自作パケット処理系の性能測定と可視化&改善のPDCAを回して最強のパケット処理系の作り方を学ぼう

2023年10月27日(木)-28日(金)に開催されたPyCon APAC 2023にて「自作パケット処理系の性能測定と可視化&改善のPDCAを回して最強のパケット処理系の作り方を学ぼう」と題して発表しました。
今日では自作パケット処理系に関しての情報が世の中に多くなり開発の敷居が低くなってきていますが、開発したモノを更により良くするためのカイゼンに関する情報はまだまだ少ないと感じています。そこで自作したPGW-Uと呼ばれるパケット処理系の開発とカイゼンを通じて得た知見を元に登壇発表することにしました。
この発表を通じて自作パケット処理系を行う人・行った人が開発の第二段階であるチューニング等のカイゼン方法を得ることが出来たら嬉しいです。
事前知識としてモバイルのコンテキストの説明をします。
基本的なLTEアーキテクチャは下図のとおりです。パケットはUEから基地局やMMEを通りSIMに含まれる鍵で認証を実施し、セッション確立後SGWを通ってインターネットに出ます。 詳しく3GPP TS23.401とGSMA IR88を参照してください。
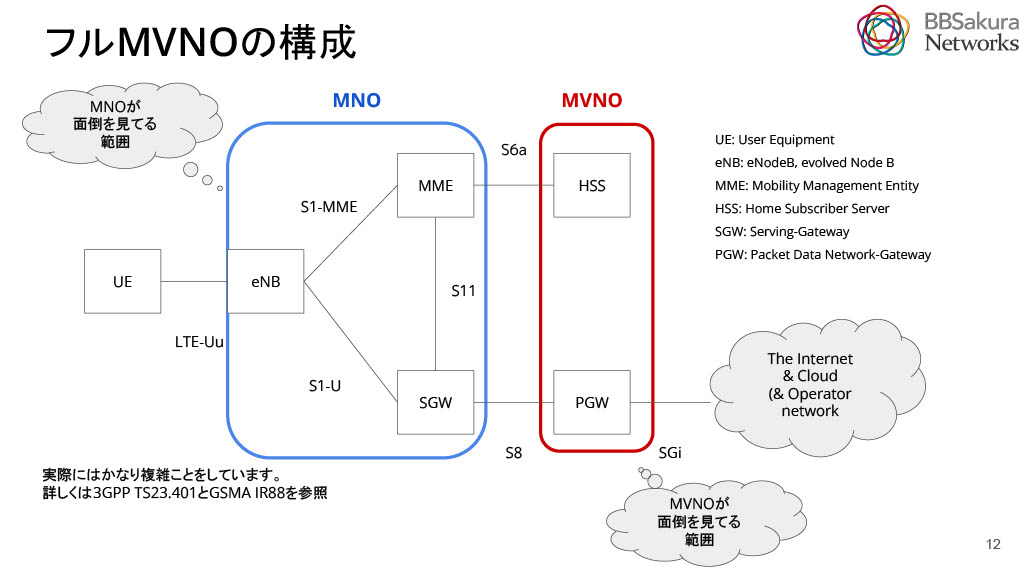
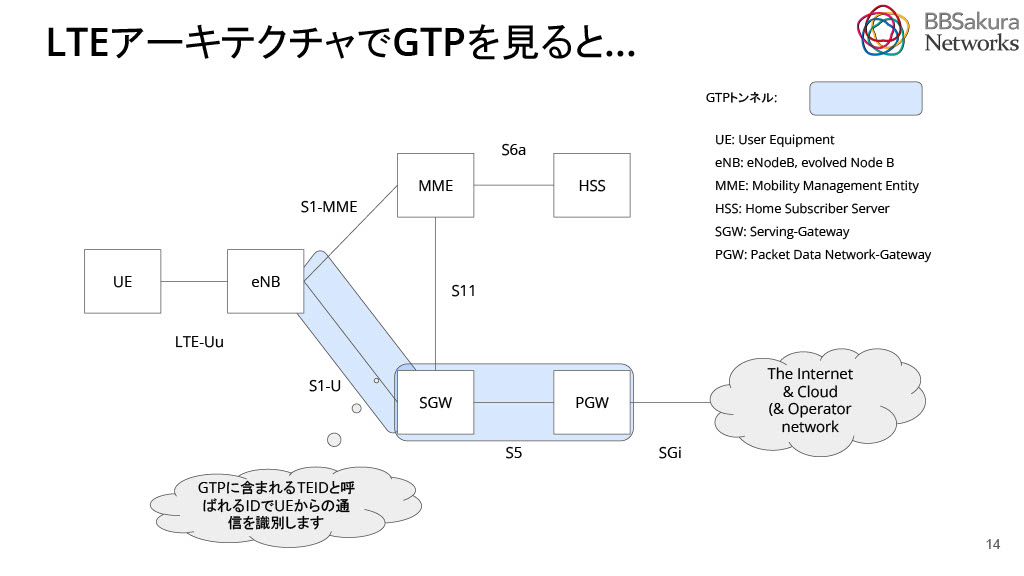
PGWとは、インターネットやクラウド網へ通信するためのゲートウェイです。GTPとよばれるトンネルプロトコルの終端で、モバイルユーザが移動しても通信がつながり続けるハンドオーバーの仕組みを実現しています。TEIDとよばれるIDを利用しユーザ通信を識別することで、トラフィック計測に基づく課金を実現することができます。ユーザのインターネット接続通信パケットはすべてPGWを経由するため、これにより高負荷になる傾向があります。そのため、PGWの性能を引き出すことで、ユーザにとって快適な接続性を提供できるようになります。
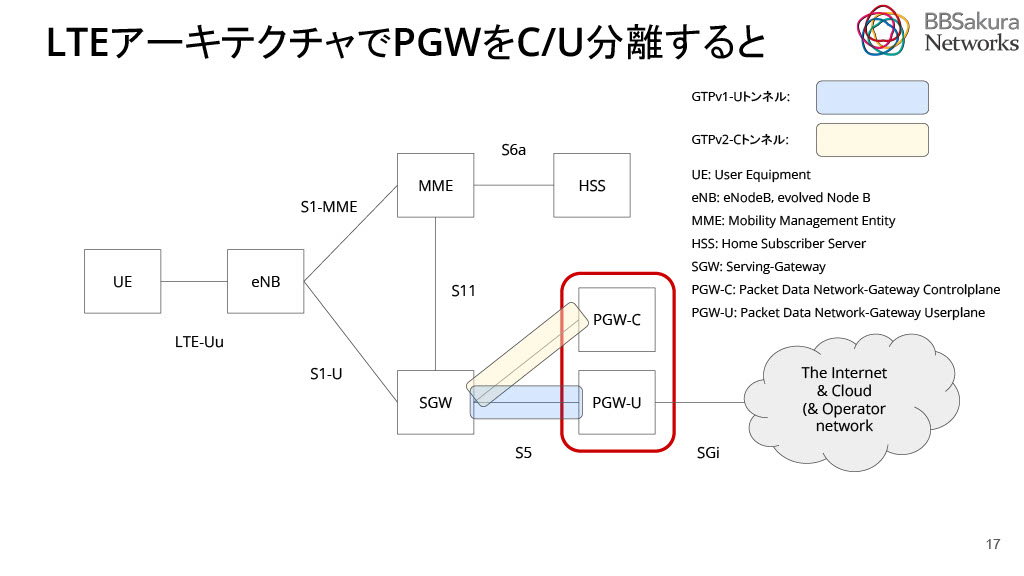
