さくらのIaaS基盤のモニタリングとOpenTelemetry

この記事は2025年7月5日(土)に行われたオープンソースカンファレンス 2025 Hokkaidoにおける発表をさくナレ編集部で記事化したものです。
目次
はじめに

さくらインターネットの藤原です。今回はモニタリングとOpenTelemetryの話をします。
私は2011年から2024年まで14年間、面白法人カヤックというところにおりました。最後の方はSREをやってました。そして2025年2月にさくらインターネットに入りまして、主にIaaS基盤開発を担当しています。それからISUCONで何度か優勝や出題をしたことがあります。それに関連して、Webパフォーマンスチューニングの本も共著で書いています。OSSの開発もしていて、カヤックにいたときにAmazon ECSのデプロイツールであるecspressoというものを作って結構使われたり、AWS Lambdaのデプロイツールであるlambrollを作ってたりしました。最近はさくらのAppRunのデプロイツールも作っています。趣味はランニングで、今朝も10kmぐらい走ってきました。北海道は涼しくていいですね。
さくらのIaaS基盤
さくらのIaaS基盤ではOSSを結構使っています。データプレーンではLinux, QEMU, KVM, LVM, Open-iSCSIなどを使っていて、コントロールプレーンは自社開発のソフトウェアとミドルウェアはOSSという組み合わせで動いています。使用している主なOSSとしては、nginx, Apache httpd, PHP, Perl, Go, MySQL, RabbitMQといったところが挙げられます。
さくらのIaaS基盤のアーキテクチャ(初期: 2011〜2020年頃まで)

さくらのクラウドの初期(2011年から2020年頃まで)のアーキテクチャは、APIサーバーと多数のスクリプト群で構成されていました。お客さんがコントロールパネルから操作するとAPIサーバーにリクエストが行き、APIサーバーが処理をします。例えばサーバーを起動したいというリクエストが来たら起動し、停止したいと言われたら停止するのですが、その処理をするのがPHPで書かれたAPIサーバーでした。それとPerlとShellの組み合わせで動いていたような感じです。
