Asakusa Frameworkのセットアップと実行編~ さくらのクラウドでHadoop/Spark/Asakusa環境を構築する(3)

はじめに
「さくらのクラウドでHadoop/Spark/Asakusa環境を構築する」の最終回となる第3回です。
前回までに、さくらのクラウド環境に Hadoop ディストリビューション Hortonworks Data Platform (HDP) を使ってHadoopクラスタを構築し、その環境に Spark をセットアップして、HadoopとSparkを連携するための設定を行いました。
今回は、Asakusa Framework を紹介します。 Hadoopクラスタ上にAsakusa Frameworkをセットアップして、Hadoop MapReduceやSpark上で動作するバッチアプリケーションを実行してみます。 また、今回はAsakusa Frameworkの機能の中から、Hive や Spark SQL といったクエリー実行エンジン(SQL on Hadoop)と連携するための機能について紹介します。
Asakusa Frameworkとは
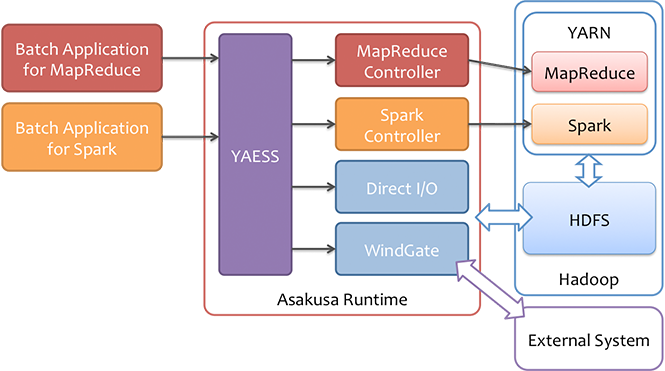
Asakusa FrameworkはHadoopやSparkを実行基盤に利用した分散バッチアプリケーションを開発、実行するためのフレームワークです。 規模が大きい、複雑なデータフローやデータ構造を持つバッチアプリケーションを開発、管理するために必要な機能セットを提供している点が特徴です。
Asausa Frameworkでは「Asakusa DSL」と呼ばれるJavaベースのDSLを使ってデータフローを記述します。 処理内容や処理単位に応じたDSLを使い分けることで、アプリケーションを効率よく開発するだけでなく、コンポーネント化や再利用性などが促進されます。 また、DSL単位でのテストやテスト自動化ツールとの高い親和性を持つテスト機構など、複雑なアプリケーションに対する品質管理や運用維持といった側面をサポートする機能も多く提供しています。
Asakusa DSLから実行可能なアプリケーションを生成するためには「Asakusa DSL コンパイラ」を利用します。 このコンパイラはHadoopやSparkといった、それぞれの実行基盤に最適な形式で実行可能なアプリケーションを生成します。 ユーザが複数の実行基盤の上でアプリケーションを評価して選択することができるのも、Asakusa Frameworkの特徴の一つです。 このコンパイラはビルドツールGradleと連携して、コマンドラインやEclipse Pluginのメニューから簡単に利用することができます。
その他、分散ファイルシステムに対して効率的なデータの読み書き、様々なデータフォーマットに対応したデータ入出力機構「Direct I/O」、 RDBMSやローカルファイルなど外部システムとの連携を行うためのモジュール「WindGate」、 複雑なバッチアプリケーションを統一的に実行するためのコマンドラインインターフェース「YAESS」など、 データ連携やアプリケーション運用についての機能も充実しています。
Asakusa Frameworkの機能や特徴、またAsakusa Frameworkを使った開発の流れについては、Asakusa Frameworkの以下のドキュメントなども参考にしてください。
サンプルアプリケーションの実行
それでは実際にAsakusa FrameworkのバッチアプリケーションをHadoopクラスタ上で実行してみましょう。
通常Asakusa Frameworkを利用する場合には、デスクトップ環境上でアプリケーションの実装やテスト、コンパイル(ビルド)を実行し、 ビルドの結果生成した実行モジュールをHadoopクラスターに配置(デプロイ)してバッチを実行する、という手順を踏むのですが、 この流れをすべて紹介するととても説明が長くなってしまうので、今回はGitHubに公開されているサンプルアプリケーションをHadoopクラスタにダウンロードして、 そこでビルド、デプロイを行いバッチを実行する、という手順を紹介します。
ユーザの準備
Asakusa Frameworkを管理する任意のグループとユーザを作成します。
今回は、前回でサーバ hdp-node1 上に作成したユーザ sakura を利用します。
環境変数の設定
Asakusa Frameworkの利用に必要となる環境変数を設定します。以下は設定例です。
export JAVA_HOME=/usr/jdk64/jdk1.8.0_40 export ASAKUSA_HOME=$HOME/asakusa export SPARK_CMD=$HOME/spark/bin/spark-submit
