さくらのクラウド向けツールを使いこなして構成管理を省力化


目次
はじめに
さくらのクラウドには、組み合わせると便利に使えるツールがたくさんあります。この記事では、Ansible, Pulumi, Prometheusを組み合わせて、構成管理を省力化するテクニックを紹介します。これらは業務で実際に利用しているツールやフローです。
さくらのクラウドについて
簡単にさくらのクラウドの紹介をします。
- データの転送料が無料です。AWSなどを使っている人には驚かれることが多いです。
- コントロールパネルが直観的に操作できると思います。
- 最小構成の料金が1,980円(1コア1GBサーバ+20GB SSD)です。さくらのVPSなどと比べると中規模以上のシステムを組む方が利用されるのかなと思います。
- ネットワーク関連サービスが豊富で、例えばこんなのがあります。
- さくらのVPS/さくらの専用サーバ/AWSとの接続
- GSLB, L4/L7ロードバランサー
- セキュアモバイルコネクト(3キャリアに繋がるSIM)
私は特にセキュアモバイルコネクトが好きです。サーバ、スイッチ、SIMという組み合わせで使えておもしろいサービスです。
さらに詳しいことは、さくらのクラウドのサービスサイトを見てください。
さくらのクラウドで利用可能なツール
さくらのクラウドで利用可能なツールはたくさんありますが、この記事では主に構成管理に使うツールを紹介します。代表的なものはこんなところかと思います。
- Terraform, Pulumi
サーバ・ネットワークインフラの構成管理に利用するためのツールです。例えば、複数のサーバを作って、それらに対して全部ファイアウォールの設定を行ったりとか、このスイッチに接続するとかを、すべてコードベースで管理できます。 - Ansible
こちらは、サーバやネットワークインフラよりはレイヤーの高い、SSHでログインしてからの作業みたいなものを構成管理することができます。例えば、Apache, nginx, Docker, 監視エージェントなどの管理ができます。
この記事では、Pulumi, Ansibleを使った構成管理を紹介したいと思います。
Pulumi

Pulumi公式サイト
ツールの概要
Pulumiは、OSSのプロビジョニングツールです。Terraformと比較されることがよくあります。インフラをTypeScript, Python, Go, C#などで構築することができます。基本的に無料で利用可能で、一部有料のプランもありますが、無料の機能だけでも十分に使えます。各種プロバイダも用意されていて、クラウドだとAWS, Azure, GCPなどに対応していますし、MySQLやPostgreSQLなどのテーブルやユーザ管理も行うことができます。ちなみにさくらのクラウドもパッケージ追加で利用可能です。
サーバの作成作業などは間違えると影響範囲が大きくなることがあるので、作業をコード化するのはとても重要です。Pulumiを使うことで、間違えやすい作業をコード化し、同じ作業を何度実行しても状態が変わらないように記述すること(冪等性)が可能になります。
Pulumiのインストール
さくらのクラウドにおけるPulumiのインストール手順を以下に示します。
# pulumiのインストール $ curl -fsSL https://get.pulumi.com | sh # ステートをカレントディレクトリの .state ディレクトリに保存 $ pulumi login --local $ mkdir .state # とりあえずkubernetes-typescriptテンプレートで初期化 $ pulumi new kubernetes-typescript --force # k8s関連パッケージを削除 $ npm remove @pulumi/kubernetes @pulumi/kubernetesx # さくらのクラウドパッケージを導入 $ pulumi plugin install resource sakuracloud 0.3.0 --server https://github.com/sacloud/pulumi-sakuracloud/releases/download/0.3.0 $ npm install @sacloud/pulumi_sakuracloud # さくらのクラウドのAPIキーを入力 $ pulumi config set --secret sakuracloud:secret ****************** $ pulumi config set --plaintext sakuracloud:token 2fd7ba82-98d7-4fde-aac7-887ee8775734 $ pulumi config set --plaintext sakuracloud:zone tk1a
ポイントとしては、Pulumiにはさくらのクラウド用のテンプレートがないので、とりあえずKubernetes用のテンプレートで初期化してからKubernetes関連のパッケージを削除し、それからさくらのクラウド用のパッケージを導入することです。
簡単な例その1:サーバの作成
最初の例として、以下のファイルをご覧ください(ファイル名はindex.tsとします)。ちなみにPulumiの各種ファイルはTypeScriptで記述します。
// index.ts
import * as sakuracloud from '@sacloud/pulumi_sakuracloud';
// ディスクイメージのIDを取得
const ubuntu18archive = sakuracloud.getArchive({
filter: {
tags: ['ubuntu-18.04-latest'],
},
});
// 20GBのSSDを作成
const disk = new sakuracloud.Disk('example-disk', {
plan: 'ssd',
size: 20,
sourceArchiveId: ubuntu18archive.id,
});
// サーバを作成
const server = new sakuracloud.Server('example-server', {