このレガシーなアーキテクチャにおけるVM起動の流れとしては、まずユーザーがAPIを叩きます。するとAPIサーバーの中で処理が行われて、具体的な起動方法まで決定してからリモートでコマンドを実行するとVMが起動するという感じです。このときにVMをどのホストに建てるかも選定しなければなりません。例えば負荷が高すぎるホストに建てるのはよくないですし、いい感じにバランスするように配分しなければならないというのがあります。それから、作成するVMのCPUがいくつ、メモリがこれぐらい、ディスクはどれをアタッチするかとか、そういう細かい情報もないと起動できないのですが、そういうことも含めて全部APIサーバーが処理をしてコマンドを生成して、そのコマンドでVMを起動するという仕組みになっていました。ストレージやネットワークの操作も同じような仕組みで、PHPで書かれたAPIサーバーが頑張っていたというのが初期のアーキテクチャです。
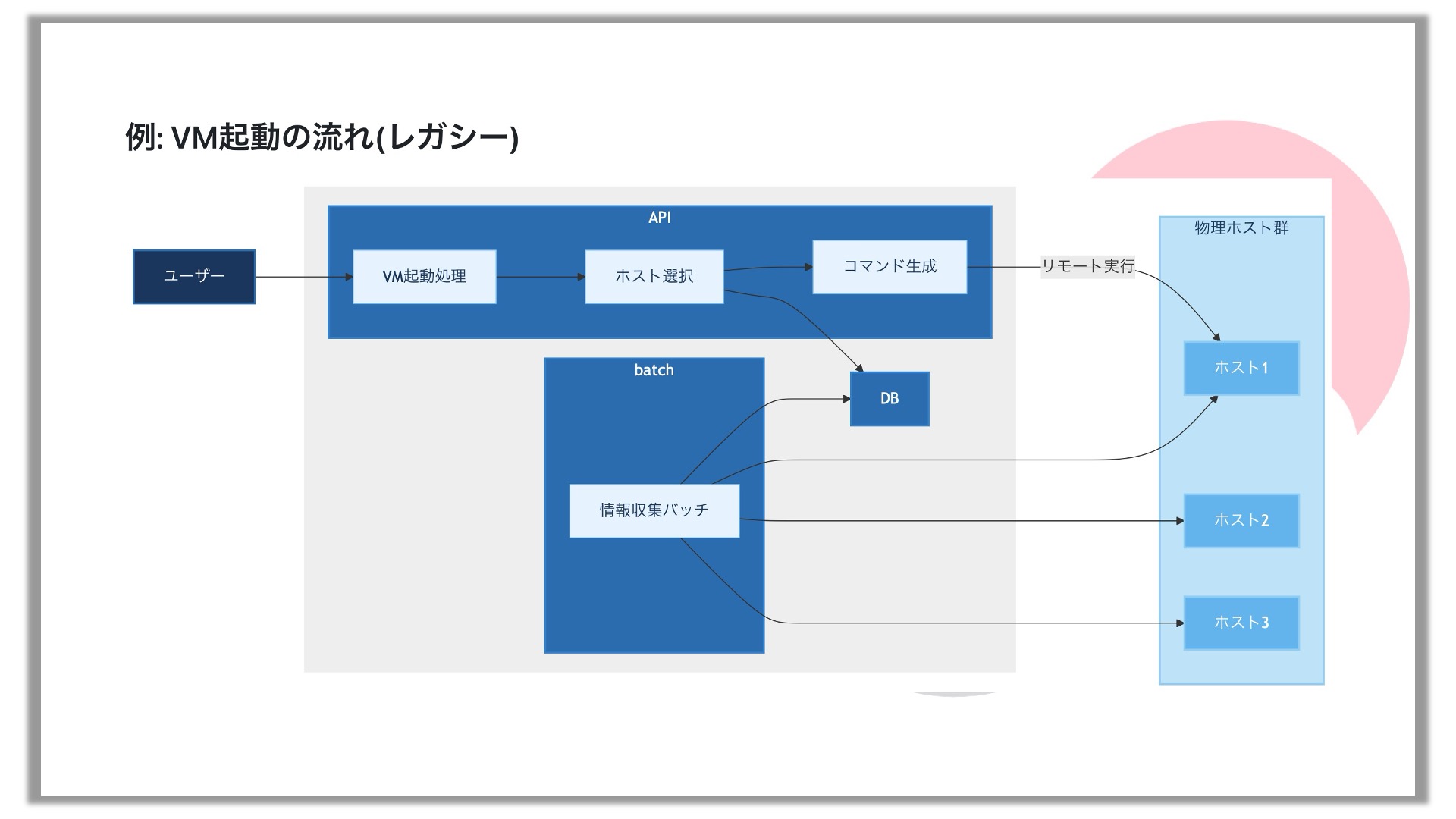
これを図にするとこうなります。中央のグレー背景の部分がPHPで書かれています。
ユーザーがリクエストすると、VMを起動する処理があり、ホストを選択して、データベースの情報を見ます。データベースに入っている情報は、情報収集を担当するバッチサーバーがホストサーバーから定期的に情報を収集してデータベースを更新しています。そして、データベースからの情報をもとにコマンドを作り、それをリモートで実行するとVMが作られます。図の中央部分にあるPHPで書かれたプログラム群は結構巨大なサイズになっています。
さくらのIaaS基盤のアーキテクチャ(2020年頃〜)

しかしこのままではつらいということで、新しいアーキテクチャへの移行を始めたのが2019年から2020年頃ですね。まだ全部が置き換わったわけではなく古い仕組みも残っていますが、新しいアーキテクチャにしていこうというのをやってます。
まずAPIは、従来はPHPで書かれていましたが、現在のさくらのクラウドの実装においては他の部分はあまりPHPを使っていません。Pythonを使っていることが多いのでPythonとDjangoに置き換えたいという話をしていますが、まだ具体的な話には進んでいない状況です。
その後に、各コンポーネントの具体的な責務、例えばどのホストで動かすか、最終的に物理サーバーの上で実行するコマンドライン引数をどのようなものにするかなどを、例えばVMだったらVM管理、ネットワークならネットワーク管理、ストレージならストレージ管理という具合に、それぞれマイクロサービスにしてしまって、APIを軽くしていこうとしています。APIが巨大だと置き換えも難しいので、まずはここを切り分けていくことを考えています。
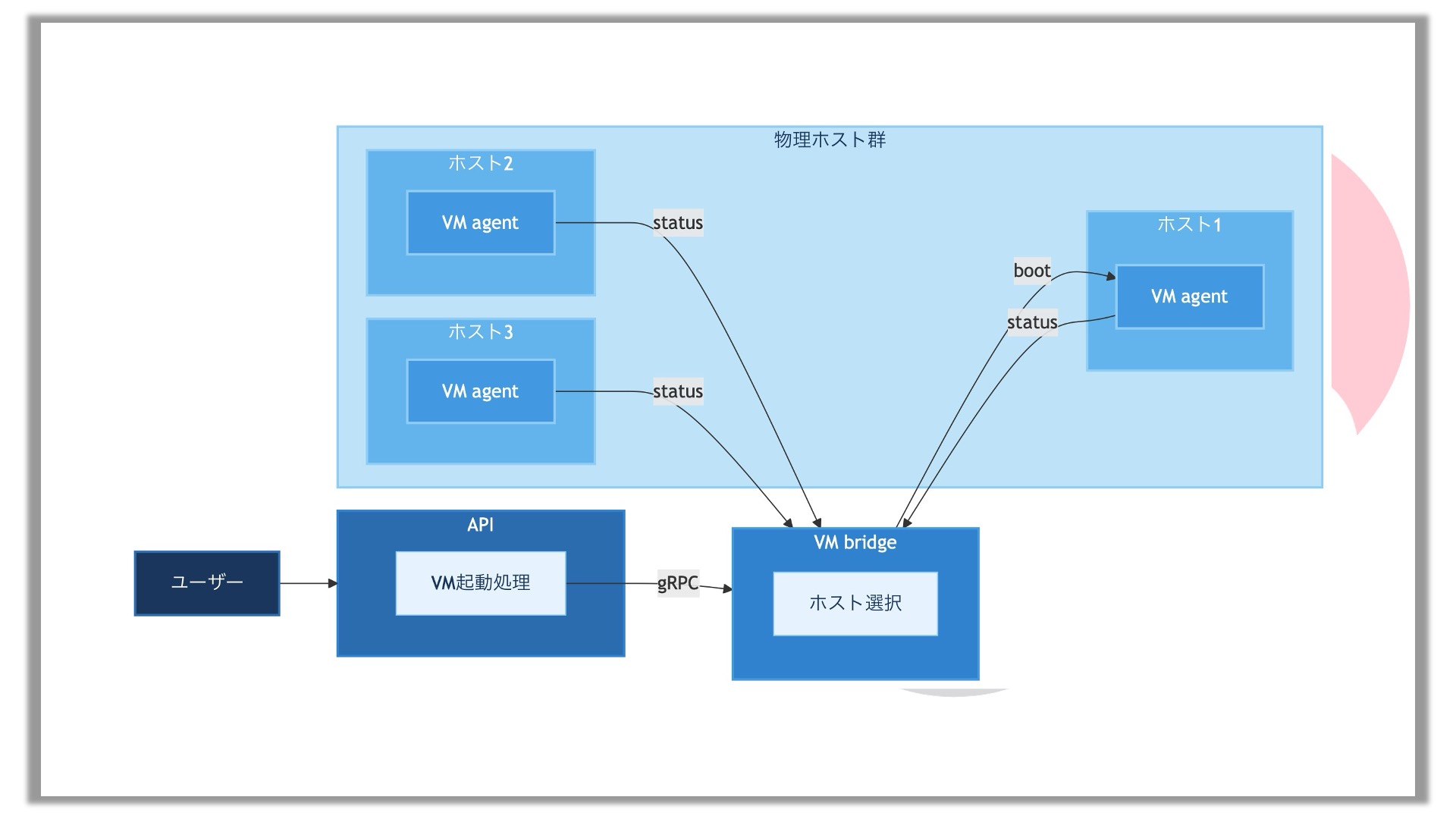
