さくらのクラウドシェルにおけるK8s運用事例

2023/5/25に「さくらのクラウドシェル」をリリースしました。リリースに際して蓄積した知見を共有しようと思い、これらのノウハウを社内勉強会で発表・共有しました。本記事では発表内容を元に、さくらのクラウドシェルの概要・インフラ構成・それらをどのように運用しているかを解説します。
目次
開発経緯・背景
まず、さくらのクラウドシェルを作ろうと考えた背景を説明します。さくらのクラウドシェルを作ろうと思った背景は以下のとおりです。

さくらインターネットの知名度向上のため、これまでのサービス形態と異なった形でユーザに提供してみようとなったわけです。そこでこれまでの会員IDでの利用形態に加え、会員登録なしで(事前準備なしで)利用可能なサービスとしてクラウドシェルをリリースしようと考えました。
また次のようなさくらインターネット側のニーズもありました。

さくらインターネットは社内でコンテナ技術を用いたサービスを何度か検討していましたが、なかなか正式運用まで至りませんでした。コンテナ技術やこれを利用するK8sといったオーケストレーションシステムの運用知見及び実績を積み、より良いサービス提供を目指したいと考えました。
さくらのクラウドシェル
そして、これらのゴールをクラウドシェルで実現しようということになりました。

さくらのクラウドシェル(以降クラウドシェル)は、その名のとおりブラウザで利用可能なシェル環境です。手元の環境に不要なソフトウェアをインストールせず、どこでも作業ができ、すぐに利用できます。
インフラ概要