disks: [disk.id],
});
この例では、はじめにUbuntuのディスクイメージのIDを取得します。次に、そのIDを使って20GBのディスクを作成し、さらにそのディスクを使ってサーバを作成しています。
ここで以下のコマンドを実行すると上記のindex.tsが実行され、さくらのクラウドにサーバが作成されます。
$ pulumi up
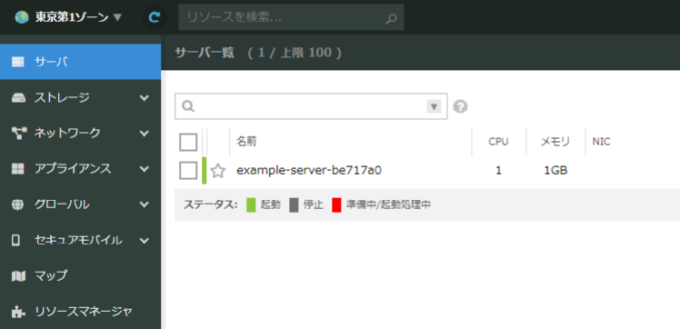
コントロールパネルでもサーバが1台作られたことを確認できます。

簡単な例その2:ネットワークにつなぐ
先ほどの例では作ったサーバがネットワークにつながっていなかったので、つないでみます。以下のコードがその例です。
// SSH鍵を登録
const sshKey = new sakuracloud.SSHKey('ssh-key', {
publicKey: 'ssh-rsa *************',
});
// サーバを作成
const server = new sakuracloud.Server('example-server', {
disks: [disk.id],
networkInterfaces: [{
upstream: 'shared',
}],
diskEditParameter: {
sshKeyIds: [sshKey.id],
},
});
まずSSHの鍵をさくらのクラウドに登録する機能があるので、それを使って鍵を登録します。その次に、先ほどの例で作ったディスクと共有ネットワークを指定し、diskEditParameterにてSSHの鍵を指定してサーバを作成します。
スタックの切り替え
Pulumiにはスタック(Stack)という概念があります。例えば開発環境・ステージング環境・本番環境とあって、インフラの構成が少しずつ違うというのはよくあると思いますが、そういったことをサポートするための機能です。
以下の例は、最初にdevというスタックがあるところに、新たにprodというスタックを作り、そちらに切り替えてからpulumi upを実行しています。こうすると1つの構成ファイルから複数の環境にデプロイできます。
$ pulumi stack ls NAME LAST UPDATE RESOURCE COUNT dev* 6 minutes ago 4 $ pulumi stack init prod # スタックprodを作成 $ pulumi stack select prod # スタックの切り替え $ pulumi up # 実行
また、pulumi.getStack()という関数を呼ぶと現在のスタック名がわかるので、スタックによって処理を分岐することもできます。
import * as pulumi from '@pulumi/pulumi';
pulumi.getStack(); // 現在のStack名 dev/prod
switch (pulumi.getStack()) {
case 'dev':
break;
case 'prod':
break;
}
情報の暗号化
Pulumiでは、シークレット情報をパスワードで暗号化することができます。下記の例では、さくらのクラウドのプラグインで要求されるゾーン名(zone)、トークン(token)、シークレット(secret)を設定していますが、シークレット情報は外部に漏れてはいけないので、--secretをつけて設定しています。
$ pulumi config set --plaintext sakuracloud:zone tk1a $ pulumi config set --plaintext sakuracloud:token 2fd7ba82-98d7-4fde-aac7-887ee8775734 $ pulumi config set --secret sakuracloud:secret ******************
pulumi configで設定を見ても、sakuracloud:secretの値は隠蔽されています。
$ pulumi config KEY VALUE sakuracloud:secret [secret] sakuracloud:token 2fd7ba82-98d7-4fde-aac7-887ee8775734 sakuracloud:zone tk1a
しかし、pulumi upなどの各種コマンドを打つときに毎回パスワードを求められるのは面倒です。これに対しては、下記の環境変数を設定するとパスワードの入力を省略することができて便利です。
# パスワードの入力を省略する PULUMI_CONFIG_PASSPHRASE=encrypt-password
依存したリソースの定義
Pulumiでは、ディスクとサーバのような、依存したリソースを定義することができます。下記のようなコードを書いても、上から順番にリソースが作られるわけではなく、どれを先に作るべきかをPulumiが考えて自動的にリソースを作成してくれます。
const disk = new sakuracloud.Disk('disk');
const server = new sakuracloud.Server('server', {
disks: [disk.id],
});
既存リソースのインポート
既存のリソースをインポートすることも可能です。下記は新しいスイッチを作成する例です。第1引数はリソース名、第2引数はスイッチのオプション(ここでは無指定)ですが、第3引数で以前に作成したサーバのIDをインポートすると、それが自動的にスイッチに接続されます。
const internalSwitch = new sakuracloud.Switch('internal-switch', {
// options
}, {
import: '123456789012', // 既存のリソースIDを指定
})
リファクタリング
Pulumiではリソースを作成する際に第1引数にてリソース名を指定します。リソース名は同じリソースの種類ごとに重複がないように決める必要があります。このリソース名を維持していれば、コードの記述方法を変えてもリソースとの紐付けは維持されます。