新しいアーキテクチャは上図のようになっています。ユーザーがAPIサーバーにVM起動処理をリクエストしたら、APIサーバーからVMを管理しているサーバー(上図ではVM bridge)にgRPCでリクエストが渡されます。VM管理サーバーはどのホストでVMを起動するべきかを判断します。判断するための情報は、各ホストにエージェントがいて、定期的に情報を送ってくれます。ここの通信もgRPCで行っています。集まった情報をもとに適正なホストを選定し、そのホストのエージェントに対してVMを起動するようリクエストします。このようにしてAPIのマイクロサービス化を進めています。
さくらのIaaS基盤のモニタリング

このように新しいアーキテクチャにしようとしているのですが、そうするとモニタリングの課題が出てきます。
さくらのクラウドにおけるモニタリングは昔からZabbixを使っていて、今でも使っています。ネットワーク機器や物理サーバーもこれでモニタリングしています。しかしマイクロサービスが増えていくと、マイクロサービスごとにきちんとモニタリングしないといけなくなります。APIのエラーログだけを見ていてもどこが悪いのかわかりません。
そこでこれをなんとかしようということで、PrometheusとGrafanaを導入しました。例えば各マイクロサービスにはPrometheusのexporterを入れます。これはHTTPのエンドポイントになっていて、ここにアクセスするとメトリクスがテキストで流れてきます。そういうのを実装しておいて、Prometheusがそれをスクレイピングしてデータを収集し、それをGrafanaで可視化するという仕組みを用意して動かしました。
しかしここにも課題があって、導入してデータが取れるようになったのはいいのですが、それがなかなかうまく使えていないという状態です。というのはダッシュボードを作るのも大変ですし、あとはアラートがうまく設定できていなかったようです。ですので集めることは集めたのですがそれほど有効に使えなくてどうしようという感じです。それからこれはよくあることらしいのですが、社内のいろんなところにPrometheusとGrafanaが乱立して、どうやってメンテナンスするのかという問題も起きています。いい感じにメンテし続けるのは結構つらく、運用コストが高いという課題があります。
Mackerel + OpenTelemetryを導入

そこでMackerelを入れることになり、結構導入が進んでいます。さくらのクラウド上で動くサービスでも、IaaS基盤でも使っています。
Mackerelは、はてなが提供しているサーバー監視とオブザーバビリティのSaaSです。Mackerelが持つ多数の機能のうち今回はメトリクスの話に絞りますが、メトリクスを集めてグラフを書いたりだとか、そのメトリクスに対してアラートを仕掛けたりといったことができます。
