さくらの生成AIプラットフォームで作るローカルLLMとDifyによるチャットボット(2) ローカルLLMの起動

前回の記事では、さくらのクラウドでUbuntu仮想サーバを作成してDifyを起動し、OpenAIを活用したチャットボットを構築しました。
第二回のこの記事では、さくらの生成AIプラットフォームでGPUを用いたオープンソースLLM(大規模言語モデル:Large Language Model)を起動していきます。
ローカルLLMと技術特性
ローカルLLM(Local LLM)とは、LLMを自社のサーバーやローカルな環境で実行・運用する方式のことです。これは、OpenAIのChatGPTやGoogleのGeminiのようにクラウド上で提供されるLLMとは対照的に、オンプレミスやエッジデバイス上でLLMを動かすことを意味します。
参考記事:ローカルLLMとは?機密データを守るための企業向けAI活用と導入ステップ
これには利点と注意点が存在します。
利点:
プライバシーとセキュリティの強化
入力されたデータが外部に送信されないため、機密情報や個人情報の保護に優れます。医療、金融、政府機関などのセキュリティが厳格な業界での検討や活用が積極的に進んでいます。
ネットワークに依存しない
インターネット非接続のオフラインやオンプレミス環境でも使用可能です。
費用の管理が容易
商用のクラウド型LLMは、ほとんどの場合トークンと言われる単位で課金が行われます。トークンは会話や処理のたびに消費されることから事前に必要コストの見積もりが困難です。ローカルLLMの場合、GPUおよび環境を維持するサーバ群のコストのみとなるため、クラウドを活用したとしても比較的固定費用のように取り扱うことができます。
注意点:
一般的には自然言語処理にはクラウド型で提供されている最新LLMモデルの方がオープンソース型LLMモデルより高い性能を発揮します。このためユーザーとのやりとりを担うチャットボットのエンジンなどではクラウド型LLMが採用されるケースもあります。
一方、生成AIの発展に伴い、その利用用途は拡大が続いています。例えば社内に存在している様々な文書をベクトルデータ化しておき検索を行えるようにするRAGや音声の文字起こしなどはそこまで複雑な自然言語処理能力が求められないため、ローカルLLMでも十分な性能を発揮するケースがあります。このあたりの使い分けについては第三回の記事で触れていく予定です。
GPUクラウドサービス「高火力」シリーズ

さくらインターネットではGPUクラウドサービスを提供しています。

ベアメタル型で最高パフォーマンスを発揮する「高火力 PHY」、仮想環境を専有可能な「高火力 VRT」、コンテナ側で軽量な環境を利用可能な「高火力 DOK」という違いがあります。
この記事ではオープンソースLLMを高火力 DOK上で起動して、API経由でシンプルなチャットのテストを行います。
LocalAI
高火力 DOKでオープンソースLLMを起動させるときに、直接インストールすることも可能ですが、今日はLocalAIというオープンソースのフレームワークを使います。

「LocalAI」は、ローカル環境で大規模言語モデル(LLM)や音声モデルなどを実行できるオープンソースのAPI互換推論サーバーです。OpenAIのAPI(ChatGPT等)と互換性のあるインターフェース(REST API)を提供することで、既存のアプリケーションをローカルLLMに簡単に対応させることが可能になります。
つまりLocalAI経由でオープンソースLLMをインストールすることで、自動でOpenAI互換のREST型APIが作成されるため非常に便利になり、独自LLMをDifyをはじめとした様々な環境に組み込むことが楽になります。
さっそくやってみる
前置きがかなり長くなりましたが、やっていきます。
1. DOK用コンテナイメージ作成用環境構築
高火力 DOKはコンテナ型GPUサービスです。JupyterLabがバンドルされており直接開発が可能となっていますが、この手順では別環境であらかじめコンテナイメージを作成して、さくらのクラウドが提供するコンテナレジストリ経由でコンテナイメージを引き渡します。
前回の記事ですでにDify用Ubuntuサーバを起動していますので詳細な手順は割愛しますが、もう一台Ubuntuサーバを起動します。今回はcloud-initは使わないため、イメージはcloud-init対応のイメージであるcloudimgでなくても問題ありません。

