バグ調査やパフォーマンス改善に役立つ!eBPFを用いたトレーシングについて

目次
はじめに
この記事では、Linuxカーネルに実装されているパケットフィルタであるeBPFを使ったトレーシングツール、具体的にはDTrace, SystemTap, bpftrace,bcc-toolsなどについて紹介させていただきます。この記事の目標を以下に示します。
- DTraceやSystemTapを簡単に説明し、eBPFを用いたトレーシングのうれしいところをお伝えします。
- bpftraceやbcc-toolsといったツールの簡単な使い方を紹介し、細かいツールを調べる上での足がかりになるようにします。
- 公式の資料がかなり充実していることをお伝えします。この記事で使っている画像はそこから使わせていただいています。
eBPF概説
eBPFは、Linuxカーネル3.15からBPF(Berkeley Packet Filter)の拡張仕様として導入されました。BPFはこれまでにもパケットフィルタやシステムコールフィルタ(例えばseccomp)など強力な機能を有していましたが、eBPFの導入によって、高速なネットワーク処理、より詳細なLinuxでのメトリクス取得に活用の幅が広がってきています。eBPFを取り巻くOSSプロダクトは開発もさかんに行われており、本記事では特にbpftraceとbcc-toolsを取り上げ、その一面を覗こうと思います。
トレーシングを可能にするツール
パフォーマンスのボトルネック調査やエラーの発生原因調査の際には、procps, sysstat, perf-toolsといったパッケージのツールや、syslogなどをまずは調査することが多いかと思います。しかし、それらから観測できるカウンタ値、ログのみからは判別できないために、より詳細なメトリクスやトレーシングが要求される状況もあるでしょう。これまでは、そうした状況下においてDtraceやSystemTapといった強力なトレーシングツールを用いることが可能でしたが、eBPFがLinuxカーネルに導入されたことをきっかけに、bpftraceが後継として開発されました。
DTraceとSystemTap
というわけで、まずはDTraceとSystemTapを見てみましょう。bpftraceはDTraceやSystemTapの後継にあたるので、これまで使われていたツールを知ることで、bpftraceを使う理由も見えてくると思います。
DTrace
