さくらのAI Engine ことはじめ(1):基本(チャット)機能とRAG、MCPによる自然言語検索

さくらのAI Engine とは
本日『さくらのAI Engine』という新しいサービスがリリースされました。さくらインターネットでは「AIの力をすべての人に届ける」をスローガンに、データ安全性が高く、透明性の高い料金形態をもつ生成AIプラットフォームを提供していました。今回のサービスリリースに伴い名称を「さくらのAI」に変更いたします。これは複数のサービスから構成されるサービスの総称となっています。
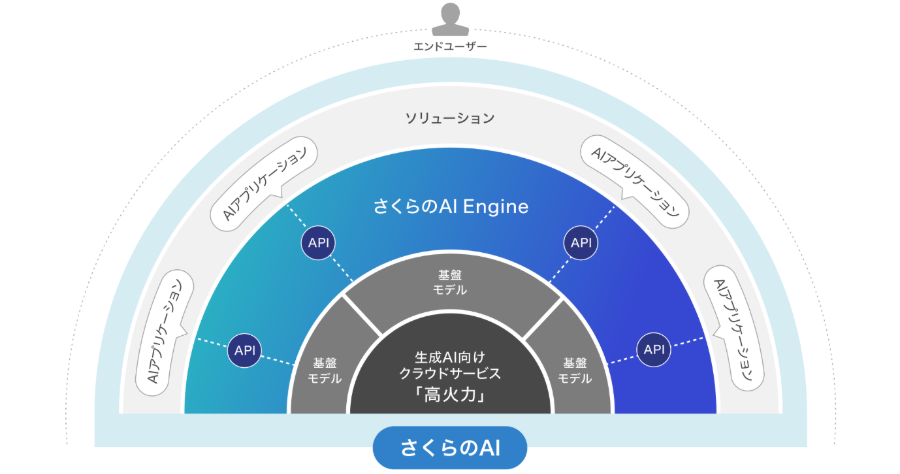
今回新たにリリースされた『さくらのAI Engine』は従量課金型でAPIを介して大規模言語(LLM)モデルを利用いただくサービスです。さくらインターネットが自社データセンターで複数のLLMモデルをホスティングしており、API経由でPOSTされたデータは学習に再利用されず、必ず日本国内にとどまることを保証するサービスです。
企業にとっての生成AIと解決すべき課題
データセキュリティ
生成AIの進化は目覚ましく、その利便性はすでに明らかな現状を鑑み、多くの企業にとってはすでに、使うべきか否か?という段階から、どう利用すべきか?という検討にシフトしています。この時に考えるべき課題がデータの安全性です。
すでにクラウドコンピューティングは民間企業だけではなくガバメントクラウドとして公的な基盤にも採用されています。それらの多くはデータが自分たちの手で管理可能であり、クラウド上に作成した疑似的な自組織ネットワークにとどまることを前提としています。
生成AI利用では、従来のクラウド環境に加えて、そこからさらにLLMモデルのエンドポイントへの通信(OpenAIやAnthropic等)が発生し、考慮すべきセキュリティ項目が増大します。『さくらのAI Engine』はOSSモデルやオープンウェイトモデルのLLMを活用し、さくらインターネットが自社DCでホスティング可能なLLMモデルのみを提供しているため、高いデータセキュリティを実現することができます。

ローカルLLMと OSSモデル/オープンウェイトモデル
近年、機密データを扱う企業では、セキュリティ確保や独自カスタマイズの観点からローカルLLMへの関心が高まっています。ローカル環境で動かすLLMには、OSSとして公開されたコードや、学習済みの重みが公開されたオープンウェイトモデルが多く活用されています。精度の高いモデルも増えており、閉域網でも利用できるため機密性の確保に優れています。ただし、企業が自前でGPUを確保し安定運用するのは依然として大きな負担です。
『さくらのAI Engine』ではこの課題を解決し、高いデータ安全性を確保した環境を提供します。
コストコントロール
生成AIは、固定的なスキーマやデータモデルを持たず、形式がバラバラな情報である自然言語の解析を実現しました。さらに、画像や音声等非構造化データの処理も可能になり進化が続いています。一般的に、ある組織が保有するデータの7割以上は非構造化データであるといわれています。生成AIの進化により従来のAI技術では実現できなかった領域のデータ蓄積と解析が可能となりました。
