分散推論基盤やその前提の考え方 〜高火力 PHYで作る分散推論基盤 vol.1〜


目次
はじめに
さくらインターネットで高火力 PHYのチームに所属している道下です。
高火力 PHYは、最新のGPUを8枚搭載し、強力なインターコネクトを備えたサーバーを提供するサービスで、大規模なモデルのトレーニングなどにご利用いただけるものになっています。
私はここ数ヶ月ほど、この高火力 PHYで利用しているサーバーと同種のGPUサーバーを利用し、近年注目度を増しているLLMの分散推論基盤技術に関して詳細に技術調査を行ってきました。今回はこの技術調査や性能検証を行う中で獲得できたナレッジを連載形式で紹介しようと思います。連載本数としては本稿執筆時点で4〜5本を見込んでおり、LLMの推論に関する基礎的な内容から、重要なソフトウェアの技術的な解説、実際の性能検証の内容など幅広く詳細に紹介していく予定です。
連載の第1回である今回は、LLMの推論処理とは何かという基本的なおさらいから、ユーザー体験に関わる指標の話、推論時のGPUの処理や、それを最適化するための手法の紹介など、以降の連載の詳細に入るための前提知識を共有します。
本記事で想定する読者は、LLMの分散推論基盤の構築や最適化に興味があり、これらの技術的な背景や近年の動向に興味があるエンジニアです。第一回は読み物中心の内容になりますが、LLMの分散推論基盤を適切に理解し構築する上で非常に重要なエッセンスを詰め込んだ内容のためお付き合いください。
LLMの推論とは?
ご存知の方も多いと思いますが、LLMの「推論」は学習済みのモデルをデプロイし、ユーザーからの入力に対して、学習済みの知識をもとに出力を生成するフェーズのことを指します。
最近は、テストタイム スケーリングなどの技術もあり、内部的にはより複雑な処理を実施するケースもありますが、ここではあくまで基礎的な話として説明します。
すでにChatGPTなどのサービスを利用したことがある人にとっては馴染みがあるかと思います。

普段これらのサービスを利用する際にはあまり気にしないかもしれませんが、LLMを推論用途でサービングすることには様々な考慮事項や課題があります。以降ではLLMの推論基盤がなぜ難しいのかについて紐解いていきます。
LLMの推論リクエストの特徴とシステムの負荷
LLMの推論は一般的なWebアプリケーションとは明確に異なる特性があります。通常、Webアプリケーションはそれぞれのエンドポイントに対してある程度決まった形式のリクエストを実行し、決まった形式のレスポンスがサーバーから返却されます。
一方でLLMの推論リクエストの場合、その内容はユーザーが任意に入力する自然言語であり、そのレスポンスもユーザーの入力内容に応じたレスポンスになります。APIという形式上での規定はあるものの、入力内容、入力長のみならず、システムから返却される出力内容や出力長までもがユーザーの入力内容に大きく依存するという特性があります。また、当然ながら各ユーザーの入力内容には多様性があり、これらのリクエストが任意のタイミングでシステムに届くことになります。
システム側の視点に立つと、ユーザーリクエストの内容に応じてシステムの処理の傾向が変わることになります。つまり、システムの負荷特性が各ユーザーの入力内容に大きく依存するため、システムの最適化が通常に比べて非常に難しいという問題として表出します。この問題は、ひいては推論システムへの適切な投資判断の困難性につながります。特にGPUのような高価なリソースを前提とするLLM推論基盤は多額の費用がかかるため無視できない問題です。

この問題は「そのシステムに対する、そのタイミングでのユーザーの入力に従う」という不確定な要素に依存するため一意に解決する方法はありません。一方でこのような特性へのアプローチの手段の例として「そのシステムに対して発生している実際のユーザーワークロードの特性を解析し、その負荷特性にしたがって最適化する」という手段(※1)が考えられます。これは、自身の持つシステムに対してユーザーの体験を向上させることに焦点を当て、コスト効率を最適化させるための手段になります。

※1 実際にAlibabaでは、総計数十億ものユーザーデータを解析し、Webアプリケーションにおける負荷モデルとしてよく利用されるポアソン分布からLLMのワークロードが外れていることを指摘し、ユーザーデータをもとにしたワークロードからシステムのリソースを最適化した論文が発表されています。
システムにかかるワークロードの特性は、実際にシステムを構築し、ユーザーを収容した上で測定する以外に正しく把握する方法はありません。一方で、それらの特性をもとにしたシステムのリソース最適化フェーズにおける具体的な技術については議論することが可能なため、この技術について後述していきます。
ただし、この最適化技術を学ぶ前提として、LLM推論におけるユーザー体験を表す性能指標について正しく把握する必要があります。ここからは具体的な技術に入る前にこれらの指標について説明します。
LLM推論におけるシステムの性能指標
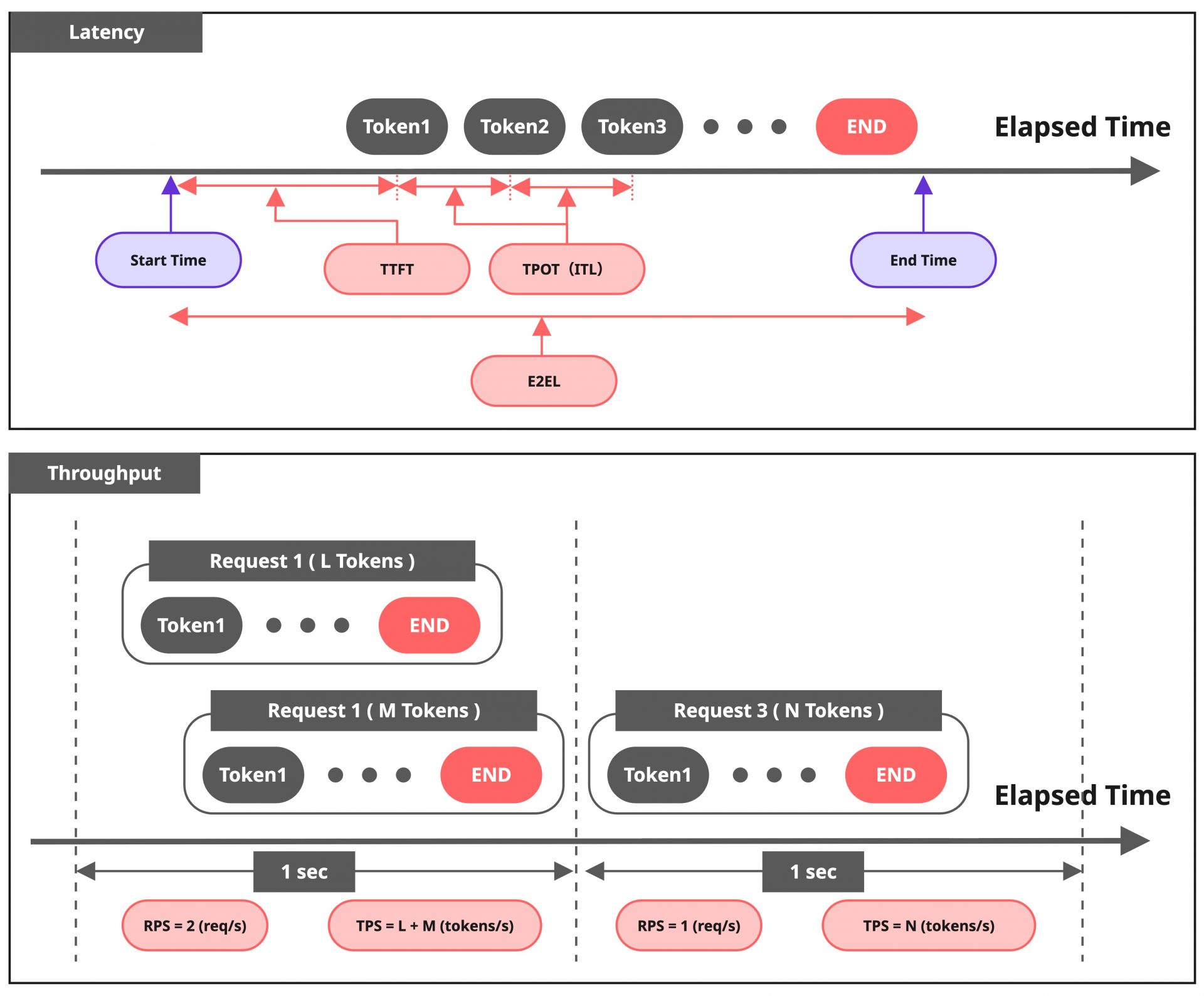
Webサービスにおいてよく利用されるシステムの性能指標にLatencyとThroughputが存在します。LLMの推論において同様にLatencyやThroughputを考えてみると、リクエストを開始してから最後の出力を得るまでの期間(以降、これをE2Eと呼称します)で考えることができます。

一方で、この指標はLLM推論におけるユーザーの体験を本当に良く反映しているでしょうか?
