Stable Diffusionの使い方と追加学習によるLoRAの作成 〜GPUコンテナサービス "高火力 DOK" の活用〜


この記事は、2024年6月29日(土)に行われたオープンソースカンファレンス2024 Hokkaidoにおけるセミナーを、さくナレ編集部にて記事化したものです。
目次
はじめに
さくらインターネットの江草と申します。今日は、つい数日前、6/27(木)に発表した弊社のサービス「高火力 DOK」という、GPUを使ってDockerのコンテナを実行できるサービスを活用して、Stable Diffusionを使ってAIによる画像生成をします。単に生成するだけではおもしろくないので、別の画像、今回は自分で撮った写真から学習して、自分の写真を再度生成するというところまでを、高火力 DOKを使ってやっていきたいと思います。
記事の流れ

私はもともと写真撮影が趣味で、上記はAIではなく実際に撮った写真です。ちなみに左下は石狩小学校の撮影イベントで撮った写真です。こういった写真の趣味を生かして何か遊べたらいいなと思って昔やってたんで、それを高火力 DOKを使って再現しようという話です。
記事の流れとしては、はじめに参考情報として、GPUを積んだサーバを借りて、その上でDockerを使えるようにするにはどんな手順が必要なのかという話をします。単に高火力 DOKを使うだけならこの手順はいらないんですが、Dockerイメージを作るときに自分で試したいこともあると思うので説明しておきます。あるいは手元にGPUを積んだPCがある人は、そこにLinuxを入れてもたぶん同じように試せると思います。その後、Stable Diffusionが含まれたDockerのイメージを作るというか、中身の説明をします。イメージの作成はGPUを積んでいないPCでもできます。イメージの作成後、それを使って高火力 DOKの上でStable Diffusionのデモをします。

これは実際にAIで生成した画像ですね。こういうのが作れるという話です。
Nvidia V100でのDocker環境構築

NvidiaのV100というGPUをLinuxから直接使う場合は、こういった手順が必要です。
まず最初に、Linuxカーネルを最新版にしておく必要があります。最新である必要はないのですが、アップデートするとドライバーが動かなくなることがあるので、先にアップデート済ませておきます。次はcuda-driverというGPUのドライバーをインストールします。これも入れた後で再起動が必要です。それからDockerを普通にインストールして、nvidia-container-toolkitという、Dockerのコンテナの中でもGPUが使えるようになるというツールを入れると、GPUを使ってDockerのイメージを、手元のPCや借りたサーバなどで実行できるようになります。
以下、これらの手順を順番に説明します。なお、LinuxのディストリビューションとしてUbuntu 22.04を想定しています。
Linuxカーネルの更新
カーネルの更新は以下のコマンドで行います。カーネルの更新があった場合は、再起動しないと新しいカーネルで上がってこないので再起動します。
$ sudo apt update
$ sudo apt upgrade ‒y
$ sudo reboot # kernelの更新があった場合だけで良いcuda-driverのインストール
続いてCUDAのドライバを入れます。実行するコマンドを以下に示しますが、これはNvidiaの公式ドキュメントに載っている手順そのままです。手順の最後にあるように、これも再起動が必要です。
$ sudo apt-get install linux-headers-$(uname -r)
$ sudo apt-key del 7fa2af80
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
$ sudo dpkg -i cuda-keyring_1.1-1_all.deb
$ sudo apt-get update
$ sudo apt-get install cuda-drivers
$ sudo rebootここでちょっと注意が必要なのが、勝手にOSのアップデートが行われて、その結果、ソフトウェアのバージョンが合わなくなって動かなくなるということがあるので、継続的に使う場合はCUDAのドライバやカーネルは自動更新されないように設定しておくといった対策が必要です。ちょっと頭の片隅に置いといてもらえればと思います。
Dockerのインストール
Dockerのインストールは以下のコマンドで行います。最も簡単なインストール方法を記載しますが、別の方法でインストールしても構いません。
$ curl -fsSL https://get.docker.com/ | shnvidia-container-toolkitのインストール
その後、nvidia-container-toolkitを入れます。これも公式ドキュメントに載っている手順の通りですが長いです。インストールした後、Dockerのランタイムとしてnvidia-ctkを使うという設定を入れて、Dockerそのものを再起動してあげればインストールは終了です。Dockerを使ったインストールは割と簡単でいいですね。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | ¥
sudo gpg --dearmor ¥
-o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg ¥
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | ¥
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | ¥
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt-get update
$ sudo apt install -y nvidia-container-toolkit
$ sudo nvidia-ctk runtime configure --runtime=docker
$ sudo systemctl restart dockerNvidia V100でのDocker動作確認

動作確認はnvidia-smiというコマンドラインツールを使います。認識しているGPUのリストを表示したり、現在GPUをどれぐらい使っているかを取得します。これが動けばGPUを認識しているということで、コンテナの中でnvidia-smiを実行してみて、動けば概ねOKということになります。具体的なコマンドとしては以下を実行します。
$ sudo docker run -it --rm --runtime=nvidia --gpus all nvidia/cuda:12.5.0-devel-ubuntu22.04 nvidia-smiDockerを使わずにNvidiaのCUDAなどを使おうと思うと、この後さらにaptでcudaを入れたりいろいろする必要があります。一方で、Dockerでやると上記のコマンドで示すようにCUDAのライブラリなどが入った状態のDockerイメージをすでにNvidiaが用意してくれているので、これを使うとソフトウェアのセットアップがすごく楽になります。Dockerを使うメリットはこのあたりになるかなと思います。この後、Stable Diffusionが入ったイメージを作るときも、このNvidia公式のCUDAのイメージをベースにセットアップしていきます。
Stable Diffusion

