さくらの生成AIプラットフォームで作るローカルLLMとDifyによるチャットボット(4) ローカルLLMによる埋め込みモデルを活用した低コストRAG


前回に引き続きローカルLLMを活用したチャットボットを作成していきます。今日はRAGを作っていきます。
RAGとは
RAG(Retrieval-Augmented Generation) とは、ナレッジと言われる外部の知識ベースや文書検索システムから情報を取り出し(Retrieval)、それを元に生成系AIが回答やテキストを出力する(Generation)というアプローチです。
簡単に言えば、「生成AIにリアルタイムで調べ物をさせて、精度の高い答えを返させる技術」といえます。2020年、Facebook AI(現Meta AI)が論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」を発表。この論文で初めてRAGという概念が体系的に提案され生成AIの新しい活用形態が生まれました。
RAGの処理フェーズ
これから構築を行うRAGはベクトル検索を用いたごく一般的なもので、処理フェーズは以下の通りです。
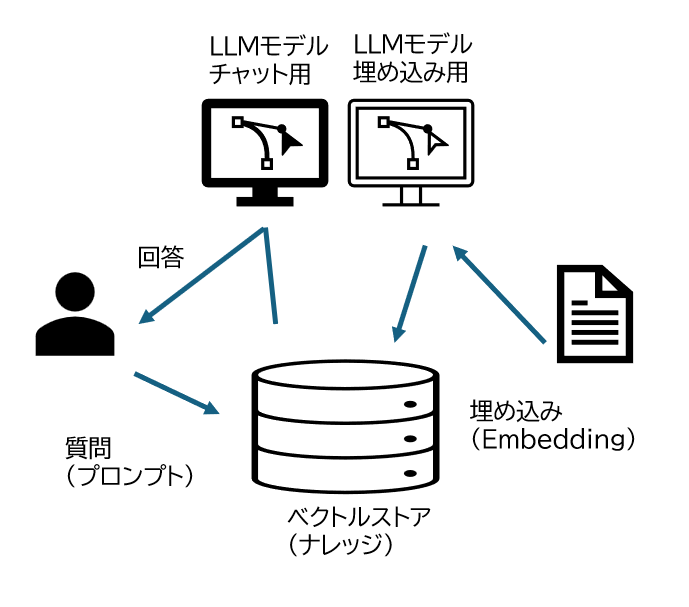
- 事前作業
- 外部知識の埋め込み:ベクトル化
- ユーザーの利用