DTraceは元々、Solaris 10, OpenSolarisに対して高度なトレーシングを行うために開発されました(*1)。D言語というプログラミング言語を用います。ただ、書き味はpure Dよりも高級なDSL(*2)です。
(*1) 現在、dtrace4linuxと呼ばれるDTraceをLinux向けに移植したプロジェクトもありますが、DTrace本体とは一部異なる挙動をする可能性があります。
(*2) Domain-Specific Language(ドメイン固有言語)。特定のタスク向けに開発されたプログラミング言語で、目的に対しては汎用プログラミング言語より書きやすくなっているもの。
DTraceはいくつかのプロバイダを提供しており、これらによってプローブが設置されます。プローブの先頭にはどのプロバイダを利用するのか指定する必要があり、これによってどのようにトレースされるのかが決定されます。プロバイダはカーネルモジュールとして実装され、ユーザランドからioctl(2)を用いてやり取りが行われることでトレーシングが実現されます。


上の図はDTraceスクリプトの簡単なサンプルです。大きく2つのブロックがあり、上のブロックがVimプロセスのopen(2)に対してトレーシングをするもので、プロセスIDを出力するようになっています。下のブロックは100秒経ったらタイムアウトして終了します。
SystemTap
SystemTapは、Linuxで高度なトレーシングを行うために開発されました。DSLで記述されたコードはC言語のソースに変換され、カーネルモジュールにコンパイルされます(*3)。SystemTapはプローブポイントをいくつか定義しており、これらによって、どこに対してトレーシングを実施するかが決定されます。
(*3) stapdynと呼ばれるユーザランドのSystemTapバックエンドも開発されているようで、この場合はstapフロントエンドによって共有ライブラリにコンパイルされたものを利用するようです。


上の図はSystemTapスクリプトの簡単な例ですが、VFS、つまり仮想ファイルシステムに対するすべてのreadシステムコールをプローブに指定しています。呼び出されたらprintfで「readが呼び出されました」と出力するだけの簡単なスクリプトです。
そしてbpftraceへ