PGWは、PGW-Cというユーザがセッションを作るための制御信号を処理するコントロールプレーンとPGW-Uというユーザがインターネット等に接続する時の利用者信号だけを処理するユーザプレーンに分割することができます。この分割をC/U分離(CUPS)と呼びます。詳しくは3GPP TS 23.214を参照してください。このC/U分離により、キャパシティの増強が容易になり、障害時の切り分けがスムーズに行えます。また、機能の単純化により、性能の最適化がしやすくなります。具体的な動作として、PGW-Uは、UplinkではSGWから受信したGTPパケットをDecapし、それをインターネット等に送信します。DownLinkでは、インターネット等から受信したパケットをGTPヘッダーでEncapし、それをSGWに送信してUEに届けます。
ここからは、自作PGW-Uを題材に高速パケット処理系の測定と評価に焦点を当てます。高速パケット処理系は、HW(Hardware)ベースとSW(Software)ベースの二つの実装があり、今回はSWベースの実装について説明します。高速パケット処理とは、簡潔に言うと余計な処理をしないことです。これは一般的なSWの高速化と同じく、並列化と高速化が肝になります。つまり「単一コアで処理をしない」ことと「単一コアの処理時間を短くする」ことが大切です。
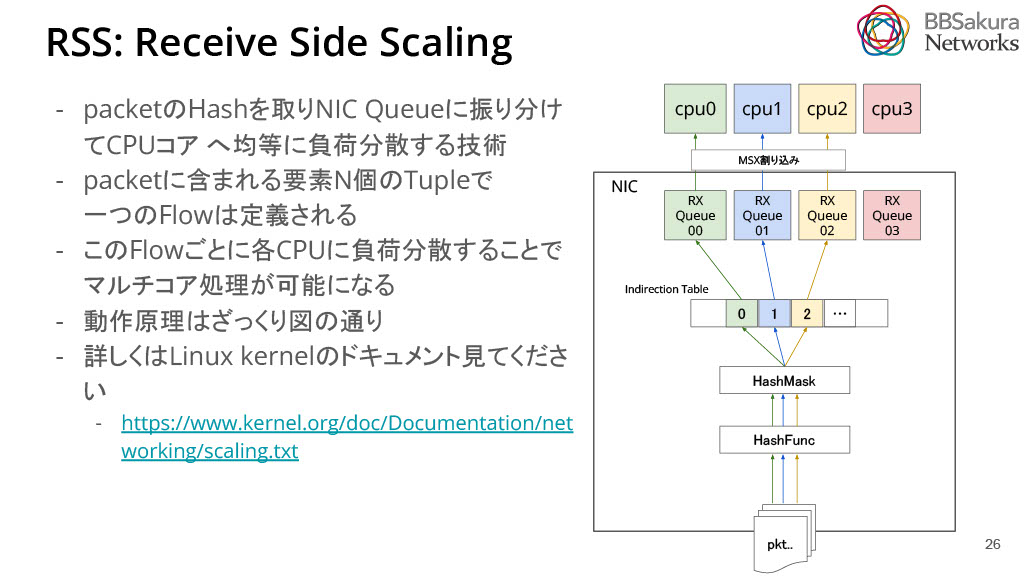
パケット処理の並列化には様々な技術が存在しますが、ここでは今回使用したRSS(Receive Side Scaling)について説明します。RSSは、パケットのハッシュを取り、NIC Queueに振り分けてCPUコアへ均等に負荷分散する技術です。今回は事前にNIC QueueとCPUの対応付けを行なっています。パケット全体でハッシュを取ることは操作コストや利便性の観点から難しいため、含まれるフィールドの要素でTupleを作成し、一つのフローを定義します。例えば、IPアドレスやソースアドレス、送信元・送信先のポート等が要素になります。このようにして、各フローごとに異なるCPUコアに負荷を分散することで均等な負荷分散を達成します。詳しくはLinux kernelのドキュメントを参照してください。
