さくらのIaaS基盤のOSSの活用事例 - 内部利用のNFSサーバー -

この記事は2025年7月5日(土)に行われたオープンソースカンファレンス 2025 Hokkaidoにおける発表をさくナレ編集部で記事化したものです。
目次
はじめに
さくらのIaaS基盤におけるオープンソースの活用事例を紹介します。ここでは内部利用のNFSサーバーを題材に、そこで利用しているオープンソースソフトウェア(OSS)を紹介していきます。
自己紹介
さくらインターネットの滝澤です。2024年2月に入社して、現在はIaaS基盤開発チームに所属しています。ときどき雑誌に執筆していて、Software Design誌にDNSの記事や、rsyslog/journald、シェルスクリプトの記事を書いています。
さくらのIaaS基盤におけるOSSの活用
さくらのIaaS基盤ではさまざまなところでOSSを活用しています。社外に公表してるところで代表的なものとしては、ハイパーバイザーや仮想マシンでKVMやQEMUを使っています。
そして、今回紹介するのは内部で利用しているNFSサーバーです。主なミドルウェアとしては、高可用性(HA)クラスターとしてCorosyncとPacemaker、冗長化ストレージとしてDRBDが使われています。このあたりを含めて、利用しているOSSを紹介していきます。
内部利用のNFSサーバーについて
まず、内部利用のNFSサーバーはどこで使われているかを軽く説明します。
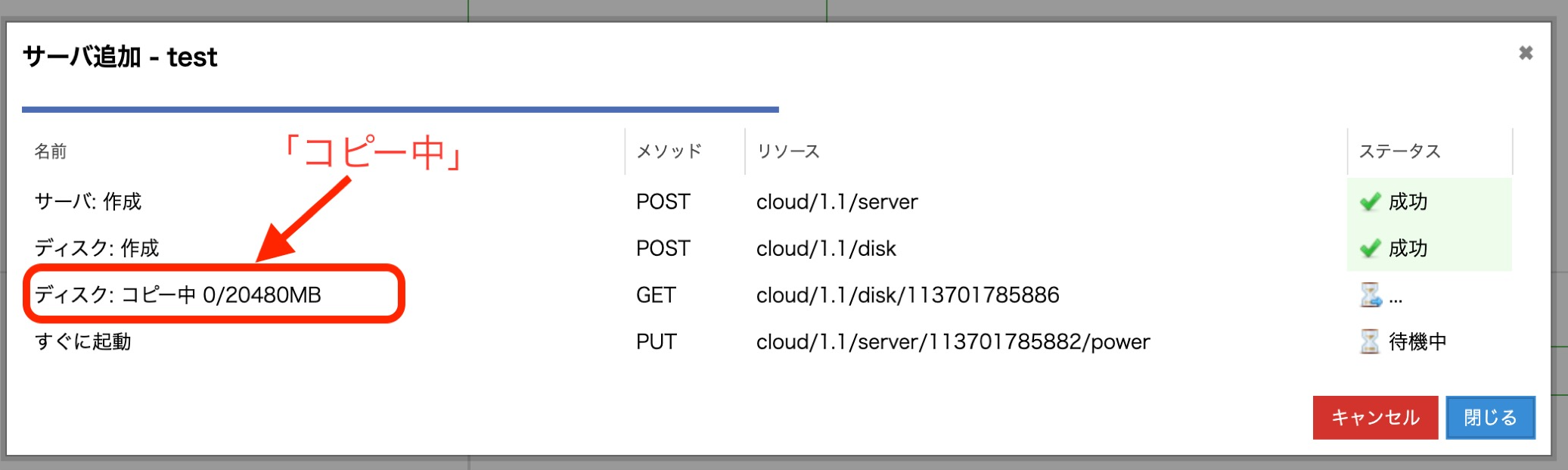
さくらのクラウドのコントロールパネルを使っている方は見たことがあると思いますが、サーバーを追加するとこのようなステータス画面が表示されます。サーバーを作成してディスクを作成して、ディスクをコピー中と表示されます。この「コピー中」の処理の中でNFSサーバーが使われています。
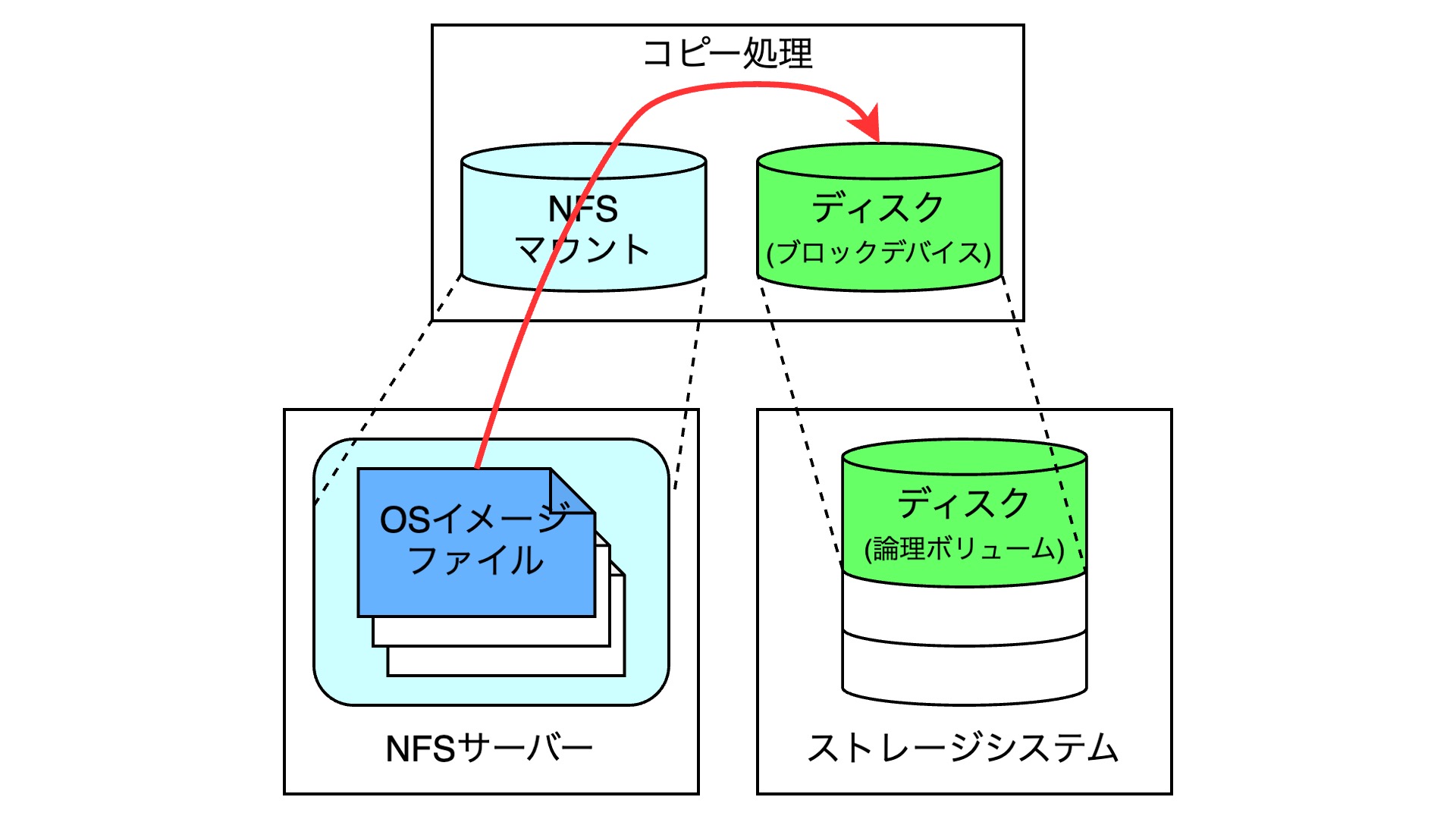
ここで何をしているかというと、NFSサーバーに格納されているOSのイメージファイルを、ストレージシステムから切り出されたディスクのブロックデバイスに対して書き込んでいます。皆さんがOSのイメージを指定してサーバーを作成すると、このコピー処理が行われることになります。
NFSサーバーの構成
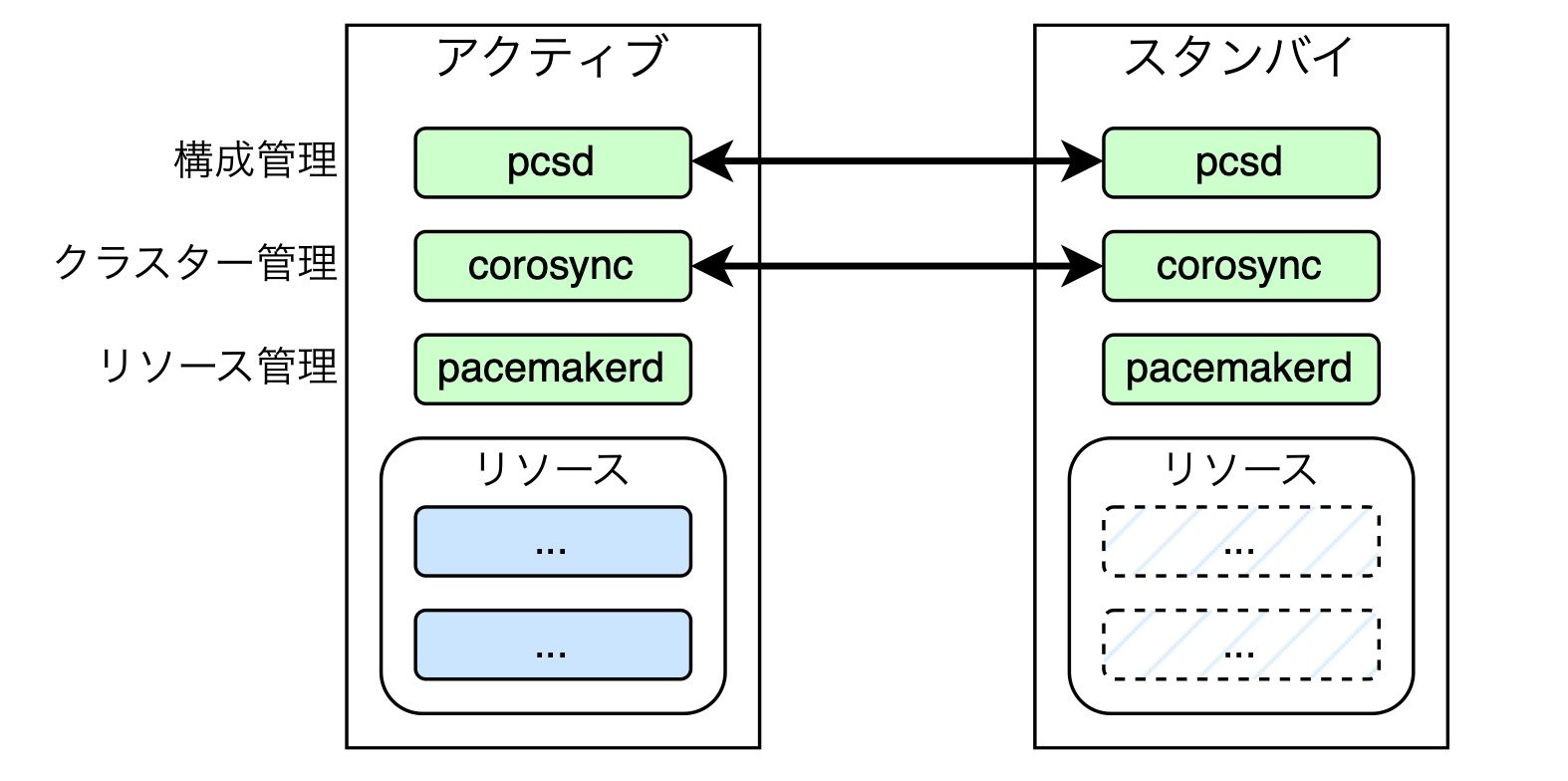
NFSサーバーの構成は、2ノードによるアクティブ/スタンバイ構成の高可用性クラスターになっています。上図で示すようにアクティブノードとスタンバイノードの2台で構成されます。そして、さまざまなソフトウェアを使ってリソースを制御します。ちなみにホストのOSはLinuxディストリビューションを使用しています。
