フロントエンドの複雑さに立ち向かう 〜DDDとClean Architectureを携えて〜

この記事は2023年12月19日に行われた「さくらのテックランチvol.6 〜ローストチキンのフロントエンドパスタとクリスマスFigmaケーキ〜」における発表を文章化したものです。
さくらインターネットでフロントエンドエンジニアをしているダーシノです。
現在さくらのクラウドのフロントエンドチームが取り組んでいるソフトウェア設計について話していこうと思います。
目次
自己紹介
さくらインターネットではシニアフロントエンドエンジニアをやっています。代表作は「NES.css」というファミコン風CSSフレームワークで、エイプリルフールには「さくらのINFRA WARS」というゲームの企画開発をしていました。

話さないこと
本記事ではソフトウェア設計ということで、以下の設計・アーキテクチャに関しては話す予定はありません。コンポーネント設計や CSS 設計に関しては過去に記事やスライドを公開していますので、気になる方はそちらを参考にしていただければと思います。
- コンポーネント設計
- CSS設計
- SPA/MPAやCSR/SSRなどフレームワークが絡む領域
- Webサーバ、CDN、BFFなどを含むインフラ領域のアーキテクチャ
なぜフロントエンドは複雑になるのか?
理由は色々あると思いますが、まずはコア部分のトレンドが大体5年周期で入れ替わったりします。例えば2006年がjQuery 、2010年にAngularJSやBackbone.js、2013〜2014年にReactやVue.jsが出てきて、2018年にReactが関数コンポーネントを採用・推奨したりVue3がComposition APIを採用したりと、結構トレンドが大きく変わったりしています。
歴史が長いコードでは「秘伝のたれ化」をしてしまって、コードはSmart UI(利口なUI)というものになりがちです。 このSmart UIというのは、View層(UI)にビジネスロジックが含まれているDDDではアンチパターンになります。ただ、有効な場合もあるので一概にアンチパターンというわけではないようです。
あとはリッチなUIを開発していこうとすると、ビジネスロジックと同じぐらいの実装が必要になります。BFF、GraphQLといったものを使わないと、複数のバックエンドの仕様をフロントエンド側で吸収する必要が出てきてしまって、フロントエンドが複雑になる理由になっています。
さくらのクラウドUIで感じた課題
先程のフロントエンドが複雑になる件は一般的な理由でしたが、さくらのクラウドのUI開発で実際に感じていた課題もあります。それはさくらのクラウドはリリースしてから10年以上の歴史があって、良いように言うと「趣がある」コードでSmart UI化しています。また、手続き型の実装がされていてコードから仕様が読み取れない、読み解きづらいという問題もありました。他にも独自UIライブラリがはがせないほどビジネスロジックと密に結合していて、新しい技術を取り入れられないという状況になっていました。その独自 UIライブラリの影響でテストが書きづらく、デグレしやすかったりとかなりストレスになっていました。
また、同じ概念のものが別の場所や別のファイルに別の名前で登録されてしまっていたり、複数のバックエンドの差異がフロントエンドに侵食してきたりなど。例えばキャメルケース、スネークケース、パスカルケースがフロントエンドのコード内に入り混じって出てくるとか、そのような感じでハチャメチャがめちゃくちゃ押し寄せてきてました。
