ニューラルかな漢字変換システム「Zenzai」の開発


こんにちは、東京大学の三輪敬太です。
私は2024年度に未踏IT人材発掘・育成事業として「ニューラル言語モデルによる個人最適な日本語入力システムの開発」というテーマで採択され、早稲田大学の高橋直希さんとともにmacOS上の日本語入力システムを作りました。今回はこの中でも中心的な開発テーマの1つであった「ニューラルかな漢字変換システム」の開発と、その成果について紹介します。
かな漢字変換とは?
日本語は通常、漢字やひらがな、カタカナ、数字、アルファベットなど、何千種類もの文字を使い分けて表記されます。これをわずか高々100個強のキーしかないキーボードで入力するために重要になるのが、日本語入力システムによる支援です。
多くの皆さんが使っている日本語入力システムでは、ローマ字を介してひらがなを入力し、それを変換して漢字かな交じり文とします。このひらがなによる入力から漢字かな交じり文を作る部分で行われるのが「かな漢字変換」と呼ばれる処理です。例えば「わたしのなまえはみわです。」と入力したら、「私の名前は三輪です。」と変換されます。
かな漢字変換の中でも特に難しいのが同音異義語の処理です。例えば「かいじょう」というひらがなに対してありえる変換候補は「会場」「海上」「開場」「解錠」などたくさんあり、かな漢字変換システムはこれらを状況に応じて変換し分けることが求められます。
従来の手法
かな漢字変換は「ユーザの端末で動かす」ことが基本とされ、サーバサイド処理の活用はあまり主流ではありません。これは機密情報をも入力し得る日本語入力システムというソフトウェアの性質上プライバシーの担保が求められること、また、ユーザ操作に対する即時応答が求められるため、通信によるオーバーヘッドが許容しづらいことに由来するものです。
そこで、ユーザの端末のみで高速に動かせることを要件とすると、どうしても高級な処理は行いにくくなります。最も有名な日本語入力システムの1つであるGoogle日本語入力(Mozc)では、高速な動作のため、変換において考慮する情報を極力減らして処理を行っています。具体的には、原則として直前1単語分の文脈のみを考慮して次の単語の変換を最適化します。このため、同音異義語などの処理には様々な限界があります。
ニューラルかな漢字変換
一方、Google日本語入力のリリースからは既に15年近く経ち、標準的な端末スペックはどんどん向上してきました。そろそろ、もう少し大きな計算リソースを前提にしたシステムを構築しても大丈夫ではないでしょうか。
そこで目をつけたのが「ニューラルかな漢字変換」と呼べる手法です。従来のかな漢字変換機は「統計的かな漢字変換」という仕組みに基づいたもので、単語と読みの情報を記録した辞書や、「どの単語がよく出てくるのか」といった頻度の情報、さらには「名詞のあとには助詞が来やすい」というような品詞のつながりの頻度の情報を組み合わせて変換候補として正しそうなものを選択します。一方、ニューラルかな漢字変換においてはこれらの情報を単一のニューラルネットワークのパラメータとして暗黙に表現し、エンドツーエンドでモデリングします。機械翻訳の世界ではすでに「統計的機械翻訳」から「ニューラル機械翻訳」への移行が起こりましたが、これに対応するのがニューラルかな漢字変換だということもできます。
