TrinoとIcebergでログ基盤の構築


目次
はじめに
2023年10月5日(木)にTrino / Presto Conference Tokyo 2023 (Online)が開催されました。本記事はイベントにて発表した内容をご紹介します。
社内の監視サーバについて
さくらインターネットでは現在社内の各チームでPrometheus, Elastic Stack, Lokiなどの監視基盤を個別に運用しています。この状態では運用負荷が大きいためSRE室でログ基盤を提供することにより、運用の手間を減らすことや運用レベルを底上げしてコスト削減ができるのではないかと検討しています。既存のOSSでの運用も行ってみたものの、マルチテナント提供・ライセンス体系の問題など課題があったことからTrinoとIcebergでの開発を始めました。
Icebergとは
Icebergはビッグデータ・データレイクを構築するためのストレージフォーマットです。データの仕様や読み書きをするための低レイヤーなクライアントライブラリが提供されています。Icebergのテーブルは Trino, Presto, Spark, Hive, Flink, Impalaなどのクエリーエンジンから同じデータを参照することが可能です。元々はNetflixが開発していたものですが、Apache Software Foundationに無償提供されて開発を継続しています。
主な特徴
- 高い信頼性:Seriallizable isolation, Snapshot, Atomic mutation
- 費用対効果の高いストレージ:Object Storage,Parquet
- パフォーマンス最適化:Partitioning, Clustering, CoW/MoR切り替え
- スキーマ変更:Schema Evolution, Table,Partitioning
今まではS3, HDFSなどに保存したデータをHive Metastoreなどに登録してTrinoなどでクエリしているというような環境も多かったかと思います。その際の課題感として「同時に読み書きが難しいことやトランザクションがサポートされていない、スキーマ定義を途中で変更することが困難、レコード単位の読み書き編集が難しい、過去の状態に復元するスナップショット機能のようなものが無い、Metastoreに負荷が集中する」などがありました。このような課題を解決するためのフォーマットがOpen Table Formatで、Apache Icebergはこれらの課題を解決しています。
TrinoでIcebergを扱う方法
TrinoではIcebergの機能を一通り簡単なSQLで操作することが可能です。他のデータソースとJOIN, UNIONを行うことも可能であり、既存のデータ基盤やMySQLなどと接続することも容易です。また、 IcebergではINSERT, SELECT, UPDATE, DELETEのテーブル作成を以下のようにSQLで簡単に使うことが可能です。
CREATE TABLE t1 (a int, b int);
INSERT INTO t1 VALUES (1, 2);
SELECT * FROM t1;
UPDATE t1 SET b = 3 WHERE a = 1;
DELETE FROM t1 WHERE a = 1;次に少し高度なテーブル定義を行ってみます。CREATE TABLEの後にWITHを指定することでIcebergのオプションを指定することができます。
CREATE TABLE example (
c1 INTEGER,
c2 DATE,
c3 DOUBLE
) WITH (
partitioning = ARRAY[
'c1',
'month(c2)'
],
sorted_by = ARRAY[
'c3'
]
);整数型のc1の値ごと、日付型のc2カラムの月ごとのパーティションと呼ばれる保存領域を作成するように指示しています。また、実数型であるc3のカラムをもとにソートするようsorted_byで指示を出しています。INSERTは以下のように行います。
INSERT INTO example VALUES
(1, DATE '2023-01-01', 1.0), ← c1=1, 1月
(1, DATE '2023-01-02', 2.0), ← c1=1, 1月
(1, DATE '2023-02-01', 3.0), ← c1=1, 2月
(1, DATE '2023-02-02', 4.0), ← c1=1, 2月
(2, DATE '2023-01-01', 5.0), ← c1=2, 1月
(2, DATE '2023-01-02', 6.0), ← c1=2, 1月
(2, DATE '2023-02-01', 7.0), ← c1=2, 2月
(2, DATE '2023-02-02', 8.0); ← c1=2, 2月
SELECT * FROM example
WHERE c1 = 1 ← c1=1, 1月をクエリ対象
AND c2 = '2023-01-01';c1が1で1月や2月、またc1が2で1月や2月というデータのグループでパーティションが作成されます。SELECTの際にWHEREとしてパーティションされたカラムを指定すると、c1が1、c2が1月といったパーティションをクエリの対象にすることができます。sorted_byを指定したc3カラムに関しては、WHERE文で大なり小なりなどの比較を行うことで効率的にクエリが行われます。
Icebergの仕組み
Icebergの内部は1層~5層の階層構造になっています。
- 1層:catalog
- 2層:metadata file
- 3層:manifest list
- 4層:manifest file
- 5層:data files
catalogはデータベースに保存され、他の情報についてはAWS S3, Google GCSなどのオブジェクトストレージに保存されます。このような役割分担を行っているため、トランザクションを提供しながらもスケーラビリティが高く、かつ低コストにデータ保存が可能となっています。オブジェクトストレージに保存されるデータは以下のような形になっています。
$ tree /mnt/s3/default/t1
.
