AIスパコン「さくらONE」で挑むLLM・HPCベンチマーク (1) MLPerf Llama 2 70Bファインチューニング性能検証


はじめに
近年、生成AIの進化を支える大規模言語モデル(LLM: Large Language Model)の開発には、莫大な計算資源と高効率な分散学習基盤が不可欠となっています。こうした需要に応え、国内における最先端のAI研究・産業利用を支えるために、さくらインターネットの組織内研究所である「さくらインターネット研究所」は、AI向けマネージドHigh Performance Computing(HPC)クラスター「さくらONE」を構築しました。さくらONEでは、AIとHPCの両面から性能を多角的に検証することを目的に、複数の代表的なベンチマークを実施しました。その成果の一つとして、2025年6月に発表されたスーパーコンピューターの国際性能ランキング「TOP500」にて世界49位にランクインしました。
本連載では、全3回にわたってさくらONEで実施した各種ベンチマーク結果をご紹介します。第1回となる本稿では、機械学習の国際標準ベンチマークであるMLPerfの概要と、Llama 2 70BモデルのLow-Rank Adaptation(LoRA)ファインチューニングのベンチマーク結果を中心に解説します。続く第2回・第3回では、GPT-3の大規模事前学習やHigh Performance Linpack(HPL)などのHPC系ベンチマークを取り上げ、AI・HPC両領域における代表的なベンチマークの概要と、さくらONEにおける性能検証の結果を紹介します。さくらONEの技術的な詳細についてはホワイトペーパーをご覧ください。
MLPerfとは
MLPerfは、AI・機械学習システムの性能を公平に評価するための国際的なベンチマークスイートであり、2018年に設立された学術機関と企業によるコンソーシアム「MLCommons」によって運営されています。MLPerfの目的は、AI・機械学習システムの性能を測定する明確な指標を提供することで、研究、エンジニアリング、マーケティング、および業界全体の競争者を同じ目標に向けて整合させ、AI技術全体の健全な発展を促すことです。
MLPerfは複数のベンチマークスイートで構成されており、主要なものとしてTraining(学習)とInference(推論)があります。Trainingは品質目標に到達するまでの学習時間を評価し、Inferenceは学習済みモデルの予測処理の性能を複数のシナリオ(Single Stream、Multistream、Server、Offline)で評価します。さくらONEは、LLMをはじめとする大規模AIモデルの学習を主要なユースケースとしているため、今回はMLPerf Trainingカテゴリのベンチマークを実施しました。
MLPerf Training
MLPerf Trainingは、AIモデルが事前に定義された品質目標に到達するまでの学習時間(time-to-train)を測定するベンチマークです。このベンチマークの設計と手法は、機械学習システムに関する国際会議MLSys 2020で発表され、論文として公開されています。このベンチマークの主な特徴は以下の通りです。
- エンドツーエンドの性能測定:time-to-trainには、計算性能だけでなく、GPU間通信、I/O性能、ソフトウェア最適化など、システム全体の統合能力が反映されます。
- 品質と性能のトレードオフを考慮:最適化によってスループットを向上できても、低精度の数値演算や大きなバッチサイズの使用により、モデルの品質が低下する場合があります。time-to-trainを指標とすることで、このような品質を犠牲にする最適化を防ぎます。
- 現実的なワークロードを反映:AI学習の主な目標である「所望の品質のモデルを可能な限り迅速に学習する」という実際のニーズを正確に反映しています。