どうすれば開発しやすくなるか
課題についてどうすれば開発しやすくなるかというのをフロントエンドチームで話し合って考えてみました。一般的に言われることなのですが、関心とか責務ごとにレイヤーを分けること。フレームワークやライブラリが捨てやすいこと。更新周期が早いので破壊的バージョンアップがあったとしても移行しやすいこと。依存が少なくて、単体テストや小さなテストが書きやすいこと。一貫した共通の言語でやりとりできること。これらをやれば開発しやすくなるんじゃないかと思い色々調べてみました。
注目した設計思想・哲学
そこで注目した設計思想や哲学なのですが、ドメイン駆動設計(Domain-Driven Design)やClean Architectureです。この二つに注目していろいろ勉強しましたので、ざっくりDDDとClean Architectureについて説明します。
ドメイン駆動設計 (Domain-Driven Design)
エリック・エヴァンスのドメイン駆動設計 / 翔泳社
著: Eric Evans
Clean Architecture
Clean Architecture 達人に学ぶソフトウェアの構造と設計 / KADOKAWA
著: Robert C.Martin
ドメイン駆動設計の良いところとイマイチなところ
良いところ
ドメイン駆動設計の良いところは共通言語(ユビキタス言語)を作ってビジネスサイドからエンジニアサイドまで一貫した共通言語で話し合うというのがあります。また、ビジネスとコードを対応付ける。ビジネスの視点で責務を分解する。特に良い点が「コミュニケーションの重要性」を説いているところです。
ドメインモデルというのは、成長させる前提でリファクタリングを繰り返して知識をどんどん蒸留させていこうというところが、かなり共感できて良いなと思った点です。
イマイチなところ
反面、いまいちなところもあります。書籍本文が難解で、読んだ人によって捉え方が異なる。それぐらい共通認識を持つのが難しい本でした。また、20年前のJava全盛期に書かれた内容のため、今では使わないようなデザインパターンなどが使われていたり若干古さを感じます。
他にもDDDの用語と別の用語。オブジェクト指向やリファクタリング界隈、Java界隈、TDD界隈などの用語のキーワードがコンフリクトしていて、誤解しやすいというのがありました。
Clean Architectureの良いところとイマイチなところ
良いところ
Clean Architectureの良いところとしては、SOLID原則を用いて関心と責務の分離ができレイヤーを分けられる、レイヤー間の依存方向を制限できるなどがあります。また、具体的な決定(どんなフレームワークを使うか、どんなライブラリを使うかなど)を遅延させることができます。遅延できるということは入れ替えやすくなるため、この部分が良いなと思いました。
イマイチなところ
反面、いまいちだなと思ったのは、書籍を読まずにネットで「Clean Architecture」を検索すると、例の同心円の図が出てきてしまい、それだけを見ると「Clean Architectureという新しいアーキテクチャが存在している」「4つのレイヤーを作ってやらなければいけないんだろうな」みたいな誤解が生まれやすいというのがありました。
