Obsidian CopilotとさくらのAI Engineで実現する、ローカルファーストなナレッジ管理 〜さくらのAI Engineを使いこなす:主要クライアント実践ガイド(1)〜


はじめに
さくらインターネットでプロダクトマネージャーとして働いている荒木です。
さくらのAI Engineは、基盤モデル搭載済みのGPUサーバーで推論処理ができるAPIサービスです。テキスト生成・分類・埋め込み・音声認識などのLLMに対応しており、既存のツールのバックエンドに組み込むことでさまざまなAIアシストを得ることができます。
そこで今回は、私が普段よく使っているクライアントツールを例に、さくらのAI Engineを組み込んで利用する方法をご紹介します。全部で4本の連載を予定しています。今回はObsidian編です。
Obsidianについて
私は日常の業務において、「何を作るか」「どう届けるか」に多くの時間を割いています。そんな仕事のスタイルの中で、ナレッジ管理は欠かせない要素です。
Markdownを使うことで、特定のプラットフォームに依存しないデータの永続的な所有権と可搬性が保証されます。Markdownとローカルファイル管理は、エンジニアが日常的に使用するGitやVS Codeなどのツールと親和性が高く、ナレッジベースをコードリポジトリと同様にバージョン管理することが容易です。
Obsidianは、そんなMarkdown専用エディタであり、Pluginで拡張することでNotionにも負けないツールです。私はMarkdownをローカルで扱うにあたって、Obsidianをここ数年使っています。SaaSではなく、ローカルで完結することも重要なポイントでした。
LLMブームとローカル環境の課題
そこにやってきたのがLLMブームです。
ただ、NotionでなくObsidianを選んだように、外部サービスは使えない(使いたくない)のであればローカルLLMに行き着きます。ローカルLLM実行環境は、セキュリティ、コスト効率、カスタマイズ性の3つの側面で重要でした。
さくらインターネットがさくらのAI Engineを始める前は、ollamaを使ってLocalで様々なLLMを試していました。16GBや36GBのメモリを載せたMacbookで試してきて、それなりに(待てば)なんとかなってきました。