生成AIのサービスはその多くが従量課金型であり消費した処理量(トークン)により課金されることが一般的です。組織にとって、電気代や電話代、クラウドコンピューティングのように従量課金型のサービスは一般化しており、生成AIの利用も同様に利用量に応じた課金が発生します。生成AIは今後も進化を続け組織が行う活動のほぼ全域に影響を及ぼします。例えば単純なチャットでも数円から数十円の課金が発生し、これが組織全域にわたり一日中発生し続けることになります。
『さくらのAI Engine』も同様に従量課金型ですが、さくらインターネットではそれと連携する高火力シリーズというクラウド型GPUサービスを展開しています。
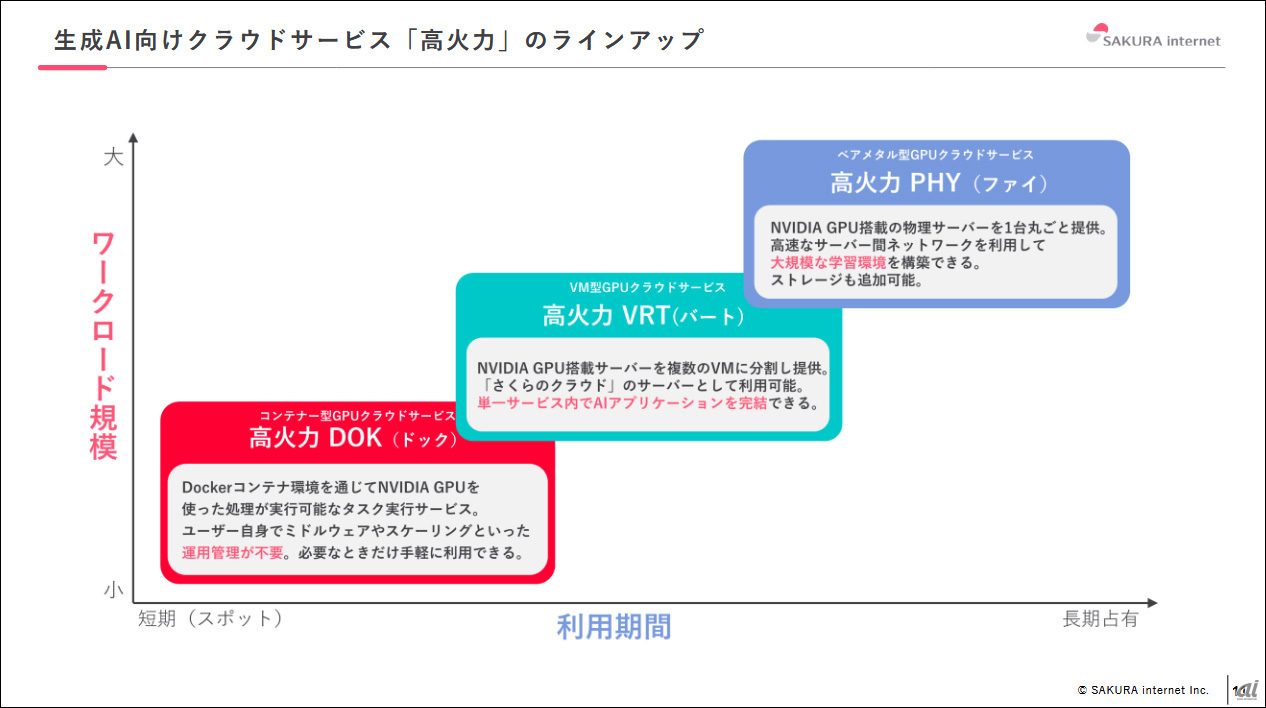
これらのサービスは月額固定費用でGPUを組織用に専有できます。高火力を利用して自組織でオープンLLMモデルをインストールすれば、コストコントロールが容易なローカルLLM環境を構築できます。こうした別サービスと併用できる点が、「さくらのAI」の特徴です。
さっそくやってみる
1. API用トークンの発行とチャットAPIのテスト
無料プランや無料利用枠付き有償プランがありますのでこちらからサインアップを行います。
公式マニュアルの利用手順にハンズオン手順が含まれていますので、それに沿ってまずはトークンの発行とチャットのテストを行います。
2. Retrieval-Augmented Generation(RAG)チャットの構築
LLMが外部の知識ベースやドキュメントを検索(Retrieval)し、その検索結果を入力として取り込みながら応答を生成(Generation)する手法です。これによりLLMは本来知りえない企業内部のドキュメントや最新のニュースなどを回答することができます。
公式マニュアルやAPIドキュメントにはcurlを使った手順が記載されていますので、このブログでは別の方法として、nodeを活用したプログラムでその機能を紹介していきます。
2.1. PDFの準備
まずはRAGの外部知識ベースとして適当なPDFを準備して登録します。このブログでは個人情報の保護に関する基本方針という政府文書を登録します。
.envファイルで以下の内容を作成します。(トークンの値はユーザごとに異なります)
SAKURA_AI_TOKEN=xxxx9d20-121f-49e1-a4c4-c24e0bfc0705:xxxx6YV7prVriKR/oPtfFnyNg5Ye+4SELsDeLGMr以下の内容でupload.mjsを作成します。
import fs from "fs";
import fetch from "node-fetch";
import FormData from "form-data";
import dotenv from "dotenv";
// .env ファイルの内容を読み込む
dotenv.config();
const API_URL = "https://api.ai.sakura.ad.jp/v1/documents/upload/";
const TOKEN = process.env.SAKURA_AI_TOKEN; // .envから取得
const FILE_PATH = "test.pdf"; // アップロードするファイル
if (!TOKEN) {
console.error(".env に SAKURA_AI_TOKEN が設定されていません。");
process.exit(1);
}
async function uploadFile() {
try {
const form = new FormData();
