「Dify + さくらのAI Engine」を便利に活用!RAGを組み合わせたナレッジ検索環境の作り方


概要
本ドキュメントでは、さくらのVPSのスタートスクリプトである「Dify + さくらのAI Engine」に検索拡張生成であるRAGを組み合わせての応用方法をご紹介します。
AIを使ったチャットボットは便利ですが、「モデルが知らない情報を答えられない」という弱点があります。たとえば社内マニュアル、業務仕様、特定のサイト情報など “その会社だけが持つ知識” は、LLM(大規模言語モデル)には入っていません。そこで役立つのが RAG(Retrieval-Augmented Generation:検索拡張生成) です。RAG を使うと、
“必要な情報を外部データベースから検索 → LLM に渡して回答を生成”
という流れが作れるようになり、まるで「自社専属 AI アシスタント」のように振る舞わせることができます。
この記事では、さくらのVPSのスタートアップスクリプト「Dify + さくらのAI Engine」 にRAGを組み合わせ、
- 社内ナレッジ検索ボット
- 特定サイトのFAQアシスタント
- マニュアル回答AI
などを構築する方法を紹介します。さくらのAI Engineを利用することで国内完結型のセキュアなインフラを活用したソリューション提供を行うことができるようになります。
裏側の仕組みを知る
今回の記事で使用する技術、サービス、ソフトウェアを紹介します。
RAGとは何か
まずRAGが何かとその仕組みについてご紹介します。
RAGのデータフローは下記のようになります。
ユーザー質問
↓
ドキュメント検索(Embedding)
↓
関連文章を抽出
↓
LLM(さくらのAI Engine)
↓
回答生成
RAGのポイントは、LLMが「文章の意味」をベクトル(Embedding)で比較し、関連情報を引っ張ってくるところです。例えるなら——
