Whisperを使ったリアルタイム音声認識と字幕描画方法の紹介


こんにちは、テリーです。2023年1月に急速に認知度が高まったAI、ChatGPTはご存知ですか? 世界中の人間の言葉を理解し、質問に答え、翻訳もします。人間の言葉だけではなく、プログラミング言語も理解して、プログラムを書くこともできつつあります。大学入試レベルの問題が解ける、みたいなウワサ話も聞いています。スゴイですね。
さて、そんなにスゴイAI、自分の専門分野で利用したいと思いませんか? 営業職ならば新規のお客さんの開拓方法の提案をして欲しいし、サポートセンター職ならお客さんのトラブル原因候補の一覧を出して欲しいし、エンジニア職ならば粗い仕様書から雛形のプログラム案を作って欲しいでしょう。
ライブ配信でもたくさんの活用方法が考えられます。ChatGPTにライブ配信の活用方法を質問してみました。
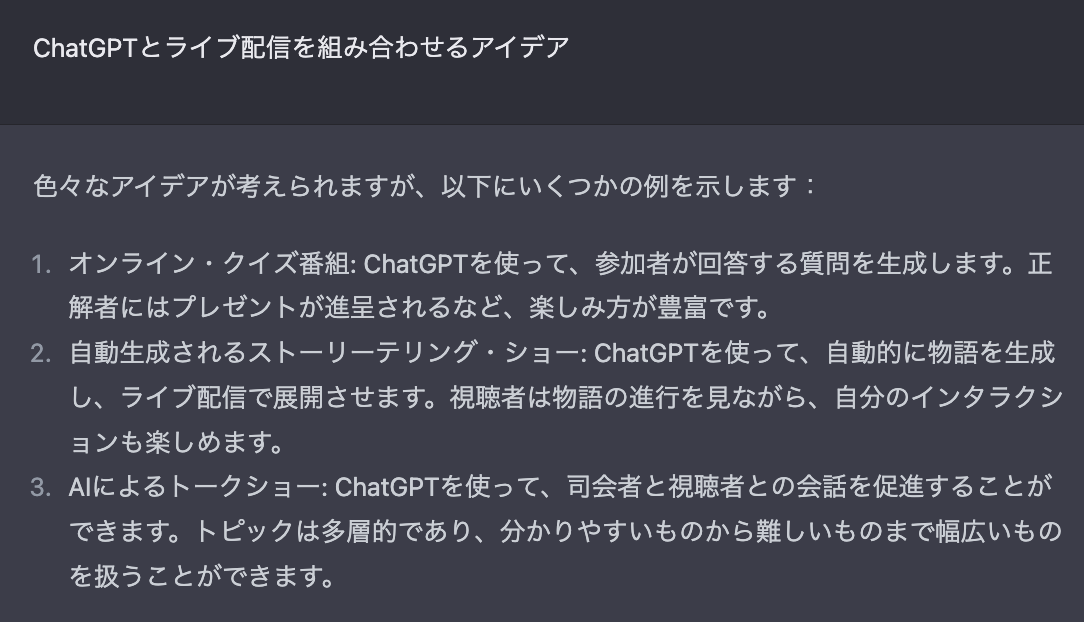
スゴイ。さすがアイデアの宝庫です。
ここであることに気づきました。ChatGPTは入力も出力も文字列であるということです。ライブ配信の場合、演者はカメラに向かって画面を見て話をするので、キーボードを押さずにChatGPTとやりとりして、ChatGPTの返答もライブ配信で流せるといいですね。
そのためには、音声認識(文字起こし)と字幕描画と音声合成が必要です。マイクで録音した音声をリアルタイムで文字列に変換して、それをChatGPTに投げることができれば、「AIと会話する動画」「動画の中で生きているAI」に近づくことになります。