正式投稿と審査
MLPerf Trainingは、原則として年2回の正式な提出期間(ラウンド)が設けられており、各組織の提出結果はMLCommonsによる審査と検証を経て正式結果として公開されます。この正式提出プロセスを通じて、産業界・学術界のさまざまなシステム実装間での公平な比較が可能になり、ラウンド間の結果比較によりハードウェアやソフトウェアスタックの進歩を定量的に追跡できます。
ディビジョン構成
MLPerf Trainingは、公平性と革新性を両立させるため、次の2つのディビジョンを設けています。
- Closed Division:学習データ、モデルアーキテクチャ、学習方法、品質目標が固定され、一部のハイパーパラメータの調整も制限されます。これにより、異なるハードウェアやソフトウェアスタック間で公平な条件下でのシステム性能比較が可能になります。
- Open Division:任意の学習データ、前処理、モデルアーキテクチャ、学習手法の使用が許可されます。これは新しい技術や手法の検証に適しています。
さくらONEでは、商用HPCクラスタとしての実用性能を評価する目的から、Closed Divisionに準拠した条件でベンチマークを実施しました。
ベンチマークタスク
MLPerf Trainingのベンチマークタスクは、画像認識、自然言語処理、レコメンデーションなど、実世界の多様なAIワークロードを代表しており、システムの汎用的な性能を総合的に評価できます。各タスクは、原則として最低2年間または4回の提出ラウンドのいずれかに達するまで継続的に採用され、その後は技術動向や利用状況に応じて新しいタスクに更新・置き換えられます。
さくらONEでは、2025年4月にMLPerfベンチマークを実施しました。この時点で最新だったMLPerf Training v4.1(2024年10月正式投稿締切)のClosed Divisionに準拠した条件で評価を行いました。v4.1のベンチマークタスクは以下の通りです。
| 領域 | タスク | モデル | 品質目標 |
|---|---|---|---|
| Vision | 物体検出 | SSD (RetinaNet) | 34.0% mAP |
| Vision | テキストから画像生成 | Stable Diffusion v2.0 | FID≤90 かつ CLIP≥0.15 |
| Language | 自然言語処理 | BERT | 0.720 Mask-LM accuracy |
| Language | 大規模言語モデル | GPT3 175B | 2.69 log perplexity |
| Language | 大規模言語モデル | Llama2-70B-LoRA | 0.925 Eval loss |
| Commerce | レコメンデーション | DLRMv2 (DCNv2) | 0.80275 AUC |
| Graphs | ノード分類 | R-GAT | 72.0% classification |
注: 本稿執筆時点の2025年11月では、MLPerf Training v5.1(2025年10月正式投稿締切)が最新版であり、除外されたタスクや追加されたタスクもあります。例えば、LLMの事前学習ベンチマークはLlama3.1 405Bに変更されています。最新のベンチマークタスクについては、MLPerf Training公式サイトをご確認ください。
Llama 2 70B LoRAベンチマーク
本節では、MLPerf Training v4.1のベンチマークタスクの1つであるLlama 2 70BモデルのLoRAファインチューニングベンチマークについて紹介します。本ベンチマークはMLPerf Training v4.0から採用されており、本稿執筆時点で最新のv5.1でも引き続き採用されています。