インターネットを見ていると、Stable Diffusionで生成された画像がたくさん出てくるので、皆さんもどこかで見たことがあると思います。生成された画像や写真みたいなものの大半はStable Diffusionで生成されているのではないかと思います。
Stable Diffusionは、Stability AI社によって提供されている、画像をAIで生成するソフトウェアと、そのときに使う学習結果のモデルです。モデルもStable Diffusionが公式で公開しているものがあります。
そのモデルには、Stable Diffusion 1.5(SD 1.5)のモデルとか、SDXL(ちょっと質が良いというか解像度の高いモデル)、それから最新のものでは、Stable Diffusion 3 Mediumというモデルもあって、ソフトウェアとモデル両方がStable Diffusionと呼ばれています。
これらのモデルは、既存のモデルを拡張する形で追加の学習をすることができます。学習したモデルもフリーで公開されてたりします。このあたり、学習後に生成された画像が著作権的に大丈夫かどうかみたいな話は別の問題としてありますので実際に使う場合には注意が必要です。
Stable Diffusionは文字を書いて説明文から画像を作る(txt2img)こともできれば、画像から説明によって新しい画像を作ったり(img2img)とか、画像のうち一部だけを塗りつぶしてそこだけ生成するとか(inpaint)、そういった機能が提供されています。
今日は単純にtxt2img、つまり文字列から説明された内容の画像を生成するというところだけを使っていきたいと思います。
Stable Diffusionの実行方法
Stable Diffusionの使い方にはいくつか方法があります。
一番よく使われているのはおそらくStable Diffusion Web UIですね。セットアップして起動したらウェブサーバが起動して、ブラウザからアクセスすると操作画面が表示されて、文字を入れてスタートボタンを押すとその場で画像が生成されるというWeb UIを使う方法です。
もう一つは、これはあまり見かけないパターンですが、Pythonのライブラリが提供されているので、プログラムを書いてStable Diffusionの関数を呼んで画像を生成するという方法も利用できます。
そして今回採用する方法は、Web UIでもなく自分でPythonのコードを書くわけでもなく、その中間的な方法としてsd-scriptsという、Stable Diffusionをコマンドラインから操作できるようなスクリプトを利用します。今回はDockerのイメージに入れてコマンドラインで使いやすくすることが目的なので、今回はsd-scriptsを使ってやっていきます。
sd-scriptsが利用できるイメージを作る
sd-scriptsが入ったDockerイメージを作るんですが、先ほどもお伝えしたように自分でCUDAのセットアップなどをしていくと大変なので、まず基本としてCUDAのセットアップが終わったNvidia公式のCUDAイメージ(nvidia/cuda:12.5.0-devel-ubuntu22.04 など)をベースに使います。この後、sd-scriptsをインストールして、sd-scriptsにはモデルが含まれていないのでStable Diffusionのモデルも含めておいて、そして簡単に使うためのシェルスクリプトを書いて使いやすくするということをします。
以下のリポジトリにDockerfileなどを置いています。
https://github.com/chibiegg/sd-docker
このように、CUDAとsd-scriptsと、実際に使いたいモデルと、それを起動するための簡単なシェルスクリプトを一つのDockerイメージにまとめておけば、あとは引数だけ変えてどんどん実行すると、猫や日本の風景などいろいろなものを生成することができるので、再利用性が高い便利なイメージになります。
Dockerfile
Dockerのイメージを作るのは意外と簡単で、Dockerfileという専用のファイルを用意するんですが、ほとんど中身はシェルスクリプトみたいな感じになっています。基本になるイメージを選び、その後どんなコマンドを実行するかを書いていくと、そのコマンドが実行された結果を含む新しいイメージができ上がります。今回使用するDockerfileを以下に示します。
FROM nvidia/cuda:12.5.0-devel-ubuntu22.04
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
RUN apt update && apt upgrade -y
RUN apt install -y wget bzip2 build-essential git git-lfs curl ca-certificates libsndfile1-dev libgl1 python3 python3-pip python3-dev git wget curl
WORKDIR /opt
RUN git clone https://github.com/kohya-ss/sd-scripts.git
WORKDIR /opt/sd-scripts
RUN pip3 install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121
RUN pip3 install --upgrade -r requirements.txt
RUN pip3 install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu121
COPY default_accelerate_config.yaml /root/.cache/torch/accelerate/default_config.yaml
RUN mkdir /sd-models
RUN wget -O /sd-models/sd_xl_base_1.0.safetensors ¥
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
RUN wget -O /sd-models/sd_xl_refiner_1.0.safetensors ¥
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
