CoroutinesによるTensorFlow Liteの推論パイプライン構築

はじめに
はじめまして。有限会社シーリスの有山圭二と申します。Androidアプリ開発者で、趣味で機械学習をやっています。
この度「さくらのナレッジ」さんに、9月22日に開催される技術書オンリーイベント「技術書典」でぼくが頒布する本の宣伝させて欲しいと言ったところ快諾をいただき、こうして筆をとることになりました。
9月22日(日曜日)池袋サンシャインシティ 展示ホールC/D(文化会館ビル2/3F)で開催される技術書オンリーイベント「技術書典7」に、個人サークル「めがねをかけるんだ」として参加します。く24D「めがねをかけるんだ」では、同人誌「わたしは機械学習プロジェクトで技術的負債を抱えました(仮題)」を頒布する予定です。
(はじめに より)
筆者は、2015年にTensorFlowが公開されてから今まで、趣味の機械学習システムの開発に取り組んできました。さくらインターネット社は取り組み初期の頃から応援してくださっていて、高火力コンピューティングサーバーをはじめとした計算資源を提供いただいています。
最初はまったくの初心者だった機械学習の取り組みも、こつこつと4年も続ければ(初心者を脱出したかは別にして)それなりにできてくるものです。しかし、成果が積み上がる裏では多くの「技術的負債」も溜まってきます。
遅いデータベース。増え続けるデータセット。「動けばいいや」と書いてそのままになっている非効率的なコード。遅いデータベース。データセットのバックアップ半年してない問題。TensorFlowや各種ライブラリの新バージョンへの追従。そして、遅いデータベース……。本書では、4年間で抱えてしまったさまざまな技術的負債を地道に返済していく取り組みを紹介します。
この記事について
ここからが記事の本編となります。本記事のタイトルは「CoroutinesによるTensorFlow Liteの推論パイプライン構築」です。TensorFlow Liteの学習済みモデルをAndroidアプリで動かすときに、処理負荷とメモリの消費量のバランスをとる推論パイプラインをCoroutinesを使って構築する手法を解説します。
実を言うと、この記事の内容は、技術書典で頒布する本とはあまり関係がありません。今後Androidアプリに機械学習モデルを組み込もうとする開発者がすぐに使えるような実用寄りの内容を目指しました。これは筆者にとって「同人誌に書きたい内容」と「ブログで発信したい内容」は異なるのだと言うことをご了承ください。
サンプルアプリ — FoodGallery
本記事で紹介するコードの全体は、筆者のリポジトリ「FoodGallery」で公開しています。
- FoodGallery with TensorFlow: https://github.com/keiji/food_gallery_with_tensorflow/releases/tag/knowledge_sakura-201909
FoodGalleryは、起動すると端末に保存されている写真の一覧を表示します(ストレージへアクセスする権限が必要です)。一覧画面では、機械学習モデルが食物の確率が高いと判定した写真を目立たせて表示します。

Androidアプリで機械学習モデルを動かす
Androidアプリケーションで機械学習モデルを動かす(組み込む)ことは、TensorFlowが発表された時点で想定されていたユースケースであり、Androidアプリ開発者の筆者がまったく専門外の機械学習(TensorFlow)に取り組もうと決めた最大の理由でもあります。
最初期のTensorFlowは、サンプルアプリのAPKを作るのにTensorFlowのリポジトリをまるごとチェックアウトしてBazelでビルドする必要がありました。その後「TensorFlow for Mobile」としてライブラリ化され、利用のハードルはぐっと下がりました。現在はTensorFlow for Mobileは非推奨となり「TensorFlow Lite」に移行しています。
TensorFlow Lite
TensorFlow Liteは、TensorFlowで作成した機械学習モデルをさまざまなプラットフォーム上で動作させるランタイムです。
TensorFlowが高火力コンピューティングサーバーのような高性能なGPUを搭載したコンピューター上で「訓練・学習」を実行する目的で開発されているのと対称に、TensorFlow LiteはAndroidやiOSなどのモバイル端末や、ボードコンピューターのような性能が限定された機器で推論のみを行うように開発されています。
また、TensorFlowのチェックポイント(パラメーター)ファイルやモデルの保存に「Protocol Buffers」が採用されているのに対して、TensorFlow Liteモデルのシリアライズには「FlatBuffers「が採用されています。これはFlatBuffersのデータの展開やパースを必要としない(データをメモリにマップしてアクセスする)特徴が、性能の限定された機器での動作に適しているためです。
