S3QLでさくらのオブジェクトストレージサービスをローカルマウントしてみよう

本記事は2021年3月まで提供しておりました旧オブジェクトストレージサービスに関する情報です。現行のオブジェクトストレージとは互換性のないAPIを用いているため、現在はご利用いただけません。ご了承ください。
はじめまして。姫野と申します。
ここでは、さくらのクラウドで「Amazon AWS S3(S3)互換API」をサポートしたオブジェクトストレージサービスが正式にリリースされたのを記念して、「さくらのクラウド」のオブジェクトストレージ(以下オブジェクトストレージ)をサーバーにマウントして使えるS3QLを紹介します。
オブジェクトストレージを使う理由
ファイルサーバーなどを構築する際、どのぐらいのストレージを準備すればいいか、悩んだことはありませんか?
増え続けるファイル容量、激写される写真や動画、編集するたびに増えるバックアップ…。データの増加を見越して5年程度は対応できるようにストレージを準備しても、2~3年で使い切ってしまったり、逆に全然使わなくて無駄が生まれたりと、ストレージの選択は本当に技術者泣かせです。
オブジェクトストレージはS3互換のhttp/httpsベースのストレージサービスです。容量無制限で、ローカルストレージを準備するよりも安価に大量のファイルを保存することができます。
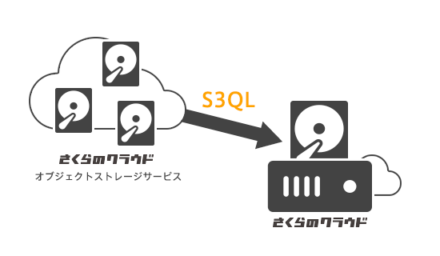
ファイルサーバーとして使うにはとても便利なのですが、そのままではファイルシステムとしてマウントすることができません。
そこで、オブジェクトストレージをファイルシステムとして取り扱うことができる、S3QLを使い、容量無制限の世界を体感してみようというのが今回の主旨です。
なぜs3fsではなくS3QL?
S3互換ストレージをサーバーにマウントして使う場合、s3fsが一般的です。
実際、s3fsを定期的なバックアップなどで使うのであれば、とても優れたOSSであり、弊社でも使っていますが、s3fsを使って読み書きをするとメモリリークが発生しやすいため、弊社では定期的に再マウントしながら運用しています。
しかし、継続的にマウントしてサービスを提供することを考えると、あまり現実的な運用方法とは言えません。そこで「常にマウントすることができ、安定して運用できるOSSはないか?」と探した結果、S3QLにたどり着き、満足する結果が得られたため、S3QLを今回紹介することとしました。
S3QLの特徴
S3QLではどのようなことが簡単にできるのか?
・1ファイル2TBまでのサイズをサポート
・GZIPアルゴリズムを利用したディスク圧縮機能
・データ重複削除機能
・ディレクトリ単位で書き込み/読み取りのロックができる機能
・書き込み/読み込みキャッシュ
・コピーオンライト/スナップショットのサポート
S3QLを使う上での注意点もあります。
・S3QLはオブジェクトストレージ内に独自形式でファイルシステムを作る構造になっているため、S3QLを経由しないと保存されたファイル名や中身を参照することができません。
・S3QLは複数サーバーからの同時アクセスをサポートしていません。S3QLのドキュメントでは1台でマウントした後、NFSやCIFSなどで共有してからアクセスする例が紹介されています。
S3QLのインストール手順
実際にS3QLを利用するためのインストール手順を紹介します。
今回は、さくらのクラウド上でCentOS6.6 64bit(基本セット)をベースに構築します。
S3QLをインストールするために必要なパッケージを順に導入していきます。
1. ビルド・マウントに必要なパッケージをインストール
CentOSのリポジトリからインストールします。
# yum install fuse fuse-libs fuse-devel libattr-devel
fuseモジュールを読み込む
# modprobe fuse
2. python3.3インストール
標準リポジトリには存在しないため、PUIASからインストールします。
# cd /etc/pki/rpm-gpg/ # wget -q http://springdale.math.ias.edu/data/puias/6/x86_64/os/RPM-GPG-KEY-puias # rpm --import RPM-GPG-KEY-puias # cat <<EOF >> /etc/yum.repos.d/puias-computational.repo > [PUIAS_6_computational] > name=PUIAS Computational Base > mirrorlist=http://puias.math.ias.edu/data/puias/computational/\$releasever/\$basearch/mirrorlist > gpgcheck=1 > gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-puias > EOF # yum install python3 python3-devel python3-libs python3-setuptools
3. easy_installで必要なパッケージをインストール
Pythonのeasy_install機能を使ってインストールします。
# easy_install-3.3 -U pycrypto # easy_install-3.3 -U defusedxml # easy_install-3.3 -U requests # easy_install-3.3 -U llfuse # easy_install-3.3 -U dugong
4. SQLiteインストール