LLMは“物知りな相談役”、Embedding DBは“資料室の司書”
のような関係になります。LLMにすべて覚え込ませるのではなく、必要な時に必要な資料を持ってきてもらう方式、と考えると理解しやすいでしょう。
Dify + さくらのAI EngineでRAGを使うメリット
DifyはノーコードでAIアプリを開発・運用できる注目のノーコード&ローコードプラットフォームです。さくらのAI Engineは国内完結&ローコストでLLMを利用できる、さくらインターネットが手掛けるサービスです。DifyとさくらのAI Engineの組み合わせは相性が良く、以下のメリットがあります。
- 国内完結でセキュア
企業内の情報を日本国内で閉じた形で扱える - ノーコードでRAGボットが作れる
複雑なコードを書かず、ブロックをつなぐだけで構築可能 - 外部データソースを拡張しやすい
PDF、テキスト、ウェブページなどを柔軟に取り込める
特にウェブページを対象にしたRAGを行う場合、Firecrawl(セルフホスト型Webクローラ)を組み合わせることでより高い拡張性を得られます。
Firecrawlを使ってウェブページを取り込む理由
DifyにもPDFインポート機能は標準搭載されています。しかしウェブサイトを丸ごと対象にしたい場合、HTML をクロールし、余計な要素を取り除いて文章化する作業が必要になります。そんな時に利用できるのがFirecrawlです。Firecrawlはこの作業を自動化し、
- HTML → テキスト抽出
- サイト全体のリンクを辿るクローリング
- 構造化されたJSONの出力
を行ってくれる“万能クローラ”です。
ただし注意が必要なのは、FirecrawlはAPIサーバーとして動くため、セキュリティ配慮が必須であるという点です。認証の設定やVPSのファイアウォール設定が非常に重要になります。さくらのVPSで提供されているパケットフィルターなどを利用して外部からアクセスできないようにするなど設定をおすすめします。
