今すぐ使える分散DB「エンハンスドデータベース(TiDB)」のご紹介

この記事は、2021年9月7日(火)に行われたさくらの夕べ Tech Night #4 Onlineでの発表を記事化したものです。
目次
はじめに
この記事では、7月にリリースした、さくらのクラウドで使える機能の1つである「エンハンスドデータベース(TiDB)」というサービスについて紹介します。サービスの紹介に加えて、その裏で使っているTiDBという分散データベースの技術についても簡単に触れようかなと思っています。
分散データベース / NewSQLについて
NewSQLとは

さて、皆さんは「分散データベース」とか、あるいは「NewSQL」とか、そういった単語を耳にすることがあるでしょうか?ということでまずはこのお話をしたいと思います。
NewSQLと呼ばれているものはどういったものかといいますと、SQLをインターフェースとするという特徴を持っていて、データベース(例えばMySQLやPostgreSQLなど)と同じように強い整合性を持ち、トランザクションをサポートしていて、かつ分散データベース(分散型のリレーショナルデータベース(RDBMS))である、というところを特徴とします。
これらの特徴のうち、最初の3つは普通のRDBMSと同じですが、それを分散していい感じに動くようにしたという点が、Newがつく所以かなと思います。
NoSQLとの関係

以前にはNoSQLというものが流行った時期もありました。Noは「Not Only SQL」の略だと言われていますが、例えばMongoDBであったり、Cassandraであったり、Elasticsearchなんかも入るでしょう。SQLではない独自のインターフェース、例えばHTTPのエンドポイントであったりとか、JSONで読み書きができるとか、そういったSQLではないインターフェースを持っています。SQLだとデータベース設計をするのにテーブル構造を決めたりとか、いろいろ大変なことがありますが、NoSQLではそれはなく、JSONに名前を付けて突っ込めるとか、検索ができるとか、そういった簡単さを備えていて、高いパフォーマンスを提供するような分散データベースであって、ただしリレーショナルではない、というようなものですね。
簡単に利用できる一方で、NoSQLはトランザクションには対応しないものが多く、ゆるい整合性(結果整合性=最後に書き込まれたデータが確実に保存される)を持つという特徴のものが多く、多くの製品がKey-Value Store(名前とバリューを紐付けて保存する)のような使い勝手となっています。

でも、使ってみると、やっぱりSQLの方が使いやすい面も多く、開発する上ではRDBMSを使うこともたくさんあります。
今まで通りSQLを使ってリレーショナルなデータベースを使いつつ、でもNoSQLみたいなスケーラビリティとか利便性はやっぱり欲しいよね、と感じるところから出てきたのがNewSQLです。
NewSQLの例