RUN wget -O /sd-models/sdxl_vae.safetensors ¥
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/resolve/main/sdxl_vae.safetensors
ADD lora_config.toml.tmpl /opt/lora_config.toml.tmpl
ADD entrypoint.sh /opt/entrypoint.sh
ENTRYPOINT ["/opt/entrypoint.sh"]この例では、もともとCUDAが入っているDockerイメージに、環境変数などを設定し、apt-getで大事なものを入れて、それからsd-scriptsのリポジトリをgit cloneしてきて、PythonのPyTorchを入れたり、必要なライブラリを入れて、wgetでSDXLをダウンロードしてきて、シェルスクリプトを置いて完了という、こんなDockerfileを作成しています。これは一個書いておけば、いつでもこの手順を再現したイメージが生成できるという意味になります。
entrypoint.sh
最後に実行されるentrypoint.shというシェルスクリプトについて説明します。全体像は先ほど提示したGitHubのリポジトリを見てください。スクリプトの末尾は以下のようになっています。
nvidia-smi
TASK=$1
case "${TASK}" in
"generate" ) gen_image "$2" "$3" ;;
"learning" ) gen_lora "$2" "$3" "$4" ;;
"study" ) gen_lora "$2" "$3" "$4" ;;
esac引数としてgenerateとlearningを取れるようにしていて、それぞれgen_imageとgen_loraという関数が実行されます。このうちgen_image()関数は以下のようなスクリプトです。(一部省略しています)
function gen_image () {
PROMPT="$1"
NUM_IMAGES=1
if [ -n "$2" ]; then
NUM_IMAGES="$2"
fi
(省略)
EXTRA_ARGS=""
if [ -n "${LORA_URL}" ]; then
LORA_FILENAME=`basename "${LORA_URL}"`
curl -o "/opt/${LORA_FILENAME}" "${LORA_URL}"
EXTRA_ARGS="--network_module networks.lora --network_weights /opt/${LORA_FILENAME}"
fi
(省略)
python3 sdxl_gen_img.py ¥
--ckpt ${MODEL_FILE} ¥
--vae /sd-models/sdxl_vae.safetensors ¥
--images_per_prompt ${NUM_IMAGES} ${EXTRA_ARGS} ¥
--sampler ${SAMPLER} --steps ${STEPS} --batch_size ${BATCH_SIZE} ¥
--outdir ${SAKURA_ARTIFACT_DIR} --xformers --fp16 --prompt "${PROMPT}"
}gen_image()の中で、sdxl_gen_img.pyという、sd-scriptsに含まれているPythonのスクリプトが指定されています。これの引数を見ると、モデルとか、何枚の画像を生成したりとか、それから--promptという引数でどんな画像を生成したいかを指定するようになっています。こういった情報を引数で渡すと画像が生成されるというPythonのコードがあるので、それを使いやすいようにラッピングしただけのシェルスクリプトです。このあたりは、自分がDockerイメージの中でやりたいことに合わせて好きなように作ってもらったらいいかなと思います。
続いてgen_lora()関数です。(一部省略しています)
function gen_lora () {
DATA_URL="$1"
OUTPUT_NAME="$2"
CLASS_TOKENS="$3"
(省略)
mkdir -p /opt/data
curl ${DATA_URL} | tar zxvf - -C /opt/data
eval "echo ¥"$(cat /opt/lora_config.toml.tmpl)¥"" > /opt/lora_config.toml
(省略)
accelerate launch --num_cpu_threads_per_process ${NUM_PROCESS} sdxl_train_network.py ¥
--pretrained_model_name_or_path="${MODEL_FILE}" ¥
--dataset_config='/opt/lora_config.toml' ¥
--output_dir="${SAKURA_ARTIFACT_DIR}" ¥
--output_name="${OUTPUT_NAME}" ¥
--save_model_as=safetensors --prior_loss_weight=1.0 --resolution=1024,1024 ¥
--train_batch_size=1 --train_batch_size=${BATCH_SIZE} --
max_train_epochs=${MAX_TRAIN_EPOCHS} ¥
--learning_rate=1e-4 ¥
--xformers --mixed_precision="fp16" --cache_latents ¥
--gradient_checkpointing --network_module=networks.lora --no_half_vae
}こちらは学習に関するスクリプトです。学習については後でもっと細かく説明しますが、これも学習するためのコマンドが標準で用意されています。ただ引数が非常に多いので、使いやすいようにラッピングしてあげるということをこのシェルスクリプトでしています。こんなところでDockerイメージを作成する準備ができました。
高火力 DOKでの実演
ここから先は、これまでに説明した方法で作ったDockerイメージを使って、実際に画像生成をしてみたいと思います。
高火力 DOKとは