DTraceとSystemTapを見てきましたが、「どちらでもやりたいことは実現できそうなんだけど、どちらを使えばいいの?」という風に悩むケースもあるかと思います。どちらも開発経緯や設計などが異なるだけで、優劣をつけたり、使い分けるのは難しいと思われます。大きな共通点は、どちらもカーネルモジュールを用いていて、それによってトレーシングが実現されているということです。bpftraceはこれらの後継に相当し、両者の良い設計を取り込みつつ、eBPFに合わせてゼロベースで開発されたOSSです。
bpftraceで可能になったことは次の通りです。
- カーネル空間である程度計算が行われるため、ユーザ空間へのデータコピーによるコストが下がりました。例えば、特定プローブ呼び出し回数のヒストグラムを生成したい場合に、ヒストグラムの計算処理をカーネル空間で行い、それをユーザランドにコピーするだけになっています。
- BPFの命令セットによる中間言語に変換され、JITコンパイルできるようになったことで高速化されました。
- Linux内部に存在するVerifierによってプログラムが厳格に検査されるようになり、より安全性が向上しました。
- これまで利用できたMapなどのデータ構造などもeBPFでサポートされました。
bpftraceの概要
bpftraceは、DSLの記述で高レベルなトレーシングが行えるeBPFフロントエンドです。IO VisorプロジェクトのOSSプロダクトとして開発が行われています。
インストール要件
bpftraceのインストール要件は、GitHubのINSTALL.mdに記載されていますので、詳しくはそちらを見てください。個人的な認識ではLinux 5.xを用いた方が安定して動作します。また、*BPF*, *EBPF*, FTRACE_SYSCALLSまわりのカーネルコンフィグが設定されていることを確認しておきましょう。Ubuntuではdebパッケージやsnapパッケージが利用可能ですので、これらでインストールすればOKです。
bpftrace概観
bpftraceの概観を下図に示します。(出典:bpftrace Internals)
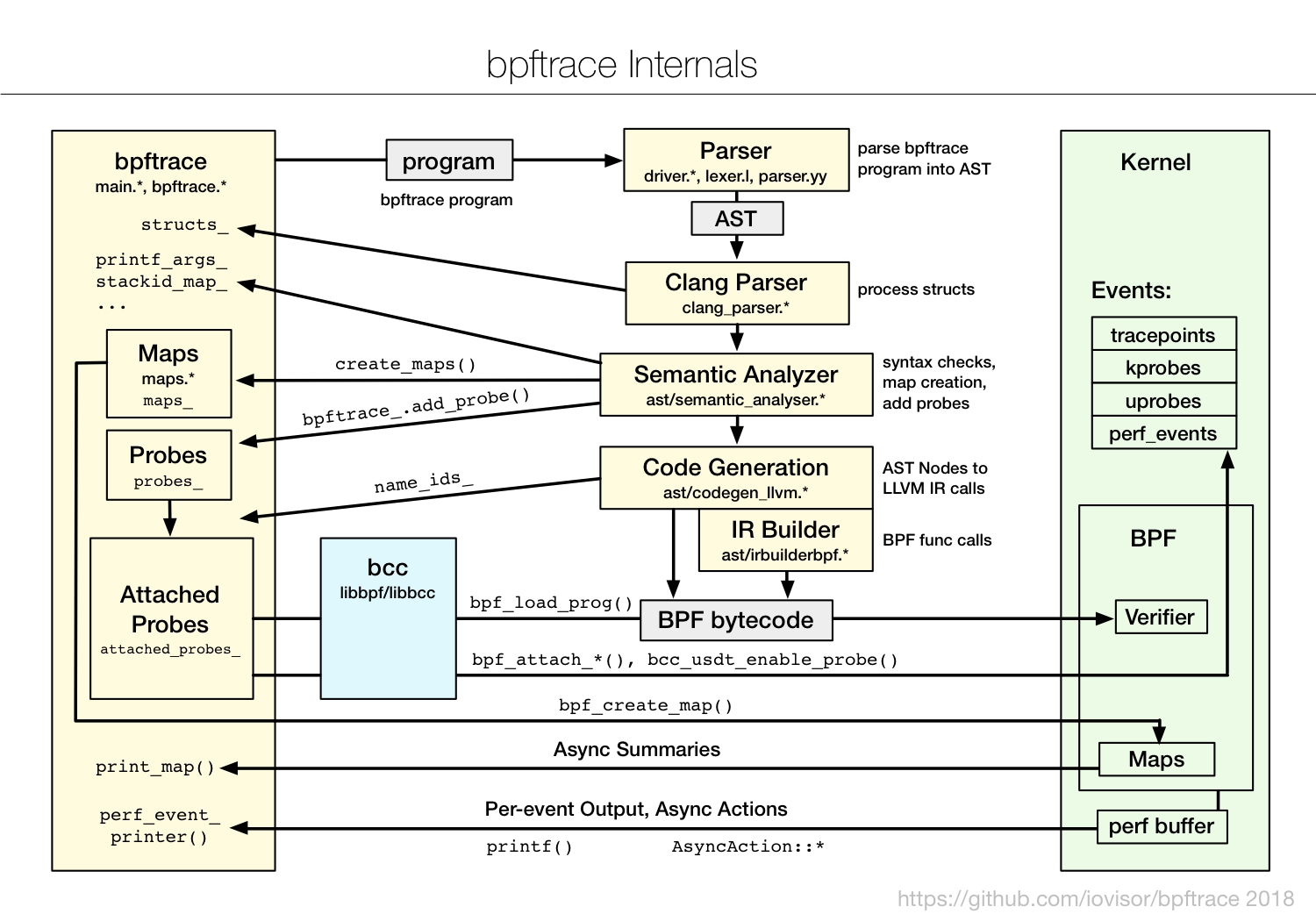
まず、左上あたりにあるprogramという灰色のボックスが、bpftraceスクリプトで記述されたプログラムです。bpftraceを実行するとこれがParserへと渡されます。ここでLexer, Parserを通してAST(抽象構文木)が生成され、構文解析されて、LLVMバックエンドによりBPFバイトコードへ変換されます。これはLinuxカーネルで実装されているVerifierに渡され、検査ののち、JITコンパイルされて実行されます。
トレース種別