音声認識の字幕描画は簡単そうに見えるかもしれませんが、ライブ配信特有の問題があります。それは「文の区切り、終わりがわからない」と言うことです。一画面に100文字表示しているテロップを見たことはありませんよね。収録しているマイクが無音になるまでのすべての文字を表示しようとすると、場合によっては100文字を超えます。長すぎる文章の字幕は視聴者が読めないのです。テレビのクイズ番組では、視聴者が一目でギリギリ読める長さの文字数で問題を作成しています。ニコニコ動画では、チャット文字列を横スクロールして表示しています。abemaニュースでは、文字起こしは「補助的なもの」と割り切って、長い文の後半のみ表示しています。
前置きが長くなりましたが、今回は、ChatGPTをライブ配信に活用することを意識して、文字列をライブ配信映像の中に登場させる「字幕描画」のサンプル実装を紹介したいと思います。映像の中に字幕を埋め込む方法は何通りもありますが、今回はOBS-WebSocketを使った方法をご紹介します。
動作環境
本記事は以下のバージョンを用いて動作を確認しています。
- MacBook Pro (14-inch, 2021) M1 Max
- macOS Ventura 13.1
- OBS Studio 29.0.2
- Python 3.9.6
- Whisper v20230124
- ONNX Runtime Web 1.13.1