さくらインターネットが6月にリリースした「高火力 DOK」というサービスの説明をします。
高火力 DOKは、先ほど作ったようなDockerのイメージを、弊社のサーバに付いているV100、またはH100(近日提供予定)というGPUを使って実行できるというサービスです。Dockerイメージは、「コンテナレジストリ(Lab)」というサービスを弊社もやってますし、他にもいろんな会社が同様のサービスをやっているので、それらのコンテナレジストリサービスに預けることができます。そして、それを預けた状態で、そのイメージを弊社の高火力 DOKで使うことができます。
さらに、そのイメージを実行するときの引数や環境変数も指定することができます。例えば、同じDockerイメージから猫の画像を作ったり犬の画像を作ったり、別の画像を作ったり、10枚作ったり100枚作ったり、というようなことを、引数さえ変えれば同じDockerイメージで実行できます。実行する際に標準出力に出力された内容と、特定のディレクトリに出力された生成結果(画像や音声など結果として保存しておきたいファイル)を、全部のタスクが終わった後で圧縮した状態で弊社のシステムの方で預かっておきますので、後からダウンロードできるというサービスになっています。
課金単位はこのコンテナの実行時間秒数だけになっていて、1秒あたり0.06円です。画像生成であれば解像度にもよりますがだいたい1枚あたり20〜30秒ぐらいで生成できますので、30秒だとして1.8円でできるということになります。これは画面上でポチポチ操作することもできますが、最終的には自分のシステムに組み込んでいただきたいと思ってまして、APIで連携することができます。