しかし、正直キビシイなと思うことも多く、個人的用途でLLMのAPIを呼び出して使う(OpenRouterなど)と何倍もの速度がでたり、より大型で高性能なモデルであれば解決することも多いことがわかってきました。
そこで選択肢に入ってきたのがさくらのAI Engineです。日本国内でサービスが提供されており、学習に使われることがないという特性は、企業で使う上で重要な要素でした。
Obsidian Copilotの設定
さくらのAI EngineをObsidianで使うには、いくつかのプラグインの選択肢があります。実はObsidianには、OpenAI、Gemini、OpenRouterなど、多数のAPIを呼び出して使うためのプラグインが存在します。
その中でObsidian Copilotでは、さくらのAI Engineがうまく動作しました。設定方法は非常にシンプルです。
必要な設定項目
Obsidian Copilotのインストールは、コミュニティプラグインを閲覧するところから始まります。
閲覧画面では検索ワードを入力できるので、copilotと入れてみると数件がひっかかります。
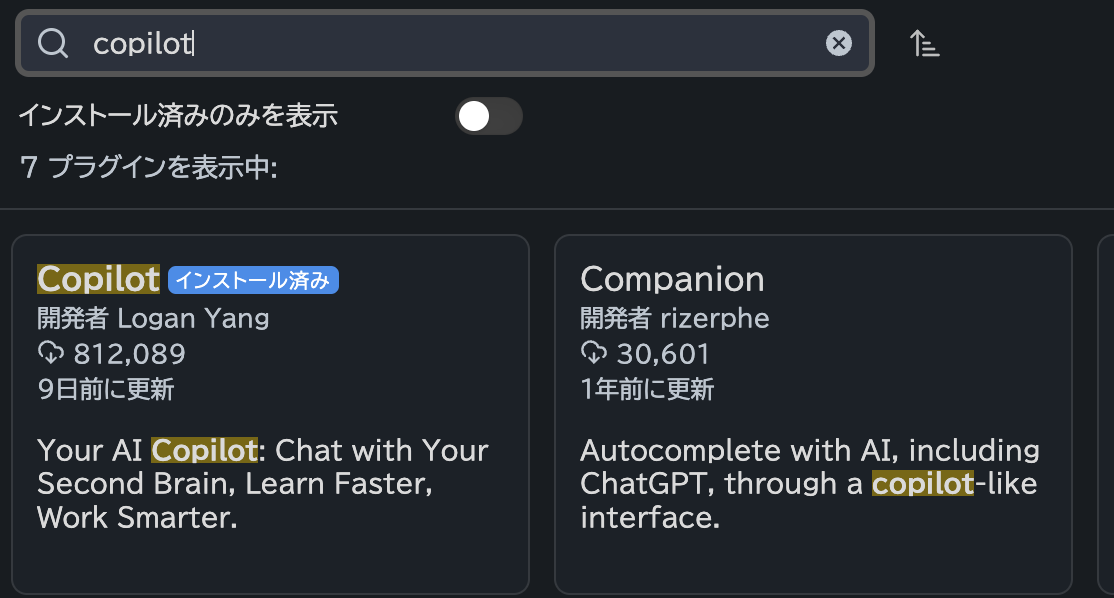
その中からCopilotを選んでインストールし、設定画面にいきます。"+ Add Model" を選びます。

設定で必要なのは以下の3点のみです:
- Base URL:
https://api.ai.sakura.ad.jp/v1 - Model Name: 使用するモデル名(例:
gpt-oss-120b) - API Key: さくらのAI Engineで発行したAPIキー
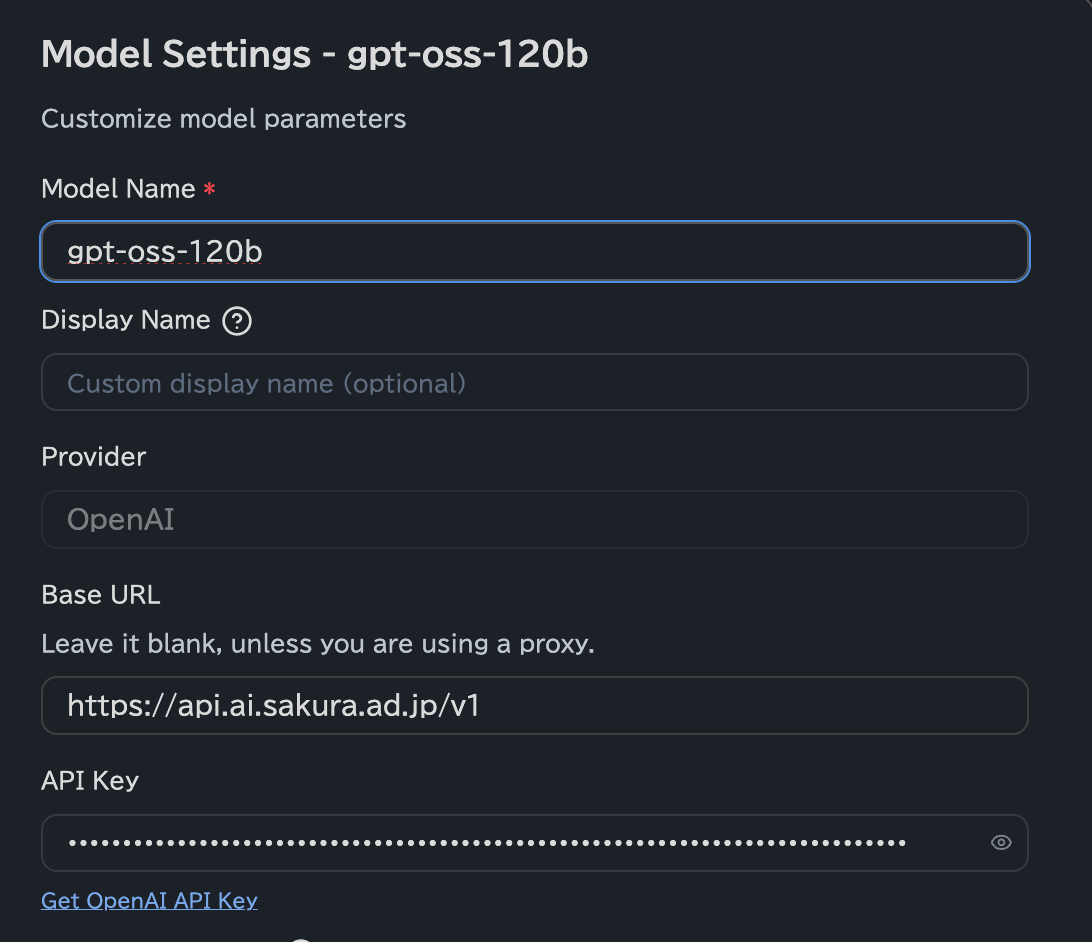
Obsidian Copilot自体はすぐに動作しました。設定完了までの時間は、プラグインのインストールを含めても数分程度です。
ただし、後述しますが、いろんなプラグインを試すことになると、そこでは時間がかかりました。
実際の使用体験
Obsidian Copilotの最大の特徴は、カスタムプロンプト機能です。
カスタムプロンプトの活用