パケット処理はPerFlowで行いたいため、ラウンドロビンではなくハッシュを取ることにしました。PerFlowで処理を行わないと、パケットのリオーダーが発生しやすくなります。リオーダーが発生すると、パフォーマンスの劣化やHoLブロッキングが発生したりと輻輳の原因となります。
ソフトウェアにおけるパケット処理高速化では、単一コアでの迅速な処理を実現するためのProtocolStackと、OSのオーバヘッドを回避するKernelBypass、そして高いパケットレートを保つためにCPUを占有し早く処理するBusyPollingを使うことが定石となっています。これらはフレームワーク上で再現されていることが多く、DPDKやXDPも該当します。ちなみに、XDPはKernelBypassはせず、プロトコルスタックに渡す前にドライバレベルで動作させることでオーバヘッドを削減しています。BusyPollingは、Linuxでパケット流量のレートが上がると自動的にポーリングを行うNAPIを利用しています。
XDPの処理のケースを図にすると、下図のようになります。水色の矢印がXDPで処理されるパスで、橙色が通常の処理されるパスになります。この図からXDPの方が処理が速いことがわかります。
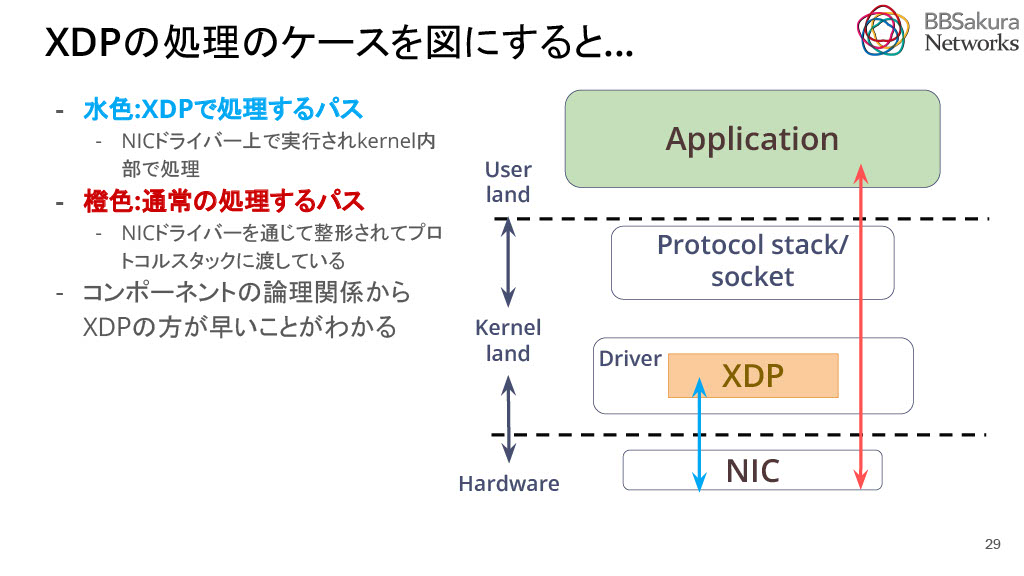
つまり、SWベースの高速パケット処理系とは、ハードウェアで並列化を行い、必要なところを可能な限り高速にCPUで処理することです。具体的にはHWでRSSを処理して、Perflowパケットをなるべくデータのバケツリレーの早いところで処理させます。
次に、PGW-Uの性能評価実験について説明します。構成は下図の通りです。
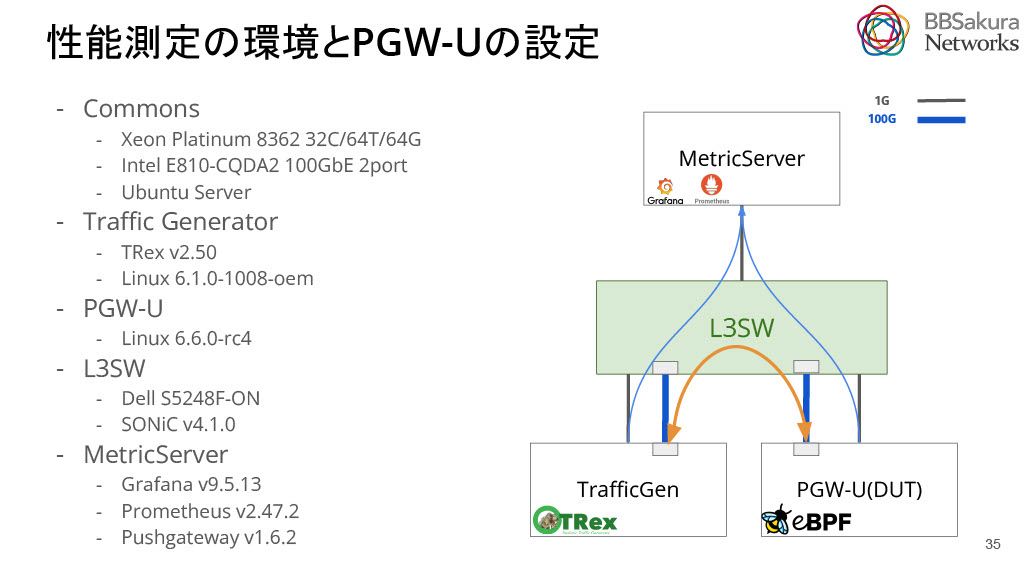
性能測定は以下のプロセスで実施します。TRexとよばれるバックエンドにDPDK製ソフトウェア、フロントエンドにPythonを使用しているOSSのトラフィックジェネレーターを使用します。Scapyを使って任意のパケットを生成し、これを利用して負荷をかけることができます。
1,TrafficGen(TRex)からUpLink/DownLinkを再現したパケットをPGW-Uに送り、PGW-UでEncap/Decapの処理がされたパケットをTRexで受け取る