以下の2つのコードは、いずれexample-serverとexample-diskを作るためのコードですが、2番目のコードのように関数を用いて定義することで、exampleというプレフィックスだけ指定してサーバを作成することを可能にしています。リソース名を維持していれば、後からでも言語の機能を使って楽に共通化を行い、記述量を減らすことが出来ます。
const disk = new sakuracloud.Disk('example-disk');
const server = new sakuracloud.Server('example-server', {
disks: [disk.id],
});
function createBasicInstance (prefix: string) {
const disk = new sakuracloud.Disk(prefix + '-disk');
const server = new sakuracloud.Server(prefix + '-server', {
disks: [disk.id],
});
return { disk, server };
}
createBasicInstance('example');
ファイル分割
コードを複数のファイルに分割することも簡単にできます。これはTypeScriptの機能を使って実現しています。下記の例では、instanceTemplate.tsというファイルで記述したサーバ作成コードを、index.tsでインポートして実行しています。
// instanceTemplate.ts
export function createBasicInstance (prefix: string) {
const disk = new sakuracloud.Disk(prefix + '-disk');
const server = new sakuracloud.Server(prefix + '-server', {
disks: [disk.id],
});
return { disk, server };
}
// index.ts
import { createBasicInstance } from './instanceTemplate.ts';
createBasicInstance('example');
Stateファイル
Stateファイルは、現在のリソース状況を保持する複数のJSONファイルです。これがあることで、Pulumi上のリソースとクラウド上のリソースを紐付けることができます。例えば、Pulumiで書いたコードを実行してサーバを10台作っているときに5台目で異常終了したとしても、Stateファイルには5台分の情報が記録されています。
ファイルの保存場所は、Pulumi Serviceを利用するか(1人なら無料、チームでの利用は有料)、AWS S3, Google Cloud Storage, Azure Blobなどのオブジェクトストレージを使うか、もしくはローカルのファイルストレージに置いてGitHub等で管理することもできます。
Ansible

Ansible公式サイト
ツールの概要
AnsibleもOSSのプロビジョニングツールですが、Pulumiと違って、サーバを立てた後の設定作業を行うツールです。YAMLファイルの内容に従って複数サーバ内の設定を自動的に行います。サーバにはAnsible内部からSSHで接続するようになっているので、さくらのクラウド/さくらのVPSといったサービスの違いや、Ubuntu/CentOSなどOSの違いに関係なく使うことができます。
設定ファイルの設置やパッケージの導入といった手順書に基づく作業は属人化しがちですが、そういった作業をコード化し、誰が何度実行しても状態が変わらないように記述することができる(冪等性)のがAnsibleの利点です。
Ansibleでできること
Ansibleには、用途ごとに多数のモジュールが用意されています。一例を以下に挙げます。
- file: シンボリックリンク・ディレクトリの作成
- copy: ファイルをサーバに送信・設置
- template: jinjaテンプレートで設定ファイル等を作成・設置
- apt,dnf: パッケージのインストール
- sysctl: Linuxカーネルパラメータの設定
- systemd: サービスの有効・開始
モジュールの総数を調べてみたところ、3000以上あるようです。中には特定クラウド向けやミドルウェア向けのモジュールも多数含まれています。
簡単な例
Ansibleは主に2つのファイルを使ってマシンへの操作を記述します。
1つはInventoryファイルです。こちらには主にホストの情報を書きます。以下に例を示しますが、まずホストのグループを作り(例では[web])、その下に、そのグループに参加するサーバのホスト名やIPアドレスなどを記述します。
# inventory.ini - サーバのホスト名・IPアドレス等を記述 [web] example-server ansible_host=163.43.192.***
もう1つはPlaybookです。こちらはどのホストに対して何を行うかを記述します。こちらも例を示しますが、hostsに対象ホスト(グループ名かall)を書き、tasksに操作を書きます。例ではpingという何もしないモジュールを指定していますが、実際には例えばaptで○○というソフトウェアをインストールして……といったことを書いていきます。
# playbook.yml - どのホストに対して何を行うか記述
- hosts:
- all # 対象ホスト web等のグループ名かallを記述 複数指定可能
tasks: # 実際にホスト上で行う操作 複数指定可能
- name: ping task # 操作の名前 実行ログに出る
ping: # 何もしないモジュール
これの実行例は以下のようになります。実行結果の最後のPLAY RECAPの項目を見ると、example-serverに対する操作が2つとも正常に行われたことがわかります。