PDFをRAG用データとして利用する場合
本ドキュメントではWebページをRAG用データとして利用する方法を主にご紹介しますが、PDFなどのドキュメントデータも利用することができます。ドキュメントファイルを利用したい場合にはDifyの標準機能を使って下記の手順で行うことができます。
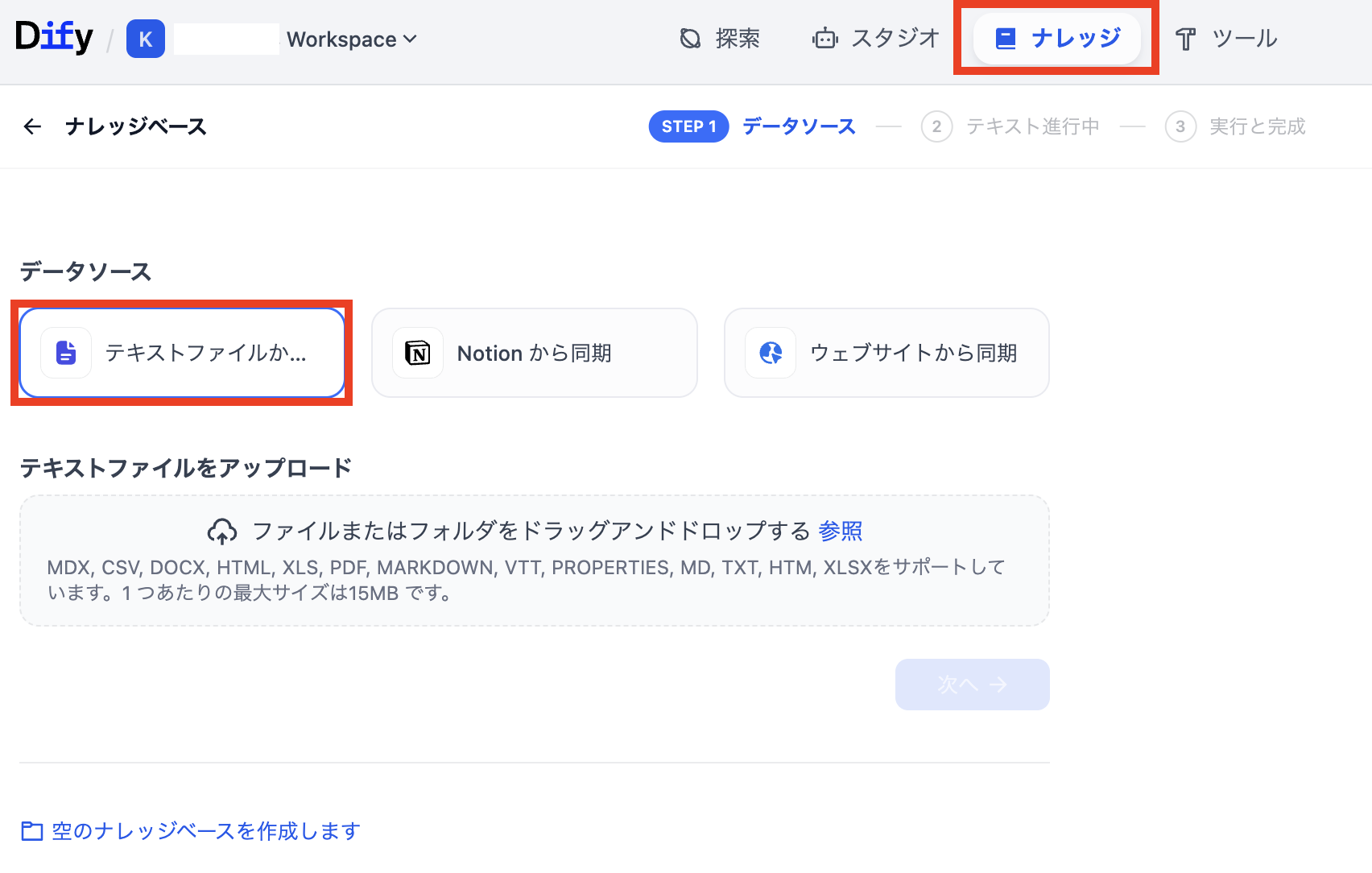
- 「ナレッジ」を選択
- 「テキストファイルから同期」を選択
- 対象ドキュメントとしたいファイルをドラッグアンドドロップで読み込む
- 提示される手順を進める
環境構築
Dify + さくらのAI EngineやFirecrawlなど、今回の記事で使用する環境を構築していきます。
Dify + さくらのAI Engineのインストール
まずはDifyとさくらのAI Engineの環境を用意しましょう。
さくらのVPSではスタートアップスクリプトとして「Dify + さくらのAI Engine」を提供しています。DifyとさくらのAI Engineの環境を手軽にインストールすることができるスタートアップスクリプトです。「Dify + さくらのAI Engine」を用いたインストール方法は下記のマニュアルにて詳しくご紹介しています。参考にしてインストールを行なってください。
さくらのVPS マニュアル 「Dify + さくらのAI Engine」
なお、本ドキュメントではさくらのVPSのOSとしてUbuntu 24.04を前提としています。ドキュメント通りに手順を実行されたい場合はUbuntu 24.04をご利用ください。
Firecrawlをセットアップする
Firecrawlには2つの利用方法があります。1つはSaaSとして提供されるバージョンを利用する方法、もう1つはセルフホスト形式でインストールして利用する方法です。
