いまさら聞けないNode.js


こんにちは!小田島です。さくらのナレッジで初めて記事を書きます。よろしくお願いします!
先日5月13日、Deno 1.0がリリースされました。Denoについては後日記事を書きますが、今回はDenoが生まれるきっかけとなったNode.jsについて、いまさら聞けないことを色々書いていきます。
対象者
本記事は、Node.jsについて以下のような疑問を持っている人が対象です。
- Node.jsって何?
- Node.jsを使うと何がうれしいの?
- Node.jsを使うときに何を注意すればいいの?
なお、本記事はNode.jsのイメージを掴んでもらうのが目的であり、ハンズオンではありません。そのためコードは1行も出てきませんのでご了承ください。
そもそもNode.jsとは?
超ざっくり説明すると、JavaScriptの実行環境です。
それまではJavaScriptといえばウェブブラウザー上で動かすのが普通でしたが、Node.jsはPythonやRubyのようにコマンドラインからJavaScriptファイルを実行でき、その場でコードを実行できるREPLも用意されています(ちなみにJavaScriptのCLIやREPLはNode.jsが最初というわけではありません)。
JavaScriptエンジンには、Google ChromeのJavaScript処理で使われているV8エンジンを搭載しています。
もともとNode.jsはウェブサービスのバックエンドのために生まれましたが、今ではもはやバックエンドにとどまらず様々な場所で使われています。
- フロントエンドの開発。WebpackなどのツールはNode.js上で動いています。
- デスクトップアプリケーション。Visual Studio Codeのような有名なアプリケーションもNode.jsなどを基にして作られています。
- 組み込み。Raspberry Piも動かせます!
なぜここまで話題を呼んだのでしょうか。単にブラウザーの外でJavaScriptを使えるようになったというだけではなく、ウェブサービスにおけるある問題を解決する手段でもあるためです。それが、次で説明するC10K問題(クライアント1万台問題)です。
いまさら聞けないC10K問題
それでは、そもそもC10K問題とはなんでしょうか?ここを正確に理解することがNode.jsを理解する第一歩です。
あなたなら何と答えますか?
解答1: クライアントが1万台になったら何かおかしくなる
絶対理解してない人の解答です。何かおかしくなるって何やねん。言葉から適当に想像しただけやろ。
まず、C10Kの「10K」は「クライアント(接続元)数が多い」という意味であって、1万という数値に何か特別な意味があるわけではありません。つまり、クライアントが9999台まではOKで10000台になった瞬間に異常が発生する、というわけではありません。状況によって5000台でも異常が発生することもあれば、15000台でも問題ない時もあります。これが2000年問題などと違う部分です。
そして何がおかしくなるのかというと、サービスの応答が極端に遅くなったり、あるいは全く応答しなくなったりします。
というわけで、次のように解答を直してみましょう。
解答2: クライアントの数が多くなるとサービスの応答が遅くなる
これはボンヤリと理解している人の解答です。
「クライアントの数」というのは正確ではありません。1秒に1つずつ、1万秒かけて接続がある場合でも「クライアントが1万台」であることには変わりないからです。