クラウドシェルは さくらのクラウド上で動作し、フロントエンド・バックエンドを提供するアプリケーション用K8sクラスタと、ユーザのクラウドシェル本体が動作するK8sクラスタを有します。なお、チームでは既存サービスとの親和性のためクラウドシェル本体をVM(厳密にはPod・コンテナ)と言っています。
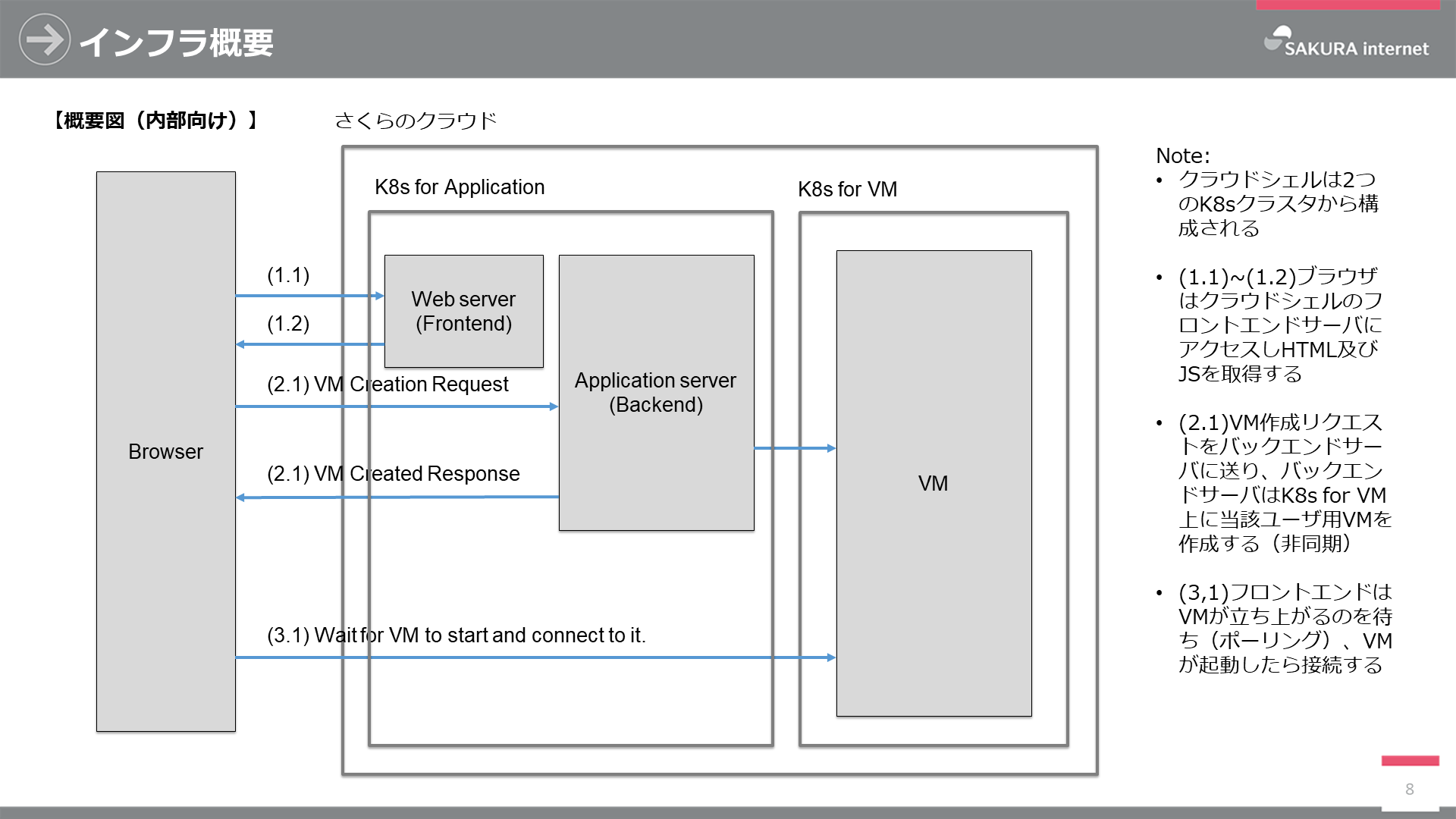
クラウドシェルの起動フローは以下のとおりです。
- ユーザがブラウザからクラウドシェル起動URLにアクセスすると、フロントエンドサーバがJavaScriptとHTMLを返す
- JavaScriptはクラウドシェル起動リクエストをバックエンドサーバに送信する
- バックエンドサーバがリクエストを受け取ると、VMクラスタに対してリクエスト情報に基づいたクラウドシェルを起動するよう要求する
- バックエンドサーバはクラウドシェルの起動を待たずにクラウドシェル本体(コンテナ)へのアクセス情報をブラウザに返す
- ブラウザはクラウドシェル本体が起動するまでポーリングし、起動したらWebSocketにて接続を行う
インフラ詳細
次に前述の2つのクラスタについて説明します。
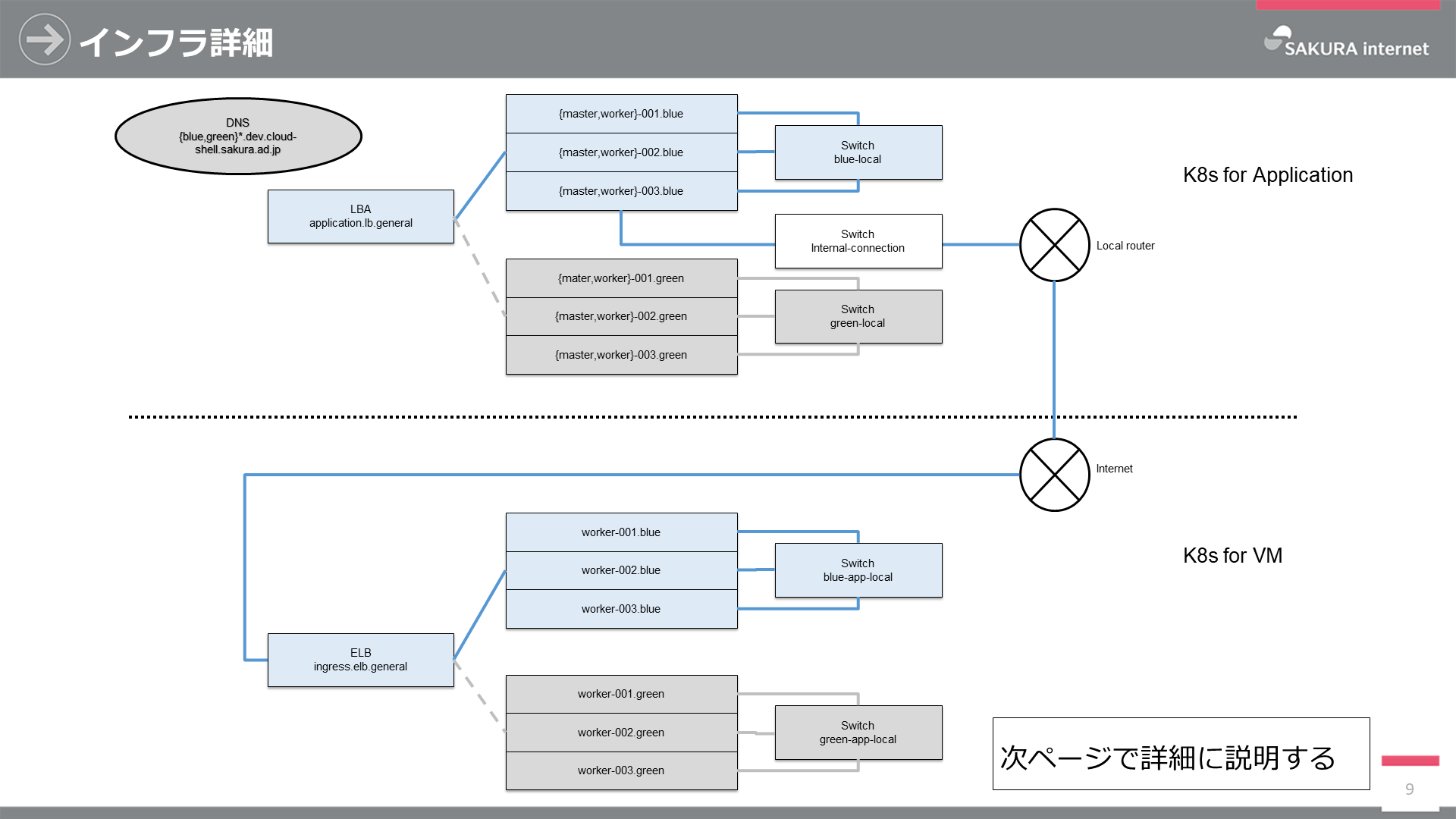
まずはアプリケーションクラスタについてです。ユーザがクラウドシェルを起動する場合、secure.sakura.ad.jp(Webサーバ)を通って、LBA(ロードバランサアプライアンス)、アプリケーションクラスタの順にアクセスします。当該クラスタはクラスタ間を接続するスイッチによって接続され、社内へのアクセスは社内アクセス用スイッチ及びそのスイッチの先にあるローカルルータを通ります。LBA、クラスタを構成するサーバ群、クラスタ間接続スイッチはTerraform, Ansible (Kubespray)を用いて構成管理及びデプロイしています。