ベンチマークの概要
Llama 2は、Meta社が2023年7月に公開したオープンソースのLLMです。本ベンチマークでは、700億個のパラメータを持つLlama 2 70Bモデルを使用します。LoRAは、ICLR 2022で発表された論文で提案されたLLMの効率的なファインチューニング手法です。LoRAでは、事前学習済みモデルの重み行列を固定したまま、低ランクの行列ペア(アダプタ)のみを学習することで、学習パラメータ数とメモリ使用量を大幅に削減しながら、全パラメータを更新する従来手法と同等以上の性能を達成できます。この特性により、LoRAは計算リソースが限られた環境でのLLMのファインチューニングや、タスク特化型モデルの開発において広く採用されています。
本ベンチマークでは、評価データセットにおけるCross Entropy Lossが0.925以下に到達するまでの学習時間を性能指標として測定します。MLPerfでは、ベンチマークの実施を容易にするため、事前学習済みのLlama 2 70Bモデルチェックポイントを公式に提供しています。参加者は、このチェックポイントから学習を開始し、LoRAによるファインチューニングを実施します。ベンチマークの適切な実施にあたっては、以下のリソースが利用可能です。
- 参照実装:MLCommonsが提供する公式の参照実装には、モデルのダウンロード、学習データの準備、学習スクリプトが含まれています。
- 正式投稿の実装:MLPerf Training v4.1に正式投稿した各組織の実装も公開されており、実用的な最適化手法を参考にできます。
主要な調整可能パラメータ
MLPerf TrainingのClosed Divisionでは、モデルアーキテクチャや学習方法は固定されていますが、一部のハイパーパラメータの調整が許可されています。ただし、許可されたパラメータについても、調整可能な範囲や値が指定されている場合や、特定の条件下でのみ変更可能とする制約が設けられています。各ベンチマークタスクで許可される調整可能パラメータとその制限の詳細については、MLPerf Training公式ルールをご参照ください。本節では、Llama 2 70B LoRAベンチマークで調整可能パラメータの中でもtime-to-trainに特に大きな影響を与える並列化戦略とバッチサイズの2つについて解説します。
並列化戦略
LLMの学習では、単一GPUのメモリに収まらない大規模なモデルサイズや、効率的な計算資源の活用のために、複数の並列化手法を組み合わせます。主要な並列化手法として、データ並列、テンソル並列、パイプライン並列があり、その全体像が以下の図に示されています。

データ並列(Data Parallelism, DP)
同一モデルのコピー(レプリカ)を複数作成し、学習データを分割して並列に処理する手法です。各GPUは異なるデータバッチで独立に順伝播と逆伝播を実行し、計算した勾配を全GPU間で同期(All-Reduce通信)してモデルを更新します。上図の例では、データ並列度DP=2であり、2つの同一モデルのレプリカが並列で学習されています。
テンソル並列(Tensor Parallelism, TP)
モデルの各層の重み行列やテンソル演算を複数のGPUに分割する手法です。例えば、Transformerの注意機構や全結合層の行列演算を複数のGPUで分担することで、単一GPUのメモリ容量を超える大きな層を扱えるようになります。上図の例では、テンソル並列度TP=4であり、1つのモデルレプリカを4つに分割しています。
パイプライン並列(Pipeline Parallelism, PP)
モデルの層を複数のGPUに分割し、各GPUが連続する層のグループ(ステージ)を担当する手法です。上図の例では、パイプライン並列度PP=4であり、GPU 0-3が最初のステージ、GPU 8-11が次のステージというように、モデルを深さ方向に分割しています。