ブラウザソースの追加
まず、字幕を表示するブラウザソースを追加します。OBS画面下部左から2番目の「ソース」欄の「+」ボタンを押して、出てきたメニューから「ブラウザ」を選択して下さい。
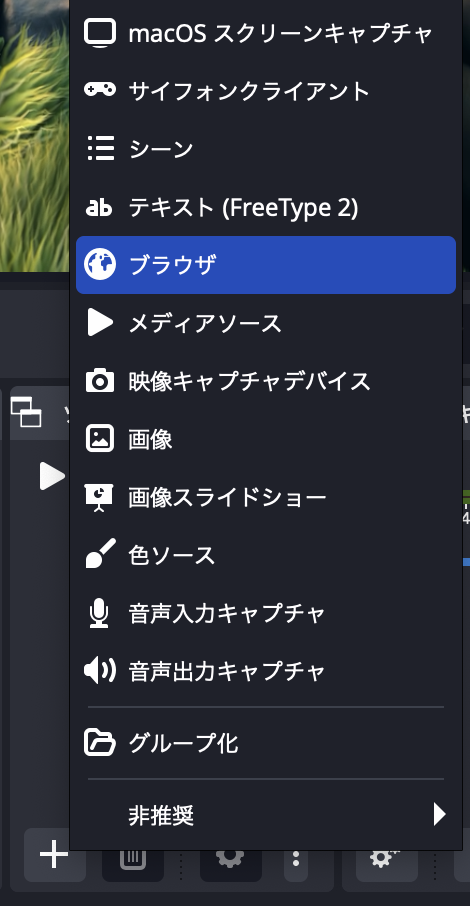
次に出てきたダイアログの新規作成の欄に「音声認識の字幕」と入力します。ここで入力した値は後述のプログラムで定数として使用しますので、お好みで変更して読み替えて下さい。
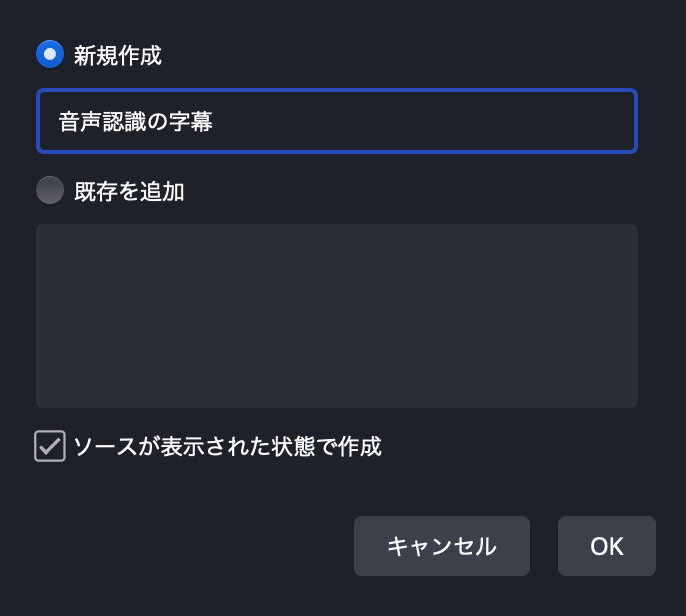
次に出てきたダイアログで、下記の項目を設定をします。
- ローカルファイル: チェックオン
- ローカルファイル名: 中身が空のファイルを作成して指定する
- 幅: キャンバスの横幅のピクセル数
- 高さ: キャンバスの高さのピクセル数
次に位置合わせです。ブラウザソースをキャンバスサイズにしたので、キャンバスにフィットさせるだけです。今回作成した「音声認識の字幕」を右クリックし、出てきたメニューから「変換」-「変換をリセット」をクリックします。

OBS WebSocketの設定
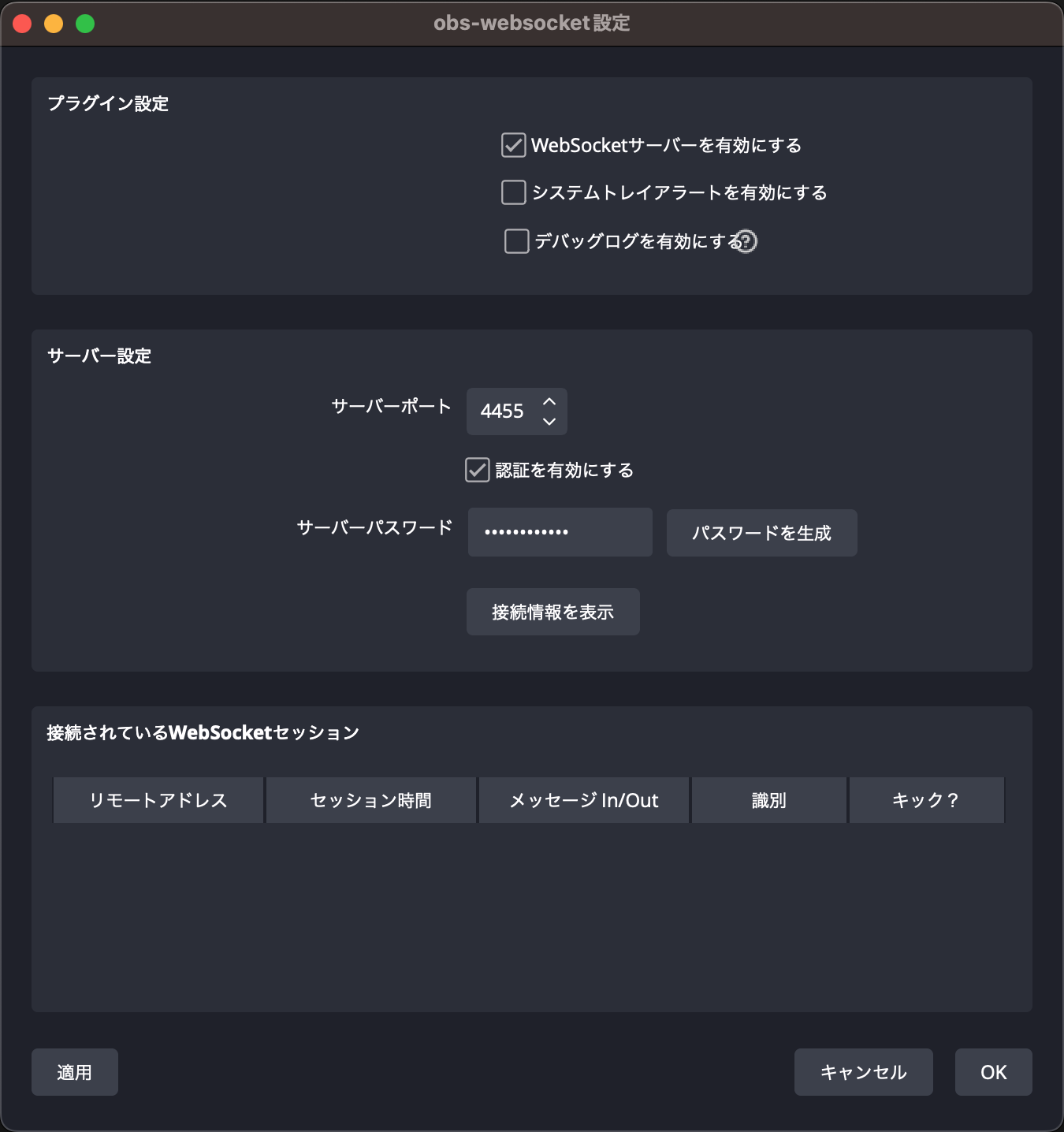
OBSのWebSocket機能を有効にします。WebSocket機能は比較的新しい機能で、使ったことがない方も多いと思います。LAN内のコンピュータからOBSの各種プロパティを取得・変更できます。各種プログラミング言語から直接APIを呼べるので、「音声認識の結果を即時に画面に反映する」ような、頻繁に変更される値の更新に適しています。