もう一つはVMクラスタです。VMクラスタは社内との接続を一切持たず、インターネットを介してのみアクセスが可能なクラスタです。ユーザはブラウザからELB(エンハンスドロードバランサ)、VMクラスタの順にアクセスします。ELB、クラスタを構成するサーバ群、クラスタ間接続スイッチはアプリケーションクラスタ同様にTerraform, Ansible (Kubespray)を用いて構成管理及びデプロイしています。
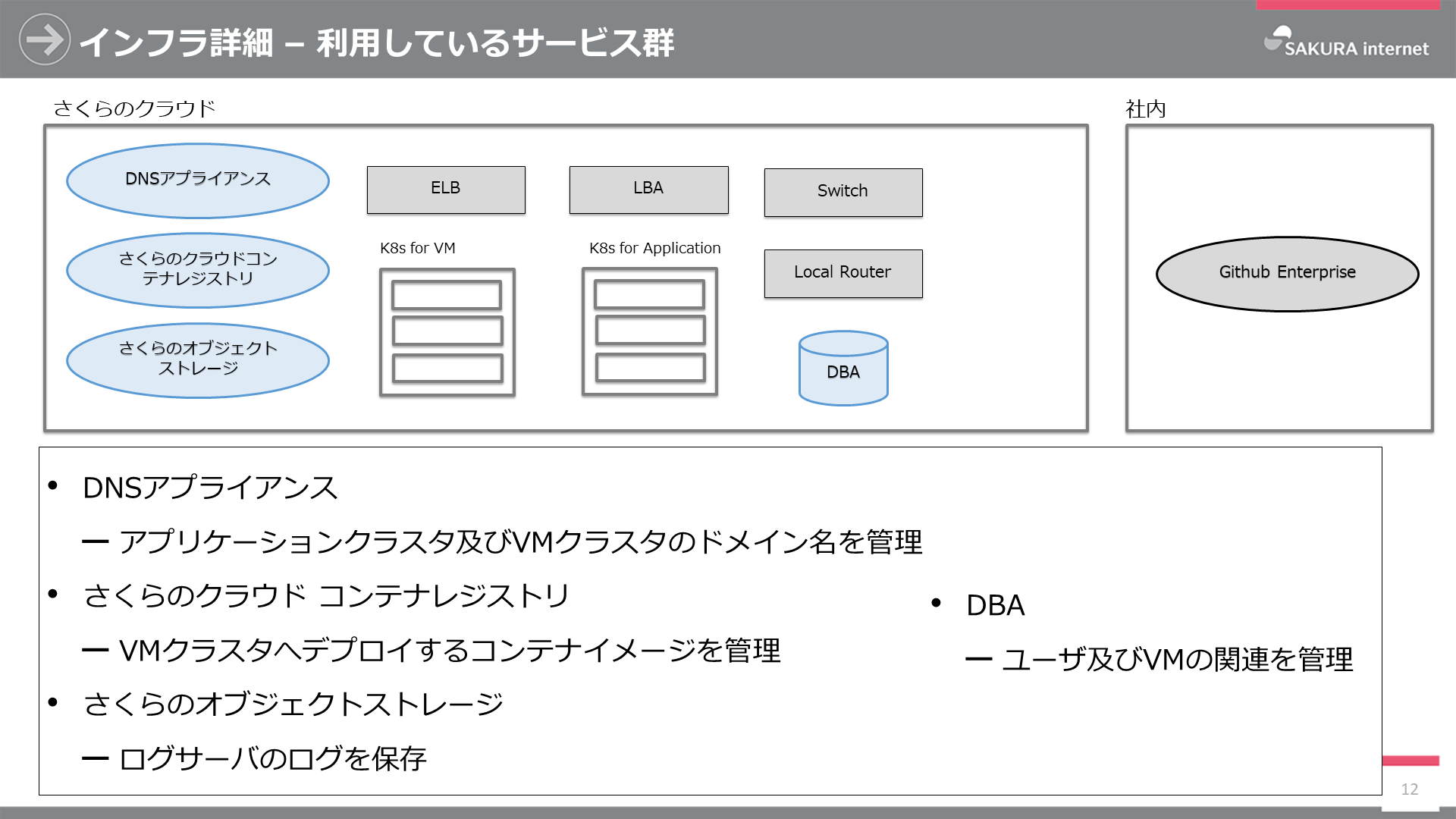
その他利用しているサービス群
その他利用しているサービスは以下のとおりです。
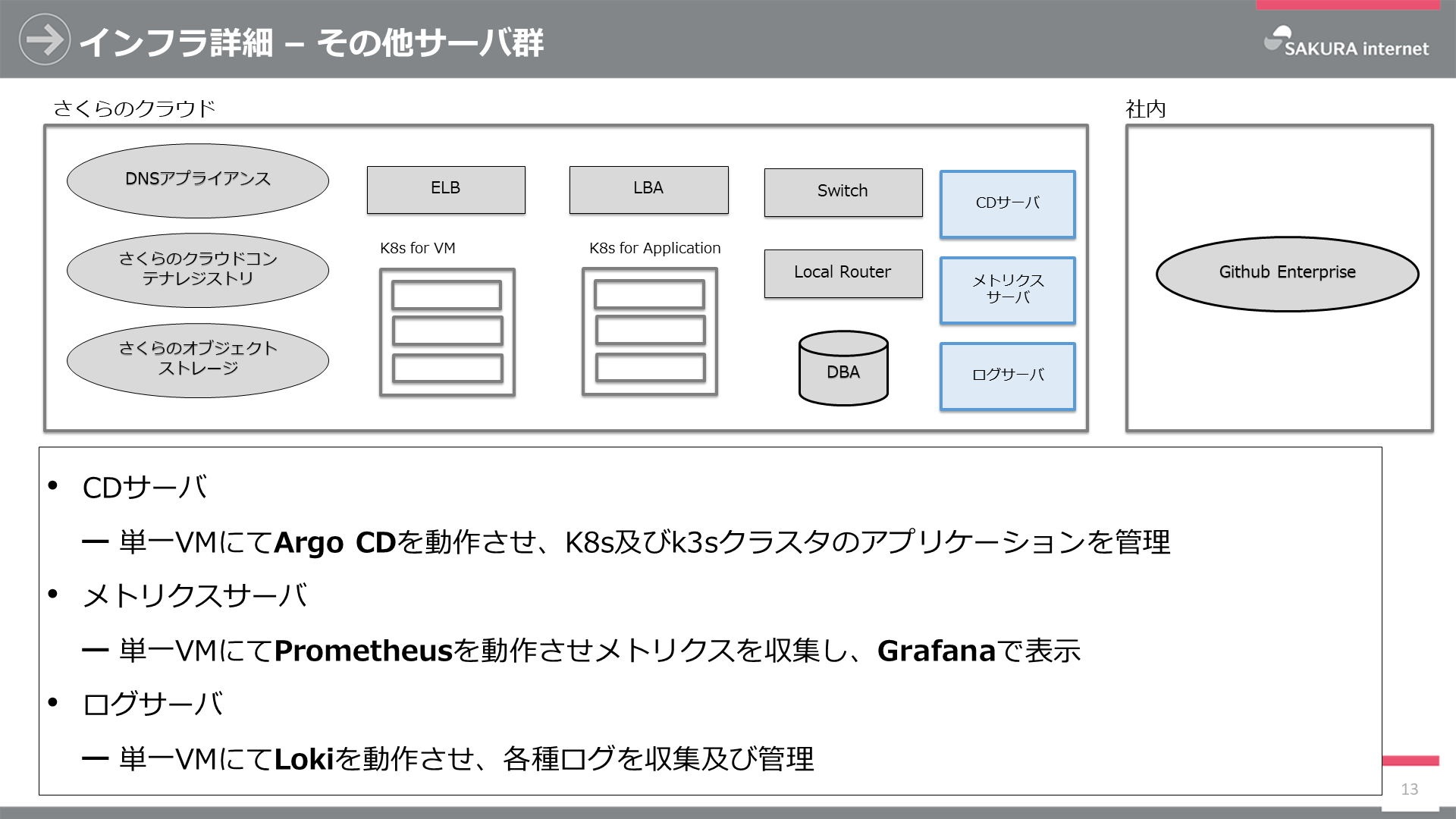
また、サービスを運用するためのその他サーバ群は以下のとおりです。こちらもTerraform, Ansibleで構築・設定しています。
インフラ構成に関するFAQ
なぜシングルゾーン構成なのか(なぜマルチゾーン構成ではないのか)
資料からパッと分からないですが、クラウドシェルはシングルゾーンで運用しています。これはクラウドシェルの稼働がゾーンダウンを考慮するサービス形態であるということもありますが、なにより社内のシングルゾーン運用においてゾーンダウンがほとんどないことや、リリース初期段階でゾーン冗長が不要だと考えたからです。
なぜArgoCDをアプリケーションクラスタやVMクラスタ上で構築・運用しないのか
