さくらのクラウドでHadoop/Spark/Asakusa環境を構築する(1) ~Hadoopインストール編~
はじめに
さくらのナレッジをご覧の皆様、はじめまして。 株式会社ノーチラス・テクノロジーズ の川口と申します。
この連載では、さくらのクラウド上に分散処理基盤用のフレームワーク Hadoop、Spark の環境を構築して、 この環境上でいくつかのアプリケーションを実行する方法を紹介します。
また、HadoopやSpark上で動作し、複雑なバッチ処理の開発に向いているバッチアプリケーション開発フレームワーク Asakusa Framework の使い方を紹介します。
HadoopやSparkがどのようなものかは、インターネット上に豊富な情報があるのでそちらを見て頂くとして、 この連載ではこれらのプロダクトを使い始めるまでの具体的な手順を中心に書いていきたいと思います。
HadoopやSpark、Asakusa Frameworkをよく知らない方や始めてさわってみる、 という方にでもわかりやすいように、各手順をなるべく丁寧に解説していきますので、 お付き合いのほど、よろしくお願いします!
この連載は全3回で、以下の内容を予定しています。
- ~Hadoopインストール編~さくらのクラウド環境に準備したサーバ群にHadoopをインストールしてHadoopクラスタ環境を構築します。この連載では、Hortonworks が提供するHadoopディストリビューション Hortonworks Data Platform (HDP) を使ったHadoopのインストール方法を紹介します。
- ~Sparkのセットアップと実行編~HadoopクラスタにSparkをセットアップして、HadoopとSparkを連携するための設定を行います。 そして、Sparkが提供するSQL実行エンジンSpark SQLや、 ストリーム処理エンジン Spark Streaming の使い方などを紹介します。 また、Sparkが提供する管理機能の使い方などを紹介します。
- ~Asakusa Frameworkのセットアップと実行編~Hadoopクラスタ環境にAsakusa Frameworkをセットアップして、バッチアプリケーションを実行する方法を紹介します。Asakusa Frameworkの概要や、Hadoop MapReduceやSpark上でそれぞれバッチアプリケーションを実行する方法を紹介します。 また、HiveやSpark SQLといったSQL実行エンジンとの連携などを紹介します。
サーバ構成
この連載では、さくらのクラウドに以下のような構成でサーバやネットワークを準備したものとして説明していきます。
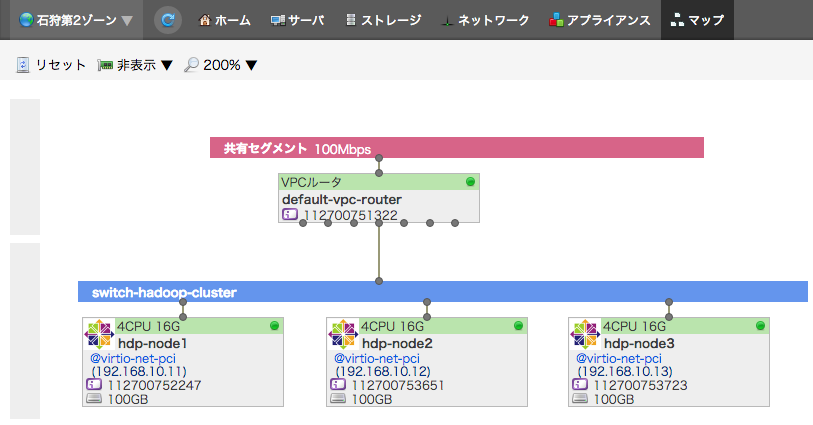
同一のネットワーク上に3台のサーバを配置し、それぞれCentOS 7用のアーカイブを使ってOSをセットアップしています。
また今回の構成では VPCルータを使用して、VPC環境としてHadoopクラスタ環境を構築します。 今回のように複数台から構成されるサーバ環境をクラウド上で試す際には、セキュリティに関する検討が苦労しがちかと思いますが、 さくらのクラウドが提供するVPCルータを使うことで、セキュアなサーバ環境を比較的容易に構築することができるようになります。
なお、筆者はさくらのクラウドの他にも様々なクラウドサービス上にHadoopクラスタを構築していますが、 さくらのクラウドはVPCルータを使ってVPC環境を簡単に構築できる、という点が特徴的であると感じています。 さくらのクラウドやVPCルータを使ったことがない方は、これを機に使ってみてはいかがでしょうか。