こちらも標準リポジトリにはないため、SQLite本家から取得してコンパイルします。
CentOS標準のSQLiteと重複しないようにインストール場所を「/usr/local/sqlite-3.8」に指定します。
# cd /usr/local/src/ # wget -q http://jaist.dl.sourceforge.net/project/sqlite.mirror/SQLite%203.8.8.2/sqlite-autoconf-3080802.tar.gz # tar zxf sqlite-autoconf-3080802.tar.gz # cd sqlite-autoconf-3080802 # ./configure --prefix=/usr/local/sqlite-3.8 # make # make install # echo "/usr/local/sqlite-3.8/lib" > /etc/ld.so.conf.d/sqlite.conf # ldconfig
5. APSWをインストール
インストールしたSQLiteに対応するバージョンをインストールします。
# cd /usr/local/src/ # wget -q https://github.com/rogerbinns/apsw/releases/download/3.8.8.2-r1/apsw-3.8.8.2-r1.zip # unzip apsw-3.8.8.2-r1.zip # cd apsw-3.8.8.2-r1
セットアップファイルを編集します。
# vi setup.py
変更箇所は赤文字になっている部分です。
(一部抜粋)
from distutils.core import setup, Extension, Command from distutils.command import build_ext, build, sdist ## ## Do your customizations here or by creating a setup.cfg as documented at ## http://www.python.org/doc/2.5.2/dist/setup-config.html ## include_dirs=['src','/usr/local/sqlite-3.8/include'] library_dirs=['/usr/local/sqlite-3.8/lib'] define_macros=[] libraries=[] # This includes the functionality marked as experimental in SQLite 3. # Comment out the line to exclude them define_macros.append( ('EXPERIMENTAL', '1') ) ## ## End of customizations ##
編集後、インストールします。
# python3 setup.py install
6. S3QLのインストール
S3QLのサイトから最新版を取得してインストールします。
# cd /usr/local/src/ # wget -q https://bitbucket.org/nikratio/s3ql/downloads/s3ql-2.13.tar.bz2 # tar jxf s3ql-2.13.tar.bz2 # cd s3ql-2.13 # python3 setup.py build_ext --include-dirs='/usr/local/sqlite-3.8/include' --library-dirs='/usr/local/sqlite-3.8/lib' --inplace # python3 setup.py install
これでインストール完了です。
次は設定を行います。
S3QLの設定手順
S3QLを使うための設定ファイルを作成します。
事前にさくらのクラウドでオブジェクトストレージを作成しておきます。
必要になるパラメータは以下の2つです。
・アクセスキーID
・シークレットアクセスキー
実際に設定していくため、下記の値を仮に使っていきます。
・アクセスキーID: sakura-object-storage
・シークレットアクセスキー: XXXXXXXXXXXXXXXXXXXXXXXXXXXXX
1. 設定ファイルの作成
オブジェクトストレージを使用するための設定を入れていきます。
( fs-passphraseは暗号化する場合のみ値を入れてください。今回は「mogamoga」というフレーズを使用します)
# mkdir /root/.s3ql/ # vi /root/.s3ql/authinfo2 [s3c] storage-url: s3c://b.sakurastorage.jp/sakura-object-storage backend-login: sakura-object-storage backend-password: XXXXXXXXXXXXXXXXXXXXXXXXXXXXX fs-passphrase: mogamoga # chmod 600 /root/.s3ql/authinfo2
2. マウントポイントの設定
ストレージのマウントポイントを作っておきます。
# mkdir /var/sakura_storage
3. S3QLファイルシステム作成
オブジェクトストレージ内にS3QLのファイルシステムを構築します。
