【生成AIに触れてみよう】 高火力 DOKことはじめ #2 ~SDXL(Stable Diffusion XL)による画像の生成~

目次
はじめに
こんにちは、にしだゆうきです。
前回の記事では、生成AIの開発が進んでいることから今後の生成AIアプリを稼働させるためにさくらから『高火力 DOK』というサービスをリリースしたこと、そしてそれを利用するための準備段階としてDockerイメージを作成するためのサーバー環境をどのように構築するのかを解説しました。それに続く本記事では、用意した環境を元に高火力 DOK上でStable Diffusion XLが動作するDockerイメージを作成し、画像生成を行うまでの方法を解説します。
Stable Diffusion XL(以下、SDXL)とは、Stability AI社が開発しオープンソースとして提供している画像生成AIの最新モデルとなります。従来のStable Diffusionよりも精度が高い画像が生成できるとされる一方で、要求されるGPUスペックが大きくなるため、新たに機材を購入してPCを組み上げるとまではいかない方は高火力 DOKを活用してその利用感を体感することができます。また、生成AIアプリとして提供するようなケースでも都度利用の形でGPUを利用することができるため、スモールスタートやコスト試算がしやすいメリットがあります。
高火力 DOKは画像生成AI以外のAIモデルを実行することもできますが、本記事ではわかりやすい例として画像生成を題材に紹介します。
前提情報
対象読者
- カスタマイズされたAIモデルを含むサービスの作り方を理解したい人
- その前段階としてDockerおよび高火力 DOKの使い方にも触れておきたい人
注意点
- サーバーおよびディスクの維持、高火力 DOKでのタスク実行には費用がかかります
- さくらのクラウドの場合、使用するサーバーおよびディスクについては費用が発生します
- サーバーのみ、停止により課金を停止することができます
- 高火力 DOKは、選択したプランの単価 × 実際にDockerイメージが動作した時間 が課金額となります
- 後述の「高火力 DOK無料お試しキャンペーン」で入手できるクラウドクーポンを使用することで、さくらのクラウドおよび高火力 DOKを合わせて最大3ヶ月/20,000円分の費用を抑えることができます。
- サーバーのセキュリティ対策については言及の対象外となります
- イメージの作成時のみ起動し、それ以外は停止しておくことを強く推奨します
- NVIDIAのエンドユーザーライセンス契約(EULA)、および各モデルで定義されるCreativeML Open RAIL++-MライセンスおよびFair AI Public License 1.0-SDライセンスにあらかじめ同意されているものとします
- 本記事で紹介する内容はNVIDIA公式のイメージや公開されているモデルを利用して画像を生成するため、試していただく皆様は事前に確認ください
PC環境
本記事での解説環境は以下のとおりです。ターミナルソフトウェアは事前にインストールしておいてください。ターミナルソフトウェアからサーバーにログインした後の操作はMacなどでも同様です。
- OS:Windows 11 Enterprise / Ver. 23H2 / OSビルド 22631.3737
- ターミナルソフトウェア:Teraterm Ver. 5.2
- Dockerイメージ作成サーバーでのエディターツール:Vim
記事の説明範囲
まず、前回の記事で作成したDockerイメージ作成用サーバーを使って高火力 DOKで動作させるDockerイメージを作成し、コンテナレジストリに保存します。
その後、高火力 DOKで作成したDockerイメージに実行してもらいたい内容を含めて『タスク』として作成することで順次実行され、結果が保存されます。
最後にオプションとしてAWS S3互換で利用可能な『さくらのオブジェクトストレージ』に作成した画像を格納します。
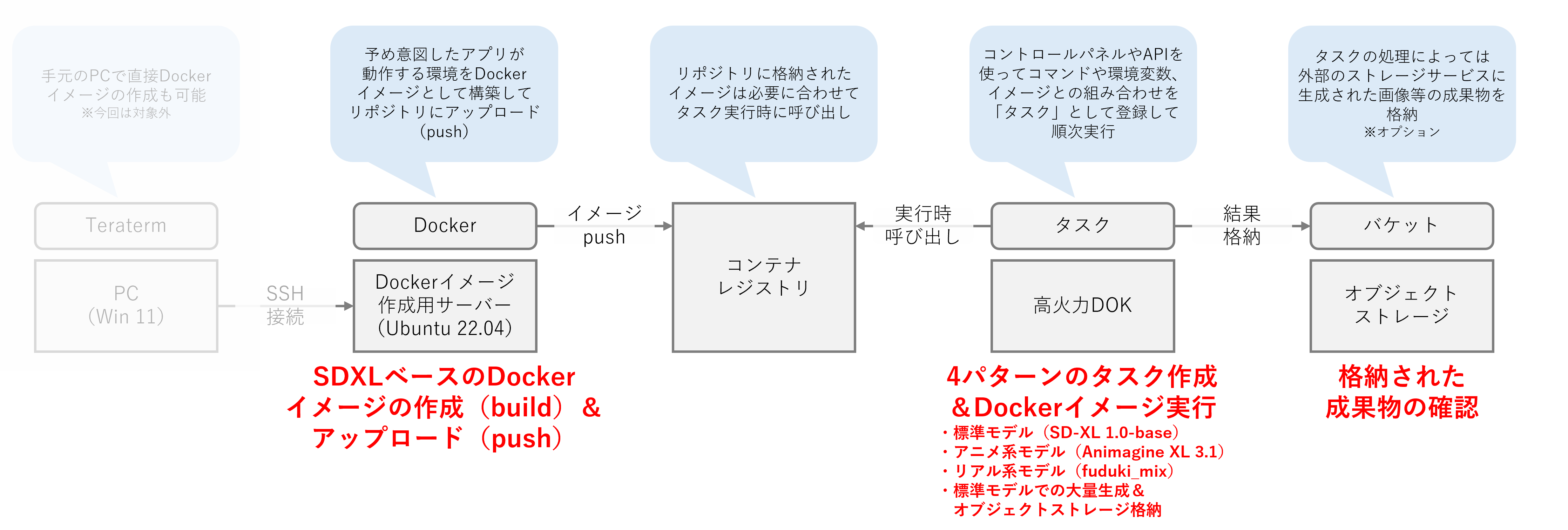
Dockerイメージの作成
今回は、SDXL 1.0をベースとして、以下3つの生成モデルを選択できるようなコンテナイメージを作成します。標準モデル以外の2モデルはその都度、外部からダウンロードする形を取るため、標準モデルよりもコンテナの実行時間が長くなる点に注意してください。
- 標準モデル(SD-XL 1.0-base)
- アニメ系モデル(Animagine XL 3.1)
- リアル系モデル(fuduki_mix)
必要なファイルの作成