AndroidアプリにTensorFlow Lite形式のモデルを組み込む
それでは、AndroidアプリにTensorFlow Lite(TFLite)形式のモデルを組み込んで推論を実行しましょう。ここではFoodGalleryで公開しているTFLite形式のモデルを例に解説します。次のURLから「food_model_3ch.tflite」をダウンロードしてください。
- FoodGallery Releases: https://github.com/keiji/food_gallery_with_tensorflow/releases/tag/knowledge_sakura-201909
まずはじめにモデルの入出力の仕様を確認します。仕様はモデルをTFlite形式に出力する時に定まります。FoodGalleryのモデルの場合、128x128の大きさのRGB画像の各ピクセルの値を32bitの浮動小数点数で入力します。出力は[0.0, 1.0]の範囲の値で、値が1,0に近いほど、入力された画像が食べ物である確率が高いことを意味します。
依存関係の追加
Android Studioのプロジェクトを開き、TensorFlow Liteのライブラリ(org.tensorflow:tensorflow-lite)をbuild.gradleのdependenciesに追加します(本稿執筆時点の最新バージョンは1.14.0です)。
dependencies {
implementation fileTree(include: ['*.jar'], dir: 'libs')
implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlin_version"
// 省略
implementation 'org.tensorflow:tensorflow-lite:1.14.0'
}
noCompressの指定
build.gradeにaaptOptionsのnoCompressを指定します。ここではassetsに置いたデータで圧縮の対象から外すファイルの拡張子を指定します。前述の通り、TFLiteモデルのシリアライザーであるFlatBuffersは、読み込みの際に展開やパースを必要としないのが特徴です。ビルドの過程で圧縮されていると(読み込む前に展開が必要になると)、正常に読み込むことができずエラーとなります。
android {
// 省略
aaptOptions {
noCompress "tflite"
}
}
モデルの読み込み
モデルを読み込むコードを次に示します。これはプロジェクトのディレクトリassetsに配置したモデルファイルを読み込んでByteBufferオブジェクト(厳密にはMappedByteBuffer)として取得するイディオムのようなものです。assetsから読み込まない場合、後述するInterpreterにFileオブジェクトを渡す方法もあります。
@Throws(IOException::class)
private fun loadModelFile(assets: AssetManager, modelFileName: String): ByteBuffer {
val fileDescriptor = assets.openFd(modelFileName)
val inputStream = FileInputStream(fileDescriptor.fileDescriptor)
return inputStream.channel.map(
FileChannel.MapMode.READ_ONLY,
fileDescriptor.startOffset,
fileDescriptor.declaredLength
)
}
モデルの実行
モデルで推論を実行するもっとも基本的なコードは次のとおりです。2つのByteBufferオブジェクトを確保して、それらをtfInferenceのrunメソッドに与えます。第1引数がモデルに対する入力、第2引数が出力に対応します。
val model = loadModelFile(assetManager, MODEL_FILE_PATH)
val tfInference = Interpreter(model)
val input = ByteBuffer
.allocateDirect(INPUT_SIZE)
.order(ByteOrder.nativeOrder())
val output = ByteBuffer
.allocateDirect(OUTPUT_SIZE)
.order(ByteOrder.nativeOrder())
tfInference.run(input, output)
output.rewind()
もう少し具体的な例を紹介します。関数inferenceは、引数に与えるBitmapオブジェクトをモデルに入力して推論した結果を返します。
