モニタリング/フィードバック – 「若手エンジニアのためのDevOps入門」(10)


こんにちは、山本和道です。
本記事は連載「若手エンジニアのためのDevOps入門」の第10回です。
| 第1回 | インフラエンジニアにとってのDevOps |
|---|---|
| 第2回 | Webアプリでの開発環境構築 |
| 第3回 | バージョン管理システム |
| 第4回 | 継続的インテグレーション/デリバリー |
| 第5回 | DevOpsのための道具箱: APIを使いこなす |
| 第6回 | リリース/構成管理: 概要 |
| 第7回 | リリース/構成管理: Terraform編 |
| 第8回 | リリース/構成管理: Ansible/Packer編 |
| 第9回 | リリース/構成管理: サンプルアプリによるCI/CD環境構築実践 |
| 第10回 | モニタリング/フィードバック |
前回はサンプルアプリケーションを用いて開発〜リリースまでの流れを体験してみました。
今回はリリース後のアプリケーションに対する監視や負荷状況などのモニタリング、フィードバックなどについて扱います。
他のプロセスにも言えることですが、特にこのプロセスについてはツールが多数存在するため、各ツールの特徴を押さえた上で自身の環境に合うツールを取捨選択することが必要です。
監視/モニタリング
アプリケーションのリリースを行なった後は正常稼動できているかを確認するための死活監視やアクセス数や応答時間といったシステムのパフォーマンス測定を行います。
これらは手動で行うことも可能ですが、監視や測定は24時間365日継続して数分おきに行うといった具合に定期的に長期間に渡って行われることが多く、自動化しておくことが望ましいでしょう。
何を監視/モニタリングするか
監視/モニタリングは対象を詳細に設定するほど詳細な値が取得できますが、その分負荷が増え監視データを保存しておくストレージを消費します。また、値を取得しても利用しないのであれば無駄となってしまいます。
どのような項目を監視/モニタリングするのかを決める/設計するにもある程度の時間がかかりますので、導入初期は最低限の項目のみにしておき、運用しながら改善していくアプローチを取ることもあります。自組織の経験やスキルなども考慮して決定するようにしましょう。
これまで監視/モニタリングを行なったことがないという方は、まず最低限の項目として以下のような項目を監視/モニタリングすると良いと思います(Webアプリケーションを想定しています)。
- DNSでの名前解決がおこなえること
- サーバ(等)ヘネットワークの疎通が可能であること
- 外部からアプリケーションへアクセスすると応答があること
- アプリケーションを構成するプロセス(WebサーバやDBサーバなど)が起動していること
- サーバ(等)のCPU使用率/メモリ使用率/プロセス数/スレッド数
- ネットワーク利用状況
- アプリケーションの応答時間
- アプリケーションへのアクセス数
- サーバ(等)でのエラー数
これらに運用上必要になった項目やアプリケーションへの機能追加時の効果測定のための項目などを随時追加していく方法とすることで、監視/モニタリングの導入自体は手早く行い、運用しながら徐々に改善していくというアプローチが取れます。
DevOpsのプロセスとしての監視/モニタリング
DevOpsプロセスとして監視/モニタリングを行う場合、アプリケーションの安定稼働のために異常があったらすぐに気づき対応を行うという目的だけでなく、次のプロセス(Plan)にフィードバックするという観点も必要です。このためには日々の監視/モニタリング結果を参照するためのレポート機能や現在の状況を一目でわかるようにするダッシュボード機能、施策の効果を測定するために容易に監視項目を追加/変更/削除できることなどが求められます。