ターミナルソフトウェアからDockerイメージ作成サーバーにログインし、Dockerイメージを作成するために必要なファイル(Dockerfile、runner.py、docker-entrypoint.sh)に、fuduki_mixを使えるようにするための追加ファイル(docker-entrypoint-fuduki.sh)を加えた4つのファイルをエディターツールを使って作成します。まずは上記のファイルについて簡単に説明します。
- Dokerfile:Dockerイメージの構築手順書。大元となるイメージはファイル冒頭に記載される「nvidia/cuda:12.5.1-runtime-ubuntu22.04」が使用され、末尾にはデフォルトで実行されるエントリーポイントが記述される
- docker-entrypont.sh:エントリーポイントと呼ばれるシェルスクリプト。Dockerイメージ上で実行される内容が記述される
- runner.py:エントリーポイント内で実行されるPythonプログラム。今回の主な実行内容はこちらに記述される
4つのファイルに記述するコードを以下に示します。なお、コードの中に、高火力 DOKで定義されている以下の環境変数が出てきます。これらの環境変数はコンテナー内で明示的に指定することなく使用できます。
| 環境変数 | 値 | 内容 |
|---|---|---|
| SAKURA_TASK_ID | ランダム | 出力ファイル名の先頭部分にユニークな値として指定される (例: be7fdd79-b5e6-4654-a08b-d4143c5d0351) |
| SAKURA_ARTIFACT_DIR | /opt/artifact | 対象フォルダに書き込まれたファイルはアーティファクトとして一時領域に保存される |
Dockerfile
エディターツールを開きます。
vim Dockerfile以下の内容を記述し、保存します。
FROM nvidia/cuda:12.5.1-runtime-ubuntu22.04
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update && \
apt-get install -y \
git \
git-lfs \
libgl1 \
libglib2.0-0 \
python3 \
python3-pip \
&& \
git lfs install --skip-smudge && \
pip install diffusers --upgrade && \
pip install \
accelerate \
boto3 \
invisible_watermark \
safetensors \
transformers \
&& \
pip cache purge && \
mkdir /stable-diffusion /opt/artifact && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
WORKDIR /stable-diffusion
RUN env GIT_LFS_SKIP_SMUDGE=1 git clone --depth=1 --progress \
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0 \
/stable-diffusion/stable-diffusion-xl-base-1.0 \
&& \
cd stable-diffusion-xl-base-1.0 && \
git lfs pull -I /text_encoder/model.fp16.safetensors && \
git lfs pull -I /text_encoder_2/model.fp16.safetensors && \
git lfs pull -I /unet/diffusion_pytorch_model.fp16.safetensors && \
git lfs pull -I /vae/diffusion_pytorch_model.fp16.safetensors && \
rm -rf .git
COPY runner.py /stable-diffusion/
COPY docker-entrypoint*.sh /
RUN chmod +x /docker-entrypoint*.sh /
WORKDIR /
CMD ["/bin/bash", "/docker-entrypoint.sh"]runner.py
エディターツールを開きます。
vim runner.py以下の内容を記述し、保存します。