例えば一番シンプルな仕組みとしては、エンドユーザーがプロンプトの文字列を誰かのシステムに入れると、画像を生成するところだけを高火力 DOKにタスクとして入れて、生成結果がエンドユーザーに返るとかですね。そういった、GPUを使う部分だけを外に出してAPIで連携することで、AIを使ったシステムが組みやすくなるという使い方をしていただければと思っています。
高火力 DOKの操作
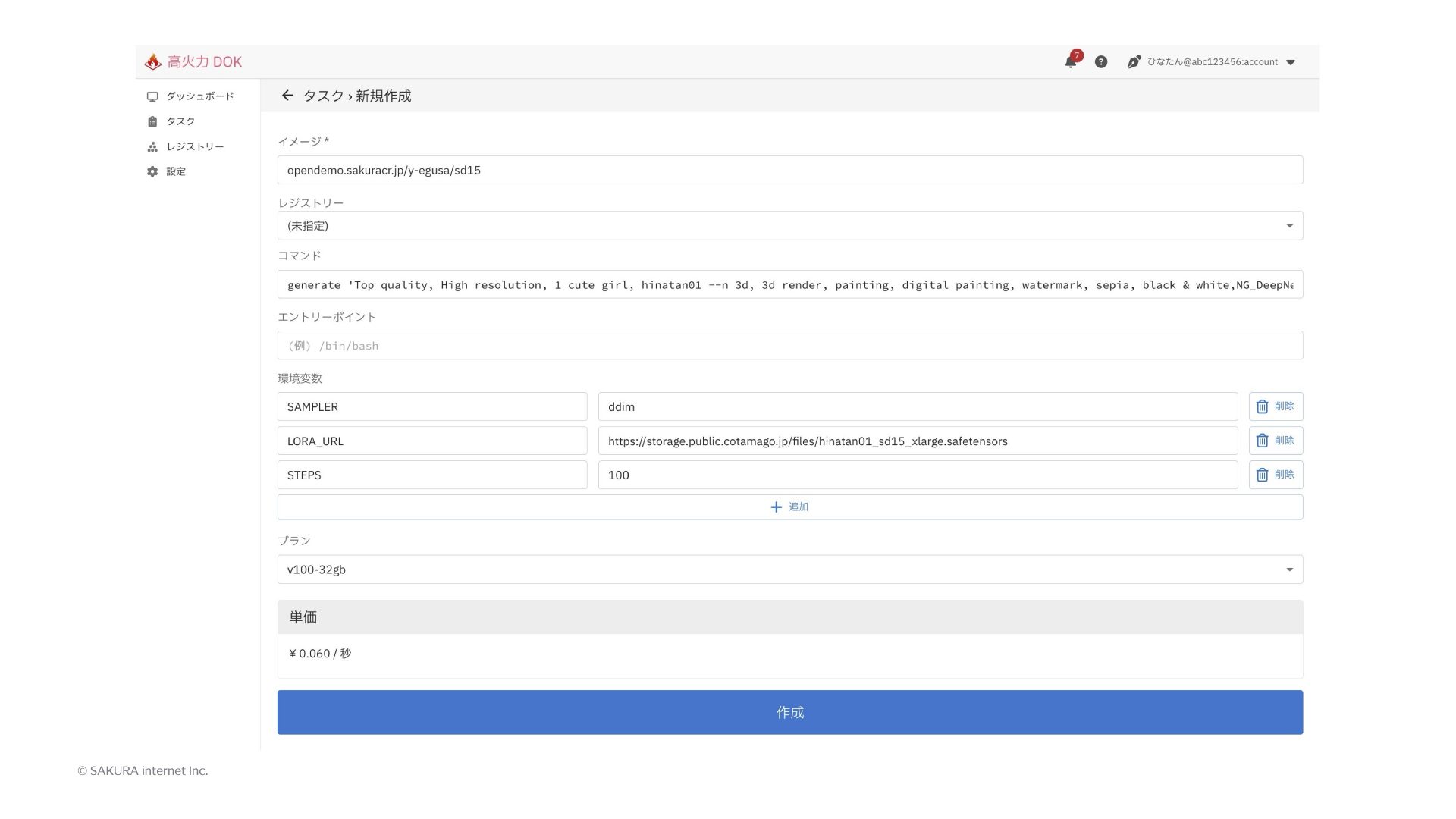
こちらが高火力 DOKの画面になります。APIからたたいてもらってもいいんですが、APIからたたくのと同じ内容を画面上でもたたけるようになってまして、Dockerを使ったことある方ならわかりやすいと思います。
まず「イメージ」のところに、実行するイメージを指定します。イメージの取得にパスワード認証情報が必要な場合は、事前に登録していただいた認証情報を「レジストリー」の欄に指定します。「コマンド」の欄には、エントリーポイントのシェルスクリプトの引数を書きます。第1引数がgenerateで、第2引数に生成したい画像のプロンプトを書いて、第3引数に枚数が入ります。あとは実行するときにつけておきたい環境変数を指定します。そしてプランを選び、作成ボタンを押すとタスクが作成されて実行されます。
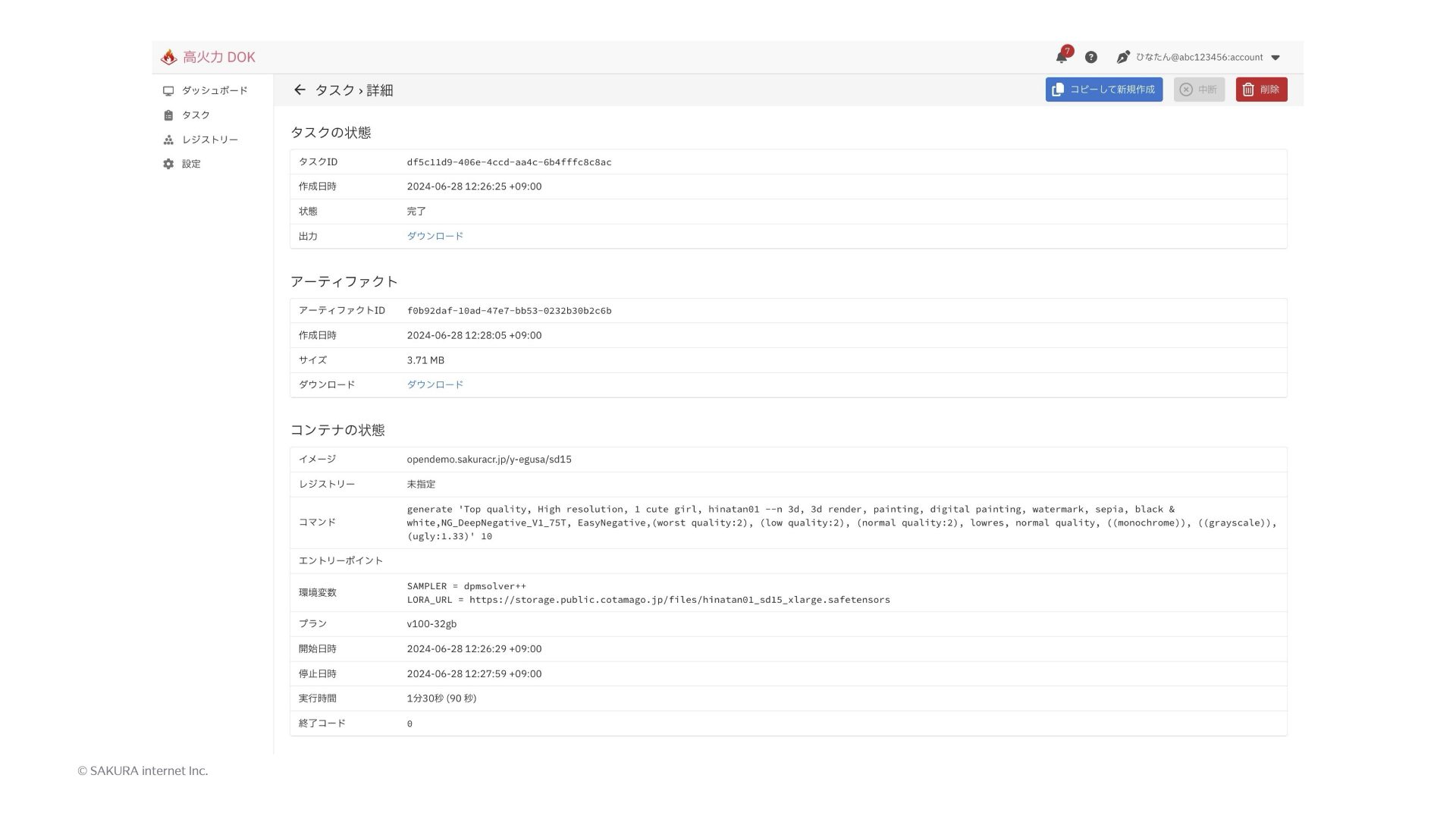
しばらく経ってタスクの実行が終わると、タスクの詳細画面で「状態」が「完了」になり、その下の「出力」に標準出力および標準エラーのダウンロードリンクが表示されます。それから、「アーティファクト」の下の「ダウンロード」から、成果物のダウンロードができます。ダウンロードの上の「サイズ」が成果物のファイルサイズで、今回の例では3.71MBとなっています。ページ下部には実行時間も表示され、今回の例では90秒になっています。
推論 (画像生成)