LLMの応答は逐次的であり、ユーザーは何よりもまず最初のトークンがLLMから返却されるまでの時間が気になるでしょう。また、最初のトークンを得たのち、次々と後続のトークンを受け取ることになりますが、このタイミングではトークンが滑らかに得られる方が望ましいでしょう。
つまり、LLMが応答するトークンの単位で指標を定義する方が、より解像度高くユーザー体験を表現できそうです。実際にこれらを表現するLatency、Throughputの新たな指標が提案され、昨今のLLM推論基盤の性能を表す指標として広く利用されるようになりました。E2Eで測定する従来の指標と合わせて、以下の表と図に整理します。
| 指標の種類 | 指標 | 説明 |
|---|---|---|
| Latency | TTFT | Time to First Token ユーザーリクエストを送信してから、最初のトークンを受信するまでの時間 |
| Latency | ITL | Inter-Token Latency 連続する2つのトークン間の間隔の平均 |
| Latency | TPOT | Time per Output Token TTFTを除く、各トークンの生成時間の平均 |
| Latency | E2EL | Total Latency(End to End Latency) ユーザーリクエストを送信してから、最後のトークンを受信するまでの時間 |
| Throughput | TPS | Tokens per Second LLMが1秒間に処理するトークン数の総数 |
| Throughput | RPS | Requests per Second LLMが1秒間に処理するリクエスト数の総数 |
ITLとTPOTは類似の概念であり、同義として扱われるケースもありますが、ベンチマークツールなどでは微妙に異なる場合があるため注意が必要です。この違いは単一リクエストで考えるか、複数リクエストにわたって考えるかによって現れます。詳細を知りたい方はこちらの記事を参考にしてみてください。本記事の以降の内容においては同義のものとして取り扱います。
Goodput: Latency要件を満たすスループット指標
Throughputに関連するもう一つ重要な指標としてGoodputとよばれる、Throughputをさらに精緻化した指標が存在します。この指標もLLMの推論における指標としてよく目にするものになります。
GoodputはLatency要件を満たすような秒間のThroughputがどの程度かを示す指標です。これは「スループットが高くてもレイテンシ目標を達成できない場合があり、必ずしも優れたユーザー体験につながるとは限らない」という点を考慮した「システムの性能目標とユーザー体験目標の両方をどの程度達成できているか」を示すものになっています。
以下の図は、秒間10RPSを達成できているシステムであっても、レイテンシの制約(TTFTが200ms以下、かつITLが50ms以下)を考慮すると、この制約を満たすのは秒間3RPSになるという例です。
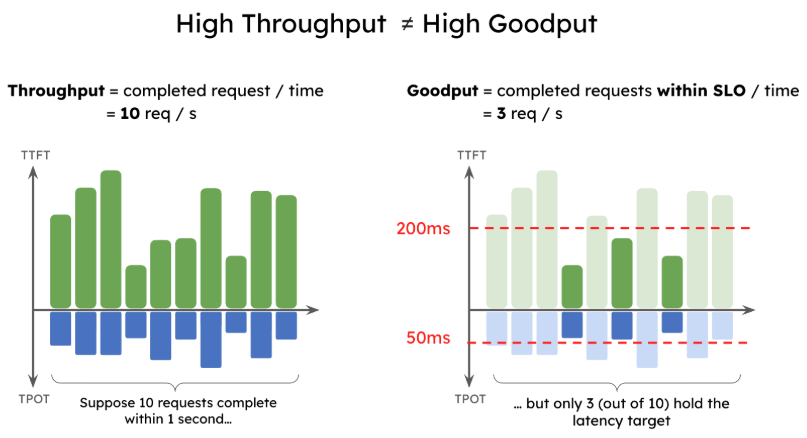
これは、例えばシステムへの投資判断を行うケースにおいて、Throughputの指標のみをもとに判断すると、Throughputは最大化できたとしてもLatencyの改善が十分に行えない可能性があることを示唆しており、投下コストに対して想定したほどユーザー体験の改善につながらず、コスト効率が悪い可能性があります。Goodputはこのような落とし穴を回避するためにも利用できる指標です。
指標の重要性について
LLMの推論基盤に限った話ではありませんが、ユーザー指標の正しい定義は、ユーザー体験を前提としたSLO・SLAの策定や、それを用いたインフラの最適化に大きく影響を与えるため、非常に重要です。