from diffusers import DiffusionPipeline, StableDiffusionXLPipeline
import argparse
import boto3
import glob
import os
import random
import torch
arg_parser = argparse.ArgumentParser()
arg_parser.add_argument(
'--model',
default='./stable-diffusion-xl-base-1.0',
help='生成に使用するモデルを指定します。',
)
arg_parser.add_argument(
'--variant',
default='fp16',
help='モデルファイルのバリアントを指定します。 none, fp16, ...',
)
arg_parser.add_argument('--batch', type=int, default=1, help='生成回数を指定します。')
arg_parser.add_argument('--num', type=int, default=1, help='生成枚数を指定します。')
arg_parser.add_argument(
'--output',
default='/opt/artifact',
help='出力先ディレクトリを指定します。',
)
arg_parser.add_argument(
'--prefix',
default='sdxl-',
help='出力ファイルのプレフィックスを指定します。',
)
arg_parser.add_argument(
'--prompt',
default='An astronaut riding a green horse',
help='プロンプトを指定します。',
)
arg_parser.add_argument(
'--negative',
default='',
help='ネガティブプロンプトを指定します。',
)
arg_parser.add_argument(
'--seed',
type=int,
default=-1,
help='乱数シードを指定します。ある値で固定すると同様の構図のイラストが出力されやすくなります。',
)
arg_parser.add_argument(
'--steps',
type=int,
default=20,
help='サンプリングステップ数を指定します。',
)
arg_parser.add_argument(
'--width',
type=int,
default=1024,
help='出力画像の幅を指定します。',
)
arg_parser.add_argument(
'--height',
type=int,
default=1024,
help='出力画像の高さを指定します。',
)
arg_parser.add_argument('--s3-bucket', help='S3のバケットを指定します。')
arg_parser.add_argument('--s3-endpoint', help='S3互換エンドポイントのURLを指定します。')
arg_parser.add_argument('--s3-secret', help='S3のシークレットアクセスキーを指定します。')
arg_parser.add_argument('--s3-token', help='S3のアクセスキーIDを指定します。')
args = arg_parser.parse_args()
seed = int(args.seed) if int(args.seed) >= 0 else random.randint(
1,
0x7fffffffffffffff - int(args.num) * int(args.batch),
)
random.seed(seed)
if args.variant != 'single':
pipe = DiffusionPipeline.from_pretrained(
args.model if args.model else './stable-diffusion-xl-base-1.0',
torch_dtype=torch.float16,
use_safetensors=True,
variant=args.variant if args.variant != 'none' else None,
)
else:
pipe = StableDiffusionXLPipeline.from_single_file(