高可用性クラスターのツール
高可用性クラスターのツールとしては、構成管理にPCS、クラスター管理にCorosync、リソース管理はPacemakerを使っています。
Corosyncはクラスター管理ツールですが、厳密には高可用性クラスターを構成するメンバーノードを管理するツールです。これは各ノード間の通信を行う役割を担っています。
Pacemakerは高可用性クラスターのリソースマネージャーです。各ノードで起動してリソースを制御します。具体的にはサービスの整合性などをチェックして、ダウンタイムを最小限に抑えることを目的としています。各ノード上で動作し、障害を検知すると再起動を試みたり、それでもダメならフェイルオーバーとか、そういったことを行います。また、フェンシングなどの機能も備えています。
PCSは、正式にはPacemaker/Corosync Configuration Systemという名前のものです。これはPacemakerおよびCorosyncの高可用性クラスターを構築・管理するための設定ツールです。pcsというCLIのツールがあり、それを使ってクラスターの作成や設定、監視、リソース管理などを行うことができます。また、pcsdというデーモンがあり、これによりリモート管理やWebインターフェースが提供されます。
NFSサーバーのリソースの構成
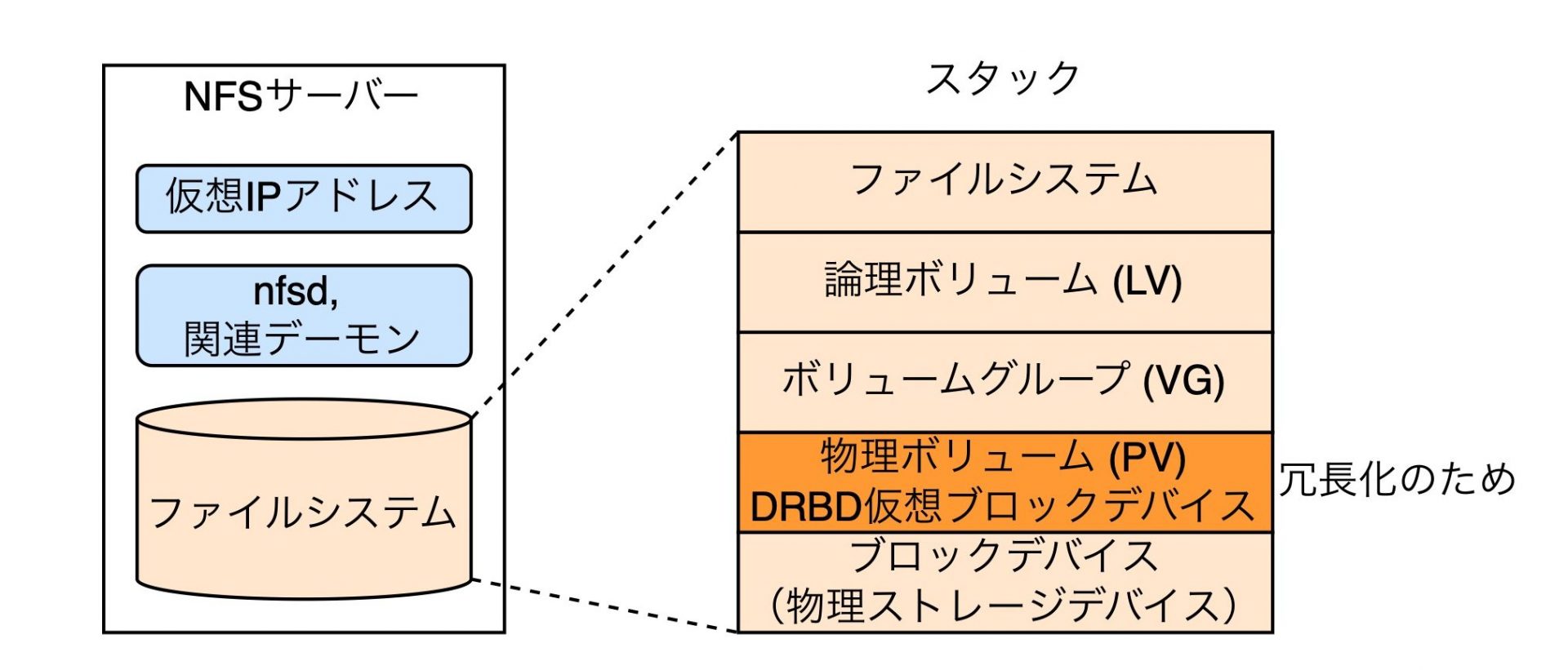
リソースの構成は上図のようになっています。NFSサーバーの中には、サービスを提供するための仮想IPアドレス、NFSサーバーなのでnfsdおよび関連するデーモン、それから提供する領域のファイルシステムがあります。
ファイルシステムスタックを下位層から順に説明します。まず物理ストレージデバイスがあります。ブロックデバイスですね。その上にDRBDを用いて仮想ブロックデバイスを設けています。これは冗長化のために設けています。そして、これを物理ボリューム(PV)としてボリュームグループ(VG)を作成し、その上に論理ボリューム(LV)を切り出してファイルシステムを作成し、NFSサーバのファイルシステムとして提供する形になっています。
DRBDについて
続いて、先ほど説明したDRBDの話をします。これは分散レプリケーション型のブロックストレージソフトウェアです。ひとことで言うと、ブロックデバイスをネットワーク経由でミラーリングするソフトウェアということになります。あとで必要になるので先にここで説明しますが、DRBDデバイスのロールとして、primaryとsecondaryというものがあります。