|-- data
| |-- 20230928_101505_00007_k5eys-54e49815-ddcf-48b7-9596-ba766979a688.parquet
| |-- 20231002_083351_00006_jpegd-d2a1e1ac-1bef-4fab-981c-98c86462c630.parquet
| `-- 20231002_083432_00010_jpegd-7c0bd2af-85a5-44a4-a179-82c9a1965139.parquet
`-- metadata
|-- 00000-1afbaa09-8ed5-4868-9952-02fdd22ccbd6.metadata.json
|-- 00001-5e8fc4c9-962c-4958-a134-ab1a13bfea99.metadata.json
|-- 00002-704c029e-e5c8-46ca-9ea1-7187930be895.metadata.json
|-- 733ba142-1754-4330-ad61-59f58bfd1d71-m0.avro
|-- 733ba142-1754-4330-ad61-59f58bfd1d71-m1.avro
|-- 7f9e5444-9486-4172-aade-288819b03d49-m0.avro
|-- snap-1463702341869305305-1-e07c019a-2f9b-4eab-94b1-38f083598652.avro
|-- snap-4566183149179530475-1-b3e2bfc0-0b45-477f-9d38-e2c445eda04c.avro
`-- snap-7319754993849090227-1-7f9e5444-9486-4172-aade-288819b03d49.avro1層:catalog(カタログ)
テーブル名のプレフィックスの中にdata, metadataというプレフィックスが並び、その中に実データやメタデータが並んでいます。catalogはメタデータファイルの格納位置を保持し、トランザクションを提供しています。バックエンドの選択肢としてMySQLなどのRDBやHive Metastoreなどの既存のカタログ、キーバリューストアやREST APIなどに対応しています。
以下のSQLはバックエンドMySQLとして利用した際のテーブル構造になっています。テーブル名などの情報などに続いてmetadata_locationというフィールドが定義されています。テーブルに変更を加えるごとにメタデータファイルが生成され、その都度このmetadata_locationが更新されていくような形となっています。
mysql> SHOW CREATE TABLE iceberg_tables;
CREATE TABLE iceberg_tables (
catalog_name varchar NOT NULL,
-- example: rest_backend
table_namespace varchar NOT NULL,
-- example: default
table_name varchar NOT NULL,
-- example: t1
metadata_location varchar DEFAULT NULL,
-- example: s3://bucket/.../00001-.....metadata.json
previous_metadata_location varchar DEFAULT NULL,
-- example: s3://bucket/.../00000-.....metadata.json
PRIMARY KEY (
catalog_name,table_namespace,table_name
)
);2層:metadata file(メタデータファイル)
metadata fileはテーブルの構造を保持しています。CREATE TABLEの際に指定するようなスキーマ・パーティション・ソートなどの情報を持っています。途中でテーブル構造が変更された際にはバージョニングされたうえでそのスキーマが複数定義されます。また、スナップショットの一覧も保持しており、manifest listのパスを記録しています。
$ jq '.' \
/mnt/s3/default/t1/metadata/00001-.....metadata.json
{
"schemas": [...],
"partition-specs": [...],
"sort-orders": [...],
"snapshots": [
{
"snapshot-id": 1463702341869305300,
"manifest-list":
"s3://bucket/.../metadata/snap-1463...8652.avro",
...
