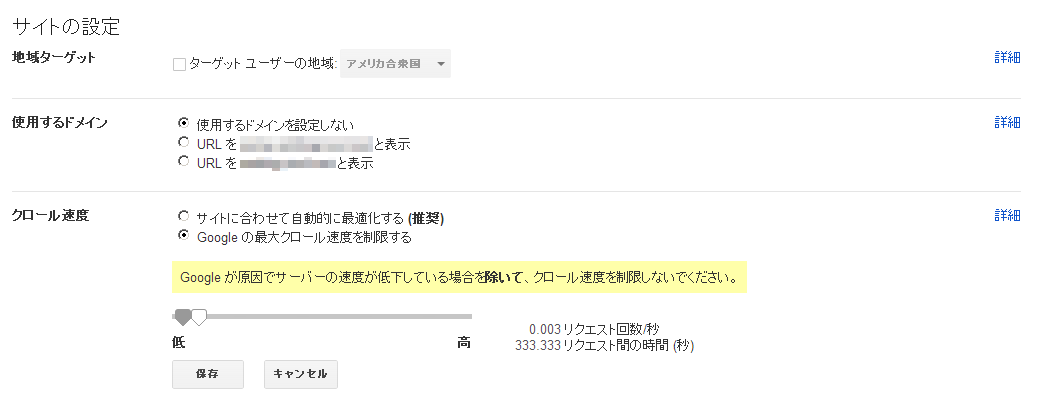
サイトの設定画面の下側に「クロール速度」という項目があり、ラジオボタンで「Google の最大クロール速度を制限する」を選択すると図16のようなUIが現れる。PageRankが高いサイトではGooglebotの訪問頻度が高まりクローラの負荷が問題になることもあるが、警告にあるように通常は設定しないほうが良い。仮にGooglebotの負荷が問題となってもサーバーパフォーマンスの見直しを優先したほうがいいだろう。
サイトマップ
Googleにサイトのページを認識してもらう方法としてサイトマップを利用する方法がある。通常はサイトマップに頼らずクロールされるようにサイトの導線構造を適切に設計していくほうが健全であり、必要ないものだが、埋もれてしまっているページやアクセスの少ないサイトでは有用なこともある。また、Googleニュースに登録する場合や、Googleカスタム検索でページ属性を登録する場合に利用することもあるものだ。
サイトマップは、URL表記などに不備があると認識エラーが増え、サイトの品質を落とす要因にもなりかねないので、できるだけ慎重に作業したいものである点に留意していただきたい。サイトマップにすべてのページを登録する必要はないので、もし正確性に不安があるようであれば、最初は確実に記述できるページだけで構成していくところから始めることをお勧めする。
サイトマップの記述方法は、Googleのヘルプ(https://support.google.com/webmasters/answer/156184?hl=ja)を参照すると良い。日本語がおかしいようだったら?hl=jaを?hl=enとして比較確認してみることをお勧めする。前述のヘルプドキュメントなどもGoogle ウェブマスター ツールの機能画面を開いた状態で、左上のヘルプに関連リンクが現れる。何か不明なとこがあったらヘルプを活用してみる良い。
サイトマップの用意ができたら、「クロール」の「サイトマップ」の画面で、右上にある「サイトマップの追加/テスト」ボタンからテストや登録を行う。
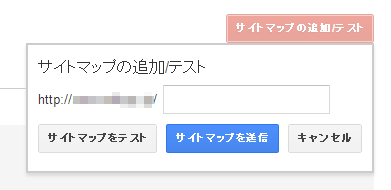
まずは「サイトマップをテスト」のほうをクリックすると、サイトマップがパースされ、その結果が表示される。

このようにエラーなく認識されたら、もう一度同じようにサイトマップのURLを追加し、「サイトマップを送信」のほうをクリックして登録する。すぐには検索インデックスには登録されず、処理待ちとして数日は待つぐらいの感覚である。少しずつページがインデックスに登録されていき、認識状況をグラフとともに確認できるようになる。