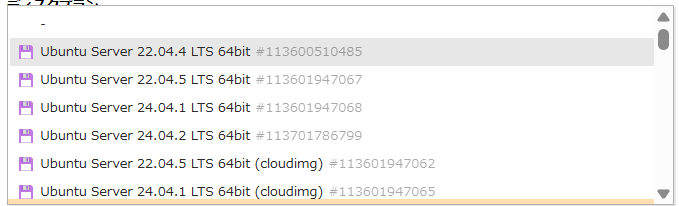
ディスクサイズは100GBを指定します。
サーバが起動したらまずはシステムを最新にアップデートし、作業に必要なモジュールをインストールします。
# パッケージリストを更新
sudo apt update
# システム全体をアップグレード
sudo apt upgrade -y
# 必要な基本パッケージをインストール
sudo apt install -y curl wget git vim build-essential途中にOS初期設定の画面が出てきますので、デフォルトのまま2回続けてEnterを押します。
シェルに画面が戻ってきて入力可能となれば完了です。次にDockerをインストールします。
# 古いDockerを削除(存在する場合)
sudo apt remove docker docker-engine docker.io containerd runc
# Docker公式GPGキーを追加
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# Dockerリポジトリを追加
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# パッケージリストを更新してDockerをインストール
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Dockerサービスを開始・有効化
sudo systemctl start docker
sudo systemctl enable docker
# 現在のユーザーをdockerグループに追加(再ログイン後に有効)
sudo usermod -aG docker $USER
# Dockerのインストール確認
docker --version2. コンテナレジストリの作成とログイン
次にさくらのクラウドでコンテナイメージを登録するレジストリを作成します。左ペインのグローバルからコンテナレジストリを選択します。
画面右上の追加をクリックします。