サーバ環境の準備
以降で紹介する手順については、サーバ環境が以下の条件を満たしている必要があります。
- サーバ間でパスワードなしのSSH接続が可能である
- サーバ間でホスト名が解決ができるようになっている
- サーバ間でインストールに必要なポートがブロックされていない
- firewalld (iptables) などにより意図せず必要なポートがブロックされないよう注意してください
- 環境上の問題がなければ、一時的に firewalld やiptables を無効にしておきます
- SELinuxが無効になっている
- NTPが有効になっている
Hadoopのインストール前に、サーバ環境がこれらの条件を満たすよう設定しておいてください。
サーバの前提条件を詳細に確認したい場合は、以下のドキュメントを参照してください。
Ambari Documentation: 4. Prepare the Environment
Ambariを使ったHadoopクラスタの構築
AmbariはHadoop用の運用管理ツールです。HadoopクラスタをWeb画面からウィザード形式でインストールできたり、 Hadoopクラスタの状況を把握するためのダッシュボード画面、 Hadoopクラスタの各種設定やホストの追加や停止などのメンテナンス機能、モニタリング機能などを提供します。
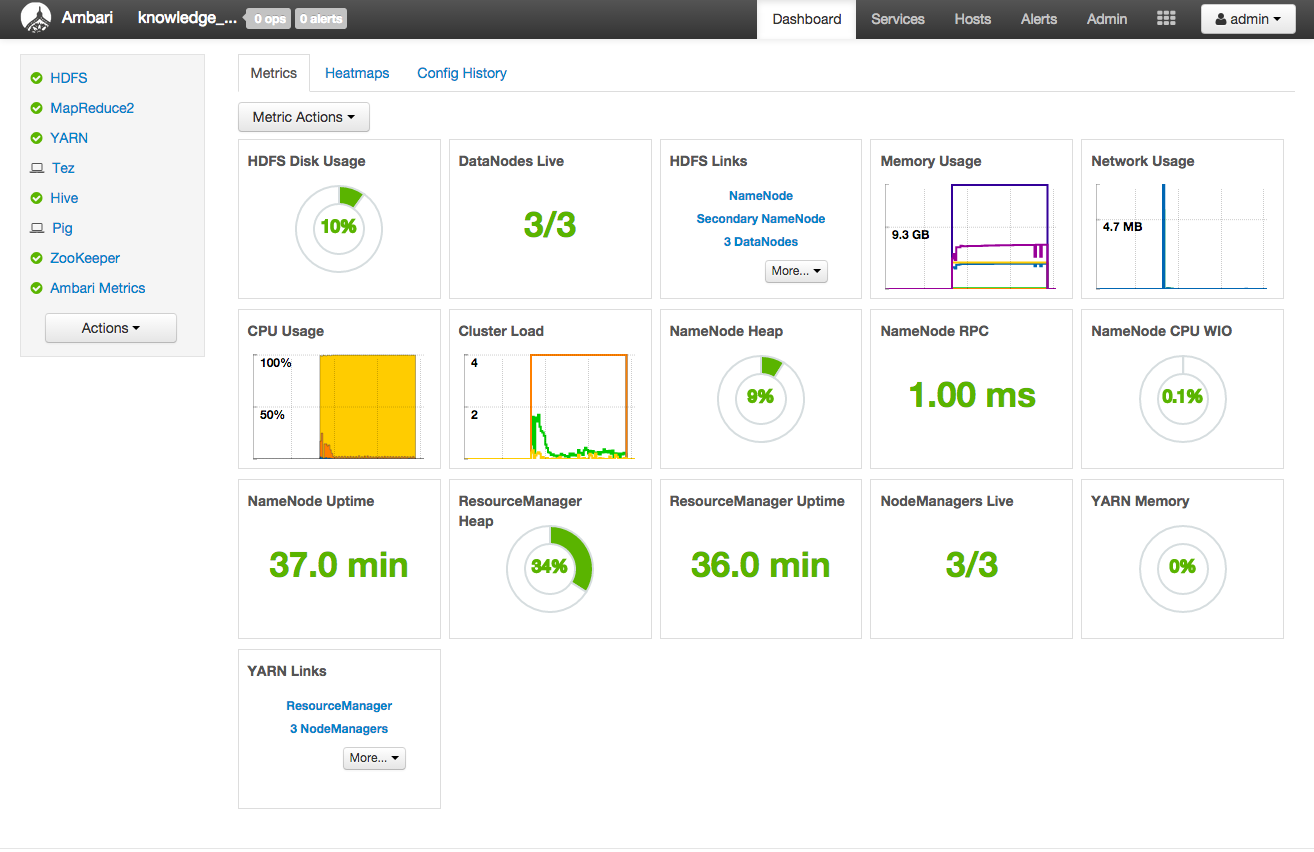
以下はAmbariのダッシュボード画面の例です。 ダッシュボード画面は各種リソース使用状況や異常が発生しているノードの有無、 各種管理機能へのリンクなどを表示します。 ダッシュボード画面をはじめ、いくつかの画面は利用形態に応じたカスタマイズが可能です。
また、AmbariはシェルやRest API経由で操作を実行することも可能で、 運用自動化のためのプラットフォームとしても機能します。
今回はAmbariのインストールウィザード使ってHadoopクラスタを構築する方法を紹介します。
Ambariのインストール
それではまず、Ambariの管理機能を担うAmbariサーバをセットアップしていきます。
AmbariサーバをHadoopクラスタとして用意したマシンのいずれかにインストールします。 今回はサーバ「hdp-node1」上にインストールします。
hdp-node1にrootでログインし、以下の手順でセットアップしていきます。
wget が入っていない場合、 wget をインストールします。
Ambari用のyumリポジトリを登録します。
Ambariサーバをインストールします。
Ambariサーバのセットアップを開始します。ambari-server setup はいくつかの設定を対話式に実行していきます。
ユーザアカウントのカスタマイズを行うかどうか。今回はデフォルトのままでセットアップします。
Hadoopクラスタで使用するJDKを選択します。今回はJDK 8を選択します。
JDKの利用に関するライセンス条項に同意するかの確認です。問題なければ次へ進みます。
and not accepting will cancel the Ambari Server setup and you must install the JDK and JCE files manually.
Do you accept the Oracle Binary Code License Agreement [y/n] (y)?