運用状態に入ったサイトでも日々のページ追加もあるため、すべてが登録された状態ではなく、常に送信数に対してインデックス登録は少し少ないといった状態が続く。登録されていないページが多少あってもとくに問題ではない。もし多数のページが登録されないといった状態なら、1つのページがいくつかのURLで記載されていないか(重複コンテンツ)、存在しないURLを記述してしまっていないかなど確認したほうがいいだろう。
もしサイトマップファイル自体に不備が発生し、何かしらの問題がある場合は、ファイル一覧のところで!アイコンが表示され、問題の件数に数字が記載される。

ファイル名もしくは問題の件数の部分がリンクになっており、そこをクリックするとそのファイルの詳細情報が表示される。エラーがある場合はエラーのタブが追加され、その内容について詳細が記述される。
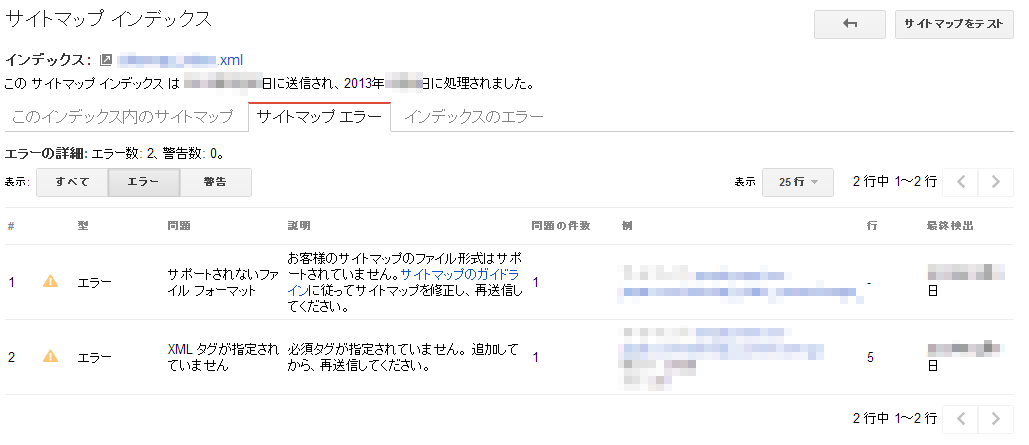
ある程度詳細に警告が記載されるので、この内容を参考にサイトマップを修正しくことが可能である。
Fetch as Google
Fetch as Googleは、特定URLのクロールと、Google検索にインデックスを登録してもらうように手動で依頼するツールである。このツールを使うと、即座にクロールが行われ、Google検索のインデックスへ登録申請もできる。利用場面としては、作成・修正したページが正しくクロールされるかのチェックと、Google検索への登録を少しでも早めたいときの2つである。
登録手順は2ステップで行われる。まず、Fetch as Googleのページを開き、上部のテキストボックスにURLを入力して「取得」ボタンを押す。
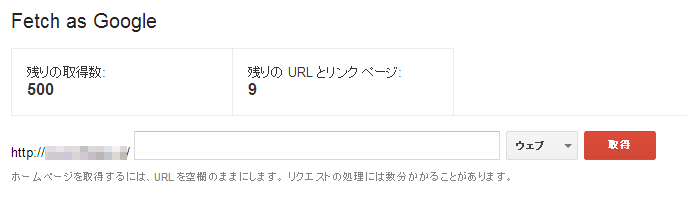
入力したURLに対して、バックエンドで実際にクロールが行われ、通常は数秒後に画面が切り替わる。画面下側にURLが列挙されていき、問題なく取得できれば「成功しました」と表示される。これでクロールチェックは完了である。

続けてクロールされたページをGoogle検索のインデックスに登録する場合は、「インデックスに送信」ボタンを押し、次の画面で単独ページを送信するか、送信したページとそのページにあるリンク先をクロールするかを選択する。
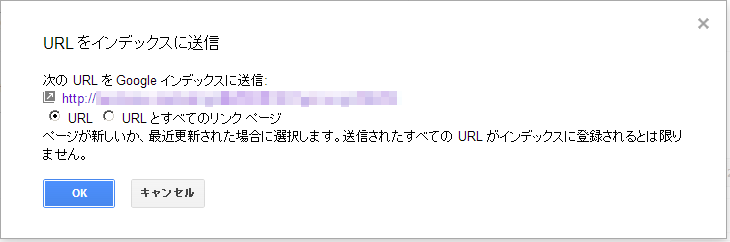
この際、一連の動作は画面描画と非同期処理で行われており、操作が速いとエラーが続出する。ゆっくり作業をするのがコツである。
Fetch as Googleの注意点
Fetch as Googleはアカウントごとに送信制限が設けられており、
- 単独ページ 500件/週まで
- ページとそのリンク 10件/週まで