設定方法は、OBSのメニューから「ツール」-「obs-websocket設定」をクリックし、出てきたダイアログの一番上のチェックボックス「WebSocketサーバーを有効にする」をオンにします。そして「パスワードを生成する」を押します。後述のプログラムで定数として使用します。これでWebSocket機能を使用できるようになります。
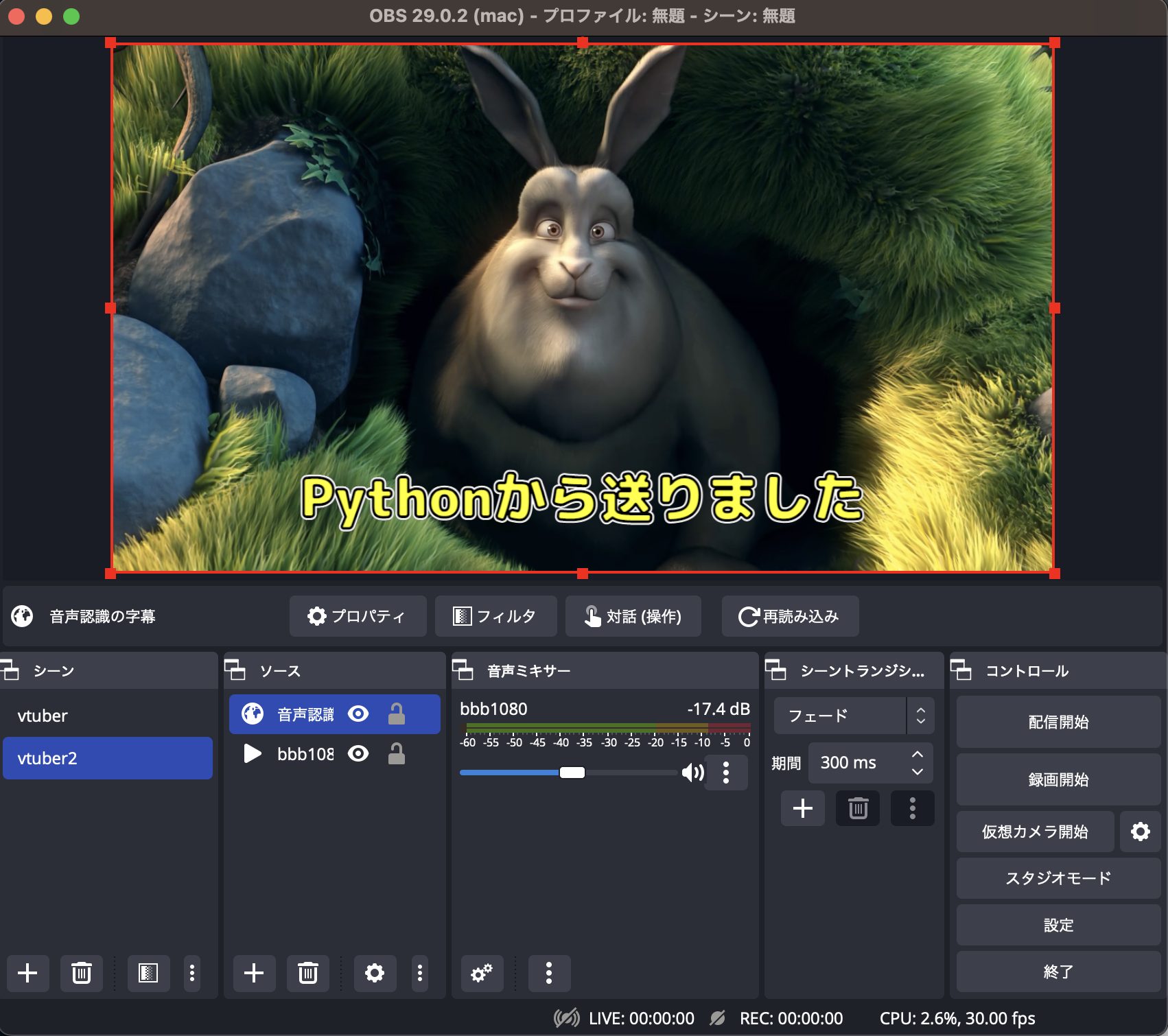
Pythonのプログラムから字幕変更
PythonのプログラムからOBSにWebSocketで接続し、簡単な字幕データを送ってみましょう。
必要なライブラリはA Python SDK for OBS Studio WebSocket v5.0です。下記のコマンドを実行してインストールします。
pip3 install obsws-python字幕を描画するためのcssファイルをテンプレートとして用意します。後述するpythonのプログラムから参照しやすいディレクトリに配置して下さい。ここでは static/jimaku.css というファイル名にします。
1. @import url('https://fonts.googleapis.com/css2?family=M+PLUS+Rounded+1c:wght@900&display=swap');
2.
