Prometheusのクエリ機能とアラート機能


Prometheusでは蓄積されたデータに対し、その値をそのまま単純にグラフ化するだけでなく、さまざまな条件を指定してクエリ処理を行って集計し、その結果をグラフ化するという機能も備えている。また、特定の条件を満たしたときにメールなどの手段でアラートを送信する機能もある。今回はこれらの機能について紹介する。
Prometheusのクエリ機構
Prometheusによるデータ集計やグラフ表示については、取得したデータを選んでグラフを表示する、といったシンプルなものを前回紹介した。Prometheusではこういった単なるデータ表示に加えて、データを集計・加工してグラフ化する機構も用意されている。
Prometheusで用いられる「ラベル」
Prometheusのクエリ機構について説明する前に、Prometheusでデータ管理に使われる「ラベル」という仕組みについて紹介しておこう。Prometheusのexporterでは、データに対し「ラベル名=値」という形式で任意のラベルを指定できるようになっている。Prometheusではこれは次のような書式で表される。
<データ名>{<ラベル名1>=<値>, <ラベル名2>=<値>, ...}
たとえば、node_exporterが出力できる「node_cpu」というデータはCPUの利用状況に関するデータなのだが、これには「cpu」および「instance」、「job」、「mode」という名前のラベルが設定されている(図1)。このうち、「cpu」はCPUコアID、「instance」は送信元のホスト名およびポート名、「job」にはジョブの種別を示す「node」という文字列、「mode」には該当する時間の種別が記録される。
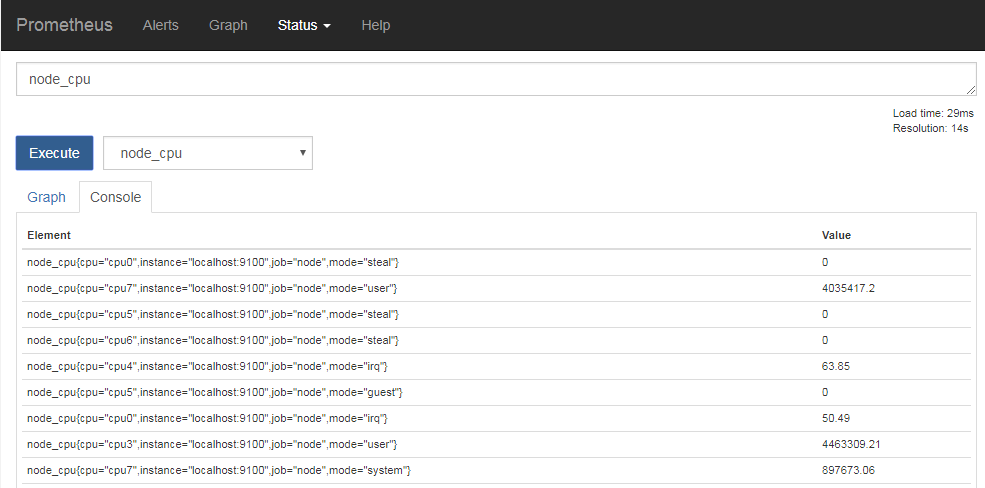
LinuxではCPUのコアごとに利用時間を次の表1のように分類して記録しており、その名称がそのままmodeラベルに格納されている。
| 名称 | 説明 |
|---|---|
| idle | 何もせず待機していた時間 |
| user | ユーザープロセスが使用した時間 |
| system | システムプロセスが使用した時間 |
| iowait | I/O処理待ちで使われた時間 |
| nice | 優先度の変更のために使用した時間 |
| irq | ハードウェア割り込みで使用された時間 |
| softirq | ソフトウェア割り込みで使用された時間 |
| steal | ゲストOSがCPU割り当て待ちになっていた時間 |
| guest | ゲストOSが実行したCPU時間 |
たとえば「node_cpu{cpu="cpu2",instance="localhost:9100",job="node",mode="idle"}」という項目は「cpu2」のidle時間を示している。
さて、Prometheusのグラフ画面では、グラフ下にこのラベルごとの凡例が表示されており、それらをクリックすることで特定のデータに関するグラフだけを表示させることができる(図2)。
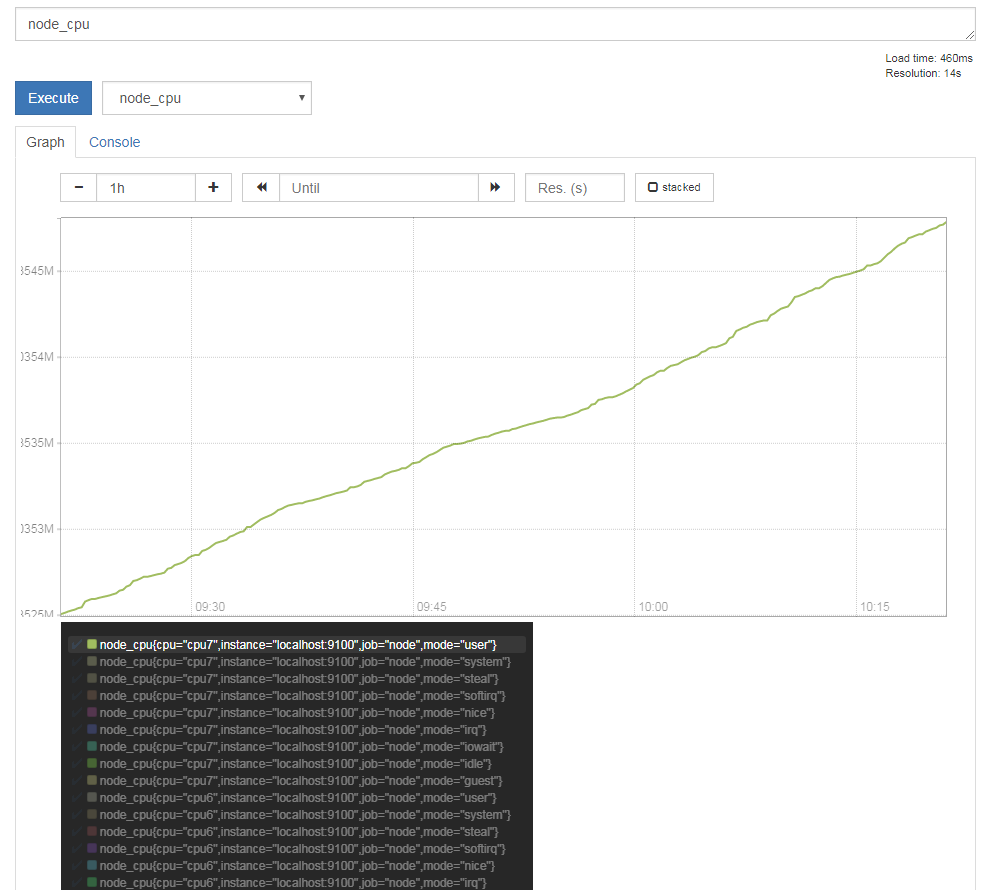
また、画面上の入力ボックスに「<データ名>{<ラベル名1>=<値>, <ラベル名2>=<値>, ...}」の形式でラベルを指定することで、指定したラベルを持つデータのみを表示できる(図3、4)。
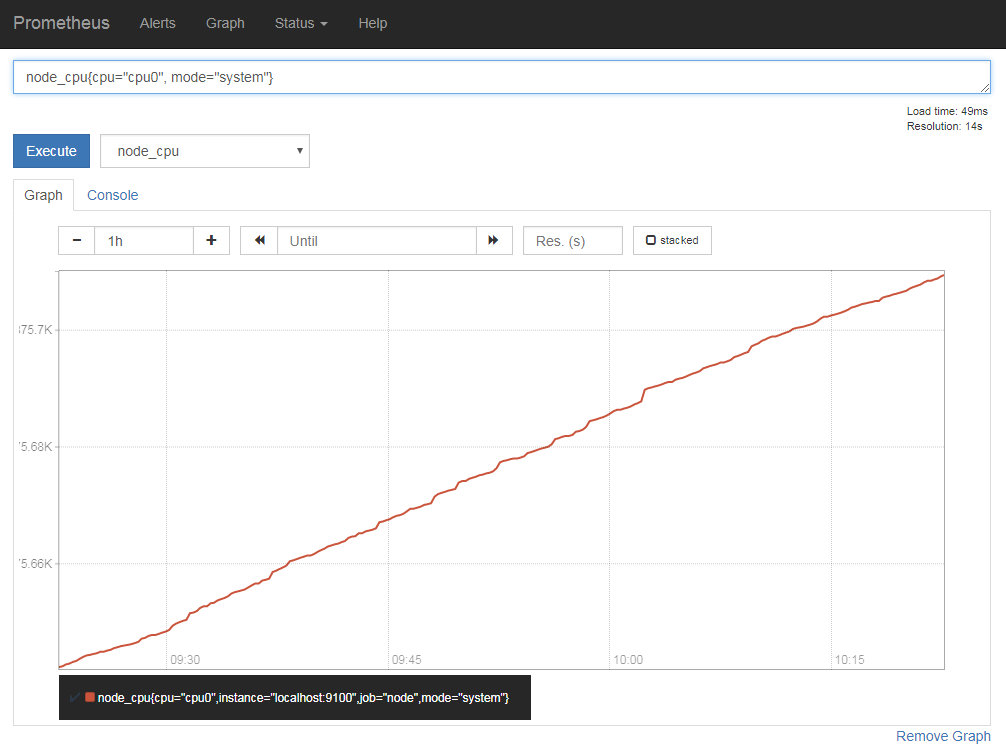
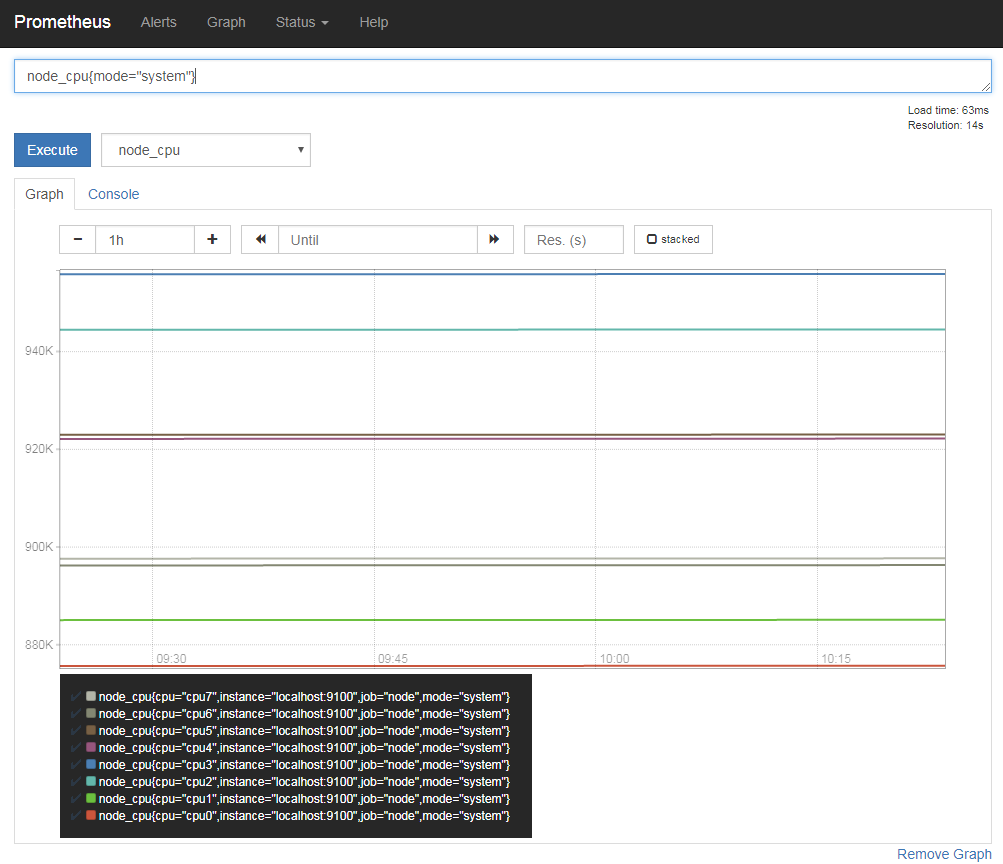