となっている。あとどのくらい送信できるかは画面上に記載されており、時間の経過とともに制限数が回復していく仕組みだ。
このツールは立ち上げたばかりのサイトでどうしても特定のページがインデックスされない場合に使うこともできるが、そのような場合はサイトの導線構造を見直すほうを優先すべきである。また、一度インデックスされると、次の更新まで一定の期間を置かれて更新が滞ってしまうので注意が必要だ。「作業中のページをとりあえずGoogle検索に登録してみるか」といったことには使わないほうが良い。できるだけしばらくこの状態で問題ないという完成度までページ作成が進んでから使うことをお勧めする。通常のページ公開時も考え方は同様だ。うっかりクロールされてしまうとページを修正しても更新されにくく、しばらく古いページが残ってしまう。
また、Fetch as Googleは依頼ツールであり、インデックスが更新されるかどうかはGoogle任せという点にも留意しておきたい。通常はまずキャッシュが更新され、その後に検索結果に表示されるサマリが更新される。1週間ほどで更新される場合もあればもう少し時間がかかるときもある。埋もれたページだと3か月ほど更新されない状況になるのでこのツールを実施するだけの価値はあるが、それほど依存してもいけないツールである。何らかの理由で緊急の更新が必要な場合は、後述するURL削除を利用したほうが良い。
サイトのメッセージ
Google ウェブマスター ツールを使いだすと、ときどきサイトに関するメッセージが送られてくるようになる。MediaWikiやWordPressを利用していれば、それらのアップデートアラートもメッセージとして流れてくる。
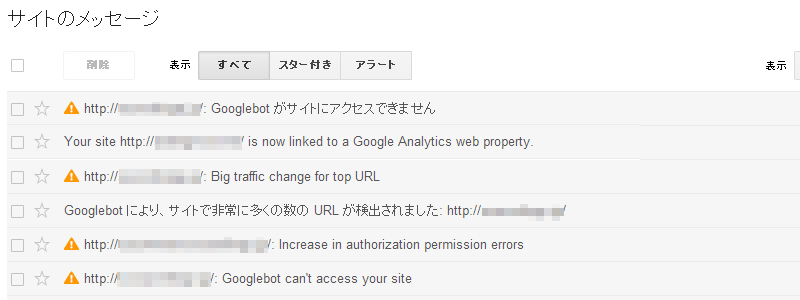
黄色い!マークアイコンが付いたメッセージは注目すべきメッセージである。
前述の全体設定における重要な問題のメール送付では、!マークのものがすべて送付されるわけではない点に注意しておきたい。クローラがサイトにアクセスできない、サーバーエラーが増えているといった致命的な問題のみが送付されてくる。
サイト運用では、基本的にメッセージに記載してあるとおりの問題が発生しているので、その対処が必要となる。表現はそのときどきで多少変わるのと、日本語設定でも英語が流れてくることもある。どのような種類のメッセージが流れてくるか以下にピックアップしたので、参考にしていただければと思う。