並列化手法の組み合わせ
実際の大規模なLLM学習では、これら3つの並列化手法を組み合わせた「3D並列」が広く用いられます。上図は「DP×TP×PP = 2×4×4」の構成例を示しており、同色のGPUが同一ノード上に配置されることで、ノード内の高速通信を活用してテンソル並列を実行し、ノード間通信でパイプライン並列とデータ並列を実現しています。さらに、これらに加えて、入力テンソルをシーケンス次元に沿って分割するコンテキスト並列(Context Parallelism, CP)や、各層の計算における活性化テンソルを分割するシーケンス並列(Sequence Parallelism, SP)などの手法も組み合わされ、システムの規模や特性に応じた多様な並列化戦略が取られます。Llama 2 70B LoRAベンチマークでは、これらの並列化手法の組み合わせを調整することで、最適な性能を引き出すことが重要です。
バッチサイズ
バッチサイズは、学習の効率と収束速度に大きく影響するパラメータです。分散学習においては、以下の2つのバッチサイズを区別して考慮する必要があります。
グローバルバッチサイズ(Global Batch Size, GBS)
分散学習において、全GPU・全ノードで同時に処理される1ステップあたりの総サンプル数です。大きなグローバルバッチサイズは、より安定した勾配推定を可能にし、学習の収束を安定させます。ただし、バッチサイズが大きすぎると学習率などのハイパーパラメータの調整が必要になる場合があります。
マイクロバッチサイズ(Micro Batch Size, MBS)
1つのGPUが一度の順伝播・逆伝播で処理するサンプル数です。マイクロバッチサイズは、GPUメモリの使用量と計算効率のバランスを決定します。大きすぎるとメモリ不足(Out of Memory)を引き起こし、小さすぎるとGPUの計算資源を十分に活用できなくなります。
ベンチマーク測定
測定結果
本ベンチマークでは、1ノード(8 × NVIDIA H100 SXM 80GB GPU)から96ノード(768 × NVIDIA H100 SXM 80GB GPU)まで段階的にスケールを拡大し、各構成におけるtime-to-trainを測定しました。測定結果とそれぞれのパラメータ設定は以下の通りです。
| Item | 1 Node | 8 Nodes | 64 Nodes | 96 Nodes |
|---|---|---|---|---|
| Total GPUs | 8 | 64 | 512 | 768 |
| DP (Data Parallelism) | 2 | 8 | 64 | 96 |
| TP (Tensor Parallelism) | 4 | 4 | 4 | 4 |
| PP (Pipeline Parallelism) | 1 | 1 | 1 | 1 |
| CP (Context Parallelism) | 1 | 2 | 2 | 2 |
| SP (Sequence Parallelism) | True | True | True | True |
| GBS (Global Batch Size) | 8 | 8 | 64 | 96 |
| MBS (Micro Batch Size) | 1 | 1 | 1 | 1 |
| Time-to-train (min) | 28.444 (unverified) | 4.789 (unverified) | 1.941 (unverified) | 1.256 (unverified) |
注: 本稿で紹介する結果は非公式(unverified)なものであり、MLCommons Associationによる検証を受けていない点にご留意ください。