Mackerelは2014年から続いている歴史あるサービスなのでメトリクスの仕組みが3種類あります。昔からある仕組みがhost metricsとservice metricsの2つです。host metricsは、サーバーにMackerelのエージェントを入れるとそのエージェントが取ってくれるメトリクスです。service metricsはサーバーに紐づかないメトリクス、例えば論理的なサービス(Webサービスなど)に紐づくメトリクスです。この2つが最初からあったのですが、それに加えて昨年公開されたのがラベル付きメトリクスです。これはOpenTelemetryと互換性があります。ラベルというのは、例えば環境がプロダクションで、ホストネームが○○で…というような複数の属性についてkeyとvalueがメトリクスに紐づいていて、例えばあるkeyに対するvalueを取ってきたり平均を出したりというようなことができるという、結構柔軟に扱えるのがラベル付きメトリクスです。OpenTelemetryは、サーバーやサービスに関するテレメトリデータ(ログ・メトリクス・トレース)を統一的に収集・送信するためのフレームワークです。これはOSSとして開発されています。
というわけでMackerelとOpenTelemetryを導入してやっていこうとしているのですが、実はPrometheusのexporterはすでにあるので、ここのメトリクスはそのまま使って、それをMackerelに送りたいということで、otel-collector (OpenTelemetry Collector)を使った解決策を考えました。otel-collectorは、メトリクスの収集・加工・送信といったことを、定義ファイルを書くとそれに従ってやってくれるツールです。これを使うと、例えばPrometheusのreceiverというのがあって、これがPrometheus互換のメトリクスを取ってきて、必要であれば加工して、otlp exporterというOpenTelemetryのプログラムを使ってMackerelに送ってやることができます。こうすれば、既存のPrometheusのモニタリングなどはそのまま動かしながら、同時に同じメトリクスをMackerelにも送ることができるようになります。同時に動かすことで、値がきちんと取れていることも確認しながら移行することができるようになりました。
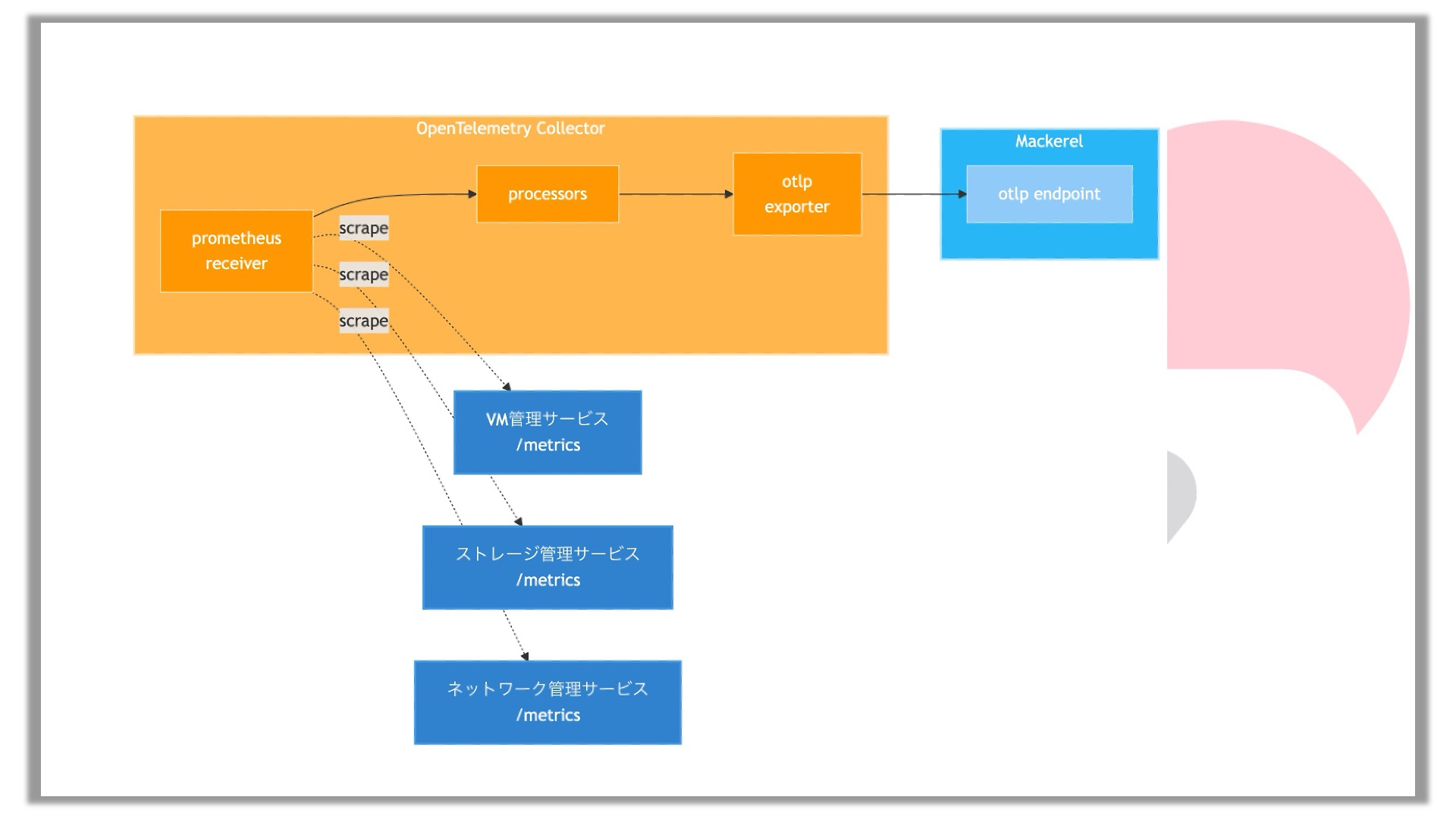
この動きを概念図にすると上のようになります。左上のオレンジの枠がOpenTelemetry Collectorです。その中にPrometheus receiverというのがあります。receiverと言いつつも実際には受信するのではなく動作としては取りに行くのですが、これが各サービスに対してスクレイプしていってメトリクスを取ってきて、それを加工して、otlp exporterからMackerelに対してデータを流します。これで各種マイクロサービスのメトリクスがMackerelに流れていく仕組みができあがります。
