対話可能な選択的機械除草ロボットのプロジェクトとさくらの専用サーバの利用について

はじめに
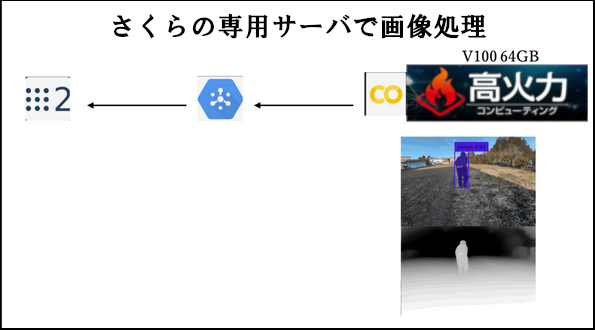
2023年度未踏IT人材発掘・育成事業のために、さくらの専用サーバ 高火力シリーズの「NVIDIA V100(64GB)」プランを貸していただいた。プロジェクトのホームページからロボットが動く様子を事前に見ておくと本記事の理解に役立つだろう。
ロボット制御の仕組み
言葉の指示をロボットが実行できるコマンドに変換して、ロボットを制御するシステムを開発した。言葉の指示はWhisperで文字起こししてGPT-4によってコマンドに変換した。

ロボットに取り付けたカメラからGoogle Cloud Pub/Sub経由で画像を送信してサーバで処理をし、処理結果をローカルに戻してロボットを制御した。ロボット開発のフレームワークはROS 2を用いて、さくらの専用サーバとは画像や処理結果の通信をした。
コマンドはGO_TOとGO_ALONGの2種類実装した。ユーザの言葉の指示をなるべくこの2つのコマンドで対処できるようにプロンプトの設計をした。
GO_TOについて
どこか目印の元へ向かう言葉の指示、例えば「家のとこまで向かって」や「私についてきて」という指示はそれぞれGO_TO("house")やGO_TO("person")というコマンドに変換される。引数には検出したいクラス名を渡す。それの検出・セグメンテーションにはGrounded-SAMを使用した。画像内の相対的な位置をもとにロボットが向かうべき方向を決定する。一方で単眼メトリック深度推定用のモデルZoeDepthも常に回しておいて、目的の物体にある程度近づいたら止まるようにした。

GO_ALONGについて
物体をなぞりながら移動するためのコマンド。GO_ALONG("road")やGO_ALONG("crop row")といったものを想定している。作物列は一般的なオブジェクトではなく、Grounding DINOでは検出することが不可能である。そこで作物列専用の検出モデルをdetectron 2を微調整することで作成したが、これについては本記事では省略する。

環境構築
コード全体を示すと非常に長く煩雑になるので、本記事用に短くしたコードを掲載する。ここではGoogle Cloud Pub/Sub経由で得た画像を逐次処理するコードを示す。処理とは具体的に深度推定+セグメンテーション、深度推定の処理画像を表示するようにしている。環境構築の方法から解説するので、これを見ながら手元で動かすこともできる。
dockerでcuda12.1の環境を作る。
docker run -it --gpus all --network=host nvidia/cuda:12.1.0-devel-ubuntu20.04 /bin/bash作成したコンテナを立ち上げる。
docker start [ID]
docker exec [ID] -it/bin/bash必要なパッケージをインストールする。
apt update
apt install -y wgetapt-get install -y unzip git python3.9 python3-pip python3.9-dev python3.9-venv python-numpy libgl1-mesa-glx libglib2.0-0仮想環境を作成する。
cd ~python3.9 -m venv ohanasource ohana/bin/activatejupyterを使えるようにしておく。また、wheelをあらかじめインストールする。
python -m pip install jupyterlabpip install wheel新しいターミナルでssh接続してjupyterを立ち上げる。ポートフォワーディングしておくこと。
ssh -L 8888:localhost:8888 ubuntu@IPAddr
jupyter lab --allow-root --NotebookApp.allow_origin='<https://colab.research.google.com>' --port=8888 --NotebookApp.port_retries=0 --ip=*ローカルPCでGoogle Colabを立ち上げてローカルランタイムに接続する。
Grounding DINOのために、最初にCUDA_HOMEのパス設定をしておく。
echo 'export CUDA_HOME=/usr/local/cuda' >> ~/.bashrc
source ~/.bashrcあとは以下のコードを実行すればできる。
実装
- ソースコードのインポート
!pwd
import os
HOME = "/root/workspace"
print("HOME:", HOME)
### ZoeDepth
%cd {HOME}
!pip install --upgrade timm==0.6.7 #このバージョンじゃないとエラーが出る
!pip install scipy
!git clone https://github.com/isl-org/ZoeDepth.git
%cd {HOME}/ZoeDepth
import torch
zoe = torch.hub.load(".", "ZoeD_NK", source="local", pretrained=True) # NK : MDE model
zoe = zoe.to('cuda')
from zoedepth.utils.misc import get_image_from_url, colorize
!pip3 install --upgrade google-api-python-client
!pip3 install --upgrade google-cloud-pubsub
!pip install pytz #timestamp of JST
from datetime import datetime
import pytz
import torch
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import cv2
import base64
import json
import os
import time
from datetime import datetime
from google.cloud import pubsub_v1
from queue import Queue, Full
from threading import Lock
from concurrent.futures import ThreadPoolExecutor
from typing import List
from scipy import stats
from threading import Lock, Thread
from multiprocessing import Pool
### Grounding DINO
%cd {HOME}
!git clone https://github.com/IDEA-Research/GroundingDINO.git
%cd {HOME}/GroundingDINO
!git checkout -q 57535c5a79791cb76e36fdb64975271354f10251
!pip install -q -e .- モデルロードやSegment Anything Modelのインポート
### Grounding DINO
%cd {HOME}
import supervision as sv
import torch
import GroundingDINO.groundingdino.datasets.transforms as T
from GroundingDINO.groundingdino.models import build_model
from GroundingDINO.groundingdino.util import box_ops
from GroundingDINO.groundingdino.util.slconfig import SLConfig