適当な名前を付けて作成をクリックします。この名前は後で使いますのでメモしておきます。
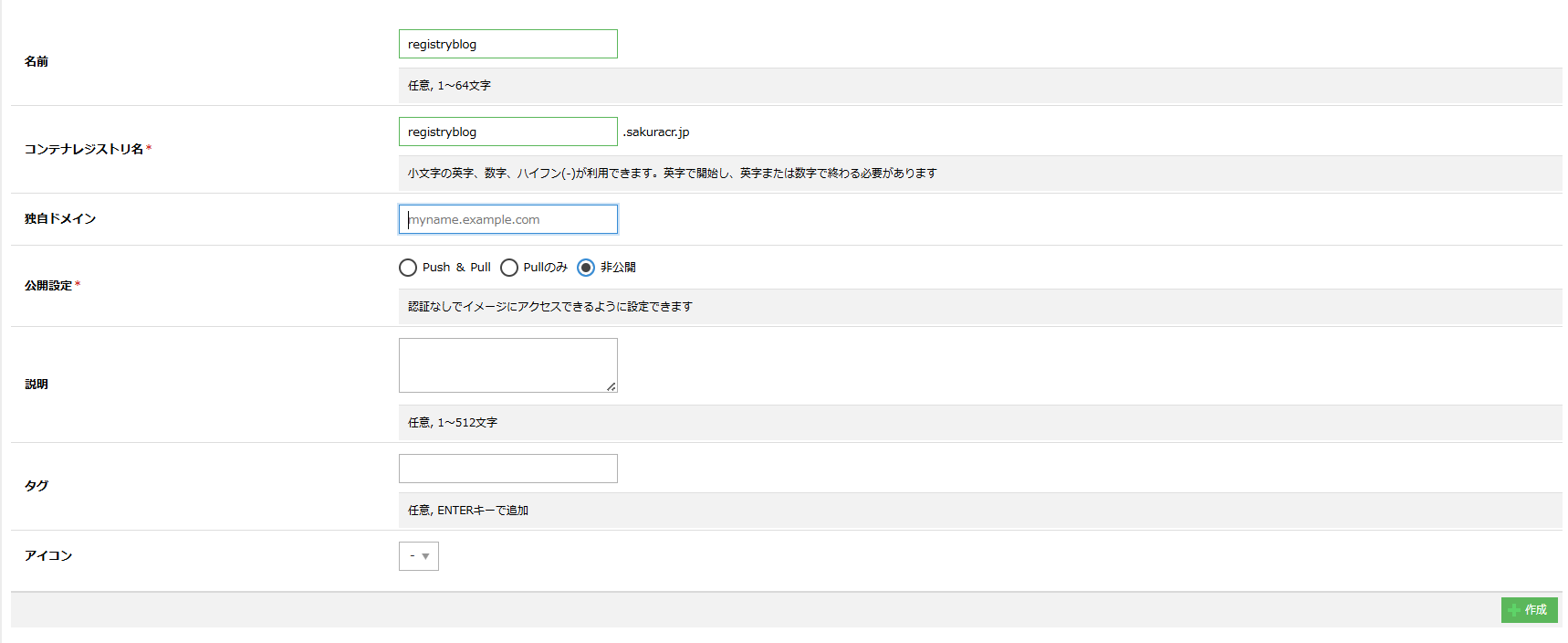
作成されたレジストリの名前は <名前>.sakuracr.jp となります。なお名前はさくらのクラウド全体で一意となるため、この手順とは異なる値を設定してください。
作成されたレジストリをクリックしてユーザータブを選びます。
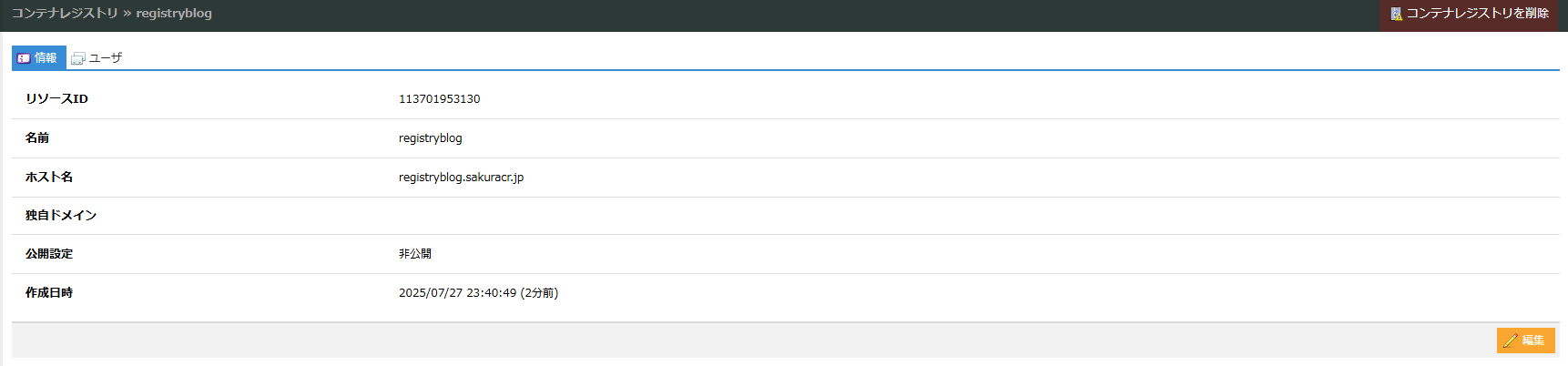
ユーザー名とパスワードを指定してユーザーを作成します。
ユーザーが作成されたらシェルからログインを行います。
sudo docker login registryblog.sakuracr.jpUsername: test
Password:
Error response from daemon: Get "https://registryblog.sakuracr.jp/v2/": unauthorized: Unauthorized
ubuntu@ubuntu:~$ sudo docker login registryblog.sakuracr.jp
Username: blog
Password:
WARNING! Your credentials are stored unencrypted in '/root/.docker/config.json'.
Configure a credential helper to remove this warning. See
https://docs.docker.com/go/credential-store/
Login Succeeded3. Dockerイメージの作成
ではDockerイメージを作成します。改めて整理ですが、このDockerイメージの中にはLocalAIをNVIDIAのドライバ付きでインストールします。
オープンソースのLLMモデルは、LocalAIが起動した後にインストールを行うため設定は行っていません。代わりにオープンソースLLMを配布しているHugging Face用設定も投入しておくことで、LocalAIが後程Hugging Faceからモデルをダウンロードできるようにしています。
まずDockerfileを以下の内容で作成します。
# LocalAI with NVIDIA GPU Support
# 動作確認済み - 日本語対応モデル対応
FROM nvidia/cuda:12.2.0-devel-ubuntu22.04
# 環境変数設定
ENV DEBIAN_FRONTEND=noninteractive
ENV PATH="/usr/local/cuda/bin:${PATH}"
ENV LD_LIBRARY_PATH="/usr/local/cuda/lib64:${LD_LIBRARY_PATH}"
# 基本パッケージのインストール
RUN apt-get update && apt-get install -y \
wget \
curl \
git \
python3 \
python3-pip \
build-essential \
cmake \
&& rm -rf /var/lib/apt/lists/*
# LocalAIのダウンロードとインストール
RUN wget -O /usr/local/bin/local-ai https://github.com/mudler/LocalAI/releases/latest/download/local-ai-Linux-x86_64 && \
chmod +x /usr/local/bin/local-ai
# 作業ディレクトリの作成
WORKDIR /app
# モデルディレクトリの作成
RUN mkdir -p /app/models /app/config
# LocalAI基本設定ファイル
RUN cat > /app/config/local-ai.yaml << 'EOF'
debug: false
context_size: 1024
threads: 4
models_path: "/app/models"
galleries:
- name: "huggingface"
url: "https://raw.githubusercontent.com/mudler/LocalAI/master/embedded/model_library.yaml"
- name: "localai"
url: "https://raw.githubusercontent.com/mudler/LocalAI/master/embedded/model_library.yaml"
EOF
# ポート公開
EXPOSE 8080
# 起動スクリプトの作成
RUN cat > /app/start.sh << 'EOF'
#!/bin/bash
echo "Starting LocalAI with GPU support..."
echo "==================================="