ラベルの指定では一致を示す「=」だけでなく、「一致しないもの」を対象とする「!=」や、正規表現にマッチするものを対象とする「=~」、正規表現にマッチしないものを対象とする「!~」といった演算子も利用可能だ。たとえば「node_cpu{cpu!="cpu1",mode="user"}」のように指定すると、「cpu」ラベルが「cpu1」以外で「mode」ラベルが「user」のものが表示される(図5)。
正規表現を利用して「node_cpu{cpu=~"cpu[0-3]",mode="user"}」のように指定すれば、「cpu」ラベルが「cpu0」「cpu1」「cpu2」「cpu3」で「mode」ラベルが「user」のもののみを表示できる(図6)。
クエリでは演算子を利用して値を加工したり、複数のデータを対象に加算などの演算を行うこともできる。利用できる演算子は以下のとおりだ。なお、「%」は剰余、「^」はべき乗を求める演算子となっている。
+ - * / % ^
もちろん演算の優先度を指定するための括弧も利用可能だ。たとえば「(node_memory_Inactive + node_memory_MemFree) / node_memory_MemTotal」のようにすることで、全メモリ量に対する(インアクティブなメモリ量+フリーなメモリ量)の割合を表示できる(図7)。
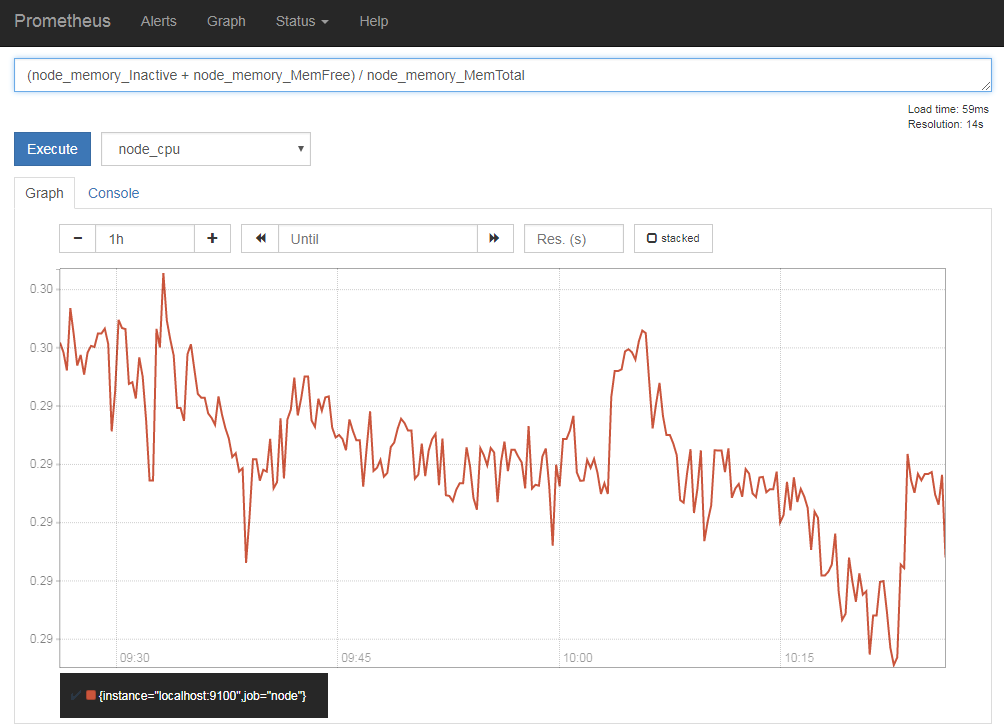
さらに、さまざまなクエリ関数も用意されている。詳しくはドキュメントを参照して欲しいが、たとえば指定した条件に合致するすべての値を合計するには「sum()」関数が利用できる。たとえば、「sum(node_cpu{mode="idle"})」と指定すると、node_cpuデータのうち、「mode」ラベルが「idle」であるものすべての値、つまり「node_cpu{mode="idle",cpu="cpu0"}」〜「node_cpu{mode="idle",cpu="cpu7"}」までの合計をグラフとして表示できる(図8)。
「ave_over_time()」や「max_over_time()」など、「_over_time」系の関数を利用することで時間軸方向の集計も行える。たとえば、「node_memory_Inactive」の1時間の平均値をグラフ化したい場合、次のようなクエリを実行すれば良い(図9)。
avg_over_time(node_memory_Inactive[1h])
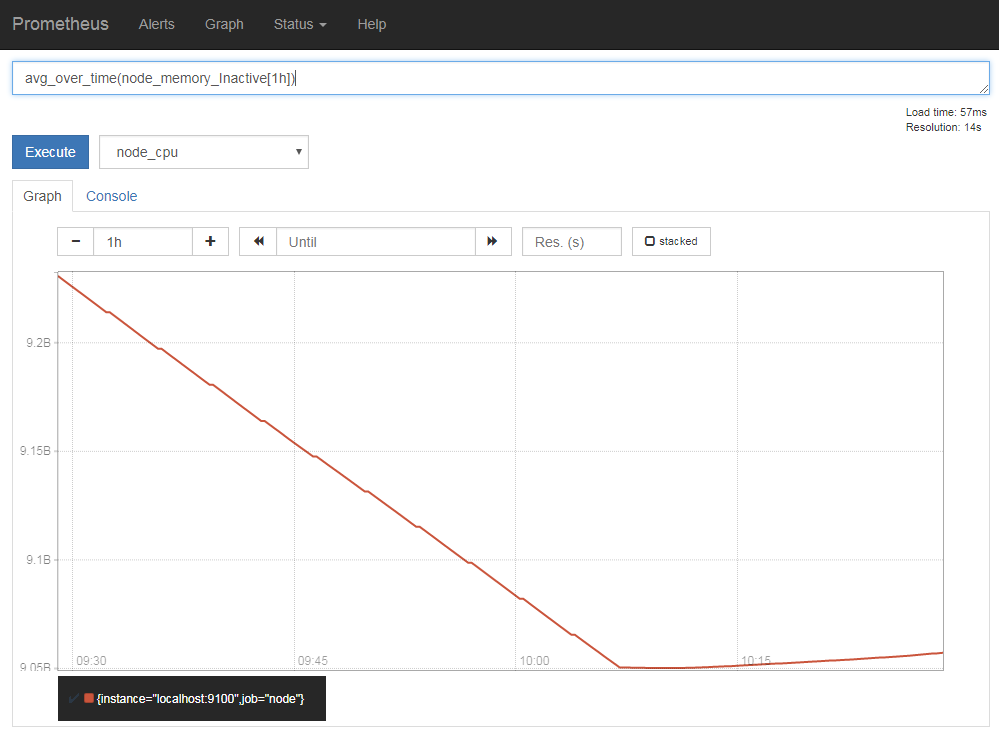
ここで、「[1h]」の部分が対象とする期間を指定する部分となっている。時間の指定には表2の単位が使用できる。
| 単位 | 説明 |
|---|---|
| s | 秒(seconds) |
| m | 分(minutes) |
| h | 時間(hours) |
| d | 日(days) |
| w | 週(weeks) |
| y | 年(years) |
演算子とクエリ関数を組み合わせた複雑な統計処理を実行することも可能だ。たとえば次のクエリは、1分単位でのCPUのidle率を表示するものとなっている(図10)。
sum(delta(node_cpu{mode="idle"}[1m])) / sum(delta(node_cpu[1m]))
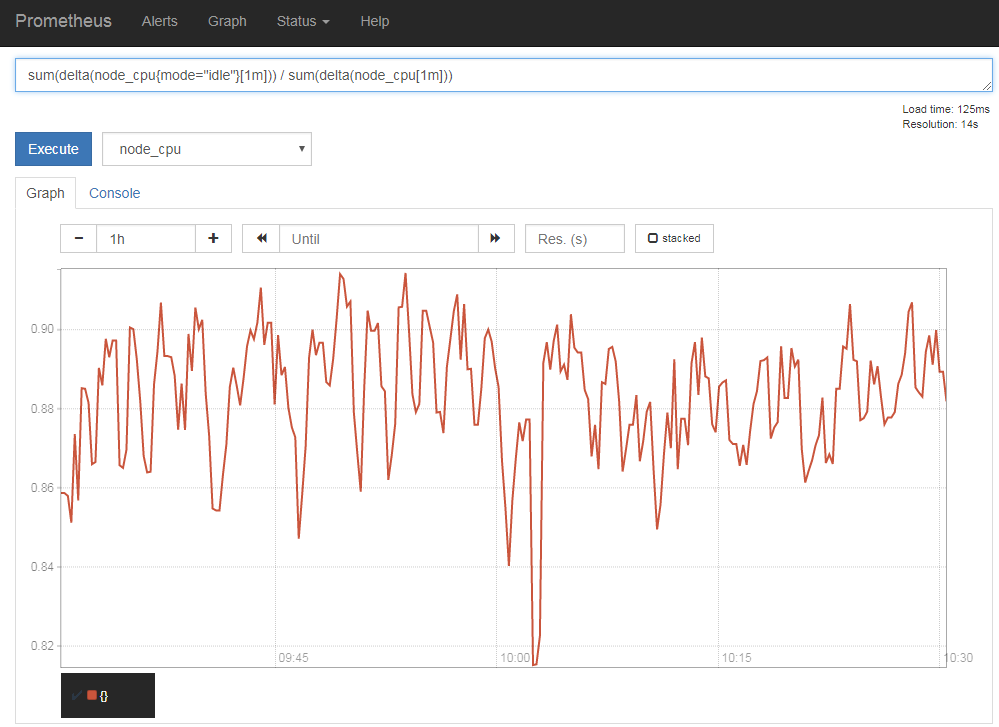
ここでは、指定した時間でのデータの変化量を返す「delta()」関数を使い、まず「delte(node_cpu{mode="idle"}[1m])」で各CPUのidle時間の1分間での変化量を取得し、sum()関数でそれを合計したものを、各CPUの各時間の1分間での変化量の合計(「sum(delta(node_cpu[1m]))」)で割ることでidle時間の割合を求めている。