ここで問題になるのは同時接続数です。ある瞬間に多数のクライアントから接続があり、一度に捌く数が多くなると応答が遅くなるのがC10K問題です。
それでは次のように直すとどうでしょうか。
解答3: クライアントの同時接続数が多くなるとサービスの応答が遅くなる
正解に近づいてきましたが、まだ正確ではありません。
そもそもなぜ応答が遅くなるのでしょうか。その原因がマシンスペックであるなら、わざわざ「クライアント1万台問題」などと大仰な名前をつける必要はありません。同時接続数が増えればより高いマシンスペックを要求されるのは当たり前で、マシンスペックが問題ならマシンを買い替えろと言えば済む話です。
マシンスペック以外の原因がある場合からこそのC10K問題です。
解答4: サーバーのハードウェア性能は問題ないにもかかわらず、クライアントの同時接続数が多くなるとサービスの応答が遅くなる
というわけで、これが模範解答です。
大事なことなのでもう一度書きますが、ハードウェア性能は問題ないというのがポイントです。たとえスパコン並のスペックがあっても起きる時は起きるのがC10K問題です。
では、ハードウェア性能以外の問題とはなんでしょうか。次で説明します。
C10K問題の原因
C10K問題を引き起こす原因は主に3つです。
プロセス数の上限
かつて、ウェブサービスを構築するソフトウェアとしてLAMPが一般的に使われていました。OSとしてのLinux、ウェブサーバーとしてのApache HTTP Server(以下Apache)、データベースとしてのMySQL/MariaDB、スクリプト言語としてのPerl/Python/PHPの頭文字を取った言葉です。かつてはウェブサービスを立ち上げる際にはこれらのソフトウェアを使うことがごく一般的でした(今でも使われています!)。
そして以前のApacheでは、1つのリクエストに対して1つのプロセスを割り当てて処理をする方式が一般的でした(今では他にもいくつか処理方式があります)。
OS内で走るプロセスにはプロセスIDが割り当てられています。例えば32bit Linuxでは32767が上限です(64bit Linuxでは100万以上まで引き上げられます)。上限を超えるプロセスは生成できないため、1リクエスト1プロセス方式ではプロセス数の上限以上のリクエストを同時に処理できません。ウェブサーバーではApacheの他にも様々なプロセスが走っているため、Apacheに割り当てられるプロセスもその分減ります。

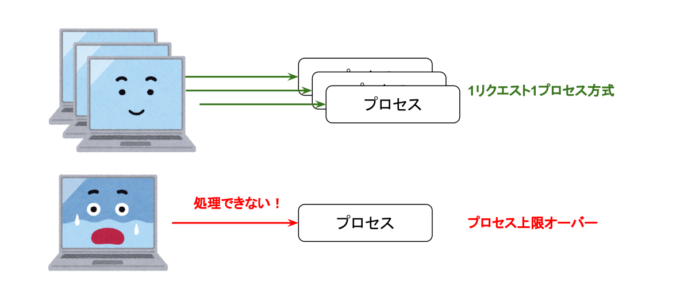
リクエスト数がプロセスの上限を超えるとそれ以上受けつけられなくなる
コンテキストスイッチのコスト
コンテキストスイッチとは、1つのCPUが複数のプロセスを並行処理する(処理するプロセスを切り替える)ためにそれまでの処理の内容を記録し、新しい処理の内容を復元することです。「コンテキスト(文脈)」「スイッチ(切り替え)」という名前からもお分かりいただけると思います。複数のプロセスが同時に走っているように見せるため、OS内ではこのコンテキストスイッチが頻繁に繰り返されています。

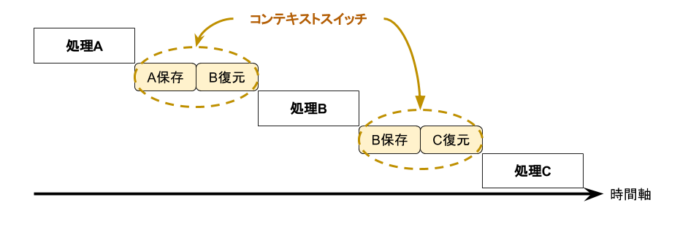
1つのCPUで複数のプロセスを切り替えるために必要なのがコンテキストスイッチ
1リクエスト1プロセス方式では、リクエストが増えるとプロセスも増えるため、コンテキストスイッチのコストが無視できなくなります。特にメモリー空間の切り替えには大きなコストがかかります。そしてコンテキストスイッチのコストが大きくなると、肝心なリクエストを捌くCPUリソースが足りなくなります。