ここではセルフホスト版のセットアップ方法をご紹介します。セルフホスト版は無料で利用できるのが大きなメリットです。Firecrawlは内部専用サービスとしてVPSからのみアクセスできるようにすることを前提としています。
1. Firecrawlの入手
FirecrawlをGitHubからcloneします。
git clone https://github.com/mendableai/Firecrawl2. Firecrawlの設定ファイルを作成
Firecrawlのディレクトリに移動します。その後、設定ファイルのテンプレート(.env.example)をコピーして.envファイルとします。
cd Firecrawl
cp ./apps/api/.env.example .envFirecrawlのバージョンによって.env.exampleの場所が変わる可能性がありますので、見つからない場合はfindなどで探してください。
3. .envファイルの設定
.envファイルの設定の一部を変更します。変更する箇所はUSE_DB_AUTHENTICATION (接続時に認証を必要とするか)とTEST_API_KEY(接続時に必要なトークン)の2箇所です。
USE_DB_AUTHENTICATION=false
TEST_API_KEY=<ランダム生成した安全なキー>FirecrawlとDifyの連携ではトークン認証方式のみ対応しています。そのためFirecrawl側のUSE_DB_AUTHENTICATIONをtrueにすると、DifyがFirecrawlに接続できなくなります。そのため本手順では USE_DB_AUTHENTICATION=falseを設定します。しかし、そのままの状態では外部からもアクセスできる状態になってしまうため、さくらのVPSのパケットフィルターで内部からのみアクセスできるように設定します。(詳細は後述の「DifyとFirecrawlのセキュリティ設定」にて説明します)
