さくらのクラウド高火力プランを使って大規模言語モデル(LLM)を動かしてみよう 〜後編〜


この記事は、2023年6月17日(土)に行われたオープンソースカンファレンス 2023 Online/Hokkaidoにおける発表を編集部にて記事化したものです。
前編のあらまし
さくらインターネットの芦野です。
前編の記事では、さくらのクラウド高火力プランの概要や事例、それから大規模言語モデル(LLM)の概要や主な実装をご紹介しました。それに続く本記事では、さくらのクラウドでLLMを動かす方法の解説や、LLMを使って実装したチャットボットのデモなどをご紹介します。
さくらのクラウドで大規模言語モデルを動かすための手順
それでは、さくらのクラウドで大規模言語モデルを動かすための手順の説明に入っていきたいと思います。今回は先ほどもご紹介しました、サイバーエージェント社が公開しているOpenCALMを動かしてみます。OpenCALMは、私が知る限りでは数少ない日本語大規模言語モデルの一つで、公開されている中では唯一なのかなと思ってたりしております。Hugging Faceという、機械学習のモデルを公開・共有できるプラットフォームにて公開されております。
手順を説明する前に、さくらのクラウドをあまり使ったことがない方は、「さくらのクラウド超入門チュートリアル」という記事がありますので、こちらを必要に応じてご覧ください。
では具体的な手順を説明します。まずさくらのクラウドを使うにあたって、さくらインターネットの会員IDというものを取得していただきます。その後にさくらのクラウドのアカウントというものを作成しますと、さくらのクラウドが利用いただけるようになります。弊社のウェブサイトにご利用の流れが出ておりますので、利用される際はぜひこちらのリンクをご覧ください。
会員IDを取得しますと、さくらのクラウドにログインできますので、こちらの画面からログインをしていただきます。
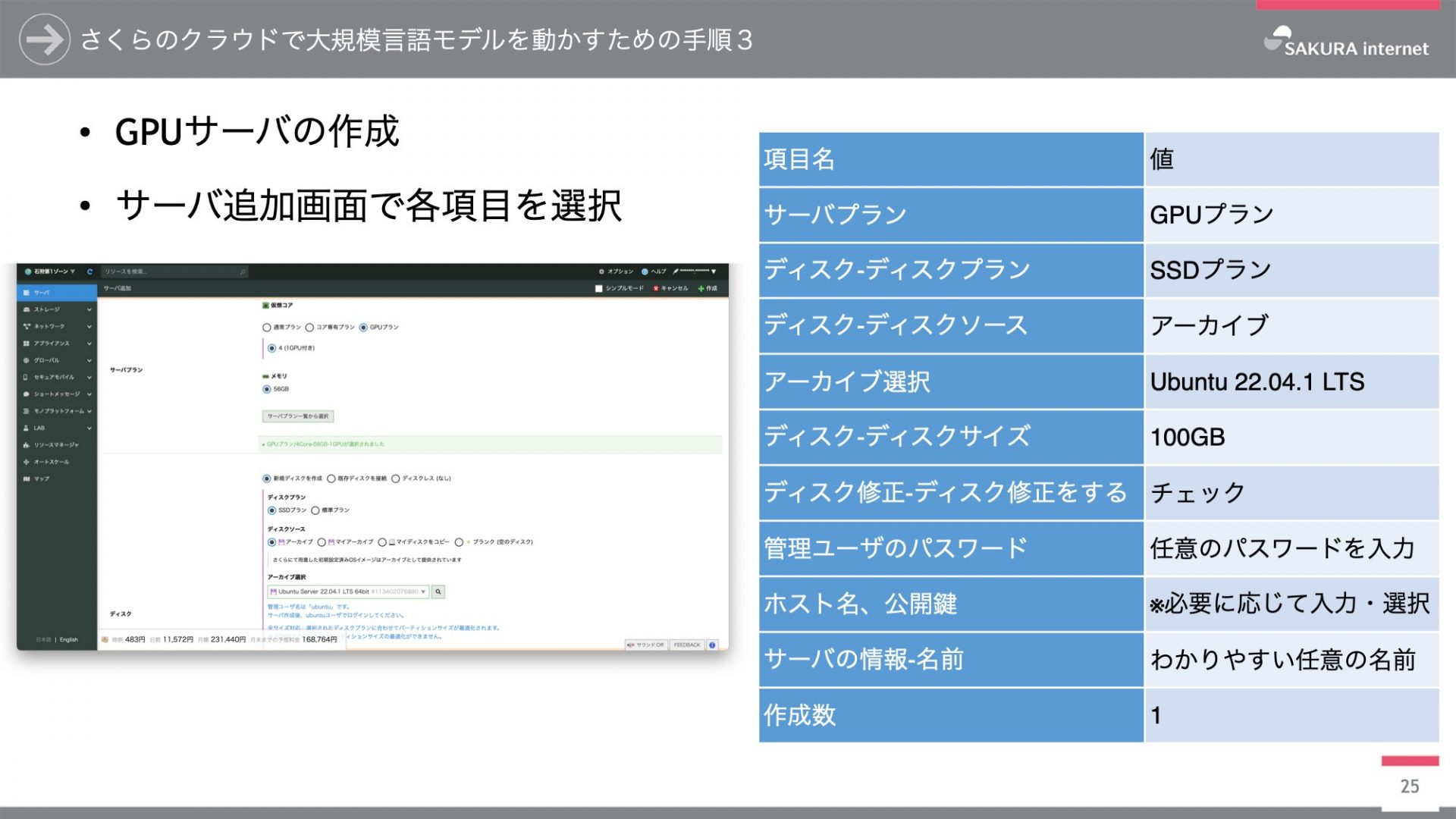
ログインすると一番最初にサーバの一覧画面が出てきまして、サーバ一覧画面の右上の方に「追加」ボタンがありますので押しますと、図の左側にあるサーバ追加画面が表示されます。こちらの方に、図の右側に掲載した項目と値を入力していただきますと、GPUサーバの作成を行うことができます。サーバプランがGPUプラン、ディスクがSSD、アーカイブがUbuntu 22.04.1 LTSですね。ディスクの容量はおよそ100GB程度あれば十分動きます。その他、OSのパスワードやホスト名、公開鍵の設定なども必要に応じて入力してください。それから、GPUサーバは普通のサーバに比べて値段が高めになっておりますので、作成数は必ず1でお願いします。
サーバの作成ボタンを押すと、サーバの作成完了までお待ちいただくことになります。だいたい10分ほどで作成完了になるかなと思います。タイミングによってはこれより早かったり時間がかかったりするんですが、平均的には10分ぐらいと思っていただければ大丈夫です。
サーバが完成したら、サーバが電源の入った状態で出来上がってきますので、出来上がったサーバにsshでログインしていただきます。サーバ作成時に設定していただいたパスワードまたはSSH鍵を用いてログインをしてください。
サーバにログインしたら、まずはじめにGPUドライバのインストールを行います。さくらのクラウドの高火力プランでは、現状は一つのモデルのGPUのみをサポートしておりまして、そちらがNVIDIA社のTesla V100というものになります。ですので、NVIDIA社のドキュメント通りにドライブのインストールを行います。コマンドをリンク先のドキュメントから抜粋して掲載します。こちらを実行することでドライバーのインストールが完了します。