実際に製品として存在するNewSQLはいくつかあります。
例えばプロプライエタリなものとしてサービス提供されているのがGoogleのSpannerですね。これはGoogle Cloud Platformで使えるもので、ソースコードは公開されていませんが、論文とかで情報はオープンになっています。
そして、Spannerの考え方を参考にいろんなソフトウェアが実装されてます。例えばCockroachDBであったりTiDBであったり、あるいはYugaByteDBといったものが作られています。TiDBはMySQL互換のインターフェースを備えていて、CockroachDBとYugaByteDBはPostgreSQL互換のインターフェースを実装しています。
TiDBの仕組み
ここからは、私が普段使っているTiDBの話をしようかなと思います。TiDBを例に、こういった分散RDBMSがどのように動作するのかを、サービスとは関係ないレベルで簡単にご紹介します。
TiDBのコンポーネント
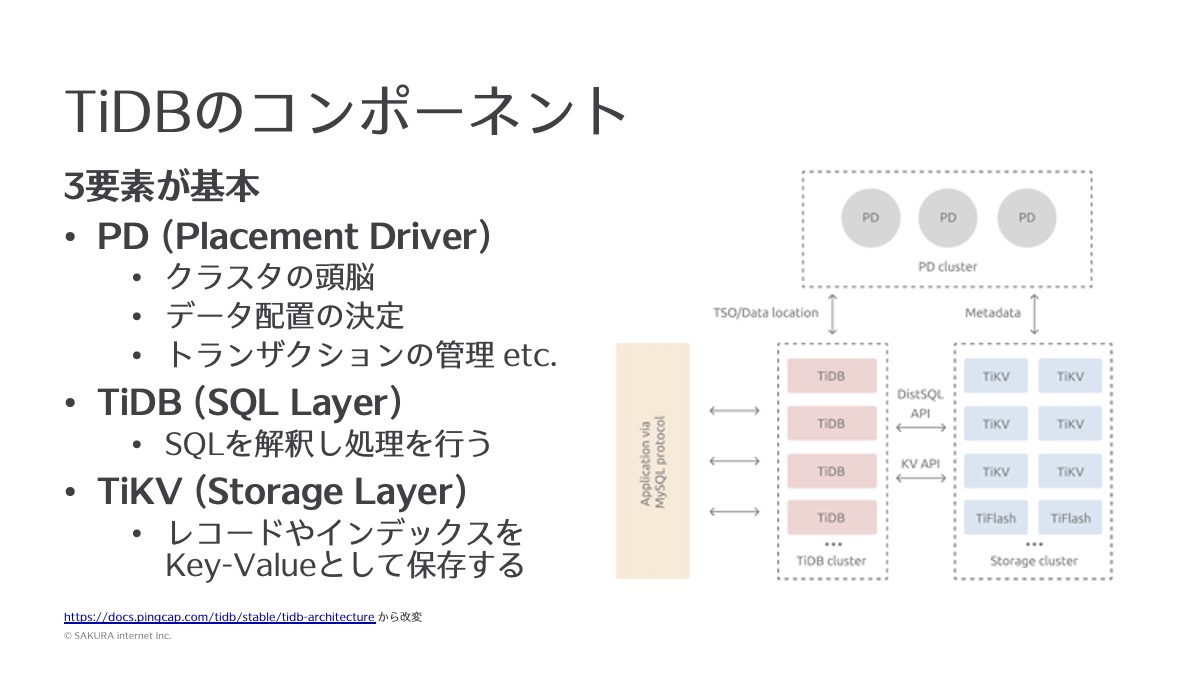
TiDBの場合は、サーバーコンポーネントソフトウェアが基本部分として3種類あります。
PD (Placement Driver)
PDというサーバーが一番中心となって動くコンポーネントになってまして、「クラスタの頭脳」とでもいうべき存在です。
どこにどのデータを配置するか、あるいはトランザクションにおいてトランザクションの開始からデータが変更されたり読まれたりして、最後にコミットするかロールバックするかということを管理する機能を持っており、一番重要な部分になります。
TiDB
2つ目がTiDBです。名前がちょっとややこしく、このシステム全体を「TiDB」ということもあれば、そのうちのコンポーネントの1つのTiDBを指すこともあって、この場合は狭い意味でのTiDBです。TiDBはアプリケーションと通信するSQL互換の部分を担っており、入力されたSQLを解釈し、データを保存したり、SELECTしたり、集計などをして応答するという機能を持っています。
TiKV
最後のーつがTiKVです。これはデータを保管する上で重要な機能を担っており、名前の通り Key-Value Storeとして動作するソフトウェアです。データはすべてここに保存されています。例えばTiDBに入ってきたINSERT文を処理する際には、PDがどこに突っ込むかを決めた上で、TiKVに1行ずつ、Key-Valueとして保存される、ということになります。
例えばノード間のレプリケーションとか、分散しての参照とか、そういったものはすべてこのTiKVのクラスタの中で処理されるようになっています。
テーブルとKey-Valueの関係

データベースの中身をKey-Valueとして保存するというのはどういうことかを少し理解すると、なるほどと思える部分もあるかと思いますので、簡単にご紹介します。
データベースやテーブルの定義はKey-ValueとしてTiKVに格納
まず、CREATE DATABASEやCREATE TABLEをしたときの、データベースやテーブルの定義のようなメタデータは、Key-ValueとしてTiKVにそのまま保存されています。TableIDをキーとして、バリューがそのテーブルの構造みたいな感じですね。
テーブル内の各行は1つのKey-ValueとしてTiKVに格納
その上で、レコードをINSERTするとレコードの1行1行がKey-Valueとして保存されます。キーは「t{TableID}_r{RowID}」という名前で、バリューとしてデータが入る形になります。例えば、テーブル10番のレコード1だったらt10_r1というキー名で、データがIDと氏名と年齢と住所みたいなカラムだったら、それら全てをひとつのバリューとして保存します。
Unique Indexは1つのKey-ValueとしてTiKVに格納
ここで「SELECT * FROM (テーブル名)」とすると、テーブル内のレコードに相当するKey-Valueが全部検索されて、結果が表のように出力されます。しかし、それだけだと常に全件取得することになって大変なので、RDBMSで使われているIndexも使うことができます。
例えばPRIMARY KEYやUNIQUE制約がかかったインデックスはKey-ValueとしてTiKVに保存されており、IndexIDのバリューを含むキーに、そのバリューのRowはこれですよというRowIDがバリューとして入っています。
他のIndexはキーとしてTiKVに格納
UNIQUE制約以外の、重複を許すようなインデックスの場合には、バリューを使わずに、その値のRowIDがありますよというようなキーが保存されています。例えば年齢が10歳から20歳までみたいなものは範囲で指定してごっそり持ってくることができるというような、Indexとしての役割もKey-Valueで実装されています。
このように、保存先はKey-Value Storeなんだけど、TiDBというソフトウェアが間に入ることで、ユーザはRDBMSのように利用することができるという感じになっています。
一般的なRDBMSとの違い
では一般的なRDBMSと何が違うの?というところが重要だと思いますので、簡単にその違いの一部をご紹介します。

