さくらのクラウドでHadoop/Spark/Asakusa環境を構築する(2) ~Sparkのセットアップと実行編~

目次
はじめに
「さくらのクラウドでHadoop/Spark/Asakusa環境を構築する」第2回目です。
前回は、さくらのクラウド環境にHadoopディストリビューション Hortonworks Data Platform (HDP) を使ってHadoopクラスタを構築しました。
今回は、Apache Spark を紹介します。 前回構築したHadoopクラスタにSparkをセットアップして、HadoopとSparkを連携するための設定を行います。
SparkがHadoopと連携して動作することを確認できたら、いくつかのSparkアプリケーションを実行してみます。 また、Sparkが提供するSQL実行エンジン Spark SQLや、 ストリーム処理エンジン Spark Streaming 、 Sparkが提供する管理画面などを紹介します。
インストール構成
これからHadoopクラスタにSparkを、また次回ではAsakusa Frameworkをそれぞれインストールしていきますが、その準備としてこれらを管理するためのユーザ環境を整えます。
ユーザの準備
SparkやAsakusa Frameworkを管理する任意のグループとユーザを作成します。ユーザやグループの具体的な作成手順はここでは省略しますので、利用するOSが提供する方法に従ってユーザとグループを準備してください。
この連載では、sakura という名前のグループとユーザを使います。
なお、ユーザはクライアントとなるマシンにのみ作成してあればOKです。 ここでは、Hadoopクラスタとして準備した3台のサーバのうち hdp-node1 にこのユーザを作成したものとします。
HDFS上のホームディレクトリの準備
sakuraユーザ用に、HDFS上のホームディレクトリを作成します。
hdp-node1にrootでログインし、以下の手順で作成します。
Sparkのダウンロード
それではSparkをインストールしていきましょう。
まずは、SparkのダウンロードサイトからSparkをダウンロードします。


以下の手順でダウンロードします。
- Choose a Spark release: 最新版を選択。本記事の作成時点では「1.5.1 (Oct 02 2015)」。
- Choose a package type:「Pre-build for Hadoop 2.6 and later」 を選択。
- Choose a download type: 「Select Apache Mirror」を選択。
- Download Spark: リンク先のミラーサイトからアーカイブファイルをダウンロードしてください。
ダウンロードしたアーカイブファイル「 spark-1.5.1-bin-hadoop2.6.tgz 」をサーバ hdp-node1 に配置します。 ここではホームディレクトリ直下 ( /home/sakura ) に配置したものとします。
Sparkのインストール
ここでは、 $HOME/spark というパスにSpark本体をインストールします。
hdp-node1にsakuraユーザでログインし、以下の手順でSparkをインストールします。
Sparkのバイナリが正しく配置されたかを確認します。 Spark本体に含まれるコマンド bin/spark-submit を以下のように実行します。
正常に配置された場合は以下のように表示されます。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.1
/_/
Type --help for more information.
以降では、コマンドの実行例は $HOME/spark がカレントディレクトリになっているものとして説明します。
Sparkの設定
ここでは、SparkをHadoopと連携するための設定と、Sparkの管理機能の設定を行います。
HDP Versionの確認
HDP上でSparkを実行するには、一部の設定項目に「HDP Version」を指定する必要があります。 HDP Versionは環境上のクラスパスの解決などに使われます。
HDP Versionはパッチリリースなどでそのバージョンが変わるため、HDPをインストールしたタイミングによっては本連載で紹介する値と異なっている可能性があります。 そのため、HDP Versionは(本連載で紹介している値をコピーするのではなく)必ず以下の手順で確認して、表示された値を使うようにしてください。
HDP Versionを確認するには以下のコマンドを実行します。
hdp-select status hadoop-client
今回の環境では、HDP Versionは以下のように表示されました。
hadoop-client - 2.3.0.0-2557
2.3.0.0-2557 の部分がHDP Versionです。
環境変数の設定
Sparkが使用するHadoop環境の設定は、環境変数で指定します。 環境変数は conf/spark-env.sh に設定します。
ここでは、 spark-env.sh 以下のように設定します。
spark-env.sh
export HADOOP_CONF_DIR=/etc/hadoop/conf
SparkをHadoop(YARN)上で実行するには環境変数 HADOOP_CONF_DIR にHadoopの設定ファイルのパスを設定します。 HDPの標準インストール構成では /etc/hadoop/conf というパスが利用できます。