また、異常時の対応についても開発チーム/運用チームで協調するために監視データや調査結果の共有や対応状況のトラッキング、対応結果の蓄積、次回以降の対応時に過去の対応を参考にできることなども重要です。
このためにRedmineなどのBTS(バグトラッキングシステム)などを併用することもあります。
監視/モニタリングのためのツール/サービスは柔軟な設定ができるものが多いため、どのような目的のためなのかを明確に意識しておかないと膨大な量の設定を行うことになりかねません。単なる監視を目的とするのではなくDevOpsプロセス全体を見据えた目的を立てた上でツール/サービスの導入/設定を行うようにしましょう。
監視/モニタリングのためのツール/サービス
監視/モニタリングを行うためのツール/サービスとしては以下のようなものがあります。
ツールごとに様々な特徴があります。監視方法や収集するデータ、監視ツール自体の操作感などは当然異なりますが、以下のような点についても違いがありますので導入の際の考慮が必要です。
インストール方法
各自の環境にインストールして利用するのか、提供されているサービスを利用する形態(SaaS型)なのかという違いがあります。
各自の環境にインストールする場合、プライベートなネットワーク内の監視といった各自の環境に応じた柔軟な構成を取れるといったメリットがありますが、インストールやアップグレードといった作業が発生したり、専用のサーバが必要になったりというデメリットもあります。
また、提供されているサービスを利用する形態の場合、すぐに利用が始められる、インストールやアップグレード作業はサービス側で行ってくれるため不要といったメリットがありますが、インターネット経由で外部への接続ができる必要があったり、カスタマイズできる範囲に制限があったりといったデメリットもあります。
データ収集方法
監視対象にエージェントをインストールし収集したデータを監視サーバに送るpush型や監視サーバが各監視対象のデータを収集するpull型といった形態があります。
push型の場合は監視対象にエージェントをインストールするだけで監視対象を増やせるといったメリットがありますが、エージェントのインストールそのものが煩雑であったり、管理対象が多数となった場合に大量の監視データが送りつけられる監視サーバの負荷が高くなりがちであったりといったデメリットもあります。
これに対しpull型の場合は監視サーバ側で監視対象を設定ファイルなどに定義することで監視対象を増やしていきます。監視対象が増えた際は毎回設定ファイルを修正する、または動的に監視対象を発見するための仕組み(PrometheusのService Discoveryなど)が必要になります。また、pull型であっても監視データの収集などのためにエージェントのインストールが必要な場合もありますので注意が必要です。加えて、監視サーバから監視対象にアクセスできるようにネットワークやファイアウォールの設定なども必要となります。
ツールによっては設定次第でどちらの方法にもできるものも存在します。
データの保存方法/利用方法
収集した監視データは監視サーバ側で保存されることになりますが、その形式はテキストファイルやRDB、ツール独自の形式など様々なものがあります。収集したデータのバックアップや2次利用に影響しますのでこの辺りも押さえておきましょう。
また、収集したデータを長期間に渡って保存しておきたい場合、ツールによってはデータの保存期間を伸ばすことや、別途保存するための仕組みが必要になることもあるため、注意が必要です。
異常検出時の通知/アクション
監視/モニタリングで異常を検知した際はサーバやミドルウェアの再起動やインフラの状況確認、必要に応じてアプリケーションの代替手段の準備などの何らかのアクションが必要になります。