OpenTelemetry Collectorを用意する

それから、OpenTelemetry Collector(otel-collector)を用意する必要があります。otel-collectorはGoで書かれたアプリケーションなので、これをビルドするなり、あるいはバイナリを入手するなどして用意します。
otel-collectorの構成要素としては、先ほど紹介したreceiverという、収集のためのコンポーネントがあります。PrometheusやOTLPのプロトコルで受信することができます。あとはjaegerからデータを取ってきたりとか、fluentdforwardはメトリクスではなくログを受け取るものです。hostmetricsは動いているホストのCPU情報を拾ってくることができます。他にもたくさんあります。
次にprocessorです。これもいろいろあります。batchというのはデータを外に出す時に五月雨式に送ると大変なので1分間のデータをまとめて送るというようなことをしてくれます。memory_limiterというのは、otel-collectorにメトリクスを送りすぎるとotel-collectorが爆発することがあるので、それを防ぐためにメモリの上限を設定して、メトリクスが多すぎたらドロップするというような動作をします。それからtransformは、メトリクスを加工したりラベルを付けるとか置き換えるとか、そういうことができます。
exporterはメトリクスを外に出すものです。OTLPプロトコルで外に出すものもありますし、prometheusremotewriteというのはPrometheusに対して書きに行くものです。それからfileといってファイルに直接JSONで書くこともできます。それからextensionというのは追加機能です。ヘルスチェック(health_check)とか、pprofというのはプロファイリングツールです。
otel-collectorはこれらの構成要素が組み合わさって1つのバイナリとして動くのですが、これをどう用意するかという問題があります。コンポーネントが本当にたくさんあるので、全部入りにするとバイナリが大きくなり過ぎますし、かといって絞ると欲しいものが入っていないということが起きます。