fun inference(bitmap: Bitmap): Float {
val scaledBitmap = Bitmap.createScaledBitmap(bitmap, IMAGE_WIDTH, IMAGE_HEIGHT, false)
val resizedImageBuffer = ByteBuffer
.allocate(IMAGE_WIDTH * IMAGE_WIDTH * 4) // 4 means channel
scaledBitmap.copyPixelsToBuffer(resizedImageBuffer)
resizedImageBuffer.rewind()
val inputBuffer = ByteBuffer
.allocateDirect(IMAGE_WIDTH * IMAGE_WIDTH * IMAGE_CHANNEL * 4) // 4 means float
.order(ByteOrder.nativeOrder())
for (index in (0 until (IMAGE_WIDTH * IMAGE_HEIGHT * 4))) { // 4 means channel
if ((index % 4) < 3) {
inputBuffer.putFloat(resizedImageBuffer[index].toInt().and(0xFF))
}
}
inputBuffer.rewind()
val model = loadModelFile(assetManager, MODEL_FILE_PATH)
val tfInference = Interpreter(model)
val resultBuffer = ByteBuffer
.allocateDirect(4) // 4 means float
.order(ByteOrder.nativeOrder())
tfInference.run(inputBuffer, resultBuffer)
resultBuffer.rewind()
val confidence = resultBuffer.float
return confidence
}
次の図は、関数inferenceの動作を示したものです。
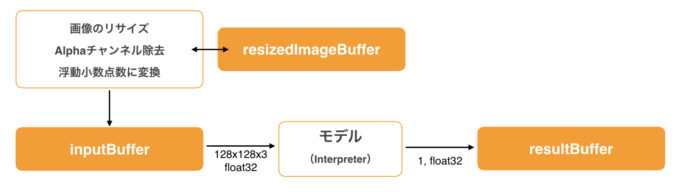
まずはじめにBitmapオブジェクトを規定の大きさにリサイズして、ピクセルをresizedImageBufferにコピーします。また、この時に不要なアルファチャンネルを取り除き、浮動小数点数に変換しています。
loadModelFileでモデルをロードした後、TensorFlow Liteの推論を担当するInterpreterクラスをインスタンス化しています。メソッドrunに入力と出力のByteBufferを指定して推論を実行して、最後にresultBufferからfloatの値を1つ取りだします。
モデルを実行する上での課題
一見、単純に見えるモデルの実行ですが、Androidというプラットフォームで実行するにはいくつかの課題があります。
モデルの入出力
ここまで、モデルの入出力にByteBufferを使ってきましたが、本来Interpreterのrunメソッドの引数の型はAny(Javaで言うObject)です。つまり、どんなオブジェクトでも型チェックなしに指定できます。モデルの入出力と合致しているかはコンパイルのタイミングではわからず、実行時にエラーが起きる扱いづらい仕様です。
基本的にはInterpreterはクラスの中に閉じ込めて、外部からはオブジェクトを介して使えるようにするのが良いでしょう。また個人的な意見として、モデルの入出力には必ずByteBufferを使うことをおすすめします。仕組み上、モデルの想定している入出力形式と合致すれば、FloatやByte, Intの配列でも動作します。たとえば、FoodGalleryのモデルでは次のようにしても推論を実行できます。
// [1, IMAGE_HEIGHT, IMAGE_WIDTH, 3]
val input = Array(1) {
Array(IMAGE_HEIGHT) {
Array(IMAGE_WIDTH) {
FloatArray(3) {
0.0F
}
}
}
}
val output = FloatArray(1)
tfInference.run(input, output)
しかし、Kotlinでこのような多次元配列を使うことは、筆者の経験上あまりありませんし、それをしたいとも思いません。
次の表は「allocateで確保したByteBuffer」「allocateDirectで確保したByteBuffer」「FloatArray」をInterpreterに与えたときの推論の実行時間を計測したものです。FloatArrayよりByteBufferの方が実行時間が短いことがわかります。
| Pixel 3(Android 9) | Essential PH-1(Android 9) | |