2.TrafficGenで計測結果(rx_bps等)を PushGatewayというメトリックサーバ に送る
3.PGW-Uにはnode exporterを導入し、自身のCPU利用率等のメトリックを収集
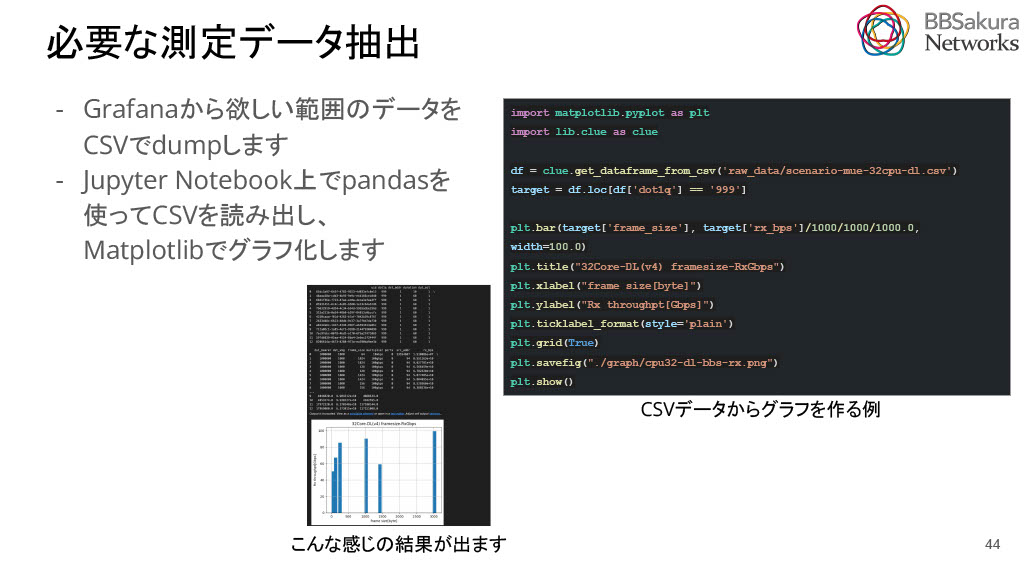
4.メトリックをgrafana経由で CSV形式でダウンロードしMatplotlibとsklearnを駆使してグラフ化
5.グラフを眺めて、考察し洞察を得る
次に、MultiFlowを実現するためのFlow変数について説明します。通常のパケットは固定化されていて、単一クライアントを想定しています。しかし、今回の性能試験では、RSSによるマルチコアの分散を実現するために擬似的に複数クライアントを用意する必要があります。このため、TRexのFlow変数の定義を応用し、送信元IP等を変化させることで複数クライアントを擬似的に再現しました。検証では、UplinkではSrcIPとTEID、DownLinkではVlan IDとSrcIP、DstIPを変化させました。

生成したパケットを使用して性能試験をします。以下は設定の流れです。
初めに、クライアントのインスタンスを作成し、投げたいパケットとそのストリームを定義します。Flow変数のためにランダムシードも定義もできます。その後、TRexのバックエンドに接続してポートを初期化します。L3モードの指定も行います。これにより、ARPを自動で投げてくれるため、MACアドレスに関する設定項目を省略できます。また、L2モードで動作させることでMACアドレスに関する設定項目を省略せず記述できます。
また、実際にリクエストを送信し、返ってきたパケットをpcapにしてdumpすることができます。測定される通信は高速なので、パケットが正しいかどうかを一つ一つ判断することは測定ツールのパフォーマンスとは両立できず難しいです。そのため、あらかじめパケットdumpして正しい挙動か確認しておきます。最後は送信するポートを指定し、リクエストを開始して終了まで待ちます。

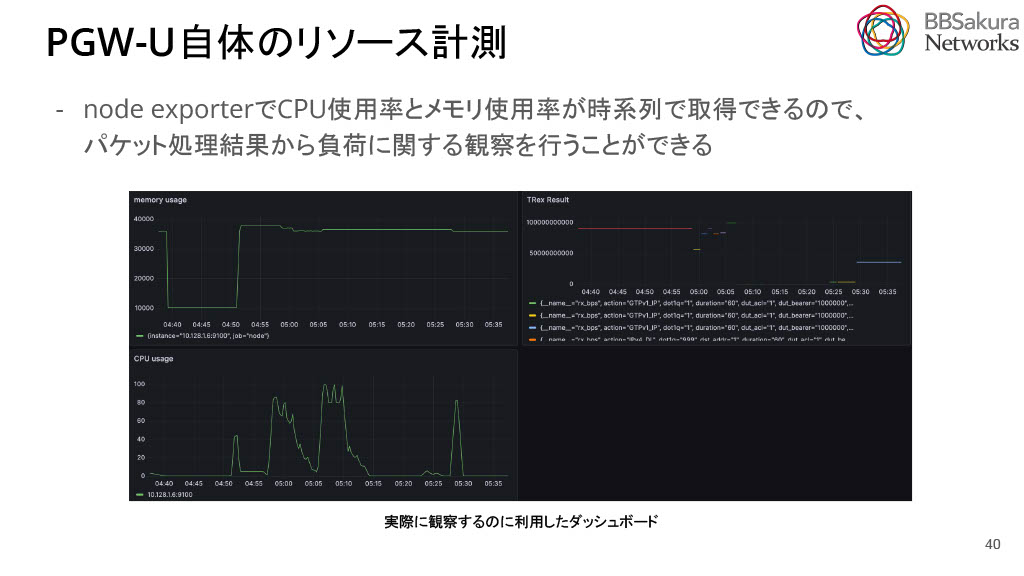
PGW-U自体のリソース計測をします。node exporterでCPU使用率とメモリ使用率を時系列で取得できるので、パケット処理結果から負荷に関する観察を行うことができます。