上表の赤いところがデメリットで、MySQLやPostgreSQLのような旧来のRDBMSの方が良いところもあれば、TiDBのような分散データベースの方が良いところもあります。
そのため、使い分けをする、あるいは得意なところ・不得意なところを理解した上で使うことが必要になります。
例えばレイテンシ (1つのSQLを発行して、そのSQLが完了するまでにかかる時間) は従来のRDBMSの方が小さい、つまり速いという特徴があります。相対的にはTiDBは1個1個のSQLを処理する時間は大きくなるという特徴があります。これは理由が明らかで、1台のサーバで処理する場合にはローカルのディスクへのアクセスで完了するためすごく速いのですが、分散システムの場合にはバックエンドに複数台いるTiKVにリクエストを投げて、処理が終わったら応答を返すということになるので、ネットワークを利用する分時間がかかります。
一方で、時間あたりに処理できるクエリ数だったり、容量のようなもの、パフォーマンスに関連するところは、旧来のRDBMSだと基本的にサーバのスペックによって確定します。もっと速くしたくなったらもっとコアを積んだサーバに変えるしかないですし、あるいは容量を増やしたくなったらそのサーバのディスク容量を増やすしかない、というようなことが基本的な考え方になります。
しかし、分散RDBMSの場合には、例えばSQLの処理が足りなくなってきたと思ったらTiDBのノードを増やせばいいですし、容量を増やしたいなと思ったりディスクI/Oがネックになってるかなと感じたらTiKVのノードを増やせばいい、というふうな形で、スケールアウトすることができるのがメリットです。
その一方で、スケールアウトできるようにするためにはクラスターを構築しないといけません。旧来のRDBMSだと1台でも動きますし、冗長化するためには最低2台(マスターとレプリケーション)で冗長構成が作れたんですが、TiDBのシステム要件に書いてある本番用途の要求では最低でも合計8台いるということで、最初のハードルが高くなっているという特徴があります。こういったことを理解して使う必要があります。
TiDBのメリット

簡単にTiDBのメリットをまとめます。これは分散システムに一般的に言えるメリットに近いものです。
まずメンテナンス作業が容易なことです。1台のノードですべて処理している場合には、メンテナンスするときにサーバをシャットダウンしようと思うと、フェイルオーバーをして別のサーバに役割を移したりするというような、ごそっとすべての機能を別のサーバに移動するというようなメンテナンスをしないといけないため、手順を誤ったりするとすぐにサービスに影響が起きてしまうこともあり、手順を作るのも大変だったりします。
しかし、TiDBの場合 (TiDBに限らず分散システムでは一般に)、たくさんのノードが常に動いているので、1台止めようが2台止めようが他のノードが正常であれば一部の処理が他のノードに移るという感じで作業ができますのでメンテナンスが容易です。
それと同じく、意図しないノード障害があった場合も、1台のサーバが停止しただけでは処理の何分の1かが別のノードに移るだけなのでサービス影響が小さいというメリットもあります。
容量やパフォーマンスの増減を、ノードの台数を増やしたりすることで構築後に調整できるというのもメリットになります。
さくらインターネットでのTiDBの活用
こういった特徴がありますので、弊社ではここ何年かでいくつかのシステムにTiDB (あるいはTiKV) を活用しています。