前述したように、LLMの推論基盤の場合は一意に最適化する方法はなく「実際のユーザーワークロードの特性に従った最適化」を行うという手法が、最適化として取りうる一つの手段となります。ユーザーワークロードの特性を数値化するためには必然的にこれらの指標を使うことになることからも、これらの指標を正しく理解することはシステム最適化の上で欠かすことはできません。
LLM推論基盤のようにGPUの利用を前提とする非常に高価なシステムの場合、裏付けのない最適化は即座にコストという形で跳ね返ってくることになります。RoI(Return of Investment)がシビアになりやすいシステムだからこそ、これらの指標を常に考慮し改善を検討する必要があります。
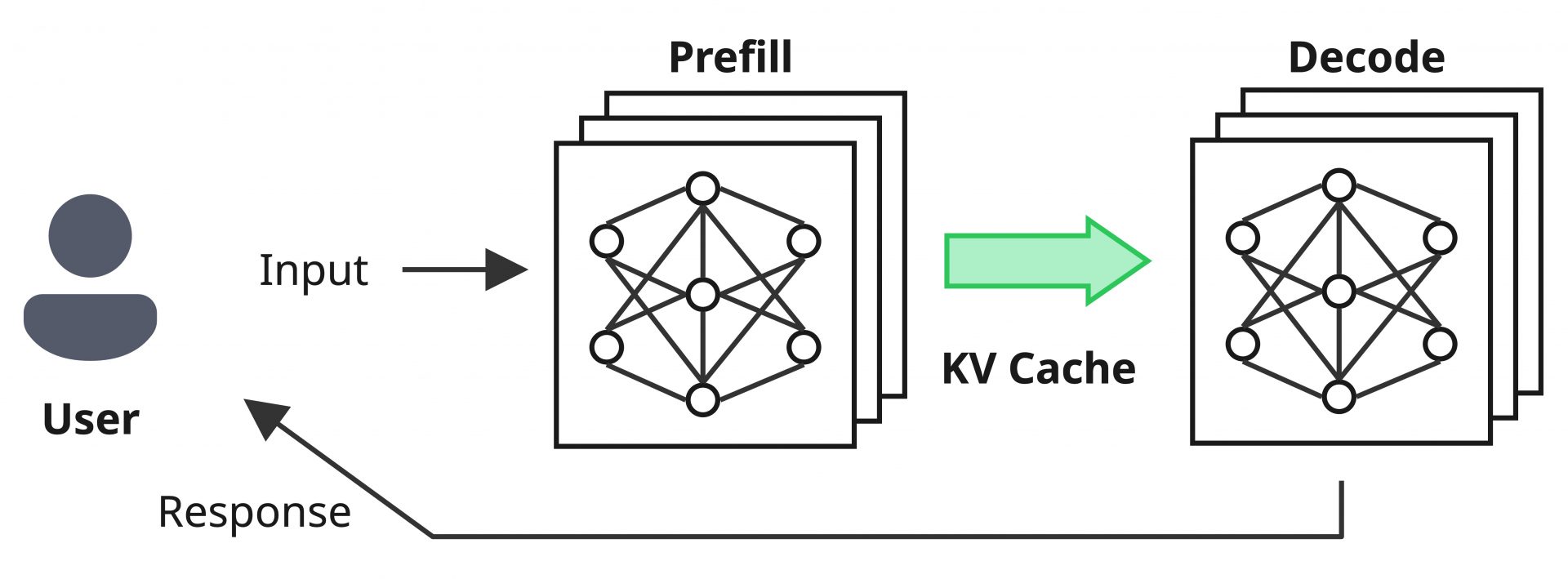
LLMの推論処理とKV Cache
LLM推論の指標についての紹介が終わったので、ここからはLLM推論処理の技術的に詳細な議論へ進みます。
推論フレームワーク
LLMは膨大なパラメータを持つ構造であり、これを動作させるためには大量のメモリーが必要になります。また、推論処理自体も大規模な行列演算を行うため計算能力も重要です。多くの場合、LLMを動作させる際には通常のプログラムのようにCPU・メインメモリー上に載せるのではなく、別の計算資源(主にGPU)上で処理させることが一般的です。
LLMそれ自体は学習済みのモデルでしかないため、我々が想像するサービスにするためにはフレームワークが必要になります。またこれらのフレームワークは単純にLLMをサーブする以上に、より効率的な推論処理を行うための最適化技術がサポートされていることが多いです。これらのフレームワークとしては現在様々なものが存在していますが、今回はその中でも業界のデファクトスタンダードの地位を確立しつつある、vLLMと呼ばれるソフトウェアを取り上げることにします。
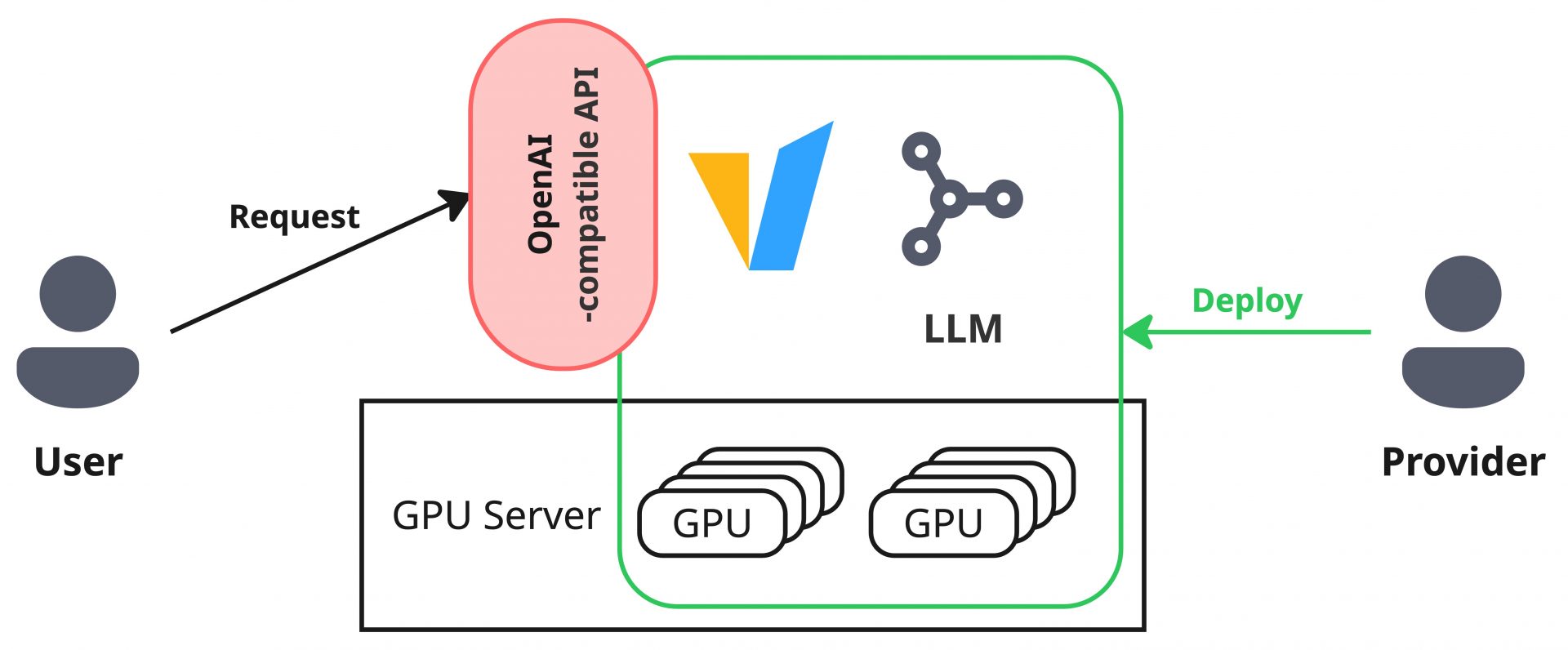
vLLMを利用してモデルをデプロイすると、合わせてOpenAI API互換のAPIサーバーが起動します。ユーザーはこのAPIサーバーに対してリクエストを実行し、LLMからの応答を得ることができます。プロダクション環境としては不十分ではありますが、PoCで試すぶんには十分な構成が即座に構築できます。
推論処理の詳細とKV Cache
ここからはLLMの推論が実際にどのような処理を行っているかについて触れるとともに、非常に重要な概念であるKV Cacheについて紹介します。
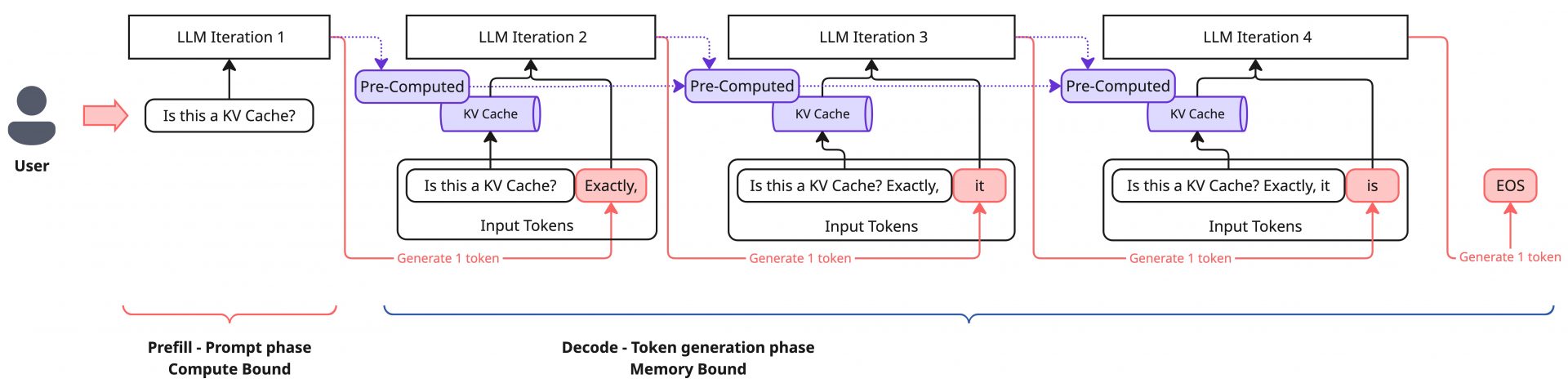
推論システムにユーザーリクエストがくると、LLMはその内容をもとに計算を行い、トークンを一つ生成します。
この生成されたトークンを入力の末尾に追加し再度同様の計算を行う、という処理を繰り返すことによって文章を生成していく動作がLLMにおけるトークン生成の処理になります。
重要な事実として、各イテレーションでの計算結果(入力に対するアテンション(※2)の演算結果)は使い回しが可能です。そのため、初回のイテレーションでは入力全体に対して演算を行う必要があり計算力が必要になる一方で、それ以降はその結果を使い回すことができ、新しく生成されたトークン以外の計算を削減できるため、計算にかかる時間を大幅に削減できます。
この計算結果のキャッシュが「KV Cache」と呼ばれるものです。初回の計算ではユーザーの入力トークンに対するKV Cacheが生成され、それ以降は生成されたトークンに関する計算結果も追加でキャッシュされていきます。
※2 ここで、計算結果の使い回しが可能な理由を説明するには、TransformerにおけるAttentionの説明が必要になります。本稿では紙面上の都合で割愛しますが、KV Cacheの実態について把握する上で、さらにはKV Cacheに対しての最適化技術を知る上で、必須の知識となります。
上記のLLMの処理は初回以降の計算量の大幅な削減が可能であるものの、KV Cacheの読み出しや書き込みに伴うメモリー操作がGPU処理の支配要因になります。そのため、初回処理とそれ以降の処理で処理のボトルネックが明確に変化し、前者のCompute Boundな処理をPrefill、後者のMemory Boundな処理をDecodeと呼びます。