echo "GPU Information:"
nvidia-smi 2>/dev/null || echo "nvidia-smi not available (normal in build environment)"
echo "==================================="
echo "LocalAI will be available at:"
echo "- Web UI: http://0.0.0.0:8080"
echo "- API: http://0.0.0.0:8080/v1/*"
echo "==================================="
# LocalAI起動
exec /usr/local/bin/local-ai \
--config-file /app/config/local-ai.yaml \
--models-path /app/models \
--address 0.0.0.0:8080 \
--debug=false
EOF
RUN chmod +x /app/start.sh
# ヘルスチェック
HEALTHCHECK --interval=30s --timeout=10s --start-period=60s --retries=3 \
CMD curl -f http://localhost:8080/v1/models || exit 1
# 起動コマンド
CMD ["/app/start.sh"]次に以下のコマンドでイメージを作成します。
sudo docker build -t registryblog.sakuracr.jp/localai:latest .初回はいろいろなものをダウンロードしますので数分間待ちます。
[+] Building 77.3s (3/11) docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 2.20kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.2.0-devel-ubuntu22.04 2.2s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/8] FROM docker.io/nvidia/cuda:12.2.0-devel-ubuntu22.04@sha256:c4e81887e4aa9f13b1119337323cba89601319ecb282383b879c4ba50510fd17 75.0s
=> => resolve docker.io/nvidia/cuda:12.2.0-devel-ubuntu22.04@sha256:c4e81887e4aa9f13b1119337323cba89601319ecb282383b879c4ba50510fd17 0.1s
=> => sha256:aece8493d3972efa43bfd4ee3cdba659c0f787f8f59c82fb3e48c87cbb22a12e 29.54MB / 29.54MB 2.0s
=> => sha256:9fe5ccccae45d6811769206667e494085cb511666be47b8e659087c249083c3f 4.62MB / 4.62MB 0.7s
=> => sha256:8054e9d6e8d6718cc3461aa4172ad048564cdf9f552c8f9820bd127859aa007c 56.08MB / 56.08MB 2.0s
=> => sha256:5307765dadf8460b069757105b659484d7551f149397fb56c4817f383dd5b028 15.62kB / 15.62kB 0.0s
=> => sha256:c4e81887e4aa9f13b1119337323cba89601319ecb282383b879c4ba50510fd17 743B / 743B 0.0s
=> => sha256:ec5d41e67e1e8e8a82451aa5d08bf3db04a2859e9a9266569406537ee2d7a9f8 2.63kB / 2.63kB 0.0s
=> => sha256:bdddd5cb92f6b4613055bcbcd3226df9821c7facd5af9a998ba12dae080ef134 185B / 185B 1.0s
=> => sha256:5324914b447286e0e6512290373af079a25f94499a379e642774245376e60885 6.89kB / 6.89kB 2.0s
=> => extracting sha256:aece8493d3972efa43bfd4ee3cdba659c0f787f8f59c82fb3e48c87cbb22a12e 1.2s
=> => sha256:9a9dd462fc4c5ca1dd29994385be60a5bb359843fc93447331b8c97dfec99bf9 1.10GB / 1.10GB 26.5s