args.model,
torch_dtype=torch.float16
)
pipe.to('cuda')
for batch_iteration in range(int(args.batch)):
print('Seed is {0}'.format(seed))
images = pipe(
prompt=args.prompt,
negative_prompt=args.negative,
generator=torch.Generator('cuda').manual_seed(seed),
guidance_scale=7.5,
height=int(args.height),
num_images_per_prompt=int(args.num),
num_inference_steps=int(args.steps),
output_type='pil',
width=int(args.width),
).images
for i in range(len(images)):
images[i].save(
os.path.join(
args.output,
'{}_{}.png'.format(args.prefix, seed + i),
),
)
seed = seed + len(images)
if args.s3_token and args.s3_secret and args.s3_bucket:
print('Start uploading to S3')
s3 = boto3.client(
's3',
endpoint_url=args.s3_endpoint if args.s3_endpoint else None,
aws_access_key_id=args.s3_token,
aws_secret_access_key=args.s3_secret,
)
files = glob.glob(os.path.join(args.output, '*.png'))
for file in files:
print(os.path.basename(file))
s3.upload_file(
Filename=file,
Bucket=args.s3_bucket,
Key=os.path.basename(file),
)docker-entrypoint.sh
エディターツールを開きます。
vim docker-entrypoint.sh以下の内容を記述し、保存します。
#!/bin/bash
set -ue
shopt -s nullglob
export TZ=${TZ:-Asia/Tokyo}
if [ -z "${SAKURA_ARTIFACT_DIR:-}" ]; then
echo "Environment variable SAKURA_ARTIFACT_DIR is not set" >&2
exit 1
fi
if [ -z "${SAKURA_TASK_ID:-}" ]; then
echo "Environment variable SAKURA_TASK_ID is not set" >&2
exit 1
fi
if [ -z "${PROMPT:-}" ]; then
echo "Environment variable PROMPT is not set" >&2
exit 1
fi
pushd /stable-diffusion
python3 runner.py \
--batch="${BATCH:-1}" \
--height="${HEIGHT:-1024}" \
--model="${MODEL:-}" \
--variant="${VARIANT:-fp16}" \
--negative="${NEGATIVE_PROMPT:-}" \
--num="${NUM_IMAGES:-1}" \
--output="${SAKURA_ARTIFACT_DIR}" \
--prefix="${SAKURA_TASK_ID}" \
--prompt="${PROMPT}" \
--s3-bucket="${S3_BUCKET:-}" \
--s3-endpoint="${S3_ENDPOINT:-}" \
--s3-secret="${S3_SECRET:-}" \
--s3-token="${S3_TOKEN:-}" \
--seed="${SEED:--1}" \
--steps="${STEPS:-20}" \
--width="${WIDTH:-1024}"
popddocker-entrypoint-fuduki.sh
