いかにして我々は7/19の史上最大規模の障害から復旧したのか

こんにちは。さくらのナレッジ編集部の安永です。
2025年1月22日(水)-24日(金)の3日間、京都市勧業館みやこめっせにてJANOG55ミーティングが開催されました。そこで実施されたセッションの中から、1月23日(木)に行われた「いかにして我々は7/19の史上最大規模の障害から復旧したのか」の模様をレポートします。発表者は、ビットスター株式会社 小岩秀和さんです。

目次
はじめに
2024年7月19日、世界中でWindowsサーバーを中心とした大規模なシステム障害が発生しました。この障害は、クラウドストライクというEDR(Endpoint Detection and Response)ソフトウェアに起因するもので、航空会社や小売業など、多くの業界に影響を及ぼしました。本記事では、この障害への対応プロセスと、そこから得られた学びを解説します。
前提条件
ビットスターが管理するシステムは、小売業向けの基幹システムでさくらインターネットのさくらのクラウド上で稼働しています。ほぼ全てがwindows serverで構成されており、拠点から既設の広域イーサのサービスでさくらインターネットのハウジングラックに入り、ハブハイブリッド接続サービスでクラウドサーバに接続しています。さくらのクラウドは国産パブリッククラウドとして東京と石狩にリージョンをもち、IaaSを中心としたサービスを提供しています。特に、サーバへのコンソールアクセスが可能な点が特徴で、これが後の復旧作業で重要な役割を果たします。

障害の概要と発生状況
7月19日14時30分頃、ビットスターの運用するシステムで異常が検知されました。slack上にZabbixから複数台のサーバにリーチャビリティがないというアラートが次々と発報しました。複数台から同時にアラームが発報している状況から、何が発生しているかわからない状態でした。
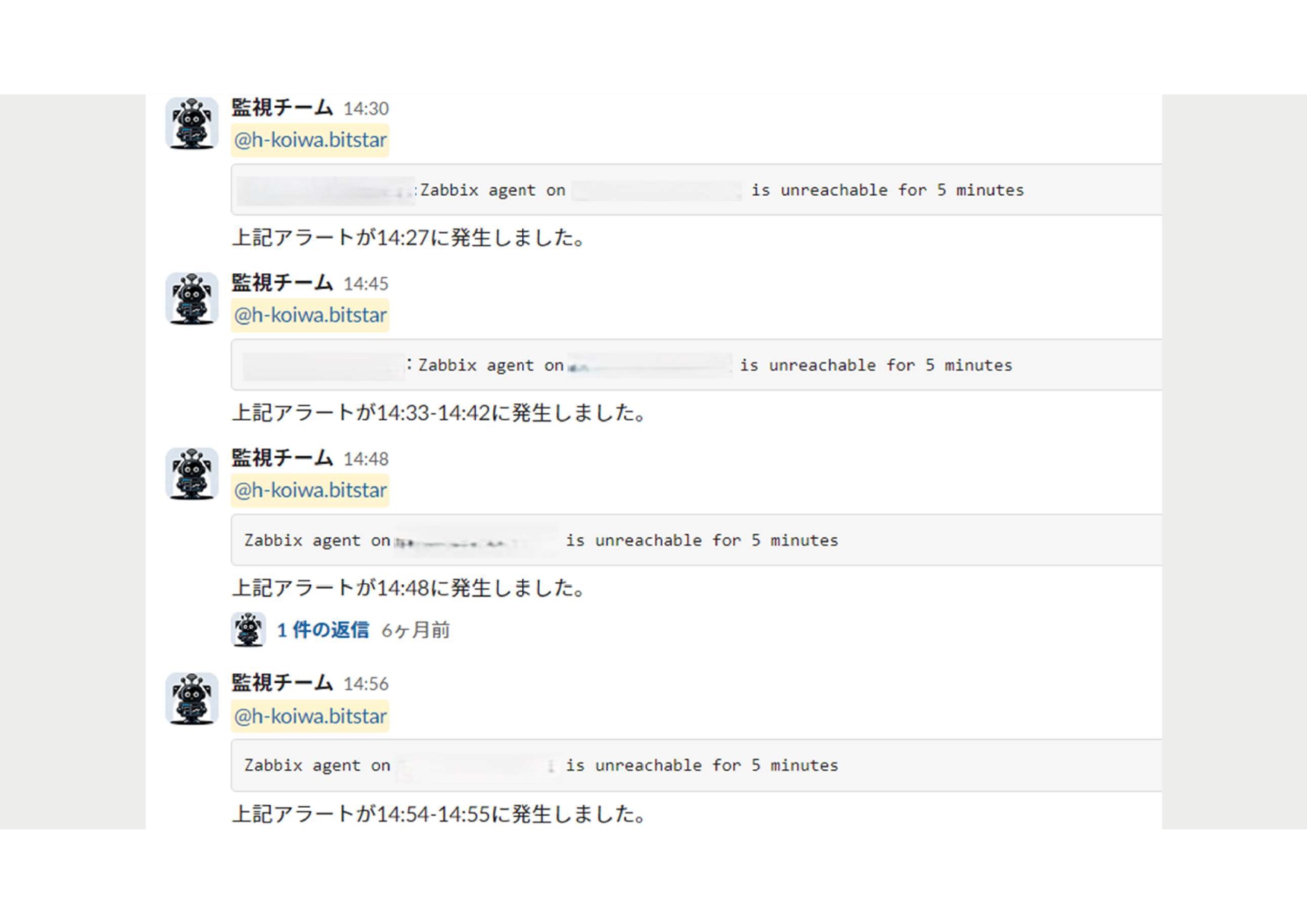
そこで、1台のサーバのコンソールにアクセスしてみると、サーバが再起動しセーフモードで起動を繰り返し、通常の起動ができない状態が続いていました。複数台のサーバで同様の事象が発生しているため、この時点では原因が不明で、クラウド基盤の障害情報も確認しましたが、特に異常は報告されていませんでした。状況が混沌とする中、お客様から「クラウドストライクが原因でワールドワイドでの障害が発生している」との情報が寄せられ、事態の深刻さが明らかになりました。
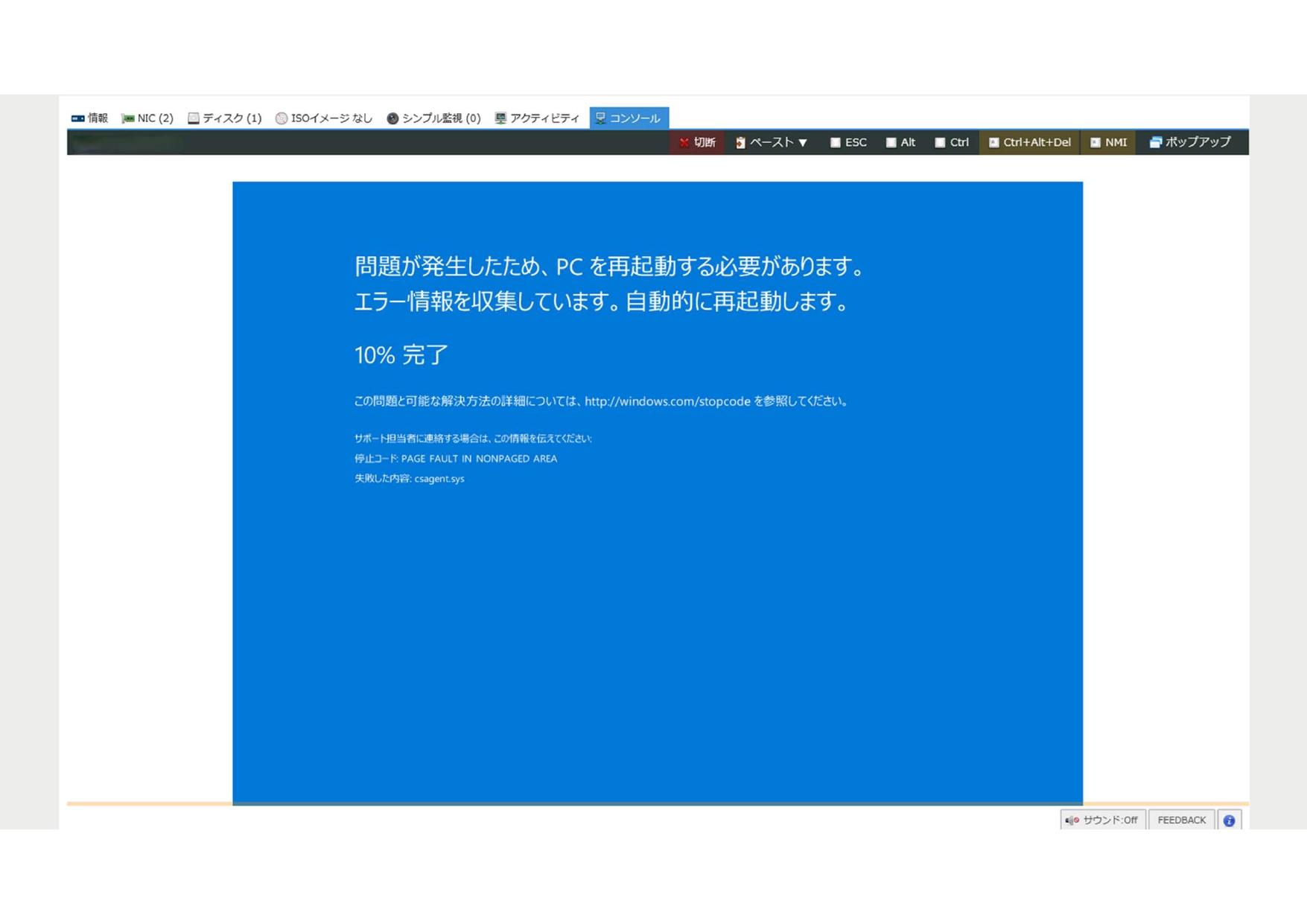