マルチプロセスではなくシングルプロセス・マルチスレッドにすればプロセスIDの問題やコンテキストスイッチのコストはかなり改善されますが、それでも次に述べる問題があります。
ファイルディスクリプターの上限
こちらはCPU以外の問題です。
例えばデータベースを扱うアプリケーションの場合、リクエストごとにDBサーバーに接続すると、その分だけファイルディスクリプターを消費します。また、MySQLのキャッシュにmemcachedを使う構成にしていると、消費するファイルディスクリプターの数が倍になります。
ファイルディスクリプターとは簡単に説明するとOSが読み書きしているファイルのIDのようなもので、プロセスIDと同様にこれも一度に使える上限がOSごと・プロセスごとに設定されています。
つまり、OSで決められている以上の同時接続はできないため、プロセスIDの他にもこのファイルディスクリプターも同時に捌けるリクエストを制限する要因になります。
C10K問題の解決方法
C10K問題がOSの内部処理に絡む厄介な問題だということは理解いただけたかと思います。そんな厄介な問題はどのように解決すればいいのでしょうか。
方法1: サーバーの台数を増やす
1台のサーバーで捌けないなら10台使えばいい。
10台のサーバーで捌けないなら100台使えばいい。
そんなひたすらレベルを上げて物理で殴る、あるいは札束で殴る解決方法です。
ある意味もっともわかりやすい方法ですが、処理能力を遥かに下回るリクエスト数しか処理できないのでマシンスペックがもったいないのと、負荷を分散させるロードバランサー側にもC10K問題が発生しないように設計しなければいけません(後者はDNSラウンドロビンや広域負荷分散のようにロードバランサーも分散させるといった方法があります)。
一方、それとは全く別のアプローチによる解決方法も考え出されました。それが次の方法です。
方法2: シングルプロセス・シングルスレッドでリクエストを捌く
頭のいい人はこんなことを考えました。
「マルチプロセスとかマルチスレッド方式でプロセスIDの上限やコンテキストスイッチに引っかかるなら、シングルプロセス・シングルスレッドで全部のリクエストを処理すればいいんじゃね?」
「それに、シングルプロセス・シングルスレッドでDBコネクションとかも使い回せばファイルディスクリプターも枯渇しないんじゃね?」
まさに逆転の発想です。そこで生まれたのが非同期・ノンブロッキングI/Oです(正確には非同期とノンブロッキングは違いますが、ここでは省略します)。
従来の同期的なI/Oは、例えばDBサーバーからデータを取得する場合はデータが返ってくるまでアプリケーション側の処理も止めてしまいます。その場合、データが返ってくるまでの間はCPUが完全に暇になります。洗濯機のスイッチを入れて洗濯が終わるまでずっと洗濯機の前で待っているようなものです。

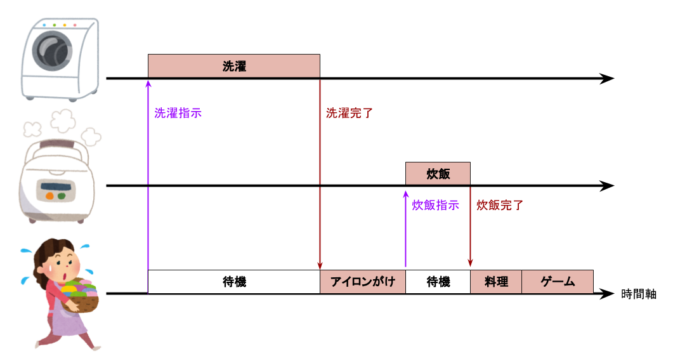
同期的に家事を行う例。待機時間が多く、リソースを有効活用できていない。
それに対して非同期I/Oは、CPU以外のリソースを使う場合に「このデータを処理しといてね。処理が終わったら教えてね」という指示を与え、完了を待たずに(ブロックせずに)別の処理を行います。
例えば、DBサーバーにクエリーを投げて「処理が終わったらこの関数をコールしてね」という指示を出し、処理が返ってくる前にファイルからデータを読み込む。その時も「読み込み終わったらこの関数の引数にデータを入れてコールしてね」という指示を出してCPUは別の処理を行う。そして先に終わった処理(先にコールされた関数)から処理の続きを行うといったイメージです。