=> => sha256:e2554c2d377e1176c0b8687b17aa7cbe2c48746857acc11686281a4adee35a0a 1.69kB / 1.69kB 2.3s
=> => sha256:95eef45e00fabd2bce97586bfe26be456b0e4b3ef3d88d07a8b334ee05cc603c 63.35kB / 63.35kB 2.3s
=> => sha256:4640d022dbb8eb47da53ccc2de59f8f5e780ea046289ba3cffdf0a5bd8d19810 1.52kB / 1.52kB 2.5s
=> => sha256:aa750c79a4cc745750c40a37cad738f9bcea14abb96b0c5a811a9b53f185b9c9 2.34GB / 2.34GB 66.6s
=> => sha256:9e2de25be969afa4e73937f8283a1100f4d964fc0876c2f2184fda25ad23eeda 88.05kB / 88.05kB 2.8s
=> => extracting sha256:9fe5ccccae45d6811769206667e494085cb511666be47b8e659087c249083c3f 0.2s
=> => extracting sha256:8054e9d6e8d6718cc3461aa4172ad048564cdf9f552c8f9820bd127859aa007c 1.5s
=> => extracting sha256:bdddd5cb92f6b4613055bcbcd3226df9821c7facd5af9a998ba12dae080ef134 0.0s
=> => extracting sha256:5324914b447286e0e6512290373af079a25f94499a379e642774245376e60885 0.0s
=> => extracting sha256:9a9dd462fc4c5ca1dd29994385be60a5bb359843fc93447331b8c97dfec99bf9 26.2s
=> => extracting sha256:95eef45e00fabd2bce97586bfe26be456b0e4b3ef3d88d07a8b334ee05cc603c 0.0s
=> => extracting sha256:e2554c2d377e1176c0b8687b17aa7cbe2c48746857acc11686281a4adee35a0a 0.0s
=> => extracting sha256:4640d022dbb8eb47da53ccc2de59f8f5e780ea046289ba3cffdf0a5bd8d19810 0.0s
=> => extracting sha256:aa750c79a4cc745750c40a37cad738f9bcea14abb96b0c5a811a9b53f185b9c9イメージが無事完了したら出来上がったイメージをレポジトリにPushします。数分かかりますのでしばらく待ちます。
sudo docker image push registryblog.sakuracr.jp/localai:latestThe push refers to repository [registryblog.sakuracr.jp/localai]
a28b6f916379: Pushed
d24513a6d0b4: Pushed
97e6ba013380: Pushed
9a637de6ffc4: Pushed
4f57bd08cb26: Pushed
f8f7b038febb: Pushing [===========> ] 334.2MB/1.455GB
3dfe148e2dfd: Pushed
31bb8354caec: Pushed
d09e0d675218: Pushing [=> ] 181.5MB/4.611GB
d7ea66469795: Pushed
cd08f63effcf: Pushed
3afff21308c2: Pushed
fdfb7cb43648: Pushing [=====> ] 187.1MB/1.726GB
863984995e20: Pushed
f6922d7436ee: Pushed
2468321ae51b: Pushed
c0d9ea20683b: Pushed
256d88da4185: Pushing [==============================================> ] 72.42MB/77.82MB4. 高火力 DOKを使ってイメージを起動
無事にコンテナレジストリへのPushが完了したらいよいよ起動です。高火力 DOKはさくらのクラウドのトップ画面から選択できます。
まずは最初にコンテナレジストリの認証情報を登録します。左ペインからレジストリー認証情報を選びます。