from GroundingDINO.groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
from GroundingDINO.groundingdino.util.inference import annotate, load_image, predict
from huggingface_hub import hf_hub_download
def load_model_hf(repo_id, filename, ckpt_config_filename, device='cpu'):
cache_config_file = hf_hub_download(repo_id=repo_id, filename=ckpt_config_filename)
args = SLConfig.fromfile(cache_config_file)
args.device = device
model = build_model(args)
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
checkpoint = torch.load(cache_file, map_location=device)
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
print("Model loaded from {} \n => {}".format(cache_file, log))
_ = model.eval()
return model
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "groundingdino_swinb_cogcoor.pth"
ckpt_config_filename = "GroundingDINO_SwinB.cfg.py"
device = 'cuda'
groundingdino_model = load_model_hf(ckpt_repo_id, ckpt_filenmae, ckpt_config_filename, device)
### SAM
import sys
%cd {HOME}
!{sys.executable} -m pip install 'git+https://github.com/facebookresearch/segment-anything.git'
%cd {HOME}/../weights
lighter sam model
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
SAM_CHECKPOINT_PATH = os.path.join(HOME, "../weights", "sam_vit_b_01ec64.pth")
SAM_ENCODER_VERSION = "vit_b"
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry[SAM_ENCODER_VERSION](checkpoint=SAM_CHECKPOINT_PATH).to(device='cuda')
sam_predictor = SamPredictor(sam)
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import cv2
import base64
import json
import os
import pytz
import time
from datetime import datetime
from google.cloud import pubsub_v1
from queue import Queue, Full
from threading import Lock
from concurrent.futures import ThreadPoolExecutor
from typing import List
from scipy import stats
from threading import Lock, Thread
from multiprocessing import Pool
from segment_anything import SamPredictor
from scipy import ndimage
import matplotlib.patches as patches- Grounding DINO用の関数
%cd {HOME}
from GroundingDINO.groundingdino.util.inference import annotate, load_image, predict
import numpy as np
import torch
from PIL import Image
from torchvision import transforms as T
from typing import Tuple
def detect(image, text_prompt, model, box_threshold = 0.3, text_threshold = 0.25):
image_numpy, image_tensor = load_image_from_numpy(image)
boxes, logits, phrases = predict(
model=model,
image=image_tensor,
caption=text_prompt,
box_threshold=box_threshold,
text_threshold=text_threshold
)
annotated_frame = annotate(image_source=image_numpy, boxes=boxes, logits=logits, phrases=phrases)
annotated_frame = annotated_frame[...,::-1] # BGR to RGB
return annotated_frame, boxes
### for grounding dino image input
def load_image_from_numpy(image_data: np.array) -> Tuple[np.array, torch.Tensor]:
transform = T.Compose([
T.Resize(800),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# NumPy配列をRGBに変換(もしBGRフォーマットの場合)
if image_data.shape[2] == 3: # 3チャンネルの画像であることを確認
image_data = cv2.cvtColor(image_data, cv2.COLOR_BGR2RGB)
# NumPy配列からPILイメージに変換
image_pil = Image.fromarray(image_data)
image_transformed = transform(image_pil)
return image_data, image_transformed- SAM用の関数
def segment(image, sam_model, boxes):
sam_model.set_image(image)
H, W, _ = image.shape
boxes_xyxy = box_ops.box_cxcywh_to_xyxy(boxes) * torch.Tensor([W, H, W, H])
transformed_boxes = sam_model.transform.apply_boxes_torch(boxes_xyxy.to(device), image.shape[:2])
masks, _, _ = sam_model.predict_torch(
point_coords = None,
point_labels = None,
boxes = transformed_boxes,