パラメータ選定
MLPerf Training v4.1に正式投稿した各組織の実装では、並列化戦略とバッチサイズなどのパラメータ設定も公開されているため、これらを参考にしました。各組織の実装を確認すると、例えばLLMの事前学習ベンチマークでは各組織が独自にパラメータを探索している一方で、Llama 2 70B LoRAベンチマークにおいては、ほぼすべての組織が同一のパラメータ設定を採用していることが判明しました。この理由は定かではありませんが、本ベンチマークにおいては最適なパラメータ設定がある程度確立されている可能性があります。実際に、これらの標準的な設定とは異なるパラメータでベンチマークを試行しましたが、time-to-trainの改善は見られませんでした。このため、さくらONEでのベンチマーク実施においても、独自のパラメータ探索を行わず、v4.1における正式提出組織と同一のパラメータ構成を採用しました。
性能評価
スケーラビリティ
各構成におけるtime-to-trainの測定結果を以下の図に示します。
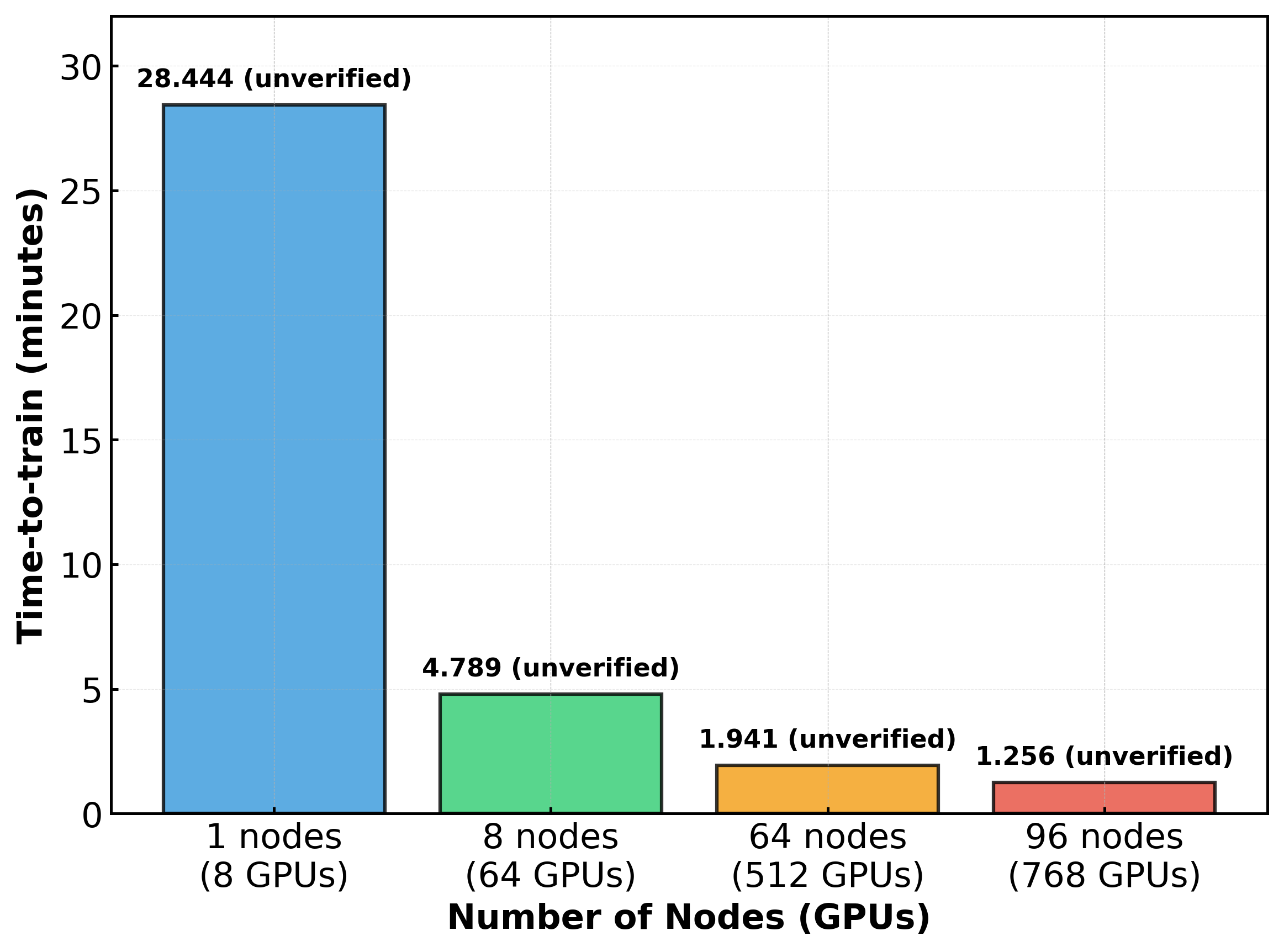
実験結果から、システムスケールが大きくなるにつれて、time-to-trainが短縮されていることが確認できます。具体的には、1ノードから8ノードへのスケールアップにより、time-to-trainは28.444分から4.789分へと約5.9倍短縮され、1ノードから96ノードへのスケールアップでは約22.6倍の短縮が実現されました。ただし、GPU数の増加に対するtime-to-trainの短縮率は、スケールが大きくなるにつれて低下しており、特に64ノード以降では並列化による短縮率の低下が顕著です。これは、通信オーバーヘッドの増大や、本ベンチマークの計算規模に対して大規模なシステムでは並列化の限界に近づいていることを示唆しています。
他システムとの比較
MLPerf Training v4.1の正式提出結果のうち、同規模で同一GPU(NVIDIA H100 SXM 80GB)を使用したシステムと比較すると、1ノード(8GPU)構成における最速記録は27.54分、8ノード(64GPU)構成における最速記録は4.75分であり、さくらONEはこれらとほぼ同等の性能を示しました。なお、96ノード(768GPU)構成での正式提出はありませんでしたが、128ノード(1024GPU)構成の最速記録は1.188分であり、さくらONEの96ノード構成の結果(1.256分)とほぼ同等の性能でした。
おわりに
本稿では、AIスパコン「さくらONE」で実施したMLPerf Training Llama 2 70B LoRAファインチューニングベンチマークの結果を紹介しました。MLPerfは、AI・機械学習システムの性能を公平に評価するための国際標準ベンチマークです。time-to-trainという明確な指標により、ハードウェア性能だけでなく、システム全体の統合能力を評価できます。さくらONEでは、1ノード(8GPU)から96ノード(768GPU)まで段階的にスケールを拡大し、MLPerf公式提出結果と同等の性能水準を達成しました。これにより、さくらONEがLLMのファインチューニングにおいて競争力のある性能を持つことが実証されました。次回は、同じくMLPerf Training v4.1に含まれるGPT-3 175B事前学習ベンチマークを取り上げ、より大規模な分散学習における性能検証の結果を紹介します。
なお、さくらインターネットでは、今回ご紹介した「さくらONE」に加え、GPUベアメタルクラウドの「高火力 PHY」、GPU仮想マシンの「高火力 VRT」、GPUコンテナの「高火力 DOK」、そして推論APIサービス「さくらのAI Engine」も提供しています。ぜひご利用ください。