生成AI向けパブリッククラウドサービスをつくってみた話

こんにちは。さくらのナレッジ編集部です。
7月に開催されたJANOG54 Meetingで「生成AI向けパブリッククラウドサービスをつくってみた話」について、さくらインターネット 高峯 誠さん、井上 喬視さん、平田 大祐さんが登壇しました。その内容をレポートします。

生成AI向け基盤について
時系列

生成AI向け基盤について、まずは時系列を用いて概要を説明します。2011年に、さくらインターネットは北海道石狩に自社運営の石狩データセンタを開所しました。2016年9月に初めてGPUのコンピューティングリソースを提供する「さくらの専用サーバ 高火力」シリーズのサービスを開始し、2020年7月にはさくらの専用サーバの新しいネットワーク基盤「さくらの専用サーバ PHY」というサービスも提供開始しました。さらに、2021年には2016年に提供開始したさくらの専用サーバ高火力のGPUサーバを仮想化し、さくらのクラウドに載せる「さくらクラウド 高火力プラン」の提供を始めました。
2023年6月には経済産業省から「クラウドプログラムの供給確保計画」に認定されました。クラウドプログラムとは、AI向けの電子計算機の提供と考えてください。この認定を受け、2024年1月には生成AI向けのクラウドサービス「高火力 PHY」の提供を開始しました。本プログラムでは、この高火力 PHYのサービス開発について説明します。
なぜ生成AI向け基盤にチャレンジしたのか

さくらインターネットが生成AI向け基盤にチャレンジできた理由は大きく分けて3つあります。1つ目は、石狩データセンタの存在です。大規模な自社運営のデータセンタでは、大規模なサーバやネットワークの構築が可能であり、10年以上に渡る運用経験を持つ運用人材が多数在籍していました。2つ目は、GPUサーバの運用実績があったことです。2016年からGPUインフラの構築運用サービス事業を継続して行っていました。3つ目は、既存サービスのネットワーク基盤を活用できたことです。さくらの専用サーバ PHYのネットワーク基盤にGPUサーバを活用することで、約半年間での提供開始が可能となりました。この迅速な提供開始が、さくらインターネットが生成AI向け基盤にチャレンジするきっかけとなりました。
生成AIの需要と取り組み
現在、生成AIに関するニュースは毎日のように報道されており、その注目度の高さが伺えます。国内の多くのユーザも生成AIを使ってみたいという要望を持っています。特に、早く学習を始めたい、大規模なクラスタを組みたい、GPUサーバ間で高速な通信を実現したい、最新のGPUをたくさん使いたい、高速なストレージが欲しい、そしてこれらを安価に利用したいという多様なニーズがあります。これらのユーザの声を汲み取りながら、生成AI向け基盤の事業化を進めてきました。
生成AI向けインフラ基盤の現状と全体像

現在、提供する生成AI向けインフラ基盤には、NVIDIA製のH100 GPUが2000基以上備わっています。ここで言う「基数」とは、サーバ台数ではなくGPUの枚数を指します。また、サーバ間のインターコネクトの通信速度は200Gbps×4、あるいは世代によっては400Gbps×4となっており、高速なデータ通信を実現しています。高性能な通信インフラが整備されているため、ユーザは大規模なクラスタ構築や高速なデータ処理を行うことができます。
さらに、GPUの基数が2000枚以上あることから、計算処理能力は2EFlopsを超えています。EFlops(エクサフロップス)とは計算処理能力を表す指標で、1EFlopsは1秒間に100京の計算を行う能力を指します。さくらインターネットのインフラ基盤は、2EFlopsあるので、1秒間に200京の計算を処理できる能力を持つ非常に高い性能を誇ります。
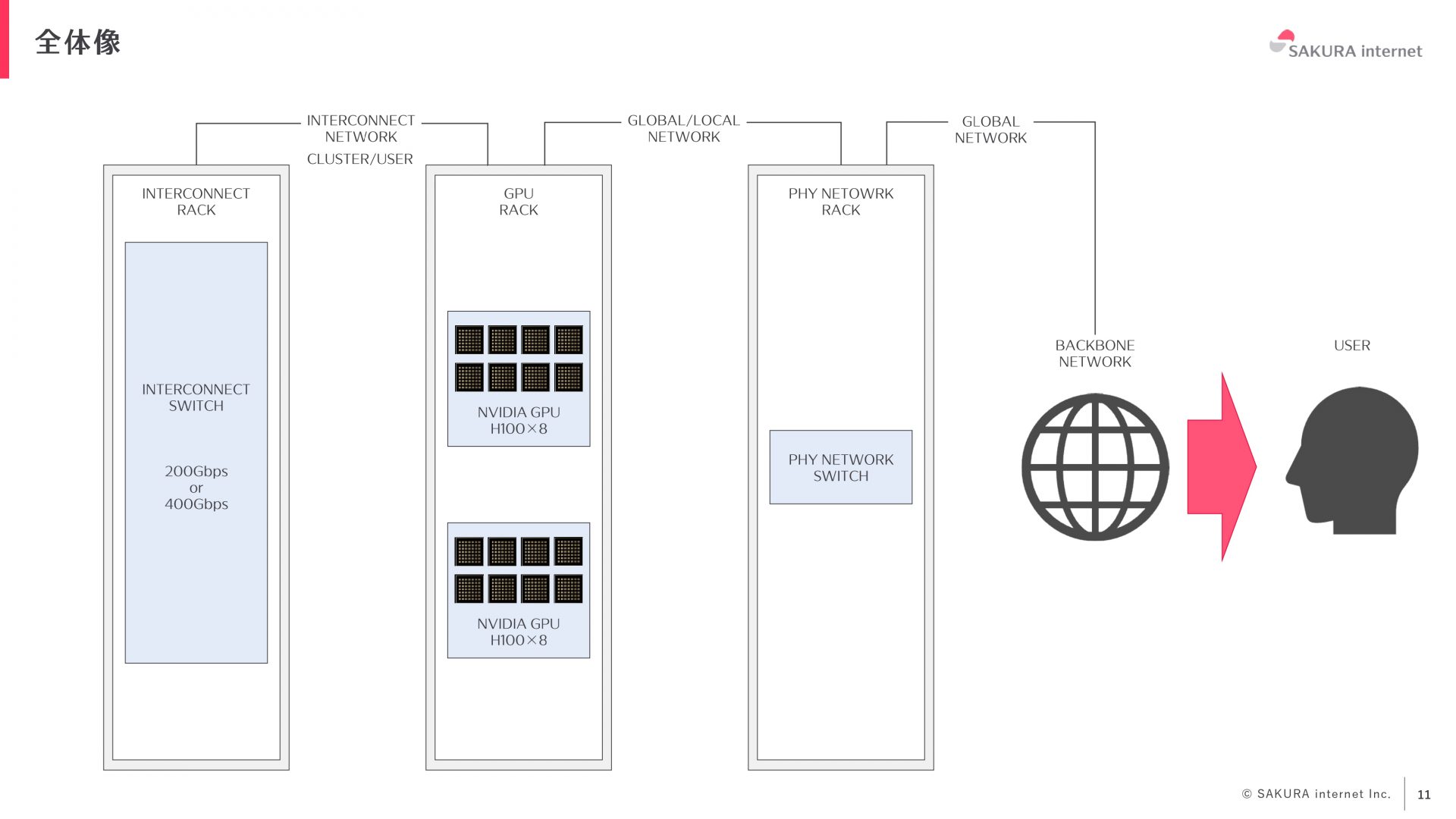
生成AI向けインフラ基盤の全体像についてです。まず、上図の左のラックにはインターコネクトのスイッチが設置されており、中央のラックの各GPUサーバと接続されています。GPUサーバを複数利用するお客様には、インターコネクト側でクラスタの設定を行い、高速なサーバ間の通信を実現しています。また、GPUと右側のラックに搭載している既存のさくらの専用サーバ PHYのスイッチと接続し、ユーザに高性能なインフラを提供しています。
GPU/データセンタファシリティ
GPUサーバの構築と設置