エディターツールを開きます。
vim docker-entrypoint-fuduki.sh以下の内容を記述し、保存します。
#!/bin/bash
set -ue
shopt -s nullglob
export TZ=${TZ:-Asia/Tokyo}
if [ -z "${SAKURA_ARTIFACT_DIR:-}" ]; then
echo "Environment variable SAKURA_ARTIFACT_DIR is not set" >&2
exit 1
fi
if [ -z "${SAKURA_TASK_ID:-}" ]; then
echo "Environment variable SAKURA_TASK_ID is not set" >&2
exit 1
fi
if [ -z "${PROMPT:-}" ]; then
echo "Environment variable PROMPT is not set" >&2
exit 1
fi
pushd /stable-diffusion
if [ ! -e fuduki_mix ]; then
GIT_LFS_SKIP_SMUDGE=1 git clone --depth=1 https://huggingface.co/Kotajiro/fuduki_mix
pushd fuduki_mix
git lfs pull -I /fuduki_mix_v20.safetensors
popd
fi
python3 runner.py \
--batch="${BATCH:-1}" \
--height="${HEIGHT:-1024}" \
--model="./fuduki_mix/fuduki_mix_v20.safetensors" \
--variant="single" \
--negative="${NEGATIVE_PROMPT:-}" \
--num="${NUM_IMAGES:-1}" \
--output="${SAKURA_ARTIFACT_DIR}" \
--prefix="${SAKURA_TASK_ID}" \
--prompt="${PROMPT}" \
--s3-bucket="${S3_BUCKET:-}" \
--s3-endpoint="${S3_ENDPOINT:-}" \
--s3-secret="${S3_SECRET:-}" \
--s3-token="${S3_TOKEN:-}" \
--seed="${SEED:--1}" \
--steps="${STEPS:-20}" \
--width="${WIDTH:-1024}"
popdDockerイメージの作成とアップロード
上記4つのファイルを作成したら、dockerコマンドを使用してイメージのビルドと、さくらのコンテナレジストリへのアップロードを行います。
まず、さくらのコンテナレジストリにログインします。
sudo docker login <作成したレジストリのホスト名>.sakuracr.jp/sdxl1.0-base
Username:<作成したユーザー>
Password:<作成したユーザーのパスワード>イメージを作成(build)します。
sudo docker build -t <作成したレジストリのホスト名>.sakuracr.jp/sdxl1.0-base:latest .※末尾に引数として「.」が必要です。
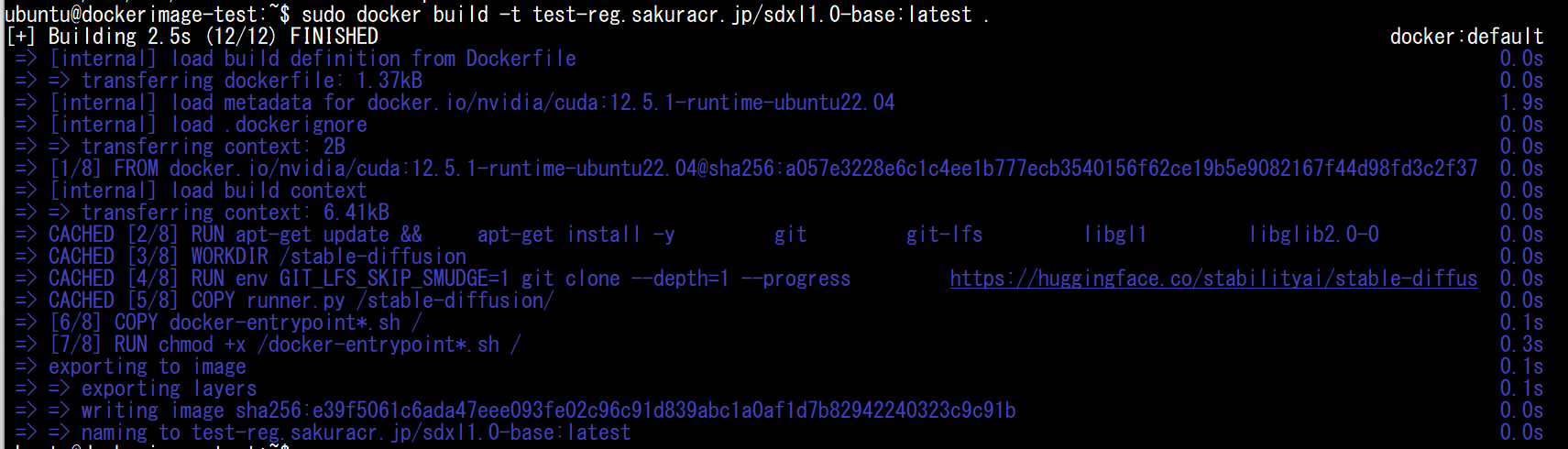
イメージの作成が完了したら、そのイメージをコンテナレジストリにアップロード(push)します。容量が大きいため、初回はかなり時間がかかります。
sudo docker image push <作成したレジストリのホスト名>.sakuracr.jp/sdxl1.0-base:latest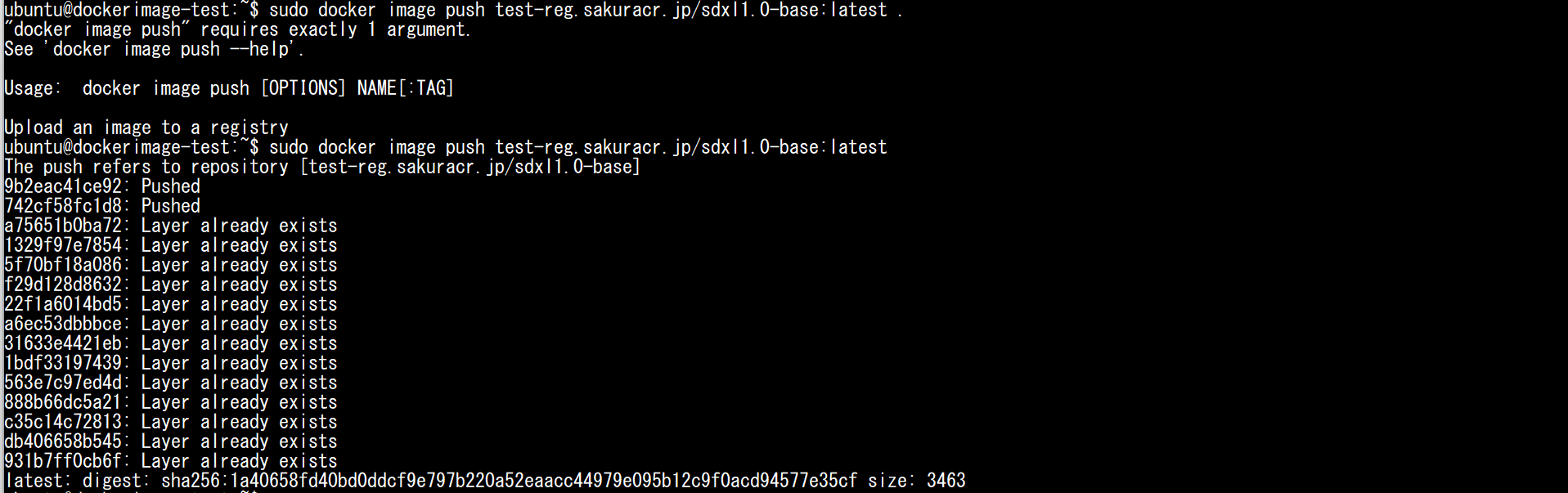
※上記の実行例は一部Push済みの状態から差分のみアップロードしているため、「Layer already exists」と表示されている箇所があります。
以上で準備は完了です。Dockerイメージ作成サーバーからログアウトします。
exit高火力 DOKのログインおよびプライベートレジストリの設定
Webブラウザで高火力 DOKのコントロールパネルにアクセスし、会員IDもしくはユーザーコードを使ってログインします。
高火力 DOKでは、DockerHubなどにあるパブリックなDockerイメージも利用できますが、プライベートなコンテナレジストリに格納されているDockerイメージを利用することもできます。本記事では、前回の記事で作成したコンテナレジストリ(Lab)のプライベートレジストリを組み合わせ、必要な認証情報を使ってDockerイメージを読み出します。