3. body {
4. margin: 0;
5. padding: 0;
6. border: 0;
7. display: flex;
8. flex-wrap: wrap;
9. justify-content: center;
10. align-items: flex-end;
11. align-content: flex-end;
12. overflow: hidden;
13. margin: 5vh 5vw;
14. font-family: 'M PLUS Rounded 1c', sans-serif;
15. font-size: 10vh;
16. line-height: 1.1em;
17. text-align: center;
18. position: relative;
19. }
20.
21. body::before {
22. content: attr(data-text);
23. position: absolute;
24. color: #FF0;
25. -webkit-text-stroke: 0.5vh #000;
26. z-index: 30;
27. }
28.
29. body::after {
30. content: attr(data-text);
31. position: absolute;
32. color: #FFF;
33. -webkit-text-stroke: 1.0vh #FFF;
34. z-index: 20;
35. }次に下記のPythonプログラムをテキストエディタで作成し、実行します。
1. import obsws_python as obs
2. import re
3. OBS_PASSWORD = 'mystrongpass'
4. TARGET_SOURCE_NAME = '音声認識の字幕'
5. CSS_TEMPLATE_PATH = 'static/jimaku.css'
6. with open(CSS_TEMPLATE_PATH) as f:
7. CSS_TEMPLATE = f.read()
8. def send_jimaku(text):
9. css = re.sub(' content: .*;', ' content: "' + text + '";', CSS_TEMPLATE)
10. obscl.set_input_settings(TARGET_SOURCE_NAME, {'css': css}, True)
11. obscl = obs.ReqClient(host='localhost', port=4455, password=OBS_PASSWORD)
12. send_jimaku('Pythonから送りました')3行目の定数OBS_PASSWORDは、OBS WebSocketのダイアログで設定したパスワードに読み替えて下さい。
4行目の定数TARGET_SOURCE_NAMEは、OBSに追加したブラウザソースの名前です。
5行目は上述のCSSテンプレートのファイル名です。
9行目はテンプレートの文字を置き換えています。contentの前にスペースを一つ入れているのは、justify-contentにマッチしないようにするためです。
11行目でPythonプログラムからOBSに接続し、10行目で上書きしたいプロパティ"css"を送信しています。
音声認識APIの作成
自作のプログラムから文字を送ってOBSに表示ができることが確認できたら、次は音声認識のプログラムを作成します。音声認識にはChatGPTを開発したOpenAI社が公開しているWhisperというライブラリを使用します。下記のコマンドでWhisperをインストールします。また、whisperは内部でffmpegコマンドを使用するので、ffmpegにPATHを通すか、カレントフォルダに配置します。
pip3 install openai-whisperまた、音声認識をWebAPIの形でデータを受け付けるように、Webアプリフレームワークで有名なFlaskを使用します。これはmultipart/form-dataを正しく受け取るためだけのライブラリなので、他の類似実装でも問題ありません。SimpleHTTPRequestHandlerでも実装してみましたが、行数が長くなり本記事の主題と離れるためFlaskで説明します。
pip install flask下記のPythonプログラムをテキストエディタで作成します。ファイル名はwhisper_server.pyとしましょう。
1. import os
2. import time
3. from flask import Flask, jsonify, request, redirect
4. import whisper
5. import obsws_python as obs
6. import re
7. import threading
8.