取得したデータの値をそのまま見たい場合、「Graph」タブではなく「Console」タブを使用することは前にも述べたが、ここれは「<データ名>」もしくは「<データ名>{<ラベル名1>=<値>, <ラベル名2>=<値>, ...}」の後に「[<時間>]」を指定することで、現在時刻から指定した時間前までのデータを表示できる。
たとえば、node_exporterで取得できる「node_memory_Active」というデータについて、最新5分間のデータを表示するには「node_memory_Active[5m]」と指定すれば良い(図11)。
![図11 「[<時間>]」というフォーマットで指定した時間のデータを表示できる](/images/2017/11/prome31.png?amp=1)
また、基準とする時刻は「offset <時間>」という形式で指定できる。たとえば1時間前を基準とし、そこから5分前までのデータを見たい場合、「[5m] offset 1h」と指定すれば良い(図9)。
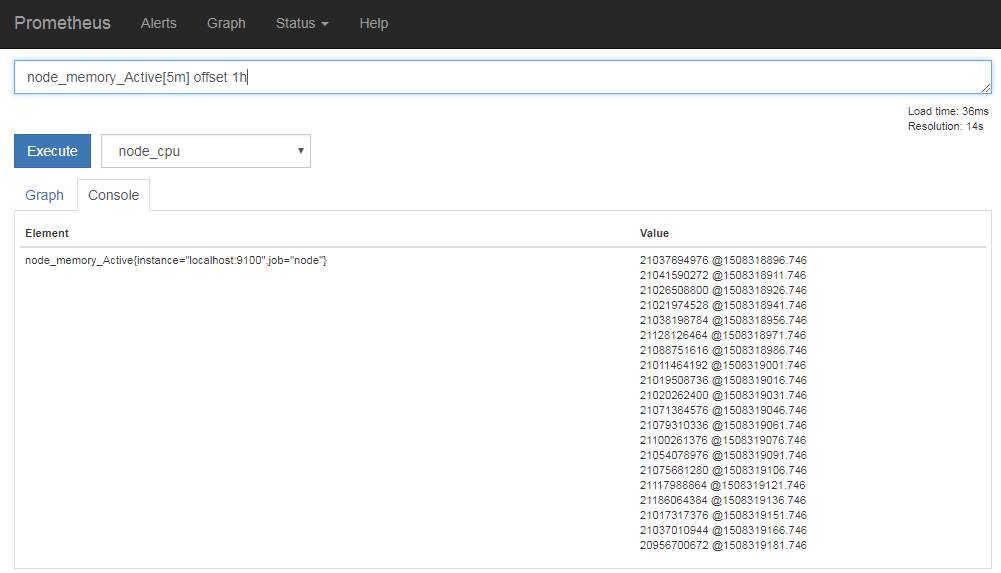
よく使用する条件を登録する
Prometheus Serverでは、あらかじめ設定ファイルにルールを登録しておくことで、そのデータを簡単にコンソールから呼び出せる「Recording rules」と呼ばれる仕組みがされている。この仕組みを使って登録されたルールは依存するデータの取得時に自動的に計算され、その結果が内部データベースに記録される。そのため、複雑なクエリを含むものでも瞬時に結果を表示できるという特徴がある。
Recording rules機能を利用するには、リスト形式でルールを記述したファイルのパス名を、Prometheus Serverの設定ファイル(/etc/prometheus/prometheus.ymlファイルなど)の「rules_files:」セクションで指定しておく必要がある。
次の例は、「/etc/prometheus/recording.rules」というファイルに記録されたルールを使用するよう指定するものだ。
# Load and evaluate rules in this file every 'evaluation_interval' seconds. rule_files: - "/etc/prometheus/recording.rules"
なお、Recording rules機能で使用するルールファイルは、Prometheusバージョン1系と2系でフォーマットが異なるので注意したい。まずバージョン1系では次の形式で記述する。2行目のようにラベルを指定することも可能だ。
<名称> = <クエリ式>
<名称>{<ラベル名>=<値>, ...}= <クエリ式>
次の例は、先で紹介したCPUのidle率などを求めるクエリを「node_cpu_ratio」という名称で登録するものだ。
node_cpu_ratio{mode="idle"} = sum(delta(node_cpu{mode="idle"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="user"} = sum(delta(node_cpu{mode="user"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="system"} = sum(delta(node_cpu{mode="system"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="iowait"} = sum(delta(node_cpu{mode="iowait"