また、XDPのコードにおいて、具体的にどれくらいの関数が呼び出され、負荷がかかっているのかを把握するためには、perfコマンドを利用しカーネル内部の呼び出しをプロファイルし、得られた情報をフレームグラフ化します。これにより、アプリケーションでのボトルネックを特定しやすくなります。

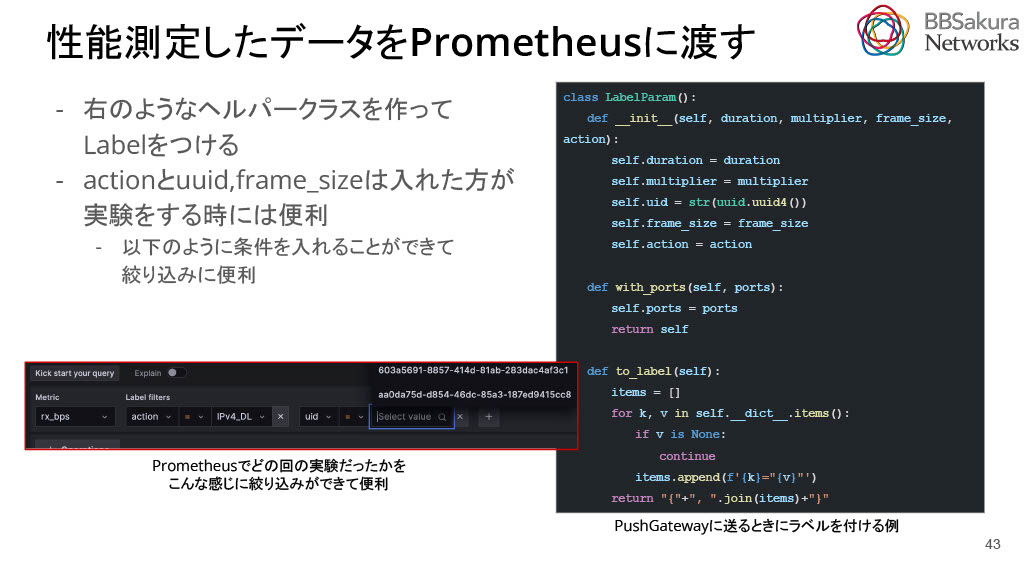
測定終了後は、データをPrometheusに渡します。負荷が終了してから結果を取得できるので、pull型のエクスポータを使うのは難しく、PushGatewayと呼ばれるPush型のメトリックエクスポータを利用して測定結果をPrometheusに送信します。PushGatewayにデータを送るときは、下図のようにラベルをつけると便利です。これにより、どのような実験をしたか等調べることができます。最低限actionとuuid, frame_sizeを含めると実験時に便利です。
Grafanaで結果を確認し、必要なデータをCSVでdumpします。それをJupyter Notebook上でpandasを使ってCSVを読み出しMatplotlibでグラフ化します。
CSVを再度読み込ませ、今度はsklearnを使いCPU負荷とframeseizeの因果関係をもとに線形回帰モデルを作ります。

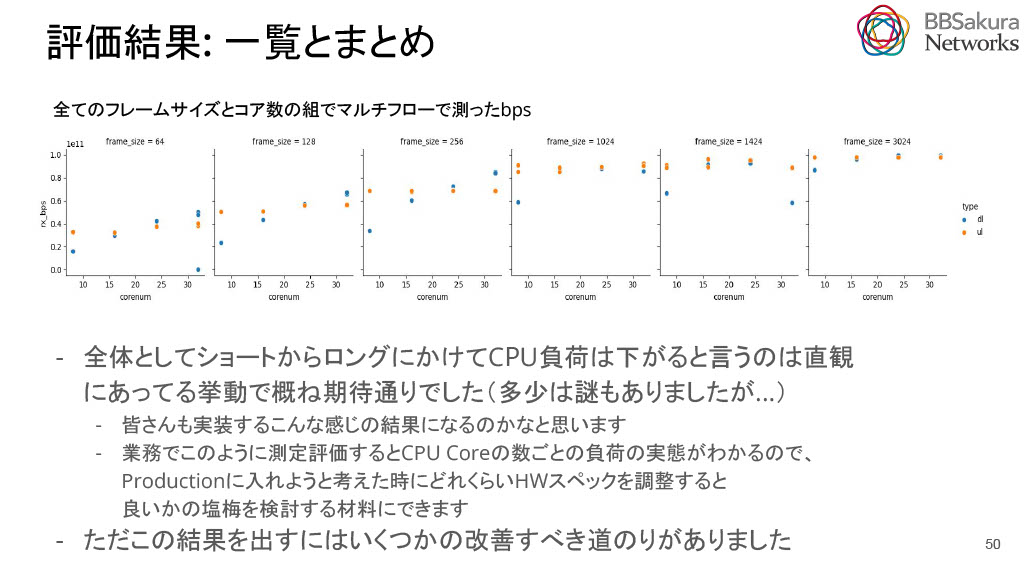
ここからは実際に評価した結果を示します。評価条件は下図のとおりです。変動部分ではパケットサイズを64から3024のパターンまで試行します。それをCPUコアを絞ったバージョンも含め刻みながら実行し、シングルコア性能とマルチコア性能、ペイロード長とCPUの数を変えながら調べることで評価を行いました。

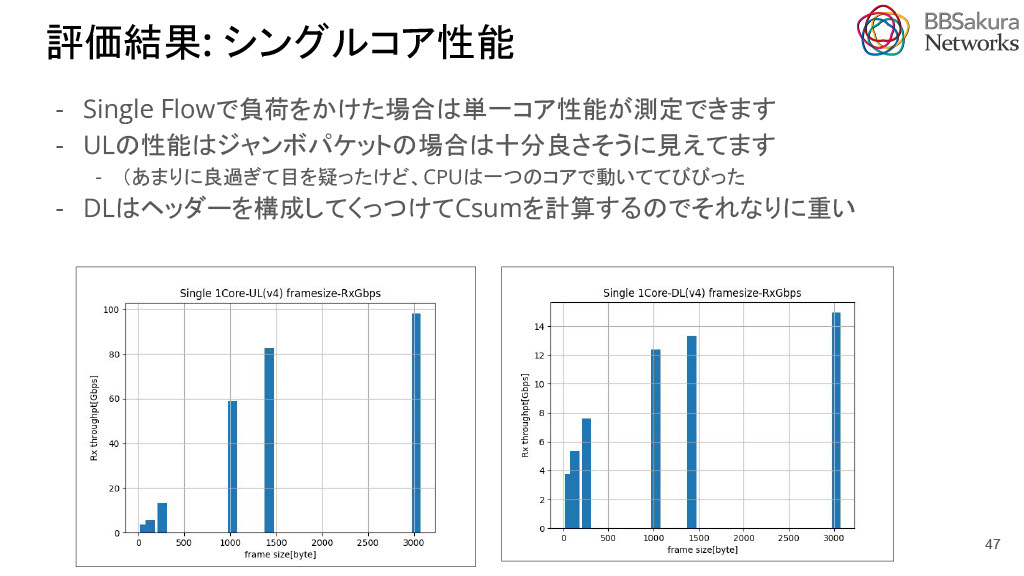
シングルコア性能の評価結果です。SingleFlowの負荷がかかっています。
左のUpLinkの場合はこの通り。ジャンボパケットの場合は、CPUコア1つでほぼ100GbEを処理できています。