},
{
"snapshot-id": 8429213630642387000,
"parent-snapshot-id": 1463702341869305300,
"manifest-list":
"s3://bucket/.../metadata/snap-8429...ef78.avro",
...
}
],
...
}3層:manifest list(マニフェストリスト)
manifest listには実行計画の際に利用されるパーティションの値の範囲とmanifestへの参照が含まれています。先ほどの例では、たとえば`c1=1,c2=1月`のデータが入っている情報がこちらに入ってくる形になります。
$ avrocat \
/mnt/s3/default/t1/metadata/snap-8429...ef78.avro \
| jq '.'
{
"manifest_path":
"s3://bucket/.../metadata/a2c1...-m0.avro",
"manifest_length": 6683,
"partition_spec_id": 0,
"content": 0,
"sequence_number": 2,
"min_sequence_number": 2,
"added_snapshot_id": 8429213630642387000,
"added_data_files_count": 1,
"existing_data_files_count": 0,
"deleted_data_files_count": 0,
"added_rows_count": 1,
"existing_rows_count": 0,
"deleted_rows_count": 0,
"partitions": { "array": [] }
}
{
"manifest_path": ...
4層:manifest file(マニフェストファイル)
manifest fileには実データへの参照のほかに、カラムごとの値の上限下限などの統計情報が入っています。
$ avrocat \
/mnt/s3/default/t1/metadata/a2c1...-m0.avro \
| jq '.'
{
"status": 1,
"snapshot_id": { "long": 8429213630642387000 },
"data_file": {
"file_path":
"s3://bucket/default/t1/data/2023...a688.parquet",
"file_format": "PARQUET",
"lower_bounds": {
"array": [
{ "key": 1, "value": "\u0001" },
{ "key": 2, "value": "\u0002" }
]
},
"upper_bounds": {
"array": [
{ "key": 1, "value": "\u0001" },
{ "key": 2, "value": "\u0002" }
]
},
"value_counts": { ... },
...
}
}
{
"status": ...5層:data files(データファイルズ)
data filesには実際に書き込まれた値が入っています。フォーマットはParquet, ORC, Avroなどをユーザーが指定可能です。
$ pqrs cat \
/mnt/s3/default/t1/data/2023...a688.parquet
{a: 1, b: 2}data filesの格納位置はパーティションの有無で少し異なります。以下はパーティションが存在しない構造です。テーブル名の後に続くdata, metadataの中にフラットにそれぞれデータとメタデータが保存されています。
【Partition無し】
$ tree t1/
t1/
|-- data
| |-- 20230928_101505_00007_k5eys-54e49815-ddcf-48b7-9596-ba766979a688.parquet
| |-- 20231002_083351_00006_jpegd-d2a1e1ac-1bef-4fab-981c-98c86462c630.parquet
| `-- 20231002_083432_00010_jpegd-7c0bd2af-85a5-44a4-a179-82c9a1965139.parquet