しかし、ビットスターはクラウドストライクについての情報を持ち合わせていませんでした。保守範囲はネットワーク、OSやクラウドの基幹部分であり、ミドルウェアについては保守範囲外だったからです。アンチウィルスのシステムの入れ替えについて話を聞いた記憶はあったけれど、入れ替え作業もお客様で実施したため、タッチしたことのない部分でした。
復旧への道のり
原因特定と初期対応
障害発生後、まず状況把握に奔走しました。X(旧Twitter)で「クラウドストライク」を検索したところ、関連情報が徐々に集まり始め、EDRソフトウェアの不具合が原因であることが判明しました。しかし、当初は具体的な復旧方法がわからず、Redditやニュースサイトで「特定のファイルを削除すれば直るかもしれない」という情報が飛び交う中、慎重な対応が求められました。
やがて、クラウドストライクから公式アナウンスが発表されました。内容は「セーフモードで起動し、特定のファイルを削除後、再起動することで復旧可能」というものでした。これを受け、復旧作業が本格化します。
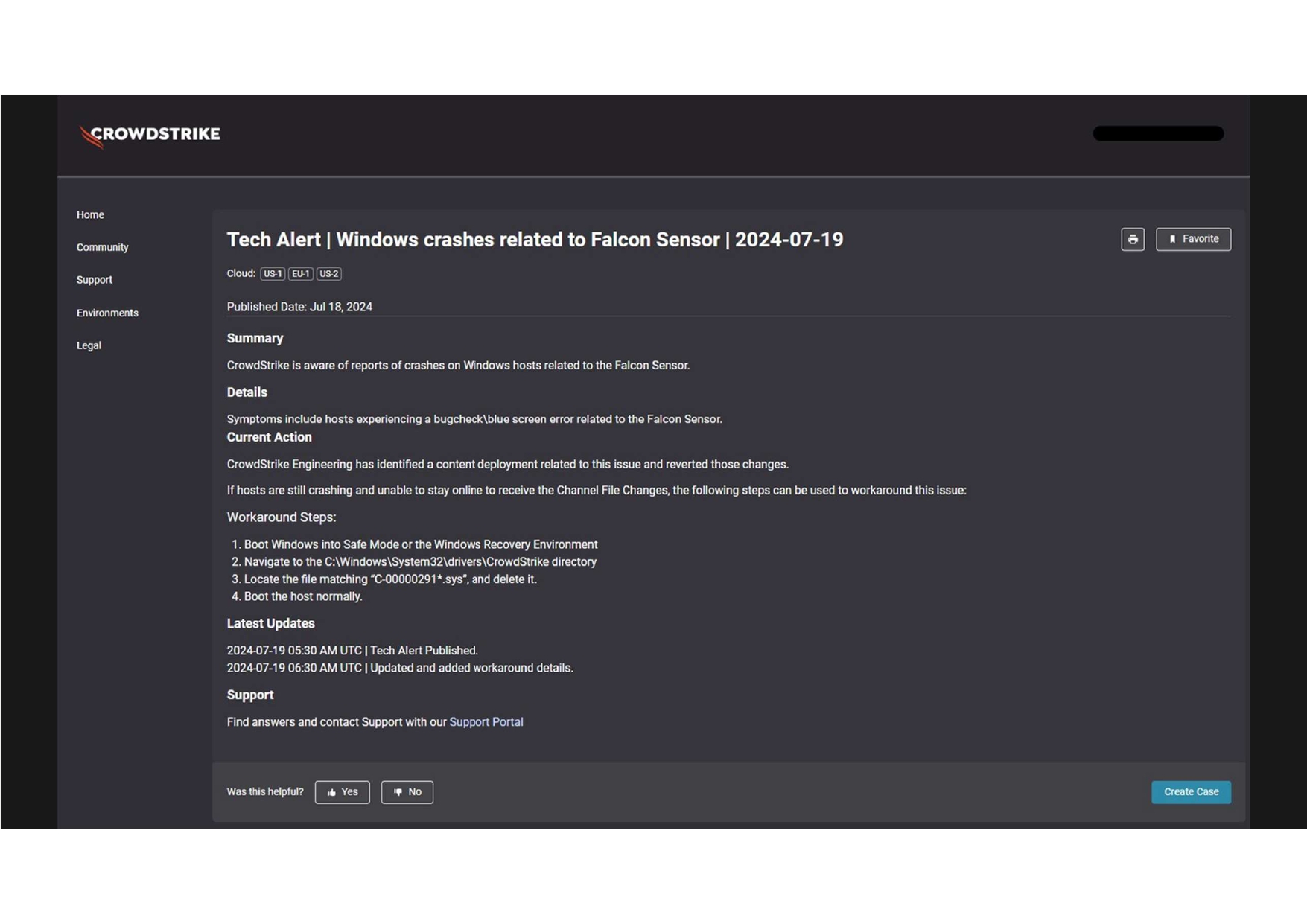
サーバーの状態と対応策
ビットスターが管理するサーバーは、障害発生時点で2つの状態に分かれていました。
- セーフモードでログイン可能なサーバー: コンソールからログインでき、操作が可能な状態。
- 再起動ループに陥ったサーバー: コンソールアクセスが取れず、操作不能な状態。