石狩データセンタにおいて、自前で約200台のGPUサーバを構築・設置しました。構築期間は約2週間で、毎日30人前後の社員が石狩データセンタに集結しました。データセンタ勤務者だけでは稼働が足りず、東京や大阪からも参加しましたまず何百本もの電源ケーブルを設置し、サーバをハンドリフターを使って移設する作業をしました。その後、約200台のGPUサーバを数班×数人組で構築しました。

200台を一度に納品・設置するのは難しいため、仮置きスペースを確保し数十台ずつに分けて納品しました。このスペースを利用することで、スムーズに設置作業を進めることができましたが、台数が多いため開梱だけでも半日以上必要でした。また、サーバ1台あたりの重量は100kg以上あるので、作業者の負荷軽減策として設置前にパーツを取り外す工夫をしました。

その後、4人1組でハンドリフターを用いて高さを調整しながら設置を行いました。この作業はたくさんの作業者と時間をかけて安全に行う必要がありましたが、事故なく成功させました。このようにして、約200台のGPUサーバを無事に構築・設置しました。
GPUサーバの構築時に考慮すること
GPUサーバの構築において、消費電力、冷却機能、騒音対策の3点を考慮する必要がありました。
消費電力
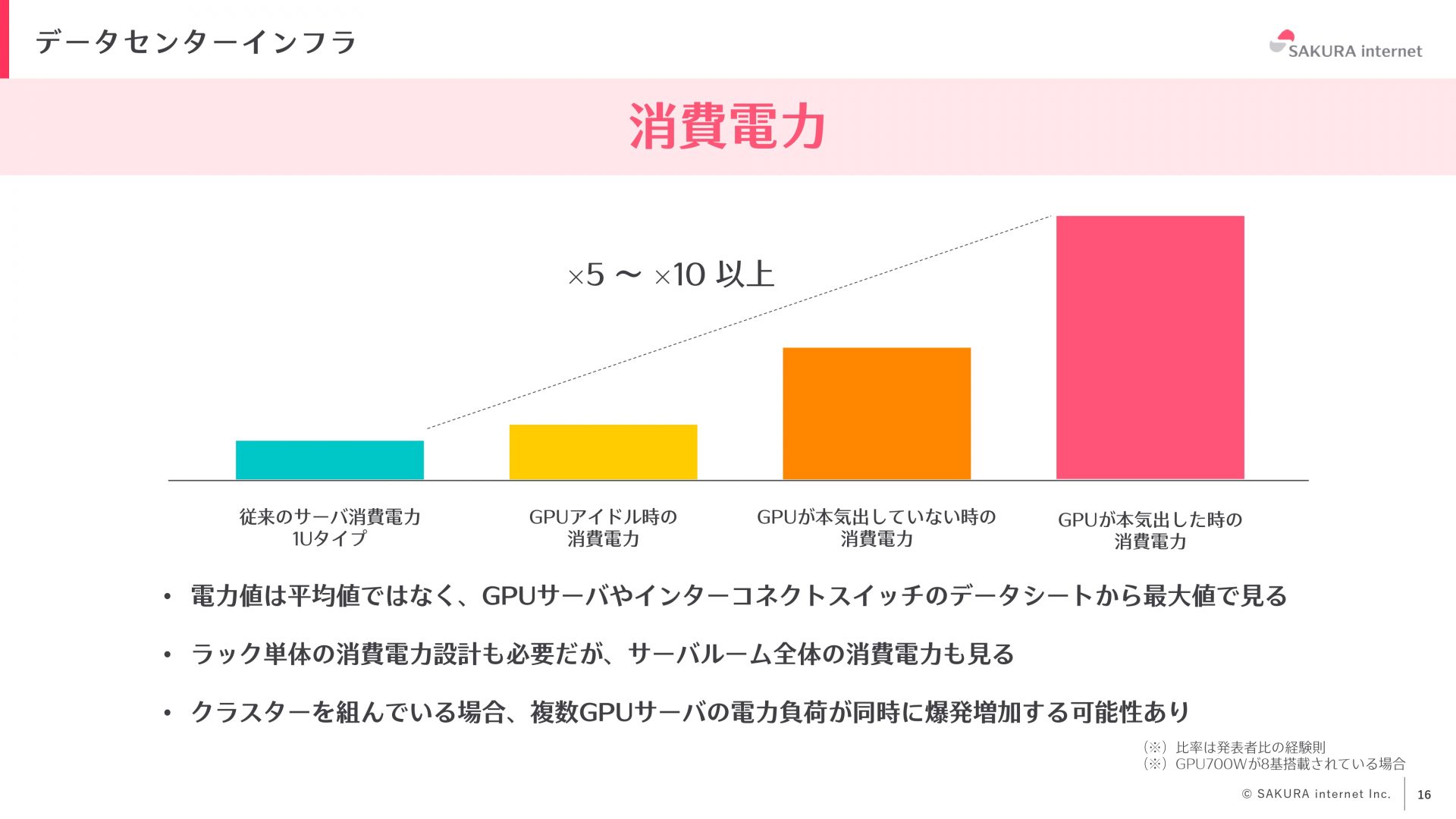
GPUサーバの消費電力は従来のサーバと比較すると、5倍から10倍、多い場合には20倍になることもあります。そのため、設計時には平均値ではなく、データシート(スペックシート)の最大値を基に消費電力を計算する必要があります。また、ラック単体の消費電力だけでなく、サーバルーム全体の消費電力量も考慮する必要があります。サーバルーム全体の消費電力量や電力供給可能量を把握し、何台のサーバを設置できるかを正確に設計することが重要です。さらに、クラスタを組んでいる場合、ユーザの使い方によっては複数のGPUサーバの電力負荷が爆発的に増加する可能性があります。そのため、最大値で設計しなければ、電力オーバーによる電源断が発生するリスクがあります。
冷却機能

2つ目は冷却機能です。消費電力に比例して排熱も多くなるため、GPUサーバでは冷却が非常に重要です。2000年代のデータセンタでは、部屋全体を冷やす空調方式が一般的でしたが、これでは1ラックごとに効率的に冷却することが困難です。そのため、アイルコンテインメントで列ごとに扉やカーテンで冷たい空気と暖かい空気を分離する空調方式が最低限必要です。しかし、そのような対策を講じても排熱量が非常に多い筐体の周囲に何も設置できない場合があります。排熱が他のサーバに影響を与え、不具合を引き起こす可能性があるためです。また、ラックに空きスペースがあり、GPUサーバを4、5台追加することが可能でも、冷却を十分に行うことができないため設置することができません。今後の対策として、水冷式の冷却システムの検討や、ラック扉に大量のファンを設置するなどの方法が必要となるでしょう。
騒音対策