先ほど作成したコンテナレジストリの情報を入力して登録をクリックします。

左ペインからタスクを選びます。
画面右上から新規作成をクリックして必要な項目を入力します。

- 名称:任意
- イメージ:先ほどPushしたイメージのフル名(例:registryblog.sakuracr.jp/localai:latest)
- レジストリー認証情報:先ほど登録したコンテナレジストリ
- HTTPポート:8080

作成をクリックすると以下の通り起動準備中となります。


ステータスが実行中になるまで待ちます。コンテナイメージレジストリから数GBのファイルをダウンロードした後、初期設定スクリプトが実行されていますので少し時間がかかります。
5. モデルの組み込みと会話テスト
ステータスが実行中になれば利用可能です。
HTTP URLをクリックするとエンドポイントURLが表示されます。
ブラウザでアクセスを行い、以下の画面が表示されれば無事起動しています。

先ほどコンテナイメージを作った環境から以下のコマンドを実行します。URLは環境ごとに異なりますので書き換えて下さい。
curl https://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/v1/models実行すると以下のような結果が返ってきます。
{"object":"list","data":[]}これはLocalAIにはまだモデルがインストールされていないという結果です。オープンソースのLLMモデルとしてMetaが開発したLlama3をもとにコミュニティベースでファインチューニングが行われた軽量モデルのLlama3.2 1Bをインストールします。まずは以下のコマンドでインストール可能なモデルを特定します。
curl -s https://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/models/available | grep -o '"name":"[^"]*"' | grep
-i "llama.*3\.2""name":"llama-3.2-1b-instruct:q4_k_m"
"name":"llama-3.2-3b-instruct:q4_k_m"
"name":"llama-3.2-3b-instruct:q8_0"
"name":"llama-3.2-1b-instruct:q8_0"
"name":"versatillama-llama-3.2-3b-instruct-abliterated"
"name":"llama3.2-3b-enigma"
"name":"llama3.2-3b-esper2"
"name":"llama-3.2-3b-agent007"
"name":"llama-3.2-3b-agent007-coder"
"name":"fireball-meta-llama-3.2-8b-instruct-agent-003-128k-code-dpo"
"name":"llama-3.2-chibi-3b"
"name":"llama-3.2-3b-reasoning-time"
"name":"llama-3.2-sun-2.5b-chat"
"name":"llama-3.2-3b-instruct-uncensored"
"name":"llama3.2-3b-enigma"
"name":"llama3.2-3b-shiningvaliant2-i1"
"name":"llama-doctor-3.2-3b-instruct"
"name":"onellm-doey-v1-llama-3.2-3b"
"name":"llama-sentient-3.2-3b-instruct"
"name":"llama-smoltalk-3.2-1b-instruct"
"name":"fusechat-llama-3.2-3b-instruct"
"name":"llama-chat-summary-3.2-3b"
"name":"fastllama-3.2-1b-instruct"
"name":"dolphin3.0-llama3.2-1b"
"name":"dolphin3.0-llama3.2-3b"
"name":"minithinky-v2-1b-llama-3.2"
"name":"LocalAI-functioncall-llama3.2-1b-v0.4"
"name":"LocalAI-functioncall-llama3.2-3b-v0.5"
"name":"kubeguru-llama3.2-3b-v0.1"
"name":"menlo_rezero-v0.1-llama-3.2-3b-it-grpo-250404"
"name":"hermes-3-llama-3.2-3b"一番軽量なllama-3.2-1b-instruct:q4_k_mをインストールしてみます。
curl -X POST https://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/models/apply \
-H "Content-Type: application/json" \
-d '{
"id": "llama-3.2-1b-instruct:q4_k_m",
"name": "llama32-1b"
}'{"uuid":"df1cade7-6afe-11f0-a5a1-ee357dfc3fac","status":"http://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/models/jobs/df1cade7-6afe-11f0-a5a1-ee357dfc3fac"}出力されたURLにアクセスするとインストール状況が確認できます。
{
"deletion": false,
"file_name": "/app/models/llama-3.2-1b-instruct-q4_k_m.gguf.partial",
"error": null,
"processed": false,
"message": "processing",
"progress": 18.098630944171777,
"file_size": "770.3 MiB",
"downloaded_size": "139.4 MiB",
"gallery_element_name": ""
}progress部分がインストール進捗率です。ブラウザをリロードしながら100になるまで待ちます。
インストールが完了すると以下の表示に代わります。
{
"deletion": false,
"file_name": "",
"error": {},
"processed": true,
"message": "error: no backend found with name \"llama-cpp\"",
"progress": 0,
"file_size": "",
"downloaded_size": "",
"gallery_element_name": ""
}ではいよいよテストです。質問をしてみます。
curl -X POST https://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama32-1b",
"messages": [
{"role": "system", "content": "あなたは日本語で応答するアシスタントです。"},
{"role": "user", "content": "こんにちは。日本語で自己紹介をしてください。"}
],
"max_tokens": 100,
"temperature": 0.7
}'{
"created": 1753630575,
"object": "chat.completion",
"id": "0ca6ff0c-c75d-4b79-9655-0802c63f92b3",
"model": "llama32-1b",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "はい、こんにちは!私はアシスタントです。特に、質問に対する質問や、情報を提供するときに役立つことが求められます。質問の質問の際に、英語で質問を聞きますので、英語での質問については、質問を聞くことで使い分けることができます。"
}
}
],
"usage": {
"prompt_tokens": 58,
"completion_tokens": 77,
"total_tokens": 135
}
}回答が無事戻ってきました! 質問を投げ込んでいるエンドポイントの v1/chat/completions はOpenAI APIと同じ形式で互換性が維持されています。
次回予告
次回はこのモデルをDifyに組み込んでGUI付チャットボットを作成していきます。