洗濯機のスイッチを入れたら洗濯が終わるのを待たずに炊飯器のスイッチを入れ、炊き上がるのを待たずにゲームで遊ぶ。そして先にごはんが炊き上がったけどゲームがいいところだったら(CPUリソースを使っていたら)炊飯器はしばらく放置して、ゲームが一区切りついたら(CPUリソースが空いたら)ごはん支度を始める。そして洗濯が終わったらアイロンをかける…という流れをイメージすると理解できるでしょうか。

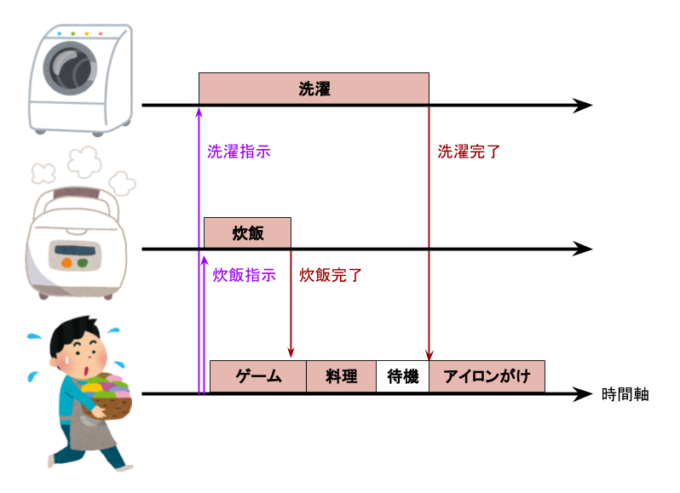
非同期的に家事を行う例。洗濯や炊飯が終わるまで別の処理を行ってリソースを有効活用できる。
この非同期I/Oのメリットはもう1つあります。それは処理の効率が上がることです。上の家事の図を見れば分かりやすいと思いますが、同期処理では洗濯や炊飯が終わるまでひたすら待機しているため、全て完了するまでに時間がかかります。それに対して非同期処理では洗濯と炊飯を外部に任せて並列処理している間に別のこと(ゲーム)を効率よく進められます。
この方式を取り入れたウェブサーバーがNGINXで、軽量・高速で有名です。構成によっては、同じウェブサーバー内でApacheの前段にNGINXを配置するだけで負荷が下がることもあります。
Node.jsのアプローチ
ようやくNode.jsの話に戻ってきました。長かった…
Node.jsも、シングルプロセス・シングルスレッド・非同期I/Oに基づいて設計されています(内部的にスレッドを作成する場合があります)。処理すべきものがどんどんイベントキューに追加され、それらを全て1つのプロセスで捌きます。そしてファイルアクセスや通信などのCPUを使わない処理は非同期で行われ、処理が終わったらコールバック関数が呼ばれます。そのため、きちんと設計すればC10K問題は発生しません。

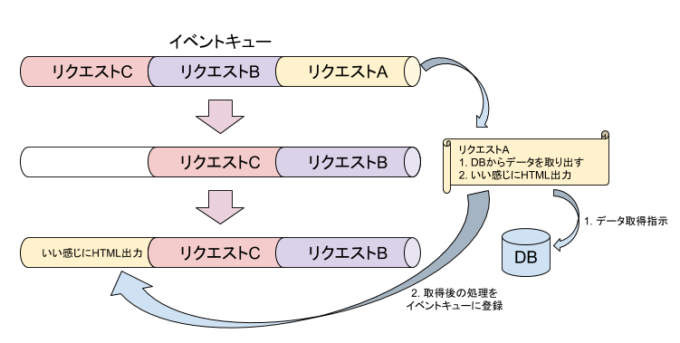
Node.jsのイベントキューの処理。全ての処理がキューに登録され、1つのプロセスで処理される。
もともとJavaScriptはシングルプロセス・シングルスレッドが前提で、さらに高階関数(関数を引数や戻り値とする関数)を簡単に使える言語なのでC10K問題と相性がよかったのでしょうね。
そしてフロントエンドとバックエンドを同じ言語(JavaScript)で開発できるという点もウェブサービス開発者のハートを鷲掴みし、話題を呼びました。
Node.jsを使う時の注意
「C10K問題も解決できるしフロントエンドと同じJavaScriptで書けるしNode.jsサイコー!」
だがちょっと待ってほしい。
確かにNode.jsはC10K問題を解決できますしJavaScriptで開発できますが、これで全ての問題を解決できるわけではありませんし、シングルプロセスや非同期処理になったことで新たに発生する問題もあります。
非同期処理の記述が面倒
まず、非同期処理は同期処理に比べて圧倒的に記述が面倒です。
- 非同期関数を使いまくるとコールバックが増えてネストが深くなる
- 例外処理が書きづらい
- かといって同期関数を使うとC10K問題どころかC2問題が発生する
ネストや例外に関しては、最近のJavaScriptはPromiseやasync/awaitが導入され、同期バージョンとあまり変わらないコードでわかりやすく記述できるようになっています。しかし、だからと言って非同期処理を意識せずに済むかというとそんなことはなく、前提知識として理解しておかないと開発時に思わぬバグを埋め込んでしまいます。