例えば、sakura.ioという、携帯電話回線を使ったIoTプラットフォームのサービスでは、データを保存する「データストア(V2)」というサービスでTiKVを採用しており、端末から来たデータの蓄積や計算に使っています。
あと、TiDBそのものも、さくらのクラウドのLabプロダクトの一部、最近開発しているものでは管理システムに採用しています。
これまでならMySQLなどに保存していた設定情報とか契約情報のデータをTiDBに入れて運用している実績があります。
さくらのクラウド エンハンスドデータベース (TiDB)
このTiDB、あるいはNewSQLは、すごく便利なんですが、最初から8台必要であったり、構築面倒であったり、少し使うだけにしてはいろいろ不便なところがあります。
だったらすぐに使えるようにしようと、さくらのクラウド上にパブリックサービスにしてご提供させていただくことになりました。
それがさくらのクラウドの「エンハンスドデータベース (TiDB)」です。

なぜサービスにしたかと言いますと、本来であれば自分でクラスタを構築する必要があるのですが、自分でクラスタを作らなくても、この分散システムの利便性を感じてほしいなと思っているからです。
使い方は簡単で、さくらのクラウドにログインして、新しく作るデータベース名と接続パスワードを決めて作成すると、すぐにTiDBの上で作成されたデータベースを利用することができるようになっています。