この高火力 DOKを使って、先ほど作ったDockerイメージで推論をしてみます。これはあくまでも今回作成したイメージの使い方なので、皆さんが使うときは引数や環境変数を実際に自分が使うイメージで置き換えていただきたいんですが、今回のイメージでは第1引数にgenerateを渡して、第2引数にプロンプト、第3引数に枚数を指定します。さらに環境変数で一部のパラメーターが設定できます。このようなシェルスクリプトになっています。

これで実際に猫の画像を作ってみようという場合には、上図のように指定します。特に第2引数のプロンプトですね。ここはStable Diffusionのコツなんですが、きれいな画像を出したいときは「Top quality」とか「High resolution」といった言葉を先頭に付けると、いい画像を生成してくれるというコツがあります。詳しくはStable Diffusionの使い方とか、いろんな方のプロンプトの作り方などを見てください。それから「1 cute cat」が「かわいい猫を1匹描いてください」ですね。
そして「--n」の後は、逆にこういう画像はイヤだというものをいろいろ書きます。最後に第3引数で画像を10枚生成するという指定をすると、下図のように猫が10枚生成されます。

手元の高火力 DOKの環境でも実行できますが、処理に時間がかかるので先に実行しておきます。高火力 DOKでは、過去のタスクからコピーして新規タスクを作成できます。それから、現在はGPUはV100のみ提供でH100は利用できないんですが、H100も提供に向けて準備中で、私の開発環境ではH100も使えるので、ここでは使ってみます。
処理としては1枚あたり20秒ぐらいで画像が生成されたりするんですが、実際にはタスクを登録してから処理するサーバにジョブが積まれて(イメージの事前の取得など)、あるいは処理が終わった後も結果のアップロードとか、いろいろな前処理・後処理がありますので、タスクを突っ込んでから20秒で結果が出てくるわけではないところにちょっと注意をしていただきたいと思います。ただ、課金されるのは事前の準備などを除いた、GPUを使っている時間だけ課金されますので、登録してもなかなか実行されない場合でもそこは課金されていないので大丈夫だと思ってください。
同じプロンプトでも初期値が違うと全然違う結果が出るので、いい画を得るには100〜200枚ぐらい生成した中から奇跡の1枚を選んでください。1枚だけ生成してもなんか微妙なものが出てくるので、ほとんどの使い方としては、まずは数枚作ってみて、プロンプトが悪くなさそうだったらたくさん生成して一番良いものを使うというような、そういう流れになるのかなと思っています。
学習 (DreamBoothによるLoRAの作成)
次に、学習をやっていきたいと思います。学習というのは、例えばもともとのモデルには当然ながら私の顔などは含まれていませんし、あるいは好きなキャラクターなども含まれていないので、自分と同じ顔や同じキャラクターを出したいとか、あとは富士山の写真を作りたいのに、プロンプトに「Fujisan」と指定してもなんかとんがった山は出てくるんだけど富士山とは似ても似つかない山が出てきたりしますので、富士山はどういう山かを学習させる必要があります。そういう場合に今回紹介するような方法を使います。
ここで、まっさらな状態からモデルを作るとなると、画像を何万枚も用意して、学習時間も何千時間もかけたり、コストもかけてということになるんですが、Stable Diffusionでは追加でちょっとだけ学習するということができます。その方法の一つが、DreamBoothというソフトウェアによって、LoRAという追加部分のモデルファイルを作成するという方法です。

その作り方にもいくつかあって、上記のスライドはsd-scriptの学習方法に関するREADMEから抜粋しまとめたもので、詳しくはリンク先を見ていただきたいんですが、今回そのうちの簡単なもの2つを紹介したいと思います。
1つがclass+identifier方式で、同じ画像、例えば私が映った写真をたくさん用意して、そのすべての画像ファイルについて、同じ単語を紐付けて学習するという簡単な方式です。写真だけ用意すればできる方法ですが、この方法は簡単な一方でデメリットがあり、画像内にある私の顔以外の背景とか着てる服とか、いろんな要素について指定することが難しいというデメリットがあります。
そこで、これをもうちょっとだけ拡張したのがキャプション方式です。こちらは画像ファイルを用意した上で、それぞれの画像ファイルについて説明文を個別に用意してあげるという方式です。これは大変なんですが、精度が上がります。
class+identifier方式

それぞれの方式について図を用いながら説明します。まずはclass+identifier方式です。
例えばこういう3枚の画像を学習させたいときに、例えばすべての画像に対して、「hinatan01」という単語はこういう特徴だということを学習させるとします。ところがこの方法では、服とか背景とかポーズとか表情とか、あるいはAIに対してこの顔の特徴を学習してくださいとは言ってないので、AIもこれがhinatan01だと言われて、タオルを持ってることかなとか、そういう要素も含まれてしまうことになります。よって、この学習結果を使って画像を生成すると、学習したときの写真に映っていた、本来生成したい物ではない物が出てくるとか、そういった精度の悪化が起きたりします。
キャプション方式

もうちょっといい方式がキャプション方式です。それぞれの画像に対して説明文を用意します。これが面倒くさいんですが、AIの学習というものは、教師データをいかに精度良く用意するかという人間の作業によって精度が上がります。
キャプションには、学習させたい単語の要素はもちろん入れておくのですが、それ以外の要素も説明します。例えば女の子1人だとか(1girl)、1人で映っているとか(solo)、髪の毛が長い(long hair)、こちらを見ている(at viewer)、笑っている(smile)、口を開けている(open mouth)、髪の毛が黒色(black hair)、制服を着ている(school uniform)、上半身(upper body)、背景がちょっとボケている(blurry background)など、いろんな特徴のうち、学習させたい単語に紐付かない情報も全部説明します。実際に全部というのは難しいんですが、感覚的にはやれるだけ全部やります。こういうことをすると、学習する時にこれらの要素を取り除いた、残りの特徴っぽいものがこの単語に紐付くことになります。よって、ただ単語を1つ紐付けるよりは精度が良くなります。これがキャプション方式です。
今回は説明しませんが、AIの中には、画像からテキストを生成するものもあります。写真の中身を説明するやつですね。これを使っていったん全部テキストに起こして編集していくという方法を取れば、ちょっと楽に作業ができるというのが裏技としてはあったりします。
追加学習 (LoRAの作成)