具体的にこのPrefillやDecodeの処理はGPU上で実行されますが、vLLMをはじめとする推論フレームワークはユーザーのリクエストをバッチ化してGPU上で効率的に処理する機能をサポートしています。以降では、このバッチ処理について説明しつつ、これが抱える課題について整理します。
バッチ処理によるGPUの効率的な利用
ここからはバッチ処理の観点から、LLM推論におけるGPUの処理に目を向けて議論を展開していきます。GPUのバッチ処理として、LLM登場以前からStatic Batching、Dynamic Batchingというバッチ戦略が存在していました。バッチ処理のイメージを持ってもらうため、そして推論処理のバッチ戦略の難しさを理解するために順を追ってこれらを説明します。また、ここでのGPUの処理はLLMの推論処理を前提とします。
まず、Static Batchingですが、これは最も単純なバッチ処理形式で、決められた一定のリクエスト数が蓄積されるまで待機し、それらを一つのバッチとしてまとめて処理する方式です。
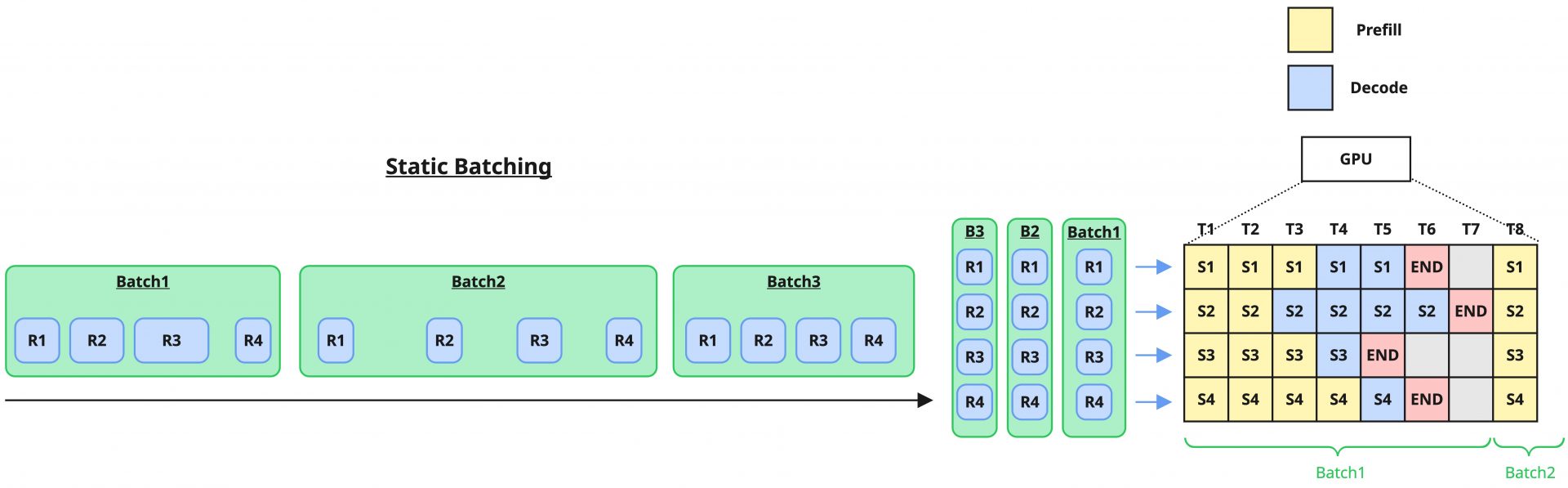
この方式は一定のリクエストが蓄積されるまでバッチ処理を開始しないため、特に最初に到着したリクエストは、それ以外のリクエストの到着まで遅延することになります。さらに、実行内容がLLMの推論処理の場合、それぞれのリクエストに対してトークン生成量は異なる(短文を生成することもあれば、長文を生成することもある)ため、バッチ内での他のリクエストの完了にも影響されることになります。このようにLLMの推論処理では、単純なリクエスト蓄積の遅延以外に、追加の遅延やGPU処理が遊んでいる時間が発生する可能性があります。
Dynamic Batchingは、Static Batchingで問題になっていた「一定リクエストになるまで待つ」を解消するための戦略で、従来より多くのシステムで採用されるバッチ処理です。この方式は、受信リクエストをバッチ単位でまとめるのは同じである一方、固定のバッチサイズを強制せず、タイミングウィンドウを設定することによってその期間内で到着したリクエストを処理するというものです。
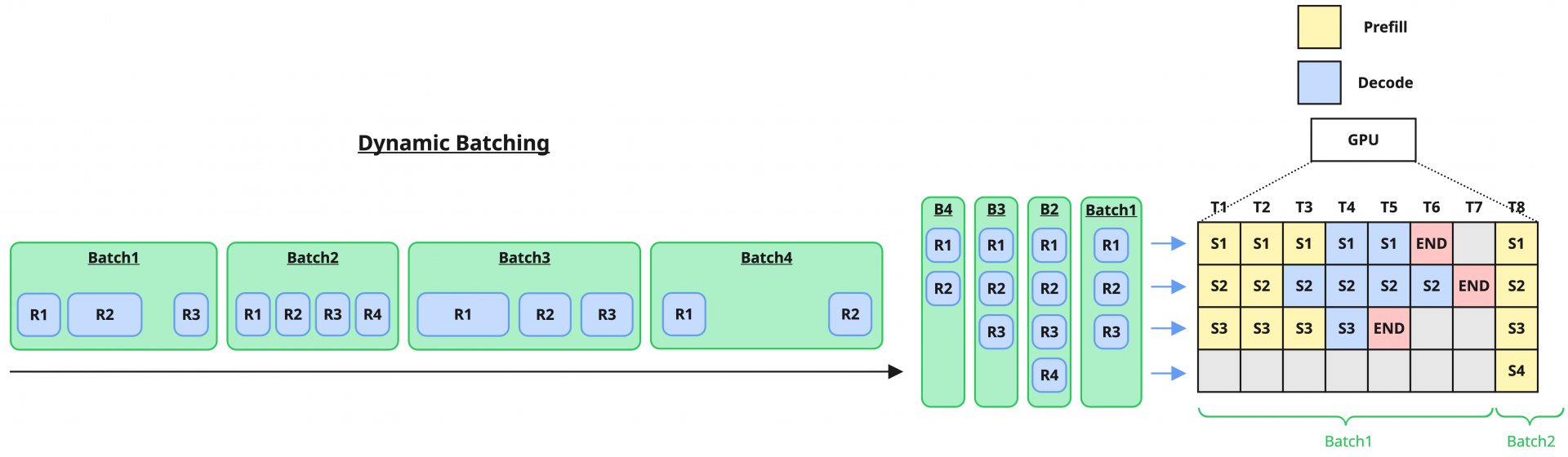
リクエストが多いケースでは即座にバッチサイズが埋まるため処理を開始し、リクエストが少ない場合も時間経過によってそれまで溜まっていたリクエストを処理するという、ThroughputとLatencyのバランスの取れた手法になっています。当然、バッチが完全に満たされない状況での処理の実行はLatencyを改善する一方でGPUの利用効率を最大化できないという欠点になります。また、Dynamic Batchingもバッチ単位で結果を返却することが基本のため、LLMの推論処理においては特定のバッチ要素に対して他のバッチ要素が影響を受けることは避けられません。
LLMの推論処理のようにリクエストに対する出力長が一定ではないワークロードにおいて、従来のStatic BatchingやDynamic Batchingはいずれも「バッチで処理した結果を一括で返す」という特性上、相性が悪いという課題がありました。
ここでContinuous Batchingという手法が開発されることになります。これは端的に言えば「同一バッチ内の各リクエストは、その処理の完了後、即座に新しいリクエストに置き換えて処理をする」という手法です。
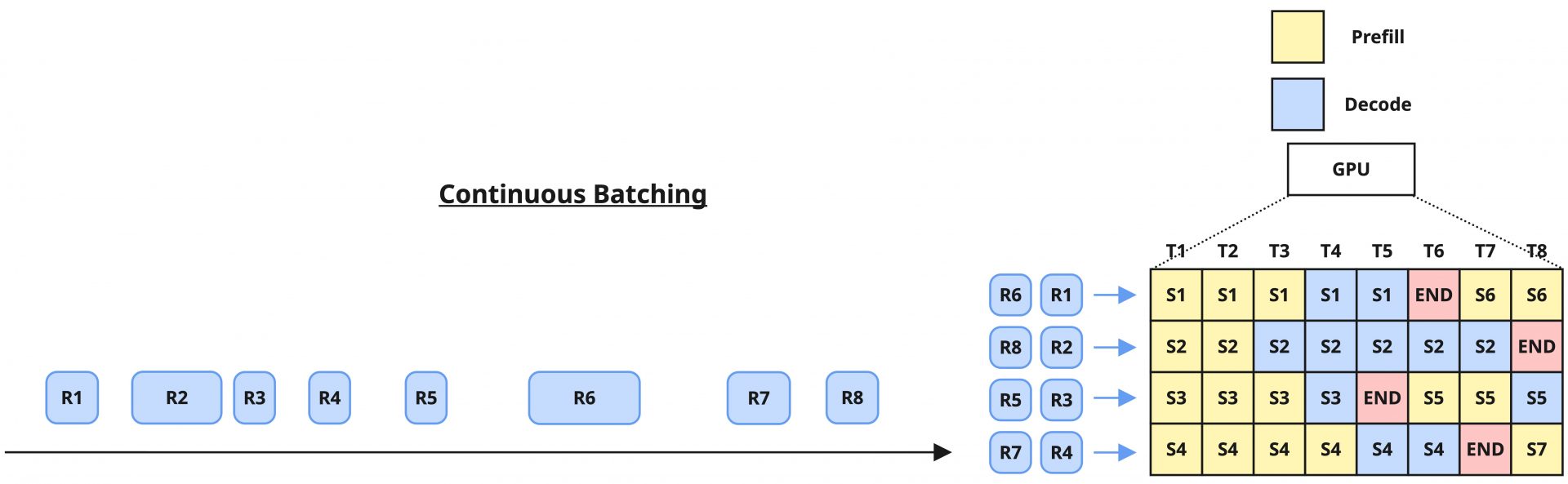
この方式は従来のバッチ処理のように特定リクエストの完了を別のリクエストが待機することがなくなるためLatencyが改善され、さらにGPUのリソース利用効率も最大化を狙うことができる、LLM推論ワークロードにフィットしたバッチ戦略になります。