HDPで使用するデータベースのカスタム設定を行うかどうか。今回はデフォルトのままでセットアップします。
Ambariサーバのセットアップが実行されます。 セットアップに成功すると、以下のように出力されます。
Ambariサーバの起動
Ambariサーバのセットアップに成功したら、Ambariサーバを起動します。
Ambariサーバの起動に成功すると、以下のように出力されます。
なお、Amabriサーバの起動ステータスの確認、停止はそれぞれ以下のコマンドで実行できます。
ambari-server statusambari-server stop
Hadoopクラスタのインストール
それでは、Ambariのインストールウィザードを使ってHadoopクラスタをインストールしてみましょう。
ブラウザで http://[Ambariサーバホスト名]:8080 にアクセスすると、Ambariのログイン画面が表示されます。
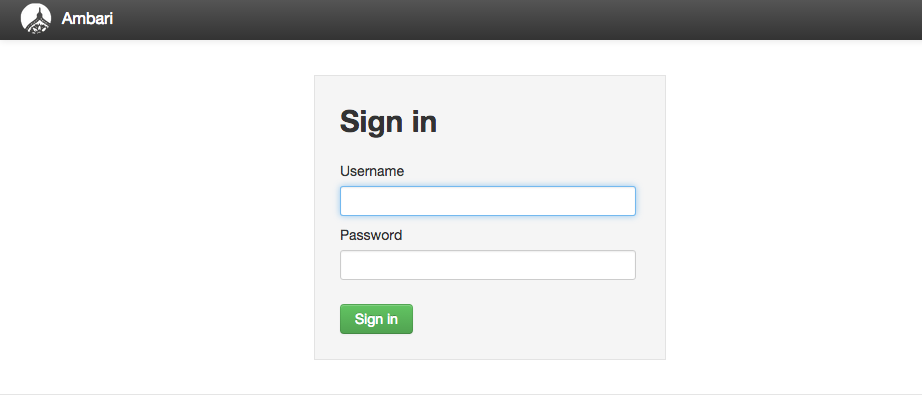
デフォルトで用意されている管理ユーザー名は admin で、パスワードも admin です。 ログインに成功するとWelcome画面が表示されます。
クラスタを新規作成するには画面中央の「Launch Install Wizard」ボタンを押下します。