form.append("file", fs.createReadStream(FILE_PATH));
const response = await fetch(API_URL, {
method: "POST",
headers: {
Accept: "application/json",
Authorization: `Bearer ${TOKEN}`,
...form.getHeaders(),
},
body: form,
});
if (!response.ok) {
throw new Error(`HTTP error! Status: ${response.status}`);
}
const result = await response.json();
console.log("アップロード成功:", result);
} catch (error) {
console.error("アップロード失敗:", error);
}
}
uploadFile();実行に必要なライブラリをインストールします。
npm install node-fetch form-data dotenvでは実行してみます。このサンプルではupload.mjsと同じフォルダにあるtest.pdfをアップロードします。
node upload.mjs
[dotenv@17.2.2] injecting env (1) from .env -- tip: ⚙️ enable debug logging with { debug: true }
アップロード成功: {
id: 'c840506a-0017-4fb7-b6dd-5b56e7bedaa5',
status: 'pending',
content: '',
name: 'test.pdf',
tags: [],
model: 'multilingual-e5-large'
}pendingと表示されれば処理待ちのキューに登録が成功しています。しばらく待つとコントールパネルでステータスがavailableとなり登録が完了します。AI EngineのRAGデータ取り込みは512トークン単位で文章が分割され、ベクトル化された値と元の文章がペアで保存されます。
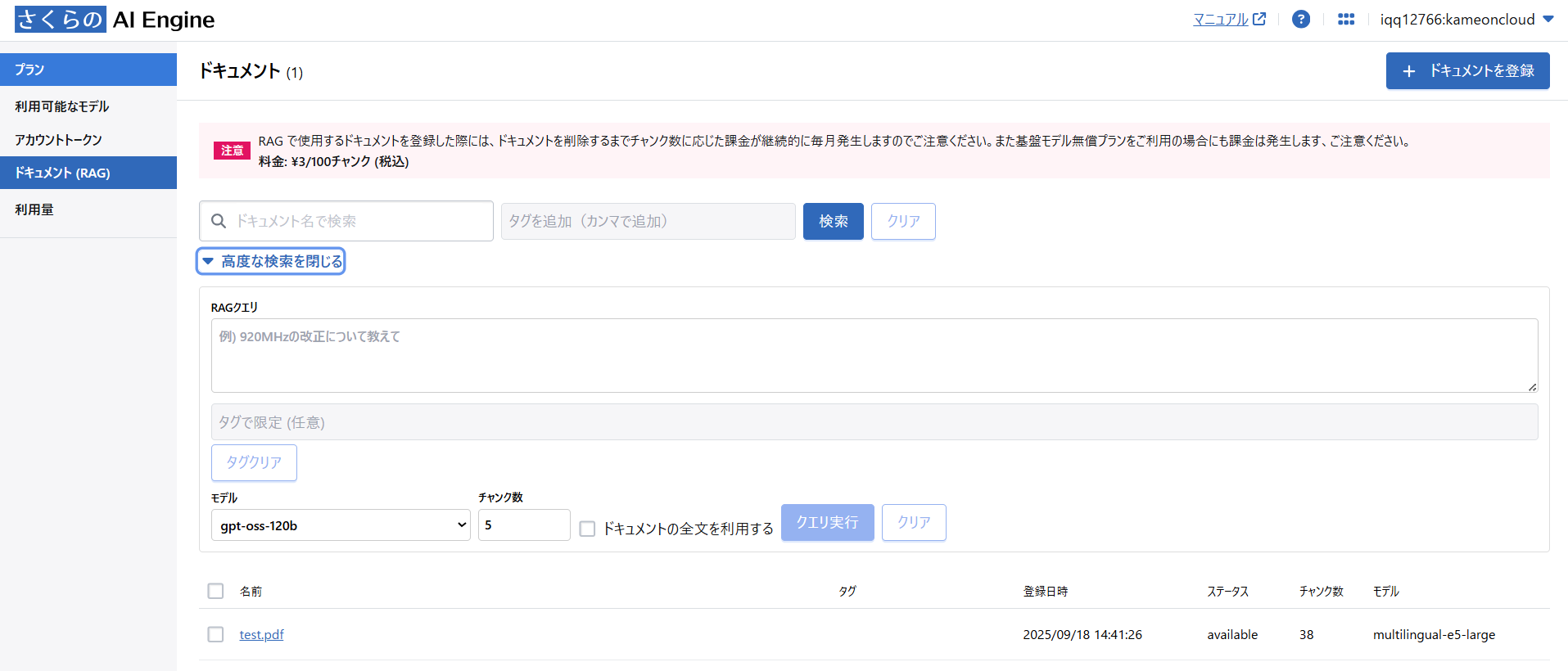
2.2. RAG検索
ではRAG検索を行っていきます。RAG検索は通常以下のステップが必要です。
- 質問文をベクトル化
- ベクトル化された値を用いて、RAGの外部知識ベース(ベクトルストア)に対して検索を実施
- この際、数値化されたベクトルには言葉の意味が含まれているため、近しい言葉の意味を持つ別の文章を検索結果として出力できるのがこの記述の大きな特徴です。
- 例えば「犬」「猫」「イルカ」をベクトル化すると数学的に「犬」と「猫」が近しいものになります。
- 検索結果として出力された分割後の元の文章をLLMが自然な日本語にして回答を生成
AI Engineでは1と2を一つのエンドポイントで同時に処理してくれるので便利です。
それでは実際にやってみましょう。search.mjsというファイルを以下の内容で作成します。
/**
* RAG minimal sample:
* 1) Query vector store (/v1/documents/query)
* 2) Build context prompt
* 3) Call chat completions (/v1/chat/completions)