3つ目は騒音対策です。GPUサーバは消費電力が非常に大きく、空調も強化する必要があるため、ファンの稼働音が非常に大きくなります。一般的なサーバルームでは70〜80デシベル程度の騒音ですが、GPUサーバがあるサーバルームでは90〜100デシベル程度の騒音が発生します。この音量は電車が通るガード下に相当し、人が会話できる環境ではありません。

厚生労働省の騒音障害防止のためのガイドラインでは、85デシベル以上の環境では耳栓やイヤーマフの着用、それらの着用を促す標識の掲示が義務付けられています。また、作業者は6ヶ月以内に1回の聴覚検査を受ける必要があります。

騒音障害予防のために耳栓やイヤーマフを装着すると、作業者同士の会話が困難になるという課題があります。最近では、Bluetooth対応のインカムを導入することで、作業者同士やリモートでの会話が可能になりました。これにより、効率的にコミュニケーションを取りながら作業を進めることができます。
導入したネットワーク
構築スケジュール
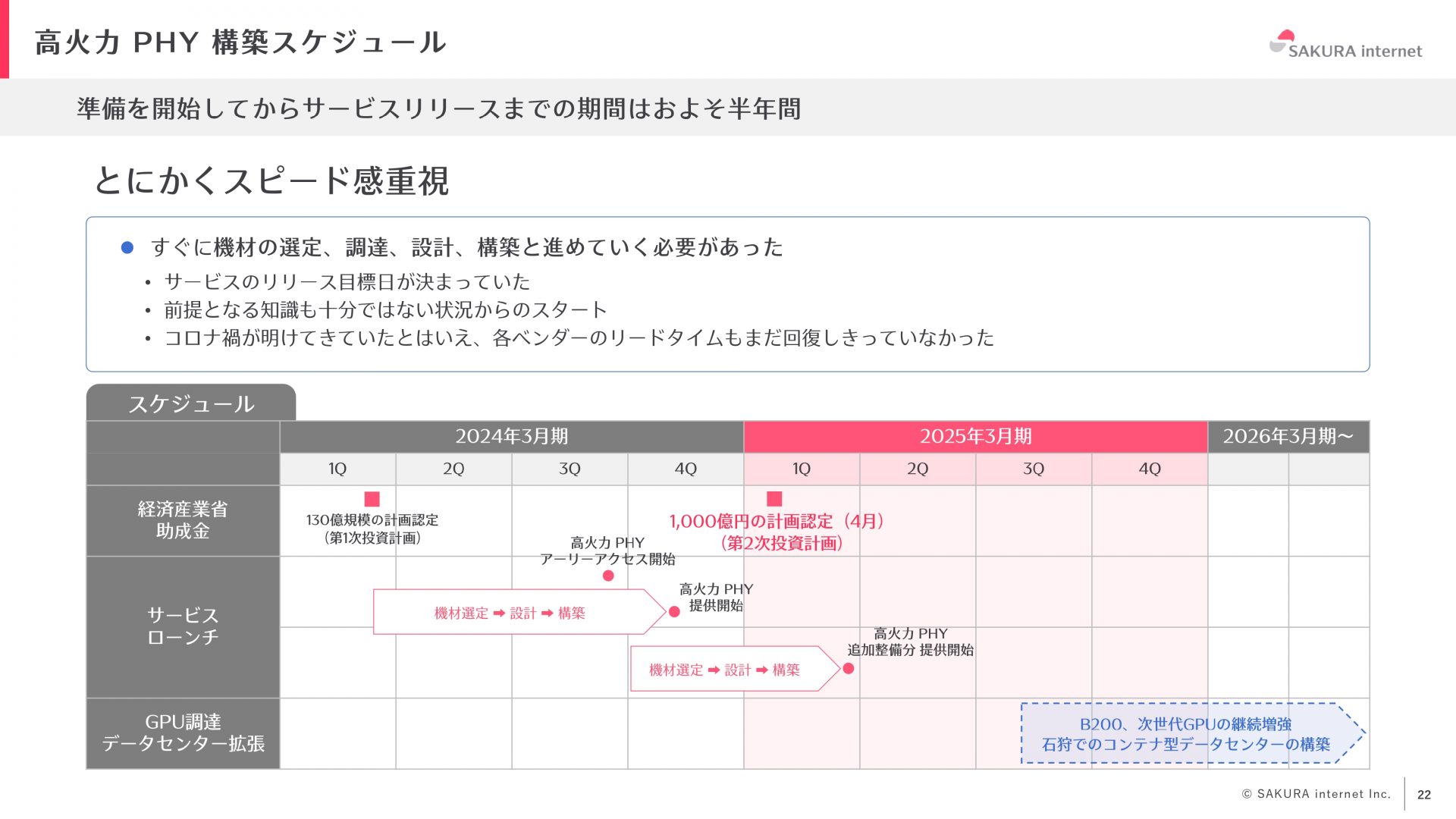
まず、今回の高火力 PHYというクラウドパブリックサービスの構築スケジュールについて詳しく説明します。準備からリリースまでは約半年と非常に短期間でした。しかし大規模なGPUクラスタの構築は初めての経験であり、十分な知識がない状態から開発をスタートしました。また、コロナ禍の影響が継続しており、各ベンダの装置のリードタイムが完全には回復していなかったため、物資の調達も難しい部分がありました。このような状態で、サービス開発に向け非常に急いで準備を進めることになりました。
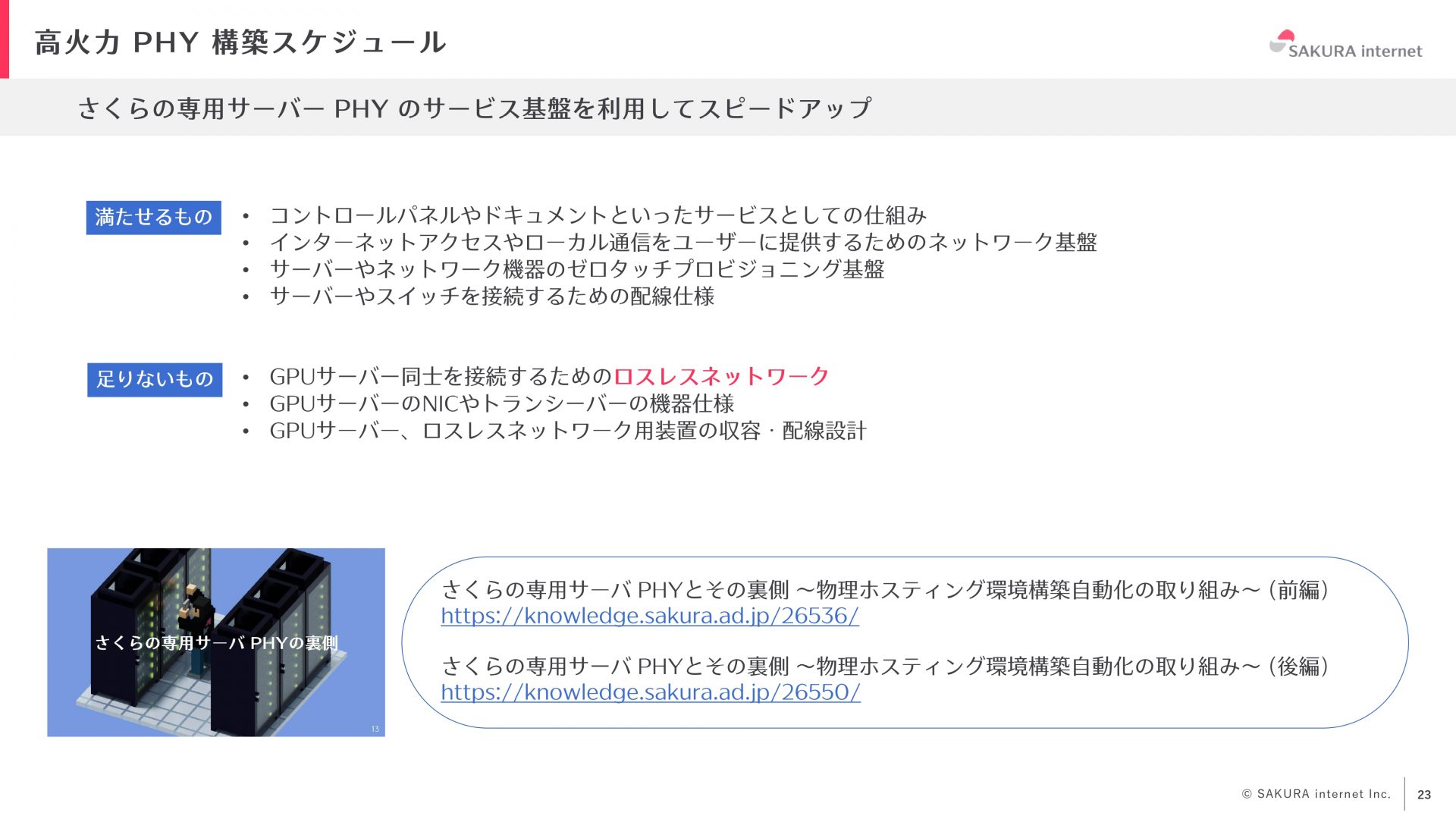