「Get Started」画面ではクラスタ名を入力します。クラスタ名は任意の名前でOKです。 今回は knowledge_sakura という名前でクラスタを作成します。
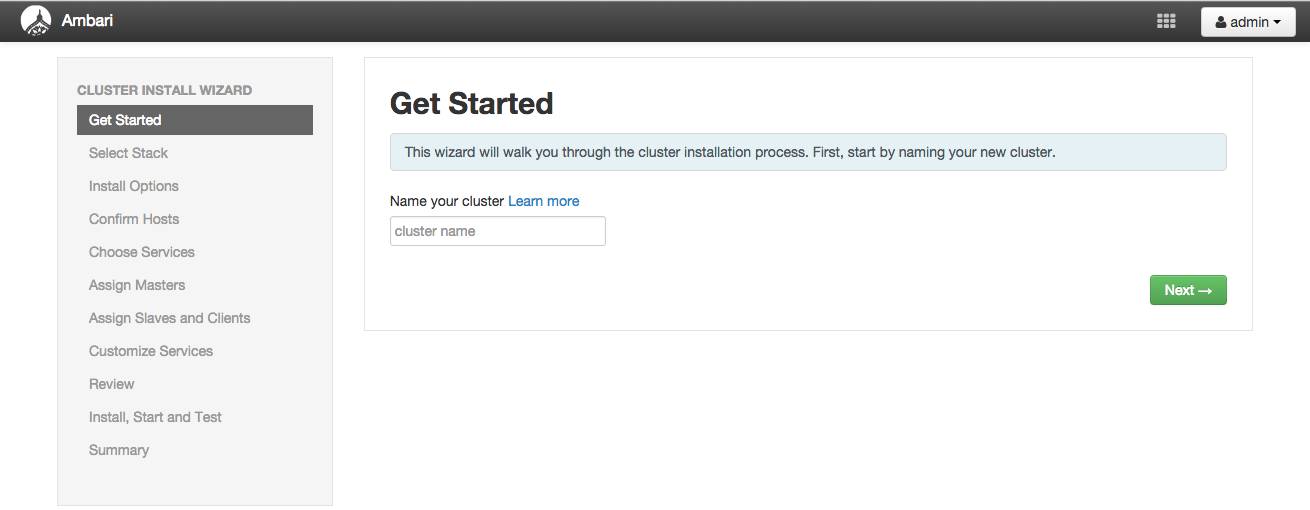
「Select Stack」画面ではインストールするHDPのバージョンなどを選択できます。 今回は本書の執筆時点では最新の「HDP 2.3」を選択します。
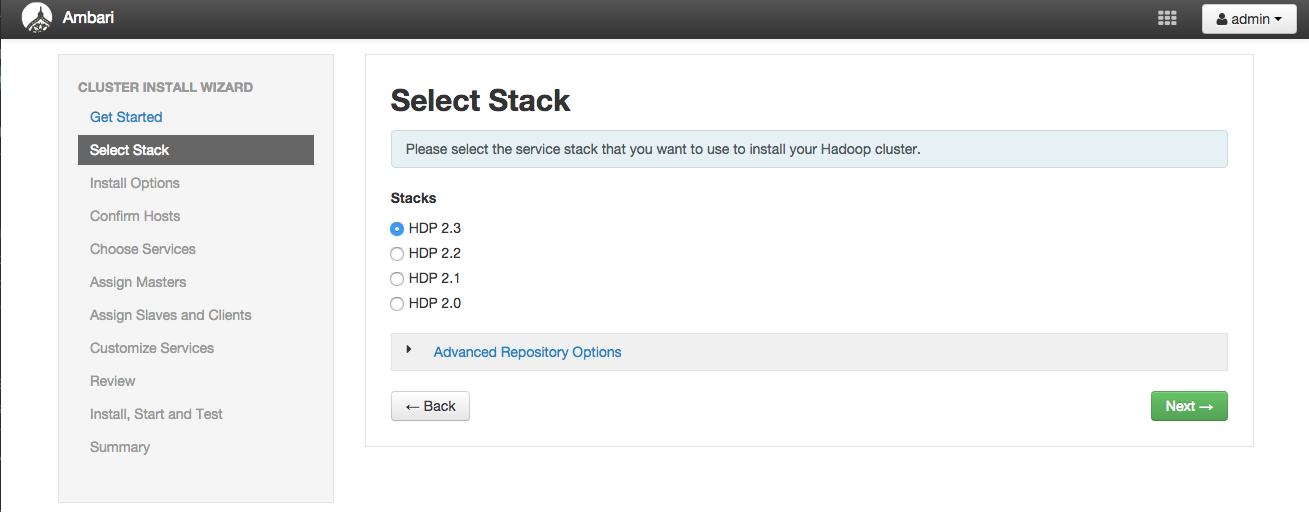
「Install Options」画面ではインストール対象となるホストの情報などを入力します。
「Target Hosts」欄ではHadoopクラスタに追加するホスト名を入力します。 1行に1ホスト名を入力します。 今回は先述のサーバ構成で紹介したサーバ構成に従って以下のホスト名を入力します。
hdp-node1hdp-node2hdp-node3
「Host Registration Informatation」欄ではAmbariサーバからHadoopクラスタの各ホストに接続するための認証情報を指定します。 今回は公開鍵認証方式でAmbariサーバと各ホストを認証するため 「Provide your SSH Private Key ot automatically register hosts」を選択し、秘密鍵の内容をテキストエリアに入力します。