multimask_output = False,
)
return masks.cpu()
def draw_mask(mask, image, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.8])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
annotated_frame_pil = Image.fromarray(image).convert("RGBA")
mask_image_pil = Image.fromarray((mask_image.cpu().numpy() * 255).astype(np.uint8)).convert("RGBA")
return np.array(Image.alpha_composite(annotated_frame_pil, mask_image_pil))- Google Cloud Pub/Subからの画像から最新の画像を取得する関数。これを実行するにはGoogle Cloud Pub/Subの設定が必要。また、ROS 2の方で画像を送信する必要がある。もしこれができなければ動画ファイルを置いておき、そこから読み込むなどして対応すれば良い。
class ImagePool:
def __init__(self, pub_sub_project="Serika-vision", pub_sub_subscription="image-pubsub-topic-sub"):
self.subscriber = pubsub_v1.SubscriberClient()
self.pub_sub_project = pub_sub_project
self.pub_sub_subscription = pub_sub_subscription
self.latest_image = None
self.lock = Lock()
def start_subscribing(self):
subscription_path = self.subscriber.subscription_path(self.pub_sub_project, self.pub_sub_subscription)
self.subscriber.subscribe(subscription_path, callback=self.callback)
print(f"Listening for messages on {subscription_path}..\n")
def callback(self, message):
try:
payload = json.loads(message.data.decode('utf-8'))
message.ack()
if "image" in payload:
image_data = base64.b64decode(payload["image"])
image = np.frombuffer(image_data, dtype=np.uint8)
image = cv2.imdecode(image, flags=1)
with self.lock:
self.latest_image = image
except Exception as e:
print(f"Error occurred while processing message: {str(e)}")
def get_latest_image(self):
with self.lock:
return self.latest_image- 画像処理
class AIInference:
def __init__(self):
self.save_image = False
self.frame_number = 0
self.classes = 'person,tree,house'
self.box_threshold = 0.35
self.text_threshold = 0.25
def process_grounding_sam(self, image):
try:
annotated_frame, detected_boxes = detect(image, text_prompt=self.classes, model=groundingdino_model)
segmented_frame_masks = segment(image, sam_predictor, boxes=detected_boxes)
if len(detected_boxes) == 0:
print("No specified object detected. ")
return None
annotated_image = draw_mask(segmented_frame_masks[0][0], annotated_frame)
return annotated_image
except Exception as e:
print(f"Error occurred while grounding sam: {str(e)}")
return None
def process_depth_estimation(self, image):
try:
depth = zoe.infer_pil(image)
colored_depth = colorize(depth)
print('depth estimated')
return colored_depth
except Exception as e:
print(f"Error occurred while depth estimation: {str(e)}")
return None- main
def main():
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = f"{HOME}/serika-vision-~~~.json"
image_pool = ImagePool()
ai_inference = AIInference()
ai_inference.classes = 'person,glasses,hat'
image_pool_thread = Thread(target=image_pool.start_subscribing)
image_pool_thread.daemon = True # Ensures the thread will close when main exits
image_pool_thread.start()
try:
while True:
latest_image = image_pool.get_latest_image()
if latest_image is not None:
grounding_sam_image = ai_inference.process_grounding_sam(latest_image)
depth_image = ai_inference.process_depth_estimation(latest_image)
if grounding_sam_image is not None:
plt.figure(figsize=(6, 6))
plt.imshow(grounding_sam_image)
plt.axis('off')
if depth_image is not None:
plt.figure(figsize=(6, 6))
plt.imshow(depth_image)
plt.axis('off')
plt.show()
cv2.waitKey(1)
except KeyboardInterrupt:
print("keyboard interrupt...")
finally:
image_pool.subscriber.close()
image_pool_thread.join()最後に
これにより所望の処理結果が画像として表示される。本プロジェクトではこの結果をROS 2側に送信してロボットを操縦する。ただし、本記事ではコマンドに合わせて処理内容を変える部分も省略している。