私が設定しているカスタムプロンプトの例を2つご紹介します。
Translate to Japanese
日本語に翻訳してもらうプロンプトです。
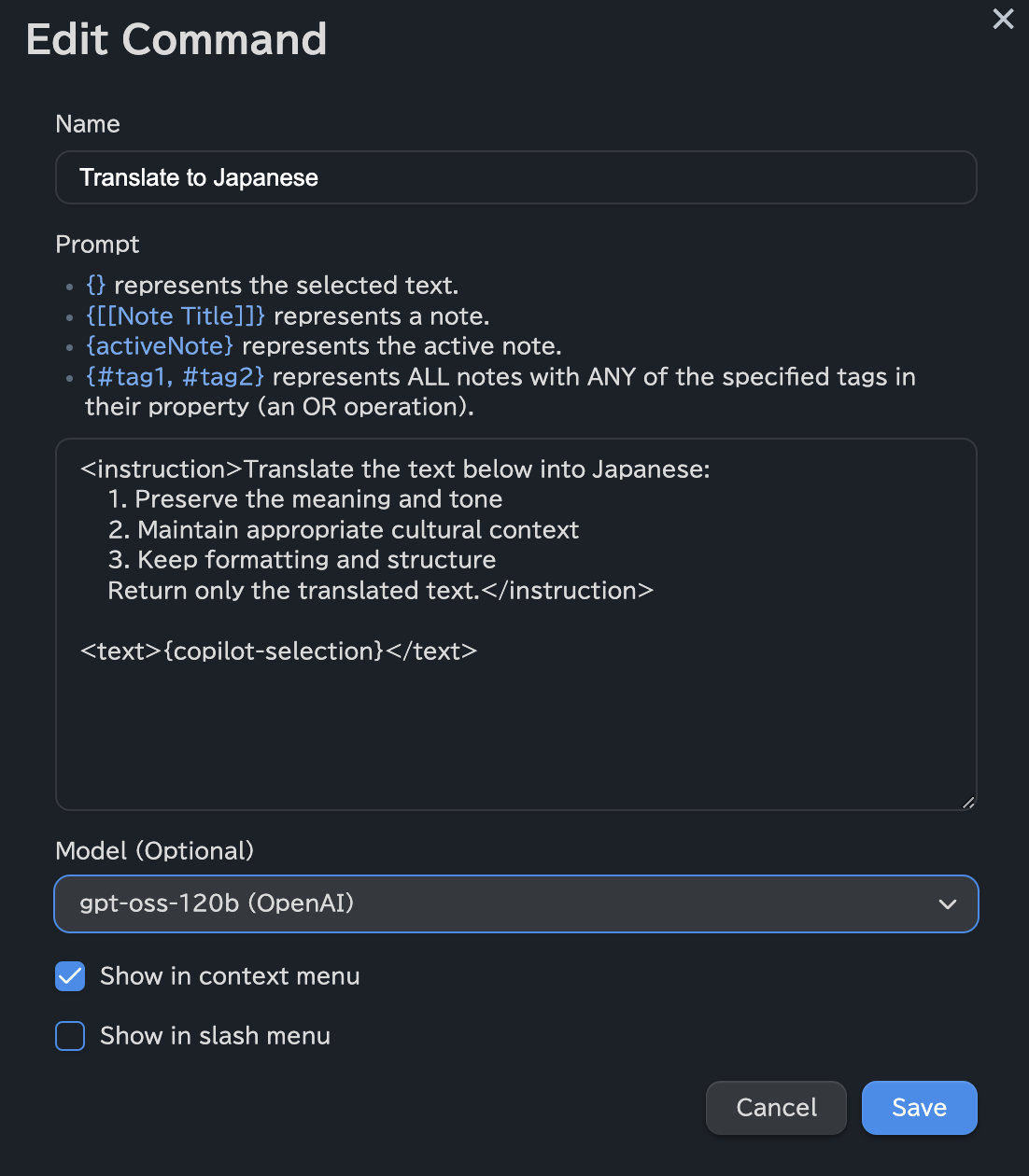
無駄な空行など整理
無駄な空行などを整理して読みやすくするためのプロンプトです。
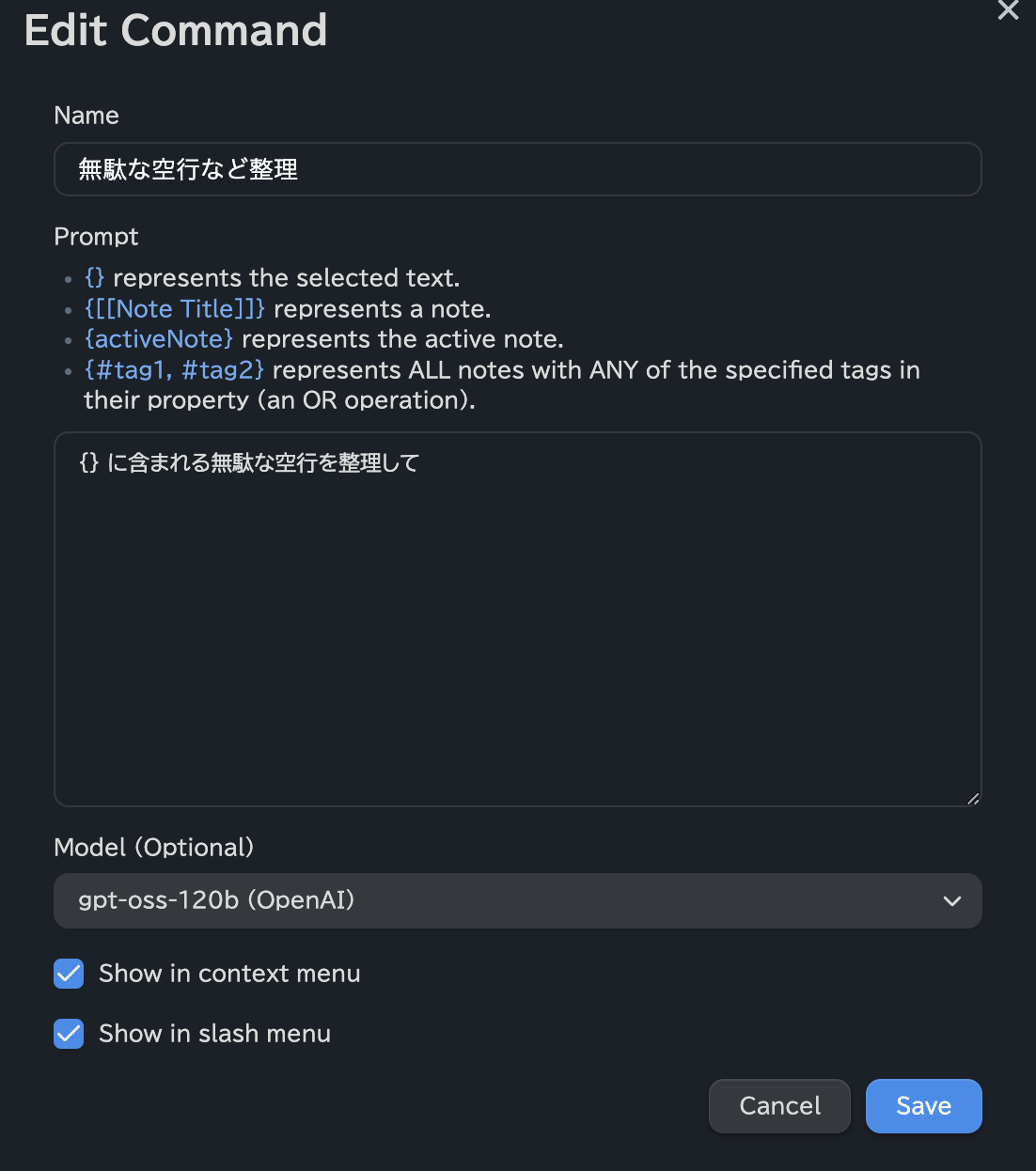
これらのカスタムプロンプトは、マウスで選んだ文字列に対してのみ実行できます。実行結果はReplace(置換)もInsert(挿入)もできるのがとても便利です。
以下に実行例を示します。整形前の文章として以下のものを使用します。

この文面をマウスで選択し、「無駄な空行など整理」プロンプトを適用します。
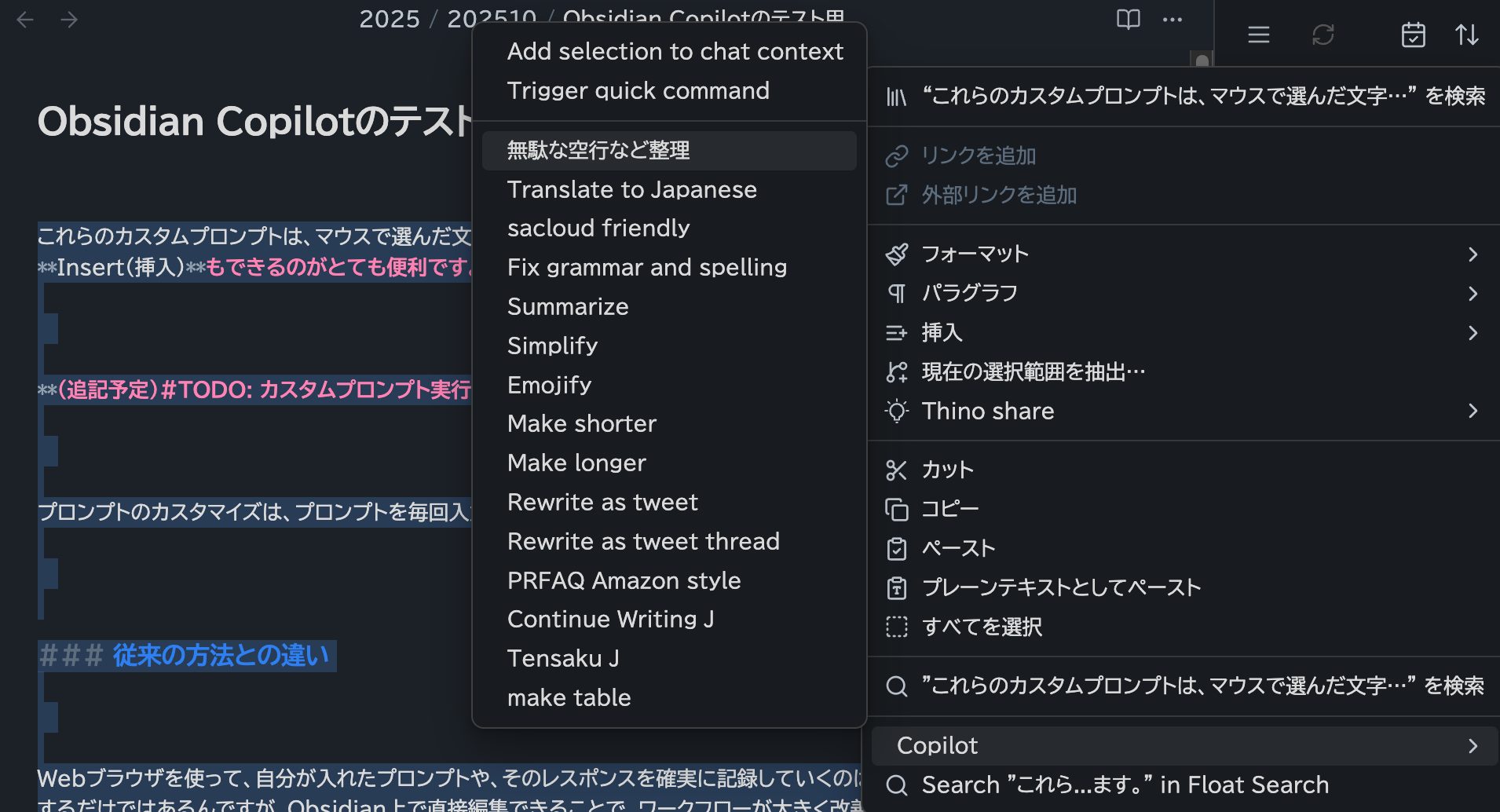
数秒待つと整形結果が表示されます。
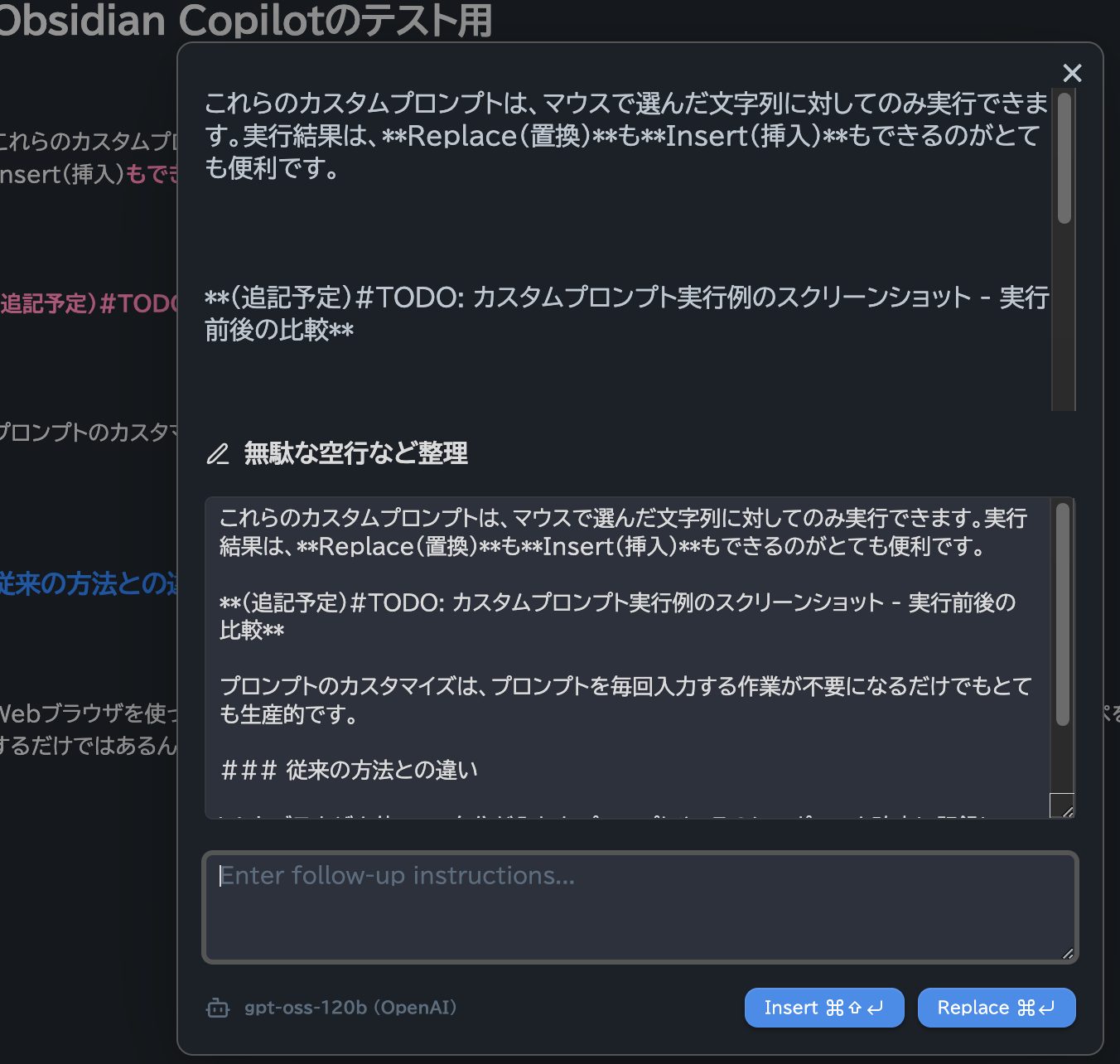
上図の右下に表示されているようにInsertかReplaceを選べるので、今回はInsertを選びます。