bpftraceにおけるトレースの種別は以下の4つです。
- kprobe
- uprobe
- Tracepoint
- USDT (User Statically-Defined Tracing)
これらの中でも特に安定して使えるトレース種別はTracepointですので、Tracepointを使って情報を取得する例をご紹介します。詳細はTracepointに関するブログ記事をご参照いただきたいのですが、Linuxのソースコード上に静的にプローブポイントが設定されるので、他の種別と比較して更新頻度が少なく、書いたプログラムが環境によって突然動かなくなる問題が発生しにくいことが安定して使える理由です。
bpftraceを使ってみる
それではbpftraceを使ってみましょう。ここでは、Linuxのプロセススケジューラがプロセスを終了させた時、そのプロセスのコマンド名をMapデータ構造に保存し、呼び出し回数を記録してみます。使用する環境は以下の通りです。
- OS:Ubuntu 18.04.4 LTS (bionic)
- uname -aの出力
Linux kazu-desktop 5.3.0-51-generic #44~18.04.2-Ubuntu SMP Thu Apr 23 14:27:18 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
- CPU:4コア
- メモリ:16GB
トレーシングの流れとしては、まず、Tracepoint一覧に欲しいものがあるかを探します。それから、引数にコマンド名をとっていることを確認し、DSLを書いて実行します。順に見ていきましょう。
Tracepoint一覧に欲しいものがあるか探す
Tracepoint一覧に欲しいものがあるか探すには、bpftraceに-lオプションを足すとプローブポイントを一通り列挙することが可能です。以下の実行例では、検索用文字列の先頭にtracepointがきて、間は何かわからないのでワイルドカードを入れて検索しています。結果として1件マッチしています。

引数にコマンド名を取っていることを確認
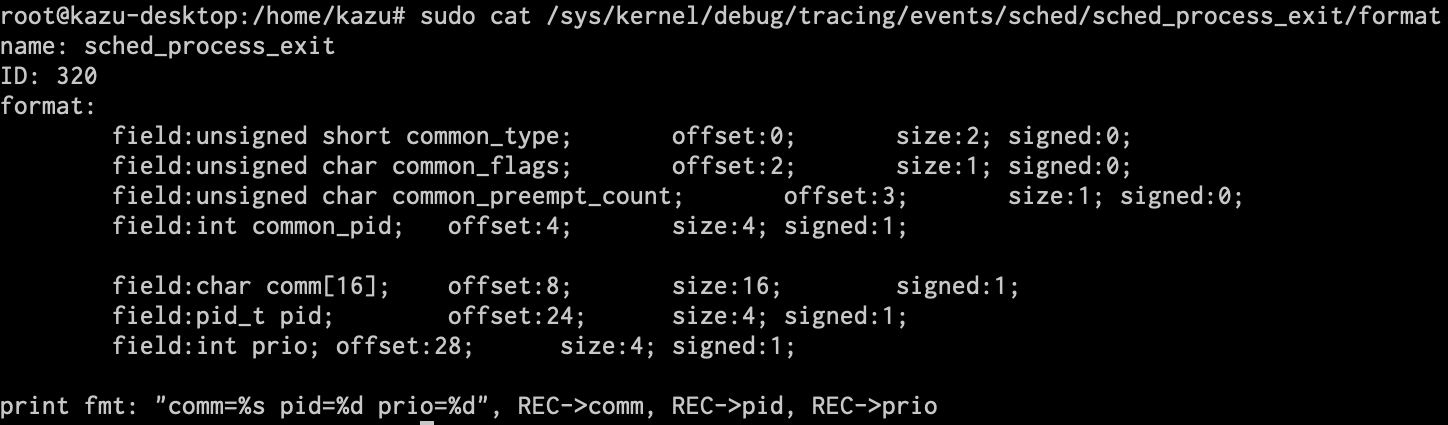
引数にコマンド名を取っていることを確認するには、/sys/kernel/debug/tracing/events/$(先ほど見つけたTracepointをパス化したもの)/format のファイルに詳細が書かれていますので、それを見ます(*4)。引数の上から5つ目のcomm[16]がコマンド名を示すので、これを使うことになります。