Sparkプロパティの設定
Sparkが実行するアプリケーションの動作に関する設定は、Sparkプロパティで指定します。
Sparkプロパティはアプリケーション実行時に実行用コマンドの引数として指定する方法や、 設定ファイル conf/spark-defaults.conf で指定する方法などがあります。
ここでは spark-defaults.conf を以下のように設定します。
spark-defaults.conf
spark.master yarn-client spark.driver.extraJavaOptions -Dhdp.version=2.3.0.0-2557 spark.yarn.am.extraJavaOptions -Dhdp.version=2.3.0.0-2557 spark.eventLog.enabled true spark.eventLog.dir hdfs://hdp-node1:8020/user/sakura/spark-events spark.history.fs.logDirectory hdfs://hdp-node1:8020/user/sakura/spark-events spark.yarn.historyServer.address hdp-node1:18080
spark.master はSparkのアプリケーションの実行モードを決定するためのプロパティです。 ローカルで実行、Sparkが提供するクラスタ管理の上で実行、YARNやMesosなどのクラスタ管理の上で実行、といった設定が可能です。 ここでは yarn-client という値を指定し、Hadoopが提供するクラスタ管理であるYARN上で実行するよう指定します。
spark.driver.extraJavaOptions と spark.yarn.am.extraJavaOptions はそれぞれSparkアプリケーション実行時に起動するJava VMのオプションを追加するプロパティです。 ここで、先ほど確認したHDP Versionの値を追加します。今回の構成では、HDP Versionは必須なので必ず設定してください。
spark.eventLog.enabled 以降の4つのプロパティは、SparkのHistory Serverを利用するための設定です。 Hisotry Serverについては後ほど説明します。
補足: yarn-cluster 向けの設定
※ここで説明する手順は必須ではないので、とりあえず先に進みたい方は読み飛ばしてください。
上記では、 spark.master の値に yarn-client と指定しましたが、 SparkをYARN上で動作させる場合には yarn-cluster というモードを指定することもできます。 このモードの違いを説明するために、少しだけSparkのアプリケーション実行の仕組みを説明します。
Sparkアプリケーションは、アプリケーションの実行管理やスケジューリングを受け持つ1つの「Driver」プロセスと、 アプリケーションの個々のタスクを分散して実行する複数の「Executor」プロセスが協調して動作します。 詳しくは、SparkのドキュメントCluster Mode Overviewを参照してください。
yarn-client はDriverプロセスがYARNの管理外で実行されますが、 yarn-cluster はDriverプロセスがYARNの管理下で(つまりYARNのコンテナ上で)実行されます。 詳しくは、SparkのドキュメントRunning Spark on YARNを参照してください。
Hadoopクラスタで利用可能なリソースの潤沢さにもよりますが、リソース管理やログ管理などの運用面ではyarn-cluster のほうがメリットがある点も多いです。 今回はクラスタが小さいことと、 yarn-cluster では後ほど説明するツール「Spark Shell」が yarn-cluster モードでは使用できないため、 yarn-client モードを使用します。
なおHDPでは、 yarn-cluster を利用する場合、アプリケーション実行時のクラスパス解決のために追加の設定が必要です。 Sparkのインストールディレクトリ配下に conf/java-opts というファイルを作成し、HDP Versionを解決するためのシステムプロパティを設定します。
echo "-Dhdp.version=2.3.0.0-2557" > $HOME/spark/conf/java-opts
クライアントのログ設定
デフォルトの設定で出力されるINFOログはかなり量が多いので、 ログの出力を抑止したい、いった場合にはログ設定を変更します。
Sparkが出力するログの設定を変更するには conf/log4j.properties を編集します (正確には、YARN上で実行する場合はこの方法によるログの設定はDriverプロセスのみ有効です)。
log4j.properties を編集する場合、 conf/log4j.properties.template というテンプレートファイルがあるので、これをコピーして編集するとよいでしょう。
以下は、INFOログの出力を抑止してWARN以上のログレベルの出力のみを行う例です。 テンプレートファイルを変更する場合、2行目の ...=INFO, console を ...=WARN, console に変更します。