今回リリースした高火力 PHYは、さくらの専用サーバ PHYというクラウドサービスのサービス基盤を利用して構築したため、短期間で構築できました。すでに整備されていたコントロールパネルやドキュメントなどのユーザへのサービス提供の仕組みやインターネットアクセスなどのネットワーク機能、ゼロタッチプロビジョニング基盤や監視システム、配線などを流用しました(詳細は、オープンソースカンファレンスで発表した内容をご参照いただければと思います)。しかし、GPUサーバのサービスを提供するにあたって、GPUサーバ同士を繋ぐためのネットワークの検討、NICやトランシーバーの選定や収容、配線の設計を一から行う必要がありました。
ネットワーク導入と設計について
GPUクラスタのネットワークを選定する際に重視したことが3つあります。1つ目が、時間の制約です。短期間での構築が求められていたため、複雑な構成は避け、シンプルなアーキテクチャにすることを優先しました。機器の台数が増えると検証や構成に時間がかかるため、シンプルさが重要でした。2つ目は、マルチテナンシーの要件です。パブリッククラウドサービスとして提供するため、マルチテナンシーが必須でした。InfiniBandベースのファブリックではマルチテナンシーの提供が難しいため、Ethernetベースの設計を採用しました。3つ目は、公平性の確保です。パブリッククラウドサービスとして、多くのユーザに公平にサービスを提供するため、ユーザ間での公平性を確保できる基盤が必要でした。これら3つを踏まえた設計により、効率的かつ公平なサービス提供を実現するネットワークインフラを構築しました。
Arista Networks 7800R3の採用