DownLinkは、想定通りあまり性能が出ておらず、ジャンボパケットでも15Gbpsぐらいしか処理できていません。これはヘッダーをつけたりchecksumを計算するため処理が重くなっていると想定しています。
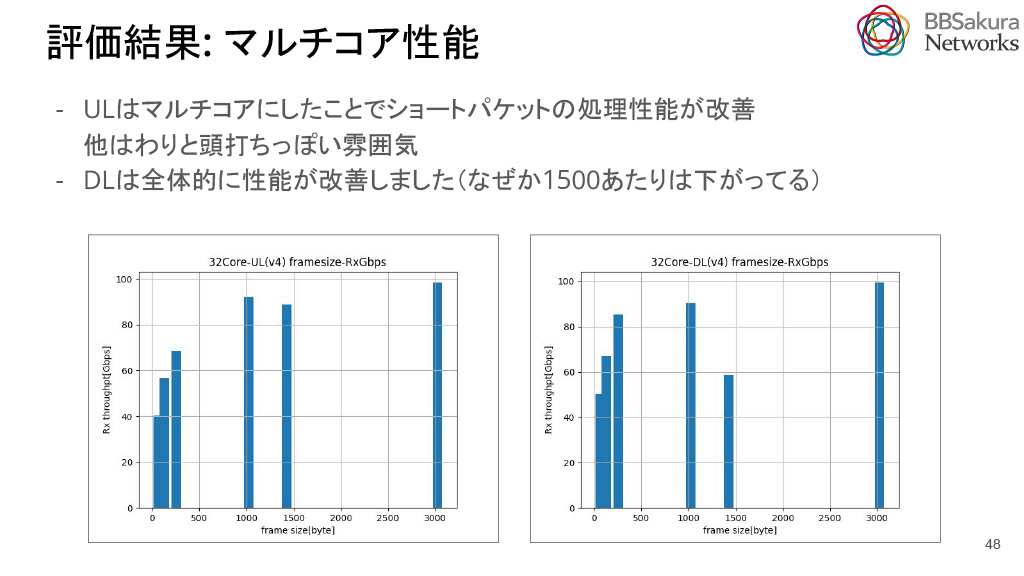
次に、マルチコア性能の評価結果です。MultiFlowの負荷がかかっています。
UpLinkは、マルチコアにしたことでショートパケットの処理性能が改善し、DownLinkは全体的に改善しました。1500byte付近は想定外に下がっていました。UpLinkが高性能だったのは、CPUに大した負荷が掛からずに処理ができているからです。この結果からDecapの負荷は低いという知見を得ました。DownLinkの場合は、中間のペイロードサイズで24コアだけが負荷が落ち着いてるので不思議ではありますが、3024byteでは32コアでも負荷が下がっており、概ね直観に当てはまっていました。
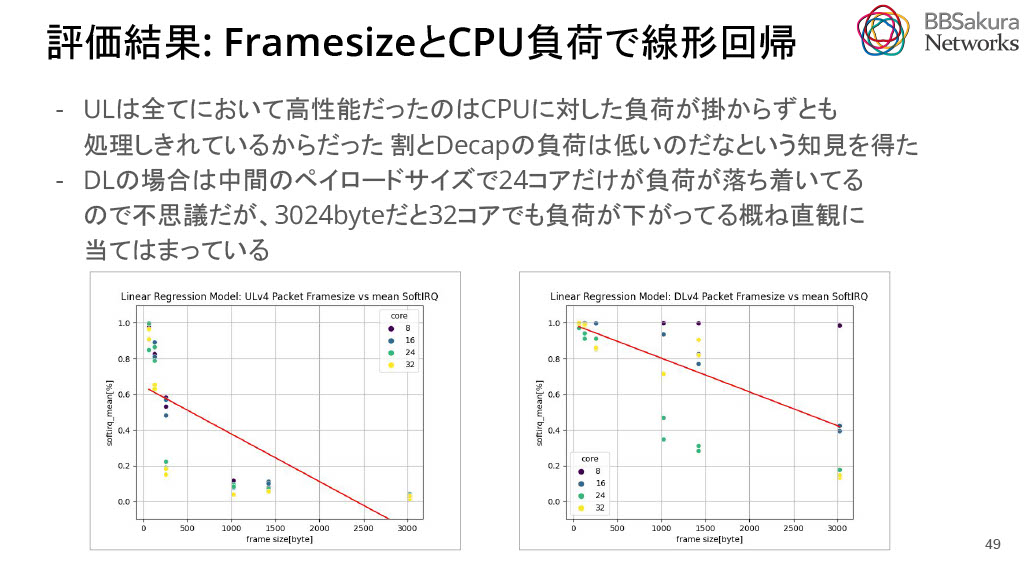
線形回帰モデルで得たグラフを用いて確認します。これを見ることでUpLinkの性能が良かった理由が明らかになります。一言で言えば全部の処理が軽いためです。全てのコアでショート以外は軽い負荷でした。
DownLinkの場合、24coreの時だけ負荷が落ち着いていますが、一番大きいジャンボパケットは32coreでも負荷が下がり軽くなっていて、概ね直感に当てはまります。
全てのフレームサイズとコア数の組でMultiFlowを測定しました。UpLinkとDownLinkの落差が可視化でき、興味深い結果となりました。ただし、全体としては概ね期待通りの挙動でした。
業務でこのように性能評価を行うと、CPUコア数ごとの負荷の実態が明らかになります。これは、Productionでのサーバ購入時にどれくらいのHWスペックが必要かを調整する際に役立つ良い材料や指標になります。
最後に今回の測定を通して見つけた3つの問題点と改善について説明します。
1.eBPF MAPに100万エントリを流した結果、エントリ数が大きくなるとデータが消失してしまいました。
これはeBPF Mapにベアラデータを100万件叩き込んだケースで気づいた問題です。