これはおそらくフロントエンドに限ったことだと思うのですが、JavaScriptのフレームワークの制約があるので、相性によって綺麗にはまらない部分がいくつかありました。
実践する前に…
DDDとClean Architectureを学んで実際に実践しようと思ったのですが、やはりどちらの書籍、設計思想とか哲学というのも内容が難しく、チームメンバーの共通認識を作るため、またはスキルの底上げを図るために読書会や勉強会を主催しました。これはネット上の記事はわりと方法論やすぐに「こういうふうに書きましょう」みたいなコードが先に出ることが多く誤解しやすいため、哲学や思想とかもっと抽象的なところを学ぶ、理解するために書籍の勉強会や読書会を行いました。
- DDD読書会(25回)
- DDDモデリング勉強会(2回)
- OOP・SOLID原則勉強会(2回)
- 実践 Clean Architecture 勉強会(複数回)
- ペアプロ・モブプロ(30回以上)
実際にクラウドUIで半年間開発してみた
読書会や勉強会を経て、全員で共通認識を持てた先でようやくクラウドの UI に適用してみて、半年間開発してみました。ざっくり以下のような感じのレイヤーでやっています。
- Presentation層
- Application層
- Infrastructure層
- Domain層
この 4 つのレイヤーで設計しました。ここからそれぞれのレイヤーについて、より深く説明していこうかなと思います。
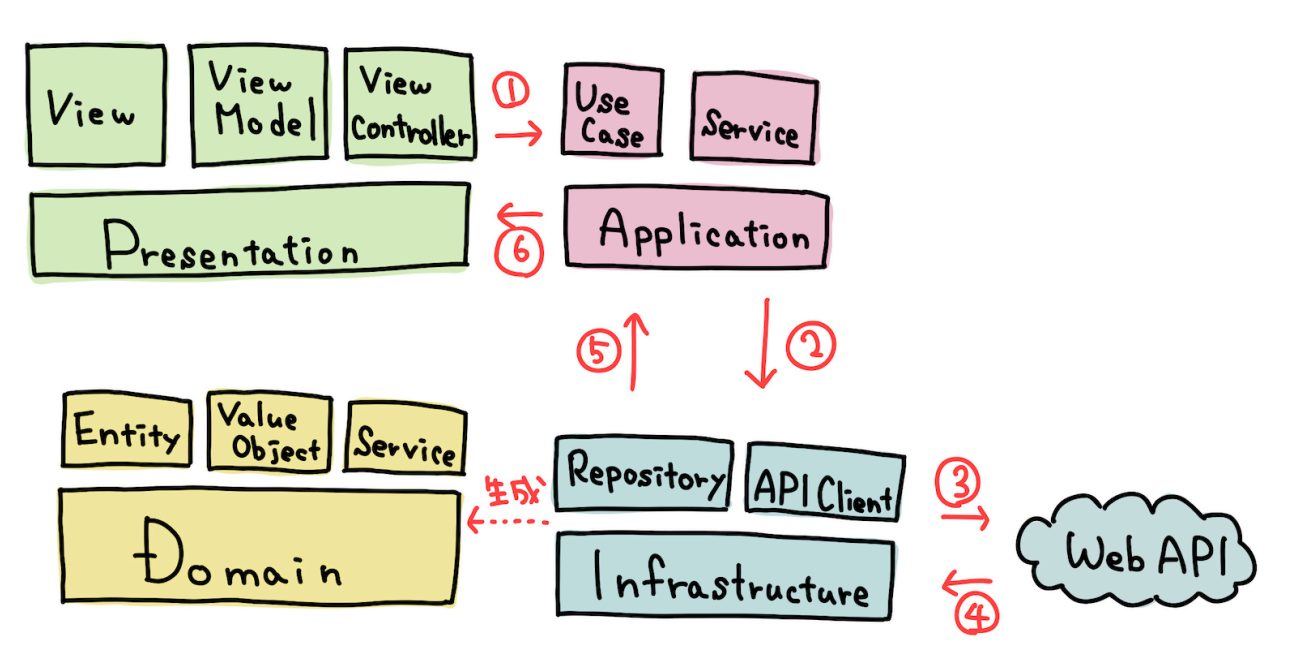
Domain層
- Entity
- ValueObject
- Service
Domain層はシステムのコア部分、ビジネスロジックを扱う部分になり、Entity, ValueObject, Serviceというものがあります。
Entityはシステム上ユニークになるオブジェクトのことを指しています。本来DDDの文脈でいうと、Entityはミュータブルなオブジェクトになるはずですが、クラスベースのオブジェクト指向で開発を始めたので、メンバ変数を変更してもJavaScriptのフレームワークで変更検知がされないという問題がありました。そのため、Entityとは言いつつもイミュータブルなオブジェクトとして扱いました。
ValueObjectは一意に認識できなくても良いオブジェクトです。さくらのクラウドであればIPアドレスなどを入力するところがあり、String型で定義してしまうと何でも入れられてしまい制約や検証ができないことやCIDR表記のレンジがチェックしづらいなどの問題があり、そういったものを解決するためにまとめてValueObjectに入れました。
Serviceは、EntityやValueObject単体で解決する問題であればいいんですけど、複数のドメインオブジェクトにまたがって行う処理があるので、そういったものはDomain層のServiceに入れて対応しました。
Domain層サンプルコード
Entityクラスを継承したTaskクラスがあり、その中にisDoneメソッドやisExpiredメソッドなどの振る舞いを持っています。本来のDDDであればchangeTitleのようなメンバ変数を変更するメソッドが生えてくるのですが、先ほど説明した通り JavaScriptのフレームワークとの相性でメンバ変数の変更が検知できないためここは使わないようにしています。
class Task extends Entity {
#title: string
...