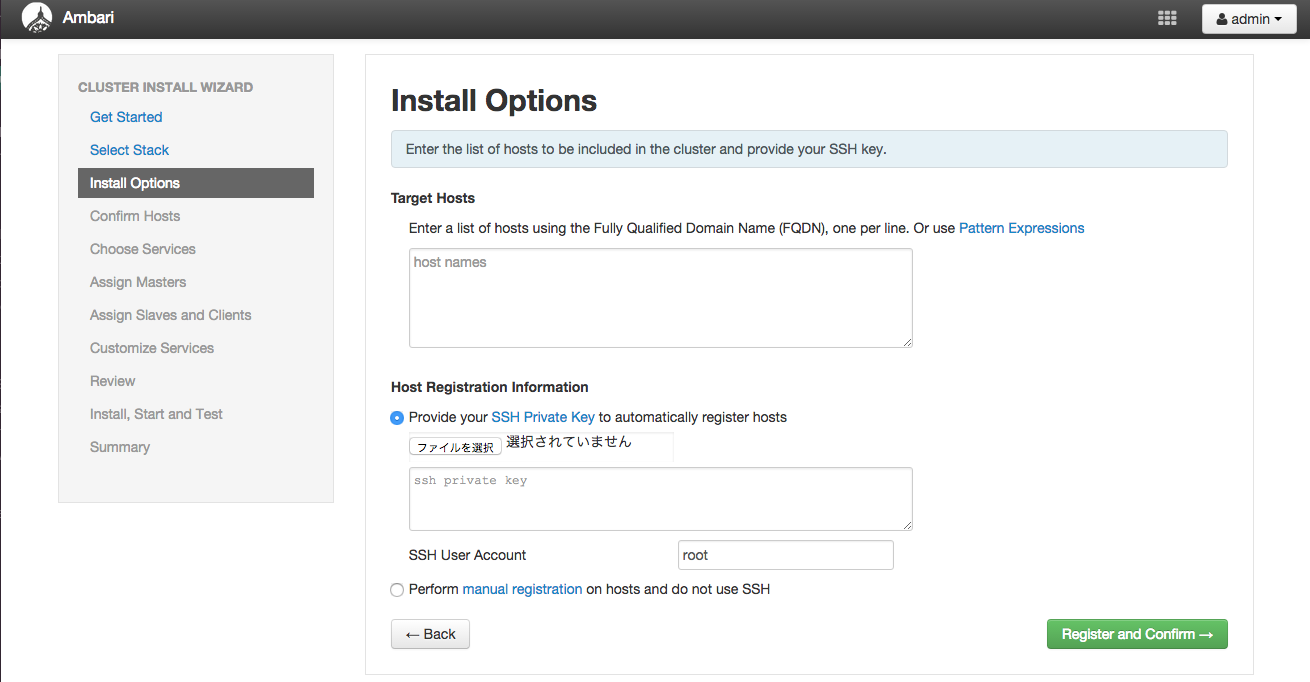
ホスト情報と認証情報を入力して「Register and Confirm」ボタンを押下すると、 各ホストへHDPモジュールのインストールが開始されます。
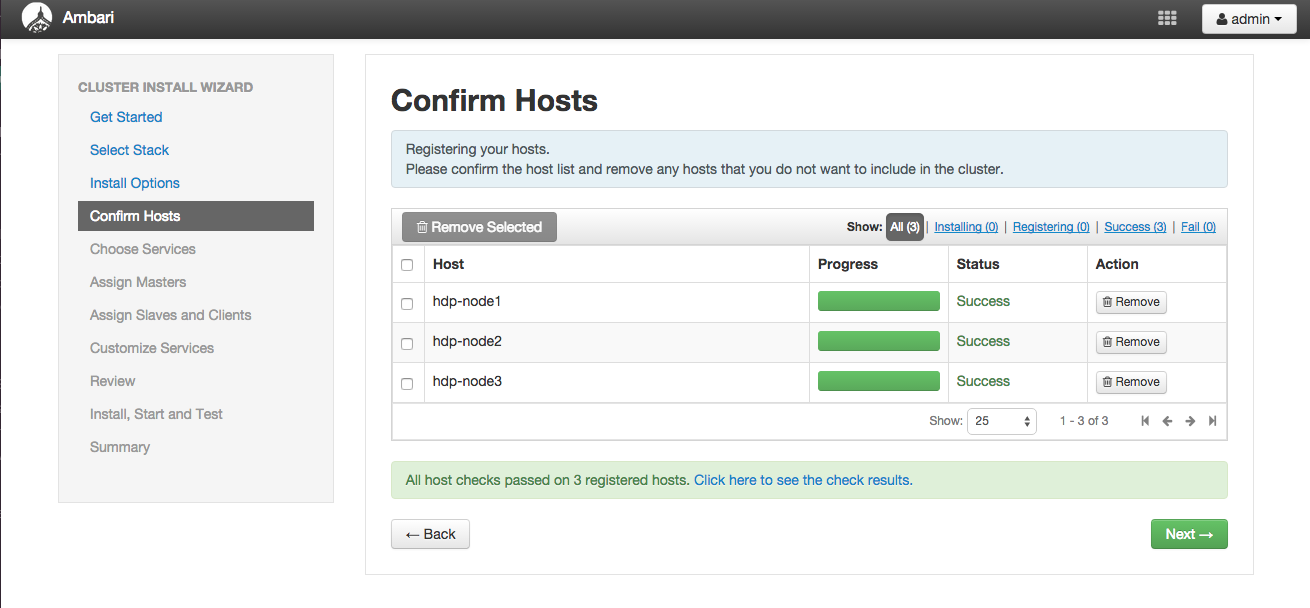
「Confirm Hosts」画面では各ホストのインストール状況が表示されます。 各ホストのStatusが「Succuess」になればインストールが成功です。
もしインストールが失敗した場合はホストの設定などを見直してください。 インストールをリトライするには、前の画面に戻って再度「Register and Confirm」ボタンを押下します。
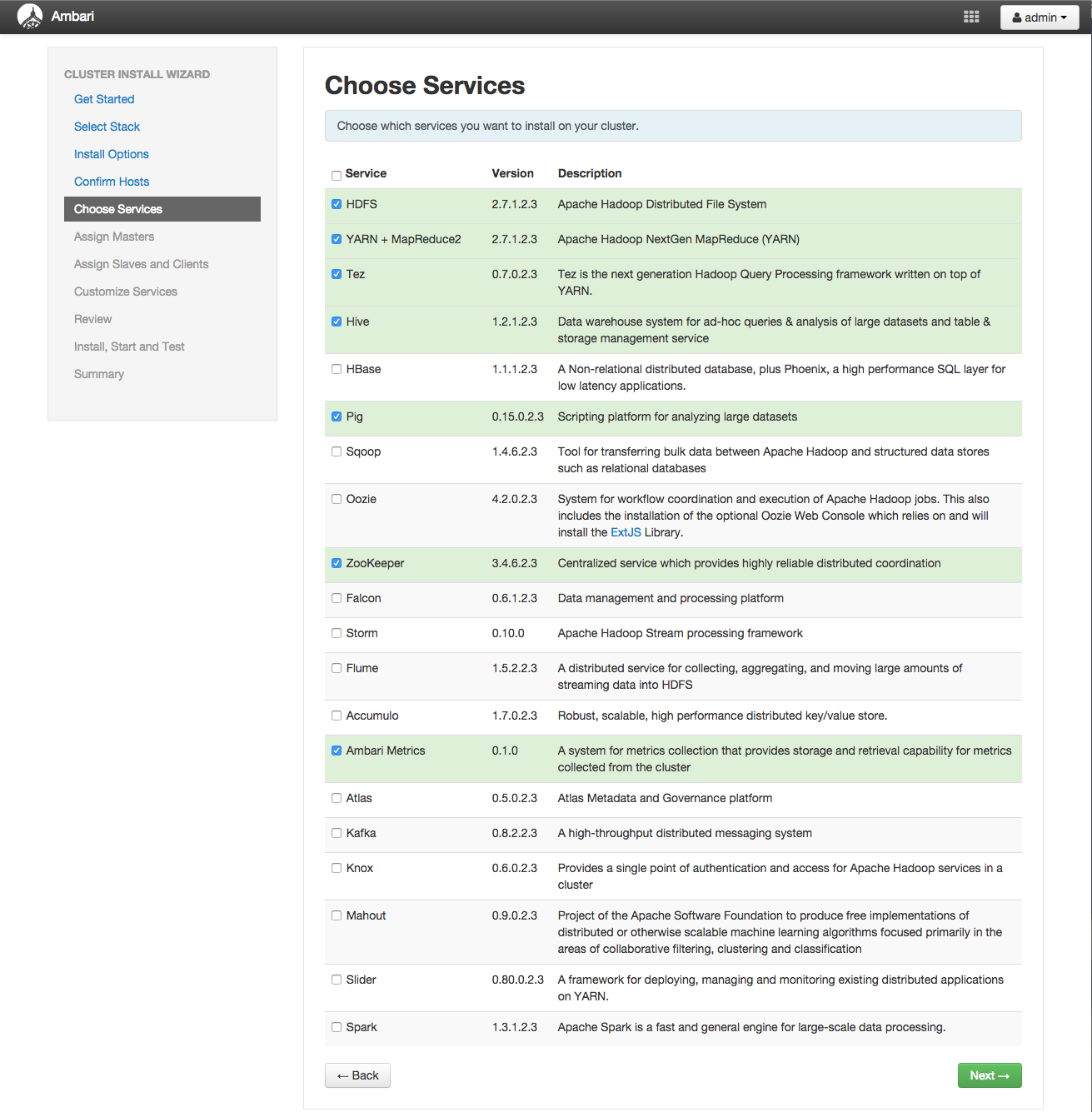
「Choose Services」画面では、Hadoopクラスタで利用するサービスを指定します。 ここで指定したサービスが最終的なインストールプロセスでセットアップされます。
今回は、以下のサービスをセットアップします。
- HDFS
- YARN + MapReduce2
- Tez
- Hive
- Pig
- Zookeeper
- Ambari Metrics