*/
import 'dotenv/config';
const API_BASE = "https://api.ai.sakura.ad.jp/v1";
const TOKEN = process.env.SAKURA_AI_TOKEN;
if (!TOKEN) {
console.error("ERROR: Please set env SAKURA_AI_TOKEN to your Bearer token.");
process.exit(1);
}
// ---- CLI 引数 ----
// 例: node index.mjs "個人情報とは" --tags=PII --model=gpt-oss-120b
const argv = process.argv.slice(2);
if (argv.length === 0) {
console.error("Usage: node index.mjs \"質問文\" [--tags=tag1,tag2] [--model=gpt-oss-120b]");
process.exit(1);
}
const USER_QUERY = argv[0]; // 最初の引数を質問に
const argPairs = argv.slice(1).map((a) => {
const m = a.match(/^--([^=]+)=(.*)$/);
return m ? [m[1], m[2]] : [a.replace(/^--/, ""), true];
});
const args = Object.fromEntries(argPairs);
const TAGS = (args.tags ? String(args.tags).split(",") : []).filter(Boolean);
const MODEL = args.model || "gpt-oss-120b";
const TEMPERATURE = args.temperature != null ? Number(args.temperature) : 0.7;
const MAX_TOKENS = args.maxTokens != null ? Number(args.maxTokens) : 1000;
const TOP_K = args.topK != null ? Number(args.topK) : 5;
async function httpJson(url, opts = {}) {
const res = await fetch(url, {
...opts,
headers: {
Accept: "application/json",
Authorization: `Bearer ${TOKEN}`,
...(opts.headers || {}),
},
});
const text = await res.text();
if (!res.ok) throw new Error(`HTTP ${res.status} ${res.statusText}: ${text}`);
return text ? JSON.parse(text) : {};
}
/** ベクトル検索 */
async function vectorQuery({ query, tags }) {
const url = `${API_BASE}/documents/query/`;