isDone(): boolean { ... }
isExpired(): boolean { ... }
/**
* @deprecated
* 本来ならEntityには変更系のメソッドも生えるのだが、
* JSフレームワークはメンバ変数の変更を検知できないので使えない
*/
changeTitle(newTitle: string) { ... }
}Presentation層
- View
- ViewModel
- ViewController
主にUIを扱う部分で、Presentation層内はMVCアーキテクチャを採用しています。Presentation層のViewはHTMLやCSSを書くところで、基本的にロジックなどは書かないようにしています。ロジックはViewModelの方に任せていて、データの加工であったりUIの制御などを扱っています。Vue.jsやReact を知っている方であれば、VueのComputedやMethods、ReactのカスタムHooks と言った方がわかりやすいかもしれません。
ViewControllerはPresentation層とApplication層を繋ぐ薄いレイヤーで、例えばユーザがボタンを押したときにApplication層にあるUseCaseを呼び出すみたいな、そういったControllerとして扱っています。
Presentation層サンプルコード
ControllerからTask Entityを受け取ります。Task EntityをViewModelのuseTaskに渡してあげるとformattedTitleが返ってきます。あとはタスクが終わっていたら(task.isDone() === true なら)Deleteのボタンを表示する、終わっていなければUpdateのボタンを表示するといったふうに実装しています。
const task = await controller.findByID(query.id)
const { formattedTitle } = useTask(task)
<UI>
<h1>{ formattedTitle }</h1>
{
task.isDone()
? <button onClick={() => controller.delete(task)}>Delete</button>
: <button onClick={() => controller.update(task, input)}>Update</button>
}
</UI>
// ViewModel
function useTask(task: Task) {
const formattedTitle = useMemo(() => {
const status = task.isExpired() ? 'Warning' : 'Progress'
const title = task.title()
return `${status}: ${title}`
}, [...])
return { formattedTitle }
} Application層
- UseCase
- Service
主にユースケースを扱う部分になっています。ユーザーが画面を表示して何をするかという行動単位でUseCaseを作っています。例えばタスクを登録する、タスクを完了する、削除する、変更するなどそういった単位でUseCaseを作っています。
また、Application層内にもDomain層と同じようにServiceがあり、これはDomainの外部の関心事を実装するためのステートレスな軽量サービスにしています。具体的にはこの辺はJavaScriptのモジュール化して使ったりしています。もちろんstaticクラスとか使ってもいいと思うのですが、このような感じでやっています。
Application層サンプルコード
ITaskUsecaseというインターフェースをTaskInteractorで実装してfindByIDやdelete、updateというユースケースを作っています。このupdateは本来はTask Entityの中身を書き換えてrepository.save(task)を実行すると良い感じに書き換わってくれるのですが、JavaScriptのフレームワークでうまくできないのでDTOを噛ませてやっています。この辺は少し苦肉の策という感じです。
class TaskInteractor implements ITaskUsecase {
async findByID(id: TaskID) {
const task = await repository.findByID(id)
return task
}
async delete(task: Task) {
await repository.delete(task)
}
async update(task: Task, input: FormInput) {
// 本来なら書き換えた Task をそのまま Repository に渡せば良いのだが、
// メンバ変数の書き換えはJSフレームワークで検知できないため DTO で代替する
const dto = new TaskDTO(task, input)
const newTask = await repository.save(dto)
return newTask
}
}Infrastructure層
- Repository
- APIClient
API通信やデータの永続化を行う部分です。Repositoryというのは、データの取得や更新、永続化を行い実際のデータアクセス方法を隠蔽しています。そのため呼び出し側はAPIをコールするか、Web StorageのLocal Storage、WorkerやIn-Memory Cacheなど何を参照するか意識しなくてもデータの保存や取得ができます。