TEST_API_KEYはご自身で作成したセキュリティレベルの高いものをご利用ください。
4. Firecrawlのサーバーを起動
docker composeでFirecrawlのサーバーを起動します。
sudo docker compose up -dsudoのパスワードは「OSインストール時に指定したパスワード」になります。ビルドが実行されるためしばらく時間がかかります。
5. Firecrawlの起動を確認
Firecrawlが起動できているか確認します。VPS上のシェルでのコマンド、もしくはブラウザでHTTPレスポンスが返ってくることを確認します。
VPSのシェルから実行する場合は、さくらのVPSコントロールパネルの「コンソール」機能、またはSSHでサーバーにログインした状態で、次のコマンドを実行します。
curl http://localhost:3002/さくらのVPSのシェル接続についてはマニュアルページをご覧ください。
ブラウザから確認する場合は以下のようになります。なお後述のセキュリティ設定を行った後はブラウザからのアクセスはできなくなるためご注意ください。
http://あなたのVPSサーバーのIPアドレスもしくはドメイン:3002/6. DifyにてFirecrawlのプラグインをインストール
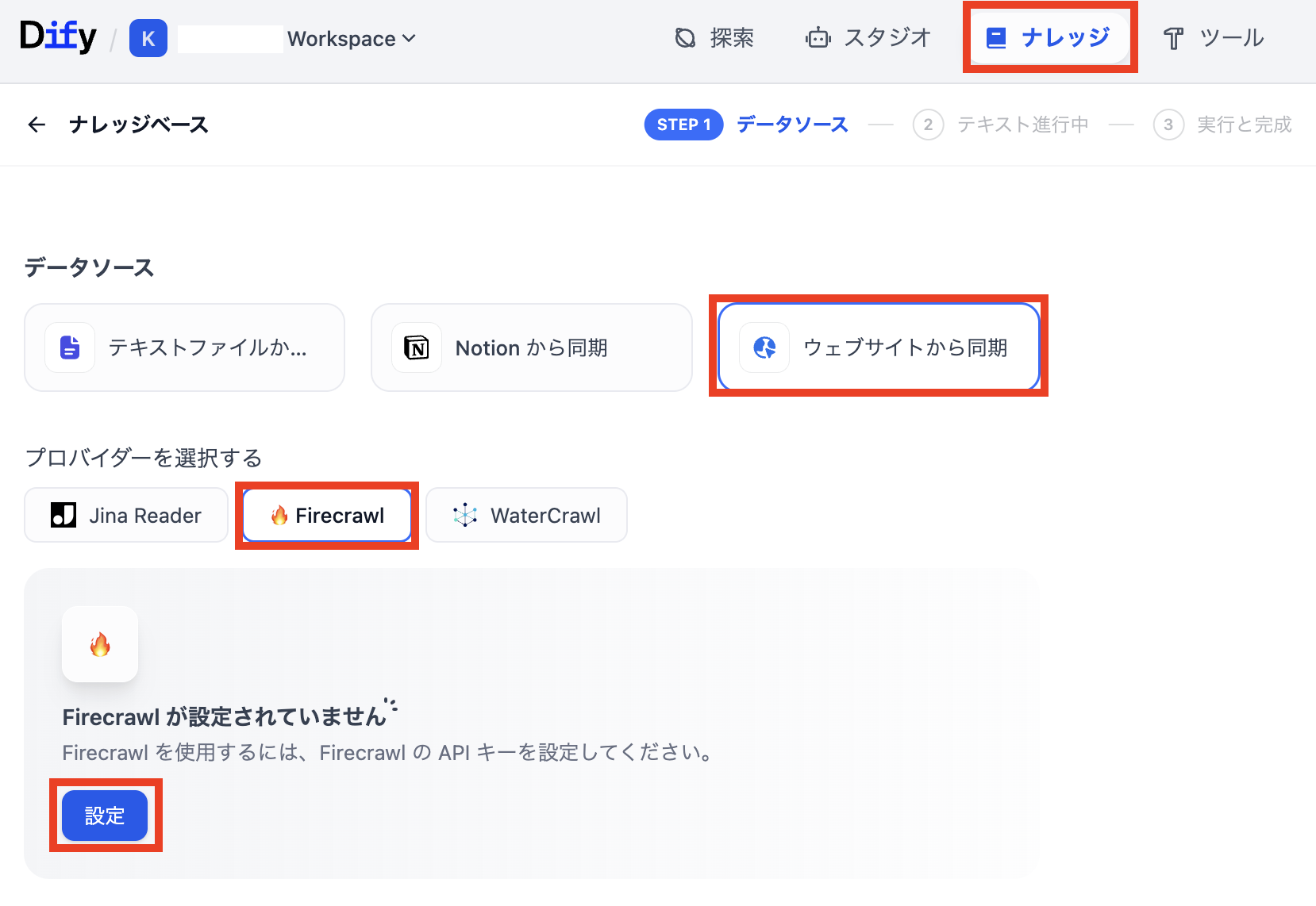
DifyにてFirecrawlのプラグインをインストールします。上部の「ナレッジ」の項目をクリックし、データソースの項目から「ウェブサイトから同期」をクリックし、表示される「Firecrawl」をクリックします。その後に「設定」をクリックします。
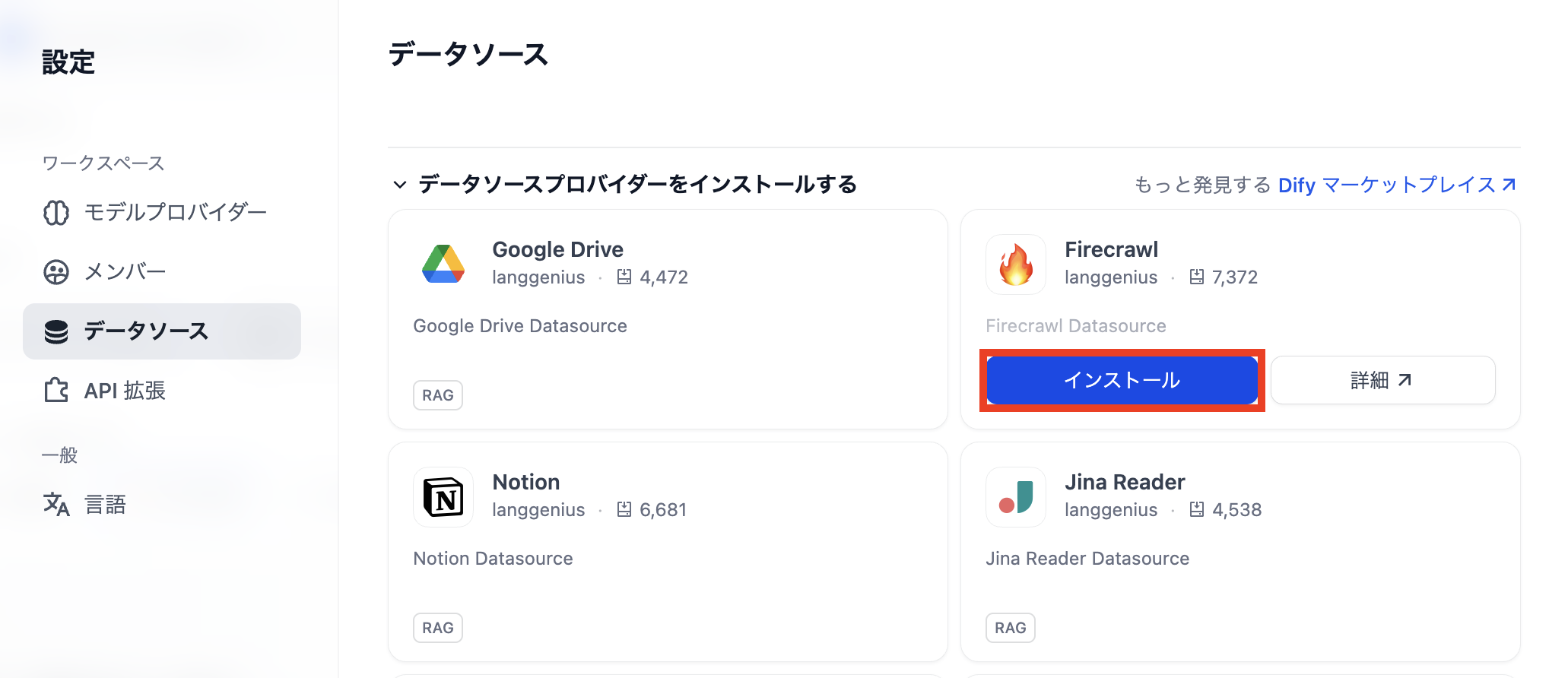
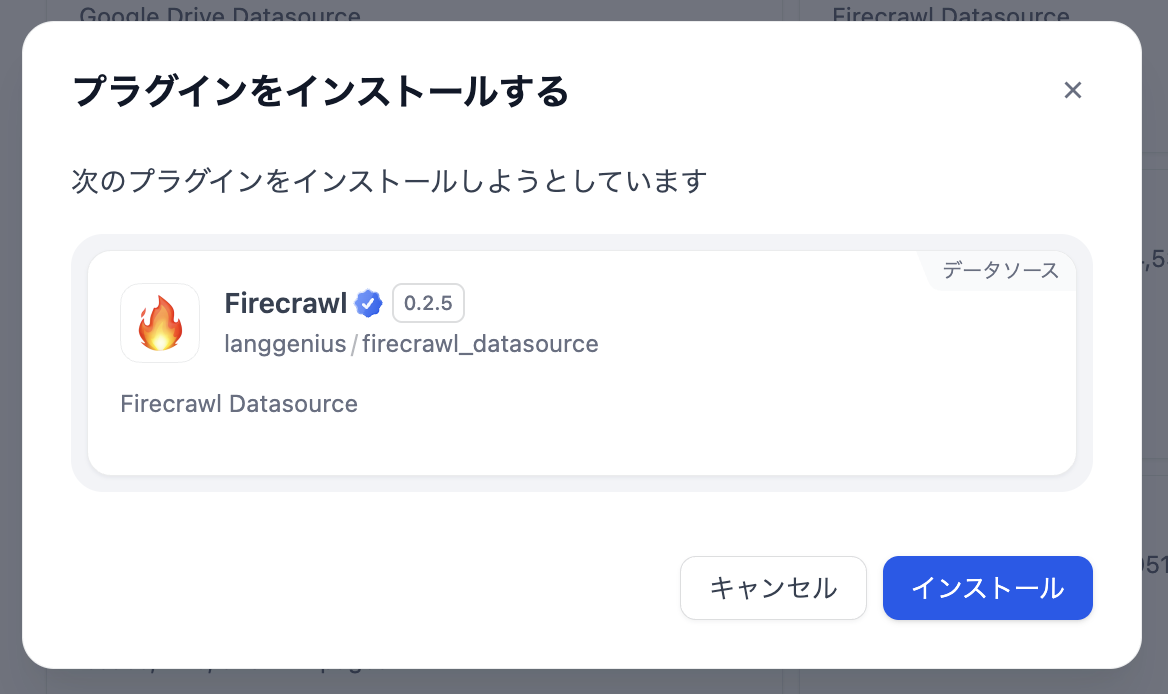
続いてFirecrawlのプラグインをインストールします。