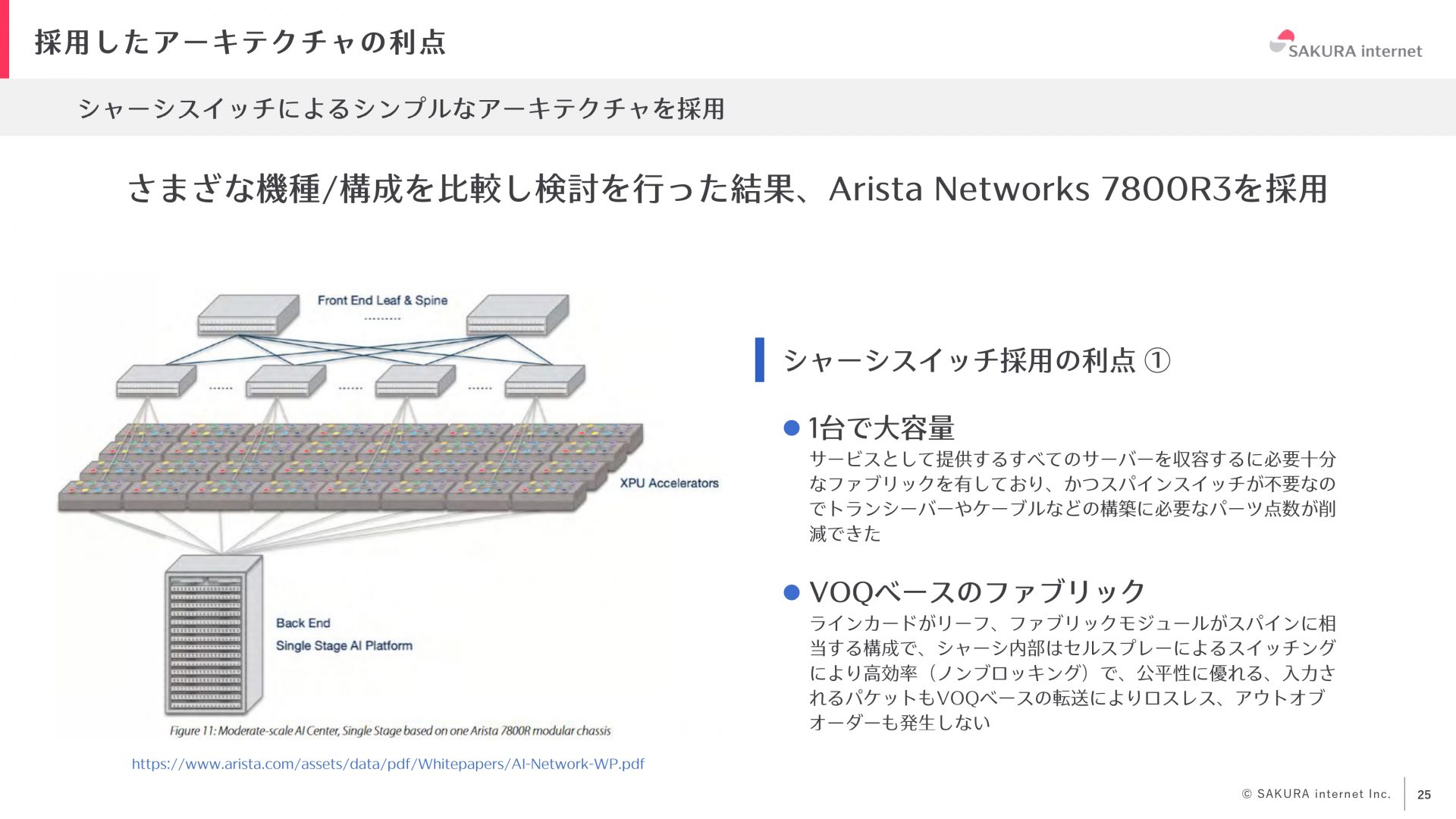
GPUサーバのネットワーク機器は複数のベンダを比較し、Arista Networksの7800R3に複数台のGPUサーバをまとめて接続する構成構成を採用しました。このシャーシスイッチを導入する決め手となった特徴と導入のメリットについて説明します。
7800R3は1台で非常に大容量のファブリックを持つスイッチです。これにより、複数台のスイッチを必要とせず、1台で全てのGPUサーバを収容できます。通常であると、ClosアーキテクチャでLeaf Spine構成を取ることが一般的ですが、どうしても機器の台数が増える構成になってしまいます。このスイッチを導入することで、1台のスイッチのみのシンプルな構成となるので運用が非常に楽になり、運用負担も大幅に削減できます。また、シャーシスイッチの特徴として、VOQベースのファブリックを有しており、シャーシ内はセルスプレーによるスイッチングで、基本的にノンブロッキングなため、公平性も担保されます。VOQベースの転送によりロスレスで、パケットがスイッチから出て行く際もアウトオブオーダも発生しません。
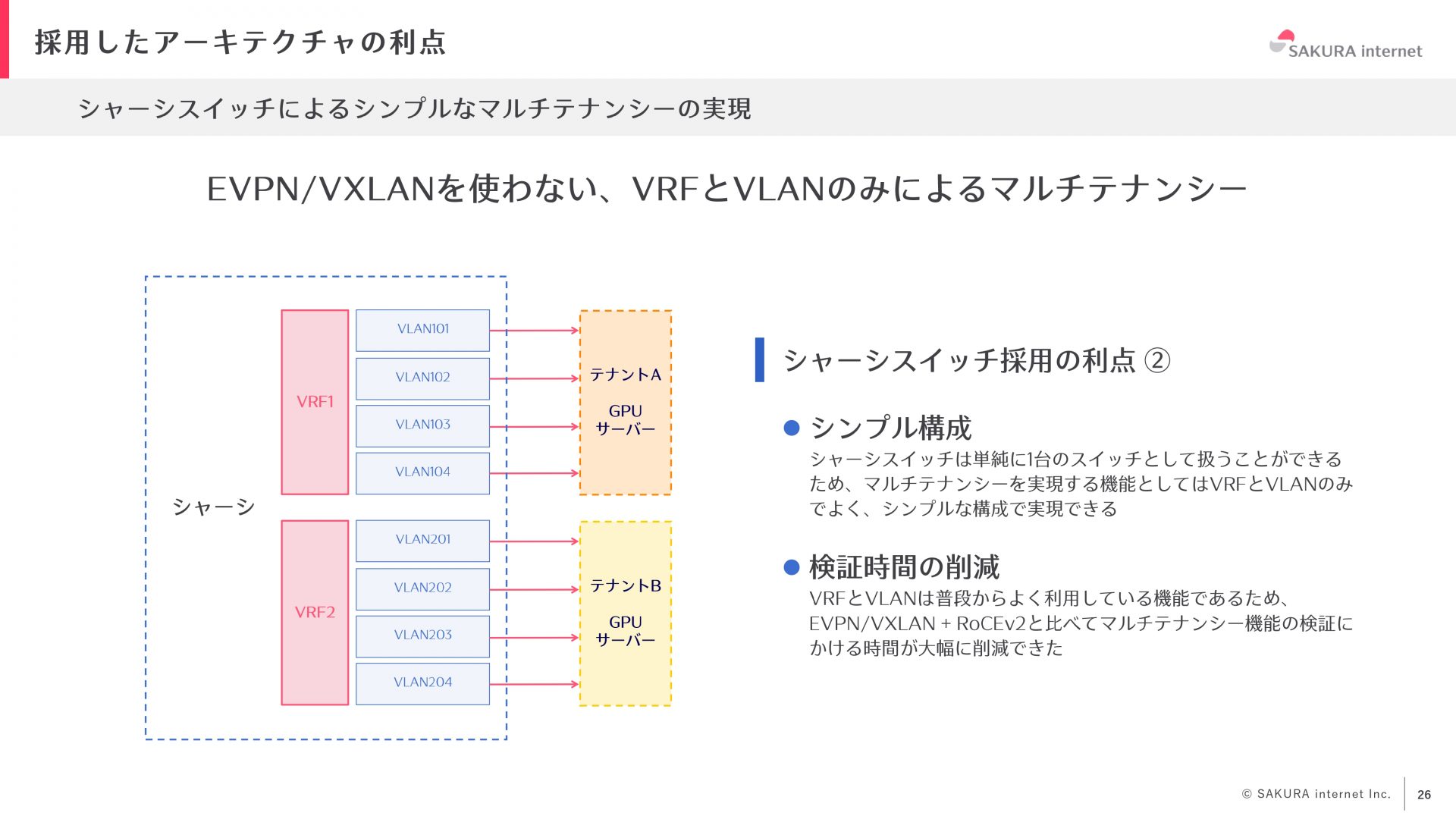
シャーシスイッチは1台のスイッチとして扱うことができるため、マルチテナンシーを実現する機能としてVRFとVLANのみでよく、シンプルな構成を実現できます。EVPNやVXLANを使用し、クロスアーキテクチャでマルチテナンシーを実現することが一般的ですが、今回のスイッチを採用したことで使い慣れたVRFとVLANを使えるので、検証にかかる時間が大幅に削減され、コンフィグも非常にシンプルになりました。
搬入と設置