!マークあり Googlebot can't access your site Increase in soft 404 errors Increase in not found errors Increase in server errors Increase in authorization permission errors Incorrect zzzz implementation on xxxx User-generated spam Big traffic change for top URL マークなし Googlebot found an extremely high number of URLs on your site: Your site xxxx is now linked to a Google Analytics web property. Crawl rate change request for xxxx WordPress Update Available MediaWiki Update Available
これらのうち、「Big traffic change for top URL」は気にする必要がないケースが多い。アクセス数に大きな変化があったので、何かしらサイトに問題が発生した「可能性があるのかも」ぐらいに捉えておくのが良い。大きなアクセス数変化があったときにメッセージが流れてくるのだが、日本の祭日を考慮していないようで連休があったときにこのメッセージが届きやすい。
URL の削除
Google検索に登録されているページを削除したい場合は、Google ウェブマスター ツールから行うことになる。この際、実際にそのページが一般からアクセスできない、もしくは少なくともクローラがアクセスできない状態が必要になる。ページ削除の流れとしては以下のようになる。
- 削除したいページを実際に削除しサーバーレスポンスとして404を返すようにする。もしくはrobots.txtにて該当URLをクローラからブロックする
- 「URL の削除」にてURLを入力し、削除申請をする
- 1日ほどでGoogle検索の検索結果ならびにキャッシュが削除される(2013年12月時点)
Fetch as Googleとは異なり、反映は速やかに行われる。
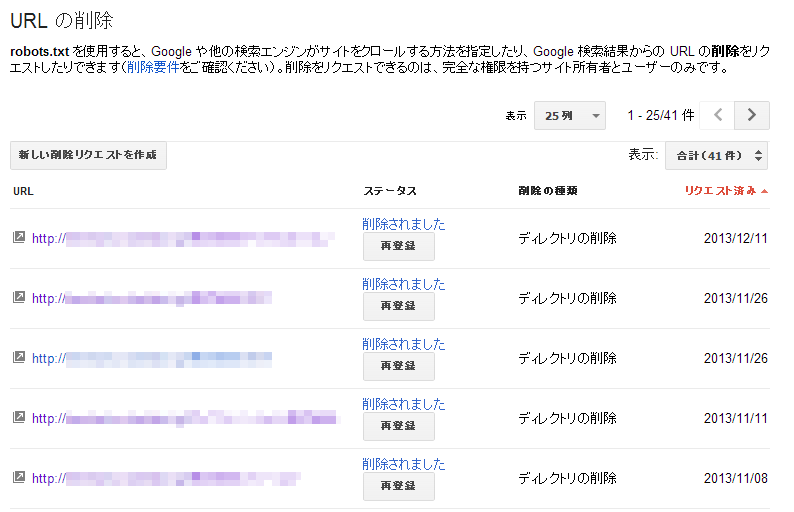
削除依頼の際には、単独ページの削除のほかに、キャッシュのみ削除、ディレクトリの削除が選べる。

ディレクトリを削除は指定ディレクトリ下を削除するというよりは先頭マッチのURLパターンを削除するように動作し、ディレクトリ構成になっている必要はない。パラメータ付きのURLが複数ページ存在し、一気に削除したい場合にも利用できる。
なお、URL の削除の機能もバックエンドとの同期に失敗しやすいツールであり、画面遷移に失敗したり、削除件数などで誤ったデータを取得してしまったりすることが多々ある。何か動きがおかしいと思ったら、あまり深く考えず、画面をリロードしなおして確認しなおすと良い。
URL の削除の注意点