クラウドシェルのクラスタ運用方針として、責務を分離した運用がしたかったというのが大きいです。また、ArgoCD、アプリケーション、クラウドシェル本体のライフサイクルが異なり、これによりそれぞれに求められる可用性が異なってきます。異なる可用性によってクラスタ全体が最も高い水準を求められることになり、これによって運用が煩雑になることを避けたかったことも理由です。同様の理由で、メトリクスサーバやログサーバをアプリケーション・VMクラスタから分離しています。
クラスタのアップグレード方式
アプリケーション及びVMクラスタはBlue/Greenアップグレード方式を採用しています。
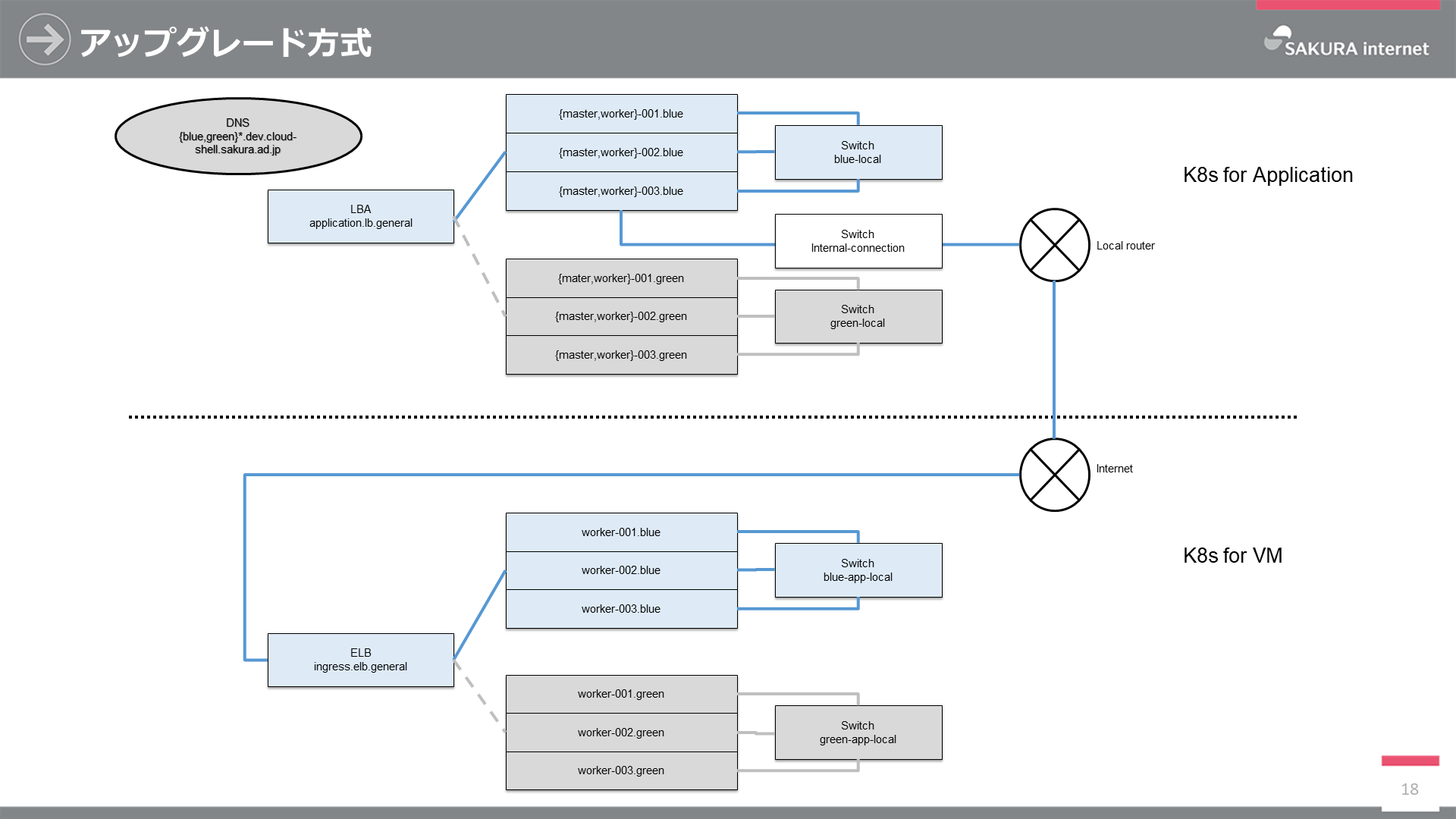
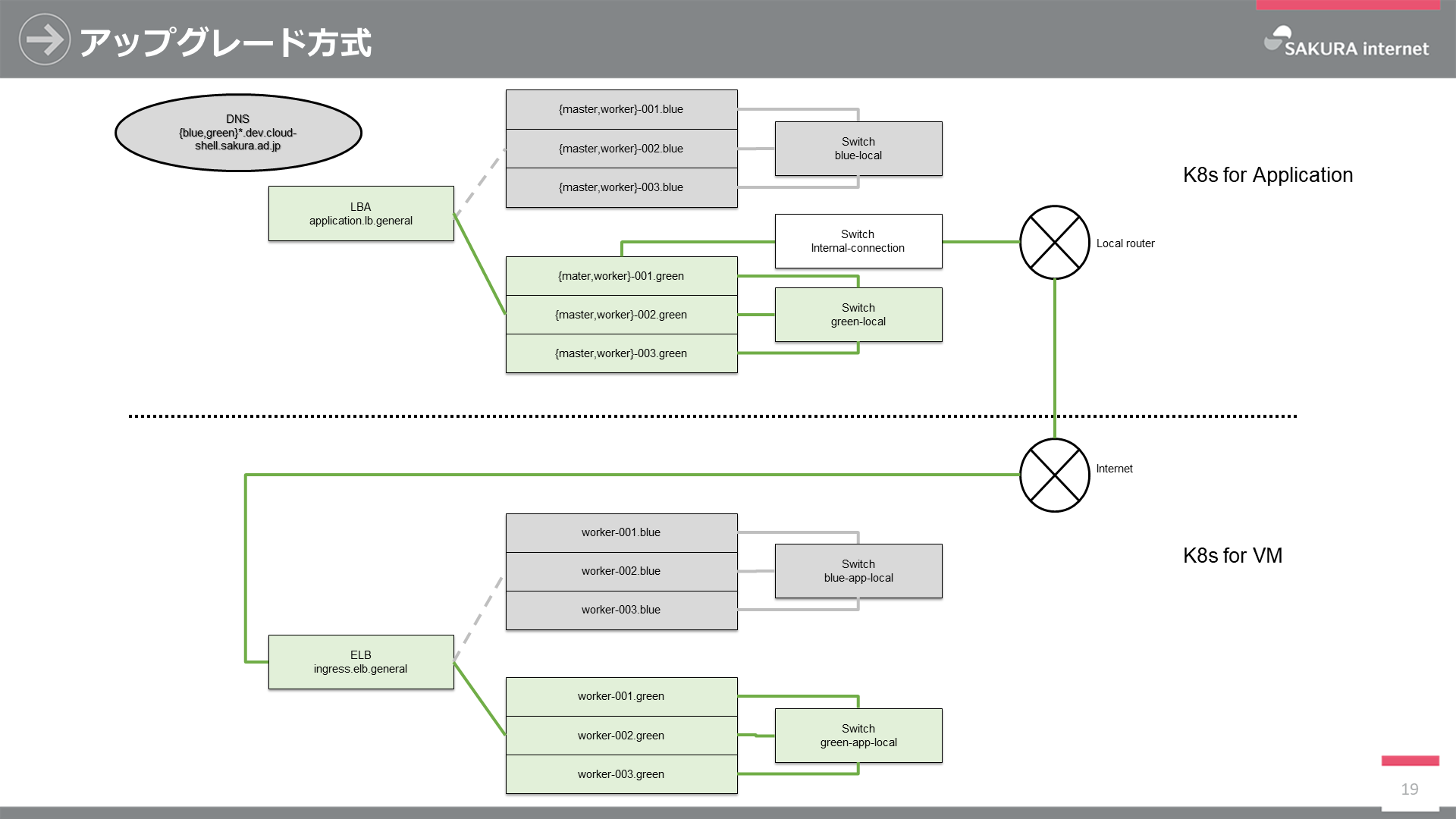
これはK8sクラスタをアップグレードする際はもちろんですが、さくらのクラウドの破壊的な変更やノード個別にアップグレードが煩雑になってしまう場合に有用です。具体的にはTerraformでGreenを作成及びAnsibleで設定した後、Terraformにてロードバランサの接続をGreenに切り替えることで実現しています。3年間運用しているさくらのオブジェクトストレージでも同様の方式であり、運用実績もあるためこの方式を採用しています。
K8sをもっと詳しく
Calico(CNIプラグイン)
クラウドシェルではCNIプラグインにCalicoを選択しています。これはKubesprayがサポートしているCNIプラグインであり、また社内で利用実績及び知見があったことが理由です。例えばCalicoにはNATPortRangeというNATから外向き通信を行う際に利用するポート範囲を設定するパラメータがあり、これはデフォルトで1024以上のポートにマッピングされます。