primaryであるときのみデバイスを利用できます。secondaryのときは利用できません。そして、1つのノードだけがprimaryに昇格できます。このあたりのことは後ほど詳しく説明します。
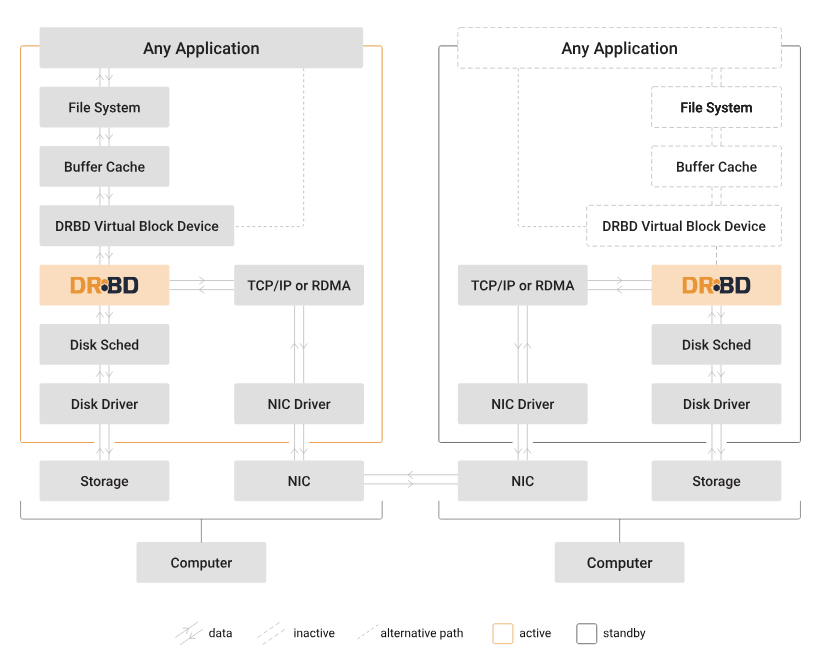
これがDRBDの公式サイトに掲載されているアーキテクチャです。左側がアクティブノード、つまりprimaryです。右側がsecondaryノードです。
primaryノードの最上部に「Any Application」と書いてありますが、これがアプリケーションです。その下にファイルシステムがあり、バッファキャッシュがあります。さらにその下にDRBDのバーチャルブロックデバイスがあります。
ここでアプリケーションがファイルシステムに書き込みをすると、ローカルのストレージに書き込みが行われますが、それと同時にTCP/IPやNICを経由してsecondaryノードのDRBDデバイスのディスクにも書き込みます。このようにすることでミラーリングを行っています。
リソースの制御
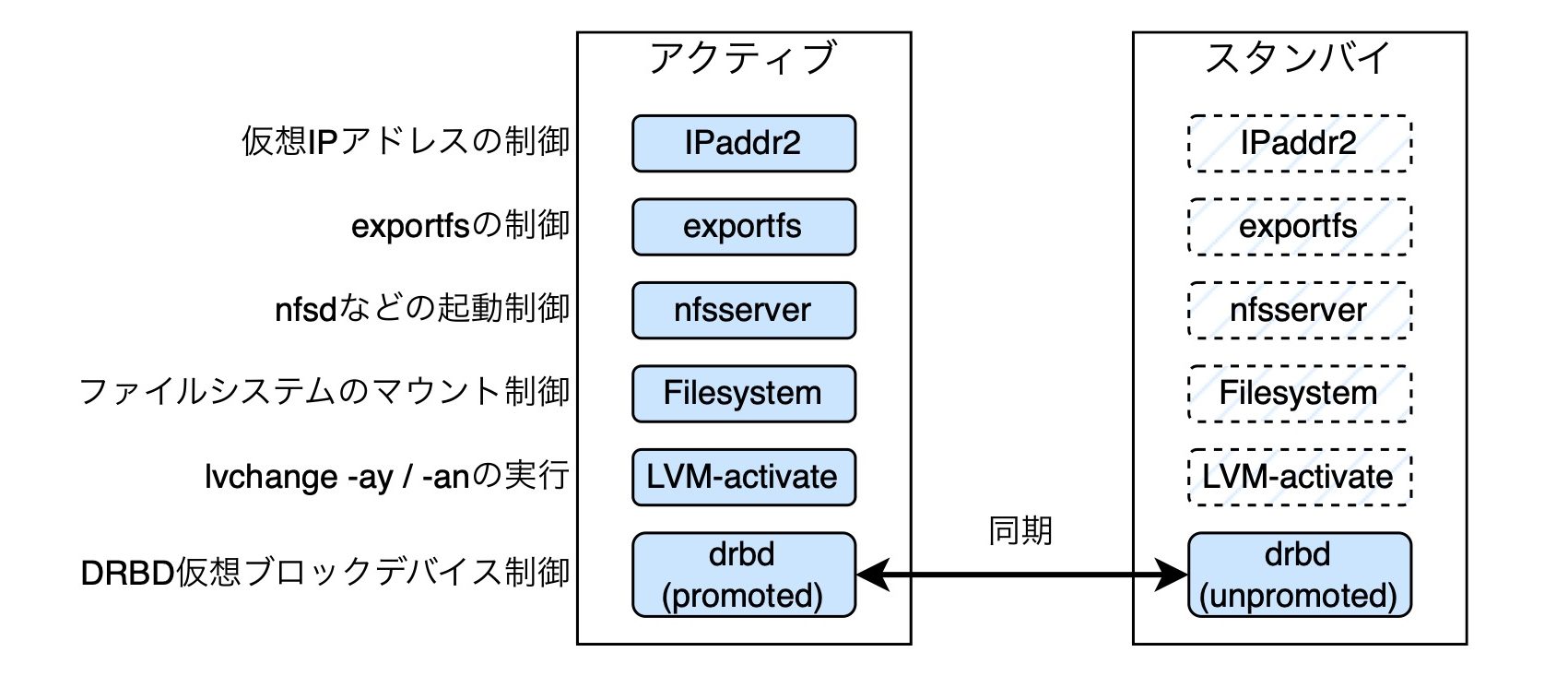