9. UPLOAD_FOLDER = 'uploads'
10. ALLOWED_EXTENSIONS = {'m4a','mp3','wav'}
11. OBS_PASSWORD = 'mystrongpass'
12. TARGET_SOURCE_NAME = '音声認識の字幕'
13. CSS_TEMPLATE_PATH = 'static/jimaku.css'
14. WHISPER_MODEL_NAME = 'small' # tiny, base, small, medium
15. WHISPER_DEVICE = 'cpu' # cpu, cuda
16.
17. with open(CSS_TEMPLATE_PATH) as f:
18. CSS_TEMPLATE = f.read()
19.
20. def send_jimaku(text):
21. css = re.sub(' content: .*;', ' content: "' + text + '";', CSS_TEMPLATE)
22. try:
23. obscl.set_input_settings(TARGET_SOURCE_NAME, {'css': css}, True)
24. except Exception as e:
25. print(e)
26.
27. print("connecting obs-websocket")
28. try:
29. obscl = obs.ReqClient(host='localhost', port=4455, password=OBS_PASSWORD)
30. send_jimaku('')
31. except Exception as e:
32. print(e)
33.
34. print('loading whisper model', WHISPER_MODEL_NAME, WHISPER_DEVICE)
35. whisper_model = whisper.load_model(WHISPER_MODEL_NAME, device=WHISPER_DEVICE)
36.
37. os.makedirs(UPLOAD_FOLDER, exist_ok=True)
38. app = Flask(__name__, static_url_path='/')
39. app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
40.
41. lock = threading.Lock()
42.
43. @app.route('/')
44. def index():
45. return redirect('/index.html')
46.
47. @app.route('/api/transcribe', methods=['POST'])
48. def transcribe():
49. time_sta = time.perf_counter()
50. print('start transcribe ' + str(time_sta))
51. file = request.files['file']
52. ext = file.filename.rsplit('.', 1)[1].lower()
53. if ext and ext in ALLOWED_EXTENSIONS:
54. filename = str(int(time.time())) + '.' + ext
55. saved_filename = os.path.join(app.config['UPLOAD_FOLDER'], filename)
56. file.save(saved_filename)
57. lock.acquire()
58. result = whisper_model.transcribe(saved_filename, fp16=False, language='ja')
59. lock.release()
60. print('time='+ str(time.perf_counter() - time_sta))
61. print(result)
62. send_jimaku(result['text'])
63. return result, 200
64.
65. result={'error':'something wrong'}
66. print(result)
67. return result, 400
68.
69. app.run(host='localhost', port=9000)主要箇所を解説します。
11. OBS_PASSWORD = 'mystrongpass'
12. TARGET_SOURCE_NAME = '音声認識の字幕'
13. CSS_TEMPLATE_PATH = 'static/jimaku.css'11行目は、上述のOBS WebSocketで設定したパスワードです。
12行目は、上述のOBSに追加したブラウザソースの名前です。このブラウザソースに対してプロパティ変更を行います。
13行目は、上述のcssファイル名です。テンプレートとして使用します。
14. WHISPER_MODEL_NAME = 'small' # tiny, base, small, medium
15. WHISPER_DEVICE = 'cpu' # cpu, cuda14行目は、Whisperが使用する音声認識のモデルデータ名です。tiny, base, small, medium, large の中から選びます。大きいものほど精度は良いですが、処理時間、メモリ使用量ともに倍々に増えていきます。リアルタイム用途の場合、baseまたはsmallが良さそうです。tiny,baseは漢字変換のミスがかなり多く、実質使えません。リアルタイムで処理するためには、入力音声の秒数よりも認識速度にかかる時間が短い必要があります。5秒の音声の処理を5秒未満で終わらないと、遅れが積み重なっていきます。