const payload = { query, tags };
const json = await httpJson(url, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(payload),
});
const candidates = json?.results || json?.documents || json?.matches || json?.items || [];
const toText = (it) =>
it?.text ?? it?.content ?? it?.chunk ?? it?.document?.text ?? it?.document?.content ?? "";
const normalized = candidates
.map((it) => ({
id: it.id ?? it.document_id ?? null,
name: it.name ?? it.title ?? null,
score: it.score ?? it.similarity ?? null,
text: String(toText(it) || "").trim(),
}))
.filter((it) => it.text);
normalized.sort((a, b) => (b.score ?? 0) - (a.score ?? 0));
return normalized.slice(0, TOP_K);
}
/** プロンプト組み立て */
function buildMessages({ userQuery, snippets }) {
const ctx = snippets
.map((s, i) => `#${i + 1}${s.name ? " " + s.name : ""}\n${s.text.slice(0, 500)}`)
.join("\n\n");
const system =
"You are a helpful assistant. Answer in Japanese. Use the provided context faithfully.";
const user = `質問: ${userQuery}\n\n参照コンテキスト:\n${ctx || "なし"}`;
return [
{ role: "system", content: system },
{ role: "user", content: user },
];
}
/** Chat 完了 */
async function chatComplete({ model, messages, temperature, max_tokens }) {
const url = `${API_BASE}/chat/completions`;
const payload = { model, messages, temperature, max_tokens, stream: false };
const json = await httpJson(url, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(payload),
});
return (
json?.choices?.[0]?.message?.content ??
json?.choices?.[0]?.text ??
json?.output ??