ここで、DRBDも含めたリソースを制御するためのツールとしてリソースエンジェント(Resource agents)というものがあります。例えば、仮想IPアドレスの制御にはIPaddr2というリソースエージェントを使っています。他にもさまざまなリソースエージェントを使ってリソースの制御をすることができます。これらのリソース制御は、リソースマネージャーであるPacemakerの管理下で動作します。
このResource agentsは、Pacemakerと同じ開発元であるClusterLabsで開発が行われています。中身はクラスター内のリソースを管理する実行可能なプログラム群で、各々が単体で実行するコマンドになっています。これを使うことで、多様なリソースの起動や停止、監視を行うことができます。
スプリットブレインを防ぐ
次の話題に移ります。
高可用性クラスターの運用において非常に重要な話として、スプリットブレインへの対応を考慮しなければなりません。スプリットブレインシンドロームとは何かと言うと、ノード間の通信が断絶し、それぞれのノードが独立して処理を継続してしまう状態を指します。「ブレイン」(brain)は「頭」で、それが複数あるということですね。これが生じると、データの不整合や破損、二重更新などの重大な障害につながるおそれがあります。特に2ノードの高可用性クラスターではスプリットブレインが生じるリスクが大きいです。これについて説明します。
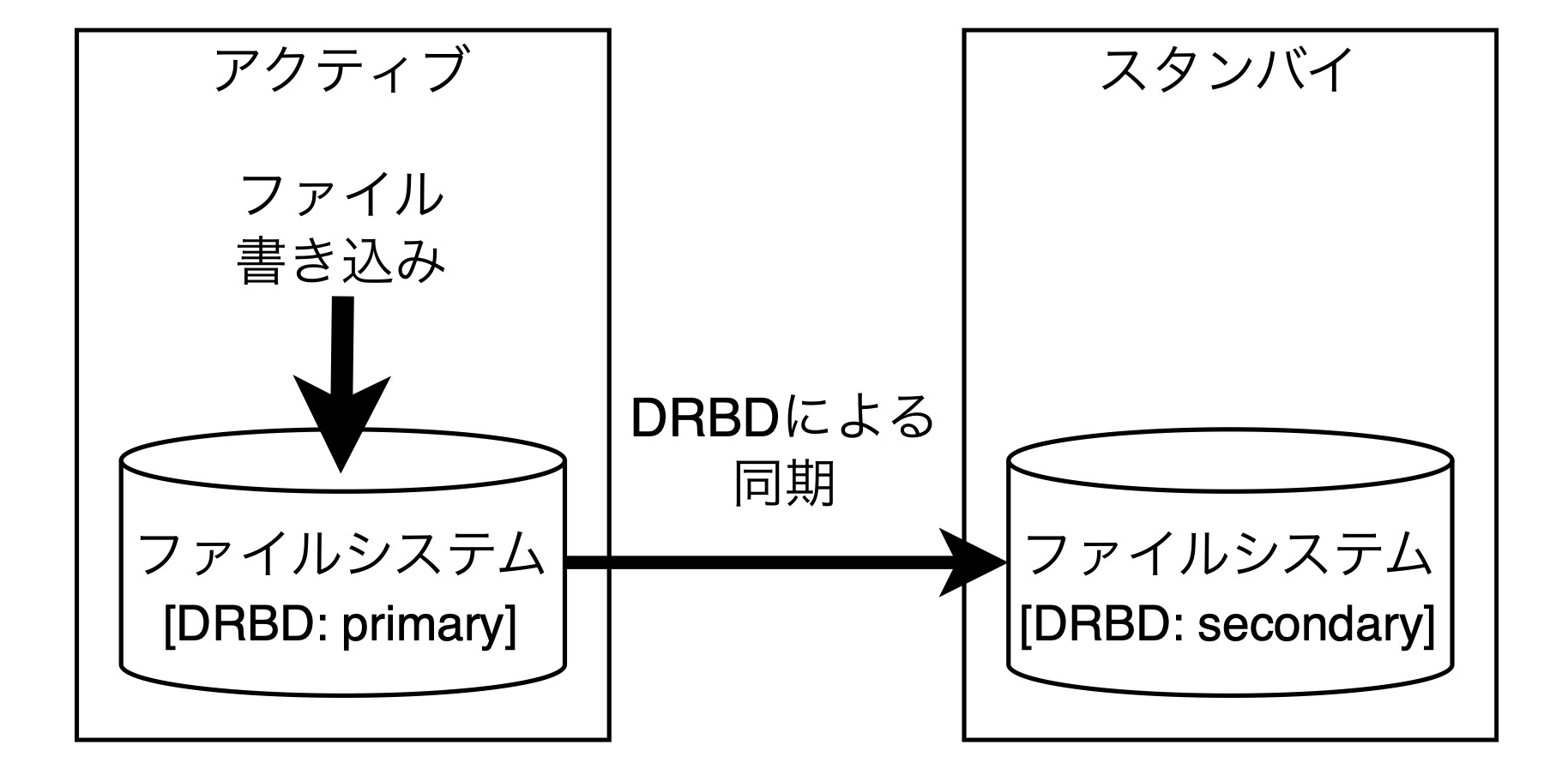
まず、上図のようにアクティブとスタンバイの構成のクラスターがあるとします。ここでアクティブのノードにファイルを書き込みます。するとDRBDによりスタンバイに同期されます。
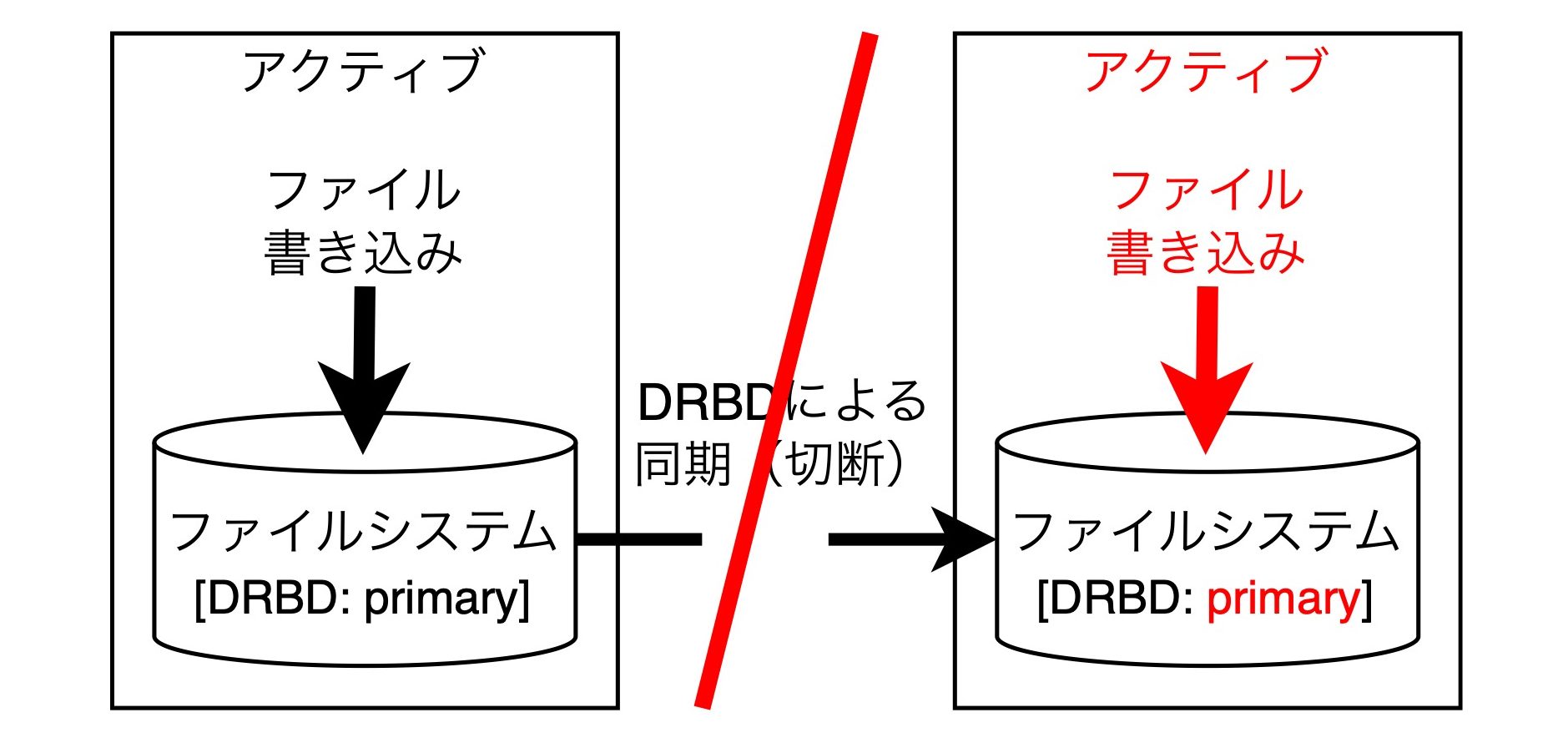
ここでネットワークが分断したとします。そうすると何が起きるかと言うと、スタンバイのノードはアクティブのノードがいなくなった(死んだ)という判断をして、自らアクティブに昇格します。アクティブに昇格するとファイルに書き込みを行います。この状態がスプリットブレインです。
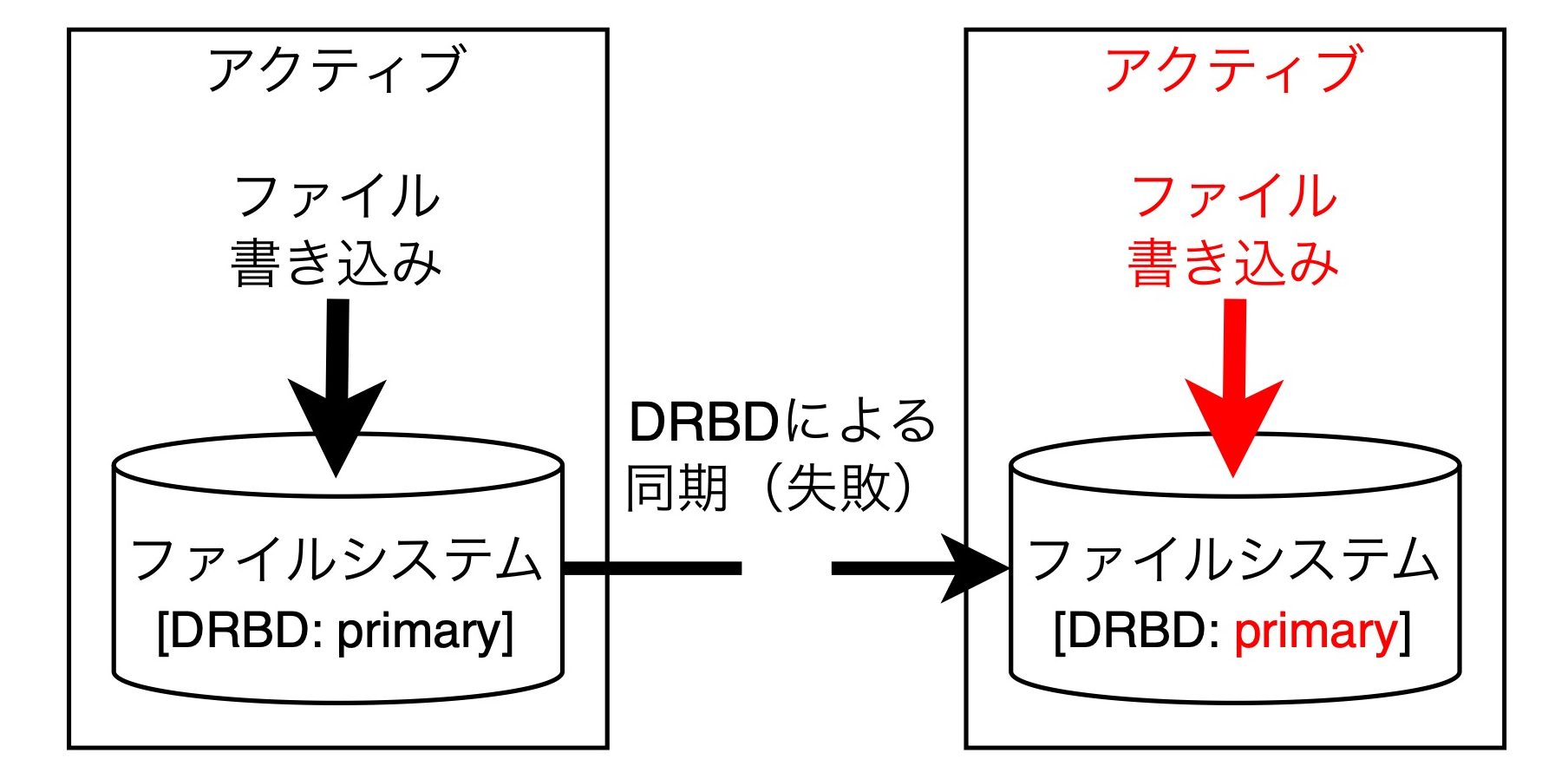
その後、ネットワークが復旧したとします。するとどうなるかというと、それぞれ独立してファイルシステムを更新しているので、ファイルシステムの不整合が発生します。そうするともう、このファイルシステムのデータはまともに扱うことができません。どちらかのノードをなかったことにしないと復旧できません。
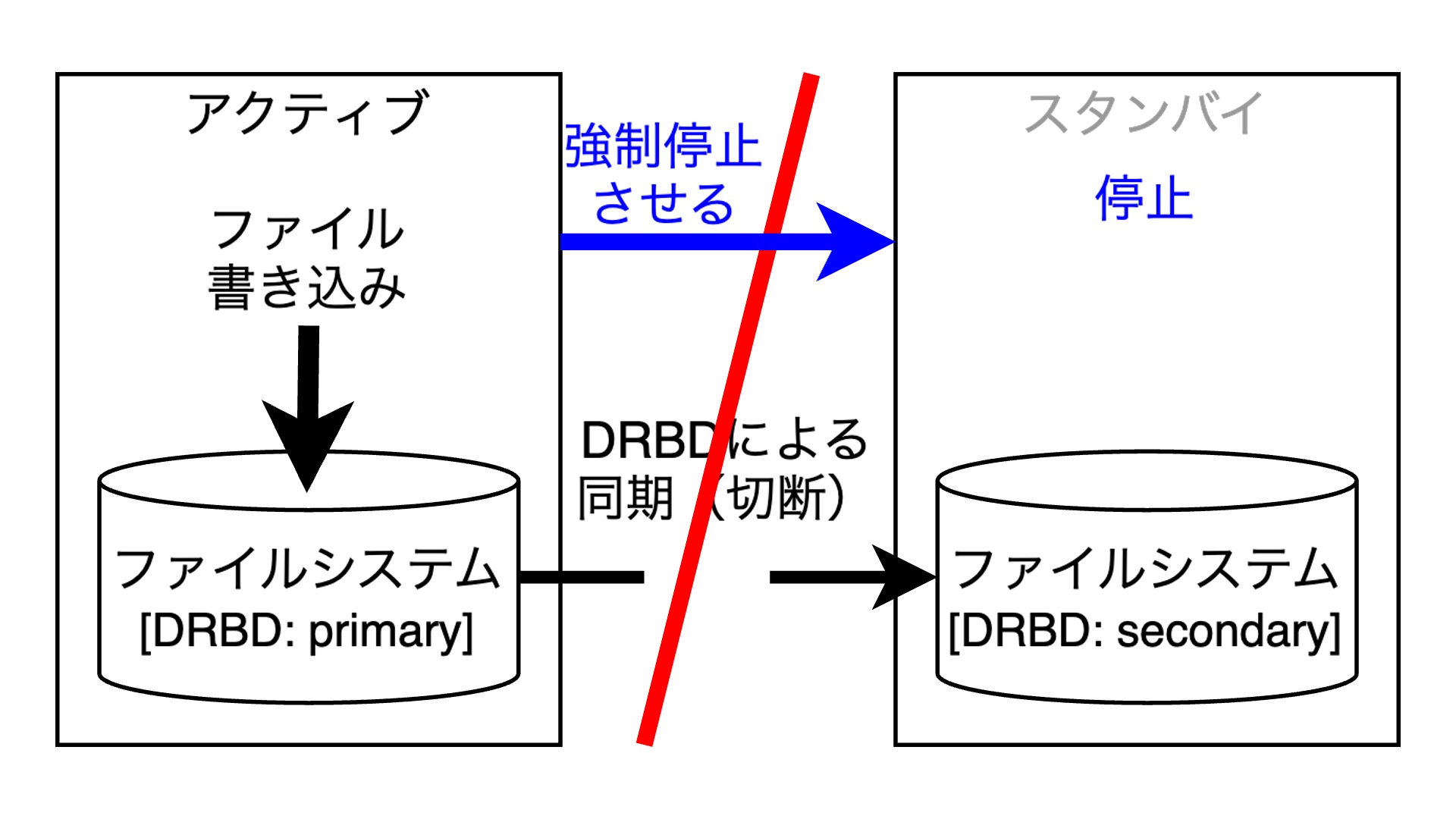