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="nice"} = sum(delta(node_cpu{mode="nice"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="irq"} = sum(delta(node_cpu{mode="irq"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="softirq"} = sum(delta(node_cpu{mode="softirq"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="steal"} = sum(delta(node_cpu{mode="steal"}[1m])) / sum(delta(node_cpu[1m]))
node_cpu_ratio{mode="guest"} = sum(delta(node_cpu{mode="guest"}[1m])) / sum(delta(node_cpu[1m]))
一方バージョン2系では、次のようなYAML形式でルールを記述するようになった。そのため、設定ファイルの拡張子も「.yml」が推奨される。
groups:
- name: <ルール名>
rules:
- record: <名称>
expr: <クエリ式>
labels:
[ <ラベル名>: <値>, ...]
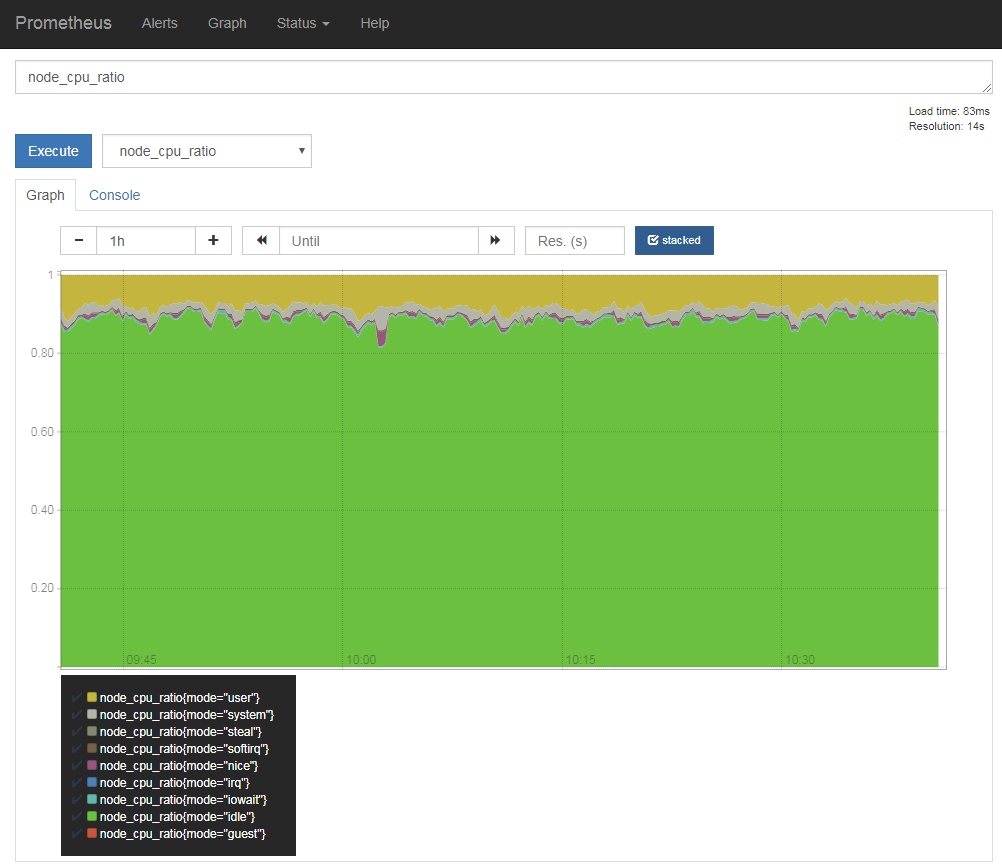
ここで登録したルールは、exporterで取得したものと同じようにクエリを行える(図13)。
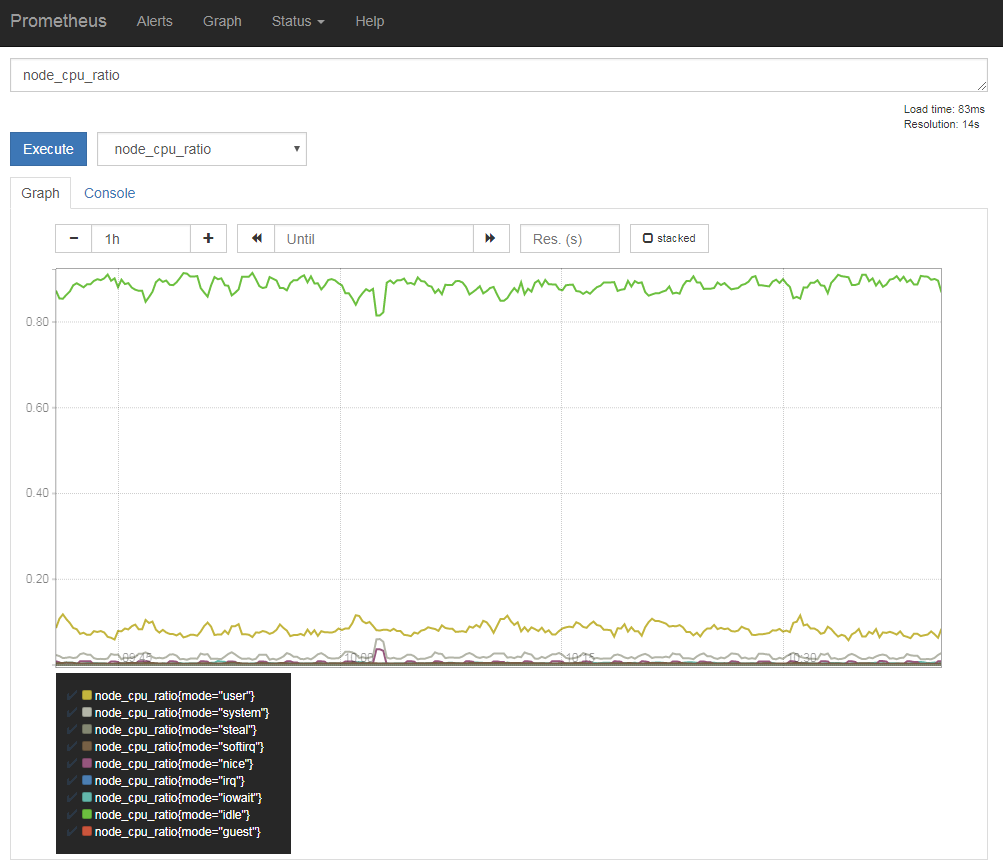
余談だが、こういったデータはグラフ右上に表示される「stacked」をクリックして積み上げ表示にすると見やすい(図14)。
Prometheusのアラート機構
続いては、Prometheusのアラート機能について解説しよう。アラート機能は、監視対象のデータがあらかじめ設定しておいた条件に合致した場合、メールやインスタントメッセージ、チャットなどを使って管理者にその旨を通知したり、指定しておいた外部サービスのAPIを呼び出すというものだ。
前回記事でも述べたが、Prometheusではアラートの生成についてはPrometheus Serverが行い、その配送についてはAlertmanagerという別のコンポーネントが行う構成となっている。そのため、Promehteus Serverでの設定に加えてAlertmanagerのインストールおよび設定も必要となる。
Alertmanagerのインストール
Prometheus ServerやExporterなどと同様、Alertmanagerについてもいくつかのインストール方法がある。DebianやUbuntu環境でのインストールであれば、公式パッケージのインストールが最も簡単だ。
# apt-get install prometheus-alertmanager
Docker経由で起動する場合、「prom/alertmanager」イメージが利用できる。
# docker pull prom/alertmanager # docker run -d --name alertmanager -p 9093:9093 -v <設定ファイル>:/etc/alertmanager/config.yml -v <データ保存ディレクトリ>:/alertmanager prom/alertmanager
公式バイナリを利用する場合も、Prometheus ServerやExporterなどと同様、systemd経由での起動をおすすめする。まず、ダウンロードしたアーカイブを次のように/usr/local/binディレクトリ以下にコピーする。