ここからは、実際に設営の様子や搬入の課題についてご紹介します。搬入日の前日に積雪し、トラックがデータセンタ敷地内に入れない可能性がありました。そこで、除雪作業を行い、搬入経路を確保しました。

シャーシスイッチは自分たちでラックに設置しようと考えていましたが、筐体が大きすぎて困難なことが判明しました。シャーシスイッチの設置にはベンダ推奨のサーバリフターのようなツールが必要でしたが、国内では調達できず、自力でラックに搭載することは不可能でした。そこで、専門業者に依頼し設置作業を行いました。

搬入の手順としては、まずシャーシスイッチの上部に玉掛けワイヤをかける部分を取り付け、フックをかけて、フォークリフトで吊り上げてから台車に乗せて運搬しました。

導入したシャーシスイッチは32Uあり、ファブリックモジュール、ラインカード、電源モジュールを抜去した状態でも約200kgあり、ラック搭載は非常に大変な作業でした。ラックへの設置時には、クレードルという専用の土台を据え付けてからシャーシスイッチをラック前面まで移動させ、90度回転させ、ラックにスライドして押し込む形で設置しました。

注意点として、1度ラックにシャーシスイッチを搭載すると大型で重量もあることから簡単に取り外しをすることができません。ラックには側面に傷がつかないようにシートが貼られていましたが、それを剥がさずにラックにシャーシスイッチを設置してしまい、剥がすことが大変でした。また、ラックに据え付けた後、ケージナットで固定する際、ネジが落下することがありました。拾って取り付けようにも手が入らず拾えなかったので、現在もそのままの状態になっています。もちろん他にもたくさんのナットがあるので、シャーシスイッチが動くことはありません。大型機械を設置する際は、こうした点に注意する必要があります。
配線設計

次に、シャーシスイッチの配線についてです。サーバ列3列とスイッチ列1列の構成で、コールドアイルとホットアイルが交互に配置されています。ラック列は2列で1アイルの構成です。アイルや列を跨いでの配線が必要になっていました。スイッチを置く場所から最も遠いサーバ設置列までは約40~50mの配線経路となり、AOCやDACを利用できませんでした。

そこで、パッチパネルを設置してシャーシスイッチに配線する方法を採用しました。しかし、シャーシスイッチが大型であるため、1つのラックにパッチパネルとスイッチを搭載させるのは難しく、隣のラックをパッチパネル専用とし、横に流してシャーシスイッチに配線する方式を取ることにしました。また、設置場所の都合で、使用するラックは600ミリの幅しかなく、非常に狭いため、配線が非常に難しかったです。
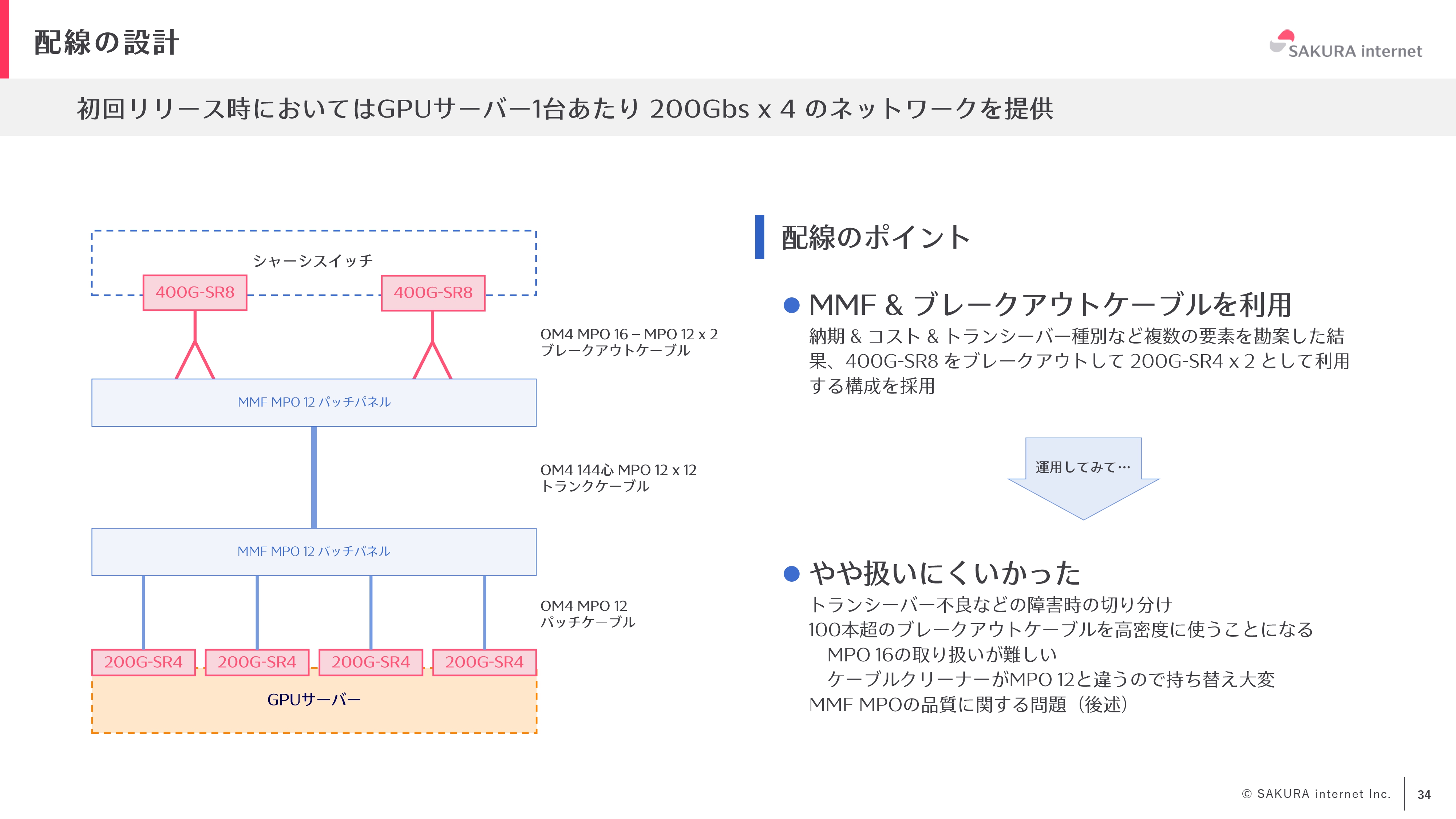
初回のリリースにおいては、GPUサーバ1台あたり200Gbs×4のネットワーク構成を提供しました。具体的には、ブレークアウトケーブルを利用して400G-SR8をブレイクアウトして200G-SR4 2本に分岐する構成を採用しています。これまでもブレークアウトケーブルは使用したことがありましたが、やはり障害切り分けの難しさ、高密度になったときのメンテナンスの難しさなどの問題があると感じています。また、400G-SR8はMPO-16規格で、MPO-12とは規格が異なるため、ケーブルクリーナー使用時に注意が必要でした。
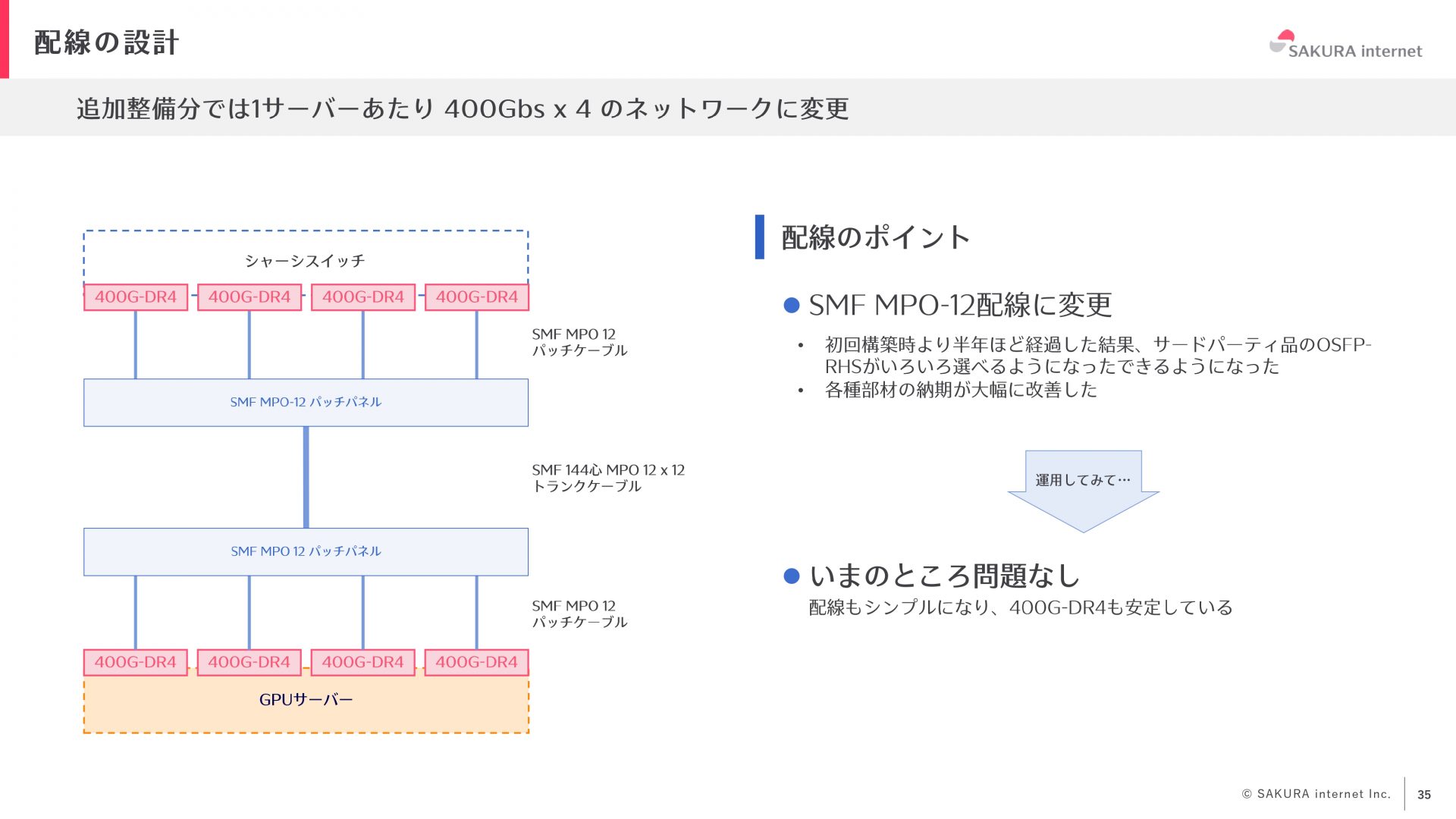
追加整備分は、部材の準備が容易になったことや納期が大幅に改善されたことから、400Gbps×4のネットワークに変更しました。400G-DR4は、ブレイクアウトケーブルではなく、SMF MPO-12ケーブルを使うことができるので、よりシンプルな構成を実現できました。