- 質問:プロンプトのベクトル化とナレッジへのベクトル検索
- 回答の生成
各パートで何が行われているかをご理解いただくために流れを見ていきます。
外部知識の埋め込み:ベクトル化
一般的にLLMは、クローラーが学習用のデータを収集しそれらを学習します。このため学習時点での情報に基づき質問に答えます。最新の情報(例えば今日の天気など)や社内の機密情報など外部に公開されていない情報については答えられません。(もっとも最近のLLMは進化しており、例えば天気の情報など自分が知らない情報についても、インターネット上で公開されている情報は能動的に検索を行い、最新情報をもとに回答をしてくれるようになっています)
このため社内の機密情報など外部に公開されていない情報に基づいた会話を行うにはLLMモデルが連携する外部知識データストアを作成しておく必要があります。それがナレッジと言われます。
ナレッジにはベクトル検索が使われるのが一般的です。ベクトル検索を使えば文字列検索ではなく、その文字列が持つ意味をベースとして、近しい意味を持つ文字列を特定することが可能となります。これを実現させるのが生成AIによるLLMモデルの一形態である埋め込みモデルというものです。
ベクトルというのは、中学や高校の数学で学んだあのベクトルです。生成AIの発展により与えられた文字列の意味を数式に置き換えることが可能となりました。