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.9.1/alertmanager-0.9.1.linux-amd64.tar.gz $ tar xvzf alertmanager-0.9.1.linux-amd64.tar.gz $ cd alertmanager-0.9.1.linux-amd64/ # cp -a alertmanager /usr/local/bin/
続いて、「/etc/systemd/system/prometheus-alert-manager.service」という名前で次のファイルを作成する。
[Unit] Description=Alertmanager for Prometheus [Service] Restart=always User=prometheus ExecStart=/usr/bin/prometheus-alertmanager -config.file=/etc/prometheus/alertmanager.yml -storage.path=/var/lib/prometheus/alertmanager ExecReload=/bin/kill -HUP $MAINPID TimeoutStopSec=20s SendSIGKILL=no [Install] WantedBy=multi-user.target
これに加えて、必要に応じてPrometheusユーザーの作成やデータディレクトリとして指定した/var/lib/prometheus/alertmanagerディレクトリの作成なども行っておく。最後にsystemctlの設定をリロードしておこう。
# systemctl daemon-reload
Prometheus Server側の設定ファイル作成
アラートを生成する条件は、Prometheus Server側の設定で行う。まず、アラート生成ルールを記述したファイルのパス名をPrometheus Serverの設定ファイル内の「rules_files:」セクション以下に追加する。今回は「alert.rules」という別ファイルとして用意した。
# Load and evaluate rules in this file every 'evaluation_interval' seconds. rule_files: - "/etc/prometheus/recording.rules" - "/etc/prometheus/alert.rules"
ここでは前述の通りRecording rulesを記述した設定ファイルも指定できるが、Prometheus Server的にはどちらのファイルも同様にルール設定ファイルとして扱われる。そのため、1つのファイルにRecording rulesとアラートルールの両方を記述することも可能となっている。
ルール設定ファイルの書式についても、Prometheusバージョン2.0で変更が行われ、バージョン1系とは異なる書式となった。まずバージョン1系だが、次のような書式でルールを記述する。
ALERT <アラート名>
IF <条件>
FOR <期間>
LABELS <ラベル>
ANNOTATIONS <ラベル>
一方、バージョン2系では次のようにYAML形式で記述するよう変更された。
groups:
- name: <ルール名>
rules:
- alert: <アラート名>
expr: <条件>
for: <期間>
labels:
[ <ラベル名>: <値>, ...]
annotations:
[ <ラベル名>: <値>, ...]