1の場合の復旧は比較的シンプルでした。クラウドストライクの指示に従い、セーフモードでログインし、問題のファイルを削除後、再起動を実施。結果、正常に復旧しました。
一方で、2の場合の再起動ループに陥ったサーバーは難易度が高く、コンソールが取れないため直接操作ができませんでした。そこで、他の仮想マシンでディスクをマウントし、ファイルを削除するアプローチを試みました。最初にLinuxで障害サーバのディスクをマウントしたところ、ディスク自体は認識できたものの、C:¥windows以下が見えず、アクセスできない問題が発生しました。BitLocker暗号化が原因ではないかと疑いましたが、パスワードが要求されないことから別のセキュリティ機能が影響していると推測されました。しかし、時間的制約からこの方法を断念し、別の方法を模索します。
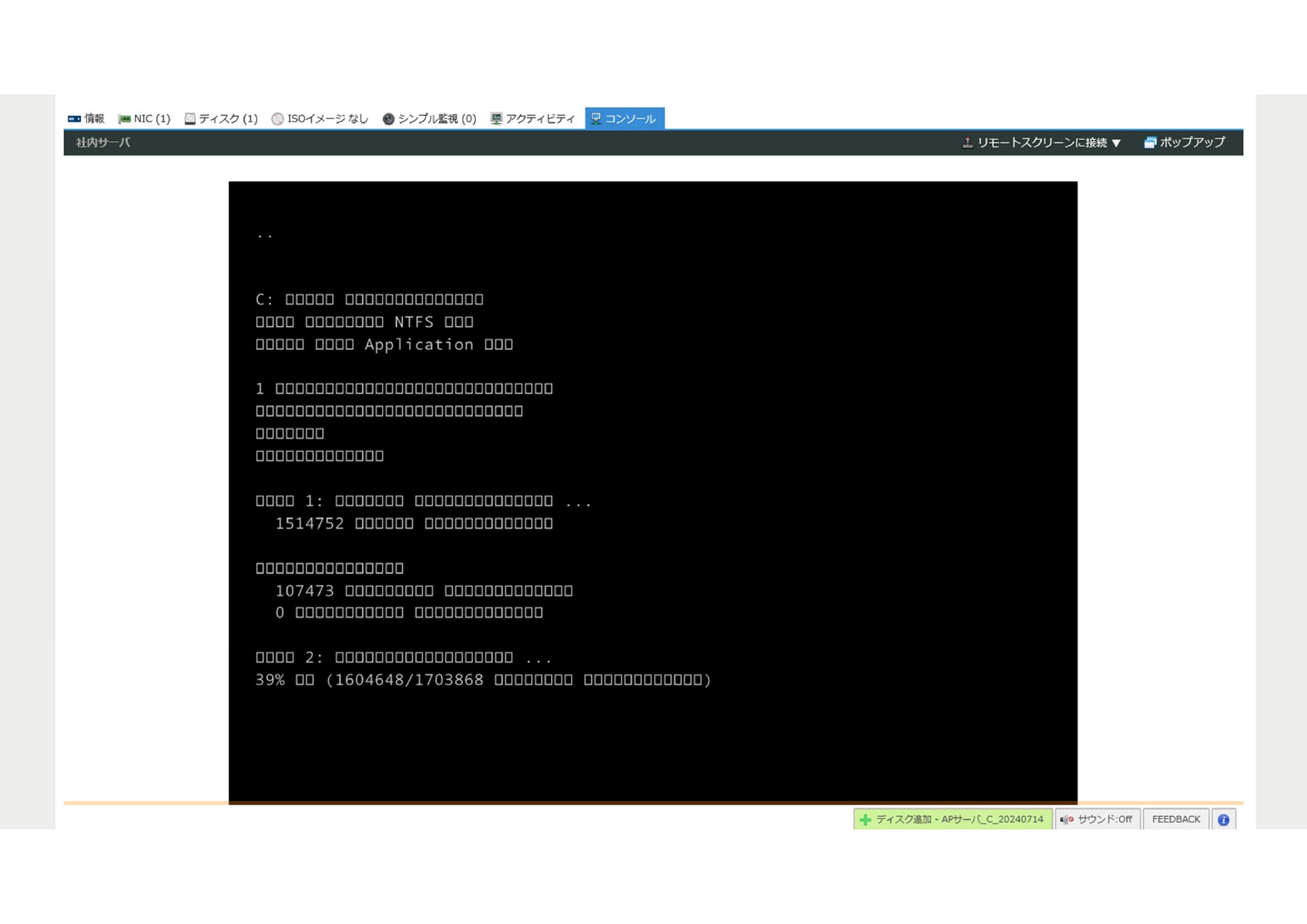
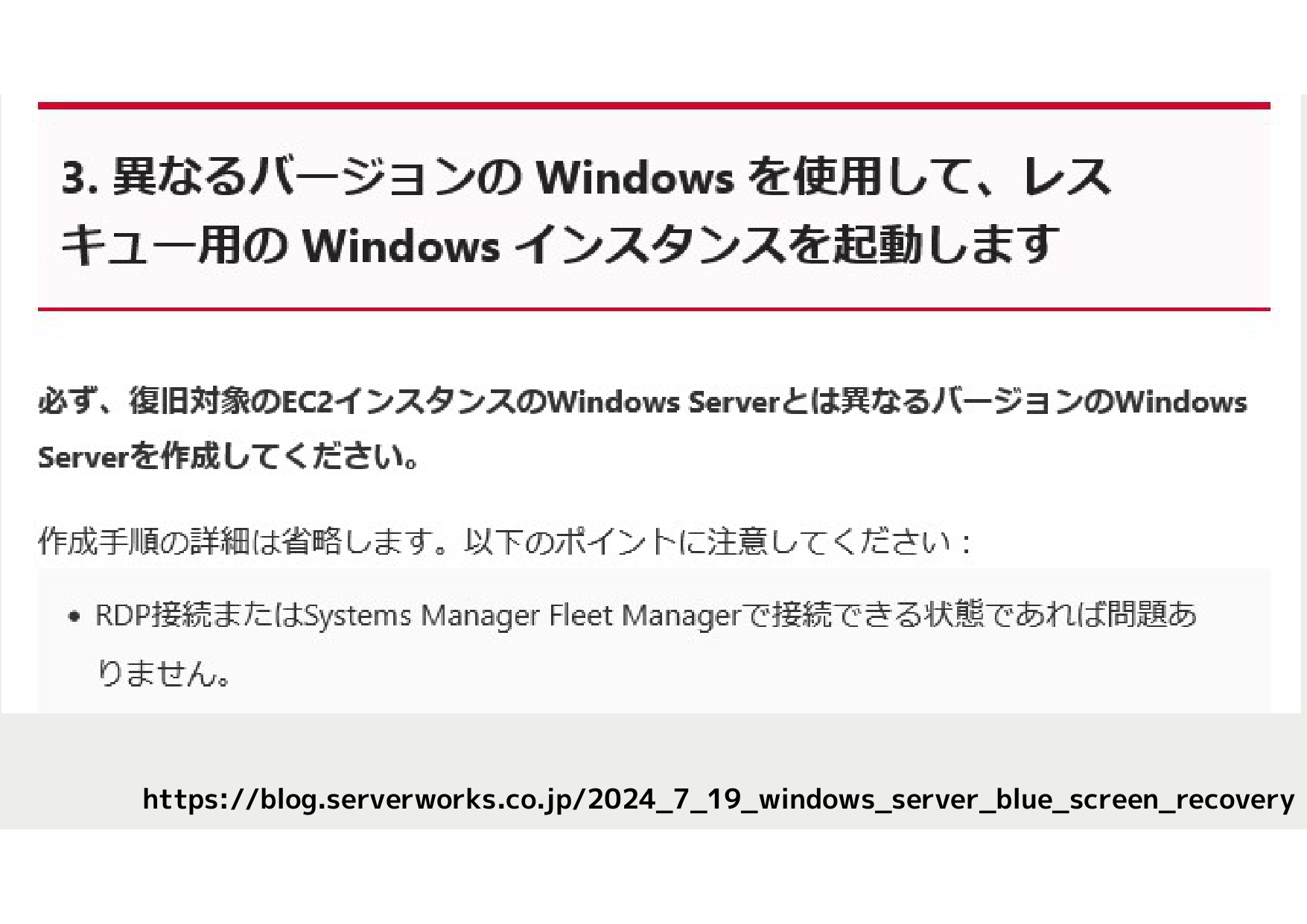
次に、セーフモードで起動可能な別のWindowsサーバーを利用し、問題のディスクをマウントしました。すると、C:¥windows配下が正常に表示され、指定されたファイルを削除することができました。しかし、ここで予期せぬトラブルが発生。ディスクを元のサーバーに戻し起動したところ、システムが完全に起動不能に陥ってしまいました。