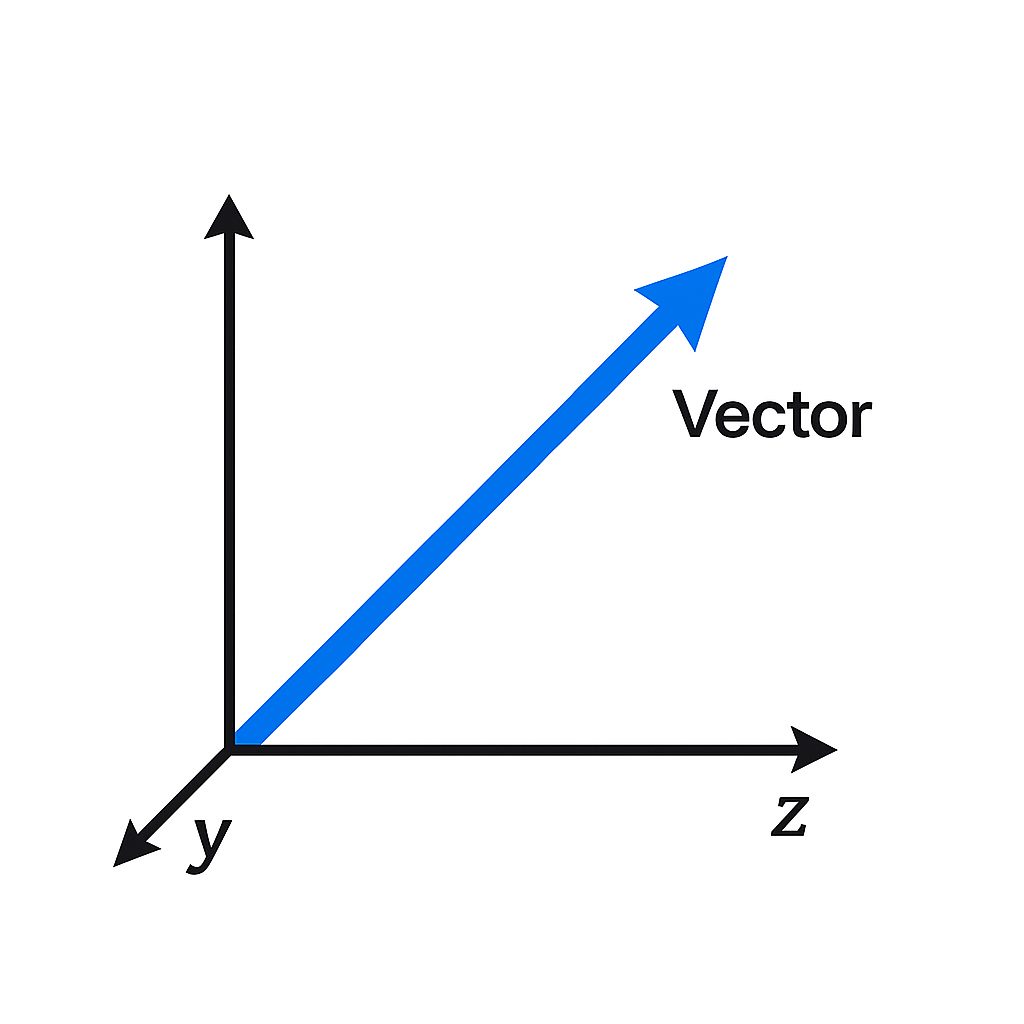
それにより同じ方向を向いているベクトルは同じ意味を含んでいる、という数式計算が実現します。例えば猫とイルカをベクトル化した場合、同じくベクトル化された犬は猫のベクトルと数学的に近しいものになります。イルカよりは猫の方が存在として近いという意味です。
なお利用する埋め込みモデルにより異なりますが、与えられた文字列の意味を解析して、数百から数千次元のベクトルを生成します。
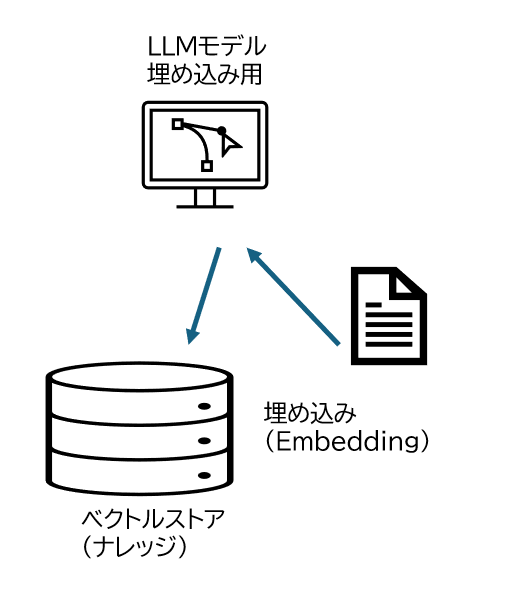
ベクトル化された文字列は、ベクトルと文字列がセットで保存されます。
ここで使われるモデルはある程度軽量なものでも精度がそこまで劣化しないといわれています。高度な会話能力がそれほど求められないためです。ローカルLLM活用の可能性がここに一つあります。
質問:プロンプトのベクトル化とナレッジへのベクトル検索
では次に、作成されたナレッジをもとにどのように質問を処理するかを見ていきます。
前の工程で、ベクトルストアには検索に利用される文字列のかけらがベクトル化されて格納されています。ここに対して質問を行う場合(質問のことをプロンプトと言います)、まずはその質問内容を埋め込みと同様に意味をもとにしたベクトル化します。