$ sudo apt-get install linux-headers-$(uname -r)
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
$ wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-keyring_1.0-1_all.deb
$ sudo dpkg -i cuda-keyring_1.0-1_all.deb
$ sudo apt-get update
$ sudo apt-get -y install cuda-driversその次にPythonライブラリのインストールを行います。今回利用するOpenCALMをPythonで扱うためのライブラリをインストールします。
$ sudo apt install python3-pip
$ pip3 install transformers accelerateこれで用意が整いましたので、サンプルコードを実行してみます。HuggingFaceで公開されているOpenCALMのサンプルコードがありますので、こちらを実行します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-7b", device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-7b")
inputs = tokenizer("AIによって私達の暮らしは、", return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
こちらが実際のサーバの画面でして、Pythonをまず立ち上げます。そして先ほどのサンプルコードを貼り付けます。すると、モデルのダウンロードが始まります。上記の動画では過去に何回かダウンロードしていて、キャッシュを参照しているのですぐダウンロードが終わります。キャッシュがない状態だと数十分くらいダウンロード時間がかかったりするので、お待ちいただければと思います。
その後に、実際にLLMを実行した結果が表示されます。「AIによって私たちの暮らしは」という文を与えると、その文で始まる文章をOpenCALMが返してくれるんですね。これを見ると、割と意味のあるつながった文章が生成されたのかなと思っています。こういったところがやっぱり日本語の大規模言語モデルの強みかなと思っています。
というところで、サンプルコードを用いてOpenCALMがさくらのクラウドで動いたところをご確認いただけたかなと思います。詳細な手順やもっと簡単に動かすための手順を記した記事も用意しております。あと、cloud-initをご存知の方はよく使われていると思うんですけれども、cloud-initのコードも用意しているので、コピペで先ほどの環境を作ることもできます。ぜひお試しいただければと思っております。
これで、さまざまなものと組み合わせてLLMを使えるようになります。今回、もっと手軽に使いたいなと思いまして、一例としてHTTP APIからLLMを使えるようにしてみました。こちらもQiitaの記事をご覧ください。
LLMを使ったチャットボットのデモ
ここからはLLMを使ったチャットボットのデモをします。LLMはOpenCALMを使用します。会話型AI構築サービス「miibo」に、さくらのクラウドで動くLLMを連携させてチャットボットを作ろうかと思います。miiboの簡単な説明をしますと、miiboは無料で会話AIを構築から共有までできるWebサービスで、わずか数分の作業で会話AIを構築できます。こちらもChatGPTに対応しておりまして、とても良いサービスですのでぜひご利用いただければと思っております。