一方Linuxカーネルは32768~60999の範囲をローカルポート(エフェメラルポート)として扱います。Linuxカーネルのローカルポートを許可するためにパケットフィルタ等で32768~60999を許可していても、NATPortRangeによって1024~32767の範囲に割り当てられた場合、外向きの通信ができないという問題が以前ありました。この知見を持っていたため、NatPortRangeの範囲をLinuxカーネルのローカルポート範囲と合わせることで早急に問題を解決できました。
Istio
不正利用の検知を行うために通信履歴を取得する必要があり、このために採用したのがIstioです。しかし単にクラウドシェルが動作するクラスタにIstioを入れたのでは、認証なしでクラウドシェルを利用する場合であってもDNSサーバに対してある程度の攻撃が可能になってしまうという問題がありました。(認証しないためユーザを特定できない)
仮にネットワークポリシー等でアウトバウンドをすべて遮断してしまうとIstio-proxy(pilot-agent)が ヘルスチェック用エンドポイント(http://localhost:15021/healthz/ready)等に通信できなくなり、クラウドシェル本体が起動しなくなってしまいます。そこで認証なしの場合はIstioをInjectionしないことでDNSサーバへの攻撃を防ぎ、会員ID認証による利用の場合のみIstio Injectionすることで不正利用対策も行えるようになりました。