15行目は、AIの計算処理をCPUで行うか、GPUで行うかの指定です。本記事執筆時点では、MacではGPUが使えません。WindowsではCUDAを適切にインストールし、CUDA対応のPyTorchをインストールすれば動作します。CUDAを使用する場合、処理速度は期待通り速くなりますが、GPUのメモリ不足のエラーがでがちなので、メモリの少ないGPUを使用する場合は、12行目のmodelを1つ下げる必要があり、「処理は速くなったが、認識精度は悪くなった」という期待ハズレな結果になります。
35. whisper_model = whisper.load_model(WHISPER_MODEL_NAME, device=WHISPER_DEVICE)35行目は、モデルデータをメモリに読み込みます。初めてwhisperを使用する場合は、ネットからモデルデータ(数百MB)をダウンロードしますので、気長に数十秒〜数分待つ必要があります。
47. @app.route('/api/transcribe', methods=['POST'])
48. def transcribe():47行目は、Flask固有の文法です。http://localhost:9000/api/transcribe にPOSTした場合にこの関数が呼ばれ、multipart/form-dataは内部で自動的に処理されます。
51. file = request.files['file']
52. ext = file.filename.rsplit('.', 1)[1].lower()
53. if ext and ext in ALLOWED_EXTENSIONS:
54. filename = str(int(time.time())) + '.' + ext
55. saved_filename = os.path.join(app.config['UPLOAD_FOLDER'], filename)
56. file.save(saved_filename)51行目で、"file"というキーで送ったバイナリファイルを受け取ります。
52-53行目で拡張子をチェックします。
54-56行目では、WebAPIとして受け取ったオーディオファイルをuploadsフォルダに別名で保存しています。拡張子のみ、元のファイルを参照しています。
57. lock.acquire()
58. result = whisper_model.transcribe(saved_filename, fp16=False, language='ja')
59. lock.release()
60. print('time='+ str(time.perf_counter() - time_sta))
61. print(result)
62. send_jimaku(result['text'])
63. return result, 20058行目で、Whisperに音声認識を実行させます。transcribe関数は認識のみ、translate関数は翻訳までしてくれますが、本記事とは関係ないので省略します。引数 "fp16=False" はCPUで処理する場合の決まり文句です。指定しないと毎回警告文がログに出るので、指定しています。引数 "language='ja'" は入力音声の言語が確定している場合に指定します。これを指定しない場合、音声認識の前に言語特定の処理が追加で行われるため、トータルの処理時間が長くなります。
57,59行目で、ロックをして、複数の音声認識処理が同時に実行されないようにしています
62行目で、OBSに音声認識結果を送信しています。
63行目で、whisperの戻り値をjson形式で返信します。
音声録音Webページの作成
音声認識WebAPIができたら、次は音声録音Webページを作成し、ブラウザ上で録音とAPI呼び出しを行います。録音と音声認識を一つのプログラムにしていない理由は、音声認識を高性能マシンで行い、録音は性能の高くないLAN内/LAN外のスマホやタブレットで行うことを視野に入れているからです。
下記のhtmlをテキストエディタで作成します。ファイル名はstatic/index.html です。whisper_server.pyと同じフォルダにstaticフォルダを作成し、その中にindex.htmlを作成します。
1. <meta charset="UTF-8" />
2. <title>Jimaku</title>
3. <script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.13.1/dist/ort.js"></script>
4. <script src="https://cdn.jsdelivr.net/npm/@ricky0123/vad/dist/index.browser.js"></script>
5. <script type="module">
6. try {
7. const myvad = await vad.MicVAD.new({
8. positiveSpeechThreshold: 0.8,
9. negativeSpeechThreshold: 0.8 - 0.15,
10. minSpeechFrames: 5,
11. preSpeechPadFrames: 1,
12. redemptionFrames: 1,
13. onSpeechEnd: async (arr) => {
14. const wavBuffer = vad.utils.encodeWAV(arr)
15. var file = new File([wavBuffer], `file${Date.now()}.wav`)
16. let formData = new FormData()
17. formData.append("file", file)
18. try {
19. const resp = await fetch("/api/transcribe", {
20. method: "POST",
21. body: formData,