簡単なアーキテクチャの説明をします。まず、さくらのクラウドの高火力プランでサーバを作り、その上にOpenCALMを用意します。その後にAPIを実装します。このAPIは、PythonのフレームワークのFastAPIを使ってtransformerモデル(OpenCALM)を呼び出すものです。FastAPIはリクエストとして文章を受け付けて、それをOpenCALMに入力します。そして、OpenCALMからの出力をAPIとして返すという役割をしております。非常にシンプルな構成で作ってみました。
こちらがmiiboのチャットボットの画面になります。ではちょっと動かしてみたいと思います。
画面の右側に青色で表示されているのが、私が手打ちで入力している文章で、左側がチャットボットの応答です。まずはちょっと挨拶をしてみます。すると返事が返ってきましたが、ちょっとよくわからない返事をしてきていますね。次はちょっと別な文章を投げてみます。そうすると「最近はまっているゲームがあるのでそれについて語りましょうか!」という、なんか元気そうな返事が返ってきました。ではさらに会話を続けてみましょう。なんかやってくれそうです。「どんなゲームが好きですか?」と投げかけると、「ストーリー性の強い作品をプレイしたり、謎解きが楽しいです」とのことです。自分も謎解きが好きなのでそのように入力して会話を続けます。これを見ていると割と応答速度もスムーズで、会話も結構成立しててすごいなと思いました。
続いてデモの2番目です。こちらは一般教養的な投げかけをしてます。「日本で一番高い山は?」という質問を投げかけてみたところ、「富士山だと教えてくださいました」と返ってきました。これは合っていますね。今度は「日本で一番長い川は?」という質問をしてみると「木曽川だそうです」と回答してきたのですが、調べてみるとこれは間違いだそうです。LLMが言ってることを完全に信じてしまうと間違ってることもあるので、使い方はちょっと気をつけましょうというところがあるかと思います。さらにデモの後半の方はなんか会話が成立してないというか、期待した答えが返ってこないなっていう感じになっていました。というところでデモを終わりにしたいと思います。
大規模言語モデルをセルフホストするメリット

ではここで、大規模言語モデルをセルフホストするメリットについて考えてみたいと思います。今回はChatGPTやOpenAIのようなSaaSを使わずに自分の環境でLLMを動かしたんですけれども、どういったことがメリットになるかをちょっと書いてみました。
例えば、特定のタスクを実行するためにカスタマイズしたLLMを使いたいというニーズがあるとセルフホストしたくなるかなと思いました。というのは、タスク固有のデータセットでファインチューニングする必要がありますからね。2番目はデータセキュリティとプライバシーというところで、外部に出せないデータを使ったLLM活用っていうのが今後出てくるのかなと思っています。あと、SaaSを使っていると、本当にあるかどうかわからないんですけれども、外部に出せないデータが漏洩してしまうという観点もあるので、自社内で持ちましょうみたいな考えも出てくるかなと思ってます。
それから、オンプレミスの恩恵というか、LLMを動かせるインフラがあるのであれば、従量課金でSaaSに払う金を気にせずにLLMモデルを動かすことができるのかなっていう、コストコントロールができるのかなと思っております。あと、LLMが自組織内にあれば最適化もできる余地があるのかなと思ってます。ただ、GPUは非常に消費電力が大きいので、電気代だとかファシリティっていうところで苦労したりするのかなと思います。それでもセルフホストするメリットがあるのであれば、セルフホストで使っていくといいのかなと思います。もしくはパブリッククラウドにLLMを置いて活用する方法もあるでしょう。