| allocate | 206,865,098 | 249,933,825 |
| allocateDirect | 220,523,720 | 278,193,550 |
| FloatArray | 243,911,354 | 281,976,871 |
一方、allocateで確保したByteBufferを与えた方が、allocateDirectで確保したものより実行時間が短いという、筆者の直感に反した結果も出ています。
筆者はallocateで確保したメモリ領域(ヒープ領域)よりallocateDirectで確保したメモリ領域の方がアクセス速度は速いと理解しています。また、TensorFlow Liteはネイティブのライブラリを呼び出しています。ネイティブライブラリにデータを渡すときはallocateDirectを使うのが定石です。実際、Googleが公開しているサンプルでも、Interpreterの入出力にはallocateDirectで確保したByteBufferを与えています。
今回、このような結果になった原因についてはまだわかっていません。Androidのバージョンか、TensorFlow Liteのバージョンか。あるいは本当にallocateで確保した領域の方が動作速度が速い可能性もありますが、今後も調査を続けていきたいと考えています。
非同期処理と消費メモリ
すでに述べたとおり、Android端末での機械学習モデルの実行には(通常のCPU処理と比較して)時間がかかります。
Androidアプリを開発したことがある人はご存じと思いますが、UIスレッドで時間のかかる処理すると表示がカクついたり、表示が固まってユーザーの操作を受け付けなくなったりします。また、UIスレッドの処理が一定時間を超えると、ユーザーのUXを損なうとしてシステムはANR(Application Not Responding)のダイアログを表示して、ユーザーにアプリの終了を促すことがあります。ANRが起こらないようにするため、I/Oや時間のかかる計算などはThreadなどを使って非同期に処理するのが原則です。
モデルの実行を非同期にする場合、はじめに思いつくのがモデルの処理をまとめてThreadに移行して非同期で実行することでしょう。今回のケースで言えば、関数inferenceをそのままThreadに移して実行するのがもっとも簡単な方法です。
しかしその方法では、モデルによる推論を複数同時に実行するときに問題が出てきます。FoodGalleryのように画像の一覧を表示する場合、それぞれの画像について推論を実行する必要があります。単純に関数inferenceをThreadに移行した場合、それぞれのスレッド実行時にByteBufferを確保するので起動するスレッドの数に比例してメモリのフットプリントが増大し、OOM(Out-Of-Memory)エラーが発生してアプリが強制終了する危険性が高まります。
スレッド間でByteBufferを共有するにしてもByteBufferはスレッドセーフではないので、複数スレッドから同時にアクセスすると正しく機能しません。同期など、なんらかの排他制御を用意する必要があります。
Coroutinesによる推論パイプライン構築
非同期処理と消費メモリのバランスの課題を解決するため、推論パイプラインを構築します。パイプラインを構築するにはさまざまな方法がありますが、今回はKotlinの「Coroutines」と「Channels」を使う方法を紹介します。
「Coroutines」は、プログラミング言語「Kotlin」の非同期処理の仕組みです。Android向けのKotlinはJavaのThreadをベースに、非同期処理の待ち合わせや実行スレッドの切り替えを簡単にできるように作られています。
たとえば、ストレージから画像をロードして表示するケースを考えます。この場合、ストレージにアクセスする(Disk I/Oが発生する)画像のロードは非同期で実行しなくてはなりません。また、画像を画面に表示する処理はUIスレッドから実行する必要があります(Coroutinesを使うには、build.gradleのdependenciesにライブラリ(org.jetbrains.kotlinx:kotlinx-coroutines-core, org.jetbrains.kotlinx:kotlinx-coroutines-android)を追加します)。
この処理をCoroutinesを使って実装すると次のようになります。
fun loadImage(path: String): Bitmap {
// 省略
}
fun showImage(path: String) {
CoroutineScope(Dispatchers.IO).launch {
val bitmap = loadImage(path)
withContext(Dispatchers.Main) {
imageView.setImageBitmap(bitmap)
}
}
}