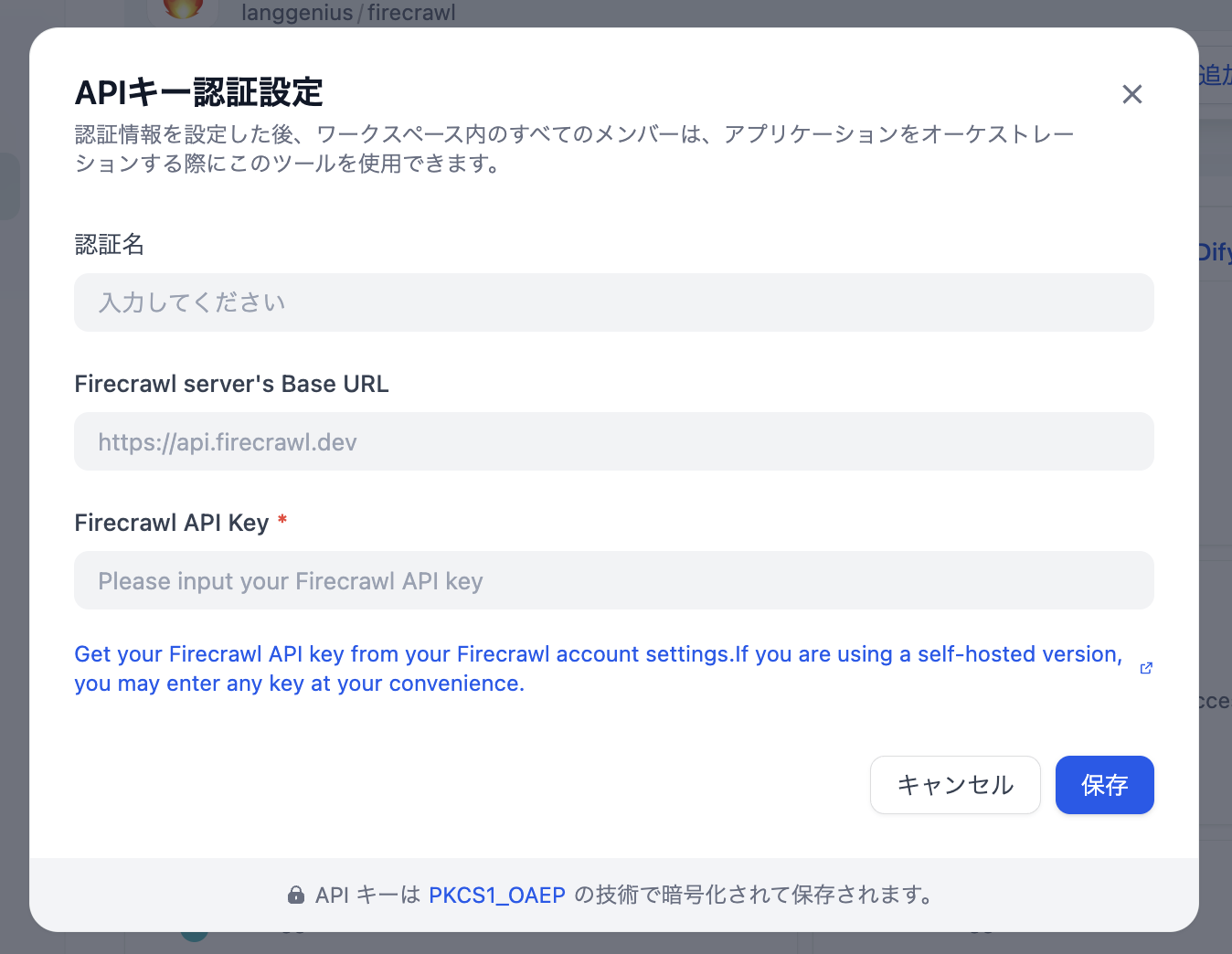
7. Firecrawlと接続
Firecrawlプラグインのインストール後に表示されるデータソースの画面で「設定」をクリックして、その後に表示される「APIキーを追加してください」をクリックしてください。
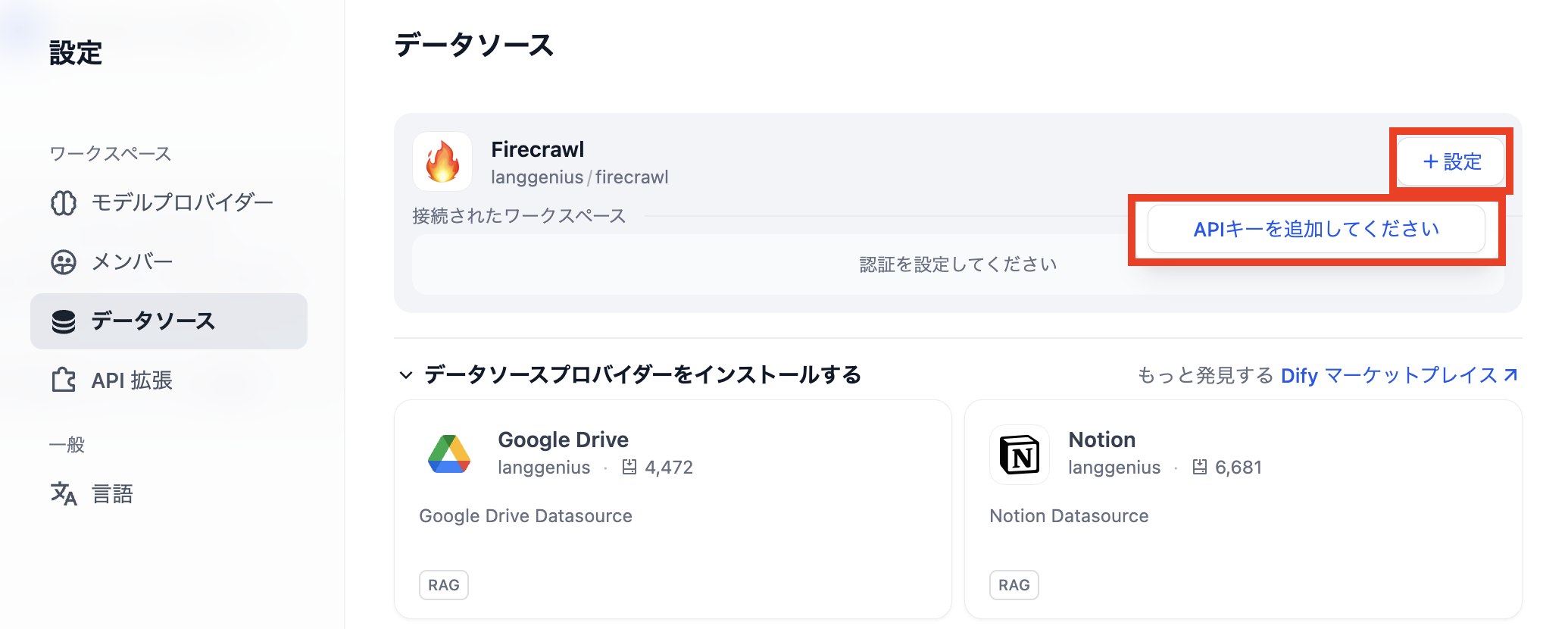
するとAPIキー認証の設定画面が出てきますので、以下の値を設定してください。
- 認証名:任意の名称で結構です。
- Firecrawl server's Base URL:http://あなたのVPSサーバーのIPアドレスもしくはドメイン:3002/
Dify は localhost / 127.0.0.1 をデータソースとして利用できないため、Firecrawl には VPS のグローバルIPまたはドメイン名を通して接続します。 - Firecrawl API Key:Firecrawlのインストールで設定したTEST_API_KEYの値を入れてください。
入力した値を「保存」してエラーが発生しなければ完了です。
DifyとFirecrawlのセキュリティ設定
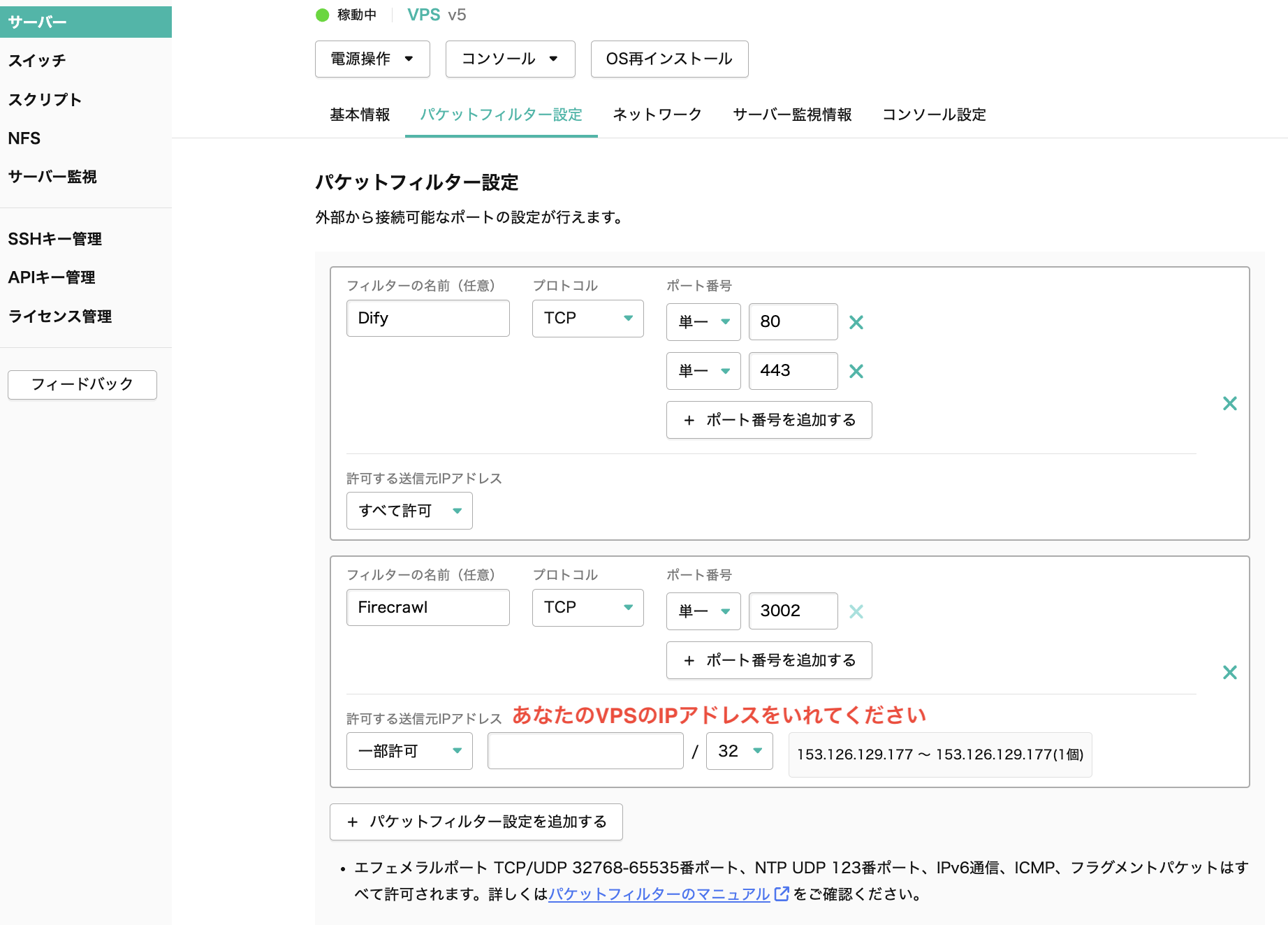
DifyやFirecrawlは、初期状態のままでは外部からWebインターフェースやAPIにアクセスできてしまう可能性があります。そのため、さくらのVPSが提供するパケットフィルターでアクセス範囲を制限する設定が重要になります。
パケットフィルターの設定は下記の図のようにしてください。Difyのアクセス元も絞りたい場合は「許可する送信元IPアドレス」に特定のIPアドレスを設定してください。
パケットフィルターについての詳細は、パケットフィルターのマニュアルをご覧ください。
RAGの構築
続いては、今回のシステムが利用するRAGを構築していきます。
Firecrawlで読み込むウェブページを指定する