(*4) 今回の例ではtracepoint:sched:sched_process_exitを用いてトレースしますので、ここで見るファイルは/sys/kernel/debug/tracing/events/sched/sched_process_exit/format となります。
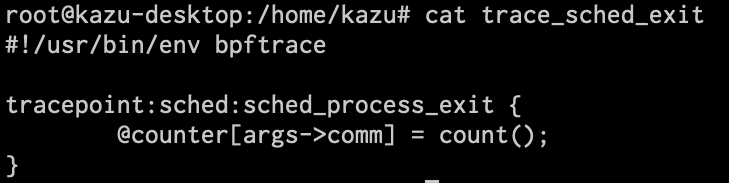
DSLのプログラムを書いて実行
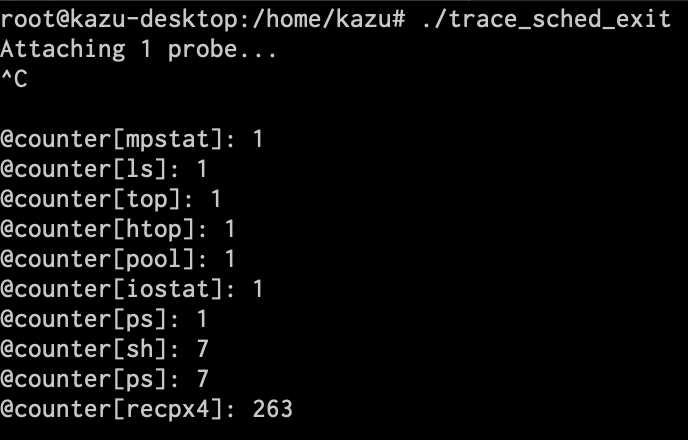
これをもとにDSLのプログラムを書いたら、こんな感じになります。Mapデータ構造である@counterのキーにコマンド名を入れ、値にカウントを入れています。
早速実行してみましょう。実行後、ちょっと時間が経ってからCTRL-Cで終了させると、以下のようにMapデータ構造の中身がすべて出力されます。
bcc-toolsの概要
では次にbcc-toolsについて見ていきましょう。
bpftraceと同じように実行できるbccというものが、同じくIO Visorプロジェクトで開発されています。このbccで書かれたツール群であるbcc-toolsを用いることで、これまで用いていた可観測性ツールよりもより役立つ情報が得られるようになります。インストール要件はGitHubのINSTALL.mdをご覧ください。もしかすると、procpsやsysstatの代替としてbcc-toolsが広く使われる未来が来るかもしれません。
一般的に、Linuxマシンの負荷が高いとかうまく動いていないとかいうときに、調査のためにログインしてすぐ調べることとしてはこんなものがあるかと思います。
- ロードアベレージを見て、負荷が高いかどうか
- syslogを見て、OOMだとか、パケットドロップが発生していないか
- vmstatで概況を確認
- CPUコアごとの負荷を確認
- リアルタイムに実行されているコマンドを確認
- I/O負荷の確認
- メモリ使用量の確認
- ネットワーク、TCPまわりの統計情報を確認
- などなど
これらに対して、bcc-toolsにはいくつかの分かりやすく使えそうなツールがあるので、それらを紹介してみようと思います。
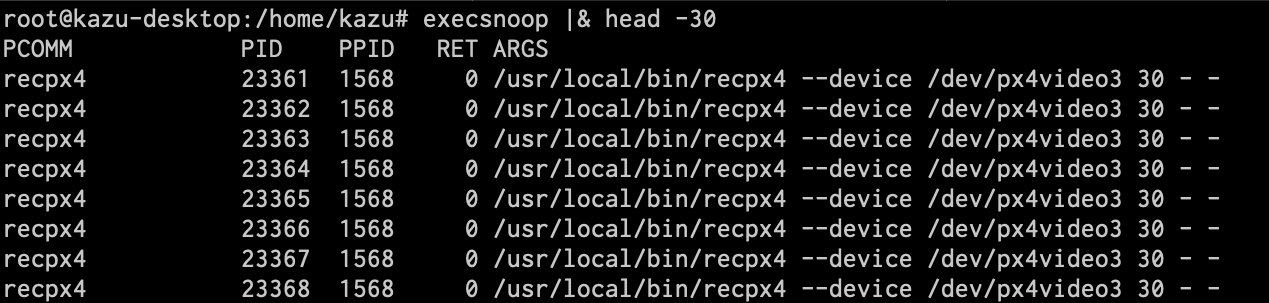
execsnoop
実行プロセスを追跡できます。コマンドの引数、親プロセスのID、終了コードなども表示してくれます。