近年の主要な推論フレームワークはこのContinuous Batching、もしくは類似のメカニズムをサポートしており、推論処理では基本的にこの戦略の利用が推奨されます。
PrefillとDecodeのバッチ化の課題とChunked-Prefill
実はこのContinuous Batchingでも解消できない課題があります。
前述の通り、LLMの推論リクエストはPrefillとDecodeの2フェーズで明確に特性が異なり、バッチ化されたそれぞれのリクエストもPrefillの処理を行ったのち、Decodeの処理を行う流れになります。Continuous Batchingでは先ほど述べた通り、空いたバッチスロットにリクエストを詰めていくため、あるリクエストがDecode処理をするバッチの中に、新しいリクエストのPrefill処理が混じることがあります。この時、Decodeの1ステップに比べると、Prefillの1ステップは非常に時間がかかるため、同一バッチの中でDecode処理がPrefillの処理を待つという現象が発生します。
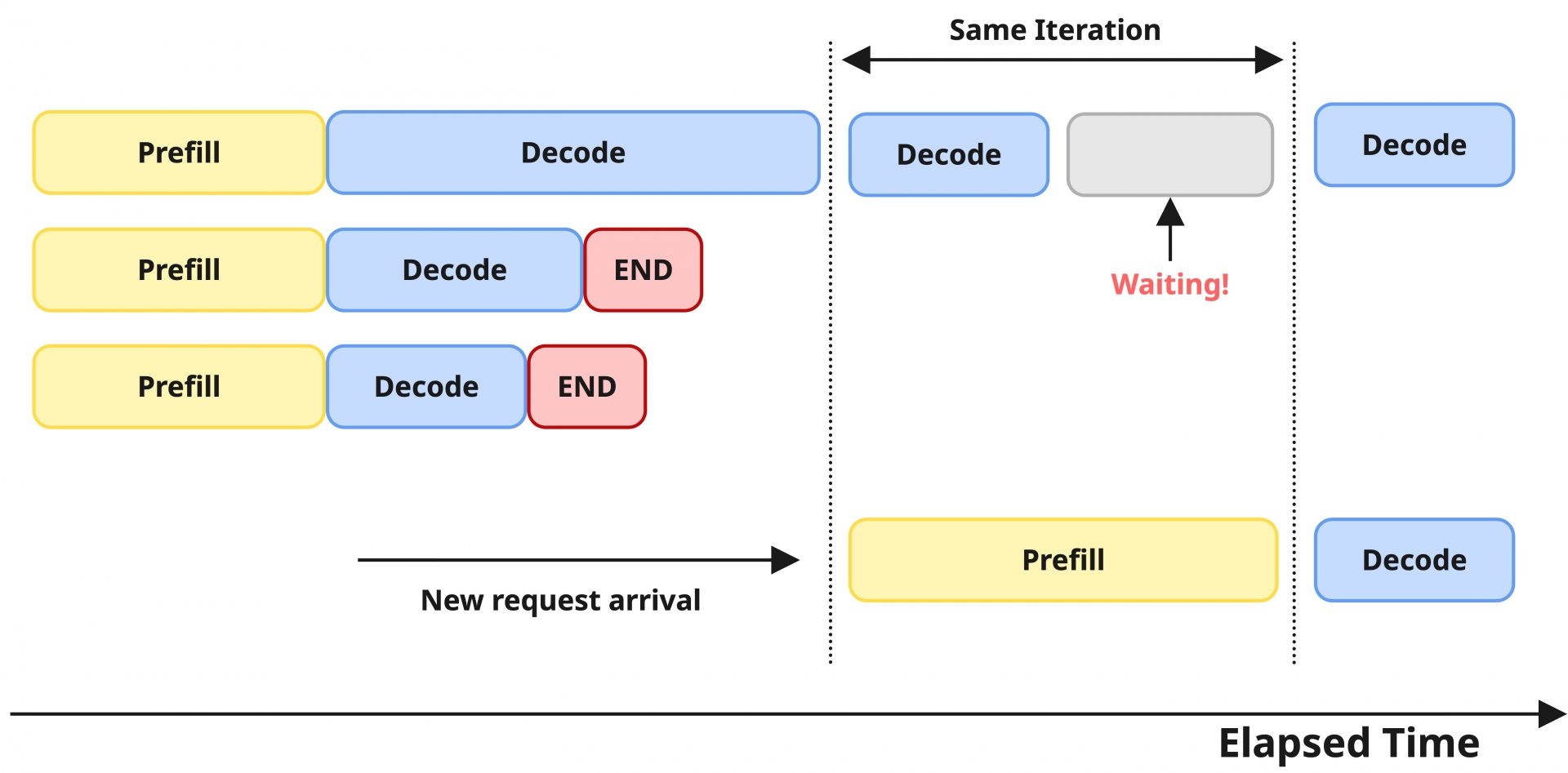
具体的な例として、あるユーザーに対してはストリームで出力を返している状況で、別のユーザーが長文のプロンプトを送信してきたとき、次のような影響として表出することになります。
- ユーザー体験の視点から見ると、ストリーム形式で生成されるトークンの出力の速度が一部遅延するなど不安定な応答速度として現れ、体験を大きく損なう可能性がある
- システム特性の観点から見ると、ITL(TPOT)の Tail Latency が増加することになる
この影響を軽減する手法として、Chunked-Prefillという技術が提案され、vLLMでは実装されています。これはその名の通り、Prefill処理を複数チャンクに分割して処理する方式です。
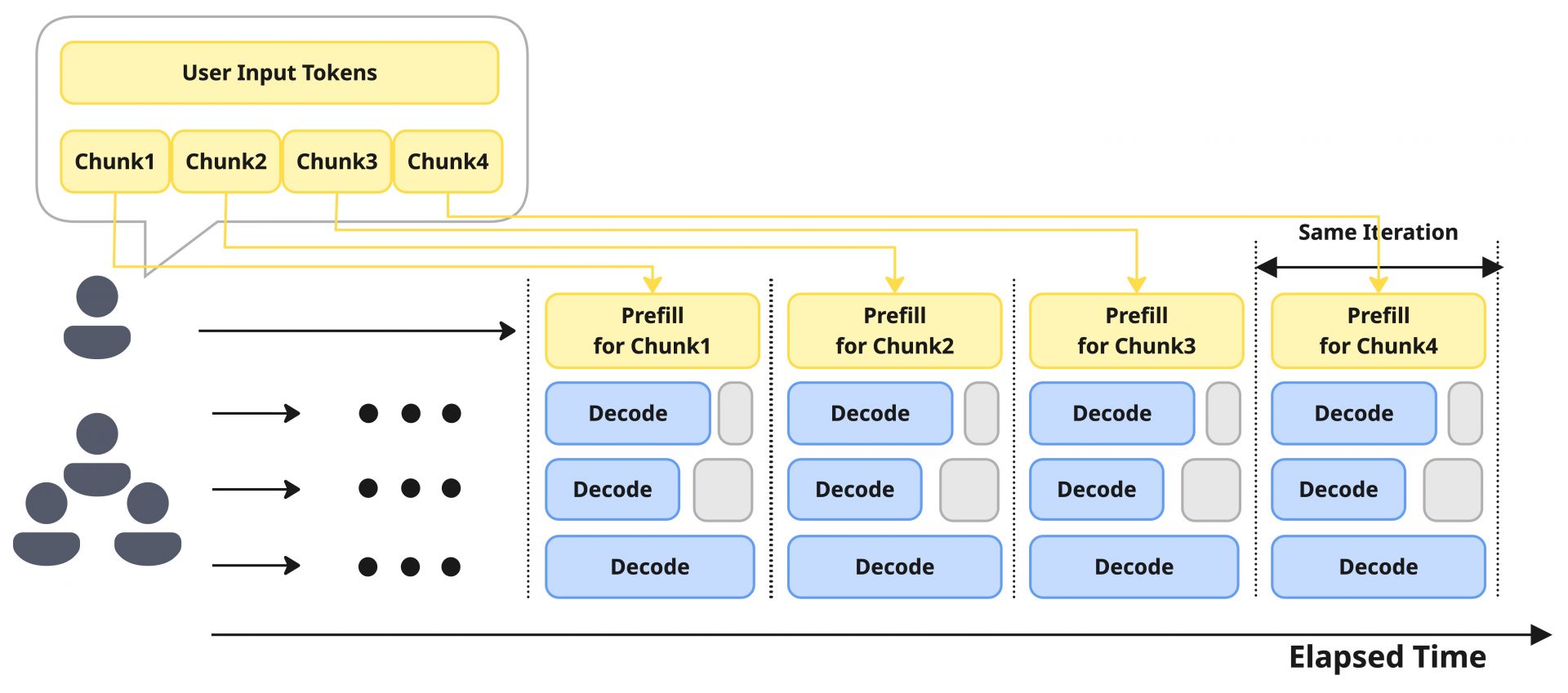
Prefillのチャンク化により、同一バッチ内のDecodeのトークン生成への遅延の影響が低減されることつながります。Chunked-Prefillでもチャンクのサイズやバッチ化の方式など様々な議論はありますがここでは省略します。
重要な点としては、このChunked-Prefillは優れた技術である一方、最大限効果を発揮するためにはチャンクの粒度やバッチのまとめ方などの変量を適切に設計する必要があり、さらにその上で潜在的には同一バッチ内部のデコード処理がPrefillによって待たされる可能性を消しきれないということです。
これは処理の仕組み上避けることはできません。これが問題になるケースとして、例えば性能を向上させるためにGPUを追加したとして、Decode処理の平均的な改善はできたとしても、ITL(TPOT)のTail Latency は限定的な改善幅にとどまる可能性があることを示唆しています。
ここで、近年LLM推論基盤の領域では一般的な技術となりつつある、Prefill-Decode Disaggregationについて議論を発展させていきます。
Prefill-Decode Disaggregation
Prefill-Decode Disaggregation(PD Disaggregation)とは
Prefill-Decode Disaggregation(PD Disaggregation / Disaggregated Prefill)はその名の通り、Prefill処理を行うGPUとDecode処理を行うGPUを物理的に分離する構成です。

引用: NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models
ユーザーリクエストに対して、まずPrefill用のGPUを利用して演算し、最初のトークンとKV Cacheを生成します。
その後、KV CacheをDecode用のGPUに転送し、Decode側で後続のトークンを順次生成していくという仕組みです。