URL の削除も利用制限がある。1日のリクエスト数は約1000件に制限されており、リクエストの操作間隔も短すぎると操作ができなくなる。ボットによる操作を避けるようなロジックが組まれているといったところだ。なお、この制限は明示されているわけではない2013年末時点の挙動であり、2013年末時点でも仕様変更が行われている。今後仕様が変わる可能性があることに留意していただきたい。
特定ページの修正を緊急で反映させるシナリオ
個人情報やパスワードなど公開したくない情報がサイトに掲載されてしまい、急ぎページは修正したが、Google検索の結果も緊急に修正したいといったことがあるとする。そのような場合、Fetch as Googleでは反映されるまでに最低でも数日単位の時間が必要になってしまう。そのような場合は、現状以下の手段が有効な手段となる。
- 問題を修正したページrobots.txtで一時的にブロックする
- URL の削除を使って該当URLを削除する
- 1日後、Google検索で削除が確認できたらrobots.txtを元に戻す
この作業で速やかにGoogle検索から問題の記述は削除できることになる。URL の削除で申請した削除は90日間有効であり、その後は通常状態に戻るので、当面はこのような対策をしておくというのが比較的現実的な作業となる。
修正したものを検索できるようにはしたいが、修整反映も即座に行いたい場合は、多少手間になるが、修整したページを別URL(パラメータ付きのみ閲覧可、少しURL文字列を変えるなど)で閲覧できるようにし、そのURLを新たにインデックスさせるというのが1つの手段となる。その際、上記の手順の後、元のURLから新しいURLに対して301リダイレクトを設定するという手順になる。そうすることで元のURLにほかのサイトから被リンクなどあった場合にも無駄にならない。内部リンクの修正も(ひとまず)必要はなくなる。
クロール エラー
クロール エラーでは、クローラがページを取得した際、なんらかのエラーがあったものが90日間記録されている。ここに記録されたエラーはユーザーも遭遇している可能性が高く、サイトの品質という面ではエラーがないようにすることはもちろんだ。加えて、基本的にエラーが多いサイトでは検索順位が低下している。
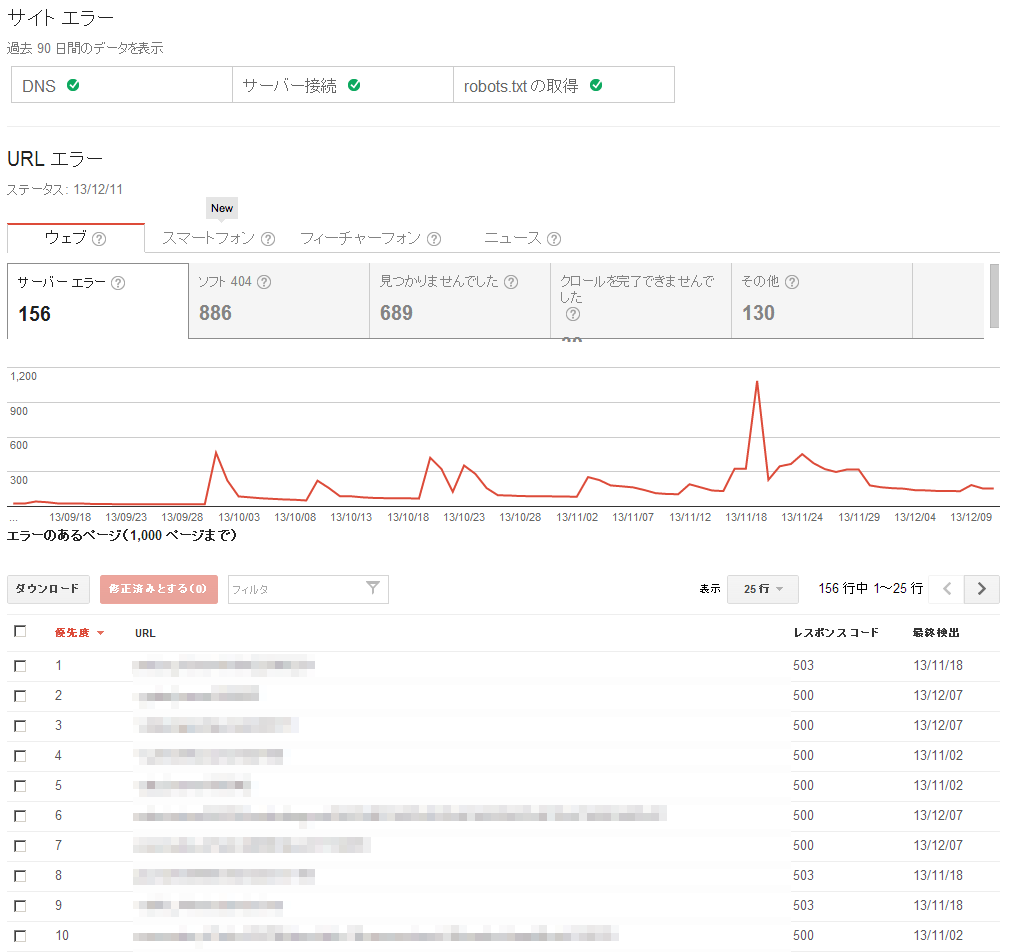
具体的なエラーは下部に優先度(エラーの頻度)順に表示されているので上から片づけていく形になる。それぞれの項目はクリックするとその詳細がポップアップ表示される。
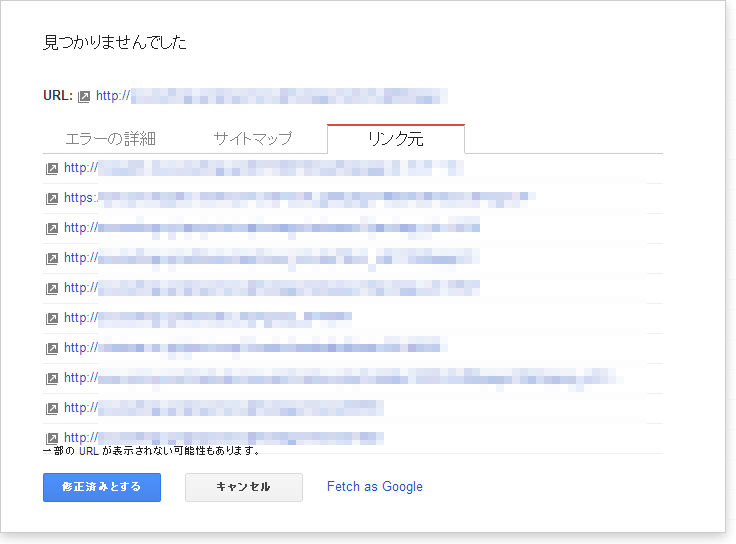