Sparkについては後ほどHDP標準のバージョンではなく最新版をインストールするため、ここではセットアップ対象から外します。
なお、いくつかのサービスは直接利用しなくても、他のサービスが依存しているためセットアップ対象に含める必要があります。
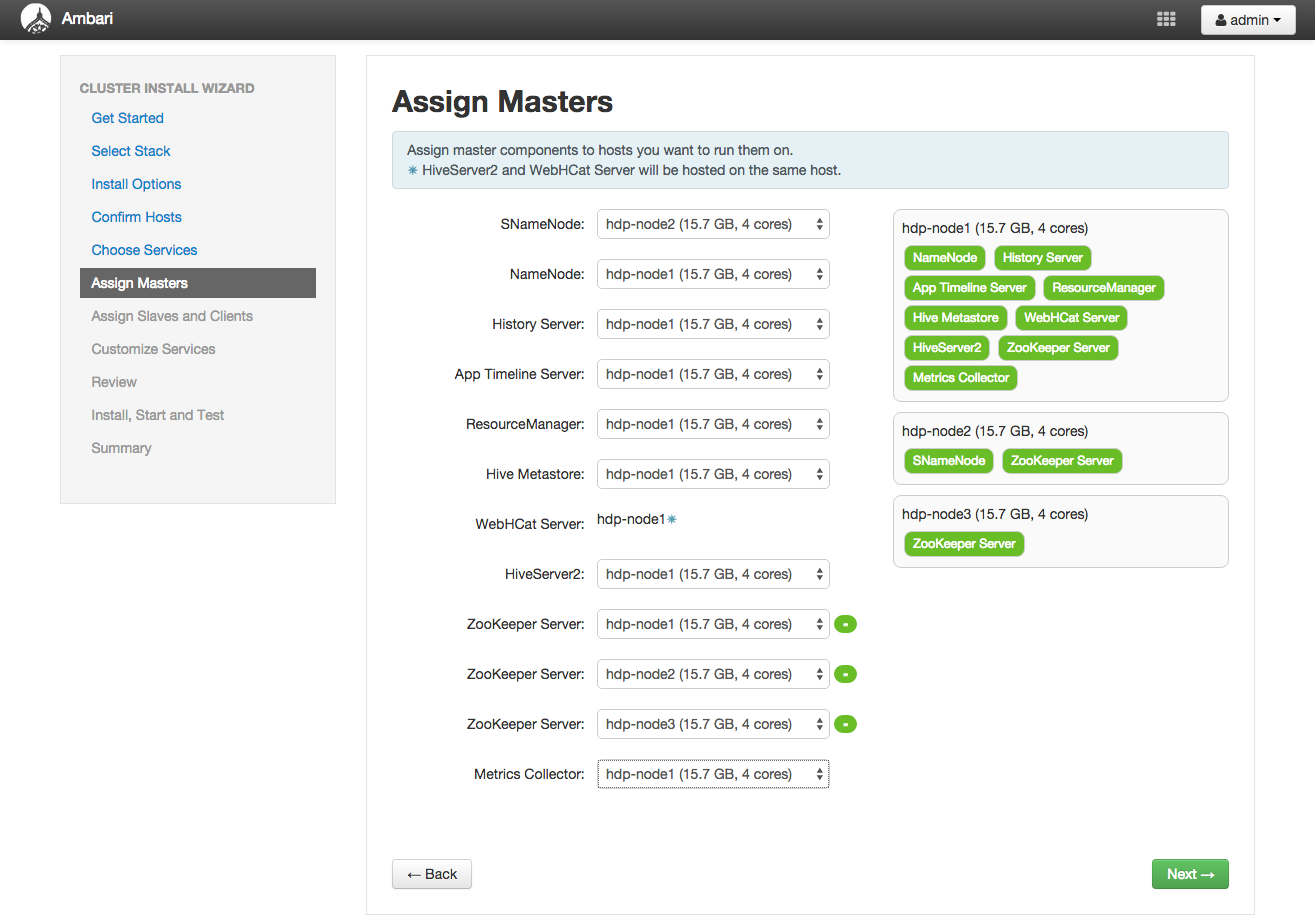
「Assign Masters」画面ではマスターとなるコンポーネントをどのノードに配置するかを指定します。
Hadoopのサービスやコンポーネントのうち、Hadoopクラスタ全体を管理するような性質をもつものをマスターと呼び、 マスターとなるサービス群やコンポーネントで構成されたノードをマスターノードと呼びます。
今回は、以下のような方針でマスターを配置します。
- マスターノードは「hdp-node1」とする。各マスターサービスはhdp-node1に配置する。
- ただし、SNameNode(セカンダリネームノード)はNameNode(ネームノード)を配置するノードとは別にする必要があるため「hdp-node2」に配置する。
- ZooKeeper Serverは最低3ノード分必要なため、今回は全てのノードを指定する。
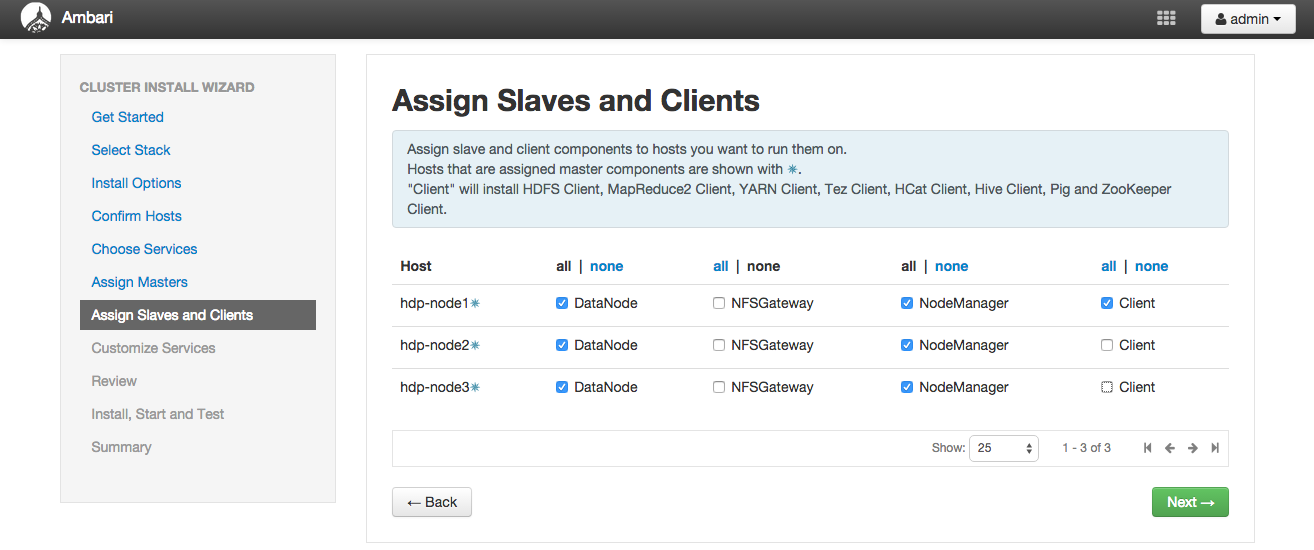
「Assign Slaves and Clients」画面ではスレーブとなるコンポーネント、クライアント用のコンポーネントをそれぞれどのノードに配置するかを指定します。