ここで、各項目の意味は次の表3のようになっている。
| 内容(バージョン1系) | 項目名(バージョン2系) | 説明 |
|---|---|---|
| IF <条件> | expr: <条件> | アラートを発生させる条件を指定する |
| FOR <期間> | for: <期間> | 指定した期間条件が継続した場合にのみアラートを発生させる。省略可 |
| LABELS <ラベル> | labels: <ラベル> | アラートに追加するラベルを「{<ラベル名>=<値>,...}」(バージョン1系)、[<ラベル名>: <値>,...]」(バージョン2系)の形で指定する。省略可 |
| ANNOTATIONS | annotations: <ラベル> | アラートの概要や説明などの追加情報を「{<ラベル名>=<値>,...}」(バージョン1系)、[<ラベル名>: <値>,...]」(バージョン2系)の形で指定する。省略可 |
なお、「LABELS」や「labels:」と「ANNOTATIONS」や「annotaions:」はどちらもラベルを指定するものだが、前者はAlertmanagerがアラートの分類などに使用するラベルを指定し、後者ではそれ以外の情報を含むラベルを指定する。具体的には、ANNOTATIONS/annotations:では「summary」というラベルでアラートの要約を、「description」というラベルでアラート内容の詳しい説明を指定するのが一般的だ。また、どちらについても値の指定にはテンプレートが利用できる。ここで、テンプレートにはラベル情報を含む「$labels」変数と、そのアラートを発生させる要因となる監視データを含む「$value」変数が渡される。
たとえば次の例は、「node_memory_MemFree」と「node_memory_Inactive」の合計値が500,000,000(500M)を下回った状態が1分間続いたらアラートを発生させる、というものだ。
ALERT LowOnMemory
IF node_memory_MemFree + node_memory_Inactive < 500000000 FOR 1m
LABELS { severity = "warn", type = "node" }
ANNOTATIONS {
summary = "{{ $labels.instance }} is low on memory",
description = "{{ $labels.instance }} is low on memory (current value: {{ $value }}"
}
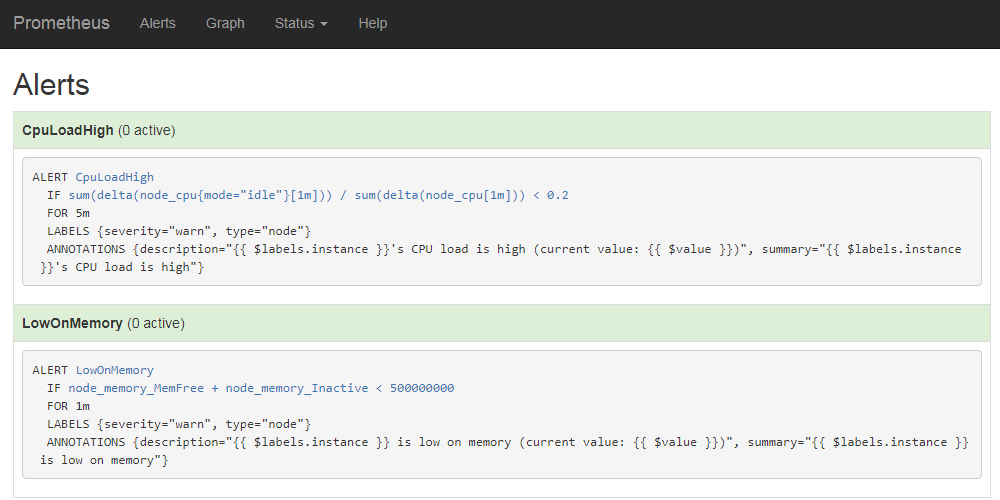
アラート設定の変更はPrometheusを再起動することで反映される。また、登録されているアラートやその状況はコンソールの「Alerts」画面で確認できる(図15)。
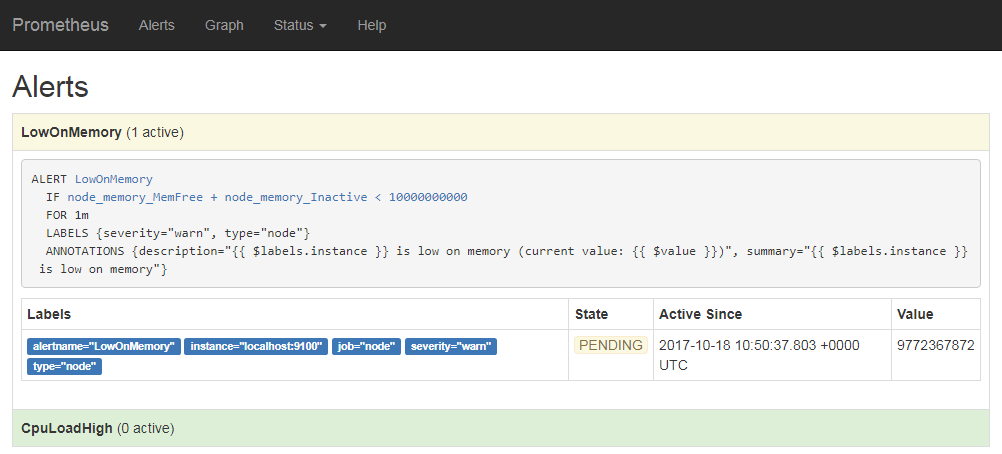
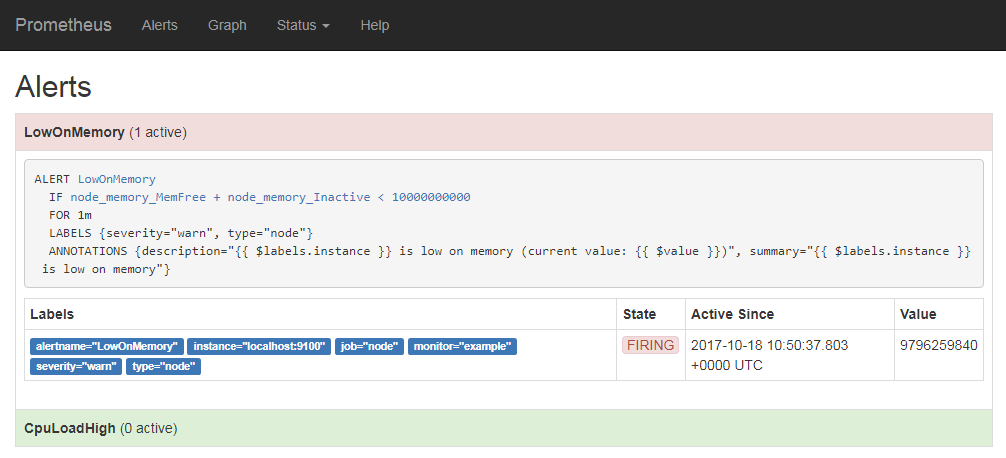
ここで条件が満たされているアラートは「active」表示となり、指定した時間それが継続した場合、実際にアラートが生成される(図16、17)。
Alertmanagerの設定
Prometheus Serverで設定をしただけでは、アラート条件が満たされたとしてもコンソールにその旨が表示される以外の通知は行われない。アラートを管理者などに通知するには、Alertmanager側での設定が必要になる。
Alertmanagerの設定は、Alertmanagerの起動時に指定した設定ファイル(一般的には/etc/prometheus/alertmanager.yml)で行う。
現在Alertmanagerでは、通知の送信手段として次のものをサポートしている。
ここでSlackおよびHipChatはチャット型コミュニケーションサービス、VictorOpsやPagerDuty、OpsGenieは開発・運用支援サービス、Pushoverはリアルタイム通知ツールだ。これらサービスを利用するには、設定ファイルにこれらサービスから発行されたAPIキーやAPI URLなどを指定する必要がある。また、Webhookは指定したURLにアラート情報をHTTPのPOSTメソッドで送信するものになる。
設定できる内容やサンプル設定ファイルなどはドキュメントから確認できるが、この設定ファイルでは次の5つのセクションに分かれている。
- global
- templates
- receivers
- route
- inhibit_rules
まず「global:」セクションだが、ここではメールの送信に使用するSMTPサーバーの情報や通知先サービスを指定する。たとえばSMTPサーバーの設定は次のようになる。
global: smtp_smarthost: '<SMTPサーバーのホスト>:<ポート>' smtp_from: '<From:行で使用するメールアドレス>' smtp_auth_username: '<SMTP AUTHで使用するユーザー名>' smtp_auth_password: '<SMTP AUTHで使用するパスワード>' smtp_require_tls': '<TLSを使用する場合はtrue、使用しない場合はfalse>'
また、Slackへ通知する場合は次の設定を追加する。
slack_api_url: <SlackのAPI URL>
「templates:」セクションでは、使用するテンプレートファイルを配列形式で指定する。たとえば/etc/prometheus/alertmanager_templates/ディレクトリ以下にある拡張子が「.tmpl」のファイルを使用する場合、次のように指定する。
templates: - '/etc/prometheus/alertmanager_templates/*.tmpl'
テンプレートファイルについては、パッケージでインストールした場合は/usr/share/prometheus/alertmanager/default.tmplとしてサンプルファイルがインストールされている。また、alertmanagerのGitHubリポジトリにもサンプル(default.tmpl)があるので、まずはこれらを適当なディレクトリにコピーして利用すると良いだろう。