この方式は物理的にPrefillとDecodeの処理を分離するため、原理上PrefillとDecodeが同一バッチに混じることがなくなりますが、KV Cacheの転送という新たな問題を誘発します。これらのメリットと課題について、以降ではそれぞれ踏み込んで整理してみます。
PD Disaggregationがもたらすメリット
前述した通り、Chunked-PrefillはPrefill処理をチャンク化することでITL(TPOT)のTail Latencyへの影響を抑えることができるものの、完全な解決には至らず、GPUのリソース投下による改善量も限定的である可能性があります。
さらに遡ると、これらのユーザー体験を示す指標やSLO・SLAについて、システム最適化の側面からその重要性を議論しました。
この視点に立つと、Prefill処理とDecode処理が同一バッチに混ざる方式は、特にSLO・SLAの要件として設定することの多いTail Latencyの値が、システムへの投下コストに対して十分に改善しないということにつながる可能性があります。GPUのような非常に高価、かつリソース量に物理的な制限があるような環境において、この問題は無視できないと言えます。
一方、PD Disaggregationの構成ではこの課題が原理的に発生せず、GPUなどのリソース投下量によって性能がスケールすることが期待されます。当然、LLM推論における全ての問題を解決するものではありませんが、特に大規模な環境や、厳密なSLO・SLAが求められる環境においては非常に強力です。冒頭紹介したGoodputをSLO・SLAの指標として利用する場合も有効な手段となります。
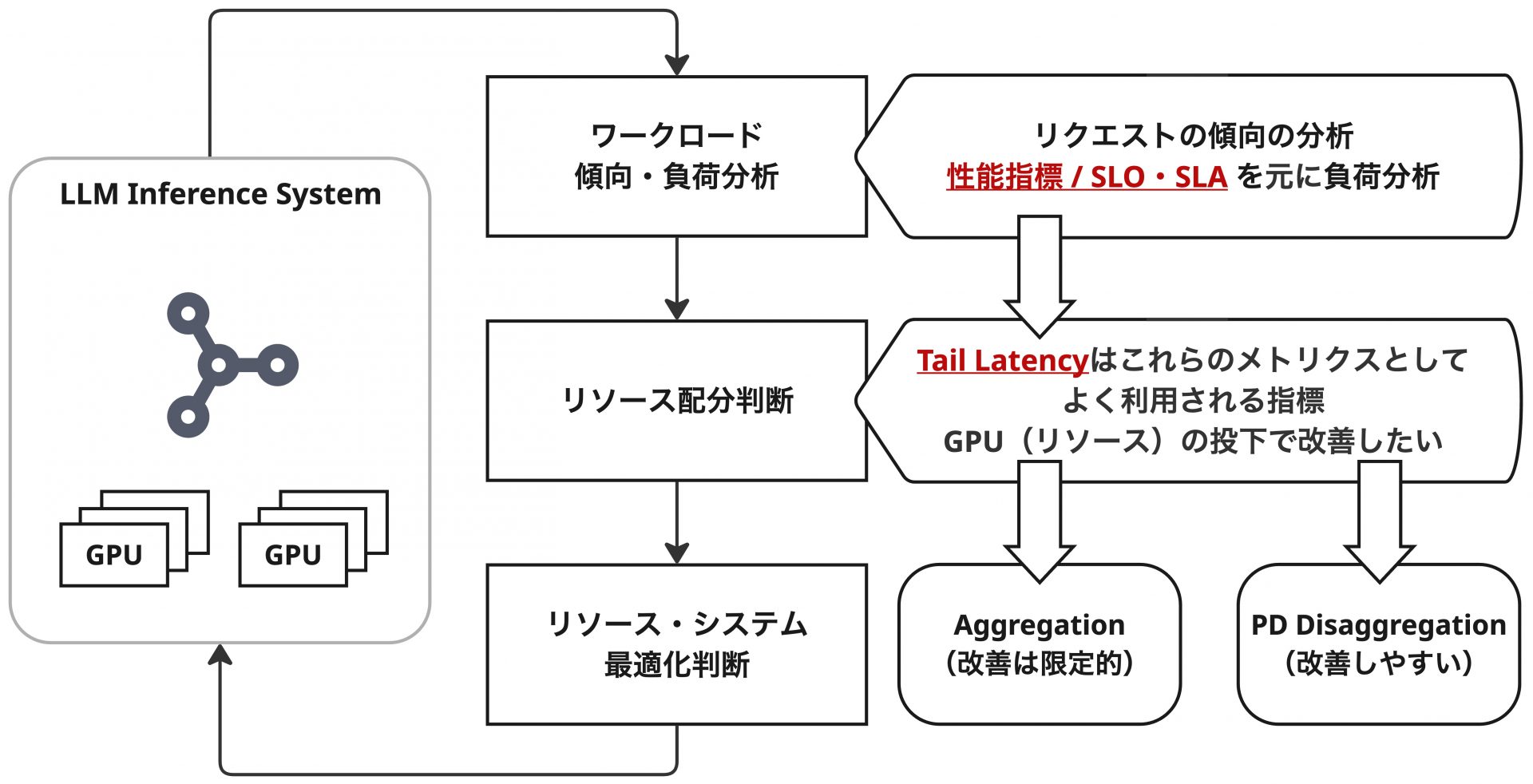
さらに、PD Disaggregationは「ユーザーワークロードにしたがった最適化」とも相性が良いです。ユーザーワークロードとして入力長が長い傾向にある場合やTTFTを改善したい場合はPrefill側に、出力長が長いケースやITL(TPOT)を改善したい場合はDecode側にGPUリソースを投下することで、傾向に特化して最適に性能をスケールさせることができます。システム的な実装は必要ですが、一時的にPrefill用のGPUリソースをDecode側に配分したり、その逆を行うことで、限られたリソース上でうまくユーザー体験を改善する方法も検討できるでしょう。これはPrefillとDecodeが明確に分離されているからこそ行える方式です。
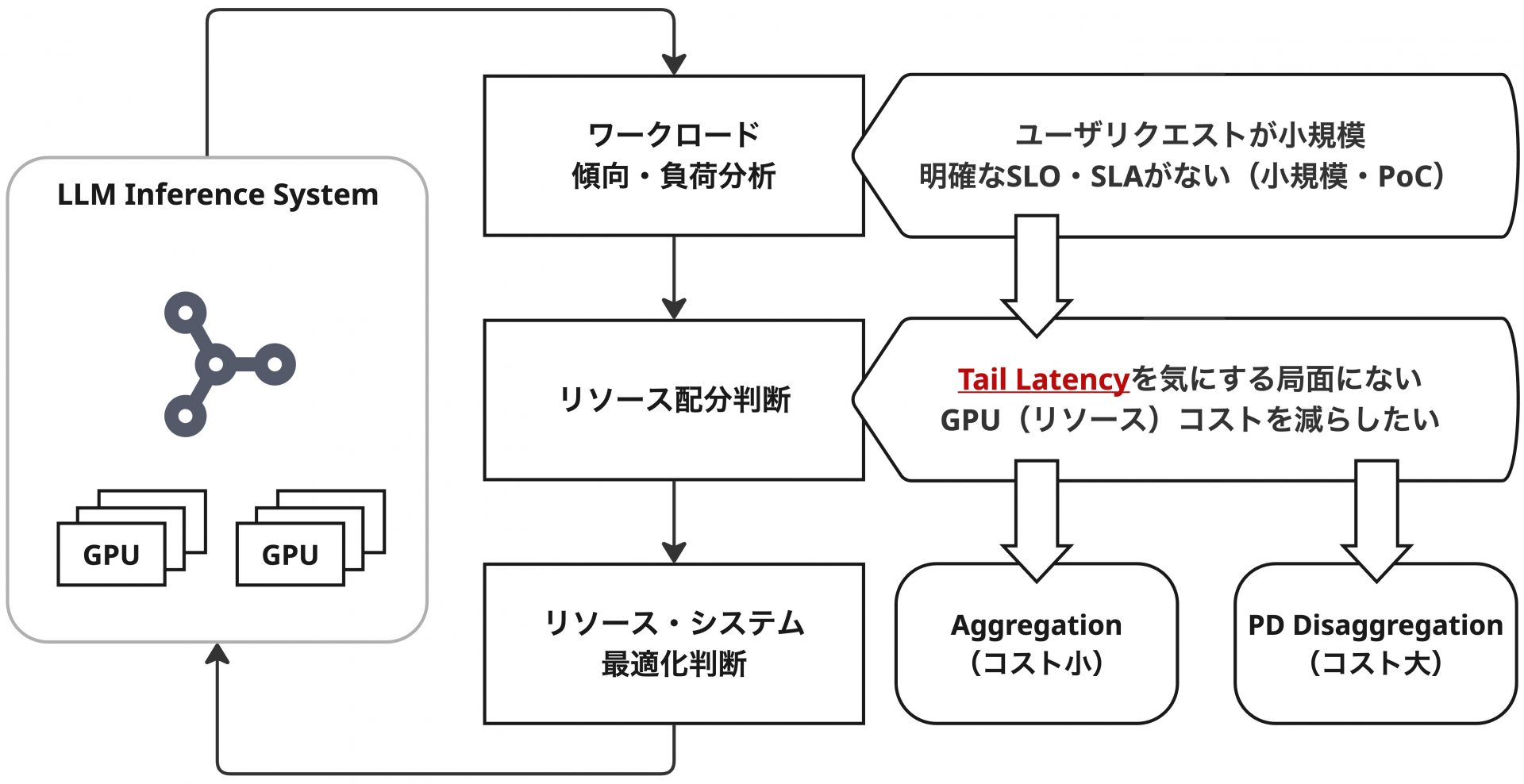
Disaggregationによるコストの増大
PD Disaggregationでは、Prefill用とDecode用にそれぞれGPUリソースを割り当てて処理させるため、単純に要求GPU数が増えることになります。LLMの推論に必要なGPU数は、粗く見積もると、モデルをロードするためのメモリー量+KV Cacheやアクティベーションに必要なメモリー量があれば十分です。例えば、特定のモデルをサーブするためにGPUが1枚で十分な場合、DisaggregationをしなければGPUは1枚で済みますが、DisaggregationするとGPUは少なくとも2枚必要になります。
つまり、SLO・SLAの定義が明確に存在しない環境やPoCなどの小規模な環境においては、PD Disaggregationのメリットよりも、コストの方が勝ってしまうケースは十分に存在します。これはGPUというリソースが非常に高価であることも拍車をかけている要因です。
より正確に言及するならば、小規模な環境においても、ITL(TPOT)Tail Latencyの改善などのPD Disaggregationのメリット自体は享受できます。しかし、これはあくまでその指標の改善がシステム的に重要とみなされる前提に立っている場合に有効だということです。私見ですが、PD Disaggregationは全てのケースにおいて万能な銀の弾丸ではないため、正しくその有効性を把握した上で、自身の環境でコストメリットがあるかの妥当性を検討することが重要だと考えています。