このようなスプリットブレインへの対策としては、障害が発生したノードをクラスターのリソース管理から強制的に隔離します。これをフェンシングと言います。例えば上の図においては、ネットワークの断絶が発生した時点で、アクティブノードがスタンバイノードを強制停止しています。これがフェンシングです。
Corosync/Pacemakerではフェンシング機能のことをSTONITHと呼びます。Shoot The Other Node In The Headの略です。上の絵では対向ノードがお互いに相手の頭にピストルを突きつけていますが、こういう状態です。
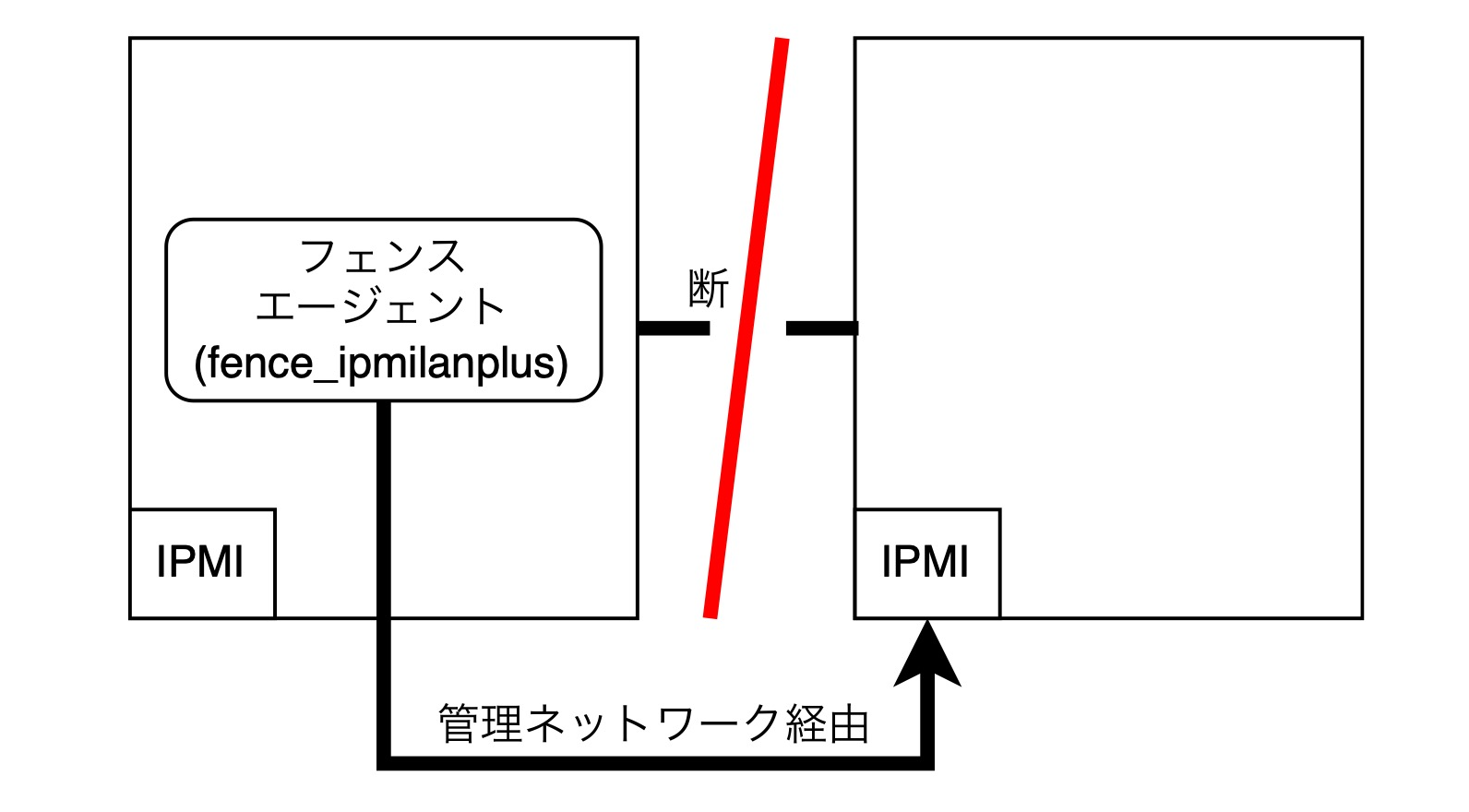
フェンシングの動作としては、物理ノードの場合は対向ノードのIPMIに接続し、電源のオン/オフを行います。ネットワーク断が発生したら、フェンスエージェントが管理ネットワークを経由してIPMIに接続し、電源のオフを行います。
ここでまたミドルウェアを紹介しますが、Fence agentsというものもあります。これはフェンシングを実行するエージェントで、共有ストレージ上のデータ破損を防ぐために開発されたデバイスドライバです。障害のあるコンピュータを隔離することで、他のシステムへの影響を最小限に抑えます。
まとめ
本発表では内部のNFSサーバーで高可用性クラスターを構築するためにさまざまなOSSを活用していることを紹介しました。利用しているOSSを再掲します。参考になれば幸いです。