最初に手をつけておいたほうが良いのは内部リンク切れによる404エラーと、認証が必要なページにリンクをしてしまっている401や403エラーである。認証が必要なページにクローラが訪れてしまう導線は切っておいたほうがいい。これらエラーのほとんどはHTMLの修正で解決できる。図29のようにリンク元のタブもしくはサイトマップを見えれば、どの導線からクローラがエラーを検出したかがわかるので、修整が必要なページもわかる。
もし、5xx系のサーバーエラーが発生しているようならWebサーバーやロードバランサーの管理を見直すことになる。エラーの日付が特定の日に集中しているようならその日にロードバランサーやスイッチに何か問題がある可能性が高い。ある程度分散しているようならWebサーバーやバックエンドのプログラムやデータベースなどを疑うことになるだろう。
1つ1つ丁寧につぶしていき、すべてが解決していれば、図30のような表示になる。シンプルすぎる表示だが目標の画面である。

クロール エラー0をあきらめる場合もある
ある程度の規模のサイトになるとエラー0をあきらめざるを得ない場合もある。前述したように外部サイトでリンクが張られた際、そのURL記述にミスがある場合が意外と無視できない。とくに日本語URLを使っている場合は、パーセントエンコードのリンクミスや途中切れは発生しやすく、URLに%だけがあったり、%に1ケタ数字のURL文字列として想定できないものが含まれたりするなど、一般的な対処では対応できないこともある(Apache2ならPerlPostReadRequestHandlerで%を含んだリクエストを前処理できるが一般的な対応とはいえないだろう)。
また、誤ったリンクからのエラーであれば、エラーを放置するという選択も現実的な解である。誤ったリンクに対応する適切なURLに対して301リダイレクトを設定していく対応もよく行われるが、その数や文字列パターンによっては、手間が膨大だったり、リダイレクトコードの管理が煩雑になる可能性があったりする。このあたりになると作業量とのトレードオフになるだろう。
エラーページはきちんと404応答をする
もう1つ重要なのは、ページがないURLはきちんと404応答することである。Webサイト運営としては当たり前の話ではあるが、これができていないサイトもある。存在しないページを200応答していた場合、内部リンク切れなどの問題があってもクロール エラーで検出できず、このツールの効率が悪くなる。もし存在しないページを開いてみて200応答が返ってきているようなら404エラーを返すようにWebサーバー設定を見直そう。
なお、PageRank保持を目的として存在しないページで404エラーを返さず200を返すというSEOが行われることもある。これに対してGoogleは対策アルゴリズムを入れてきているので、昔のように小手先のギミックは通用しなくなってきていると考えたほうが良い。