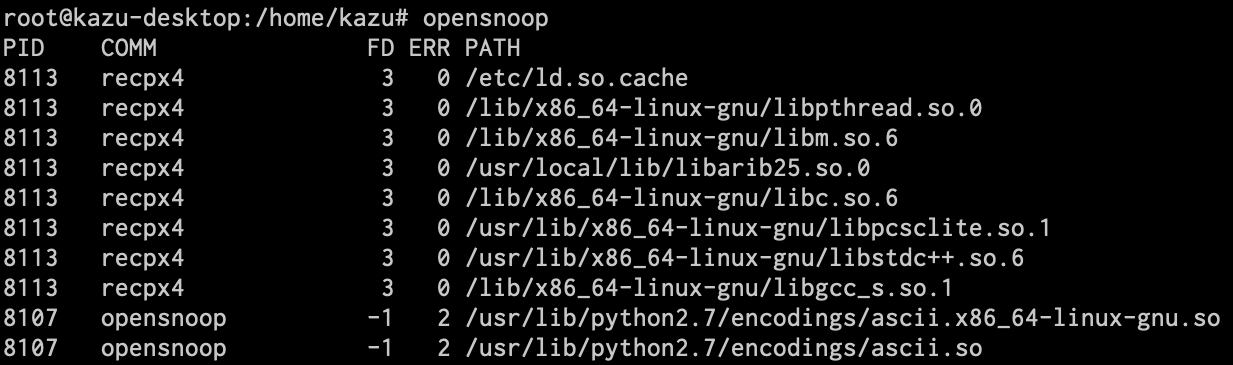
opensnoop
どのプロセスがどのファイルを開いているのかが確認できます。また、そのファイルのファイルディスクリプタや、エラー発生時の終了コードも表示されます。
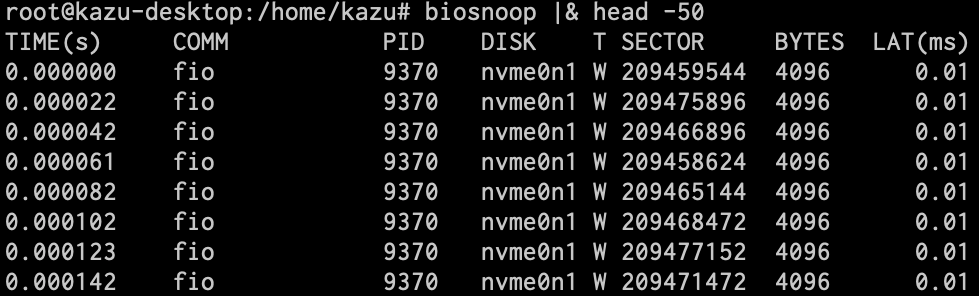
biosnoop
ブロックI/Oのバイト数、使用ディスク、コマンド、プロセスID、経過時間、遅延などを見られます。以下の例ではfioコマンドの実行中の様子を観察しています。
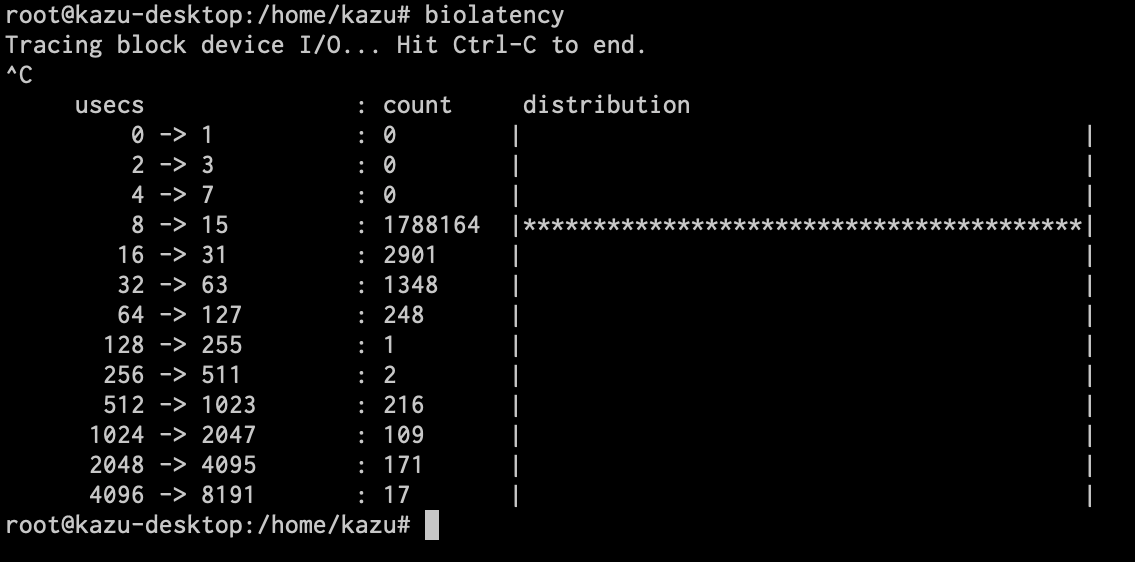
biolatency
ブロックI/Oのレイテンシを計測し、それをヒストグラムで表示します。
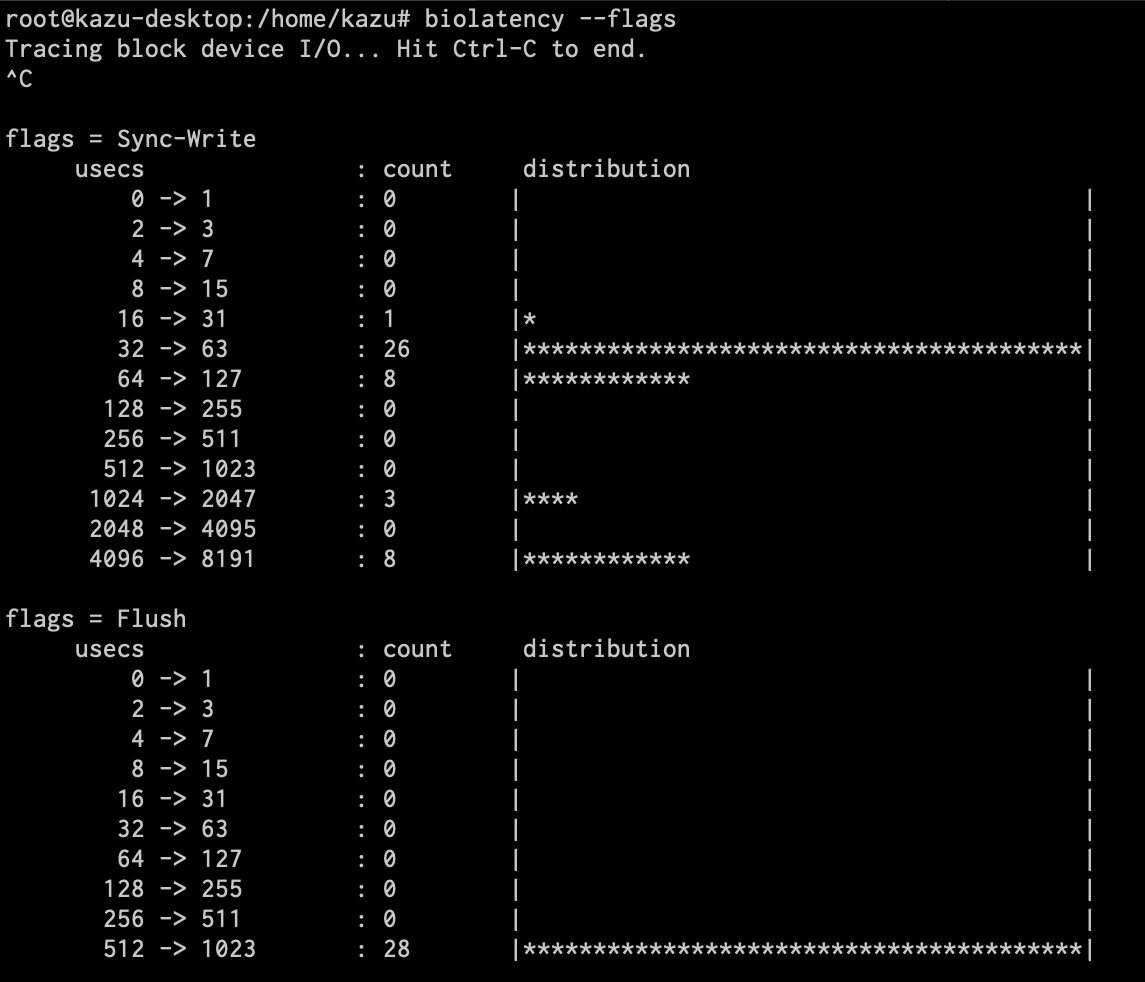
I/Oフラグ(rwbsと呼ばれる)ごとにヒストグラムを出すことも可能です(--flagsオプション)(*5)。
(*5) rwbsはこのあたりのソースコードで利用されています。
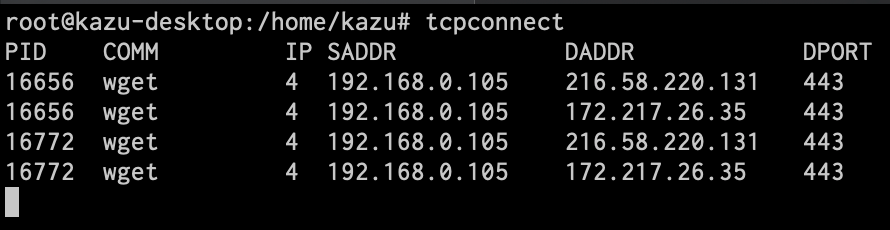
tcpconnect
TCPのconnect(3)呼び出しをトレースします。どのコマンド実行によって、どこからどこへのやりとりが行われているかを把握できます。以下の例ではwgetコマンド実行時の動きを出力しています。
tcpretrans
TCPの再送を列挙します。これは細かく追跡するのに結構手間がかかる場合があるので、個人的には結構便利だなと思っているツールです。
![]()
実行例の右端のSTATE列にTCPの状態が出力されていますが、これがSYN_SENTになっている場合、こちらが送信したもののまだ受け付けてもらえておらず、バックログキューに滞留している状態であることがを推測できます。一方、ESTABLISHEDになっている場合は、すでに接続の確立はできているので、サーバは高負荷でないと予想されます。このようなときは外部ネットワークで何かしら問題が起きている可能性が高いと推測できます。
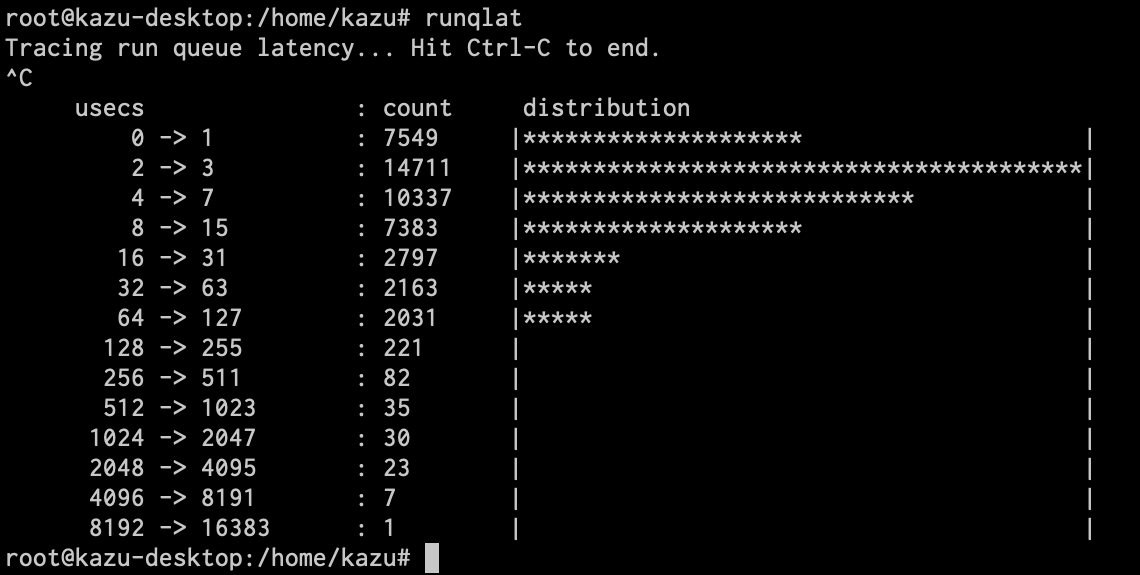
runqlat
プロセスが実行可能状態になってから実際に実行されるまでにどれくらいの遅延が発生しているかをヒストグラム化してくれます。これに近いような値としてロードアベレージを簡単に調べることが可能ですが、ロードアベレージを見るだけではrunキューで待たされたプロセスがどれくらいの遅延で実行できるようになるのかがわかりません。runqlatではこれを視覚的に分かりやすく把握できるようになっています。