今回は画像とキャプションファイルを何枚か用意して、それで学習することにします。
Dockerイメージは先ほどと同じで、今度は引数にlearningと指定します。次に、学習したい画像、今回私は5枚用意しましたが、5枚の画像とキャプションはDockerイメージには含まれていないので、起動時にwgetでウェブサーバから持ってくるというシェルスクリプトにしてあって、学習したい画像とキャプションファイルをtar.gzで固めたものを適当なウェブサーバに置いて、そのURLを第2引数に入れています。第3引数はでき上がったLoRAのファイル名を指定し、第4引数にはキャプションファイルが見つからなかった場合に紐付ける単語も指定できるようにしてますので、この4つを渡します。
環境変数の方は、BATCH_SIZEはGPUのメモリとかによってパフォーマンスの適切な数値がありますのでそれを入れます。メモリが多い場合はBATCH_SIZEを大きくすると並行で実行されて処理が早くなりますが、あまり大きなサイズを指定するとメモリが足りなくなります。MAX_TRAIN_EPOCHSというのは、1つの画像に対して何回学習をかけるかを設定できます。あまりやり過ぎると同じ写真しか出てこなくなったりしますので、このあたりのパラメータは実験しながら調整してください。

今回の場合はイメージを指定して、第1引数にlearning、第2引数にtar.gzファイルが置いてあるウェブサーバのURL、第3引数と第4引数はhinatan01とします。環境変数は2つとも10に設定しました。
実行後の結果はアーティファクト以下のダウンロードリンクからダウンロードできて、tar.gzファイルが降ってきます。今回の場合はhinatan01.safetensorsというファイル名でダウンロードされるので、これができあがったLoRAファイルだと思ってください。だいたい60MBぐらいあります。
これが学習ですが、学習結果そのものを見ることはできないので、学習したらもう一度生成してみます。生成のしかたは、先ほど猫の画像を生成したときと同じです。
猫の生成画像を見てみる
先ほどタスクを実行した猫の画像生成処理も終わっているようなので結果を見てみましょう。実行が終わった後のファイルが保管されていて、あとでダウンロードできるというのが高火力 DOKの便利なポイントですね。
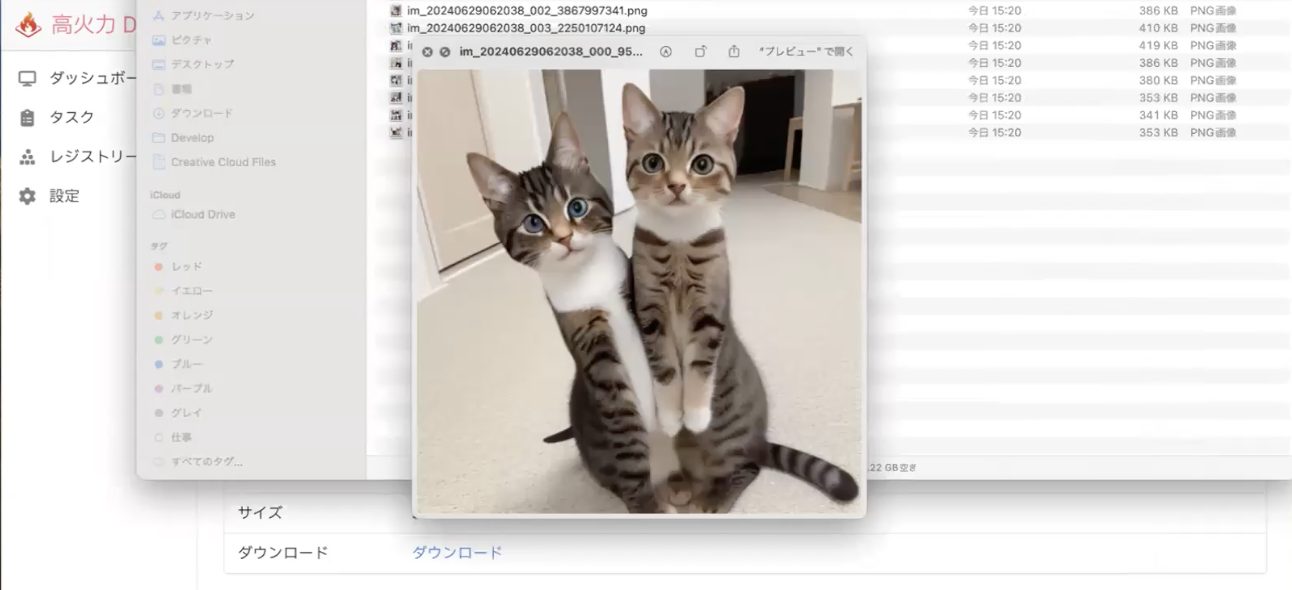
結果はこんな感じです。明らかに物理的におかしいやつとかも混ざってきます。
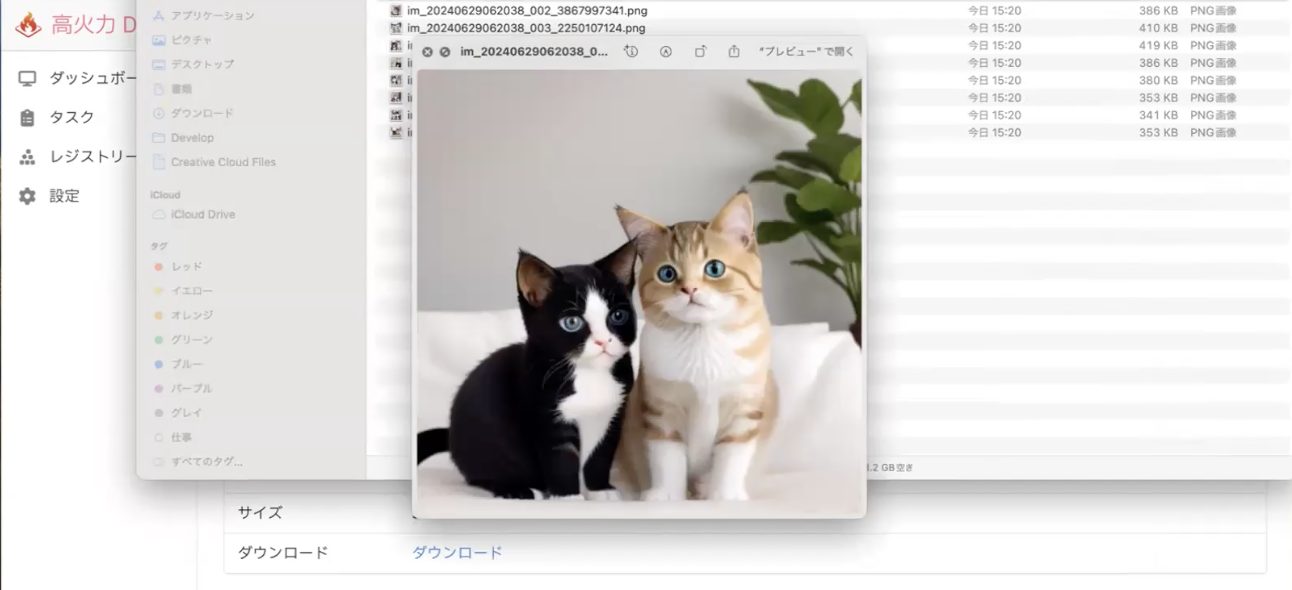
これとかいいんじゃないですかね。かわいいですね。
LoRAを使った推論 (画像生成)
LoRaを使った推論も通常の推論と概ね変わりません。