$ ansible-playbook -i inventory.ini playbook.yml PLAY [all] ************************************************************************************************************************* TASK [Gathering Facts] ************************************************************************************************************* ok: [example-server] TASK [ping task] ******************************************************************************************************************* ok: [example-server] PLAY RECAP ************************************************************************************************************************* example-server :ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Inventoryファイル
Inventoryファイルでは、ホストごとの変数やグループごとの変数を定義できます。変数は設定ファイルに埋め込むことでタスクの動作を変えることができます(詳細は後述します)。以下の例では、
- web-03だけSSHのポート番号を変更
- webグループのすべてのホストについてウェブサーバのポート番号を8080に変更
- db−01がデータベースのマスター、db-02はスレーブ
といったことを変数で定義しています。
[web] web-01 ansible_host=***.***.***.*** web-02 ansible_host=***.***.***.*** web-03 ansible_host=***.***.***.*** ansible_port=10022 [web:vars] http_port = 8080 # webグループの全てのホストに適用される [api] api-01 ansible_host=***.***.***.*** api-02 ansible_host=***.***.***.*** [db] db-01 ansible_host=***.***.***.*** db_master=True db-02 ansible_host=***.***.***.*** db_master=False
タスクでの変数の利用
このようにして定義した変数は、タスクの中で使うことができます。以下の例では、タスク名に変数を渡したり、変数の値がTrueの場合のみタスクを実行するという処理を記述しています。また、templateモジュールを利用することで、設定ファイルに変数を埋め込むことも可能です。
- name: install packages
apt:
name: "{{ package_name }}" # オプションに変数を渡す
- name: install curl
apt:
name: curl
when: "{{ curl_install }}" # Trueの場合のみタスクを実行
Dynamic Inventory
マシンの台数が増えてくると、インベントリ情報をいちいち手で書くのは面倒になります。ここで使えるのがDynamic Inventoryで、実行時にクラウドのAPIからインベントリ情報を収集してくれる便利な仕組みです。具体的には、AWC EC2, GCP GCE等のマシン一覧からインベントリを作成します。例を以下に示しますが、Dynamic Inventoryの実行ファイルを -i オプションで渡すことでこの機能を使うことができます。
$ ansible-playbook -i dynamic-inventory playbook.yml
さくらのクラウド向けのDynamic Inventory
さくらのクラウド向けのDynamic Inventoryもあります。自分で作りました。sacloud-ansible-inventoryというものです。
さくらのクラウドでは各マシンにタグを付けることができるのですが、Ansibleで管理したいマシンに __with_sacloud_inventory タグをセットしておくと、そのタグをもとにAnsibleのグループを作り、マシンが自動的に登録されます。また、サーバの説明文に変数を入れることなどもできます。

上記はさくらのクラウドにおけるサーバの編集画面です。「説明」の項目は、通常は日本語で説明文を書くのですが、ここではJSON形式のデータを入れています。そして、sacloud_inventoryというフィールドの中に書いた情報が、Ansibleで読み取られてInventoryファイルに記録されます。また、タグの欄にweb_serverとあるので、このサーバはInventoryファイルではweb_serverというグループに組み込まれます。(下記参照)
[web_server] example-server-be717a0 ansible_host=***.***.***.*** http_server_port=8080
Pulumi+Ansibleのベストプラクティス
PulumiとAnsibleについて説明したところで、両者を組み合わせて使う方法を紹介します。
まず、Pulumiでサーバタグを設定すると、それをAnsibleでグループとして扱うことができます。以下の例では、まず最初にタグの配列を定義しています。__with_sacloud_inventory はAnsibleで管理してもらうためのタグで、次の 'stack_'+pulumi.getStack() でstack_devかstack_prodが配列に入ります。それから、サーバの説明文に入るJSON文字列もPulumiで作ることができます。以下の例ではWebサーバのポートを8080にする設定を変数で定義していて、これがAnsibleに渡されます。