BPF_MAP_TYPE_LRU_PERCPU_HASHというMap Typeを使ったことが原因でした。LRUを使い、使用頻度の低いものは捨ててメモリリソースの最適化を図ろうとしましたが、実際はFULLになったら捨てるのではなく、テーブルのMAXエントリサイズの数割で削除を始める仕様でした。
3割~7割といった割合で保持エントリ数に波があったり、その影響で特定のUEが繋がらなくなったりして困りました。そのためLRUの使用をやめ、BPF_MAP_TYPE_PERCPU_HASHというeBPF Map Typeを利用するように変更し、BPF_F_NO_PREALLOCという実行時にメモリアロケートするFlagを使ってできるだけメモリを節約することにしました。
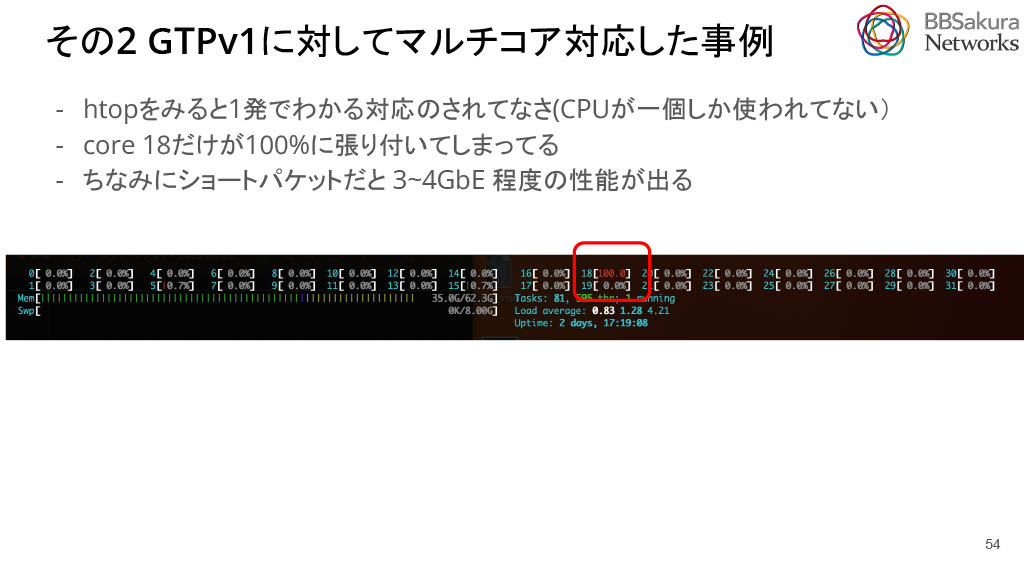
2.GTPv1に対してマルチコア対応を行いました。
測定当初からMultiFlowパケットを投げていましたが、htopを見ると1つのCPUコアだけが動作していて、RSSが効いていないことがわかりました。
一般的にパケットのFlowを識別するには5Tuple(Srcip,Dstip,Sport,Dport,Proto)の情報を利用します。しかし、GTPv1-UでMultiFlowを投げるには、この一般的な5Tupleでは負荷分散が不十分であることが分かりました。PGW-UへのリクエストはSrcip(SGWの数)以外は固定されており、SGWの数でしか負荷分散できていないことが判明したからです。そこでUE単位でIDが付与されているTEIDを要素に含めることで、ユーザ単位でのFlow識別ができるようになると考えました。
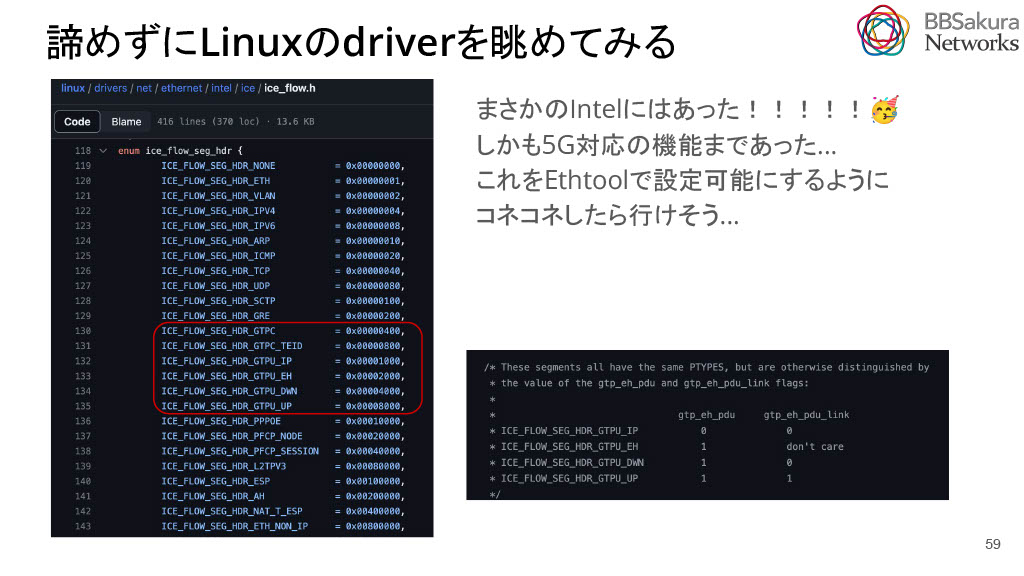
次に、TEIDを含めてFlowを見てRSSを効かせることができないか調査しました。ethtoolでGTPがRSS対応していないか確認しましたが、そのような対応はドキュメント上では見当たりませんでした。しかし、諦めずにLinuxのカーネルにあるドライバを確認すると、IntelのICEというドライバにその機能が存在していました。
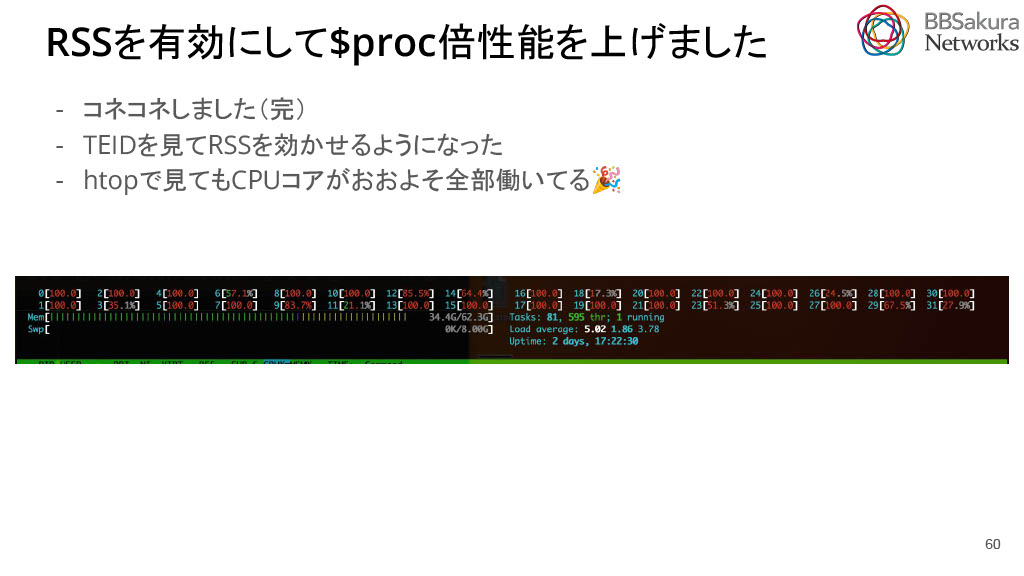