後日、サーバーワークスのブログで「異なるバージョンのWindows Serverを作成する」との記載を発見し、これが原因と考えられました。おそらく、証明書やシステムファイルの整合性に関連する問題が影響し、システムが起動不能に陥ったのでしょう。
自然復旧と最終結果
興味深いことに、3台のサーバーは何の操作もせず自然に復旧しました。原因は不明で、クラウドストライクのアップデートが適用された可能性や、障害の影響を受けなかった可能性が考えられます。また、セーフモードでのリカバリー5台、バックアップからのリストアで2台が復旧し、計10台のサーバが復旧しました。
障害から得た学び
この障害対応を通じて、小岩さんは2つの大きな気づきを得ました。
1. バックアップ戦略の見直し
従来、オンプレミス環境ではストレージが潤沢で、バックアップは全サーバを対象に簡単に取得できました。バックアップ容量がコストに直結しないため、安易なバックアップ戦略を立てていたのです。しかし、パブリッククラウド環境ではバックアップの頻度や容量がコストに直結するため、最適化が求められるようになりました。例えば、多重化システムにおいて、マスター・スレーブ構成ではスレーブをバックアップ対象から外します。また、1点障害のみを考慮し、ドメインコントローラーが2台ある場合、1台が生き残ればリカバリ可能と判断してバックアップを省略したりするケースが増えました。