データベースの作成

これはデータベースの作成画面です。データベース名と種類と、今は石狩リージョンしか選べませんが地域と、あとは同時接続数のプランを設定します。現在はβ版で無料でご利用いただけまして、50コネクション同時に使えるプランだけをご提供しております。
これらを決めて作成ボタンを押すと即座にデータベースが作成され、利用が可能になります。
情報の確認
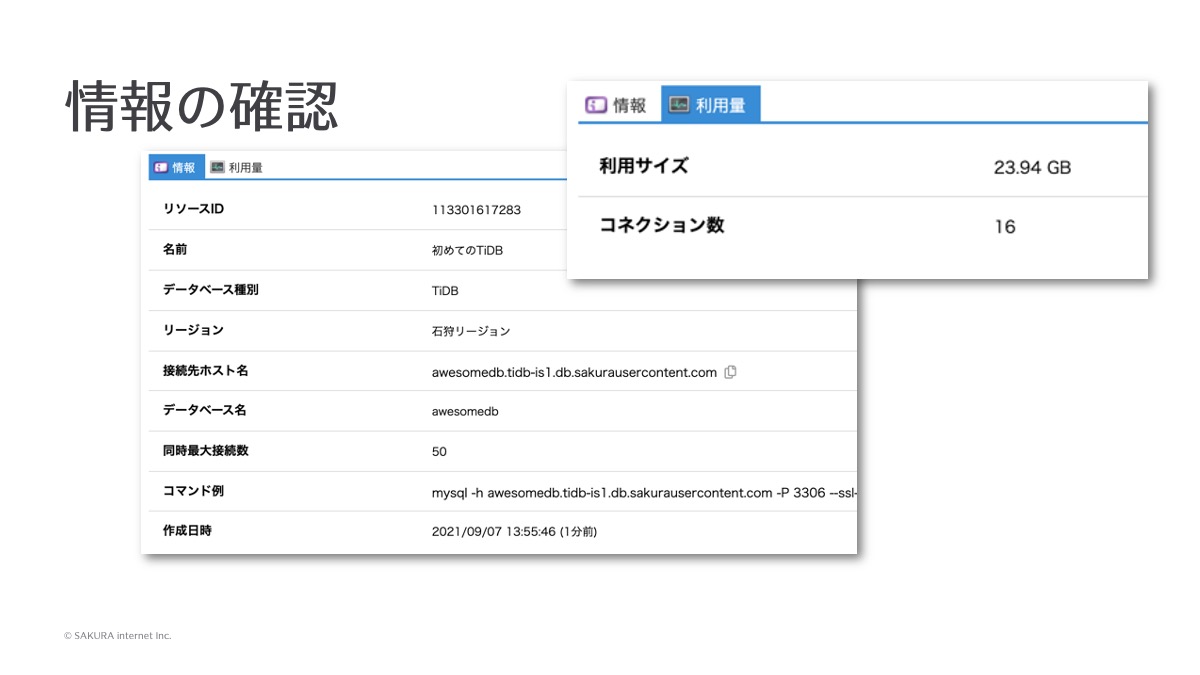
作成後の情報確認画面がこちらです。
接続先のホスト名やポート番号も表示されますので、コマンド例の行に表示されているようにMySQLクライアントで接続していただくという感じになります。また、現在保管されているデータの量や、同時に接続されているコネクション数なども見られるようになっています。
TiDBへの接続
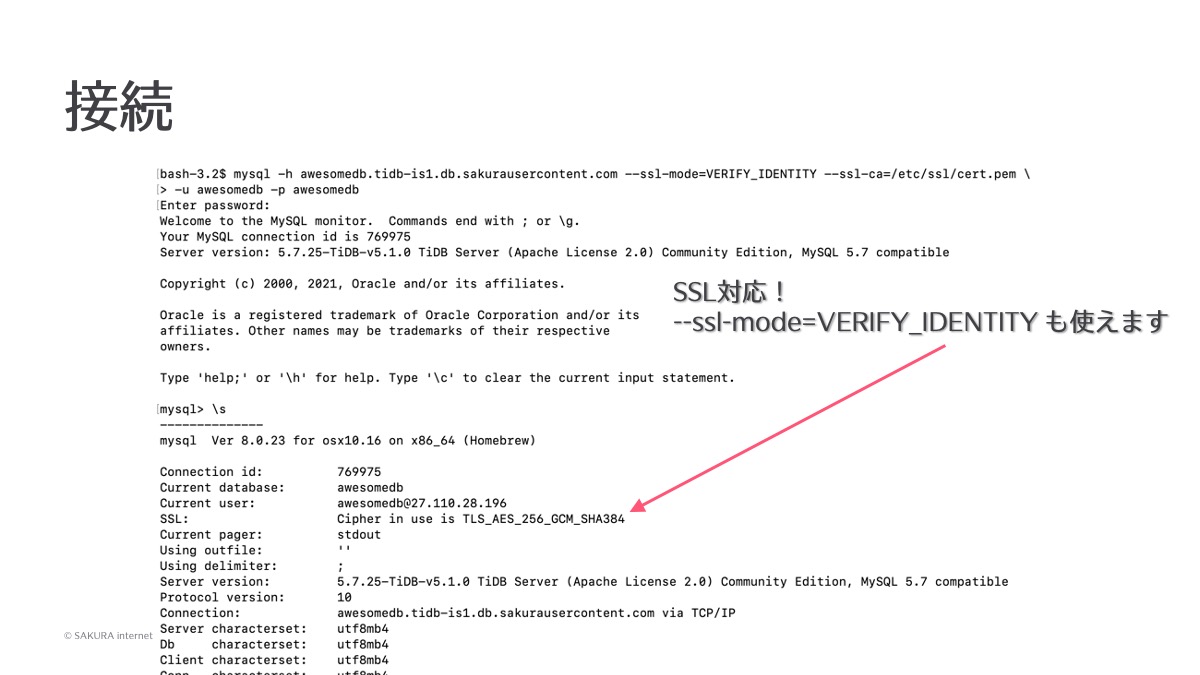
実際に接続するときはMySQLコマンドでそのまま接続することができます。インターネット越しに接続するものですのでSSLにも対応しており、TLSで暗号化された状態でデータベースに接続することができます。
エンハンスドDBのメリット