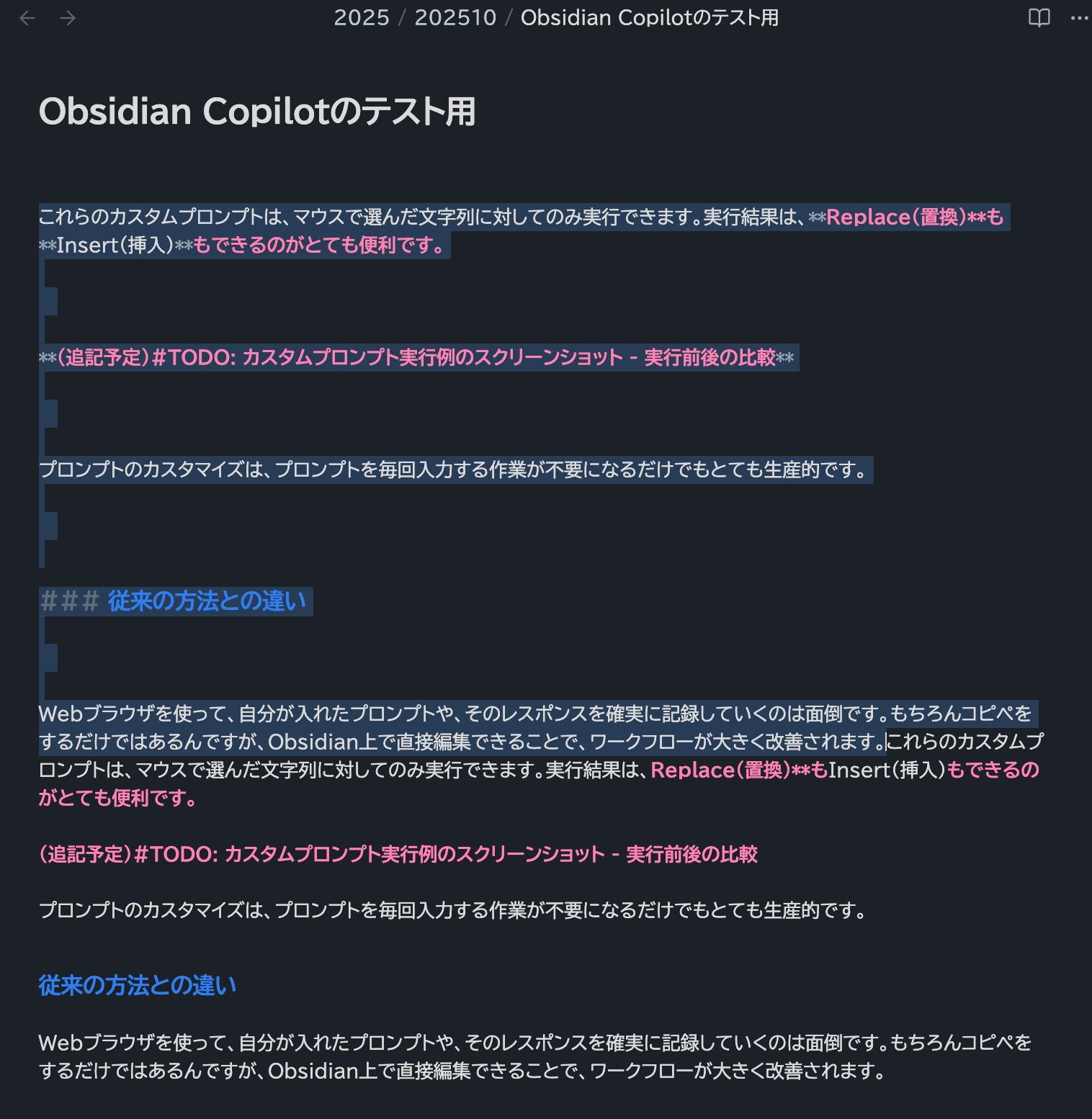
Insertした文章では複数行の空行がカットされているのがわかります。(マウスで選択した部分の直後に、整形された文面がInsertされています)
今回は簡単なプロンプトでしたが、長い長いカスタマイズされたプロンプトを再利用するときに、毎回入力する作業が不要になるだけでもとても生産的です。
従来の方法との違い
Webブラウザを使って、自分が入れたプロンプトや、そのレスポンスを確実に記録していくのは面倒です。もちろんコピペをするだけではありますが、Obsidian上で直接編集できることで、ワークフローが大きく改善されます。
すべての作業がMarkdownファイル上で完結し、そのまま記録として残るのは、ナレッジ管理の観点から大きなメリットです。
他のプラグインとの互換性について
すべてのObsidianプラグインが、さくらのAI Engineに対応しているわけではありません。
Tarsプラグインのケース
例えばTarsプラグインは、現時点では動作しませんでした。