しかし、今回の障害では全てのサーバーが同時にダウンする想定外の事態が発生し、これまでの戦略では対応しきれないことが露呈しました。バックアップ設計を見直し、全サーバーが同時に落ちる障害を考慮する必要性が浮かび上がりました。
2. 隠蔽化された技術との向き合い方
クラウドやサーバレス環境の普及により、インフラの低レイヤ知識が隠蔽化され、普段は意識されなくなっています。アプリケーション開発やサービス設計に集中できる一方で、今回のように低レイヤの技術が必要となる障害が発生すると、対応が難しくなります。若手エンジニアにはこうした隠蔽化された技術に触れる機会が減り、シニアエンジニアから知識を伝える場も減少しています。このジレンマに対し、「普段使わないが、いざという時に必要な技術をどう学ぶか」が課題として浮上しました。
議論と参加者の声
登壇後、参加者からの質疑応答が活発に行われました。質疑応答の模様を一部ご紹介します。
質問者:ベテランが死蔵しているスタックを引き出すにはどうしたらいいか。
小岩さん:机上で話すことはできるが、実践経験とは別である。実践を積む一例として、カンファレンスのNOCチームでの活動をすることでネットワーク部分がわかりやすくなるのではないかと思う。
質問者:バックアップからリカバリした理由は何か。