HTMLの改善
各ページが検索結果で露出が高まるようにするためには、titleタグおよびdescriptionが重要な要素である。検索結果として直接利用されることが多いことだけなく、同じサイト内に重複したページがあると、閲覧者に混乱を招くこともある。また、該当ページの検索順位が下がっていたりする。
HTMLの改善では、そういったtitleタグおよびdescriptionの重複ページの存在など、その不備について検出してくれる。

問題が検出された項目をクリックすると、該当の問題記述とそのURLが一覧で表示される。URLクリックすれば実際のページに移動するので、HTMLソースを確認し、修整していく作業の流れとなる。

それぞれ地道に修正していくしかないところだが、最初はわかりやすいところだけでも修正して、問題の個数を減らしてくことが始めるといいだろう。
とくに注意したいのはトップページのtitleおよびdescriptionを標準テンプレートとして扱い、各ページでその記述を流用しているケースである。ときどき見かけるが悪い手法なので注意されたい。descriptionは重複するぐらいならないほうが良い(Bingのチェックツールではアラートが検出されてしまう問題が別途あるが致命的ではない)。もし、このような問題を抱えているサイトがあり、すべての修正がすぐに難しいようであれば、各ページの修正(テンプレート流用)はいったんそのままにして、トップページのtitleとdescriptionを改めて作成する作業をお勧めする。この作業だけでもサイトのアクセス数が変わるはずだ。
地道にエラーをなくしていき、すべての問題がなくなれば図33のような画面が表示される。

一定の規模のサイトだと完全になくすことは難しい場面もあると思うが、クロールエラーと異なり本質的にエラー0になるものなので、完全な解決を目指さそう。
SEOツールとしての側面
以上、サイトの保守管理面の強い機能についてポイントを紹介してきたが、そのほかのツールもSEOとしては常に利用するものが多い。活用方法はサイトの性質によって異なり、また個別のノウハウの部分もあるので詳しくは解説できないが、定性的なところをいくつかピックアップしておこう。まずはサイトキーワードの確認である。

ここにはそのサイト全体のキーワードについて集計されている。上位のキーワードがそのサイトのテーマとなり、検索キーワードとして強くなる。ターゲットとしたいキーワードがあればそれが一番上位にくるように、サイト内で使われている単語を見直したり、テーマに沿ったコンテンツページを追加していったりする対応を行っていく。