JAVA_HOMEはHDPのインストール時に導入されたJDKのパスを指定します。HDPのバージョンによって、インストールされるJDKのバージョンが異なるかもしれないので、実際に設定する際には/etc/hadoop/conf/hadoop-env.shに設定されているJAVA_HOMEの設定値を確認してください。ASAKUSA_HOMEにはAsakusa Frameworkの実行環境を配置するディレクトリパスを指定します。なおセットアップ時に初期化を行うとこのディレクトリ配下が全て削除されるので注意してください。SPARK_CMDはSparkアプリケーションの実行するためのコマンドspark-submitのパスを指定します。
環境変数の設定は $HOME/.bash_profile などに設定しておくとよいでしょう。
ディレクトリの作成
以下のディレクトリを作成しておきます。
$ASAKUSA_HOME: Asakusa Frameworkの実行環境のデプロイ先$HOME/workspace: サンプルアプリケーションのプロジェクト(ソースコード)の配置先
mkdir $ASAKUSA_HOME mkdir $HOME/workspace
サンプルアプリケーションのダウンロード
Asakusa FrameworkのサンプルアプリケーションのソースコードはGitHub [asakusafw-examples] に公開されています。 ここからソースコードのアーカイブをダウンロードして、 $HOME/workspace に展開します。
ASAKUSAFW_VERSION=0.7.6
cd ~/workspace
wget https://github.com/asakusafw/asakusafw-examples/archive/${ASAKUSAFW_VERSION}.tar.gz
tar xf ${ASAKUSAFW_VERSION}.tar.gz
このアーカイブにはいくつかのアプリケーションが含まれていますが、ここでは example-directio-csv というプロジェクトを使います。 このプロジェクトにカレントディレクトリを移動します。
cd ~/workspace/asakusafw-examples-${ASAKUSAFW_VERSION}/example-directio-csv/
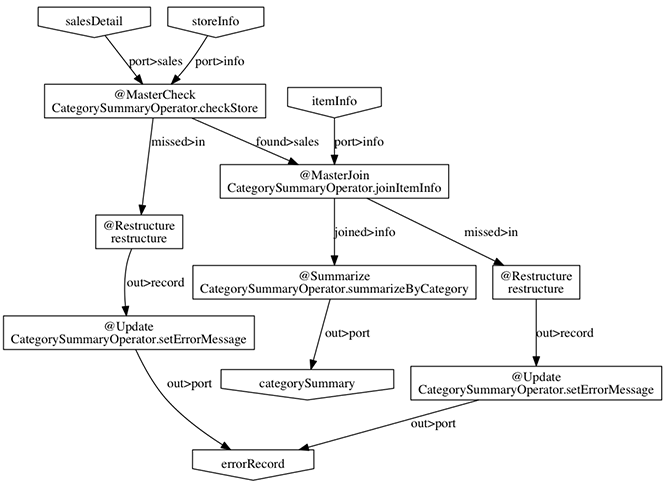
ここで実行するサンプルアプリケーション「カテゴリー別売上金額集計バッチ」は、売上トランザクションデータと、商品マスタ、店舗マスタを入力として、エラーチェックを行った後、売上データを商品マスタのカテゴリ毎に集計するアプリケーションです。
バッチアプリケーションの入力データ取得と出力データ生成には、Asakusa Frameworkの「Direct I/O」と呼ばれるコンポーネントを利用しています。 Direct I/Oを利用して、Hadoopファイルシステム上のCSVファイルに対して入出力を行います。
以下の図はここで実行するサンプルアプリケーションに対して、Asakusa Frameworkの機能でアプリケーションのデータフロー構造をグラフ化したものです。 興味のある方はアプリケーションのソースコードを確認してみてください。
アプリケーションのビルド
ダウンロードしたサンプルアプリケーションはソースコードのみ含まれている状態なので、これを実行可能な形式にコンパイル(ビルド)します。
サンプルアプリケーションのデフォルト設定では、Hadoop MapReduce(Hadoopのバージョン1系)向けの実行形式のみ作成するようになっているため、ここでは以下のように設定を追加、変更します。
- Hadoopのバージョン2系を利用する。
- Spark向けの実行モジュールも合わせて生成する。
ビルドの設定を変更するには、プロジェクト直下にあるビルド設定ファイル build.gradle を編集します。
- 6行目:
buildscript/dependencisブロックに指定しているAsakusa Gradle Pluginの指定をAsakusa on Spark Gradle Pluginの指定に変更するclasspath group: 'com.asakusafw.spark', name: 'asakusa-spark-gradle', version: '0.2.1'
- 18行目: Asakusa on Spark Gradle Pluginを適用する定義を追加する
apply plugin: 'asakusafw-spark'
修正した build.gradle は以下のようになります。
buildscript {
repositories {
maven { url projectAsakusafwMavenRepos }
}
dependencies {
classpath group: 'com.asakusafw.spark', name: 'asakusa-spark-gradle', version: '0.2.1'