高火力 DOKのコントロールパネルにログインしたら、左メニュー「レジストリー」をクリックし、右上の「新規登録」から、コンテナレジストリのホスト名と、アクセスするために必要なユーザー名およびパスワードを記入して「登録」をクリックします。
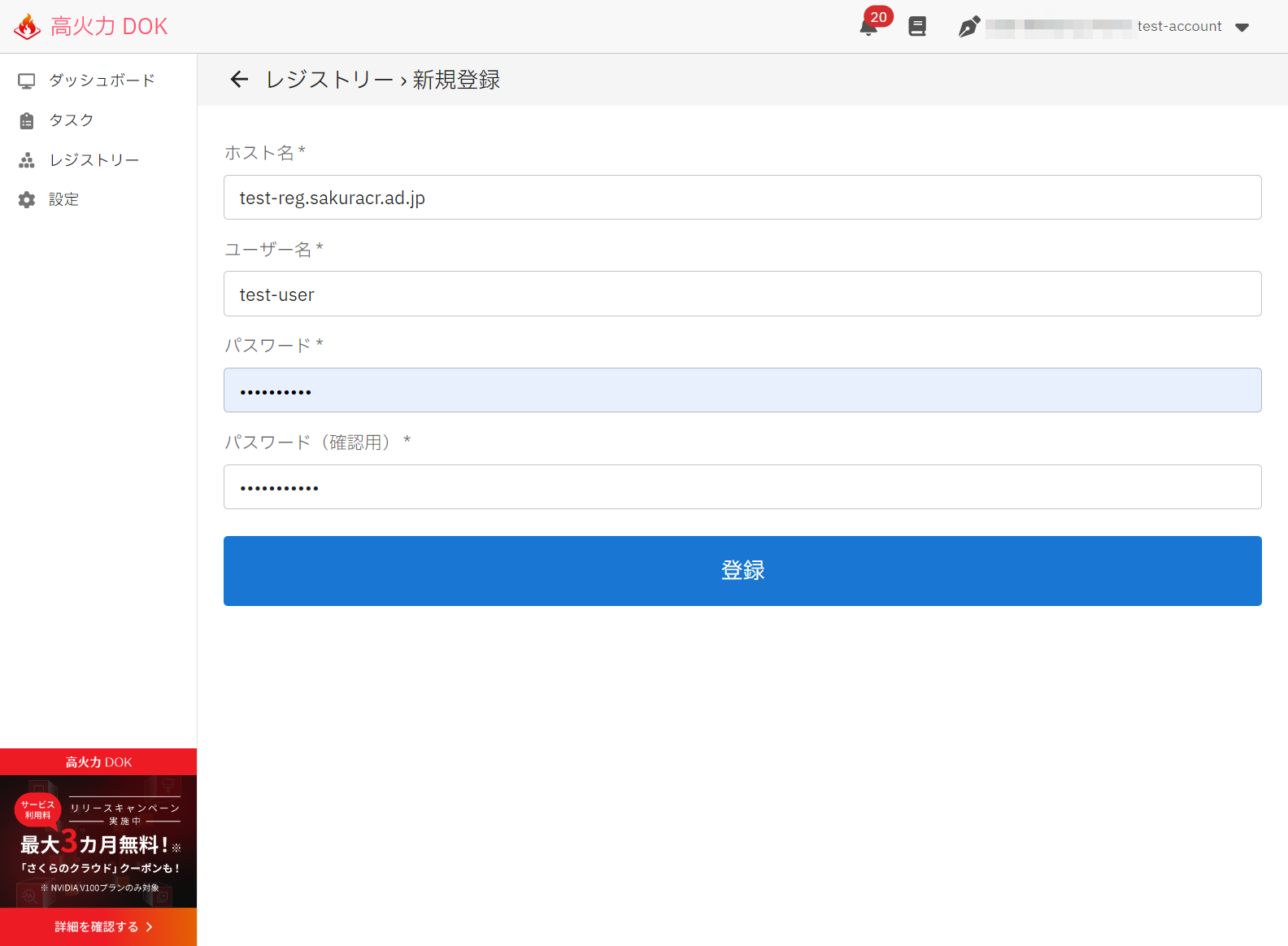
登録が成功すると、作成されたホスト名およびユーザー名が一覧画面に表示されます。
※パスワードは一覧および詳細でも表示されません。
ここまでできたら、高火力 DOKのコントロールパネルの左メニューから「タスク」をクリックします。この後は、作成したDockerイメージを使って、高火力 DOKで画像の生成タスクを実行していきます。
SD-XL 1.0-baseモデルを使用した画像生成
まずはStabilityAI社が提供するモデルSD-XL 1.0-baseを使用して画像を生成してみます。今回は最小限の内容として、生成プロンプトおよびネガティブプロンプトのみを指定して生成を行います。
※本モデルの利用にあたっては、CreativeML Open RAIL++-Mライセンスに同意しているものとします。
右上の新規作成をクリックしてタスクの新規作成画面に遷移し、以下のパラメータを指定して「作成」をクリックします。
- イメージ:<作成したコンテナレジストリ名>.sakuracr.jp/sdxl1.0-base
- レジストリー:<作成したユーザー名@ホスト>
- コマンド:<空欄>
- エントリーポイント:<空欄>
- 環境変数 - PROMPT:<任意のプロンプト>
- 環境変数 - NEGATIVE_PROMPT:<任意のプロンプト>
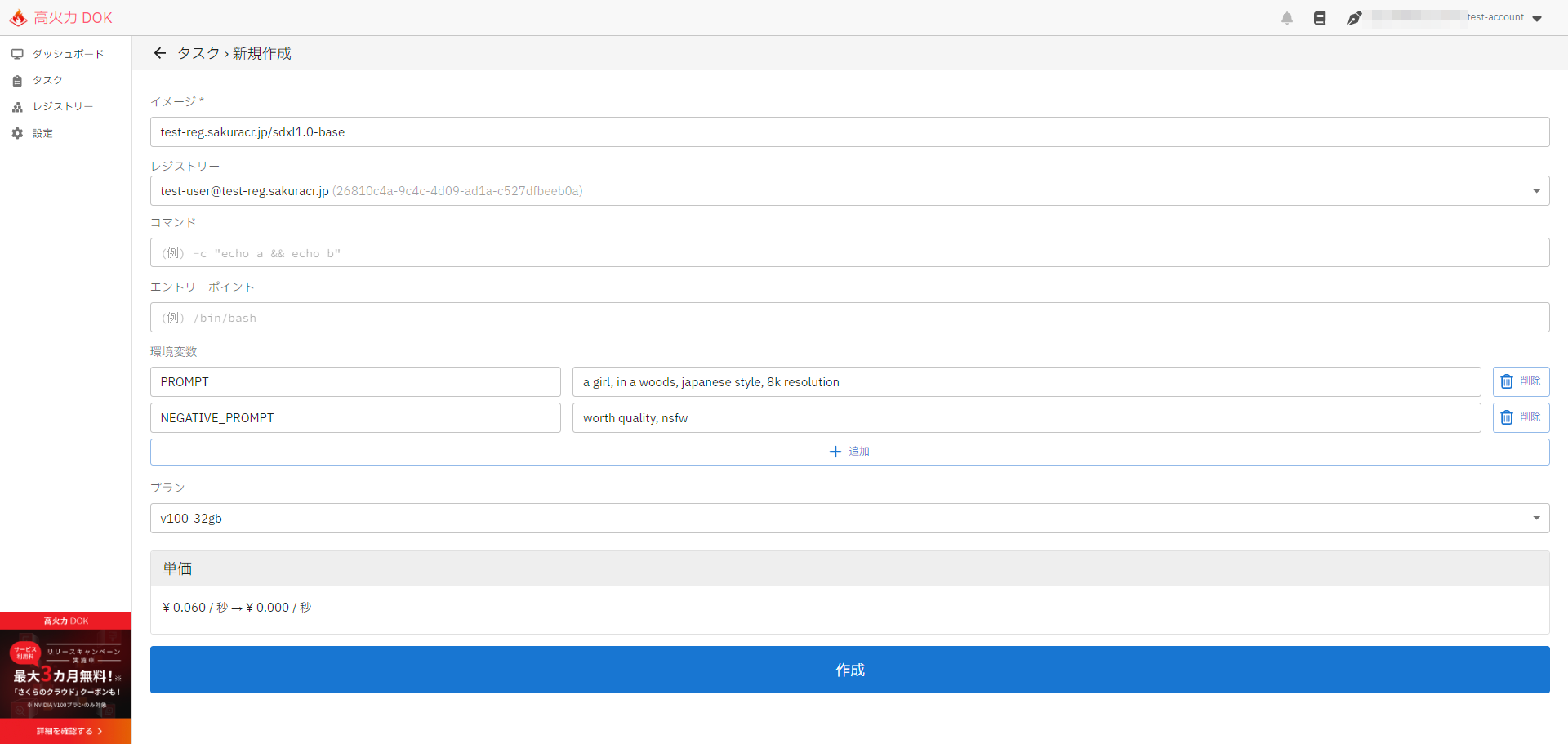
タスクの新規作成時にはダイアログが表示されますので、再度確認のうえ「作成」をクリックします。
なお、今回のDockerイメージでは、以下の環境変数を指定することができます。
| 環境変数 | 必須/任意 | デフォルト値 | 内容 |
|---|---|---|---|
| PROMPT | 必須 | なし | 生成プロンプト (例: An astronaut riding a green horse) |
| NEGATIVE_PROMPT | 任意 | なし | ネガティブプロンプト (例: worth quality, nsfw) |
| MODEL | 任意 | ./stable-diffusion-xl-base-1.0 | 生成に使用するモデル |
| VARIANT | 任意 | fp16 | モデルのバリアント、主に none, fp16 または single を指定(後ろのパートで利用) |
| SEED | 任意 | -1(ランダム) | 乱数シード、ある値で固定すると同様の構図のイラストが出力されやすくなる |
| WIDTH | 任意 | 1024 | 生成画像サイズ(幅)。大きすぎても小さすぎても正しく画像が生成されない |
| HEIGHT | 任意 | 1024 | 生成画像サイズ(高さ)。大きすぎても小さすぎても正しく画像が生成されない |
| STEPS | 任意 | 20 | 画像生成のステップ数。大きいと高画質だが生成が遅くなる |
| NUM_IMAGES | 任意 | 1 | 一度に生成する画像数。大きすぎる値を指定すると処理が失敗する場合がある |
| BATCH | 任意 | 1 | 生成の繰り返し回数。NUM_IMAGES = 5, BATCH = 20 で 100 枚生成する |
| S3_ENDPOINT | 任意 (オブジェクトストレージ利用時は必須) | なし | S3互換ストレージのエンドポイントURL。さくらのオブジェクトストレージの場合は、https://s3.isk01.sakurastorage.jp を指定する |
| S3_TOKEN | 任意 (オブジェクトストレージ利用時は必須) | なし | S3のアクセスキーID。さくらのオブジェクトストレージの場合は、前回の記事でサイト利用開始時に表示されたアクセスキーIDを指定する |
| S3_SECRET | 任意 (オブジェクトストレージ利用時は必須) | なし | S3のシークレットアクセストークン。さくらのオブジェクトストレージの場合は、前回の記事でサイト利用開始時に表示されたシークレットアクセスキーを指定する |