PD Disaggregationによって導出された技術的課題
KV Cacheの転送の課題
PD Disaggregationでは、Prefill用GPUメモリーからDecode用GPUメモリーに対してKV Cacheを転送する必要があります。
KV Cacheの転送は、ユーザーリクエストから応答までの間で行われるため、ユーザー体験(TTFT)に直接影響します。そのため、このKV Cacheの転送をいかに高速に終了させるかが課題になります。
以降では、KV Cacheの転送について、KV Cacheのサイズとインフラ側の設計の2つの視点でお話しします。
なによりもまず、KV Cacheがどの程度のデータ量になるかについての感覚を持っておくことは重要です。KV Cacheのサイズは計算可能ではありますが、利用するモデルとユーザーの入力長、バッチサイズなどに依存するため、固定サイズではありません。ここでは一例として、2種類のモデルに対して、入力サイズやバッチサイズを固定して計算した例を示します。
| Llama-3.1-8B-Instruct | Llama-3.1-405B-Instruct | |
|---|---|---|
| n_layers | 32 | 126 |
| n_heads | 8 | 8 |
| head_dim | 128 | 128 |
| precision_byte [FP16] | 2 | 2 |
| batch | 1 | 1 |
| Input Tokens | 8k | 8k |
| KV Cache Size [GB] | 1.0 | 3.94 |
入力トークン数を8kトークン、バッチサイズを1と仮定すると、Llama-3.1-8B-Instructのモデルの場合はKV Cacheは1GB、Llama-3.1-405B-Instructの場合は3.94GBほどになります。注目すべきは、このKV Cacheは8k入力をもつ単一リクエストに対して発生するものであるため、例えば同様の入力長を持つリクエストが同時に100リクエスト発生する場合は全体で発生するKV Cacheの転送量はそれぞれのモデルで100GB、394GBに及ぶことになります。
ソフトウェアが理想的にハードウェアリソースを利用できると仮定すると、KV Cacheの転送にかかる時間は、ハードウェア帯域から計算可能です。
| KV Cache Size (100 concurrency) | 100GB (Llama-3.1-8B-Instruct) | 394GB (Llama-3.1-405B-Instruct) |
|---|---|---|
| Transfer Time (100Gbps) [s] | 8 | 31.5 |
| Transfer Time (400Gbps) [s] | 2 | 7.88 |
| Transfer Time (800Gbps) [s] | 1 | 3.94 |
KV Cacheのサイズは現実的な見積もりとしてもユーザーの単一リクエストに対してGBオーダーのサイズになることがあり、PD Disaggregationではこれを高速に転送する必要があることが分かります。さらに、このサイズはユーザーの入力長にも依存するため、KV Cacheの転送を前提としたインフラを設計する上でも、この不確実性について考慮に入れる必要があります。
この前提をもとに、インフラ側の設計について触れていきましょう。近年のGPUサーバーは、NVLinkなどのScale Up Networkによる超高速なノード内GPU間接続や、高帯域NICとインターコネクトによるScale Out Network経由の高速なGPUサーバー間通信をサポートする構成が基本です。従来、これらは主にLLMの学習向けに最適化された構成と言われてきましたが、現在のLLM推論におけるKV Cacheの転送もこれらの高速なNetworkを前提として考えられています。つまり、同一GPUサーバーの中でDisaggregationをする場合はKV Cacheの転送にはScale Up Networkを利用し、GPUサーバー間でDisaggregationする場合はScale Out Networkを利用したGPUDirect RDMAによるGPUメモリー間データ転送を行う、という構成を取る形です。