}
}
task wrapper(type: Wrapper) {
distributionUrl 'http://services.gradle.org/distributions/gradle-2.8-bin.zip'
jarFile file('.buildtools/gradlew.jar')
}
apply plugin: 'asakusafw'
apply plugin: 'asakusafw-organizer'
apply plugin: 'eclipse'
apply plugin: 'asakusafw-spark'
asakusafw {
asakusafwVersion projectAsakusafwVersion
modelgen {
modelgenSourcePackage 'com.example.modelgen'
}
compiler {
compiledSourcePackage 'com.example.batchapp'
}
}
asakusafwOrganizer {
profiles.prod {
asakusafwVersion asakusafw.asakusafwVersion
}
}
dependencies {
compile group: 'com.asakusafw.sdk', name: 'asakusa-sdk-core', version: asakusafw.asakusafwVersion
compile group: 'com.asakusafw.sdk', name: 'asakusa-sdk-directio', version: asakusafw.asakusafwVersion
compile group: 'com.asakusafw.sdk', name: 'asakusa-sdk-windgate', version: asakusafw.asakusafwVersion
provided (group: 'org.apache.hadoop', name: 'hadoop-client', version: projectHadoopVersion) {
exclude module: 'junit'
exclude module: 'mockito-all'
exclude module: 'slf4j-log4j12'
}
}
また、このサンプルプロジェクトではプロジェクト直下にある gradle.properties にライブラリのバージョンを設定します。 このファイルに今回使用するAsakusa FrameworkのバージョンとHadoopのバージョンを指定します。
修正した gradle.properties は以下のようになります。
projectAsakusafwVersion=0.7.6-hadoop2 projectHadoopVersion=2.7.1 projectAsakusafwMavenRepos=http://asakusafw.s3.amazonaws.com/maven/releases
build.gradle と gradle.properties の設定を変更したら、Gradleのコマンドを使ってアプリケーションをビルドして、 ローカル環境の $ASAKUSA_HOME に実行環境をインストールします。
./gradlew assemble installAsakusafw
初回のビルド時には必要なライブラリのダウンロードが行われるため数分程度時間がかかります。 BUILD SUCCESSFUL という表示が出ればビルドが成功です。
なお、Asakusa Frameworkのバージョンアップ時にビルド方法やデフォルト設定が変更になることがあるため、 本記事とは異なるバージョンを使う場合には、Asakusa Frameworkのドキュメントを確認してください。
データの配置
バッチアプリケーションの入力となるデータをHDFS上に配置します。
プロジェクトディレクトリ配下の src/test/example-dataset ディレクトリには、サンプルデータが用意されています。 これらのファイルをHDFSのDirect I/Oの入出力ディレクトリ(デフォルトの設定では target/testing/directio )にコピーします。
hadoop fs -mkdir -p target/testing/directio hadoop fs -put src/test/example-dataset/master target/testing/directio/master hadoop fs -put src/test/example-dataset/sales target/testing/directio/sales
アプリケーションの実行