22. })
23. const resp2 = await resp.json()
24. console.log(resp2.text)
25. const result_text = resp2.text;
26. const text = document.body;
27. text.setAttribute("data-text", result_text)
28. } catch (err) {
29. console.log(err)
30. }
31. },
32. })
33. myvad.start()
34. } catch (e) {
35. console.error("Failed:", e)
36. }
37. </script>
38. <link rel='stylesheet' href='jimaku.css'>
39. <style>
40. body {
41. background-color: lime;
42. }
43. </style>主要箇所を解説します。
3. <script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.13.1/dist/ort.js"></script>
4. <script src="https://cdn.jsdelivr.net/npm/@ricky0123/vad/dist/index.browser.js"></script>3-4行目で見慣れないライブラリを読み込んでいます。これはVAD(Voice Activity Detection)という技術で、マイク音声のうち、人間の声の区間の始まりと終わりを検出します。ファンやキーボードの音などのノイズや環境音は無視してくれるので、Whisperの認識精度が格段に高まります。Whisperに限らず、音声認識処理に直接マイクの音を流し込むと、ファンの音やキーボードの音を認識しようとして、日本語としてありえない出力が出ることがあります。VADにより「人間の声の可能性が高い」こと自体をAIで判定します。本記事では、Silero VADをブラウザで動くようにした、ricky0123/VADを使用しています。
7. const myvad = await vad.MicVAD.new({
8. positiveSpeechThreshold: 0.8,
9. negativeSpeechThreshold: 0.8 - 0.15,
10. minSpeechFrames: 5,
11. preSpeechPadFrames: 1,
12. redemptionFrames: 1,
13. onSpeechEnd: async (arr) => {
14. const wavBuffer = vad.utils.encodeWAV(arr)7-12, 33行目はVADのプログラムを読み込んで、マイク入力を開始します。このオプションの最適値はまだ試行錯誤中です。一人で語る用途と、複数人で対話する場合で変わってきます。一人で話す場合、必ず息継ぎの無音区間が発生するので、比較的きれいに文が切り取れます。
13行目は、無音区間を検出して、一つの文章が途切れた時に発生するイベントです。
14行目で、その連続音声区間をwavファイル形式でメモリ上に出力します。
15. var file = new File([wavBuffer], `file${Date.now()}.wav`)
16. let formData = new FormData()
17. formData.append("file", file)
18. try {
19. const resp = await fetch("/api/transcribe", {
20. method: "POST",
21. body: formData,
22. })
23. const resp2 = await resp.json()
24. console.log(resp2.text)
25. const result_text = resp2.text;
26. const text = document.body;
27. text.setAttribute("data-text", result_text)15行目から23行目で、multipart/form-dataで音声ファイルを添付して、音声認識APIを呼び出しています。
26-27行目でbodyタグのdata-text属性に値を書き込み、フォントの描画処理をcssに任せています。
下記の画像は本プログラムの実行例です。

実行
最後にpythonプログラムを実行します。
python3 whisper_server.pyエラーなくpythonが実行されているのを確認し、ブラウザで http://localhost:9000/ を開きます。最初は緑色の長方形だけが出ます。マイクのアクセス許可ダイアログが出たら許可を押します。一言「こんにちは」と話しかけると、python側のログを見て、処理されている様子を確認します。下記のようなログが出ていれば成功です。ブラウザ画面とOBSでそれぞれ「こんにちは」の字幕が出ていることでしょう。

最後に僕が撮影したサンプル動画をお見せしましょう。
このようにしゃべっています。「こんにちは、テリヤキです。今日は字幕を入れてみました。ChatGPTで有名な会社が開発したWhisperと言う音声認識ライブラリを使って文字起こしをしています。どうですか? 字幕は正しく表示できてますか? チャンネル登録と高評価よろしくお願いします」
まとめ
音声認識ライブラリWhisperをWebAPI化し、ブラウザのマイクで録音した音声を文字起こししてOBS内で字幕描画する方法を紹介しました。Whisperの音声認識はリアルタイム用途ではまだ速度と精度のバランスがよくないですが、それが解決するのは時間の問題でしょう。本記事のテーマである字幕の動的変更とChatGPTのAPIを組み合わせると、クイズやトークなどをライブ配信することができそうです。ぜひ挑戦してみて下さい。