次にチェックしておきたいのはインデックス ステータスである。前述の重複コンテンツと関連するが、理想的なサイトであれば認識数が図35のように右肩あがりのグラフになる。
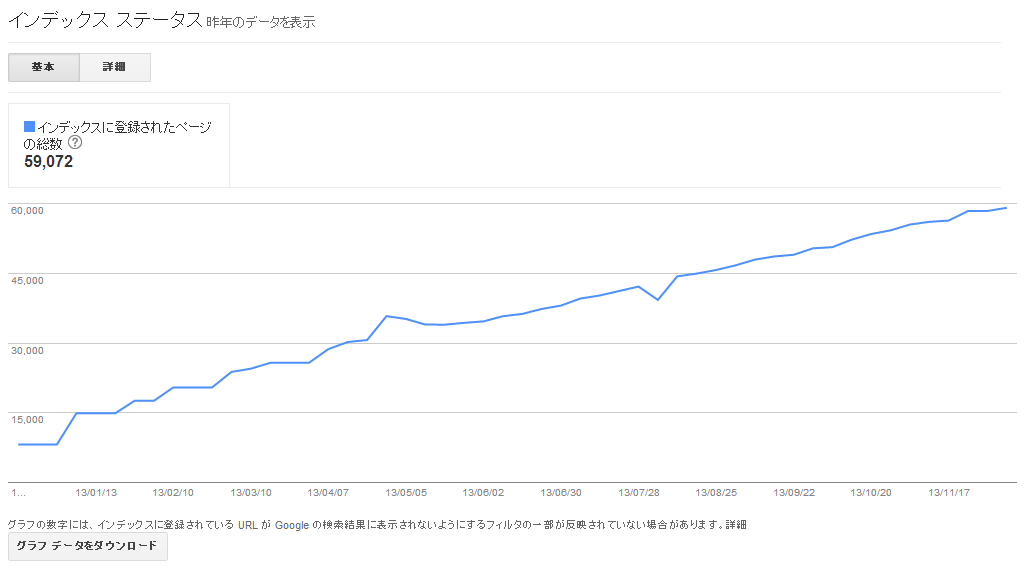
このグラフが途中大きく凹んでいたり、上下していたりする場合は何かしらの問題を抱えており、速やかな修正が必要だ。また、想定されるコンテンツページ数に対して異常に多く認識されている場合は、意図しない重複ページが存在し、全体に検索流入を減らしている状態である。
SEOとしてもっとも活用するのは、検索クエリである。
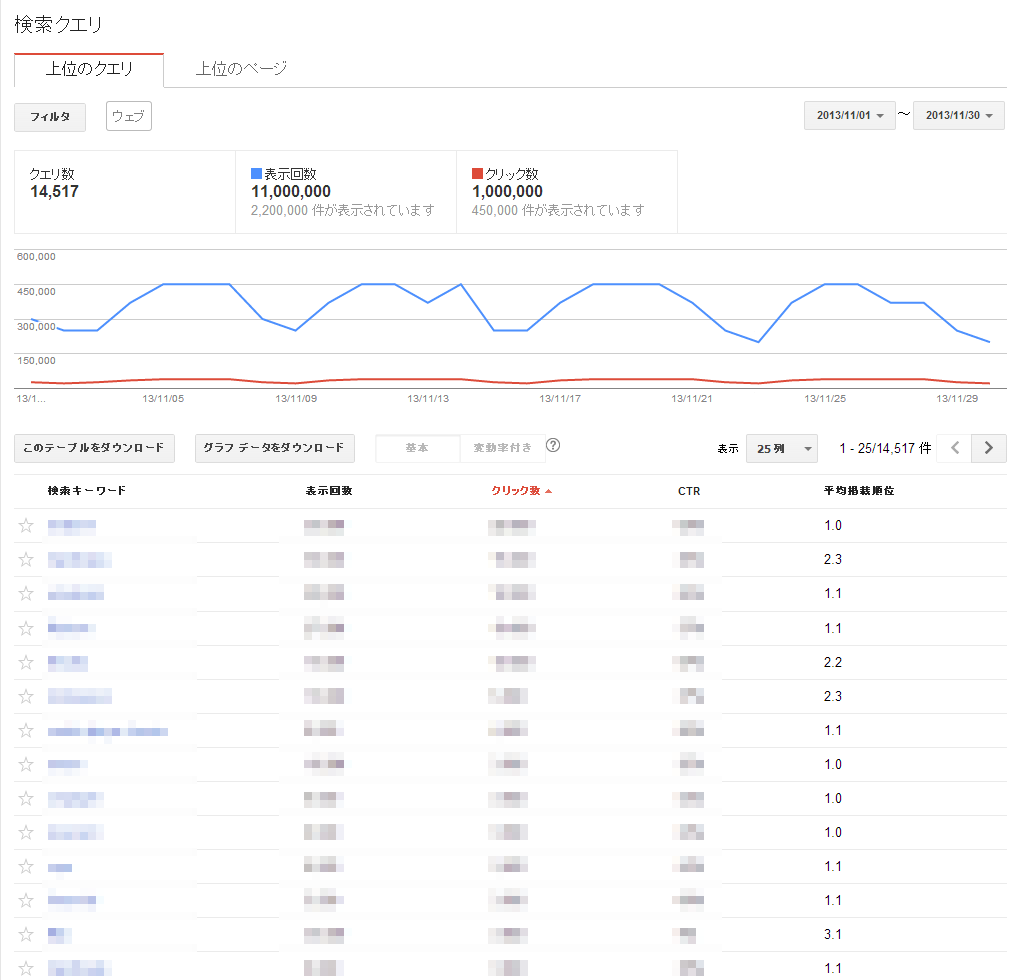
特定のキーワードに対し、どれだけ検索され、どれだけクリックされたかおおよその数値がわかる。それぞれのキーワードをクリックするとどの順位で何回掲載されたかが表示される。ここに記載された値は、指数的なまるめが行われたサンプル値で表示されているので、それぞれの数値が中心値である確率的な表記であると捉えておく点が重要だ。傾向を把握するのに使い、項目同士、数値同士の差を比較するような使い方はあまり意味がない点に注意されたい。
検索クエリを活用する際の戦略1つとしては、表示回数が多いもので順位が2ケタ、つまり通常の検索動作で2ページ目以降に表示されているものに注力することである。2ページ目以降に表示されているものが1ページ目にきた場合の流入増加のインパクトがあるので、そういったキーワードをピックアップし、対象ページもしくは新しいコンテンツページの制作に役立てるといった具合だ。
Googleのツールである、されどGoogleのツールである
以上、サイト管理の流れに沿うような形で紹介してきたがいかがだっただろうか。通常の解説記事とは異なり、経験則的な内容をそれなりに盛り込めたのではないかと思う。
最後に大事なポイントを紹介したい。それはGoogle ウェブマスター ツールをツールとして過信しないことである。Google検索の情報を活用でき、クロールの統計情報も自動的に蓄積されているのでかなり有効なツールであるが、ときどきおかしな動作をする。一時的に間違った値が入ったことも何度か経験している。本当の大きな問題が発見されれば迅速に行動したいところではあるが、ツール側の問題で一喜一憂するのは時間の無駄である。まずは慌てず、ツールのアップデートがあったのではないか? 何かメンテナンス中ではないか? たまたまデータ取得に失敗したのではないか? といったことを念頭におき、1日寝かすぐらいの気持ちで付き合うことをお勧めする。
Googleを過信しているユーザーがときどきいるが、どのツールも人が作ったものである。間違いもある。ベータ版ツールとして自分でデバッグするぐらいの気楽なスタンスで付き合うと丁度良い。