使ってみた感想

そして感想ですね。今回の資料作成を通していろいろ動かしたりした感想になります。
まず、動かすまでの手順がシンプルで、すぐに動かせたっていうのは結構驚きでした。3,4年前に機械学習で環境構築した時はいろんなライブラリをインストールしないといけなくて、しかもバージョンの縛りがあって非常に苦労したんですけれども、今回は本当にGPUドライバーとPythonのライブラリをインストールしただけだったんで、昔のような苦労をせずに動かせたのですごく良かったなと思います。あと、割と汎用的に使えるのかなと思っていて、今回はHTTP APIとして実装したデモもも行いましたが、他にもslack botにしたら面白いんじゃないかなとか、いろいろ興味ある人とお話しして夢を膨らませています。
その一方で要望もあって、もう少し精度が欲しいというところで、応答がちょっと期待はずれの時もあるかなと思います。先ほどのデモでもお見せした通り、会話があまり成立してないところもあったので、もう少し精度が欲しいなと思いました。あとはファインチューニングしてみたいですね。私もいろんな業務をしてるんですが、やっぱり業務で使えたらちょっと自分も楽になるのかなと思ったりしたので、そういったところでも使いどころを探しながら使ってみたいと思います。ファインチューニングについても今回取り上げようかなと思ったんですが、私の学習が間に合わなかったので、今回はとりあえず動かすところまでという記事を書いたところです。
そして、さくらのクラウドでも動くことがわかってすごくうれしく思いました。今回はTesla V100というGPUだったんですけれども、他のGPUも世の中にはありますので、それらのGPUを使った検証もできたら面白そうだなと思っております。
そして最後に、LLMを活用してみたいというところで、どういった仕組みで動いてるのかとか、最終的には自分でLLMを作ってみることができたらすごく楽しそうだなと思っています。そのためには、まず根底にある機械学習というところをもう一回おさらいしてやっていきたいなと思っております。
エンジニア積極採用中

さくらインターネットではエンジニア採用を強化しております。「社会を支えるパブリッククラウド」ということで、大規模計算資源のインフラ屋をやりたいエンジニアを募集しております。弊社はインフラサービスをはじめとして、他にもIoTやTellusといったWebサービスも提供しております。データセンターも持っており、一気通貫で下から上のレイヤーまで関わることができるのが弊社ならではの醍醐味になっております。またオープンソースソフトウェアを組み合わせてサービス開発しているのも弊社の特徴の一つです。さまざまなことを仕事を通して経験ができます。上から下までのさまざまなレイヤーに携わりたい、オープンソースが好きという方、ぜひご興味を持っていただければうれしいなと思っております。
詳しくはウェブサイトの方をご覧いただければと思います。カジュアル面談を行っておりますので、ぜひその際にお話しできたらと思っております。さくらインターネットでどんな働き方してるのかなとか、さくらのクラウドってどんな人たちがどんな風に作ってるのかなっていう話については、先ほどもご紹介しましたが「クラウドの作り方(GPUサーバ編)」という資料の方でご紹介しておりますので、さくらインターネットに興味がある方はこちらの資料をご覧いただきますと、より弊社について理解していただけるかなと思っております。
発表は以上です。ありがとうございました。