`-- metadata
|-- 00000-1afbaa09-8ed5-4868-9952-02fdd22ccbd6 .metadata.json
|-- 00001-5e8fc4c9-962c-4958-a134-ab1a13bfea99 .metadata.json
|-- 00002-704c029e-e5c8-46ca-9ea1-7187930be895 .metadata.json
|-- 733ba142-1754-4330-ad61-59f58bfd1d71 -m0.avro
|-- snap-1463702341869305305-1-e07c019a-2f9b-4eab-94b1-38f083598652.avro
`-- snap-4566183149179530475-1-b3e2bfc0-0b45-477f-9d38-e2c445eda04c.avro
以下はパーティションありで作成されたテーブル構造になっており、c1 = 1、c2_month = 2023-01といったディレクトリ(prefix)が作られています。
【Partition有り】
$ tree example/
example/
|-- data
| |-- c1= 1
| | |-- c2_month= 2023-01
| | | `--
20231002_100950_00021_jpegd-346ffc2d-5e11-473e-bf51-30d0898bfdc8.parquet
| | `-- c2_month= 2023-02
| | `--
20231002_100950_00021_jpegd-4029a34f-c9b1-4512-9a2d-e30bc544a163.parquet
| `-- c1= 2
| |-- c2_month= 2023-01
| | `--
20231002_100950_00021_jpegd-02a4022b-c5c3-4367-85ae-fa22904bcdf2.parquet
| `-- c2_month= 2023-02
| `--
20231002_100950_00021_jpegd-391d3d88-af2e-4e63-ba48-f6be548d8243.parquet
`-- metadata
|-- 00000-da3c553c-0ddc-4b15-85db-0ba0faf757ab .metadata.json
|-- 00001-31e284a9-429c-4fa0-a1b2-87499b41b0d4 .metadata.json
|-- 00002-c0c18a49-da83-4997-bd78-886db53c53c8 .metadata.json
|-- e4737012-26a8-452d-a9d8-17733150fd4c -m0.avro
|-- snap-2797793416297343028-1-e4737012-26a8-452d-a9d8-17733150fd4c.avro
`-- snap-7900299843327693345-1-4ddcd5de-0345-4fe3-946c-a2607c15bdb2.avro
Icebergのメンテナンスコマンド
Icebergは階層構造となっており、様々な場所に必要な情報が埋め込まれているため、クエリーエンジン側で実行計画を分散して実行することも可能です。ファイルはS3などに対応するためImmutableでキャッシュも可能な構造となっています。実行計画を立てる際にはmanifest listやmanifest fileに含まれる値のヒントとSQLのWHEREなどの条件を見ながら大幅にScan量を削減することも可能です。また、データテーブルやデータの肥大化を防ぐため、メンテナンス用のコマンドもいくつか用意されています。
最初に「マージ」ですが、細かなファイルが沢山あるとクエリのパフォーマンスが低下します。そのためある程度大きなファイルにマージするコマンドが以下となり、例では100MBをターゲットとしてマージを行っています。
ALTER TABLE example EXECUTE optimize(file_size_threshold => '100MB');次にスナップショットの削除です。以下の例では7日前のスナップショットを削除しています。スナップショットに紐づくデータも一緒に削除されます。