小岩さん:WindowsOSでマウントすればアクセスできると想定していたが、新規でWindowsOSを立てると時間がかかる。手元にはセーフモードで立ち上がったサーバがあるので、それを使おうと考えた。
質問者:実際に知識を与えるのではなく調べ方が覚えられるような状態が欲しい。
小岩さん:パブリッククラウドが流行る前は、特定の本を持っていれば良かったが、今はそのような状況ではない。情報が増え、調べやすくなった分、学習方法含めやり方を考えなければならない。
まとめと今後の展望
7月19日のクラウドストライクの大規模障害は、安定したITインフラへの依存度の高さと、隠蔽化された技術スタックの脆さを浮き彫りにしました。ビットスターの対応プロセスは、迅速な原因特定と柔軟な復旧策を模索する姿勢を示しつつ、バックアップ戦略や技術教育の課題を明らかにしました。今後、クラウド環境での障害に備えるには、コスト効率とリスク対策のバランスを見極めたバックアップ設計や、低レイヤ知識など隠蔽された技術を次世代に伝える仕組みづくりが不可欠です。
本内容は、JANOG55の参加者アンケートの中で、非常に満足、満足との回答が79%を超えていました。聴講、アンケートにご回答いただいたみなさま、ありがとうございました。アーカイブ動画は2025年7月下旬までの期間限定公開となります。公開中にぜひご覧ください。
登壇資料はこちら