400G構成に変更することで、配線本数が大幅に増加しました。追加整備分では、シャーシスイッチの両隣をパッチパネルのラックにし、両側から中央のスイッチに配線するという構成を取りました。
トランシーバーの選定と課題

トランシーバーは、スイッチ側はベンダ純正品、NIC側はサードパーティ製のトランシーバーを全面的に採用しました。
初回リリース分には、200G-SR4のQSFP56のトランシーバーを使用しました。複数のベンダ製品を比較した結果、BERの結果にばらつきがあったので、BERの結果が良いものを採用しました。また、200G-SR4のトランシーバーは、PC研磨MPOケーブル対応品と、APC研磨MPOケーブル対応品の2種類がありました。研磨方式が異なるケーブルの接続は通信不良となりますし、ラベルに記載がなければトランシーバーがどちらの対応品か外観からは判別が難しく注意が必要だと感じました。
追加整備分では、400G-DR4をNICで利用することからOSFP-RHS(flat-top)という冷却フィンのないものを採用しました。複数のベンダ製品を比較し、性能差分があまりなかったので、価格や納期を考慮して製品を選定しました。400G-DR4については、ベンダに協力してもらいベンダネームに「SAKURA」を入れてもらい特別感を出しています。
配線ケーブルの選択

トランシーバーの選定において、MMFとSMFのどちらを使用するかは非常に悩ましい問題です。MMFの方がトランシーバーも含めて安価になる傾向がありますが、MPOケーブルの研磨方式や品質などの問題が発生しやすいです。安定運用を目指すならば、SMFの方が良いかもしれませんが、トランシーバーの規格や製品化の状況によってはSMFを使えない場合もあるので、今後も悩むことになりそうです。
また、光配線はサーバラックからシャーシスイッチまでパッチパネルを介して配線をしました。MPO-16ケーブルのパッチパネルへの敷設は当初一般的ではなく、利用できるトランシーバーも限られていたので、難しく感じました。800Gの規格の動向を見ると、今後もMPO-16ケーブルを考慮しなければならない場面が増えると予想されます。MMFで配線する場合、Low-Lossタイプのコネクタを採用することで、後々の問題を回避できると考えています。パッチパネルもLow-Lossタイプを採用し、ケーブル品質に気を配ることが重要です。
そして、トランシーバーにはたくさんの規格ありますが、400Gであれば、商品数も豊富な400G-DR4が無難だと考えています。MPOケーブルは扱いづらい部分があるので、LC2芯ケーブルである400G-FR4を使っていきたいという思いもあります。各ベンダからOSFP-RHSモデルも今後リリースされそうな雰囲気があり、LPO対応のトランシーバーも増えてきていたり、800Gの動向も気になるところであるので、商品の選定に今後悩むことが増えそうです。フォームファクタについても、ConnectX-8がどうなるかわからない部分があり、トランシーバーに関する悩みは今後もつきそうにありません。
トラブルシューティング
今回、ネットワーク構築と運用において遭遇したトラブルを3つ紹介します。
トランシーバーの不具合
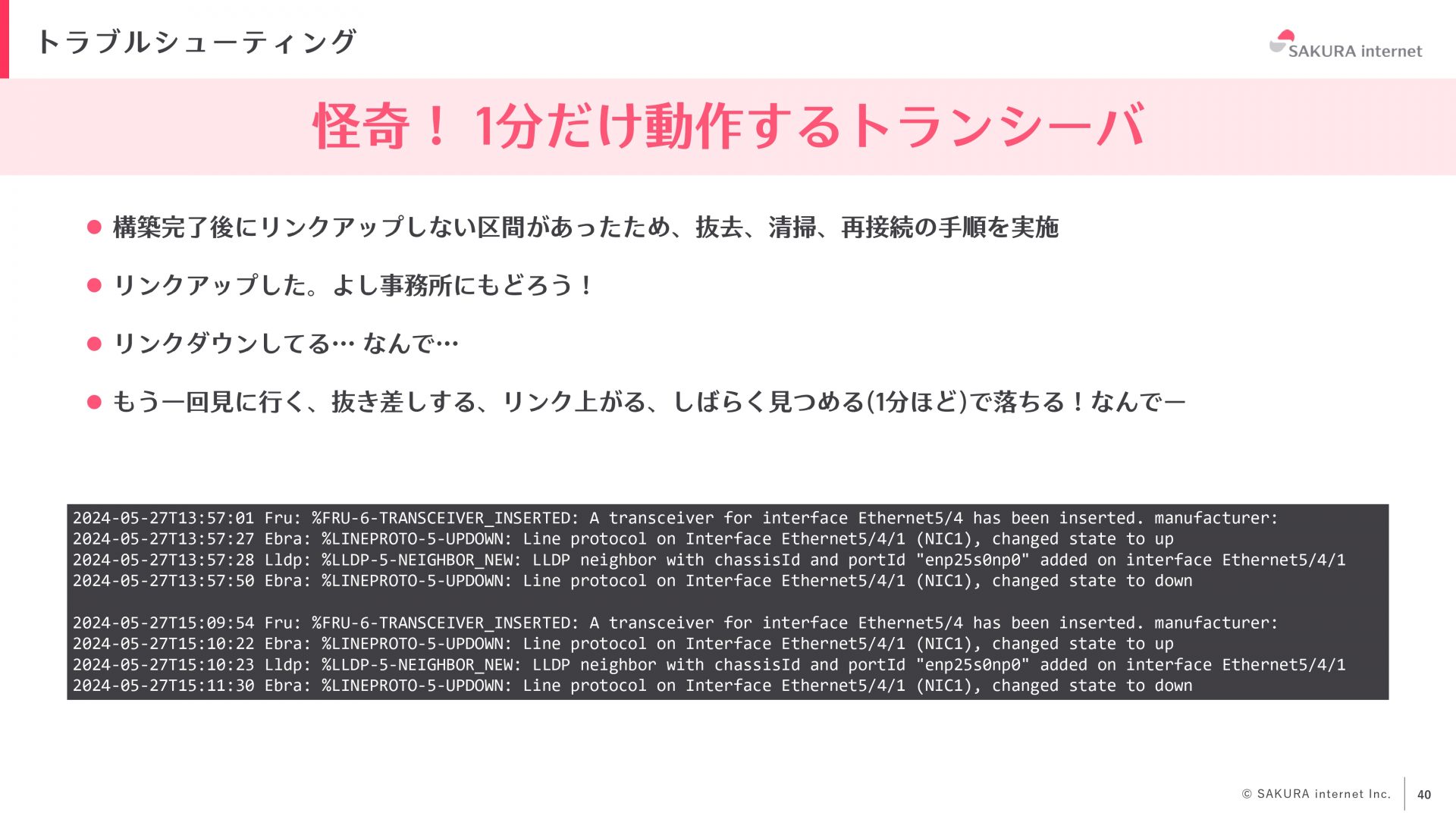
まず1つ目は「一部だけ動作するトランシーバー」についてです。夏の怪談話には少し早いかもしれませんが、これは実際に我々が直面した問題です。ネットワーク構築を完了し、サーバの電源を入れてリンクアップを確認している際に、一部の区間でリンクアップしないという問題が発生しました。通常、このような場合にはトランシーバーとMPOコネクタを一度抜去し清掃後に再接続する運用を実施します。今回もこの手順を踏み、無事リンクアップしました。しかし、リンクアップした状態で少し経つと、リンクダウンしてしまいます。再度コネクタを抜去し清掃して再接続するとまたリンクアップするのですが、30〜40秒ほど正常にリンクアップし、1分ほど経過するとリンクダウンしてしまうのです。
運用者としては、完全に壊れて全くリンクアップしない方が対処しやすく、見た目には正常に見えるが実際には不具合があるという状況は非常に厄介です。ルーターやスイッチでも同様の問題があるかもしれませんが、中途半端に動作せず、完全に壊れて欲しいと感じました。
トランシーバーの破損