ALTER TABLE example EXECUTE expire_snapshots(retention_threshold => '7d');最後に孤立したファイルの削除です。Icebergではジョブが失敗するなどで孤立したファイルが作成される可能性があります。以下の例では作成されてから7日以上経過し、かつ参照されていないファイルを削除します。
ALTER TABLE example EXECUTE remove_orphan_files(retention_threshold => '7d');Java Clientから直接データを追加する
TrinoやSparkなどを利用せず、Java Clientから直接データを追加する方法もあります。例として以下はKotlinのコードですが、 Java ClientのMavenでライブラリを取得して手軽に試すことができます。
val appenderFactory =
GenericAppenderFactory(table.schema(), table.spec())
val fileFactory = OutputFileFactory
.builderFor(table, 0, 0)
.format(FileFormat.PARQUET)
.build()
val writer = RowDataPartitionedFanoutWriter(
table.spec(),
FileFormat.PARQUET,
appenderFactory,
fileFactory,
table.io(),
Long.MAX_VALUE,
table.schema(),
)
writer.write(record)
val writeResult = writer.complete()
val append = table.newAppend()
for (dataFile in writeResult.dataFiles()) {
append.appendFile(dataFile)
}
append.commit()writerの準備で書き込むファイル形式や1つのファイルにどれだけのデータを書き込むかといった指定を行った後に writer.write()でレコードの書き込みを行っています。writer.completeでwriterの終了を行っていますが、この時点でデータファイル(例えばParquetファイル)の書き込みが完了してwriteResultにはそのファイルの一覧が格納されているため、次にAppenderを用意してwriteResultの中に入っているファイルパスの一覧をAppenderに書き込みしてappend.commitでmetadataへの書き込みを完了させます。
Java Clientでの読み取りは主にTableScan(ファイル単位)とTableScanIterable(行単位)の2つの読み取り方が用意されています。以下はファイル単位の読み出しの例ですが、filterで絞り込み条件を記述したうえでselectでどのカラムを呼び出すかを指定しています。.planFiles()を実行することでParquet, Avroといったデータファイルの一覧を取得することが出来ます。.planTasks()とすることで、.planFiles()よりも少しまとまった単位で大小のファイルを組み合わせたタスクのグループを返してくれるような API になっています。
val scaner = table.newScan()
.filter(Expressions.equal("id", 5))
.select("id", "name", "age")
val files = scan.planFiles()
val tasks = scan.planTasks()次に行単位の読み出しですが、こちらも同様にフィルターの条件を指定しています。結果はイテレータとなるので、 forループ などでレコードを読み出すことが可能です。
val result = IcebergGenerics.read(table)
.where(Expressions.lessThan("id", 5))
.build()このようにJava Clientでは少しプリミティブな、クエリエンジンが内部で使うようなAPIが公開されています。
ログ基盤のモデリング例