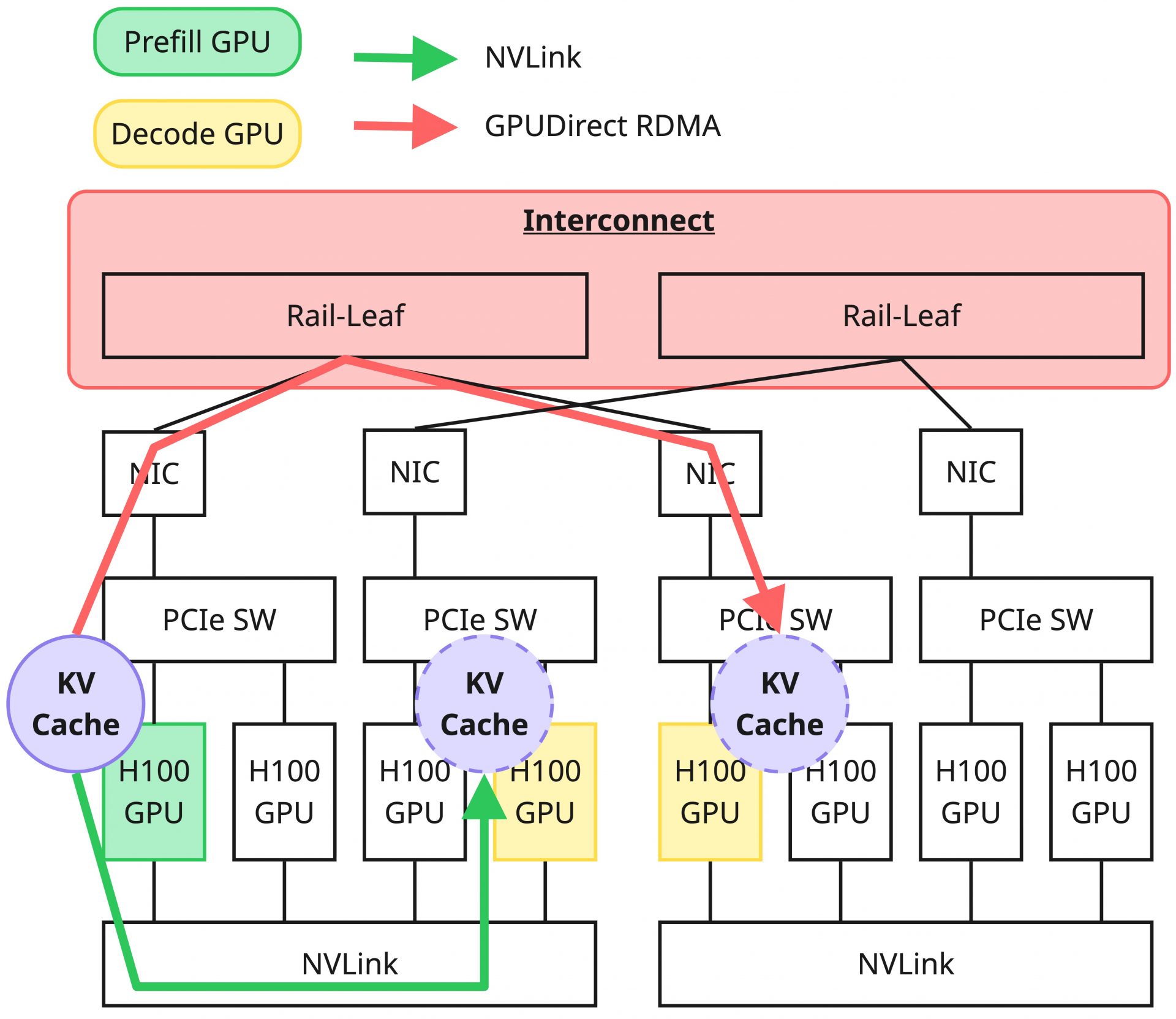
今回の連載に関連する検証を行う上で、私が高火力 PHYと同等のサーバーを選択した理由はこのような背景によるものです。また、具体的にこのようなKV Cacheの転送を行うためには、適切な通信方式を選択する能力を持つソフトウェアが必要になります。このソフトウェアについては連載の第2回で詳細にお伝えする予定です。
筆者の主観ですが、LLMの登場以前は「推論は単一GPUで十分、場合によってはMIG(Multi-Instance GPU)などで単一GPUリソースをさらに分割して使う」という形が多かったように思います。もちろん、これらの用途がなくなったわけではありませんし、採用するモデルやシステムの規模感としてフィットするケースもありますが、LLMが登場した結果、推論インフラに求められる要求も学習インフラのように激化するようになってきました。
KV Cacheの重要性
「KV Cacheを再利用することで計算時間を削減する」という考え方は、LLM分散推論システムにおいて最も重要な検討事項です。単に各リクエストのDecodeフェーズの計算量の削減にとどまらず、システム全体としてKV Cacheを効率よく利用する様々な技術(オフロードや共有、圧縮、ルーティング技術など)が提案・実装されており、LLMの推論基盤ではKV Cacheを設計の中心に据えることが定石となってきています。
KV Cacheがどのようなものか、どのようなケースで再利用可能かを把握できると、KV Cacheにまつわる最適化技術のコンセプトは比較的理解しやすいように思います。本稿でもKV Cacheの「転送」という視点から、システム的な要請(NVLinkや高速なインターコネクト)について議論しました。ソフトウェアに限らず、推論向けのハードウェアの進化も、このKV Cacheを前提としたものが増えてきているため、KV Cacheを意識して推論の周辺技術を見渡すことも重要だと感じることが多いです。
おわりに
本記事では、LLMの分散推論基盤について、ユーザー体験とそれを基軸としたシステムの最適化という視点から、基本的な概念や技術について紹介してきました。以降の連載では、今回議論した内容をベースとしながら、技術的な詳細について、実際に高火力 PHY想定の環境で構築、検証した内容をもとに紹介していく予定です。
LLMの推論技術や最適化手法は非常に多様であり技術的にも難解です。それぞれの技術は様々な技術的背景やシステム的な前提をもとにしていることが多いため、エンジニアはそれぞれの技術領域に閉じず、ネットワーク、サーバー、GPUの仕組みや特性、ソフトウェアに至るまで全体を把握することが非常に重要です。今回は紙面の都合上割愛しましたが、現在のLLMのベースとなるTransformerの構造や処理についても、正しく技術を理解する上ではほぼ必須の知識になります。
また、最新の技術が常に我々が抱える規模のシステムに対して有効であるとは限らないと私は考えています。今回はあえてPD Disaggregationに対して、それが改善するものを明確化し、小規模環境におけるコストなどの観点から疑問を投げかけてみました。具体的なデータに基づく議論は続く連載に任せるとして、我々は目の前の技術に対して、自身の持つシステムの規模や今後の発展性、投資計画などをもとに、適切に取捨選択をする技術的審美眼が必要になると考えています。
今回の連載が、LLMの推論基盤に興味があるエンジニアや、今後推論基盤を構築してみたい・構築の予定のあるエンジニアにとって、少しでもLLM推論基盤技術の理解の一助となれば幸いです。