""
);
}
(async () => {
console.log("Vector query:", USER_QUERY, "tags:", TAGS);
const snippets = await vectorQuery({ query: USER_QUERY, tags: TAGS });
console.log(`→ ${snippets.length} snippet(s) found`);
const messages = buildMessages({ userQuery: USER_QUERY, snippets });
const answer = await chatComplete({
model: MODEL,
messages,
temperature: TEMPERATURE,
max_tokens: MAX_TOKENS,
});
console.log("\n RAG Answer:\n");
console.log(answer);
})();node search.mjs "<質問文>" として実行すればRAG検索が行われます。
node search.mjs "個人情報とは"
Vector query: 個人情報とは tags: []
→ 3 snippet(s) found
RAG Answer:
**個人情報とは**
日本の個人情報保護法に基づく概念で、**「生存する個人に関する情報で、当該情報に含まれる氏名、生年月日、住所、電話番号、メールアドレス等、あるい はこれらと結びつけて特定の個人を識別できる情報」** を指します。
---
### 主なポイント(参照コンテキストから抜粋)
1. **識別可能性**
- 氏名・住所・電話番号など直接的に本人を特定できる情報だけでなく、**行動履歴、政治的立場、経済状況、趣味・嗜好などの高精度な推定情報(いわゆるプロファイリング)** も、他のデータと組み合わせて個人を識別できれば個人情報に該当します。
2. **取扱いの拡大とリスク**
- 高度なデジタル技術(顔認識・AI等)により、**個人情報が公益のために活用される機会が増えている** が、同時に不適正利用が起これば個人の権利・ 利益への大きな侵害リスクが高まります。
- 「自分の個人情報が悪用されるのではないか」という不安感が社会全体で広がっています。
3. **外部委託・国外移転への配慮**
- クラウドサービスやSNSなど外部事業者に個人情報を提供する場合、**適切な監督や安全管理措置、本人の事前同意取得、そして国外の個人情報保護制度 に関する情報提供** が求められます。
4. **個人のデータリテラシー向上**
- 法律の正しい理解や、**情報提供・説明義務、開示請求権、第三者提供の事前同意** などの権利行使を通じて、個人が自らの情報をコントロールできる 意識を育むことが重要です。
---
### まとめ
個人情報は「**特定の個人を識別できる情報全般**」であり、名称や連絡先といった直接的情報だけでなく、行動や嗜好といった間接的情報も含まれます。デ ジタル技術の進展に伴い取扱いは拡大していますが、**適正な管理・利用と本人の権利保護** が不可欠です。個人自身もデータリテラシーを高め、権利行使できる環境を整えることが、個人情報保護の実効性を高める鍵となります。3. RAG外部知識ベースのMCP化
一般的に、RAGは独立して動作し内部でLLMを呼び出し、結果を自然な日本語として回答を戻します。繰り返しになりますが、質問から回答作成まで以下のステップが実行されます。
- 質問文をベクトル化
- ベクトル化された値を用いて、RAGの外部知識ベース(ベクトルストア)に対して検索を実施
- 検索結果として出力された分割後の元の文章をLLMが自然な日本語にして回答を生成
AI EngineのRAGエンドポイントにはもう一つ、ベクトル検索のみを行い上記項番3を行わないAPIが提供されています。例えばClaude Desktopなど直接的にLLMと対話するクライアントを使っている場合、項番1,2のみを行い項番3は利用しているクライアントがデフォルトで利用しているLLMを利用する方が会話の一貫性が生まれます。
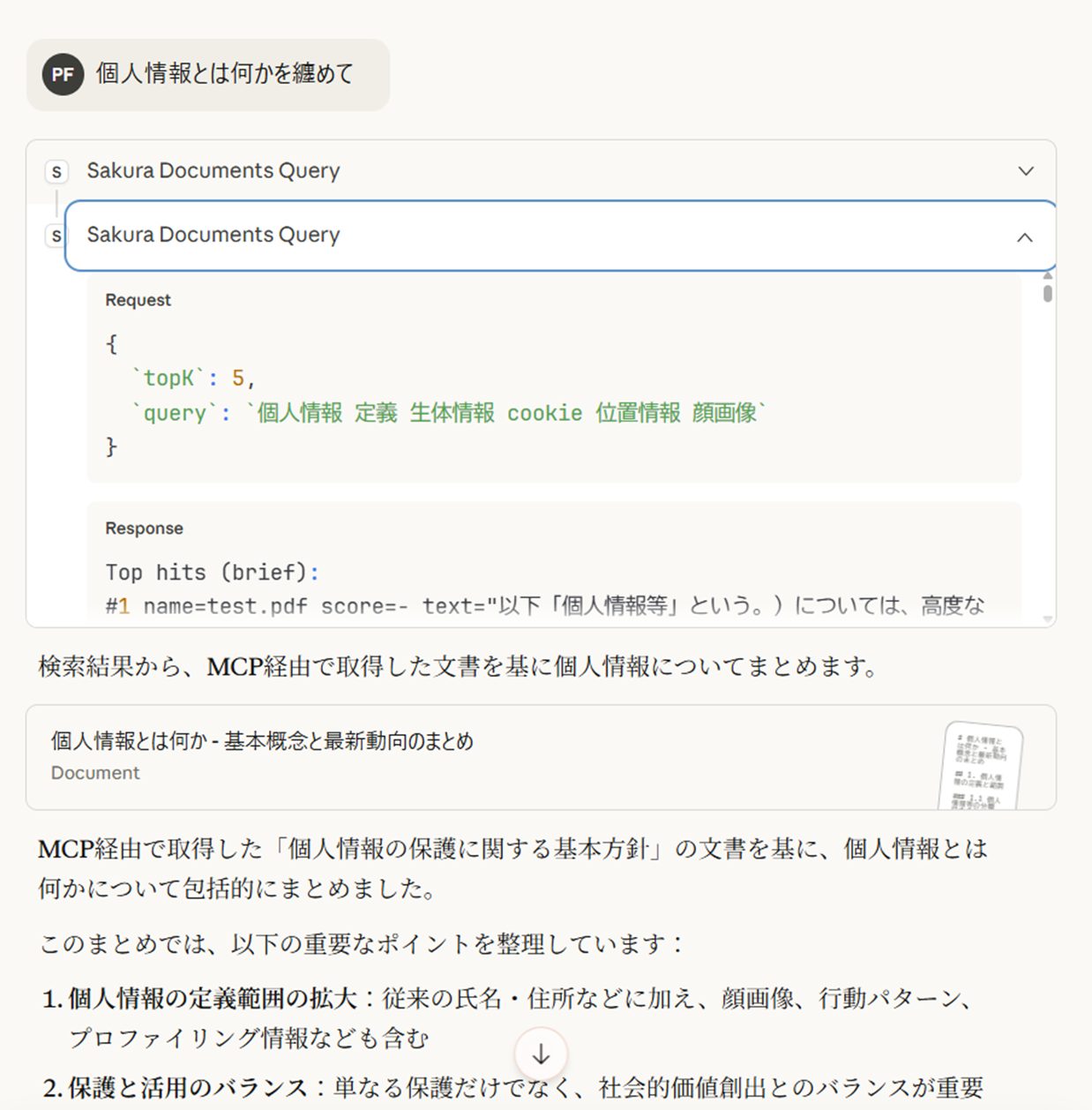