そこで、公式でディストリビューションがいくつか用意されています。スライドの一番上に書いてあるOpenTelemetry Collector("otelcol")が標準的なものです。その次にあるOpenTelemetry Collector Contrib("otelcol-contrib")は本当に全部入っているもので、ものすごい数のコンポーネントが埋め込まれています。それからKubernetes用のもの("otelcol-k8s")もありますし、"otelcol-otlp"はOTLPプロトコルに特化したシンプルなものです。OpenTelemetry Collector eBPF Profiler("otelcol-ebpf-profiler")はまだ使ったことがありませんが、eBPFのプロファイル情報を取るためのものらしいですね。こういうのが公式で用意されていて、それぞれバイナリが配られています。
ではこれを我々の環境でどうやって動かすかです。公式のディストリビューションにあるcontribを使おうとするとバイナリが300MBとかあってちょっと大き過ぎます。それに、本当にいろんなコンポーネントが入っていて、それはつまりセキュリティリスクが紛れ込んでくる可能性も上がるということでもあるので、あまり使いたくないんですね。そういうわけで、必要なものだけを組み込んだバイナリを作って、本番環境ではそれを使うことが推奨されています(参考ページ)。

そのバイナリをビルドする方法も公式に用意されています。ocb(OpenTelemetry Collector Builder)というものがあるのですが、これを使います。YAMLのファイルを用意して、exporterはこれを使う、receiverはこれを使う、というようにコンポーネントを全部記述して、それをocbコマンドに読ませるとバイナリがビルドされます。使用するコンポーネント変更するときも、このYAMLをメンテしてビルドすればよいという状態になっています。
さくらのクラウド向けのOpenTelemetry Collector

そこで今回、sacloud-otel-collectorというものを用意して、OSSとして公開しました。これはさくらのクラウド向けのOpenTelemetry Collectorです。
どうしてこれを用意したかというと、AWSなど他のクラウドプロバイダーも用意しているのでそれに倣ったというのもありますが、さくらのクラウド自体がOpenTelemetryエコシステムを採用している部分が増えてきたというのもあります。あとはモニタリングスイートというのが最近リリースされてβ版で提供されています。これはモニタリングに関するデータを扱えるサービスで、今はメトリクスとログに対応していて、トレースはそのうち提供予定ですが、これらのデータを扱って保存して可視化してくれるマネージドサービスです。これを提供していますが、そこにデータを送る手段を用意しないといけません。ということで公式のコレクタがあった方がいいだろうというのもあります。
