AWS大規模障害を乗り越えたNetflixが語る「障害発生ツールは変化に対応できる勇気を与えてくれる」
このコラムのNetflixの「FIT(障害注入テスト)」について書いた記事を執筆した直後のことですが、Netflixのサービスをある災害が襲いました。AWS(Amazon Web Services)のus-east-1リージョン全体で大規模障害が発生したのです。
この大規模障害を同社がどのように乗り切ったか。その一部が以下のBlog記事で明かされています。
「AWSリージョンが落ちることはめったにない。だが、それは実際に起こった」と記事では語っています。2015年9月20日、US-EAST-1リージョンのAmazonのDynamoDBサービスが、問題が発生して停止します。これは20以上のAWSサービスに影響を及ぼしました。その影響により、AWSをインフラとする複数のインターネットサービスが6〜8時間にわたってダウンしてしまったのです。
このAWSの大規模障害に関しては次の記事が参考になります。
9月20日に発生したAmazonクラウドのDynamoDB障害。原因はセカンダリインデックス増大によるメタデータ処理のパンク
Netflixのサービスはこの大規模障害の影響を受けたものの、このようなリージョン単位の大規模障害に備えていたことから、重大な事態には至らずに済んだそうです。
以前の記事で紹介したChaos Kongは、このようなリージョン単位の障害を再現するツールです。わざと障害を発生させるツールで経験を積んでおくことにより、システムの弱点を早期に特定して解決していたおかげで、本物の大規模障害発生時にうまく対処できたのです。

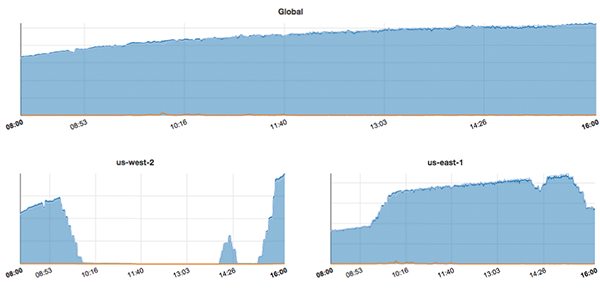
実例として、このBlogエントリ内で同社はリージョン障害を再現するツールChaos Kongを適用した時のトラフィック(ビデオ再生数)の数値を公開しています。横軸は時間で、縦軸はビデオ再生数です。us-west-2リージョンが停止している間、そのリクエストを引き受けるus-east-1リージョンのビデオ再生数が上昇していることがわかります。結果として、グローバルでのビデオ再生数は一定に保たれています。
このように、障害発生ツールにより障害対応の経験を積むことを含めて、Netflixでは「Chaos Engineering」と呼んでいます。Chaos Engineeringの原則を記した文書が下記で公開されています。
PRINCIPLES OF CHAOS ENGINEERING
同社のBlog記事には「Chaos Engineeringは私たちのシステムをより強くする。そして我々に、非常に複雑なシステムを迅速に前進させるための自信を与えてくれる」と記されています。
Netflixのサービスのように、多数のマイクロサービスの組み合わせから構成される複雑かつ巨大なシステムは、少しの手直しや障害で思わぬ波及効果が発生するかもしれません。しかし障害を恐れるあまり、大胆な機能追加やサービス内容の変更が行えなくなってしまうことは望ましくありません。そこで日頃からChaos Engineering、つまり障害発生ツールによる経験を積んでおくことで、変化に対応できるという自信と勇気を持つことができるというわけです。これは、テスト駆動開発(TDD)を推進する人々の発言と似た部分があると思います。