# Set everything to be logged to the console log4j.rootCategory=WARN, console ...
イベントログとHistory Serverの設定
Sparkではアプリケーション実行時に「イベントログ」を出力するよう設定しておくと、 Sparkが提供するWeb UIからアプリケーションの実行情報の詳細を確認することができます。 また、Hisotry Serverからはアプリケーションの実行履歴の詳細を確認することができます。
先に説明した spark-defaults.conf の例では、イベントログとHistory Serverの設定を行っています。 spark.eventLog.enabled を true にするとイベントログの出力が有効になり、 spark.eventLog.dir 、 spark.history.fs.logDirectory にそれぞれイベントログの出力先を指定します。spark.yarn.historyServer.address は後ほど説明するHadoopの管理画面からHistory Serverへのリンクを設定するためのプロパティです。
イベントログの出力先には hdfs://hdp-node1:8020/user/sakura/spark-events と設定していますので、 これに対応するHDFS上のディレクトリを以下のように作成します。
hadoop fs -mkdir /user/sakura/spark-events
これでHistory Serverを使う準備は整ったので、History Serverを起動します。 History Serverを起動するには、 sbin/start-history-server.sh を実行します。
./sbin/start-history-server.sh
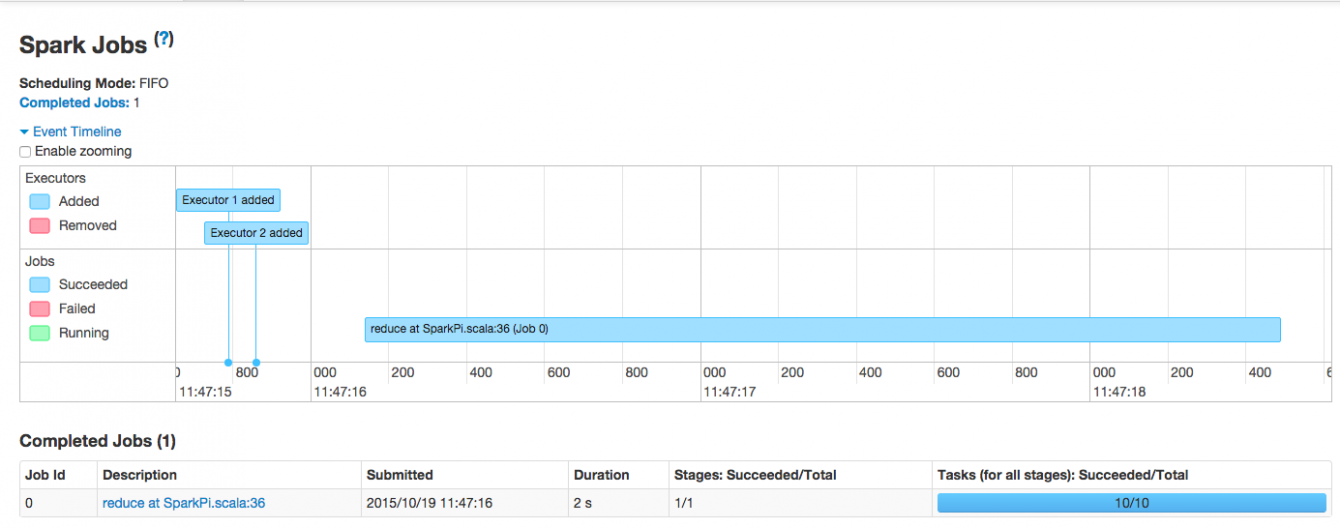
ブラウザからHistory Serverにアクセスしてみましょう。 今回の設定では、 http://hdp-node1:18080 を指定します。
正しくアクセスできた場合、以下のような画面が表示されます。

まだSparkアプリケーションを実行していないため、アプリケーションがないというメッセージが表示されています。
サンプルアプリケーションの実行
まずは、疎通確認も兼ねてSparkに同梱されているシンプルなアプリケーション「モンテカルロ法による円周率計算」用アプリケーションを実行してみます。 Hadoopを使ったことがある方は、同様のサンプルアプリケーションがMapReduceでも提供されていたことをご存じかもしれません。
以下は、円周率計算アプリケーション SparkPi の実行例です。 ビルド済のSparkアプリケーションは spark-submit コマンドで実行することができます。
./bin/spark-submit --class org.apache.spark.examples.SparkPi lib/spark-examples*.jar 10
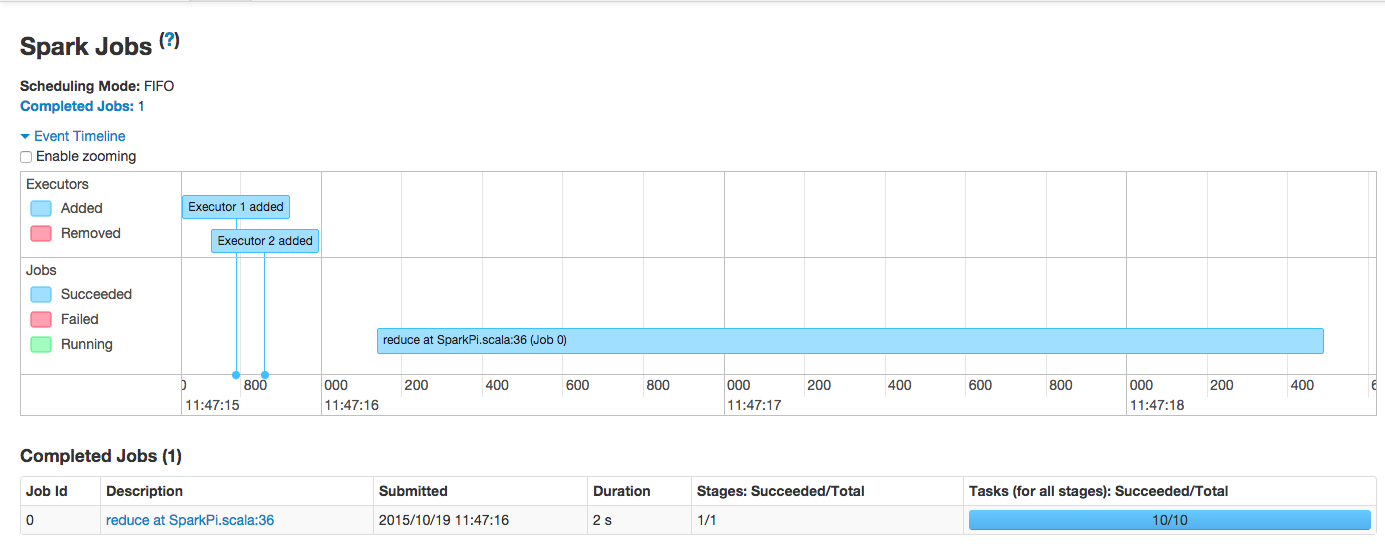
正しく実行されると、以下のように計算結果が出力されます。
15/10/14 12:39:04 INFO spark.SparkContext: Running Spark version 1.5.1 ... Pi is roughly 3.14356 ...