それを実現する技術の一つとしてMCP(Model Context Protocol)があります。MCPとはクライアントがLLMと対話を行う中で、LLM側の判断で必要に応じて外部ツール(MCP Server)を呼び、その回答をLLMが自然な言語に整形して回答文を作成します。AI EngineのRAG外部知識ベースへの検索エンドポイントをMCPプログラム化したものが以下です。これをmcp.mjsとして保存します。
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const API_BASE = process.env.SAKURA_AI_BASE_URL || "https://api.ai.sakura.ad.jp/v1";
const TOKEN = process.env.SAKURA_AI_TOKEN;
if (!TOKEN) {
console.error("ERROR: env SAKURA_AI_TOKEN is required (Bearer token).");
process.exit(1);
}
async function httpJson(url, opts = {}) {
const controller = new AbortController();
const timeoutMs = opts.timeoutMs ?? 30000;
const timer = setTimeout(() => controller.abort(), timeoutMs);
try {
const res = await fetch(url, {
...opts,
headers: {
Accept: "application/json",
Authorization: `Bearer ${TOKEN}`,
...(opts.headers || {}),
},
signal: controller.signal,
});
const text = await res.text();
if (!res.ok) {
throw new Error(`HTTP ${res.status} ${res.statusText}\n${text?.slice(0, 2000) || ""}`);
}
if (!text) return {};
try {
return JSON.parse(text);
} catch {
throw new Error(`Failed to parse JSON:\n${text?.slice(0, 2000)}`);
}
} finally {
clearTimeout(timer);
}
}
const server = new McpServer({ name: "sakura-docquery-mcp", version: "1.0.0" });
server.registerTool(
"sakura_documents_query",
{
title: "Sakura Documents Query",
description: "Query Sakura AI vector store (POST /v1/documents/query/).",
inputSchema: {
query: z.string().min(1, "query is required"),
tags: z.array(z.string()).optional(),
topK: z.number().int().positive().max(50).optional(),
timeoutMs: z.number().int().positive().max(120000).optional(),
},
},
async ({ query, tags, topK, timeoutMs }) => {
const payload = { query, ...(Array.isArray(tags) && tags.length ? { tags } : {}) };
const url = `${API_BASE}/documents/query/`;
const json = await httpJson(url, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(payload),
timeoutMs,
});
const candidates = json?.results || json?.documents || json?.matches || json?.items || [];
const toText = (it) =>