試しに今までの知識を使って簡単にログ基盤のモデリングを行ってみます。大まかな仕様としてはテナントIDごとにストア・クエリは分離しています。そしてログは例えば10月3日から4日というように時系列順でクエリされることが非常に多いです。そのため、テーブル定義ではtenant, timestampを元にパーティションを毎日生成しています。100テナント存在することを仮定すると1年間で36,500のパーティションが生成されます。多くの場合はtimestampを元に時系列順でクエリを行うことからsorted_byをtimestampに対して指定を行いました。
timestampに対してwhereの絞り込みを行うとpartitioningとsorted_byの両方のフィルタリングが行われるためクエリーパフォーマンスが上がりそうです。また、スキーマは後から変更可能であることから利用しながら環境に合わせていくのが良いと思います。
CREATE TABLE log_store (
tenant INTEGER,
timestamp TIMESTAMP(6),
level INTEGER,
-- DEBUG:0, INFO:1, WARN:2, ERROR:3
message VARCHAR
) WITH (
partitioning = ARRAY[
'tenant',
'day(timestamp)'
],
sorted_by = ARRAY[
'timestamp'
]
);ログ基盤の全体構成
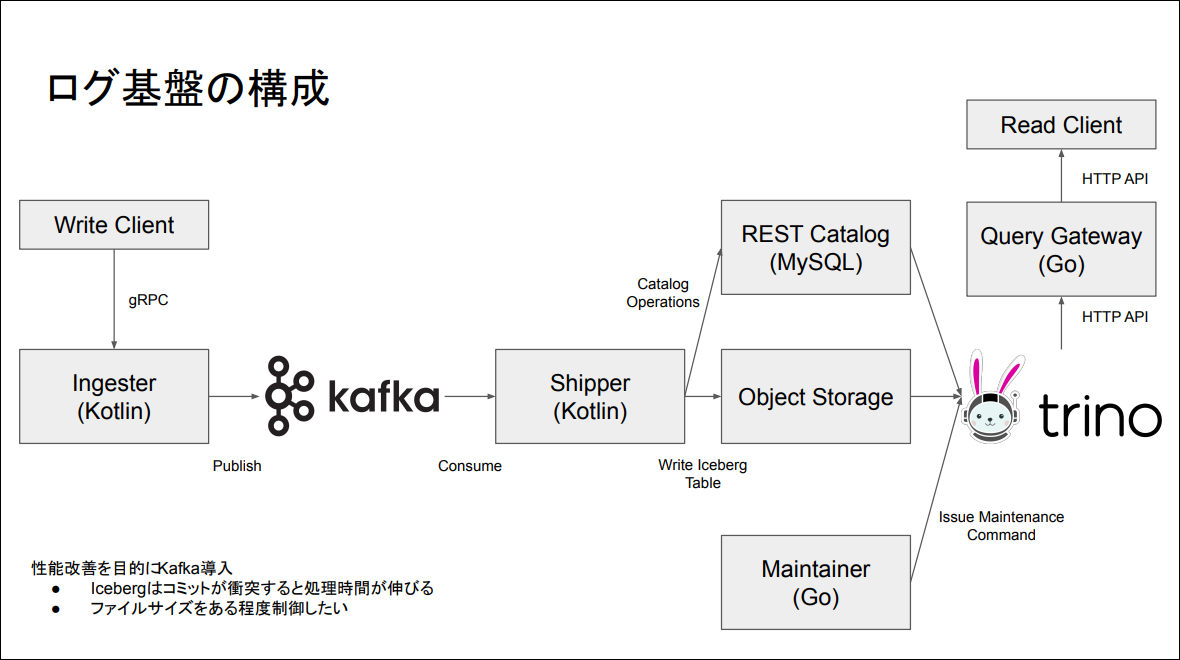
現在弊社で開発中のログ基盤は全体的にこのような構成になっています。gRPCのクライアントは例えばFluent BitやFluentdといったクライアントになります。クライアントがIngesterというコーポネントにログを投入するとkafkaにProtocol Buffersのバイト列がそのままPublishされます。そしてShipperというコンポーネントがkafkaからある程度の大きさの単位をバッチでConsumeしたうえでIcebergに書き込みを行います。CatalogはMySQLをバックエンドとしたREST Catalogで、メタデータとデータは社内のObject Storageに書き込みます。そしてクエリを発行する際はQuery Gatewayというコンポーネントを通じてTrinoにSQLクエリを発行し、Object StorageとCatalogの情報をもとにデータを取得します。定期的なメンテナンスについてはMaintainerというコンポーネントがTrinoにメンテナンスコマンドを発行することで行う予定です。
Icebergに直接メッセージを書き込まず kafka を通した意図ですが、Icebergのコミットはタイミングが衝突すると再試行を行うといった仕様になっています。その際にコミットの時間が増えてしまうという性質があることから、できるだけコミットの衝突を行いたくないといった抑制を行っています。また、小さなファイルがたくさん作られるとパフォーマンス・クエリパフォーマンスの劣化が懸念されます。この2点の理由からある程度の大きさになってからIcebergのテーブルに書き込むという構造を取っています。
TrinoとIcebergが本当に高性能なため、書くコードが少なくなっているという印象を持っています。
まとめ
Icebergはトランザクション等の機能を持つ高性能なストレージフォーマットです。内部構造に関しても階層構造を持っていることからその見通しが非常に良かったかなと思います。またIcebergはTrinoから簡単に扱えますし性能チューニングもSQLから簡単に行えることが分かりました。こういった性質から弊社では開発中の社内向けのログ基盤にIceberg, Trinoを採用しています。
環境の公開
本記事の環境はGitHubのリポジトリにアップしており、簡単に試すことができます。階層構造になっているmetadataの中身なども確認可能ですので、ご興味のある方はぜひ触ってみていただければと思います。
【今回紹介した内容が一通り試せるDocker Compose構成】
リンク:https://github.com/kamijin-fanta/iceberg-sandbox-kit
Linuxマシンでgit clone, makeだけでクラスタが起動
■ Trino, Iceberg REST Catalog, MySQL, MinIO
■ デバッグ用コンテナに avrocat, jq, pqsr等がインストール済み
※詳しい使い方はREADME.md参照