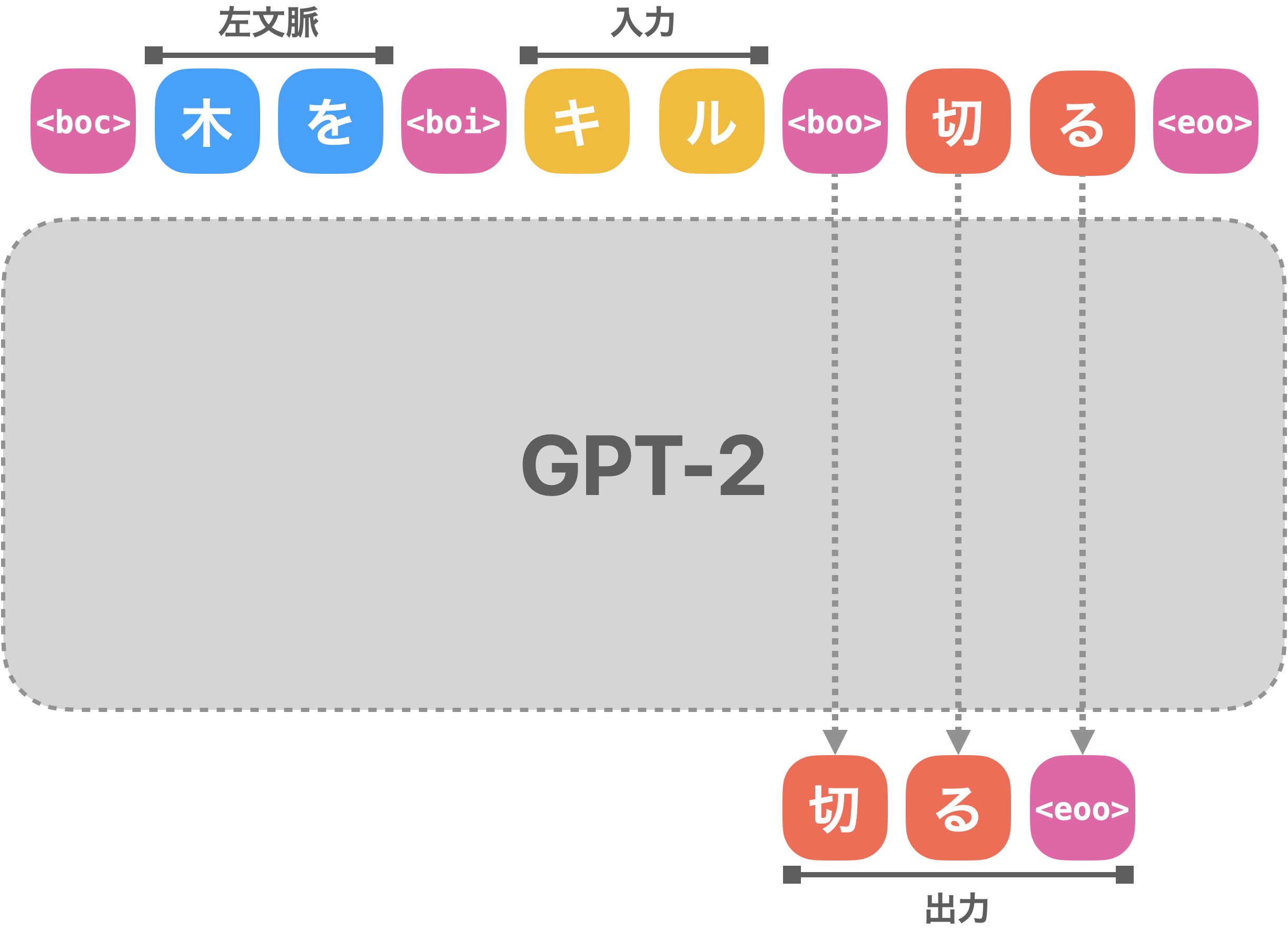
ニューラルかな漢字変換はニューラルネットワークを利用する都合上、重くて低速になりがちです。ユーザの端末のみで動かそうとすると、最近のLLMのようなモデルを動かすのはもちろん無理があります。しかし、そこそこのサイズのモデルをGPUで処理し、アルゴリズム的な最適化を行えば、実用に耐える速度を出せるのでは、と考え、この仕組みの採用を決めました。
実際のシステム開発
ニューラルかな漢字変換を実際に開発する上では、かな漢字変換を実際に解決するモデルと、そのモデルを利用する推論用コードが必要になります。残念ながらかな漢字変換用のモデルは世の中にないので、これをまずは作っていく必要がありました。
モデルのアーキテクチャにはGPT-2を選びました。これはChatGPTを作ったOpenAIが2019年に提案したモデルで、基本的な仕組みや構造は現代のLLMと大きく変わらず、無数の知見が蓄積されています。実際、今回の学習コードにはGPT-2に特化した学習ライブラリであるllm.cを利用できましたし、推論ランタイムとして用いたllama.cppでもGPT-2がサポートされています。
学習データには、オープンなコーパスに対して読み推定を行って作った1.9億文規模のデータセットを作って利用しました。こちらは誰でも使える形で公開しています。
モデル開発を進めるうえで重要だったのが計算資源です。もともとGPUインスタンスを外部で借りて利用していましたが、安価なインスタンスは遅く、1回の学習に何十時間もかかるために実験が回しづらいのが課題でした。今回はさくらインターネットの高火力 DOKを無償提供していただきました。高火力 DOKではDocker Imageを用いて環境を管理できるため、容易に再現性のある機械学習環境を構築することができます。
そこで、モデルサイズや学習率、バッチサイズなどのハイパーパラメータ、学習データなどを外部(管理ツール上のGUI)から指定して実行することで自動でモデルの学習を開始しクラウドストレージにチェックポイントをアップロードする実験環境を構築しました。高火力 DOKに搭載されているNVIDIA H100を使った環境では1回の学習が数時間で終わるため、学習→評価→改善のループを高速に回すことができました。
こうして、3種類のモデルサイズのzenz-v2.5シリーズを構築することができました。このモデルウェイトもHugging Faceで公開しています。また、zenz-v2.5-mediumはHugging Face Spaceでもお試しいただけます。
このモデルウェイトを用いて「Zenzai」というかな漢字変換システムを構築しました。既存のかな漢字変換システムを適切に置き換えるべく、従来の機能をなるべく維持しつつ高精度な変換ができるシステムを目指しました。
モデルの評価
かな漢字変換の評価は色々と難しいところがありますが、いち側面を捉える評価としてAJIMEE-Benchを構築しました。AJIMEE-Benchの主な観点は「間違って変換しやすい言葉の含まれるタスクでどれくらい正確に変換ができるか」というものです。具体的には「日本語Wikipedia入力誤りデータセット」に基づき、誤変換が実際に起きた文を用いて評価を行いました。