関数showImageで非同期の処理を開始します。CoroutineScope.launchの中が非同期に実行される処理です。CoroutineScopeではどのように実行するかDispatcherで指定します。Coroutinesには標準でいくつかのDispatcherが用意されていて、Dispatchers.IOは入出力に関係した処理の実行を想定したものです。
関数loadImageは、ストレージから画像をロードしてBitmapオブジェクトを返します。前述の通り、ロードした画像をimageViewで表示する処理(setImageBitmap)は、UIスレッド上で実行する必要があります。そのためwithContextで、setImageBitmapを実行するスレッドをDispatchers.Main(UIスレッド)に切り替えています。
同様の処理を別の書き方をすることもできます。次の書き方は、関数loadImageにsuspendキーワードを付与しています。suspendキーワードを指定することでCoroutineで中断可能な関数であることを示しています。続くwithContextで、関数を実行するDispatcherを指定しています。こうすることで呼び出し元は、関数の実行されるスレッドを意識しなくて良いという利点があります。
suspend fun loadImage(path: String): Bitmap = withContext(Dispatchers.IO) {
// 省略
}
fun showImage(path: String) {
CoroutineScope(Dispatchers.Main).launch {
val bitmap = loadImage(path)
imageView.setImageBitmap(bitmap)
}
}
Channels
Channelsは、Coroutines間で値を受け渡す仕組みです。JavaのBlockingQueueに似ていて、sendはput、receiveはtakeメソッドと、それぞれ近い動作をします。
Channelを使ったCoroutines間での値の受け渡しを次に示します。1つ目のsendJobは、1秒ごとにインクリメントした値を1つChannelに送ります。二つ目のreceiveJobは、1秒ごとにChannelから値を1つ受けとって表示します。
val scope = CoroutineScope(Dispatchers.Default)
// val channel = Channel<Int>(capacity = Channel.UNLIMITED)
val channel = Channel<Int>()
// Send Coroutine
val sendJob = scope.launch {
var value = 0
while (isActive) {
value++
println("Sending value: $value... ${System.nanoTime()}")
channel.send(value)
sleep(1000)
}
}
// Receive Coroutine
val receiveJob = scope.launch {
while (isActive) {
val value = channel.receive()
println("value: $value received ${System.nanoTime()}")
sleep(1000)
}
}
Channelはsendで値を送ります。Channelを引数無しでインスタンス化した場合、値を1つ送るとreceiveされるまでCoroutineは中断(suspend)の状態になります。
Channelはreceiveで値を受けとります。Channelに値がない場合、次の値がsendされるまでCoroutineは中断します。また、receiveの代わりにfor文を使うこともできます。
val receiveJob = scope.launch {
for (value in channel) {
println("value: $value received ${System.nanoTime()}")
sleep(1000)
}
}
実装
ここまで紹介したCoroutinesを使って、いよいよ推論パイプラインを実装します。
まずはじめにパイプラインに推論を要求するためのクラスRequestを作成します。コンストラクタに与えるのは、モデルへ入力するBitmapオブジェクトと、モデルからの出力結果を受けとるcallbackです。2番目の引数callbackはFloat型の値を引数に取る関数型です。
class Request(
val bitmap: Bitmap,
val callback: suspend (confidence: Float) -> Unit
)
推論をリクエストするには、ReqeustオブジェクトをパイプラインのrequestChannelに送信(send)します。推論結果を受けとるcallbackについてはラムダ式で指定しています。