このために、監視ツール自体がSlackやSMSなどで担当者へ通知する機能や指定のスクリプトを実行する機能などを持っているものが多いです。
ツールによってどのような通知/アクションが設定可能なのかは大きく異なる部分ですので、ツール選定の際には要件を満たすか十分に確認するようにしてください。
内部/外部からの監視
監視項目にはCPU使用率といったサーバ内部で取得する項目もあれば、アプリケーションへの外部からのアクセスに正常に応答できることを確認する項目もあります。ツール/サービスによってはいずれか片方しか選択できない場合がありますので注意が必要です。
この場合は複数のツール/サービスを組み合わせたり、外部からの監視を簡易的なものにして自作スクリプトなどで対応したりすることもあります。
これまでの項目と同じくツール選定の際は要件を満たすか十分に確認するようにしましょう。
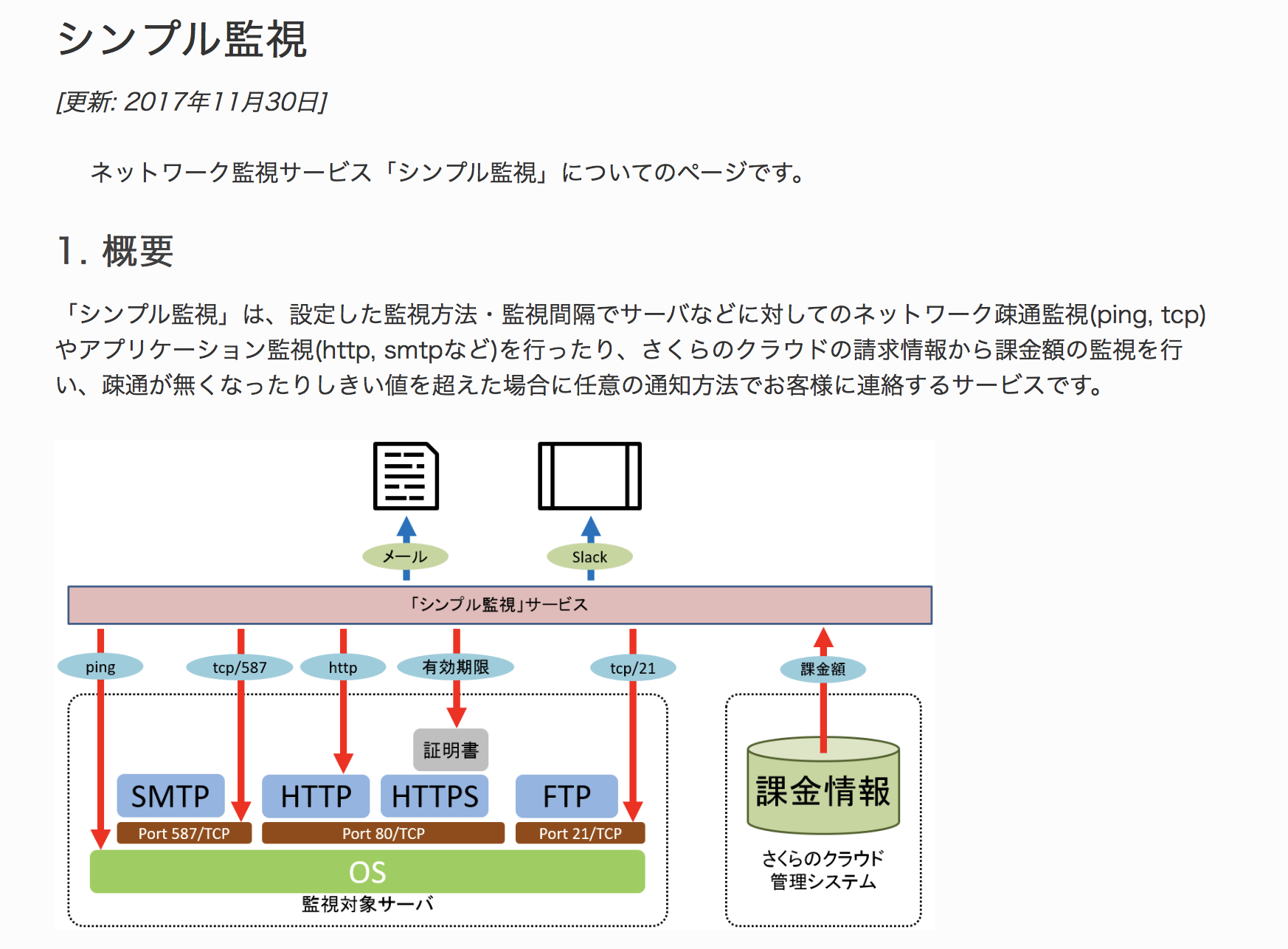
外部監視の例: さくらのクラウド シンプル監視
外部からのアプリケーション監視を手軽に行えるサービスとしてさくらのクラウド シンプル監視があります。
ネットワークの疎通確認やアプリケーションの死活管理に特化しており、別途エージェントをインストールせずともコントロールパネルから監視対象のIPアドレスまたはドメイン名と監視方法を指定するだけで利用可能となっています。
監視対象によっては無料で利用可能な場合もありますので、外部監視が必要になった際はぜひ利用をご検討ください。

インシデント管理
前述の通り、異常検出時の通知やアクションについては、監視ツール自体が通知やアクションといった機能を持つものもあるためその機能を利用するのも良いでしょう。
しかし、既存の監視システムを併用している場合やアプリケーションごとに異なる監視ツールを利用する場合など、通知元が複数に渡る場合もあります。このような場合、様々なツールからのアラートを一元管理できる、いわゆるインシデント管理に特化したツール/サービスを利用する方法もあります。
例えばPagerDutyというサービスでは多種多様な通知元への対応や、ルールに従い段階的に通知を行うエスカレーションといった機能を持っています。高負荷状態が一定時間続いたらSlackへ通知、その後数分待っても対応されないようであればメールやSMSで担当者に直接通知、それでも対応されないようであれば担当者へ架電といったように柔軟な対応が行えます。また、応用として通知だけでなくWebhookなどを介して実際の復旧処理を行うようにすることも可能です。
特に複数のシステムの運用監視を担当するような場合に便利に使えると思いますので、運用形態に合わせて導入を検討してみてください。
ユーザーのトラッキング
アプリケーションへより直接的なフィードバックを行うために、アプリケーション上で実際にユーザーがどういう動きをしたのか、どんなページ遷移をしているかといったユーザーの行動を追いたいことがあります。
この場合、WebアプリケーションであればGoogleアナリティクスといったツールを利用することでこれらの情報を収集できますし、独自のログを仕込む場合もあるかと思います。
インフラ側の監視データやログだけでなく、クライアント側のデータも合わせて参照することでより直接的にアプリケーションにフィードバックが行えますのでフィードバックのためのデータ収集の一環として導入を検討しておくのがオススメです。
まとめ
今回は監視/モニタリングとフィードバックについて扱いました。
多数のツールがありますので、導入の際は各ツールの調査を行い運用形態にあうツールを選定することがポイントとなります。
次回はチャットボットなどのDevOpsのプロセス間を繋ぐためのツールについて扱う予定です。
以上です。