| S3_BUCKET | 任意 (オブジェクトストレージ利用時は必須) | なし | S3のバケット名。さくらのオブジェクトストレージの場合は、前回の記事でバケット作成時に指定したバケットの名前を指定する |
タスクの作成が成功すると、タスクの詳細画面に遷移します。指定された内容と、状態が待機中もしくは実行中であることが確認できます。
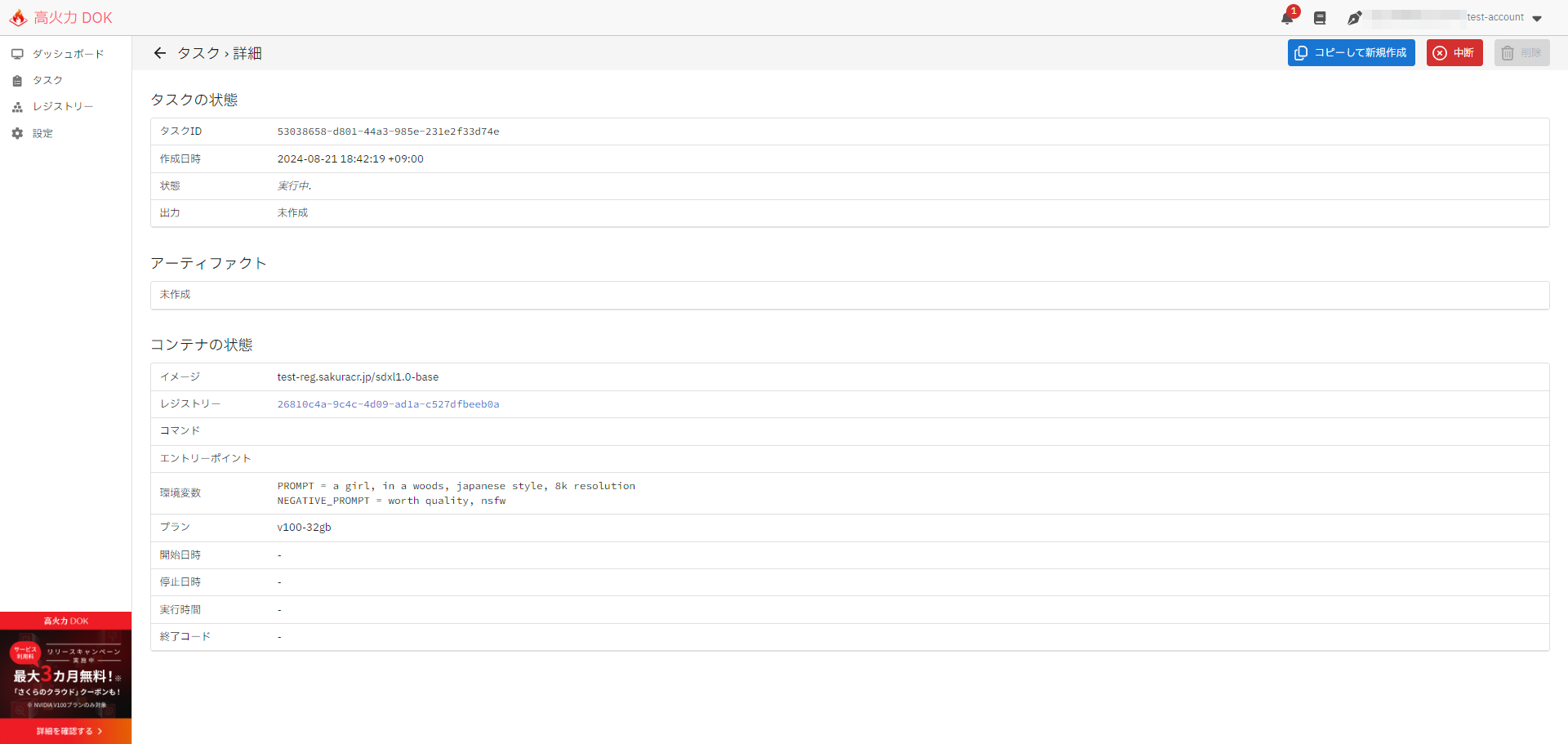
高火力 DOKでは、作成されたタスクは他ユーザーのものと合わせて順次実行されるため、実際のDockerイメージが実行されるまでに時間がかかります。また、タスクの実行開始からDockerイメージの実行開始までの間に、Dockerイメージをコンテナレジストリから取得する処理が発生しますが、この時間は課金対象外となります。

作成したタスクに問題がなければ、しばらくすると状態が完了に遷移します。完了したタスクの「タスクの状態 - 出力」欄には実行されたコンテナの標準出力の内容が、「アーティファクト - ダウンロード」欄には生成された画像をtar.gz形式でダウンロードするためのリンクが、それぞれ表示されます。
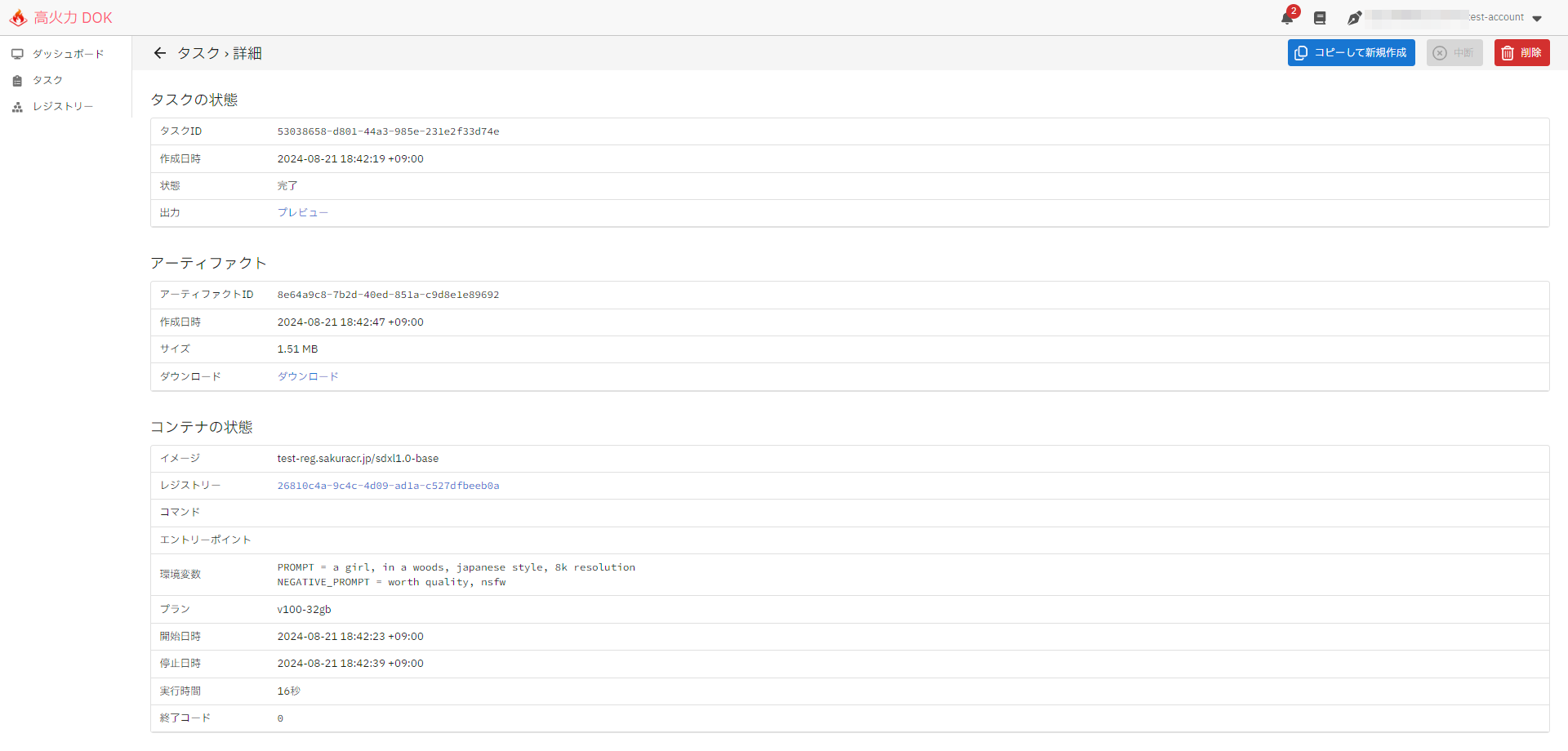
標準出力の内容を以下に示します。
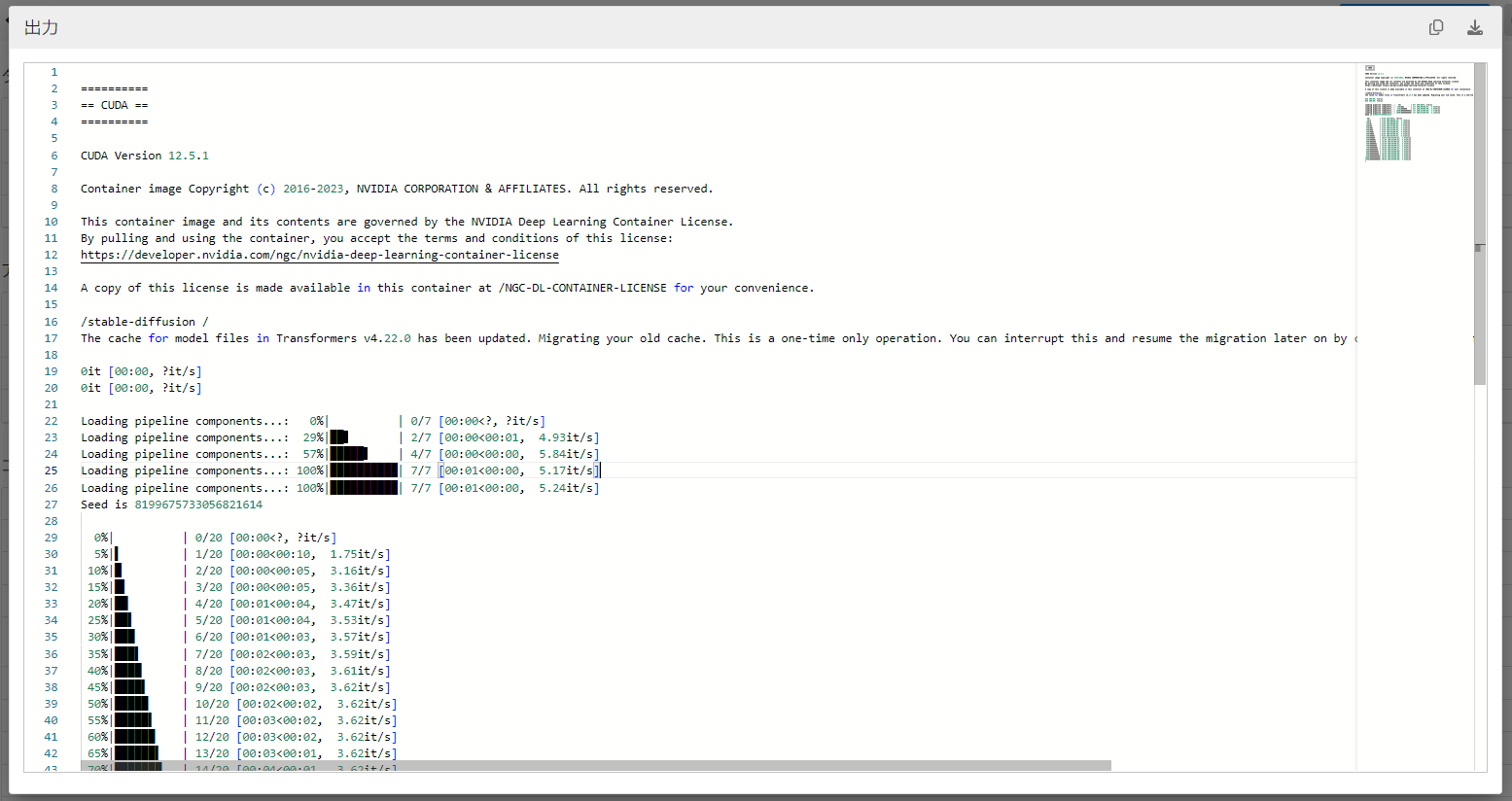
生成された画像はこちらです。

実行にかかった時間は16秒でした。
SD-XL 1.0-baseのモデルはコンテナ内に格納されているので、非常に短時間で高精度の画像を生成することが出来ました。前述のプロンプトを変えてみたり、環境変数を変更することで画像のサイズや生成枚数などを変更することもできます。
次のステップでは、別のモデルを用いて別のテイストの画像を作成します。
アニメ系モデル(Animagine XL 3.1)を使用した画像生成
Huggingface で公開されている一部のモデルは、このコンテナイメージで直接モデルを指定して利用することができます。モデルの一つである Animagine XL 3.1 では、アニメ・イラストレーション調の画像を生成することができます。
今回はHuggingface上に推奨となるプロンプトなどもあるため、同様のプロンプトに加えて推奨のプロンプトおよびネガティブプロンプトを設定します。
※本モデルの利用にあたっては、Fair AI Public License 1.0-SDライセンスに同意しているものとします。
※追加のモデルのダウンロードが行われるため、イメージ単体で実行するよりもコンテナの実行時間が大きくなることに注意しましょう。
※既存作品のキャラクターも指定すれば出力されてしまう場合があるため、指示するプロンプトには注意しましょう。
高火力 DOKのタスク作成画面では、以下のパラメータを指定します。
- イメージ:<作成したコンテナレジストリ名>.sakuracr.jp/sdxl1.0-base
- レジストリー:<作成したユーザー名@ホスト>
- コマンド:<空欄>
- エントリーポイント:<空欄>
- 環境変数 - PROMPT:<任意のプロンプト>
- 環境変数 - NEGATIVE_PROMPT:<任意のプロンプト>
- 環境変数 - MODEL:cagliostrolab/animagine-xl-3.1
- 環境変数 - VARIANT:none
生成された画像はこちらです。

実行にかかった時間は6分9秒(369秒)でした。Dockerイメージが起動してから外部からモデルを読み込むため時間がかかりましたが、標準のモデルとは全く異なるテイストの画像が生成できました。
次にまた別のモデルを使った画像生成も試してみましょう。
リアル系モデル(fuduki_mix)を使用した画像生成
これまでに扱ってきたモデルとは違い、モデルのデータ(safetensors形式やpt形式のファイル)が単体で提供されているものも存在します。こういったモデルの場合、読み込みの手順が異なる場合があります。
そういったモデルの一つであるfuduki_mixでは、フォトリアル調の画像を生成することができます。
今回はイメージ作成時に本モデルを使う前提のシェルスクリプトも入れ込んでいるため、コマンド欄にそれを指定することで呼び出して実行できます。また、こちらのモデルもHuggingface上に推奨となる画像サイズやステップ数の値があるため、同様のプロンプトに加えてそれらの値も環境変数として設定します。
※本モデルの利用にあたっては、CreativeML Open RAIL++-Mライセンスへ同意されているものとします。。