図にすると以下のようになります。簡略化されて左の図で表されますが、実際は右の図のような動作になります。
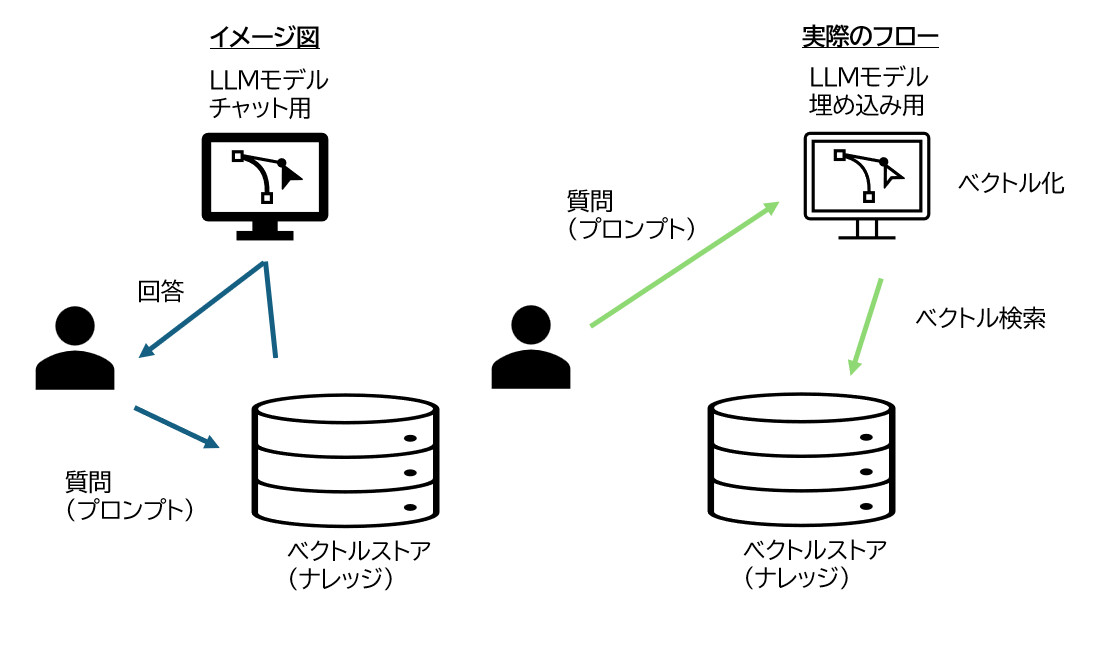
ベクトルストアにはすでに前もって埋め込まれているベクトルと元の文字列がペアで保存されていますので、プロンプトと近しい意味を持つ文字列が出てきます。
回答の生成
最後は、ナレッジから出てきた文字列をもとにきれいな回答を生成して返答を行う工程です。ベクトルはこの時点でもう不要です。埋め込みに使用するモデルとチャット用に使用するモデルは、たとえ同じサービスのものであっても技術的には別物で、チャットに使用するモデルはベクトルデータを理解できません。
この際、ナレッジから複数の候補が戻ってきた場合は、LLMモデルがそれら複数の回答をマージして一つの回答する、などの作業を行います。
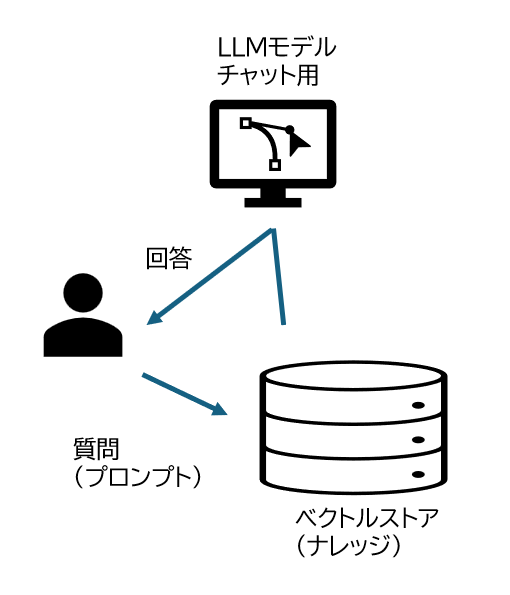
ユーザーが質問を行ってから回答が行われるまで、2回LLMが呼び出されることになります。また前もってベクトルストアに埋め込みを行う作業が消費するトークンも考えると、通常のチャットに比べてLLMの利用コストが高いことがわかります。埋め込み用LLMは最新版を使わなくても性能劣化が緩やかというのが一般的な考え方なので、ここをローカルLLMに置き換える需要は今後増えていくはずです。(もちろん本当に性能劣化が緩やかなのかは検証が必要です)