マスターに対して、Hadoopクラスタの個々のノードで分散処理を実行ためのサービスやコンポーネントをスレーブと呼び、 スレーブとなるサービス群やコンポーネントで構成されたノードをスレーブノードと呼びます。
また、Hadoopに対してジョブの実行をリクエストするためのコンポーネントがクライアントです。 クライアント用のコンポーネントはマスターノードやスレーブノード上に配置しても、 完全に独立したノードに配置してもかまいません。
今回は、以下のような方針でスレーブやクライアントを配置します。
- スレーブノードは今回準備したサーバ3台すべてに構築する。「hdp-node1」はマスターノードとスレーブノードを兼ねる。
- クライアントは「hdp-node1」とする。
- NFSGatewayは今回は使用しないのではずす。
なお、今回は台数が少ないためマスターノードはスレーブノードを同じサーバ上に構築しますが、 大規模なHadoopクラスタの場合はマシンリソースや運用面などを考慮すると、 スレーブノードとは独立したサーバ上に構築することが望ましいと思います。
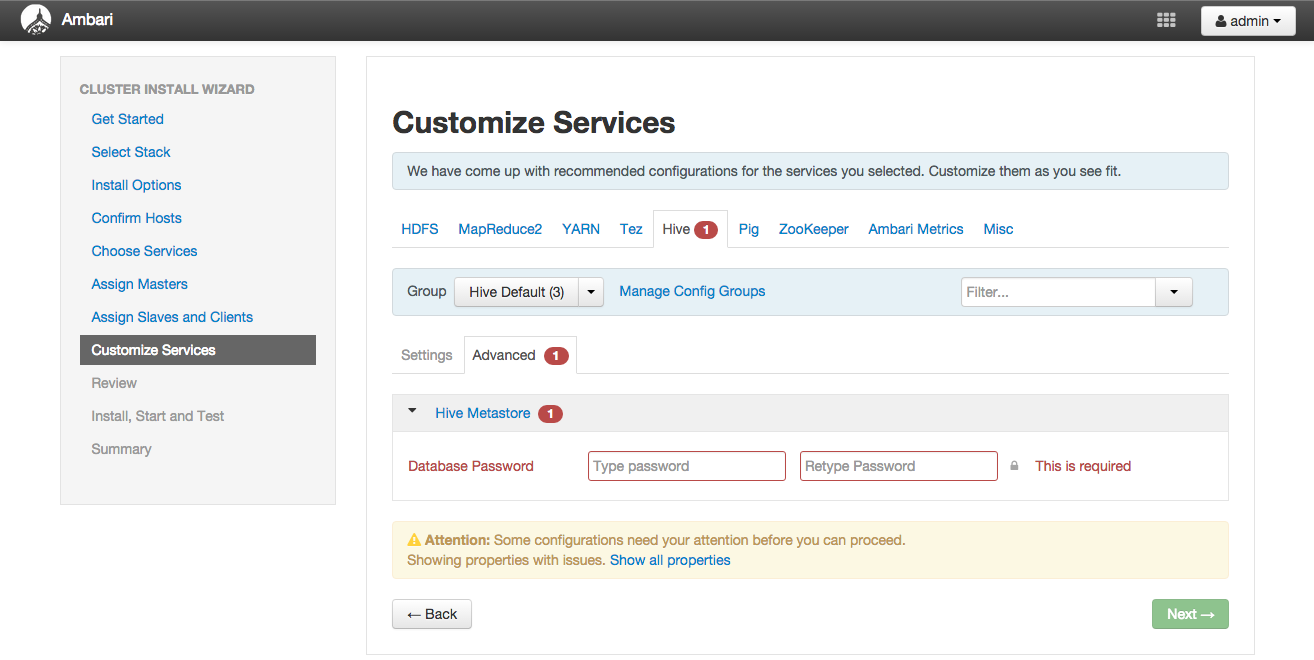
「Customize Services」画面ではHadoopクラスタの詳細な設定を行うことが出来ます。