「receivers:」セクションは、アラートの送信先を定義するセクションだ。ここでは次のような形式でアラートの送信先を記述する。
receivers:
- name: <名前>
email-configs:
- to: <メールアドレス>
- name: <名前>
email-configs:
- to: <メールアドレス>
slack-configs:
channel: <送信先チャンネル>
- name: <名前>
slack-configs:
channel: <送信先チャンネル>
:
:
メールの送信先やSlackでの送信先チャンネルなどは、それぞれ「email-configs:」や「slack-configs:」などの子要素として指定する。たとえば「email-configs:」と「slack-configs:」の両方を指定することで、メールとSlackの両方に同時にアラートを送信することも可能だ。
「route:」セクションでは、Prometheus Serverが生成したアラートを受け取った後、receiver:セクションで指定したどの送信先にそのアラートを送信するかのルールを記述する。
receiver: <送信先名> group_by: [ <ラベル1>, ... ] continue: <true/false> match: <ラベル名>: <値>, ... match_re: <ラベル名>: <正規表現>, ... group_wait: <時間> group_interval: <時間> repeat_interval: <時間> routes: <子要素>
ここで、それぞれの設定要素は次のような意味を持つ(表4)。すべてのパラメータは省略が可能だ。
| 設定要素 | 説明 |
|---|---|
| receiver: <送信先名> | アラートの送信先をreceivers:セクションで指定した送信先の名前で指定する |
| group_by: [ <ラベル1>, ... ] | グルーピングするラベルを指定する |
| continue: <true/false> | falseを指定すると、条件にマッチした時点でマッチ処理をすべて終了し、次のノード以降を無視する |
| match: <ラベル名>: <値>, ... | 条件を指定する |
| match_re: <ラベル名>: <正規表現>, ... | 条件を正規表現で指定する |
| group_wait: <時間> | アラートを受信してから送信を行うまでの待ち時間を指定する |
| group_interval: <時間> | アラートの送信後、同一のグループに属するアラートを再び送信できるようにするまでの時間を指定する |
| repeat_interval: <時間> | アラートを送信後、まったく同じアラートを再び送信できるようにするまでの時間を指定する |
| routes: <子要素> | このノードにマッチした際に、続いて実行する条件をリスト形式で指定する |
Alertmanagerのroutes:セクションは、設定ファイルの最初に記述したroute:セクション内にさらにroutes:セクションを記述できる木構造となっている。そのため、routes:セクションに記述されたリスト内の各設定要素を「ノード(node)」と呼び、最初に記述されたroute:セクションを「ルートノード(root node)」、そこに含まれるノードを「子ノード」とも呼ぶ。
Alertmanagerはアラートを受信すると、まずルートノードにそのアラートを渡し、図18のような流れで処理を実行する。
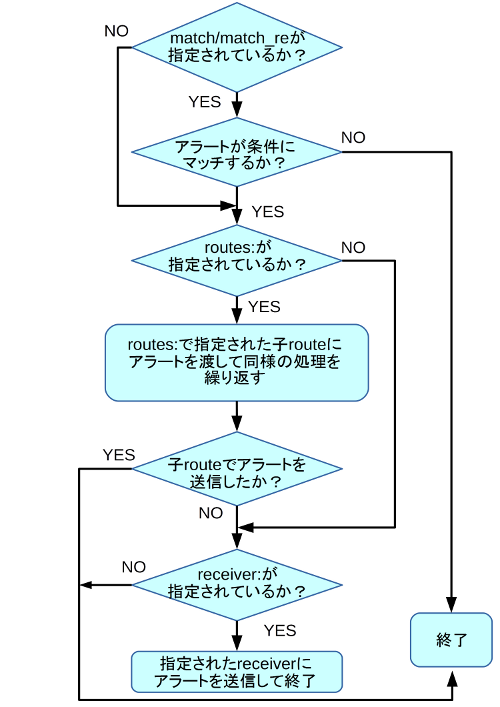
続いてそこで子ノードが定義されていた場合、その子ノードに順にアラートを渡して処理を繰り返し実行する。
たとえば次の設定では、「severity」ラベルが「warn」のものは「admins」というreceiverに、「type」が「infra」のものは「infras」というreceiverに送信される。それ以外のアラートはすべて「developers」というreceiverに送信される。
route:
receiver: developers
routes:
- match:
severity: warn
receiver: admins
- match:
type: infra
receiver: infras
さて、実際の環境で運用を行う場合、1つの問題が原因で複数のアラートが発生する場合がある。そういった場合、個別にアラートを受け取るのは冗長だ。そのためAlertmanagerでは、複数の種別のアラートをグルーピングする仕組みがある。これはgroup_by要素で設定可能で、ここに指定されたラベルを持つアラートは、そのノード以下ではすべて同じグループに属するアラートとして扱われる。
そして、Alertmanagerは最初のアラートを処理してから一定の期間内(group_wait:で指定した期間内)に受け取った同じグループに属するアラートは、すべてまとめて1つのアラートとして扱う。さらに、一度アラートが送信されたら、それと同じグループに属するアラートは一定期間内(group_interval:で指定した期間内)には再送されない。それに加えて、完全に同一のアラートについては、一度送信されたら一定期間内(repeart_interavl:で指定した期間内)は再送されない。こうした仕組みによって、似たようなアラートが短時間に大量に送信されることを防いでいる。
「inhibit_rule:」セクションでは、特定の条件下において無視するアラートの条件を指定できる。これを利用して、同グループのアラートが同時に発生した場合に特定のアラートを優先し、ほかのアラートを無視する、といった設定を行える。
inhibit_rules:
- source_match:
<ラベル名1>:<値>, <ラベル名2>:<値>, ...
source_match_re:
<ラベル名1>:<正規表現>, <ラベル名2>:<正規表現>, ...
target_match:
<ラベル名1>:<値>, <ラベル名2>:<値>, ...
target_match_re:
<ラベル名1>:<正規表現>, <ラベル名2>:<正規表現>, ...
equal: [ <ラベル名1>, <ラベル名2>, ...]