私たちの構築したZenzaiは正確性においてsmallサイズモデルで既存の製品に搭載された手法を大きく上回り、最新のLLMであるGPT-4.5を用いる手法と比べても遜色ない性能を叩き出しています。mediumサイズモデルは他の手法を大きく上回っています。
| 手法 | Acc@1 (正解率) | CER (文字誤り率) |
|---|---|---|
| Google Japanese Input | 54.0 | 6.7 |
| gpt-4o-mini-2024-07-18 | 19.0 | 21.8 |
| gpt-4o-2024-08-06 | 56.0 | 7.7 |
| gpt-4.5-preview-2025-02-27 | 80.5 | 2.8 |
| Zenzai (xsmall) | 66.5 | 4.6 |
| Zenzai (small) | 80.0 | 2.6 |
| Zenzai (medium) | 86.5 | 1.7 |
アプリケーション化
かな漢字変換は実用と強く結びついたタスクなので、モデルを作って終わりではなく実用まで持っていってこそです。未踏プロジェクトでは実際にmacOSで動作する日本語入力システムを構築し、ここにニューラルかな漢字変換モデルを搭載しました。M1以降のMacであればローカルのみで軽快にニューラルかな漢字変換を実行し、高精度な変換を利用することができます。実際に動作しているところを撮影した動画をご覧ください。
このアプリケーションは「azooKey on macOS」としてリリースしていて、誰でもお試しいただけます。今回ご紹介したニューラルかな漢字変換システムに加え、azooKey on macOSでは「個人最適化」「入力支援」といった面でも様々な試みを取り込んでいます。

未踏の成果報告会ではこのazooKey on macOSの諸機能の開発成果を紹介し、ニューラルかな漢字変換についても発表しました。様々な意見や質問をいただき楽しい場でした。
学会発表
上記のzenzモデルとZenzaiの開発内容をもとに、2025年3月10日〜14日に開催された言語処理学会第31回年次大会(NLP2025)に「ニューラルかな漢字変換システム Zenzai」という論文を投稿し、ポスター発表を行いました。
ポスター発表は朝早い時間でしたが、多くの人にお越しいただき、様々な議論ができました。また、年次大会における若手奨励賞(対象487件中20件)を受賞しました。

今後の展望
azooKey on macOSはすでに実用的な品質を実現していて、私自身この記事をazooKey on macOSを用いて執筆しています。一方、ニューラルベースの手法をいかに継続してメンテナンスしていくか、といったMLOps面にはまだまだ課題があり、このあたりを安定させていくことが長期の品質維持と持続的開発のため重要であると考えています。また、ユーザ辞書、履歴学習といった既存機能をより良く統合していく必要性も感じていて、このあたりを適切に改善していく取り組みを続けていきたいと考えています。
ニューラルかな漢字変換の分野には、研究段階・開発段階を問わず、いまだ多くの興味深い課題が残されています。この領域に取り組む技術者や研究者が今後さらに増えていくことを期待しています。