func (k *K8sRepo) createNamespace(name string, plan *plan) *apiv1.Namespace {
namespace := &apiv1.Namespace{
ObjectMeta: metav1.ObjectMeta{
…
},
}
if plan.CanEgress {
namespace.ObjectMeta.Labels["istio-injection"] = "enabled"
}
return namespace
}K8sマルチテナントホスティングの勘所
クラウドシェルの運用が始まってから日が浅いですが、これまでの社内での経験を踏まえ、K8sを用いたマルチテナントホスティングサービスの勘所を紹介します。
PodにResource Requests / Limits を必ず設定しよう
Resource RequestsとはPodデプロイ時に要求するリソース量を設定するパラメータであり、Resource LimitsとはPodが利用可能なリソースの上限を定めるパラメータです。これらを設定することで悪意のあるユーザがリソースを大量に要求することによるDoS攻撃を防ぐことができます。
また、名前空間内のリソース量の制限(強制)するLimit Rangeも設定するとベターです。
Podのネットワーク帯域制御をしよう
マルチテナント型のサービス全般に言えることですが、テナント(ここではクラウドシェル本体)はK8sのネットワーク帯域を共有するため、一部のユーザによってネットワーク帯域が圧迫される場合があります。そうならないようにテナント毎に利用可能なネットワーク帯域を制限しましょう。