さっそくやってみる
今まで見てきたように、RAGを実際に作ろうとすると複数の処理を実装する必要があり結構複雑です。Difyを使うとこれらがノーコードでできてしまうのがすごいところです。
1. 高火力 DOKへモデルの追加
まずは埋め込み専用モデルを前回の高火力 DOKに追加します。
curl -X POST https://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/models/apply \
-H "Content-Type: application/json" \
-d '{
"id": "granite-embedding-107m-multilingual",
"name": "granite-embed-jp"
}'もしバージョンアップなどでこれらが存在していない場合、以下を実行すれば利用可能なモデル一覧が出てきます。
curl -s https://e29b4acd-154d-4052-8911-193e2c394e3d.fdc6803e-d244-4eeb-b3a7-ada1aef73898.container.sakurausercontent.com/models/available | grep -o '"name":"[^"]*"' | grep -i "embed""name":"qwen3-embedding-4b"
"name":"qwen3-embedding-8b"
"name":"qwen3-embedding-0.6b"
"name":"granite-embedding-107m-multilingual"
"name":"granite-embedding-125m-english"
"name":"bert-embeddings"
"name":"nomic-embed-text-v1.5"2. 埋め込みモデルのDifyへの組み込み
前回llama3.2-1bをインストールした環境からモデルの追加を選択します。
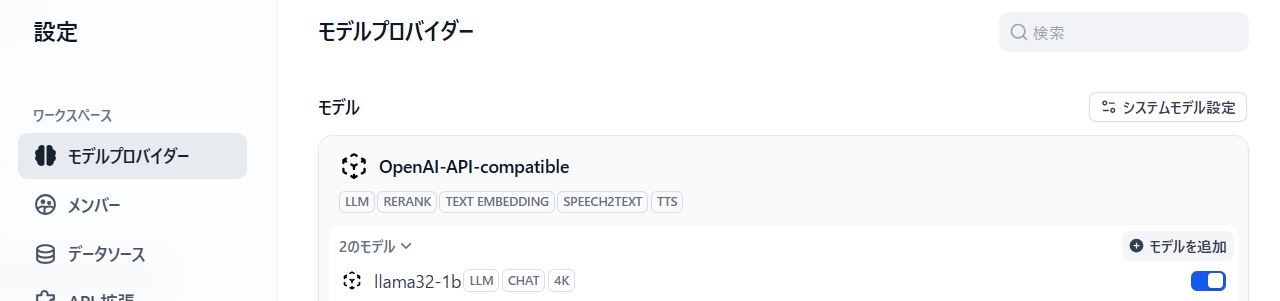
今度はTEXT Embeddingを選択し、granite-embed-jpを入力します。
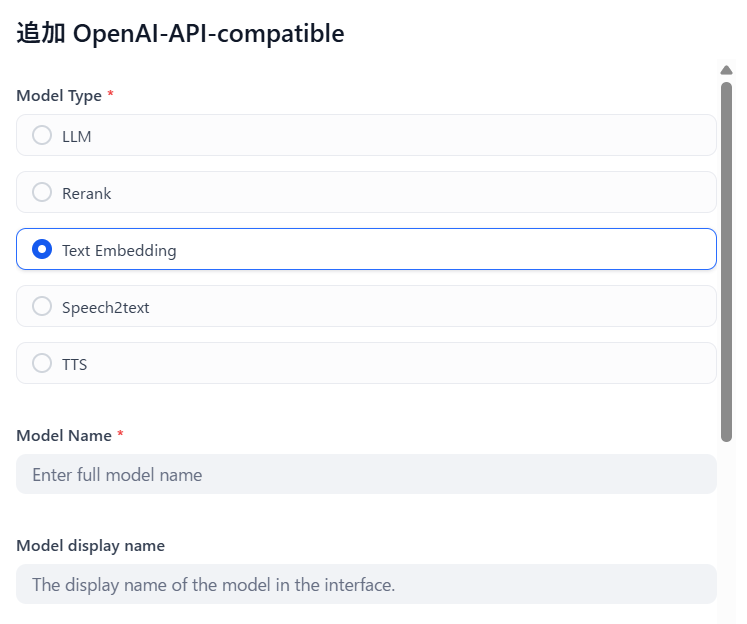
API endpoint URLは前回と同じです。

保存をクリックすると自動で疎通を行い、疎通が取れれば完了です。このようにモデルがもう一つ追加されます。