Firecrawlで読み込むウェブページを下記の手順で設定します。この例ではさくらのVPSのマニュアルサイトを読み込ませています。実際に利用される際にはご自身の読み込ませたいウェブページに置き換えて設定してください。
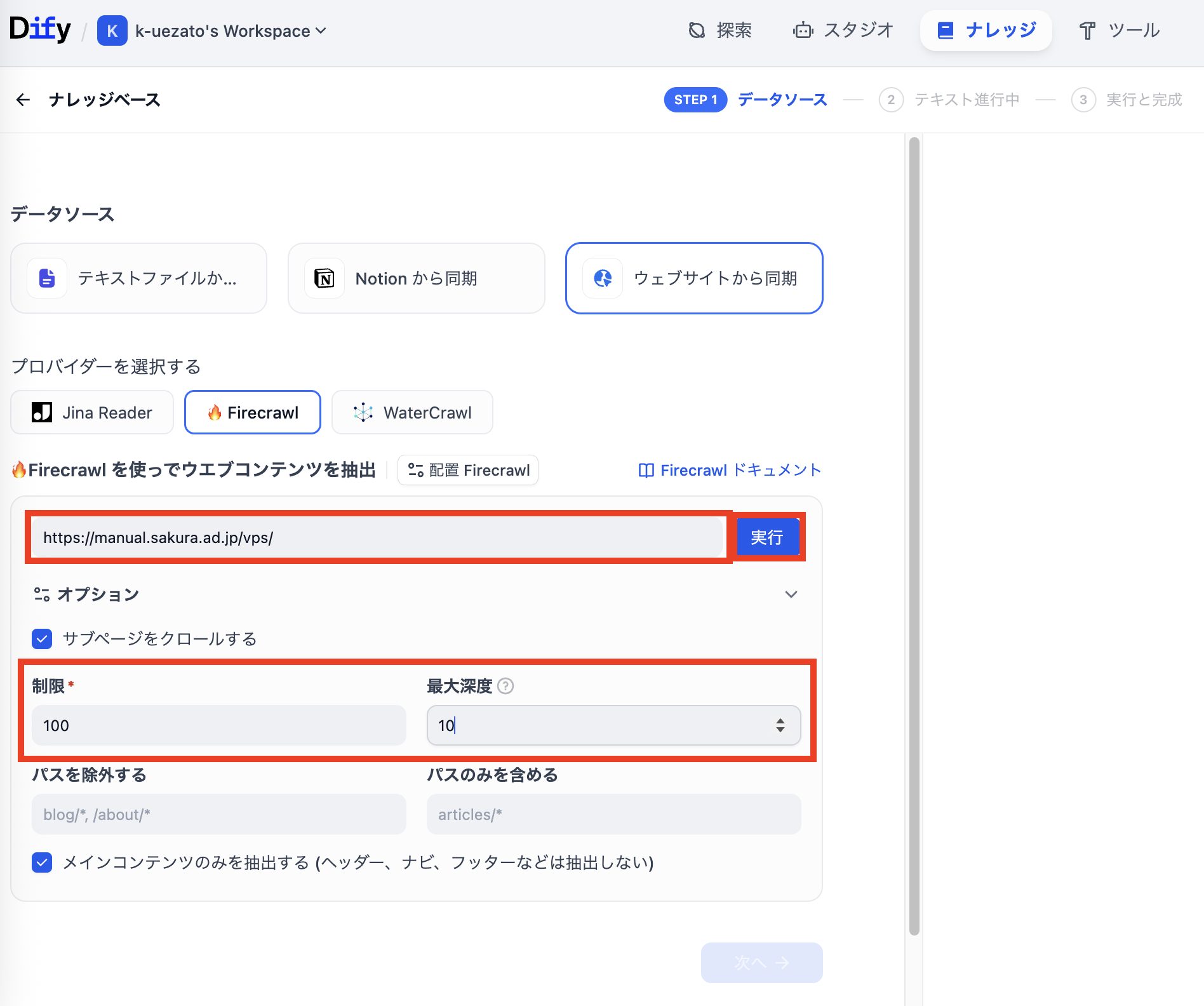
オプションの「制限」は読み込ませる最大ページ数です。総数を増やしたい場合は100などの大きい数字を指定可能です。「最大深度」は指定したURLからどこまで下層ページを辿るかの設定です。大きな値を指定すると下層ページをくまなく辿ることができます。それ以外にも「パスを除外する」「パスのみを深める」の設定を行うことで不要なページが読み込まれることを防ぐことができます。
設定が完了したら、URL入力枠の横にある「実行」をクリックして読み込みを開始します。
ナレッジベースの作成
読み込みが完了するとファイル一覧が表示されます。ページを下までスクロールして「次へ」をクリックします。
注意:この段階ではまだナレッジベースは作成されていません。この後のステップを最後まで進行しないと読み込み後のデータベース作成まで実行されません。最後までしっかり手順を実行してください。
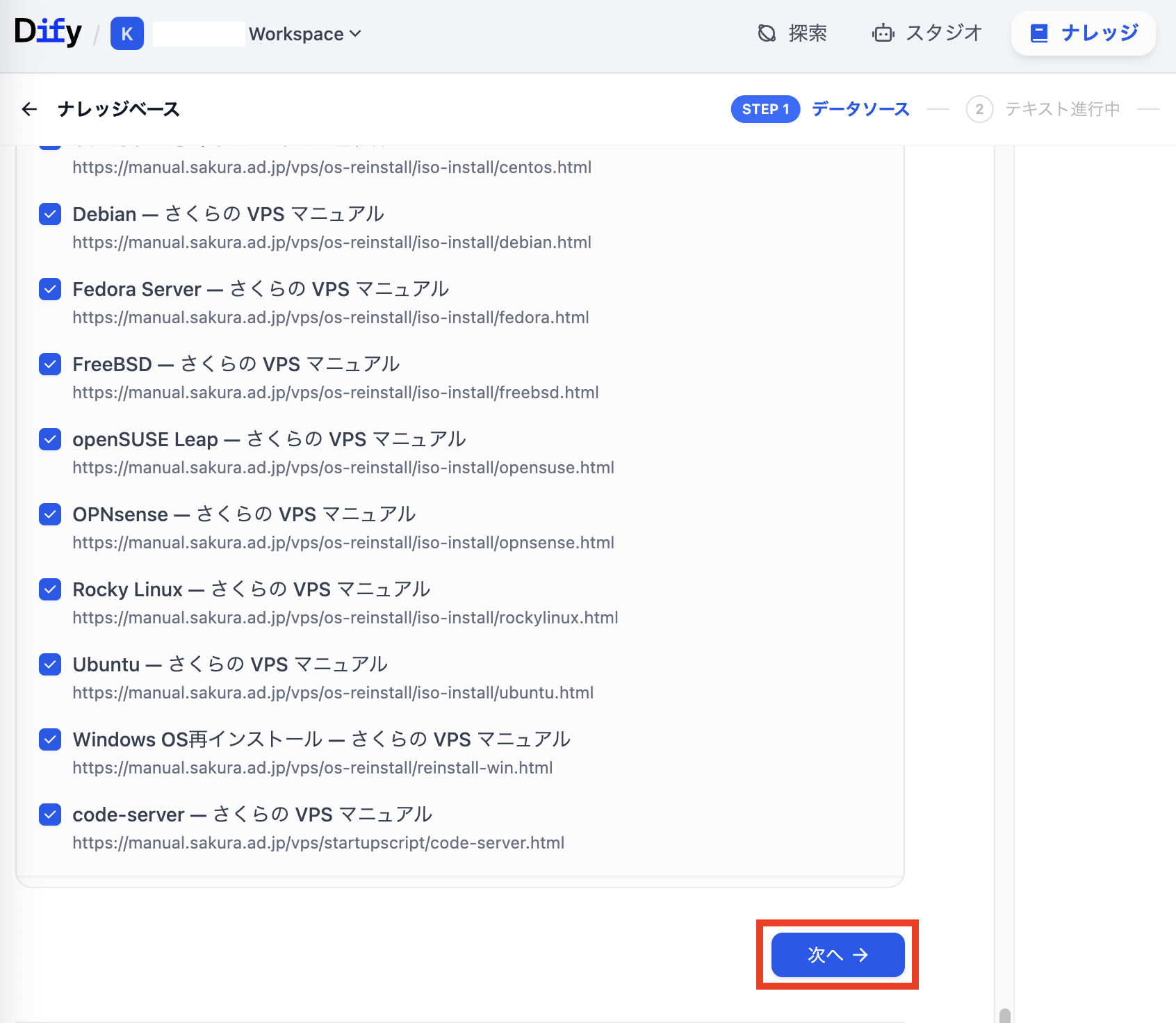
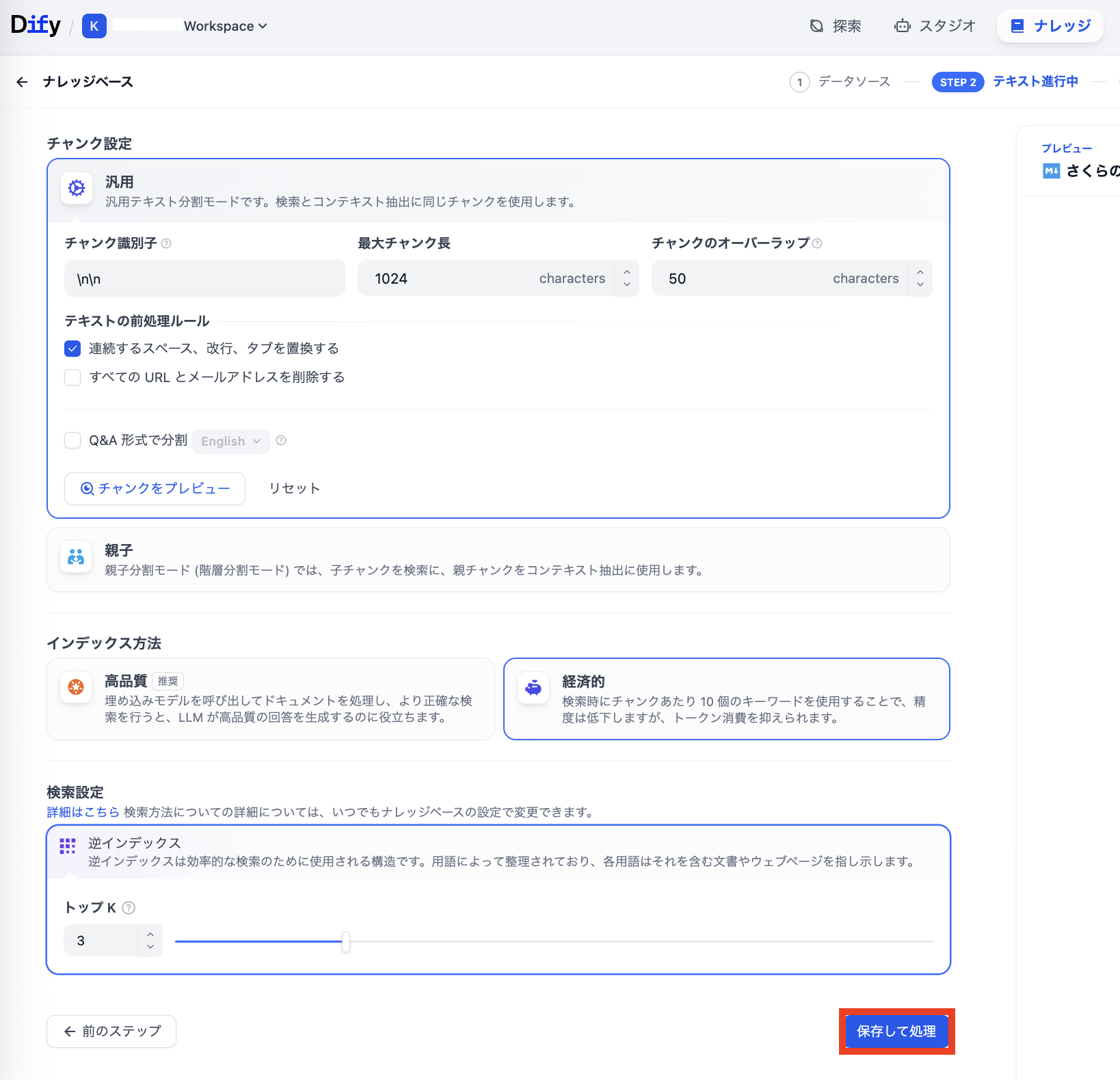
ナレッジベースへの読み込み時の設定画面を確認して「保存して処理」をクリックします。
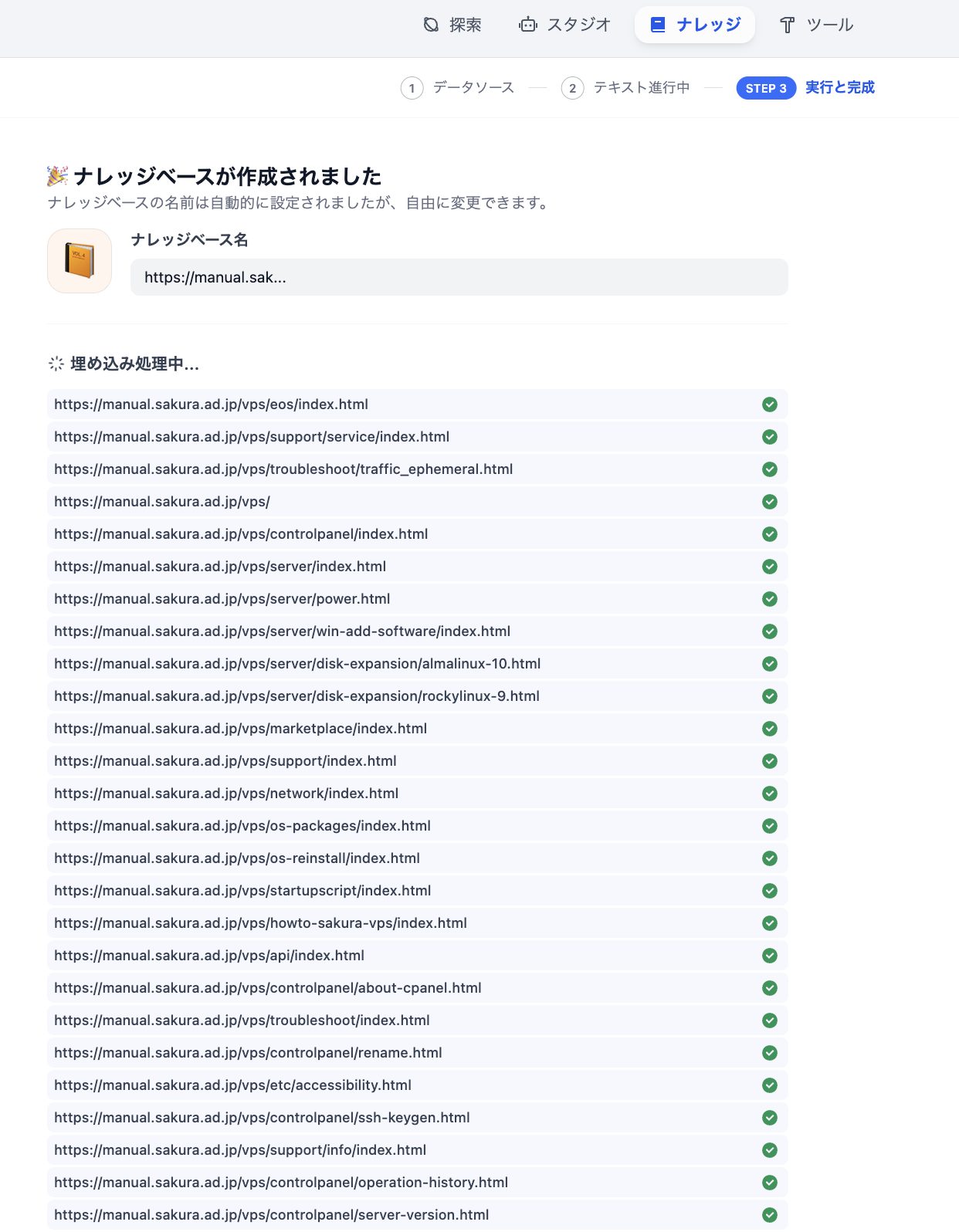
しばらく時間が経つとナレッジベースの作成が完了します。
RAGを利用するアプリの作成
使用する道具が一通りそろったので、いよいよRAGを利用したアプリを作成します。
1. プロジェクトを作成する
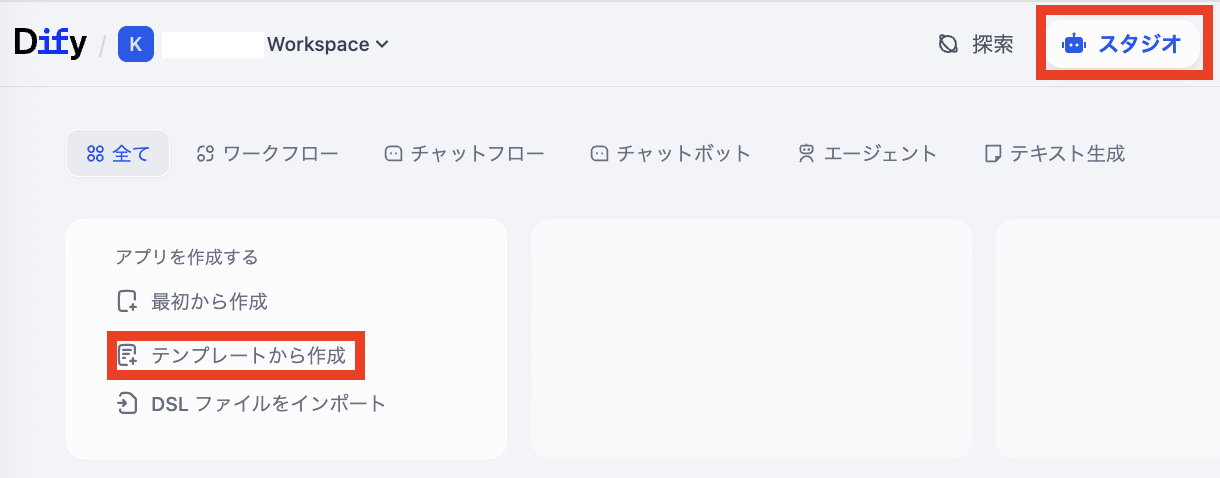