オプション指定
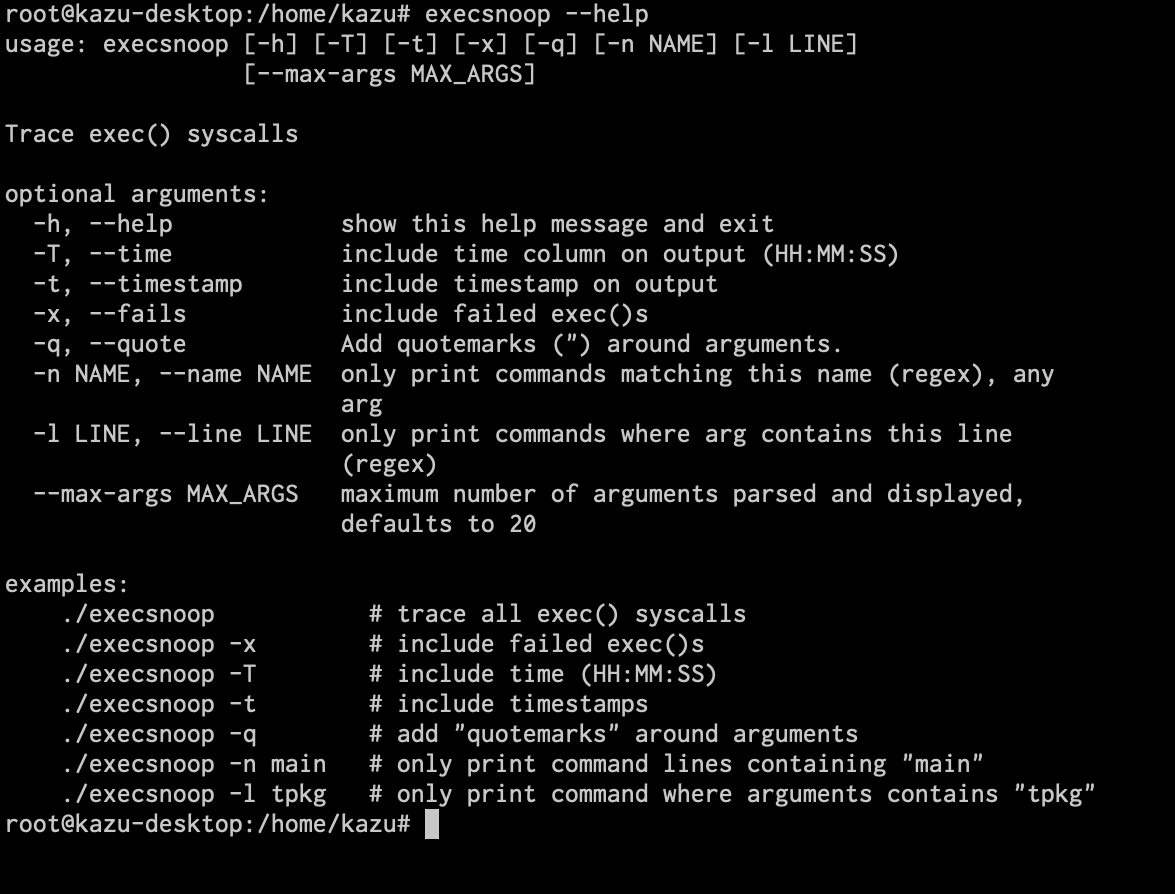
これらのツール共通のオプションとして、--helpオプションでUsage, Options, Examplesなど、かなり詳しい説明が出力されるようになっています。以下はexecsnoopの例ですが、Examplesにはコマンドの利用例や、どういう状況で使うのかといったことが書かれています。使い始めの頃はこれがかなり便利なので確認をおすすめします。
bcc-toolsの内部
bcc-toolsの内部実装についても少し紹介します。
bcc-toolsの開発言語
bcc-toolsはPythonやLuaで書かれています。iovisor/bccリポジトリのtoolsディレクトリ配下にbcc-toolsが同梱されています。iovisor/bccリポジトリにはPythonやLuaのbccライブラリも同梱されており、bcc-toolsがこのライブラリをimportする形になっています。
bccライブラリを使った実行の流れ
bccライブラリを使った実行の大まかな流れを、execsnoop.pyを例として簡単に説明します。
- まずbccライブラリをimportします。
- 次に、Cのソースをbcc.BPFクラスに渡して初期化します。ソースは文字列で定義して渡してもよいですし、別ファイルを読み込んでもよし、ヘッダファイルを利用してもかまいません。
- 初期化されたbcc.BPFのattach_xxxメソッドを呼び出します。xxxはkprobeとかTracepointとかです。こちらは呼び出されると、システムコールのperf_event_open(2)が呼び出されて、カーネル空間でパフォーマンスカウンタが収集されるようになります。
- bcc.BPFのopen_perf_bufferを呼び出し、ユーザが定義したコールバック関数を登録します。
- bcc.BPFのperf_buffer_pollを無限ループみたいな形で呼び出し続けると、イベントの発生を監視する形になります。内部的には、poll(2)が呼び出されることでperf ring bufferのイベント監視が行われます。
- こうして、イベント監視によってイベントが検知され、検知されたイベントはコールバック関数にわたり、適切に加工されて出力されます。
bcc-toolsはまだまだたくさんある!