あと、IaaS基盤に関しては、お客さんが起動したVMのCPU使用率などはコントロールパネルから見られるようになっていますが、それはVMの外からしか観測できていません。というのはお客さんのサーバーの中に手を入れるわけにはいかないので、CPU使用率は取れますが、メモリをどう使っているかとか、そういう細かいところまではわからないのです。データ転送量もインとアウトしかわからない状況で、そういうざっくりとした外側から観測できるものしかわからないというのが現状です。そういうデータをきちんと細かく取りたいと思ったら、例えば先ほどお話ししたhostmetricsレシーバーみたいなものをインストールしてもらって、そしてメトリクスを取得してモニタリングスイートに送ってもらうともっと詳しい状況が見られますよ、というような形でいろいろと使い道があるだろうと思って用意しました。
現在のsacloud-otel-collectorは本当に一般的に使えるものをビルドしただけなので特色はありませんが、リリースバイナリとDockerイメージを用意して、GitHubに置いてあります。今後はもう少しいろいろとできることがあればやっていきたいなと思っていて、例えばさくらのクラウドのマネージドサービスでreceiverやexporterといったものが必要なら、便利に使えるものがあったら作りたいなとか、あとは先ほど言ったようにVM上で動かしてやるとCPUやディスクの情報などを送れるのですが、そのときにモニタリングスイートに送るための認証情報を自動設定できる仕組みとか、いろいろやっていきたいなと思っています。
まとめ
というわけでまとめとしては、今はIaaS基盤のモニタリングをMackerelとOpenTelemetryで作り直しているという状況です。そのためにOpenTelemetry Collectorを用意してOSSにしてあります。これは内部でも使っていますし、外部でも使われるようになっていくといいなという感じです。
インフラ開発エンジニア募集中

最後に採用の告知をさせてください。現在、さくらのクラウドを開発するエンジニアを絶賛採用中ですので、興味ある方はぜひご応募ください。OSSの開発という仕事もあります。先ほど紹介したsacloud-otel-collectorは私がさっと作ってしまったもので私はOSSの開発が専門ではないのですが、OSSを専門にやっている人もいて、さくら用のSDKとかTerraform Providerとか、そういうものを開発することを専任でやっている人もいます。というわけで、OSSを開発しながら給料ももらえるみたいなこともできると思うので、興味のある方がいましたらご連絡ください。