すぐに使える
このサービスのメリットは、すぐに使えることです。データベースアプライアンスなどを作るとどうしてもサーバーの起動なりアップデートなりで時間がかかりますが、このサービスなら作成ボタンを押して5秒で利用を開始することができます。
容量を気にせず利用できる
容量を気にせずに利用できます。サーバのディスクを20GBで作ろうかな、40GBで作ろうかな、あとで増えたら困るから100GBにしとこうかな、みたいなことを考えなくてもよくて、とりあえず作ればすぐに使えます。
課金は使用量に応じて課金するつもりで考えていますので、最初から大きなディスクを用意しなくていいというのが大きなメリットだと思います。
スペックを意識せずに利用できる
それから、スペックも、作った後で2コアにしておいた方がよかったとか4コアにしておいた方がよかったみたいなことを考えなくてもいいように、同時接続数を後からプランとして増減できるようにしようと思っています。ですので、リクエスト数が増えてきたので同時接続数を増やさないといけないと思ったら、プラン変更だけをしていただければそのまま利用が継続できる、というような利便性を提供できればと思っています。
あとは、アップグレードだったり、ノード障害を意識しなくていいというのも良い特徴かなと思います。
自分でもエンハンスドDBを使ってみた
実際に私自身が1ユーザーとしてこのサービスを使って作ったものをいくつかご紹介します。
Slack Botのデータベースとして
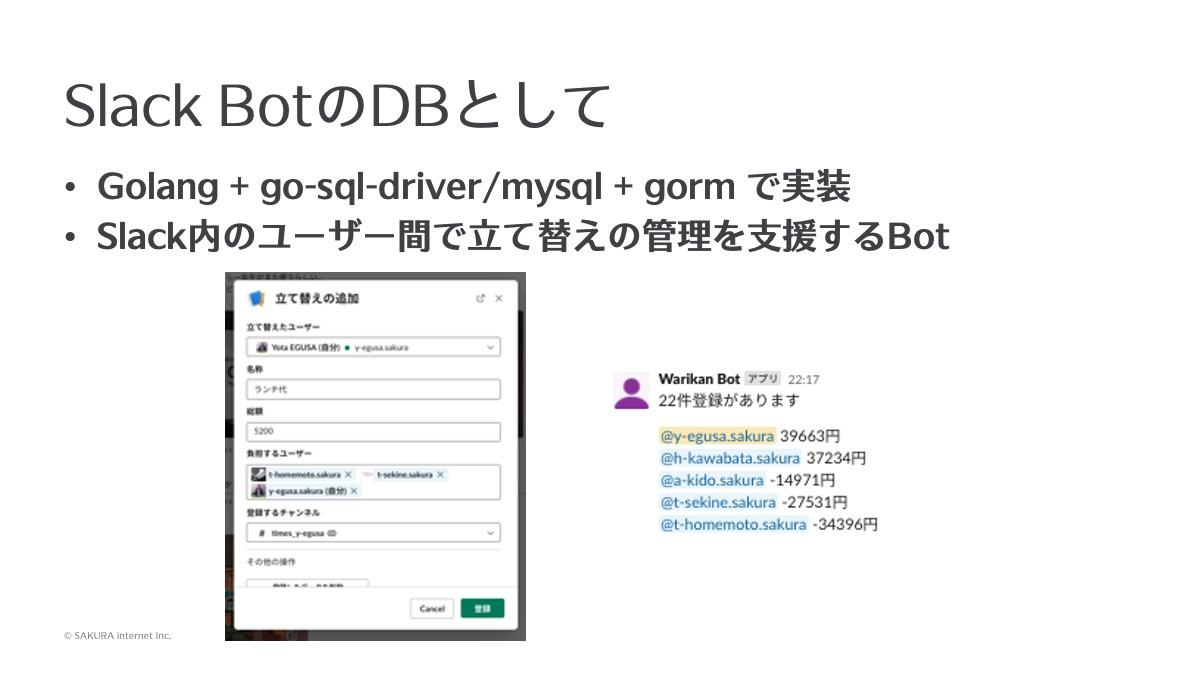
1つ目は、Slackのbotのバックエンドデータベースとして使っています。これはGoとgo-sql-driver/mysqlとgormで実装したもので、Slackユーザー間で立替の計算や割り勘の計算ができるというbotです。裏でTiDBが動いていますが、これもデータベースを作成したらすぐに使えるので、すごく便利に活用しています。
ウェブアプリケーションのデータベースとして
もう1つは、よくある使い方だと思いますが、ウェブアプリケーションのデータベースとしても実際に使っています。ひなたん写真館「フィルムデジタル化サービス」という、私がプライベートで作っているサービスですが、PythonとDjangoで実装しています。
手元ではSQLiteで開発し、実環境ではTiDBで動かしています。
Hacobuneとの利用
また、これはエンハンスドDBとは関係ないのですが、先日「Hacobune」という、コンテナを使ったPaaSサービスを弊社で提供開始しました。先ほど紹介した2つのサービスはHacobuneの上で動いてまして、データベースもマネージド、動いているソフトウェアのサーバもHacobuneでマネージド、という構成になっています。開発してDockerイメージだけを作れば簡単にインターネットで提供できるので、すごく簡単にアプリケーションが実装できるようになってきています。
インターネットサービスのデータベースとしてご活用を
エンハンスドDBは、現在はβ版で無料でご利用いただけます。まずはMySQLクライアントでつなぐだけでも結構ですので、ぜひ使ってみてください。コントロールパネルにログインして、データベースを作ってみて、CREATE TABLEとかSHOW TABLEとかたたいて、ちゃんと動いてることを実感していただいて、ぜひ実際に使ってみていただければと思います。