2つ目は、構築作業中にトランシーバーが破損しました。トランシーバー挿入後に清掃し配線をするという運用ルールのもとに、MPOのトランシーバー側のクリーニング作業を行っていました。シャーシスイッチの1ラインカード当たり36ポートあり、清掃作業で連続して500回以上必要となることもありました。この配線作業後、配線誤りがあったことが判明し、やり直しが必要になりました。これにより、クリーナーの使用回数が想定より大幅に増え、最終的には4桁の清掃回数に達することとなりました。

そのような状況で、クリーナーをトランシーバーに挿入して清掃を行っていたところ、突然黒い破片が落ちてきました。調べてみると、クリーナーがMPOのツメに当たってしまい破損していたのです。

この事態を受けて、全シャーシスイッチのトランシーバーを再確認し、他に破損がないことが確認できました。再発防止策としては、クリーナーを挿入する際には垂直を意識し、力加減に注意することを徹底することしか思いつきませんでした。しかし、手作業ゆえに完全に防ぐのは難しいと感じています。破損を防ぐための物理的な仕組みがあれば、多くの人が安心して作業できるのではないかと考えています。
通信エラーレートの高いMPOケーブル

最後のトラブル事例は、MPOケーブルの品質問題です。今回の構築では、MMF MPO-12と200G-SR4を用いてネットワークを構築していますが、構築完了後に一部の区間でビットエラーレートが高くなり、場合によってはリンクフラップが発生する問題がありました。まず、問題の発生しているMPOケーブルを抜去し、端面検査機で検査を実施したところNG判定が出ました。

上図の例では、7番と8番のコネクタにNGが出ており、MPOケーブルが使用不可と表示されていました。

ケーブルやトランシーバーを交換しても、このNG判定の原因が判明しませんでした。その後、コアディップという事象が発生してることが判明しました。これは、MPOコネクタの製造過程でコネクタの研磨を行う際に、コア部分が凹んでしまい空洞ができることを指します。この空洞が原因で反射率が変わり、信号品質に影響を与えていました。端面検査機でも、通常白いコア部分に若干の黒く凹んでいる部分を確認できました。

この問題を解決するために、NTT AT社様の協力を得て、購入した3社のMPOケーブルの品質を調査しました。その結果、以下のような判定が出ました。
上段のメーカー:コアディップが大きく、通信品質の低下の原因と推測。
中段のメーカー:ばらつきが小さく、良品と判定。
下段のメーカー:コアディップなしで最上位の品質と判定。
このように、同じMPOケーブルでもメーカーによって品質にばらつきがあることが分かりました。200Gやそれ以上の速度で運用する際には、ケーブルも事前にいくつかピックアップして検証する必要があることを痛感しました。
今後
さくらインターネットは、今後も生成AI基盤を構築運用し続けていきます。

さらなるGPUの確保を進め、2024年7月現在で2EFlopsあるGPU基盤を2027年には約9倍の18.9EFlopsにする計画を立てています。

また、数を増やすだけでなく、インフラ基盤の高度化を進めていきます。高度化に向けたチャレンジとして、高火力 PHYはベアメタルタイプを1月から提供していますが、コンテナサービスの実装を進めています。高火力 DOKというDockerコンテナの実行に特化したサービスを6月27日にリリースしました。2つ目は、インターコネクトのさらなる広帯域化に向け、200G、400Gだけでなく800Gの情報についても注視していきたいと考えています。3つ目は、GPUの現行モデルであるH100を確保していますが、次世代モデルB200も調達していきたいと考えています。そして、現在は石狩データセンタの既存フロアを生成AI基盤向けに利用していますが、今後は生成AI基盤に特化したコンテナ型データセンタを作っていこうと考えています。そこでは、水冷システムなどのデータセンタファシリティについてもチャレンジしていこうと考えています。
まとめ
JANOG54 meetingで発表した内容をご紹介しました。JANOGのYoutubeチャンネルでは期間限定で登壇内容の配信も行なっています。ぜひご覧ください。また、データセンタ作業に最適なインカムの情報がありましたら、ぜひご紹介ください。