Web UIを使ったアプリケーションの確認
YARN上で実行するアプリケーションの実行状況は、Hadoopが提供する管理画面「Resource Manager Web UI」で確認することができます。 ブラウザから、YARNのResource Managerを実行しているマシンに対してポート 8088 にアクセスします。 今回の環境では、 http://hdp-node1:8088 にアクセスします。
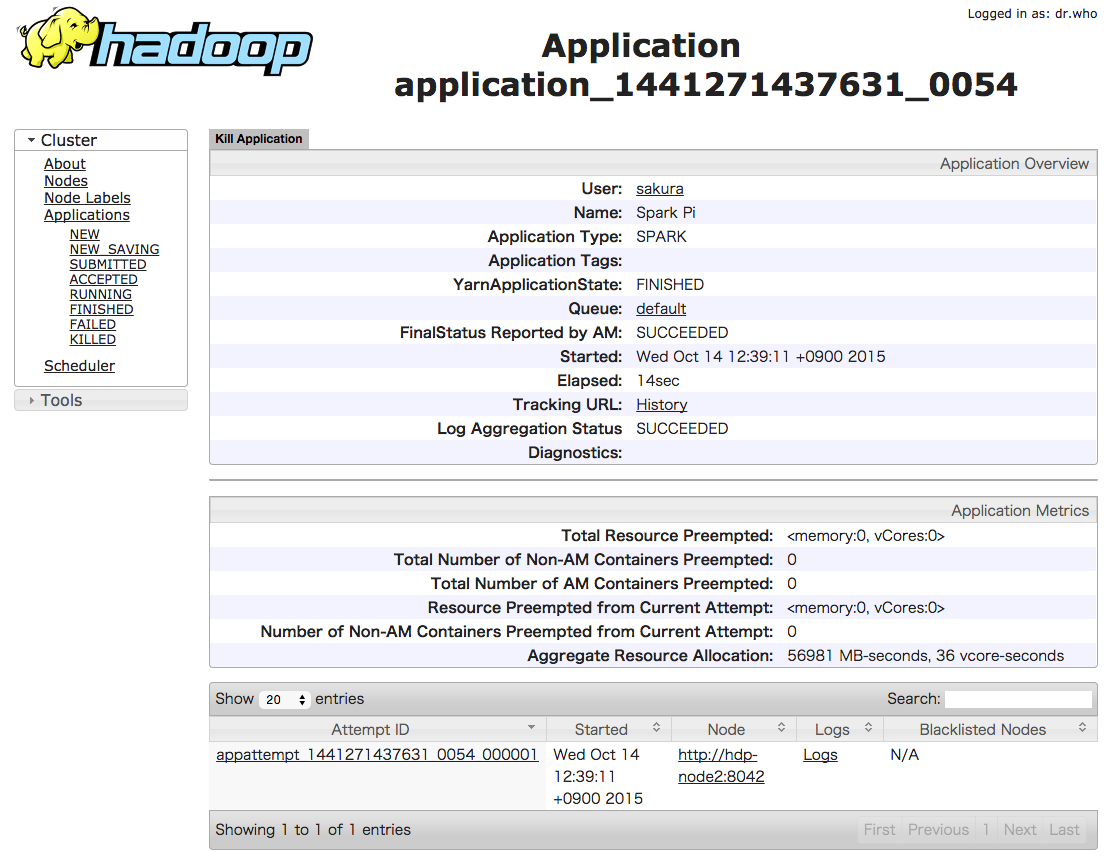

この画面ではアプリケーションの一覧やその詳細を確認することができます。 また「History」リンクからはアプリケーションの実行履歴を管理するサービスのWeb UIにアクセスできます。 Sparkアプリケーションの場合、リンク先SparkのHisotry Serverの画面が表示されます。

Spark Shellを使ったアプリケーションの実行
Sparkでは対話式にプログラムを入力してアプリケーションを実行する「Spark Shell」というツールが同梱されています。
SparkのドキュメントQuick Startには、 Spark Shellを使ったチュートリアルが公開されています。 ここではこのドキュメントに沿って、テキストファイルを処理する簡単なアプリケーションを実行してみます。
まず、入力となるテキストファイルをHDFS上の /home/sakura/wordcount/input というディレクトリに配置します。 sakuraユーザでHDFS上にwordcount/input というディレクトリを作って、 Sparkのインストールディレクトリ直下にあるテキストファイル README.md を置きます。
hadoop fs -mkdir -p wordcount/input hadoop fs -put $HOME/spark/README.md wordcount/input
Spark Shellは、プログラム言語にScala、Pythonを使うための実行コマンドがそれぞれ用意されています。 ここではScalaを利用するSpark Shell bin/spark-shell を実行します。
./bin/spark-shell
しばらくすると scala> というプロンプトが表示されます。 ここからSparkアプリケーションのプログラムを入力していきます。
scala>
まず入力ファイルを読み込み、「RDD」と呼ばれる抽象データセットを構築します。
scala> val textFile = sc.textFile("wordcount/input/*")
textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:21
Sparkのプログラムでは、このRDDに対して変換処理や出力処理を記述します。 まずは、RDDに対してシンプルな出力処理(アクション)を実行してみます。
scala> textFile.count() // データセットの要素数(ここではファイルの行数)を返す ... res0: Long = 98 scala> textFile.first() // データセットの先頭の要素(ここではファイルの先頭行)を返す ... res1: String = # Apache Spark
より複雑な処理を記述する場合、RDDに対して変換処理を行い別のRDDを返す、というプログラムを記述していきます。 以下は、これも分散処理用のフレームワークの例としてよく取り上げられるワードカウントの例です。
// ワードカウント用のRDD
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
...