it?.text ?? it?.content ?? it?.chunk ?? it?.document?.text ?? it?.document?.content ?? "";
let normalized = candidates
.map((it) => ({
id: it.id ?? it.document_id ?? it.doc_id ?? null,
name: it.name ?? it.title ?? it.document?.name ?? null,
score: it.score ?? it.similarity ?? null,
text: String(toText(it) || "").trim(),
meta: it.meta ?? it.metadata ?? it.document?.metadata ?? null,
}))
.filter((n) => n.text);
normalized.sort((a, b) => (b.score ?? 0) - (a.score ?? 0));
const limit = topK ?? 5;
normalized = normalized.slice(0, limit);
const brief = normalized.map((n, i) => ({
idx: i + 1,
id: n.id,
name: n.name,
score: n.score,
textHead: n.text.slice(0, 160),
}));
const header =
"Top hits (brief):\n" +
(brief.length
? brief
.map(
(b) => `#${b.idx} name=${b.name ?? "-"} score=${b.score ?? "-"} text="${b.textHead}..."`
)
.join("\n")
: "(no results)");
const out = {
topK: limit,
normalized,
raw: json,
};
return {
content: [
{
type: "text",
text: `${header}\n\n-----\nJSON (normalized+raw):\n${JSON.stringify(out, null, 2).slice(0, 50_000)}`,
},
],
};
}
);
const transport = new StdioServerTransport();
await server.connect(transport);
console.error("[sakura-docquery-mcp] stdio server started");次に必要なライブラリをインストールします。
npm i @modelcontextprotocol/sdk@latest あとはLLMクライアントにこのMCP Serverを組み込むことで動作可能となります。よく使われるクライアントであるClaude Codeの手順はこちらになります。
以下の設定ファイルを配置すればClaude DesktopがLLMと対話を行う中で自動でMCP Serverが呼び出されます。
{
"mcpServers": {
"sakura-docquery-mcp": {
"command": "node",
"args": ["<mcp.mjsへのフルパス>"],
"transport": "stdio",
"autoRestart": true,
"env": {
"SAKURA_AI_TOKEN": "<TOKEN>"
}
}
}
}<mcp.mjsへのフルパス> 、 <TOKEN> は皆さんの環境ごとに置き換えてください。Windows環境であればフォルダの指定にエスケープが必要で以下の書式になります。
"C:\\フォルダ名\\フォルダ名\\フォルダ名\\mcp.mjs"
起動が完了したら対話を行うLLMが自身の判断でMCPを呼び出しその検索結果(RAG検索と異なり512トークン単位で分割された文章のかけら)がLLMにより自然な言葉に整形されレスポンスが戻ってきます。
まとめ
この記事では本日リリースされた『さくらのAI Engine』のRAGチャット機能を試してみました。次回の記事では音声の文字起こしモデルを試していきます。まだまだ発展していくサービスです。ご要望などございましたら遠慮なくご連絡いただければ幸いです。