annotations:
# Ingress bandwidth
kubernetes.io/ingress-bandwidth: 200M
# Egress bandwidth
kubernetes.io/egress-bandwidth: 200M* Reserved を設定しよう
K8sにはkubeletやコンテナランタイム等のK8sに関するリソースを予約するパラメータであるKube Reservedと、sshd, udev, カーネル等のOSに関するリソースを予約するパラメータであるSystem Reservedがあります。
少なくともKube Reservedは必ず設定し(Kubesprayではデフォルトで適用されます)、System Reservedはノードを徹底的にプロファイリングした上で設定しましょう。(重要なサービスが不適切なSystem Reservedによってリソース不足で停止することを避けるため)
Eviction(Node-pressure Eviction) を必ず設定しよう
Evictionとはノード上のリソースが枯渇するのを防ぐためのプロセスです。具体的にはkubeletがノードのメモリ、ディスク容量、inode等のリソースを監視し、いずれか1つでも閾値に達するとノード上の1つ以上のPodを停止させるというものです。
Evictionの閾値にはSoft eviction thresholdsとHard eviction thresholdsがあります。Soft eviction thresholdsはSIGTERMを送った後、猶予期間が経過するまで待ち、その後SIGKILLにてPodを終了します。Hard eviction thresholdsはSIGKILLを送り、ただちにPodを強制終了します。クラウドシェルではサービスの特性上、即終了して問題ないためHard eviction thresholdsのみ設定しました。
なお、Amazon EKSもHard eviction thresholdsだけ設定されており、以下のようにインスタンスタイプによらず一律となっています。
...
"evictionHard": {
"memory.available": "100Mi",
"nodefs.available": "10%",
"nodefs.inodesFree": "5%"
},
...Pod(コンテナ)にセキュリティコンテキストを設定しよう
少なくともICMPトラフィックやRAWソケット生成が不要なPodではDROPすべきです。
apiVersion: v1
kind: Pod
spec:
containers:
- name: test
image: alpine
securityContext:
capabilities:
drop:
- NET_RAWまとめ
さくらのクラウドシェル開発の経緯・背景、そのインフラ構成、K8s運用における勘所を紹介しました。利用形態や新機能の追加によってシステム要件が変化した場合に、適切に技術選定を行うとともにプラクティスを適用していく必要があります。これからも運用を続けノウハウの蓄積と共有を行い、より良いサービスが提供できるよう励んでいきます!