バッチアプリケーションを実行するには、YAESSのコマンド $ASAKUSA_HOME/yaess/bin/yaess-batch.sh を実行します。 引数にはバッチIDとアプリケーションで利用するパラメータ(バッチ引数)を指定します。
今回アプリケーションのビルドで、MapReduce上で動作するアプリケーション、Spark上で動作するアプリケーションをそれぞれ作成したので、 ここでは両方のアプリケーションを実行してみましょう。
MapReduce上で動作するアプリケーションは、バッチID example.summarizeSales を指定して、以下のように実行します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh example.summarizeSales -A date=2011-04-01
Spark上で動作するアプリケーションは、デフォルトのビルド設定ではバッチIDの先頭に spark. という接頭辞が付いて生成されます。 ここでは以下のように実行します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh spark.example.summarizeSales -A date=2011-04-01
なお現時点では、Spark上で動作するアプリケーションでもDirect I/O(データの入出力の部分)の実行には、MapReduceのジョブが利用されることがあります。
結果の確認
このサンプルアプリケーションの実行結果は target/testing/directio/result 配下にCSV形式で出力されます。
hadoop fs -text target/testing/directio/result/category/* hadoop fs -text target/testing/directio/result/error/*
ここまでの手順が正常に実行できたら、Hadoop, Spark, Asakusa Frameworkの基本的な環境構築は完了です。
手元で開発環境を構築し、アプリケーションを開発するところから試してみたいという方は、Asakusa Frameworkの以下のドキュメントなどを参考にしてください。
- Asakusa Framework スタートガイド
- 新規のOSを用意し、アプリケーションの開発環境とローカルでバッチアプリケーションを実行するための環境を構築するためのガイドです。
- Asakusa Framework スタートガイド for Windows
- Eclipse上でアプリケーションの開発、テスト、ビルドを実行する環境を用意するためのガイドです。アプリケーションの実行は別に用意したクラスタ上で行います。
- Windows以外の環境(MacOSXやLinux)でもほぼ同様の手順で動かすことができるので、今回のようにHadoopクラスタがすでに用意されている場合は、こちらの手順がおすすめです。
Hive/Spark SQLとの連携
Asakusa FrameworkはHiveやSpark SQLなどのクエリーエンジン(SQL on Hadoop)と連携するための機能として、 Direct I/Oを使ってHiveと互換性のあるカラムナフォーマット(Parquet, ORC)ファイルを入出力する「Direct I/O Hive」や、 データモデルの定義からテーブル定義用のDDLを生成する機能などを提供しています。
これらの機能を使った連携の例として、複雑なデータ処理やしっかりテストを行いたいデータ処理はAsakusa Frameworkのバッチアプリケーションとして記述し、 そのバッチの実行結果データをアドホックに、インタラクティブな操作でSQL on Hadoopを使って照会する、 といったような使いわけができます。
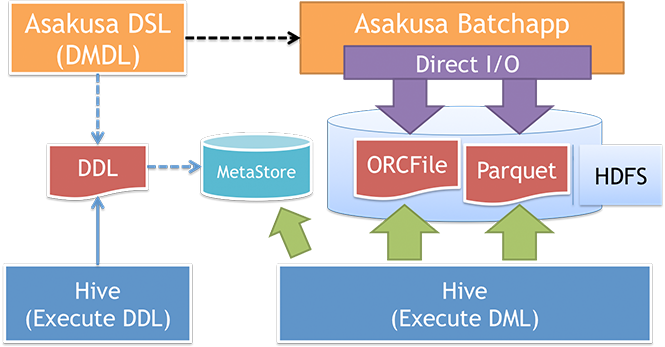
ここでは、先ほど実行した「カテゴリー別売上金額集計バッチ」のデータ入出力部分を「Direct I/O Hive」に置き換えたサンプルアプリケーションを実行してみます。 このアプリケーションは、入出力データフォーマットがCSVからParquet、ORCに変更されています。
アプリケーションのビルド
今回は先にダウンロードしたサンプルアプリケーションに含まれる example-directio-hive というプロジェクトを使うので、 このプロジェクトにカレントディレクトリを移動します。
cd ~/workspace/asakusafw-examples-${ASAKUSAFW_VERSION}/example-directio-hive/
まず、先のサンプルアプリケーションのビルド手順と同様にビルドの設定( build.gradle , gradle.properties ) を修正します。 修正箇所は先の手順と同じなので、そちらを参照してください。