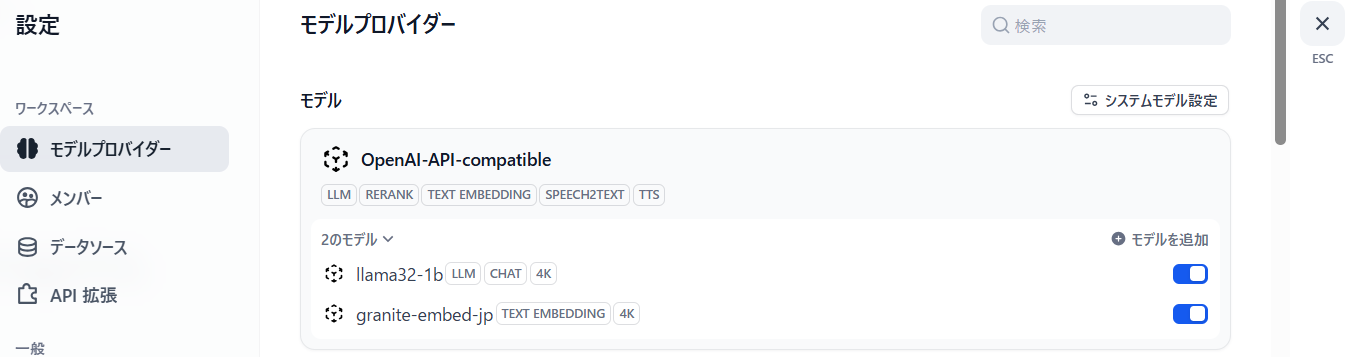
3. ナレッジの作成
コンソールのトップ画面に戻り、画面上部のナレッジタブに移動し、ナレッジベースを作成をクリックします。
適当なPDFを選んで次へをクリックします。
政府が発行している「個人情報の保護に関する基本方針」などはナレッジの作成テストによさそうです。
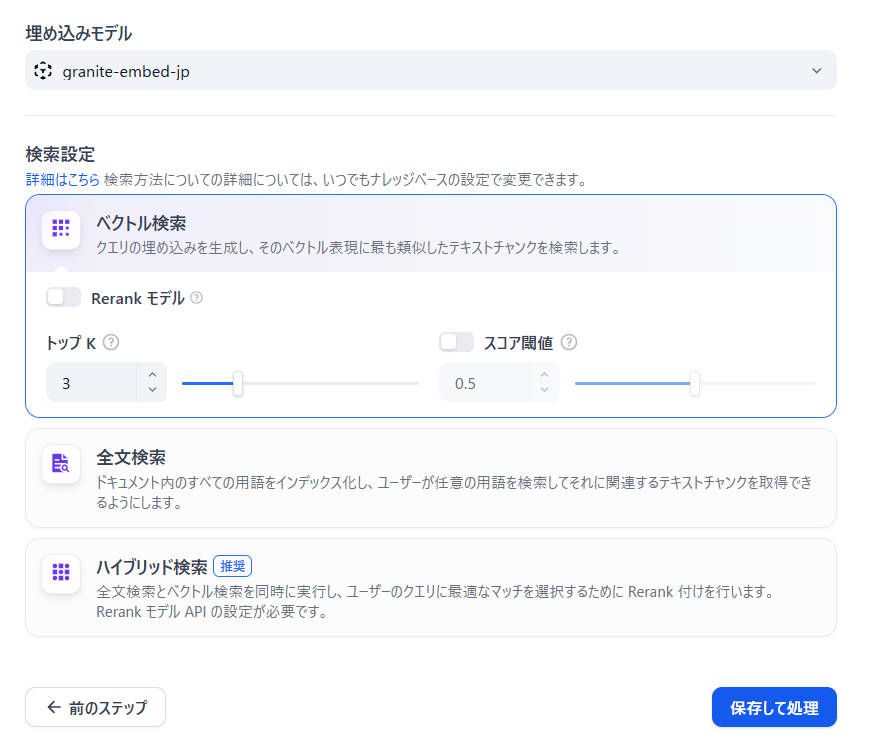
次の画面ではいろいろ設定項目が出てきますが、このあたりは精度にかかわるチューニングになります。今回はそのままデフォルトで行きます。埋め込みモデルは今回追加したモデルを選択します。保存して処理をクリックすると埋め込みが開始されます。
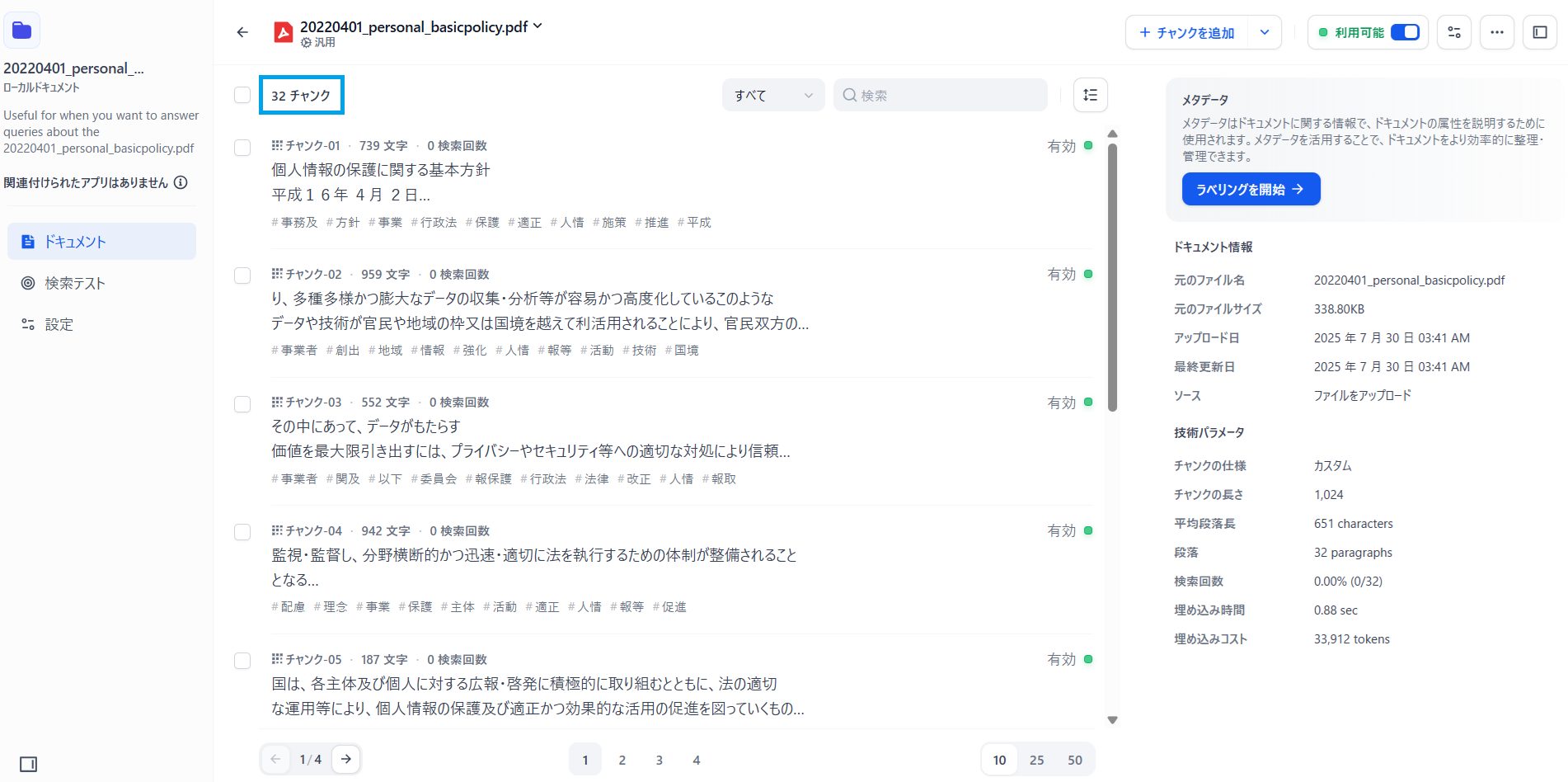
しばらく待つとナレッジができあがります。詳細画面を見ると、元のPDFファイルに書かれていた文章が32に分解されてベクトル化されたことがわかります。
4. RAGアプリの作成
次にスタジオへ移動しテンプレートから作成をクリックします。
Knowledge Retrievalを指定してクリックします。

以下のようにアプリケーションの大枠が起動します。

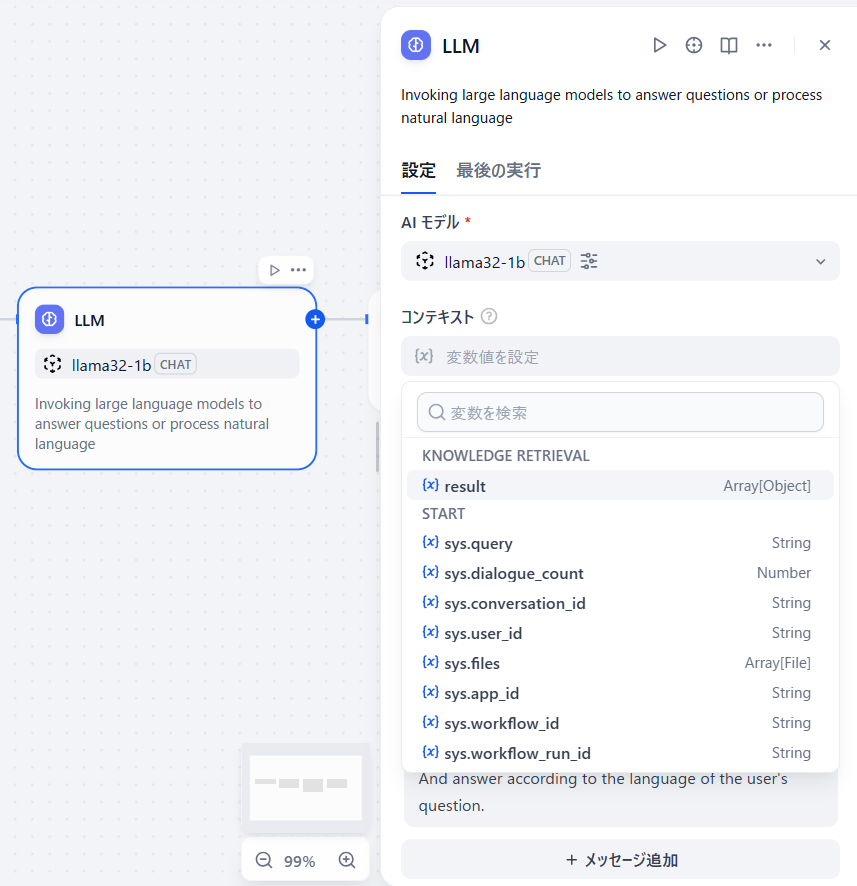