たとえば次のように指定すると、「severity」ラベルが「critical」という値を持つアラートが発生した場合、「alertname」や「cluster」、「service」ラベルが同一で、さらに「severity」が「warning」のアラートは無視されるようになる。
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
equal: ['alertname', 'cluster', 'service']
「Routing tree editor」で設定を確認する
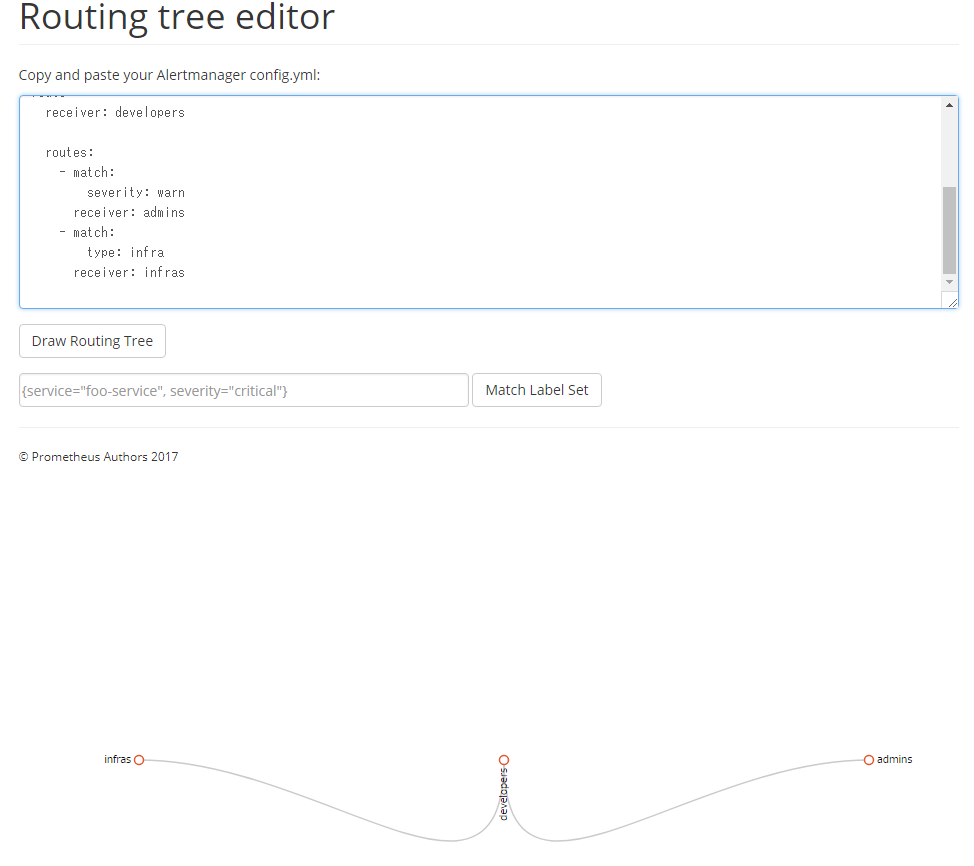
Alertmanagerの設定ではツリー構造で設定を記述するため、直感的に分かりにくい記述になることもある。PrometheusではRouting tree editorというWebブラウザ経由で利用できるツールを公開しているので、設定ファイルを作成したらこれを使って意図する動作になっているかを確認すると良いだろう。
Routing tree editorでは、「Copy and paste your Alertmanager config.yml:」以下の部分に作成したAlertmanagerの設定ファイルの内容をコピーし、「Draw Routing Tree」ボタンをクリックすると、画面下側に設定内容がビジュアル化されて表示される(図18)。
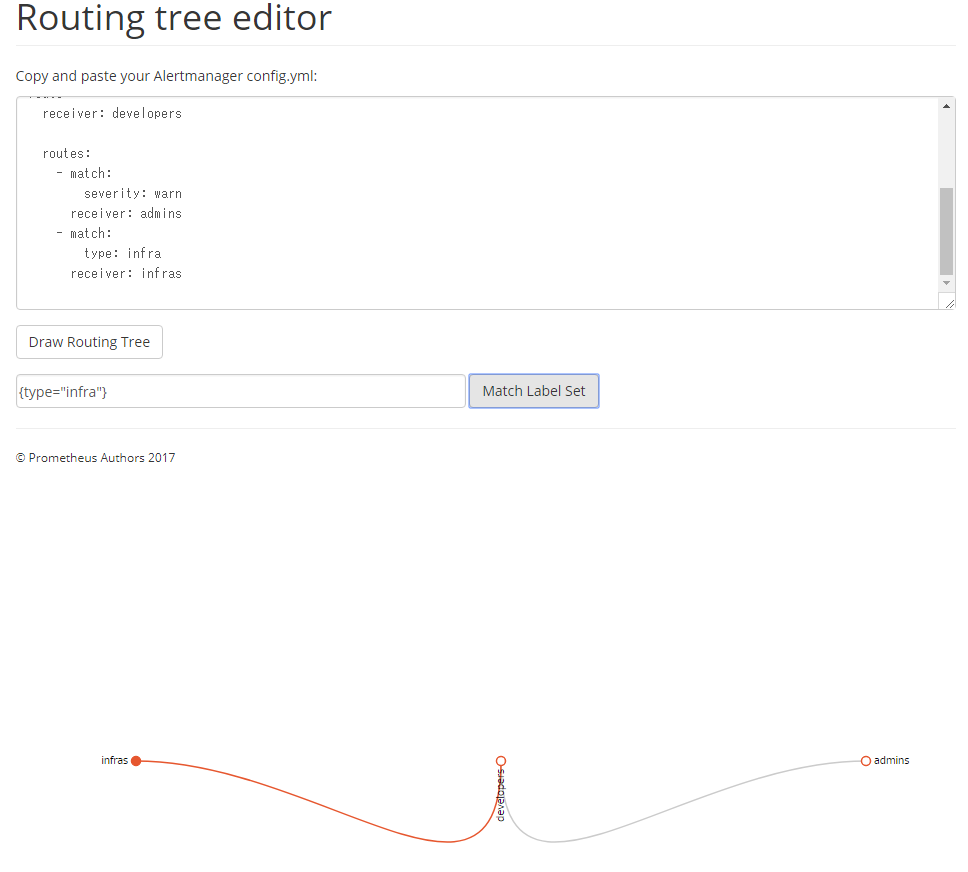
この状態で、下のテキストボックスにアラートのラベルを「{<ラベル名>="<値>",...}」形式で入力して「Match Label Set」ボタンをクリックすると、そのアラートがどのreceiverに送信されるかが表示される(図19)。たとえばこの例では、「{type="infra"}」というラベルを持つアラートが「infras」というreceiverに送信されることが確認できる。
Prometheus Serverの設定
Alertmanagerの設定と起動が完了したら、最後にPrometheus ServerがAlertmanagerにアラートを送信できるよう設定を行う。
Prometheusバージョン1系では、Prometheus Serverの起動時に「-alertmanager.url <AlertmanagerのURL>」オプションを追加する。
たとえばDebianやUbuntuでパッケージを使ってインストールした場合、/etc/default/prometheusファイルの先頭にある「ARGS=」で始まる行にオプションを追加すれば良い。たとえばPrometheus ServerとAlertmanagerを同じホストで動かしている場合、次のようになる。
# Set the command-line arguments to pass to the server. ARGS="-alertmanager.url http://localhost:9093"
また、Prometheusバージョン2系では、Prometheus Serverの設定ファイル(prometheus.yml)内に次の形式でAlertmanagerのホスト名とポート番号を指定する。
alerting:
alertmanagers:
- static_configs:
- targets:
- <ホスト名>:<ポート番号>
たとえばPrometheus ServerとAlertmanagerを同じホストで動かしている場合、次のようになる。
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
設定後は、Promehtetus Serverを再起動すれば設定が反映される。
ドキュメントは必要最低限なので試行錯誤する必要がある点が課題か
さて、ここまででPrometheusを使ってシステムやサービスの監視を行ったり、アラートを送信する方法について紹介した。前回はPrometheusの特徴としてインストールや設定の容易さを挙げたが、実際インストールについては容易で、設定も設定ファイルベースで行うため分かりやすい。ただ、設定内容のドキュメントについては必要最小限のものしかないため、ドキュメントを読んだだけでは挙動が分かりにくいところも出てくる場合がある。その場合、自分で試してみて挙動を確認するしかない。ドキュメントやチュートリアル不足は今後の課題だろう。