// RDDの全ての要素を返す
scala> wordCounts.collect()
最後に、ワードカウントの結果をHDFS上に出力します。
scala> wordCounts.saveAsTextFile("wordcount/output")
Spark Shellを終了するには exit と入力します。
scala> exit
Hadoopのコマンドでワードカウントの出力結果を表示してみます。
hadoop fs -text wordcount/output/* (package,1) (this,1) ...
このように、Spark Shellを利用することでSparkアプリケーションのためのプログラミングを簡単に試すことができます。 SparkアプリケーションのプログラミングやRDDに関するより詳しい情報は、 Sparkのドキュメント Spark Programming Guideを参照してください。
Spark SQL
Spark SQLは構造化データに対してSQLを使った操作を提供するRDDベースのAPI「Data Frame」や、Spark上でSQLの処理を分散実行するクエリー実行エンジンなどの機能を提供します。 また、Hadoopが提供するクエリー実行エンジン「Hive」のメタデータを利用することで、Hiveとの連携や互換性のある運用を行うことが可能です。
今回はSpark SQLの機能のうち、Spark SQLが提供するThrift JDBC/ODBC Server(以下「Thriftサーバ」)を経由して、Hiveのメタデータ上にテーブルを定義してSQLでアクセスする、という使い方を紹介します。
SQLの実行にThriftサーバを経由する構成にすることで、 JDBCやODBCに対応した様々なデータベースクライアントやアプリケーション、BIツールなどを使って Spark環境と連携することができます。
なお、今回はSpark SQL環境にアクセスするクライアントとして、Sparkに同梱しているJDBC環境用のCLIである「Beeline」というツールを使います。
Hive連携用の設定
Spark SQLをHadoopクラスタ上のHiveと連携するには、設定ファイル conf/hive-site.xml を作成し、 このファイルにHadoopクラスタ上のメタストアサーバのURIを指定します。
ここでは、 conf/hive-site.xml を以下のように作成します。
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://hdp-node1:9083</value> </property> </configuration>
Thriftサーバの起動とBeelineによる接続
Thriftサーバを起動します。
Thriftサーバのデフォルトポートは 10000 ですが、HDPの標準構成では同ポートでHive向けのThriftサーバであるHiveServer2が起動しているので、 ここではポートに 10001 を指定してサーバを起動します。
./sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=10001
Thriftサーバが起動したら、ThriftサーバにBeelineで接続します。
ThriftサーバのURLと接続ユーザを指定して、 bin/beeline を実行します。
./bin/beeline -u jdbc:hive2://hdp-node1:10001 -n sakura
接続に成功すると以下のようにプロンプトが表示されます。
Connecting to jdbc:hive2://hdp-node1:10001 INFO jdbc.Utils: Supplied authorities: hdp-node1:10001 INFO jdbc.Utils: Resolved authority: hdp-node1:10001 INFO jdbc.HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://hdp-node1:10001 Connected to: Spark SQL (version 1.5.1) Driver: Spark Project Core (version 1.5.1) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 1.5.1 by Apache Hive 0: jdbc:hive2://hdp-node1:10001>
テーブルの操作
まずテーブルを作成します。 SparkにはSpark SQL用のテストデータが同梱されているので、ここではこのデータ構造に対応したテーブルを作成します。 テーブルを作成する際には、テーブルデータを配置するHDFS上のロケーションを指定します。
0: jdbc:hive2://hdp-node1:10001> CREATE TABLE IF NOT EXISTS src ( 0: jdbc:hive2://hdp-node1:10001> key INT, 0: jdbc:hive2://hdp-node1:10001> value STRING 0: jdbc:hive2://hdp-node1:10001> ) LOCATION '/user/sakura/tables/src';
テーブルが作成できたことを確認します。
0: jdbc:hive2://hdp-node1:10001> desc src; +-----------+------------+----------+--+ | col_name | data_type | comment | +-----------+------------+----------+--+ | key | int | NULL | | value | string | NULL | +-----------+------------+----------+--+