// ホストの収集対象に設定・stack_dev or stack_prodのグループに追加する
const COMMON_SERVER_TAGS = ['__with_sacloud_inventory', 'stack_' + pulumi.getStack()];
const serverDesc = {
sacloud_inventory: {
hostname_type: 'nic0_ip', // 自動的に ansible_host=***.***.***.*** のように展開
host_vers: {
http_server_port: '8080', // Ansible内で参照する変数を定義
},
},
};
const server = new sakuracloud.Server('web-server-01', {
tags: [...COMMON_SERVER_TAGS, 'web_server'], // タグ
description: JSON.stringify(serverDesc), // 説明文
});
Prometheusでの監視にもさくらのクラウド向けツールを活用
Prometheusで監視を行うときにも、さくらのクラウド向けツールを使うことができます。Prometheusについての詳しい説明は省略しますが、概要としてはこんな感じです。
- Pull型の監視ツール
- exporter(外部ツール)が出力したメトリクスを取得
- 内蔵の時系列DBへ蓄積
- Grafana(外部ツール)等で可視化
Prometheus関連のツールで有名なものの1つにnode_exporterがあります。監視対象のマシンにnode_exporterをインストールして実行すると、そのマシンのメトリクス一覧を外部から取得できるようになるというものです(下記の実行例参照)。
$ ./node_exporter # 0.0.0.0:9100でlisten
$ curl localhost:9100/metrics # HELP node_load1 1m load average. # TYPE node_load1 gauge node_load1 0.7 # HELP node_load15 15m load average. # TYPE node_load15 gauge node_load15 0.53 # HELP node_load5 5m load average. # TYPE node_load5 gauge node_load5 0.69 ........
node_exporterは便利ですが、監視対象が増えるたびに対象ホストのアドレスとポート番号をprometheus.ymlに追加することになり、なかなか面倒です。ここで使えるのがsacloud-prometheus-sdです。これはAPIをたたいてさくらのクラウドから自動的にサーバの情報を収集し、Prometheusの監視対象に追加してくれるツールです。
設定例を以下に示します。ファイル名はconfig.ymlとし、さくらのクラウドのゾーン名や、収集するサーバの情報を記述します。
# config.yml
sacloud_token: ""
sacloud_token_secret: ""
sacloud_zone: "1k1a"
base_tags:
- "__with_sacloud_inventory"
targets:
- service: "node" # Prometheus側に渡すサービス名
ignore_tags: ["sandbox"] # 指定されていれば無視するタグ・複数指定可能
ports: [9100] # exporterが動作しているTCPポート番号・複数指定可能
interface_index: 0 # IPアドレスを取得するNICのIndex番号・デフォルト0
- service: "api-server"
tags: ["api"] # 対象とするタグ・複数指定可能
ports: [3000, 4000]
そしてsacloud-prometheus-sdを実行すると、以下のようなYAMLファイルが生成されます。
# /tmp/sacloud_prometheus_sd_generated.yml
- targets:
- ***.***.***.***:9100
labels:
__meta_sacloud_instances_tags: ',stack_develop,web_server,__with_sacloud_inventory,'
__meta_sacloud_zone: tk1a
hostname: example-server-be717a0
service: node
このYAMLファイルをprometheus.ymlにて指定することで(下記例の最下行参照)、Prometheusの監視対象に追加されます。監視対象が増減してもsacloud-prometheus-sdを再度実行すれば情報が適宜追加/削除されるので、prometheus.ymlを編集しなくてもよくなります。
# prometheus.yml
scrape_configs:
- job_name: 'sacloud'
file_sd_configs:
- refresh_interval: 30s
files:
- /tmp/sacloud_prometheus_sd_generated.yml
まとめ
この記事では、さくらのクラウドと各種ツールを組み合わせると構成管理を省力化できることを紹介しました。具体的には、Pulumiを使って複数台のサーバインフラを楽に管理したり、AnsibleやPrometheusのホスト一覧の管理をPulumiに寄せるといったことです。Pulumiはモダンなプログラミング言語を利用していて、複雑な構成も記述が行いやすいのが良い点だと思います。
また、今回紹介したようなさくらのクラウドのツールを作るために便利なCLIやGoのライブラリがあります。何か日常的に困っているような業務がある方は、このライブラリを使って自動化を試みてはいかがでしょうか。そして、ツールを作成された方は、ぜひ公開していただければうれしいです。