Tarsは複数のカスタムプロンプトを設定したLLMについて、それぞれの得意、不得意を変えながらどんどん使っていくのに便利なプラグインです。時間をみつけて、これもさくらのAI Engineに対応させたいとは思っています。
このように、プラグインによって対応状況が異なる点は留意が必要です。ただし、Obsidian Copilotのような主要なプラグインが動作することで、日常的な作業の大部分はカバーできます。
こんな人におすすめ
特に私のように、外部サービスの利用に制限がある場合は、Obsidianはおすすめです。外部サービスは絶対だめ!ならばローカルLLMを使うしかありませんが、日本国内でサービスが提供されている、学習に使われることのない、さくらのAI EngineであればOK!と説得できる!のであれば、ぜひご活用ください。
具体的には以下のような方に適しています:
- Markdownでナレッジ管理をしている方: Gitでバージョン管理しているドキュメントに、AI支援を追加できます
- ローカルファーストを重視する方: データの所有権と可搬性を保ちながら、LLMの恩恵を受けられます
- 企業での利用を検討している方: 学習に使われない国内サービスという点は、セキュリティポリシー上の説得材料になります
- 複数のAI作業を効率化したい方: カスタムプロンプトにより、定型的なAI作業を自動化できます
おわりに
Obsidian CopilotとさくらのAI Engineの組み合わせは、「日本のサービスで閉じつつも、高性能なLLMを活用したい」というニーズに応えるソリューションです。
ollamaによるローカルLLMでは速度やモデルサイズの制約に悩まされ、かといってクラウドのLLMサービスではセキュリティやデータの取り扱いに懸念がある——そんなジレンマを抱えている方は多いのではないでしょうか。
さくらのAI Engineは、その中間に位置する選択肢として、実用的な速度とセキュリティを両立させています。
本記事では、さくらのAI Engineを活用する最初の一歩として、Obsidian Copilotの設定と活用方法をご紹介しました。次回以降、他のクライアントツールについても順次ご紹介していく予定です。