# mkfs.s3ql --plain --authfile /root/.s3ql/authinfo2 s3c://b.sakurastorage.jp/sakura-object-storage Before using S3QL, make sure to read the user's guide, especially the 'Important Rules to Avoid Loosing Data' section. Purging existing file system data.. Please note that the new file system may appear inconsistent for a while until the removals have propagated through the backend. Creating metadata tables... Dumping metadata... ..objects.. ..blocks.. ..inodes.. ..inode_blocks.. ..symlink_targets.. ..names.. ..contents.. ..ext_attributes.. Compressing and uploading metadata... Wrote 109 bytes of compressed metadata.
4. ファイルシステムのマウント
オブジェクトストレージをマウントします。
# mount.s3ql --allow-other s3c://b.sakurastorage.jp/sakura-object-storage /var/sakura_storage/
うまくできましたでしょうか?
mount コマンドで確認して s3c://b.sakurastorage.jp/...... が見え、/var/sakura_storage/ 内にファイルを読み書きできれば成功です!
次はOS起動時に自動でマウントするように起動スクリプトを作ります。
# vi /etc/init.d/s3ql-sakura-object-storage
(下記は例となります)
-----------------------
#!/bin/bash
#
# chkconfig: 345 60 40
# description: s3ql mount/unmount
#
# Source function library.
. /etc/init.d/functions
AUTHFILE="/root/.s3ql/authinfo2"
STORAGE_URL="s3c://b.sakurastorage.jp/sakura-object-storage"
MOUNTPOINT="/var/sakura_storage"
OPTIONS="--cachesize=102400 --allow-other --authfile ${AUTHFILE}"
RETVAL=0
function start()
{
echo -n $"Mounting S3QL: "
mount | grep ${MOUNTPOINT} > /dev/null
if [ $? -ne 0 ]; then
/usr/bin/fsck.s3ql --batch --authfile ${AUTHFILE} ${STORAGE_URL}
/usr/bin/mount.s3ql ${OPTIONS} ${STORAGE_URL} ${MOUNTPOINT}
RETVAL=$?
[ $RETVAL -eq 0 ] && success || failure
echo
else
echo $"Cannot mount $MOUNTPOINT. Already mounted !!"
echo
RETVAL=2
fi
}
function stop()
{
echo -n $"Unmounting S3QL: "
mount | grep ${MOUNTPOINT} > /dev/null
if [ $? -eq 0 ]; then
umount.s3ql ${MOUNTPOINT}
RETVAL=$?
[ $RETVAL -eq 0 ] && success || failure
echo
else
echo $"Already unmounted !!"
echo
RETVAL=3
fi
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
echo "Usage: `basename $0` { start | stop | restart }"
RETVAL=4
;;
esac
exit ${RETVAL}
-----------------------
# chmod 755 /etc/init.d/s3ql-sakura-object-storage
# chkconfig s3ql-sakura-object-storage --add
このスクリプトでマウントできるかどうかのテストをします。
# service s3ql-sakura-object-storage restart
これで無事マウントできれば、再起動後も自動でマウントされます。
終わりに
今回は、S3QLの基礎的な使い方を紹介させていただきました。
容量無制限で使えるオブジェクトストレージを、バックアップやファイル置き場として便利に使うことができるはずです。
オブジェクトストレージを安定して使用する1つの案として覚えていただければ幸いです。
それでは、素敵なオブジェクトストレージライフを!