ここでご紹介したbcc-toolsは実はほんの一部で、このほかに非常に多くのツールが用意されています。詳しくは公式サイトのREADMEをご覧ください。
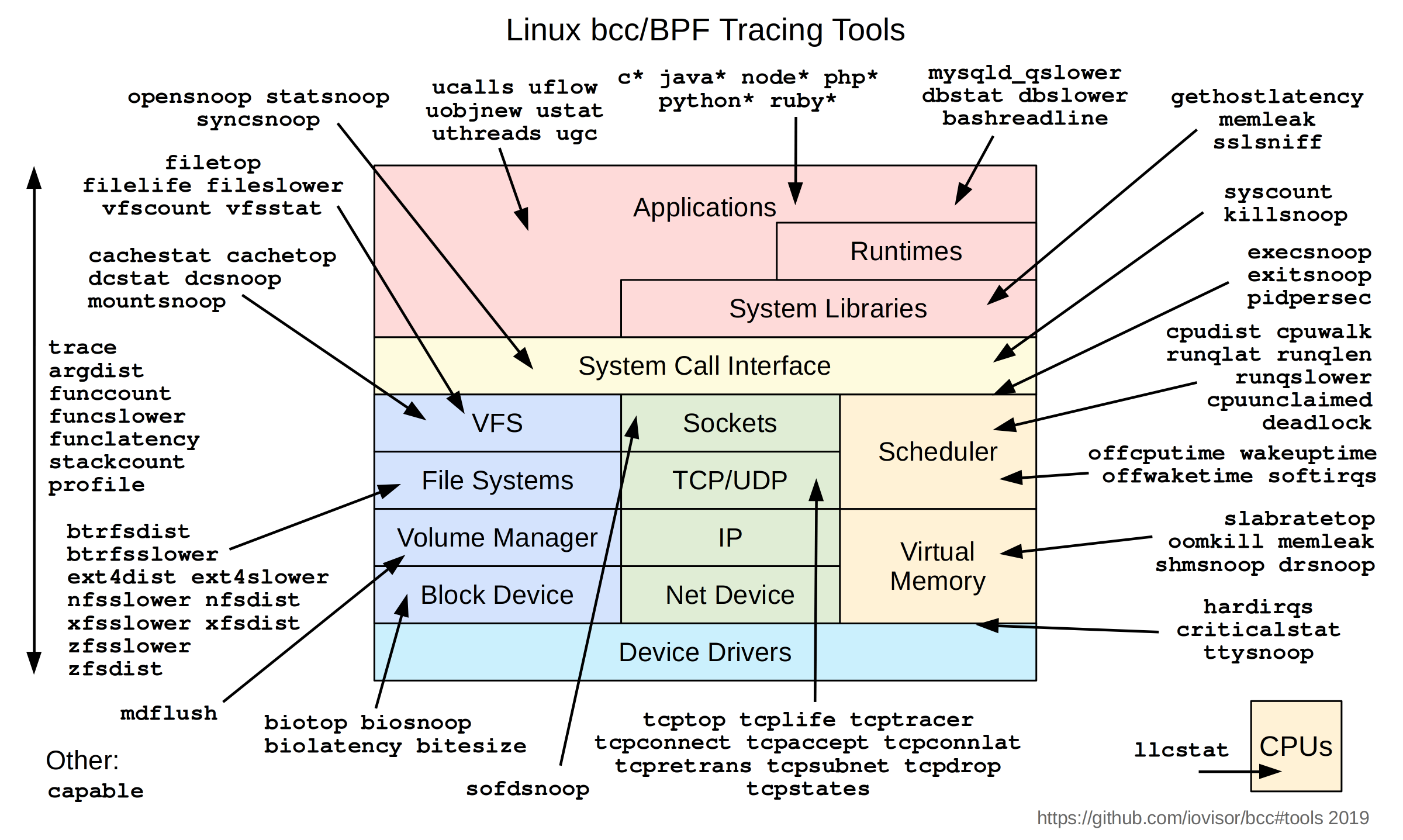
bcc-tools概観図(出典:https://github.com/iovisor/bcc#tools)
より詳しく知りたい方向けに
まずは「BPF Performance Tools」という書籍がおすすめです。eBPFのトレーシングについては、おそらくこの書籍が一番詳しいかと思います。ネットワーク処理、XDPまわりにも興味があるよ!と言う方には「Linux Observability with BPF」がおすすめです。導入に必要な知識が少ないページ数でキッチリ説明されてます。Githubリポジトリのコードも参照しながら読み進めることをお勧めします。
注意事項
bpftraceやbcc-toolsを実際に利用する場合、トレースの仕方によって負荷が変わることに注意する必要があります。
従来のトレーシングツールと比べて負荷は可能な限り抑えられているものの、当然ゼロコストではないため、ワークロード負荷が高い環境で頻繁に発火するイベントを観測しようとすれば負荷は高くなります。またCPUコア数が多いシステムではCPUコアごとに負荷が発生するため、その分トレーシングによる負荷が高くなりうるでしょうし、もっと言えばコールバック関数の実装が悪ければリソース消費が激しくなる可能性もあります。
もしツールをプロダクション環境で利用しようとするなら、BPF Performance Toolsの18章をご一読いただくことをお勧めします。加えて、どのツールを利用して、どのような環境で、何に対してトレースするかによってケースバイケースであるため、ご自身でまず検証することをお勧めします。
かくいう私は開発環境でツールを試しており、まだプロダクション環境で利用した経験はありません。しかし、「本番環境には悪魔が住んでいる」なんて言われることがありますが、いずれこのようなツールを駆使することでそういった問題を解決していきたいと考えています。
おわりに
この記事で紹介したトレーシングツールは、障害原因を調査する目的はもちろんのこと、Linuxの挙動をより詳しく知りたい場合にも有用だと思います。bcc-toolsには分かりやすいオプションが定義されているので、そちらも確認してみてください!
また、ここでは紹介しきれていませんが、IO Visorプロジェクト外で開発されているCiliumやKatranなどのOSS、Prometheusと連携できるebpf_exporter、パケット解析できるP4言語、LinuxのLSMであるLandlockなど、eBPFは面白い活用の仕方があったりします。今後も目が離せなさそうで、非常に面白い技術ネタだと思っています!また機会があればご紹介できればと思います!