また、ほとんどの入出力関数には同期バージョンもありますが、非同期がわかりにくいからといって安易に同期バージョンを使ってはいけません。Node.jsはシングルプロセスなので、処理が終わるまで他のリクエストを一切受け付けなくなります。
グローバル変数がリクエスト間で共有される
マルチプロセス方式では、グローバル変数はリクエストごとに独立しているので別のリクエストのグローバル変数に影響を与えることはありません。プログラムのどこからでも参照でき、どこからでも破壊できるという点に気をつければ、あちこちの関数に処理が飛ぶことが多いウェブサービスでリクエスト内の状態管理をするにはグローバル変数は便利です。
しかし、シングルプロセスのNode.jsではグローバル変数は全リクエスト間で共有されます。そのため不用意にグローバル変数の値を変更すると他のリクエストにも影響が出ます。
リソースを回収してくれない
マルチプロセス方式では、リクエストの処理が終わった時点で(=プロセスが終了した時点で)使っていたリソース(メモリーやファイルなど)が自動的に解放されるので、リソースの解放についてプログラマーがあまり意識する必要はありません。
一方、Node.jsでは自動的に解放されないので、明示的に解放しておかないと使われないリソースがどんどん溜まってリソースが枯渇し、新しいリクエストを処理できなくなります。
これもシングルプロセスがゆえの問題です。
一部のバグがサービス全体に影響することがある
マルチプロセス方式では、間違えて無限ループを入れてしまった場合でもクライアントからの接続が切れた時点で当該リクエストのプロセスは消滅するので、被害はそれ以上広がりません。
しかしNode.jsではクライアントが接続を切ってもプロセスがそのまま残るため、無限ループが実行され続けます。ループが終了しないため、シングルプロセスが災いして他のリクエストを処理できません。
無限ループといったわかりやすいバグでなくても、例えばLIMITを指定せずに全件取得したデータをループで処理する場合などでも取得件数によっては他のリクエストを大幅に待たせてしまいます。
CPUリソースを消費するウェブサービスには向かない
Node.jsは処理速度が特段遅いわけではなく、むしろスクリプト言語の中では十分に速いといえます。それでもシングルプロセス方式のNode.jsはマルチプロセス方式に比べて多重ループをぶん回すようなCPUを食うサービスには不向きです。処理が終わるまで他のリクエストを処理できないためです。
そのため、CPUリソースを消費する処理は別プロセスや別サービスとしてNode.jsの外側に置く工夫が必要です。
フロントエンドと同じ言語で開発できると言っても…
これまで見てきたように、フロントエンドとバックエンドで同じ言語で書けるといっても、文法が同じだけの別物といってもいいくらいの違いがあります。
特にシングルプロセス・非同期処理について理解していないと簡単にバグを作り込んでしまうため、プログラミングの初心者がいきなりNode.jsから始めると色々つまづくかもしれません。
終わりに
以上、駆け足でNode.jsについて説明しました。
最後に、冒頭に書いた3つの疑問を再掲します。なんとなくでも理解いただけましたか?
- Node.jsって何?
- Node.jsを使うと何がうれしいの?
- Node.jsを使うときに何を注意すればいいの?
意見や感想等がありましたらこちらからお願いします!