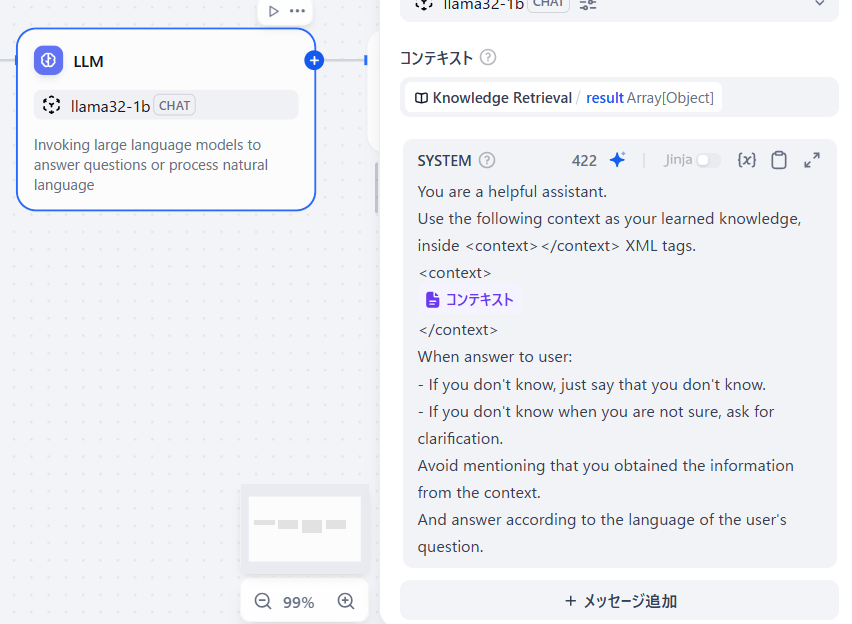
まずLLMブロックをクリックしてモデルを変更します。デフォルトはOpenAIになっていますが、ここは過去に作成したllamaを指定します。そのあと、コンテキストにKNOWLEDGE RETRIEVALのresultを選びます。これはllamaに対して質問を行うときに「先ほど作成したナレッジに対するベクトル検索の結果を使ってね」という意味です。
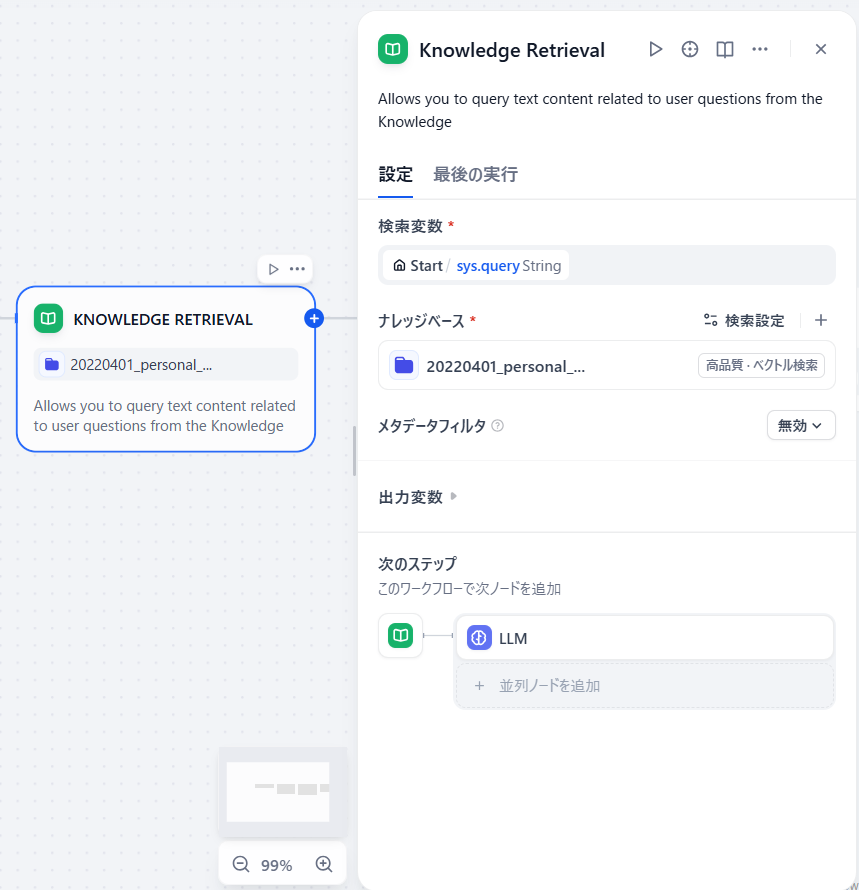
次にKNOWLEDGE RETRIEVALブロックで、先ほど作成したナレッジを選びます。
5. テスト
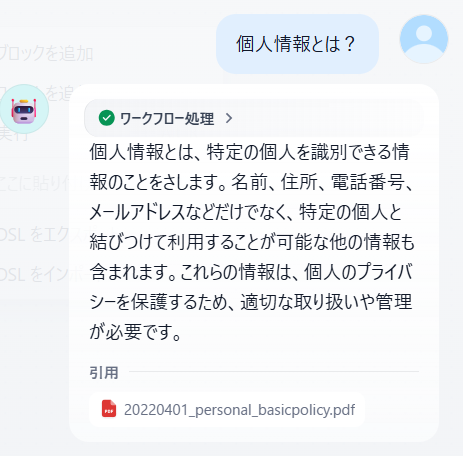
プレビューをクリックして質問を行うと、質問が返ってきます。
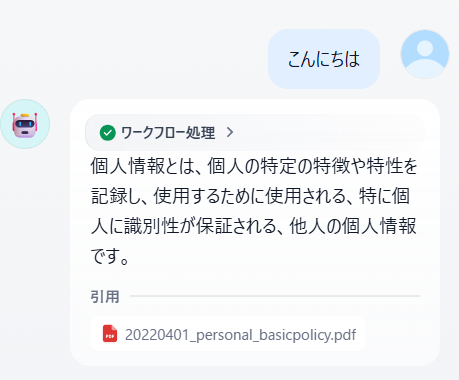
試しにチャット用モデルをGPT4に変えると少し返答が長くなりますが、そこまで返答内容が異なるわけではないことがわかります。
まとめ
4回の連載でローカルLLMを活用したチャットボットやRAGの構築を行っていきました。Difyにはまだまだいろんな機能がありますし、GPUもいろいろな使い方がありますので、気になるテーマがありましたら是非ご意見をお寄せください。