callbackにsuspendキーワードが付いているため他のCoroutineに切り替えることができます。たとえば関数updateConfidenceは、UIスレッドで動作します。
fun requestInference(image: Bitmap) {
val request = Request(image) {
updateConfidence(it)
}
requestChannel.send(request)
}
suspend fun updateConfidence(confidence: Float?) = withContext(Dispatchers.Main) {
// 省略
}
次に、推論パイプライン本体です。Requestオブジェクトを受けとるrequestChannelを用意した後、NUM_PIPELINESで指定された数のCoroutineを起動します。requestChannnelからRequestオブジェクトを受けとって関数inferenceで推論を行い、関数callbackを実行する形で結果を返します。
val requestChannel: Channel<Request> = Channel()
val pipelines = (0 until NUM_PIPELINES).map {
coroutineScope.launch {
val tfInference = Interpreter(model)
val resizedImageBuffer = ByteBuffer
.allocate(IMAGE_WIDTH * IMAGE_WIDTH * 4) // 4 means channel
val inputBuffer = ByteBuffer
.allocateDirect(IMAGE_WIDTH * IMAGE_WIDTH * IMAGE_CHANNEL * 4) // 4 means float
.order(ByteOrder.nativeOrder())
val resultBuffer = ByteBuffer
.allocateDirect(4) // 4 means float
.order(ByteOrder.nativeOrder())
for (request in requestChannel) {
val confidence = inference(request,
tfInference,
resizedImageBuffer,
inputBuffer,
resultBuffer)
request.callback(confidence)
}
}
}
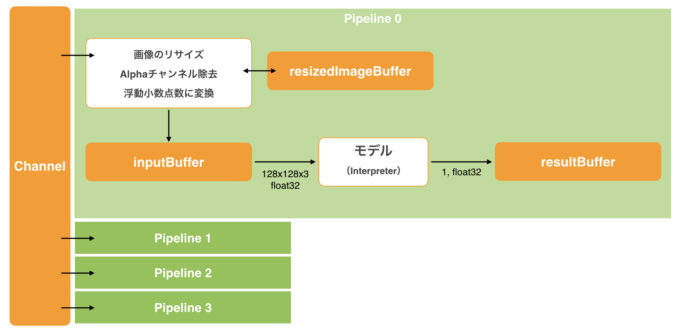
次の図は、推論パイプラインの構成を示したものです。複数のパイプラインでChannelを共有してリクエストを受けとります。また、パイプライン毎に必要なByteBufferを確保しています。こうすることで各Coroutineが使用するメモリをなるべく一定に保つようにしています。起動するパイプラインの数を増減すれば、端末の性能に応じて負荷が調整できます。
まとめ
本記事では、Coroutinesによる推論パイプラインの構築について紹介しました。Coroutinesを使うことで比較的簡単に推論パイプラインの構築ができました。同じものをLooper + Handlerで作ろうとすると、コールバックの実行スレッドを切り替えがすっきりといきません。
もちろん、これで完成というわけではありません。たとえばFoodGalleryで画像一覧を高速にスクロールすると、requestChannelにRequestをsendしてからパイプラインがreceiveするまでの間に、表示しているアイテムがrecycleされる場合があります。ここで紹介しているコードではアイテムのrecycleに対応していないので、一度リクエストをすると必要のない推論も実行してしまいます。リクエストがキャンセルされたことがパイプライン側でわかる仕組みを作る必要があります。
本記事で紹介している「FoodGallery」のコードは次のGitHubリポジトリで公開しています。本記事が、これからTensorFlow Liteを使うことになるAndroidアプリ開発者の助けになれば幸いです。
- FoodGallery: https://github.com/keiji/food_gallery_with_tensorflow/releases/tag/knowledge_sakura-201909
最後になりましたがもう一度宣伝です。筆者は、9月22日(日曜日)池袋サンシャインシティ 展示ホールC/D(文化会館ビル2/3F)で開催される「技術書典7」に、有山圭二の個人サークル「めがねをかけるんだ」として参加します。く24D「めがねをかけるんだ」では、同人誌「私は機械学習プロジェクトで技術的負債を抱えました(仮題)」を頒布する予定です。興味がある方はぜひお越しください!