今度は先ほど作ったLoRAを使いたいので、環境変数にそのLoRAのファイルのURLを指定しておくと、それをwgetでダウンロードしてきて使うようにシェルスクリプトを作ってあります。今回実行するコマンドの特徴としては、第2引数において「<lora:hinatan01:1>hinatan01」という記述がありますが、これが「学習した単語を使ってほしい」という意味になります。loraは固定文字列、hinatan01はファイル名で、その後の数値が適用量になります。強く使いたい場合は1、半分ぐらい使ってほしい場合は0.5というように、どれぐらい強くその特徴を使うかを指定して学習時の単語を指定してあげると、先ほどLoRAを作るときに使った単語の特徴が紐付いた形で画像に反映されるということになります。

というわけで、自分の写真を使って学習させた結果をもとに生成してみたのがこれですね。なんとなく似てますよね。5枚の学習からここまでできるのは割とすごいなと感動してるんですけど、これぐらい出ます。学習にかかる時間は、V100だと10分ちょっとぐらい、H100だと2〜3分で終わります。

先ほどのプロンプトだと一人の女の子(1 beautiful woman)としか書いてないので、もうちょっと説明を追加します。例えばセーラー服を着ている(sailor suit)などと書くと、ちゃんと下図のようにセーラー服を着た状態で出てきます。

髪の毛が長いとは書いてないのですが、元の学習データが髪の毛が長かった特徴が影響していて、どれも髪の毛が長くなってますね。こんな感じで学習された特徴が利用されています。
おわりに
高火力 DOKを利用すると、決まった処理を事前にDockerイメージとして作っておけば、パラメータを変えながらいっぱい実行したり、あるいはもうそこまででき上がったら自分のサービスに組み込みたいということで、API連携でシステムに機械学習やGPUを使った機能を導入することができるというサービスとして使えます。
今回私も使ってみて便利だなと思ったのが、パラメーターを変えていっぱい画像を作ったりするときに、タスクを一個ずつ順番にやらなくてもいいんですよ。前のタスクをコピーしてパラメータを変えて実行するというのを、複数のタスクでも並行して実行することができます。とにかく積まれたタスクはできる限り全部実行され、あとで結果をダウンロードできます。いいキャプションを探そうと思ったときは、キャプションをいっぱい突っ込んで10個ぐらいタスクを並べて実行し、あとで全部ダウンロードして良かったものを選ぶとか、そういった実験にも使いやすいかなと思います。皆さんもぜひ使ってみてください。


参考資料
発表資料
発表動画