テストデータをテーブルにロードします。
0: jdbc:hive2://hdp-node1:10001> LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src;
データがロードできたことを確認するためにテーブルのレコード件数を表示します。
0: jdbc:hive2://hdp-node1:10001> SELECT COUNT(*) FROM src; +------+--+ | _c0 | +------+--+ | 500 | +------+--+
いくつかクエリーを発行してみましょう。
0: jdbc:hive2://hdp-node1:10001> SELECT * FROM src WHERE key < 10 ORDER BY key; +------+--------+--+ | key | value | +------+--------+--+ | 0 | val_0 | | 0 | val_0 | | 0 | val_0 | | 2 | val_2 | | 4 | val_4 | | 5 | val_5 | | 5 | val_5 | | 5 | val_5 | | 8 | val_8 | | 9 | val_9 | +------+--------+--+ 10 rows selected (0.932 seconds)
Beelineを終了するには !quit と入力します。
0: jdbc:hive2://hdp-node1:10001> !quit
また、Thriftサーバを終了するには以下のように実行します。
./sbin/stop-thriftserver.sh
今回紹介した機能の他にも、Spark SQLにはDataFrameなど様々な機能があります。 興味がある方はSparkのドキュメントSpark SQL and DataFrame Guideを参照してみてください。
Spark Streaming
Spark StreamingはSparkでストリーム処理を行うためのコンポーネントです。
ストリームデータをRDDとして扱うことで、Saprkアプリケーションと同様のデータ操作が可能なことに加え、 ストリームデータに対して時系列の分析を行うためのウィンドウ演算などの機能が利用できます。
データの入出力にはHDFSなど通常のSparkアプリケーションで扱うことができるものに加えて、 KafkaやFlumeといった大量データを扱うためのメッセージングシステムにも対応しています。
今回は、Sparkに同梱されているSpark Streaming用のサンプルアプリケーションの中から、 TCPソケットとして受け取ったテキストデータをワードカウントする、というアプリケーションを実行してみます。
./bin/spark-submit --class org.apache.spark.examples.streaming.SqlNetworkWordCount \ lib/spark-examples*.jar hdp-node1 9999
このアプリケーションは2秒間隔で指定ポート(今回は 9999)からテキストデータを受け取り、ワードカウントを実行します。 まだ入力となるポートをオープンしていないため、実行間隔ごとに以下のログが出力されてしまいます。
ERROR ReceiverTracker: Deregistered receiver for stream 0: Restarting receiver with delay 2000ms: Error connecting to hdp-node1:9999 - java.net.ConnectException: Connection refused
このアプリケーションに入力データを送信するために、別ターミナルから nc コマンド実行します。 Sparkを実行するターミナルとは別のターミナルを準備して、以下のように実行します。
nc -lk 9999
このターミナル上でてきとうに文字を入力します。各ワードは半角スペースの区切ります。
abc def h h i jk jk hoge fuga hoge
Spark Streamingアプリケーションはこの入力を受け取り、処理間隔の都度ワードカウントを実行して出力します。
... ========= 1444880442000 ms ========= +----+-----+ |word|total| +----+-----+ | def| 1| | h| 2| | i| 1| | abc| 1| | jk| 2| +----+-----+ ========= 1444880444000 ms ========= +----+-----+ |word|total| +----+-----+ |fuga| 1| |hoge| 2| +----+-----+ ...
このサンプルアプリケーションのソースコードはこちらに公開されています。
このアプリケーションでは、Spark Streaming経由で流れてくるデータからSpark SQLのDataFrameを使って一時テーブルを作成し、SQLを使って集計処理を行っています。 このように、Spark SteamingではSpark SQLをはじめ、Sparkの様々な機能と連携できるようになっています。
興味がある方はSparkのドキュメントSpark Streaming Programming Guideを参照してみてください。
終わりに
今回はHadoopクラスタにSparkをセットアップして、Sparkの様々な機能を使ってみました。Sparkの特徴や利用イメージが少しでも伝われば幸いです。
次回は、HadoopクラスタにAsakusa Frameworkをセットアップし、いくつかのAsakusaバッチアプリケーションを実行してみます。 Spark SQLなどのクエリ実行エンジンとの連携についても紹介する予定です。