今回は細かい設定手順は省略し、デフォルトの設定でセットアップします。 ここで設定可能な項目はインストール後にもAmabriの管理画面から変更することが可能です。
ただし、HiveメタストアDBのパスワードだけはインストール時に指定が必須であるためここで入力します。 「Hive」タブを選択して「Database Password」欄に任意のパスワードを指定してください。
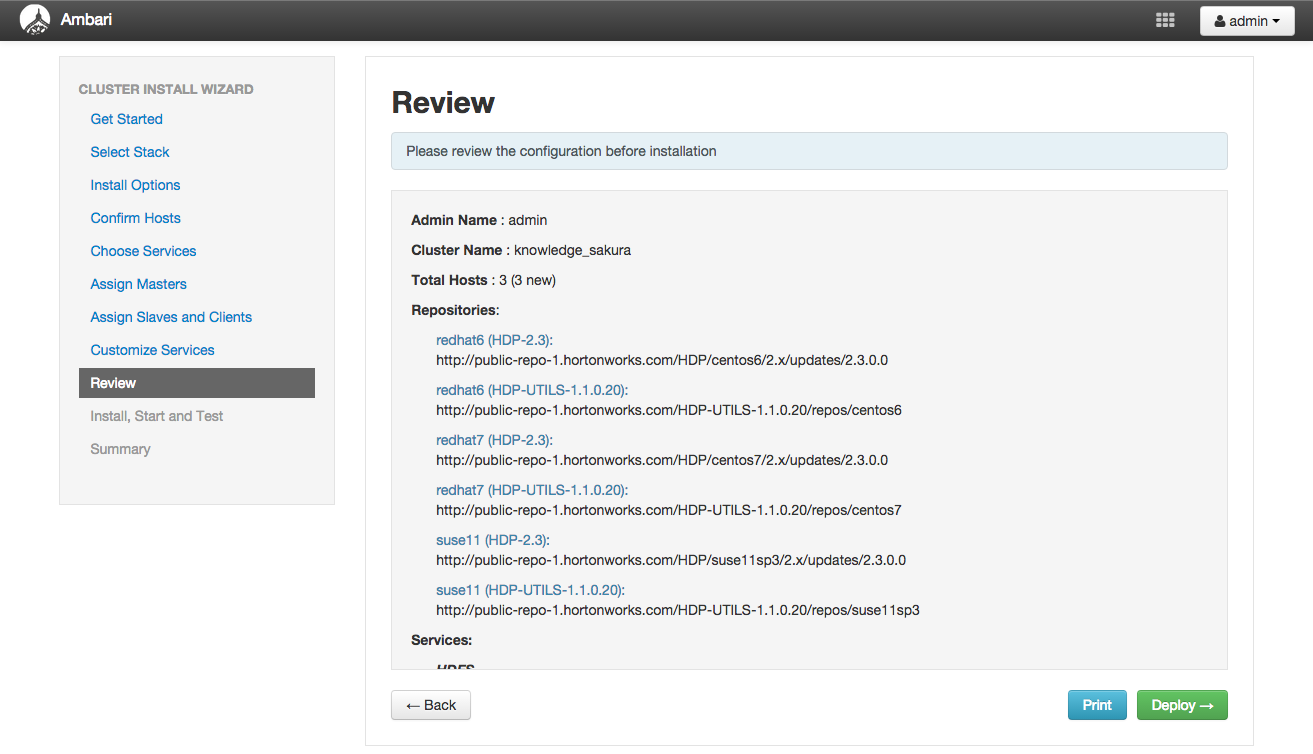
「Review」画面ではセットアップ内容の確認が出来ます。問題がなければ「Deploy」ボタンを押下してインストールを実行します。
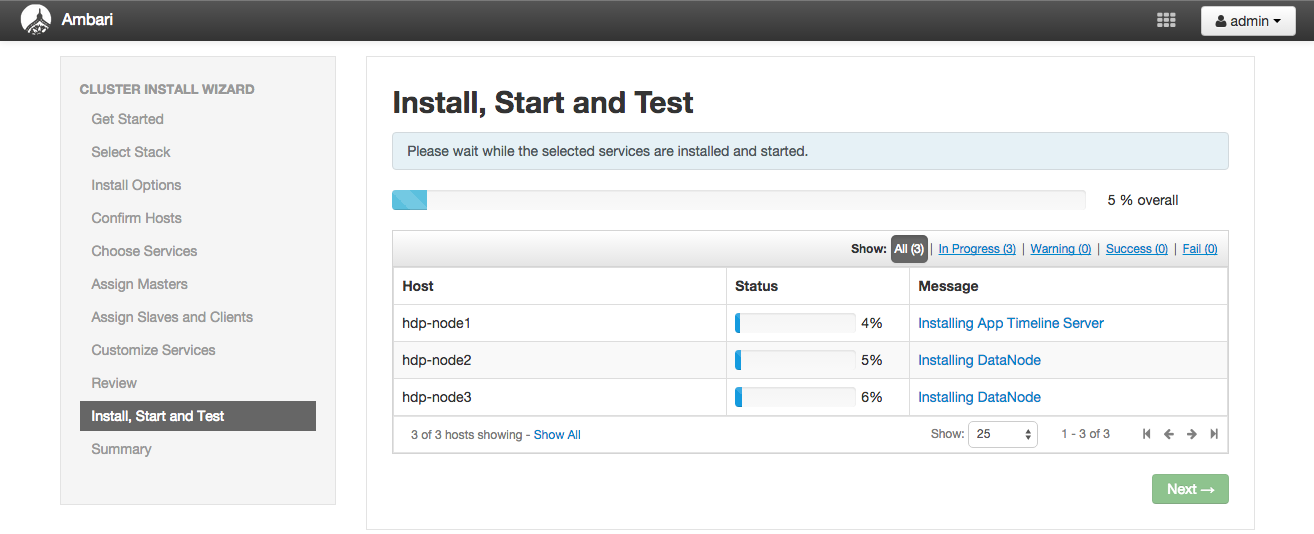
インストールが開始されます。環境にもよりますが10〜20分程度かかります。
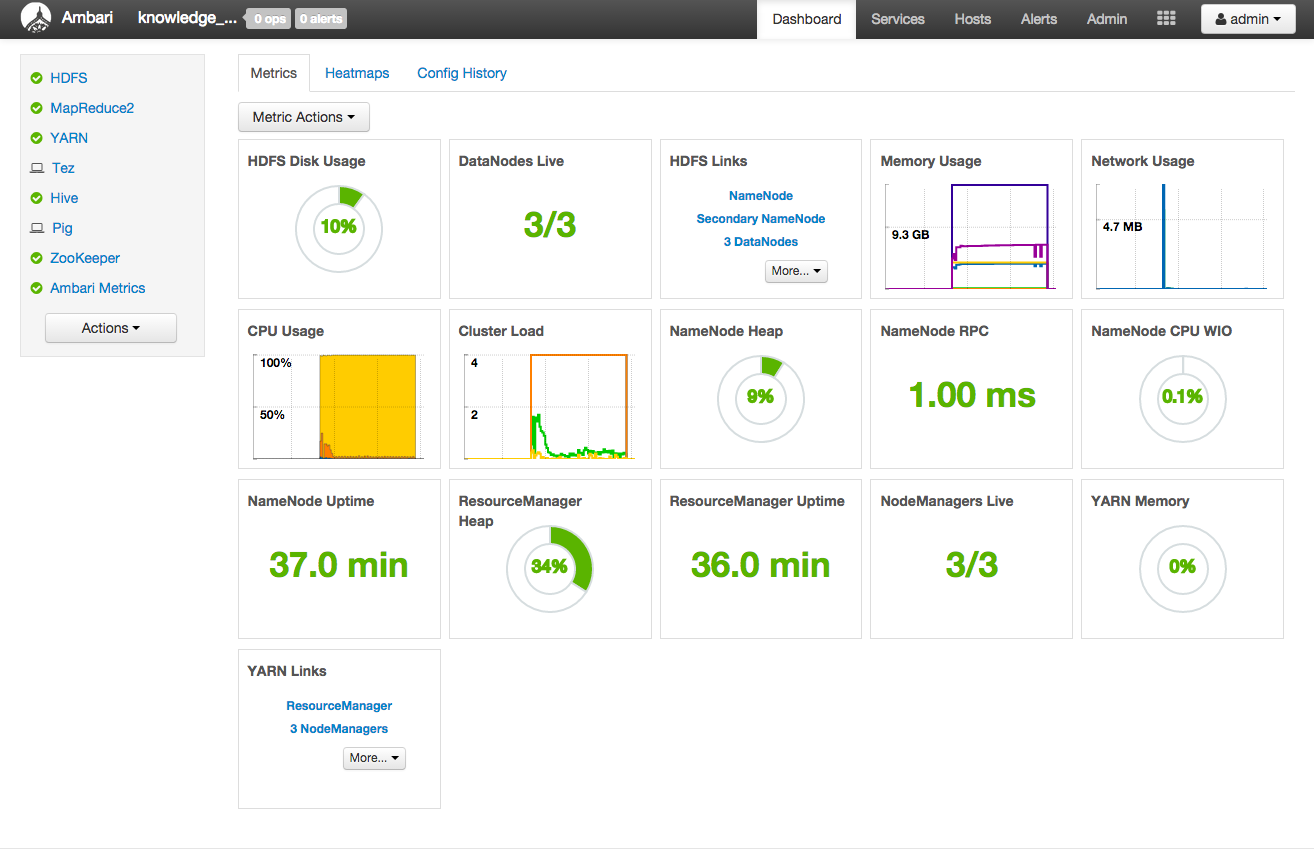
インストールが成功すると、以下のようなAmbariのダッシュボード画面が表示されます。
終わりに
今回はさくらのクラウドにサーバ環境を準備し、Ambariを使ってHadoopクラスタをセットアップするところまでを紹介しました。
次回は、このHadoopクラスタにSparkをセットアップし、いくつかのSparkアプリケーションを実行する方法を紹介します。