APIClientはさくらのクラウドのAPIを扱いやすくするためのクライアントで、エンドポイントを入力するとバチバチに型が効いたレスポンスの型やリクエストの型が返ってくるという、わりと自信作なんですけど外部に公開できないので残念です。
Infrastructure層サンプルコード
RepositoryのインターフェースをTaskRepositoryで実装しています。findByIDやdelete、updateをやっています。例えばキャッシュの中に同じIDを持っているものがあればそのキャッシュを返す、キャッシュがなければ実際にAPIをコールしてバックエンドからデータを取ってくるといったことをやっています。
class TaskRepository implements ITaskRepository {
#cache: Tasks[]
async findByID(id: TaskID) {
const isCached = this.#cache.some(a => a.id === id)
if (isCached) {
return this.#cache.find(a => a.id === id)
}
const res = await apiClient.get(`/task/${id}`, { ... })
const task = new Task(res)
return task
}
async delete(task: Task) {
const res = await apiClient.delete(`/task/${task.id}`)
}
async update(dto: TaskDTO) {
const body = dto.createBody()
const res = await apiClient.put(`/task/${dto.id}`, { body })
const newTask = new Task(res)
return newTask
}
}まとめ
よかったところ
実際この方針で半年間開発してみて良かったところは、責務ごとにレイヤーが分かれたので秩序が生まれてコードがすごく読みやすくなりました。また、フレームワークやライブラリの依存部分が局所化できて、捨てやすくなるというか入れ替えやすくなりました。例えば昔にMoment.jsというものが流行ったのですが、それがdeprecatedになって今はDay.jsに変わったことがあります。そういったものは腐敗防止層的なものを噛ませてやることで、内部の実装には全然影響はなくライブラリだけは置き換えられるといった仕組みを導入することができました。
他にもインターフェースなどで実装しているので、依存がかなり少なくてテストがすごく書きやすくなりました。今までこういう設計についてはわりと個人差が大きくて、レビューも感想ベースになってしまい「こう思います」みたいなコメントになってしまいましたが、DDDやClean Architectureをベースにしたことでその共通認識をもって正しくレビューができるようになりました。
また、言葉の定義を厳密に扱うようになりました。ビジネスサイドと開発サイドで、同じものを違う呼び方しているみたいなところがありましたが、そういったところも統一できるようになってきました。
改善の余地あり
逆に少し改善の余地ありだなと思ったところもいくつかあります。それは前提としてDDDやClean Architecture、オブジェクト指向といった前提知識を要してしまうので、プロジェクトへの参入障壁が上がってしまったかなと感じています。ですが、先月11月に入社されてフロントエンドを担当していただいている方に話を聞いてみたら元々DDDやClean Architectureの前提知識を持ってたので「レガシーコードに比べて仕様がかなり読みやすかったです」という感想をいただきました。
あとは、フレームワークの制約でアーキテクチャを厳密に適用できない。先ほど説明したクラスベースのオブジェクト指向を採用しまうと、JavaScriptのフレームワークと相性が悪いというやつです。これも対処法を考えたのですが、例えばデータ指向プログラミングみたいにデータとコードを分けたりとか、クラスを使わずデータを基本的なデータ構造(mapや配列、オブジェクトなど)として扱うと、もしかしたらフロントエンドと相性がいいんじゃないかと感じました。ただこれは未検証なので、いち個人の感想という感じです。
他にもレイヤーを分けていく上で仕方がないことだと思うのですが、冗長的なコードが増えてしまったのでエディター内で迷子になることが増えました。例えばコードジャンプしても思い通りの場所に飛ばないとか、同じようなファイルがあって探しづらいとか。ここ辺がストレスになります。
最後に
これからの展望なのですが、複雑さに立ち向かうためにはEric Evansさんもおっしゃっていた通り、継続的なリファクタリングと知識の蒸留が必要です。完成というのはないと思っていて、運用が始まってから本番なのかなと感じています。
アーキテクチャは生き物なので、今後どういうふうに成長するかわからないという部分もあります。
責任の分解や知識の配置場所とか、DDDやClean Architectureに「これはここに置きましょう」というような明確な指示はなく個人差が現れてしまうので、その辺り俯瞰的な人力レビューが必要になるかなと思います。そのためレビュー工数が増加してしまったので、対策したいなと感じてます。
今は守破離の「守」の部分なので愚直な実装が多いため、知見が溜まったらどんどん改善していきたいなと思います。
以上です。ありがとうございました。
参考リンク
ドメイン駆動設計の用語と解説(DDD入門ガイド) | Black Everyday Company
オブジェクトストレージ開発におけるDDD (ドメイン駆動設計) | さくらのナレッジ
参考文献
エリック・エヴァンスのドメイン駆動設計 - Eric Evans
Clean Architecture 達人に学ぶソフトウェアの構造と設計 - Robert C.Martin