build.gradle と gradle.properties の設定を変更したらアプリケーションをビルドして、 $ASAKUSA_HOME に実行環境をインストールします。
./gradlew assemble installAsakusafw
テーブル定義用DDLの生成と登録
データモデルの定義から、Hiveのテーブル定義用のDDLを作成することができます。
./gradlew generateHiveDDL --location /user/sakura/target/testing/directio/tables
生成したDDLをHiveのテーブルとして登録します。
>hive -f build/hive-ddl/example-directio-hive.sql
データの配置
先のサンプルプロジェクトと同様に、 src/test/example-dataset ディレクトリに入力データのサンプルが用意されているので、 これをHDFSに配置します。
hadoop fs -put src/test/example-dataset/tables target/testing/directio
入力データの確認
バッチを実行する前に、今配置したテーブルデータをHive、Spark SQLから見てみましょう。
まずはHiveから試してみます。Hiveのインタラクティブシェルを起動します。
hive
Hiveに対してクエリーを発行してみます。
>hive> select * from sales_detail
インタラクティブシェルから抜ける時は exit; と入力します。
hive> exit;
次に、Spark SQLでもテーブルデータを見てみます。 こちらは前回のSpark編で構築したThrift JDBC/ODBC Server(Thriftサーバ)経由でアクセスしてみましょう。
前回と同様、ThriftサーバにJDBCクライアントCLI「Beeline」で接続します。 なお環境によっては日本語を正しく表示するために LANG 環境変数などを設定する必要があります。
LANG=ja_JP.utf8 ~/spark/bin/beeline -u jdbc:hive2://hdp-node1:10001 -n sakura
Spark SQLに対してクエリーを発行してみます。
jdbc:hive2://hdp-node1:10001> select * from sales_detail
アプリケーションの実行
Direct I/O Hiveを使うバッチアプリケーションでも、バッチの実行環境にはMapReduce、Sparkのどちらも利用できます。 ここではSpark上でバッチアプリケーションを実行します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh spark.example.summarizeSales
結果の確認
バッチアプリケーションが生成したテーブルデータは直接HiveやSpark SQLのクエリーで参照することができます。 以下はSpark SQLを使ってテーブルデータを参照する例です。
jdbc:hive2://hdp-node1:10001> select * from category_summary; jdbc:hive2://hdp-node1:10001> select * from error_record;
Asakusa FrameworkとSQL on Hadoopの連携についてイメージできたでしょうか。 今回のように、ThriftサーバなどのJDBC/ODBCサーバ経由でデータを参照することで JDBCやODBCに対応したBIツールやアプリケーションとも連携できるようになるため、応用範囲は広いと思います。
なお今回はAsakusa Frameworkのバッチアプリケーションの開発方法までは紹介できませんでしたので、 Direct I/O Hiveを使ったアプリケーションの開発や環境構築については、Asakusa Frameworkの以下のドキュメントなどを参照してください。
おわりに
HadoopクラスタにAsakusa Frameworkをセットアップして、基本的なバッチアプリケーションの実行やHive,Spark SQLなどのクエリーエンジンとの連携について紹介しました。 今回紹介した機能以外にも、Asakusa Frameworkは様々な機能を提供しているので、興味のある方は是非使ってみてください。
さて、今回でこの連載は終了です。 分散処理環境の構築という少し馴染みのないテーマだったかもしれませんが、この連載を読んで少しでも興味を持っていただければ幸いです。
なお、さくらのナレッジには先日開催の「さくらの夕べ」で紹介された、SparkやAsakusa Frameworkを使ったさくらインターネットさんの分散処理環境の活用事例 「第26回 さくらの夕べ in東京 ~さくらで作る大規模分散処理環境~」 のレポート記事が公開されていますので、こちらも是非ご覧ください。