※追加のモデルのダウンロードが行われるため、イメージ単体で実行するよりもコンテナの実行時間が大きくなることに注意しましょう。
高火力 DOKのタスク作成画面では、以下のパラメータを指定します。
- イメージ:<作成したコンテナレジストリ名>.sakuracr.jp/sdxl1.0-base
- レジストリー:<作成したユーザー名@ホスト>
- コマンド:/docker-entrypoint-fuduki.sh
- エントリーポイント:<空欄>
- 環境変数 - PROMPT:<任意のプロンプト>
- 環境変数 - NEGATIVE_PROMPT:<任意のプロンプト>
- 環境変数 - WIDTH:1152
- 環境変数 - HEIGHT:896
- 環境変数 - STEPS:40
生成された画像はこちらです。

実行にかかった時間は14分22秒(862秒)でした。こちらもDockerイメージが起動してから外部からモデルを読み込むため時間がかかりましたが、標準のモデルとは雰囲気の異なる顔付きの画像が生成できました。
オブジェクトストレージへの生成画像の格納
高火力 DOKが標準で提供するアーティファクトの保管には72時間の保管期限が設けられており、永続的に保管することができません。そこで、手動で手元にダウンロードするのではなく、必要に応じてストレージサービスに送信し、生成された画像を永続的に保存することを考えましょう。せっかくなので時間の検証も兼ねて、NUM_IMAGESおよびBATCH変数を指定して計50枚の画像を生成してみましょう。ストレージサービスはさくらインターネットが提供するさくらのクラウドのオプションサービスである「オブジェクトストレージ」を指定します。
本記事のDockerイメージでは、必要な認証情報や保存先情報を環境変数として指定することで、前回の記事で作成したオブジェクトストレージのバケットに保存することが出来ます。
※本モデルの利用にあたっては、CreativeML Open RAIL++-Mライセンスへ同意されているものとします。
※利用にあたっては、高火力 DOKの利用料以外に、オブジェクトストレージの費用も発生します。
高火力 DOKのタスク作成画面では、以下のパラメータを指定します。
- イメージ:<作成したコンテナレジストリ名>.sakuracr.jp/sdxl1.0-base
- レジストリー:<作成したユーザー名@ホスト>
- コマンド:/docker-entrypoint-fuduki.sh
- エントリーポイント:<空欄>
- 環境変数 - PROMPT:<任意のプロンプト>
- 環境変数 - NEGATIVE_PROMPT:<任意のプロンプト>
- 環境変数 - SEED:24
- 環境変数 - STEPS:40
- 環境変数 - NUM_IMAGES:5
- 環境変数 - BATCH:10
- 環境変数 - S3_ENDPOINT:https://s3.isk01.sakurastorage.jp
- 環境変数 - S3_TOKEN:<作成したオブジェクトストレージのアクセスキーID>
- 環境変数 - S3_SECRET:<作成したオブジェクトストレージのシークレットアクセスキー>
- 環境変数 - S3_BUCKET:<作成したオブジェクトストレージのバケット名>
生成された50枚の画像の中から1枚を掲載します。

実行にかかった時間は9分59秒(599秒)でした。
実行が終了したら、オブジェクトストレージに画像が保存されているかどうかを確認してみましょう。
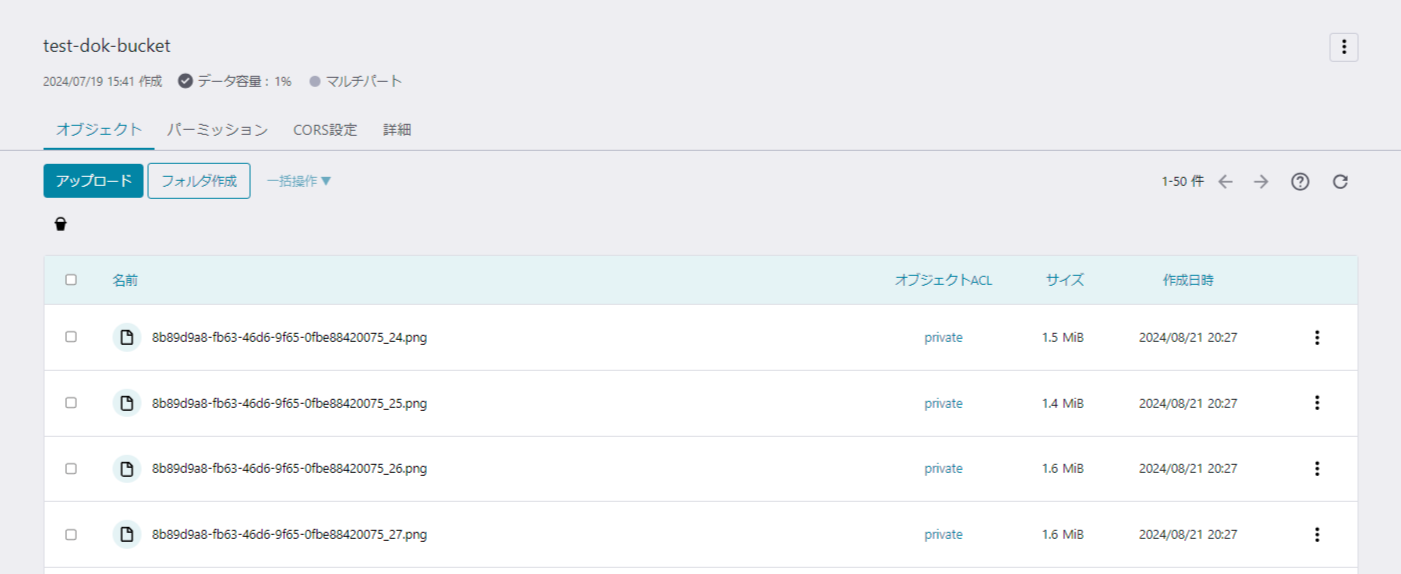
予定通り50件の画像が作成され、オブジェクトストレージにもアップロードされていることが確認できました。
なお、このDockerイメージの場合は、SEED値を指定した場合でも一つずつズラしながら画像を生成します。気に入った画像が見つかった場合、そのSEED値を指定しつつプロンプトを書き換えることで、元の生成画像のテイストを残しつつ出力する画像を調整することができます。
最後に
以上で、SDXLを軸にしたDockerイメージの構築から、実際にDockerイメージを使った画像生成までを高火力 DOKを使って実現できることがわかりました。今回は画像生成にフォーカスした内容でしたが、例えばfaster-whisperといったSpeech to textのAIモデルを動作させることで、任意の動画や音声データから文字起こしを行う、といったAI処理を行うこともできます。
今後もさまざまなバリエーションの紹介ができればと考えております。さまざまなAIモデルを使った新しいアイデアが高火力 DOKを通じて生まれることを期待しております!!!