これを利用し、TEIDを見てRSSを効かせることができるようになりました。htopで確認してもCPUコアがおおよそ全部稼働しています。この結果をもとに、Linux Kernelにパッチを出し、現在レビュー中です。
3.checksum機能をOptoutした事例
負荷計測をしているときに UDP checksum に関するスタックコールを見つけました。これは DownLink で GTPヘッター を Encap する際に UDP checksum を計算している部分です。
スタックコールがある、すなわち UDP checksum の計算はある負荷の一部であることが推察されます。そこで本当に checksum が必要かを検討・調査しました。
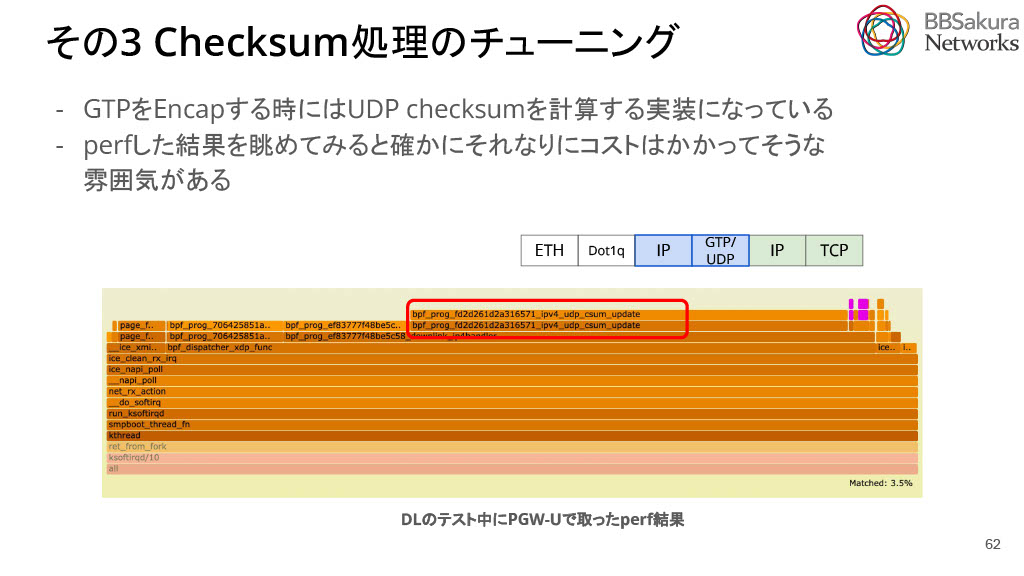
3GPP TS29.281を確認すると、相互接続する双方がサポートしていればchecksumは0でもよいという記述がありました。つまり、UDP checksumがなくてもSGWが受け入れてくれれば問題ありません。実際に調査してみても主要な接続先では問題がないことが分かりました。そのため、UDP checksumをOptoutする機能を追加し、結果として、ショートパケットでは3~4Gbpsほどの改善ができました。

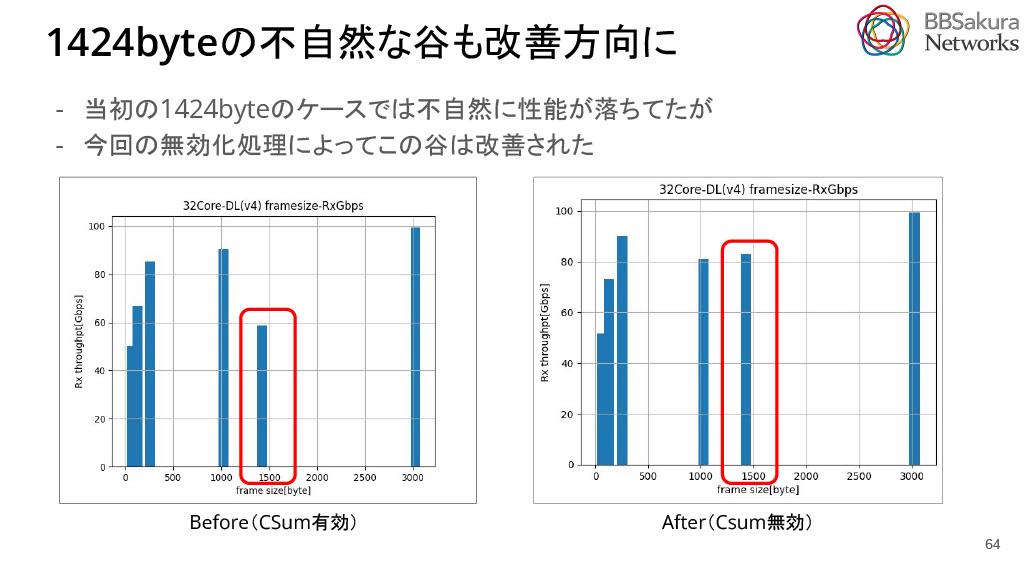
また、当初1424byteペイロード長のMultiFlowの場合において不自然な性能の減衰が観測されていましたが、checksumを無効化したことで改善しました。具体的には、当初60Gbpsだったものが、82Gbps程度となり20Gbpsほど改善しました。
今回の計測結果を踏まえ、今後について話をします。ショートパケットの場合、PGW-Uに完璧な負荷をかけることができませんでした。ですがCPUの使用率はちゃんと上限に当たっていたことはグラフで示した通りで、実用上は問題がないと考えており今後の課題としました。考えている解決方法としてはサーバを複数台使って計測できないかを検討しています。
また、SingleにおいてUpLinkとDownLinkの性能差分が大きかった問題が未解決なので理由を調査して更なる開発を探求していきます。