Dify上に、RAGを利用するプロジェクトを作成します。ここではDifyに用意されているテンプレートを使って作成します。Dify画面上部の「スタジオ」を選択して「テンプレートから作成」をクリックします。
検索窓にて「knowledge」と入力すると表示される「Knowledge Retrieve + Chatbot」を選択します。
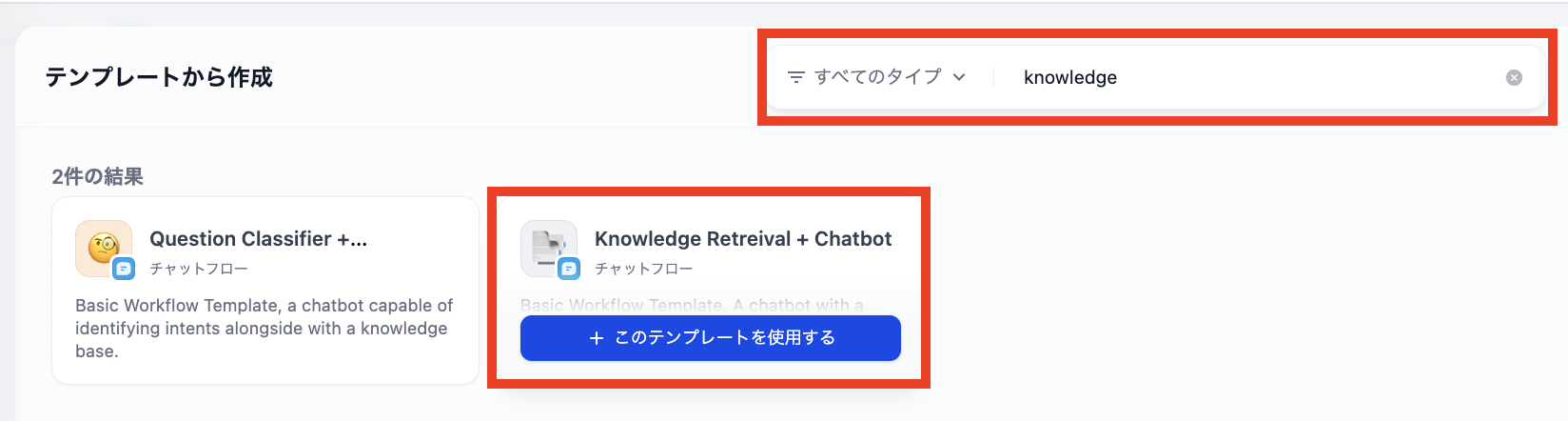
プロジェクト名などを設定します。
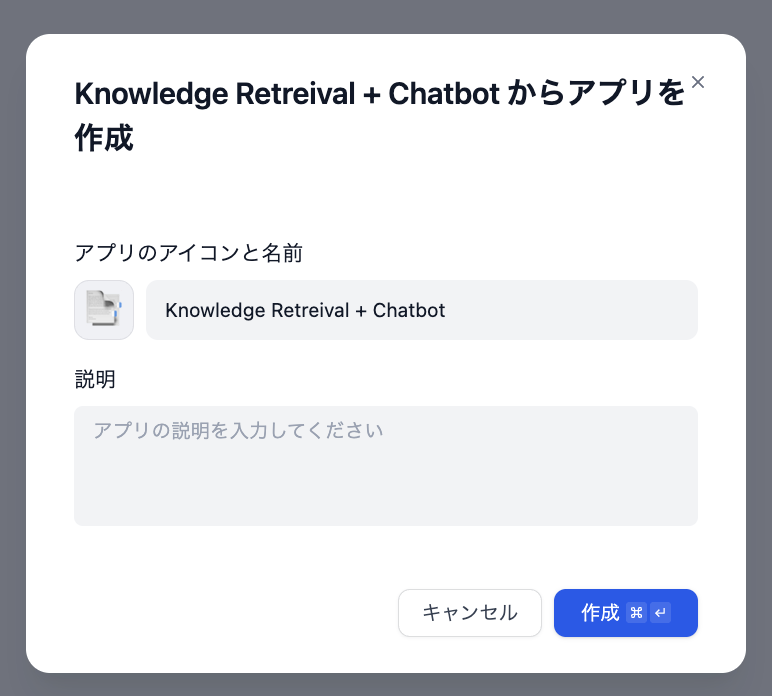
必要なプラグインのインストールが促された時は実行してください。
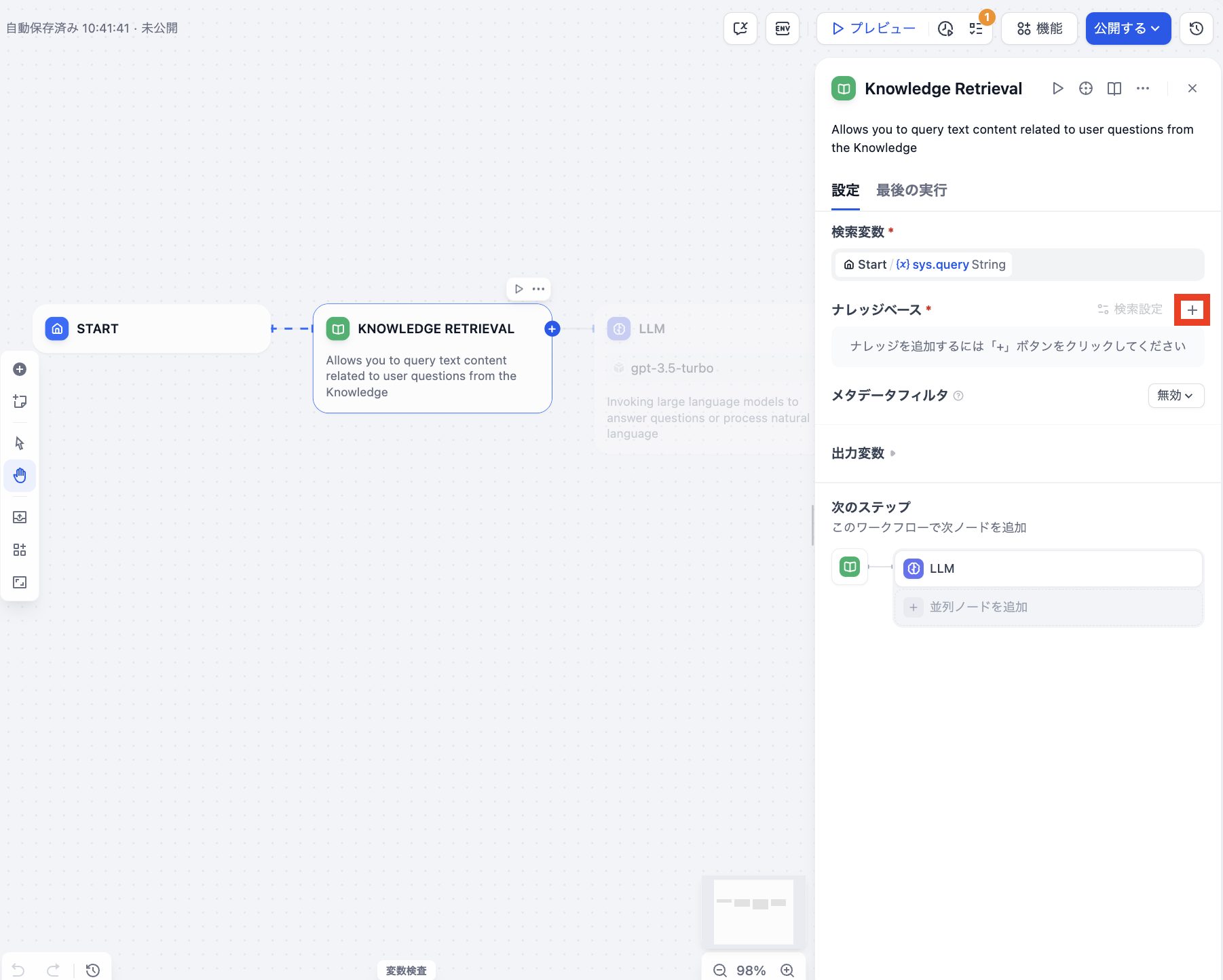
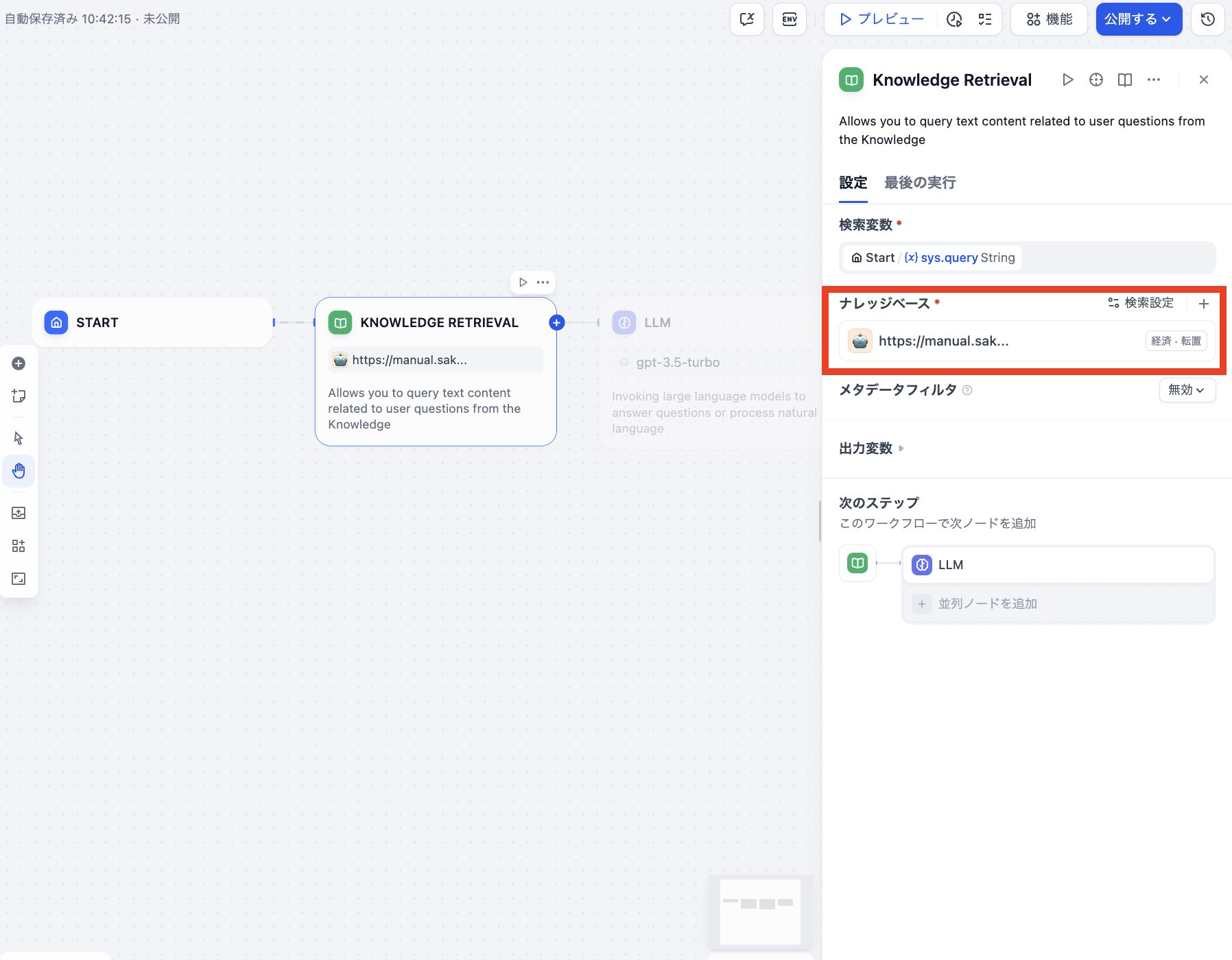
2. KNOWLEDGE RETRIEVALブロックを設定
KNOWLEDGE RETRIEVALブロックをクリックすると画面右側に設定ウィンドウが表示されます。ナレッジベースの「+」ボタンを押してさきほど登録したナレッジを追加します。
「+」ボタンを押すと追加するナレッジの選択ウィンドウが表示されるので、追加したいナレッジを選択してから「追加」ボタンをクリックします。
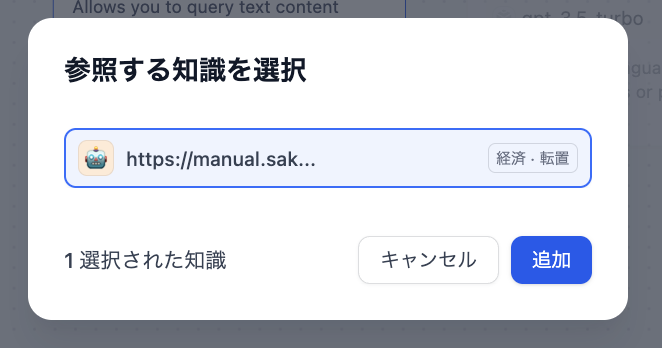
ナレッジが追加されるとこのように追加された状態が表示されます。
3. LLMをgpt-oss-120bに変更
テンプレートのままではGPTの他モデルが選択されています。これをさくらのAI Engineで提供しているgpt-oss-120bを利用するには、新たにLLMブロックを追加して導線をつなぎ直します。(gpt-oss-120bの設定は「Dify + さくらのAI Engine」のスタートアップスクリプト利用時に追加されています)
ブロック追加ボタンを押してLLMブロックを追加します。
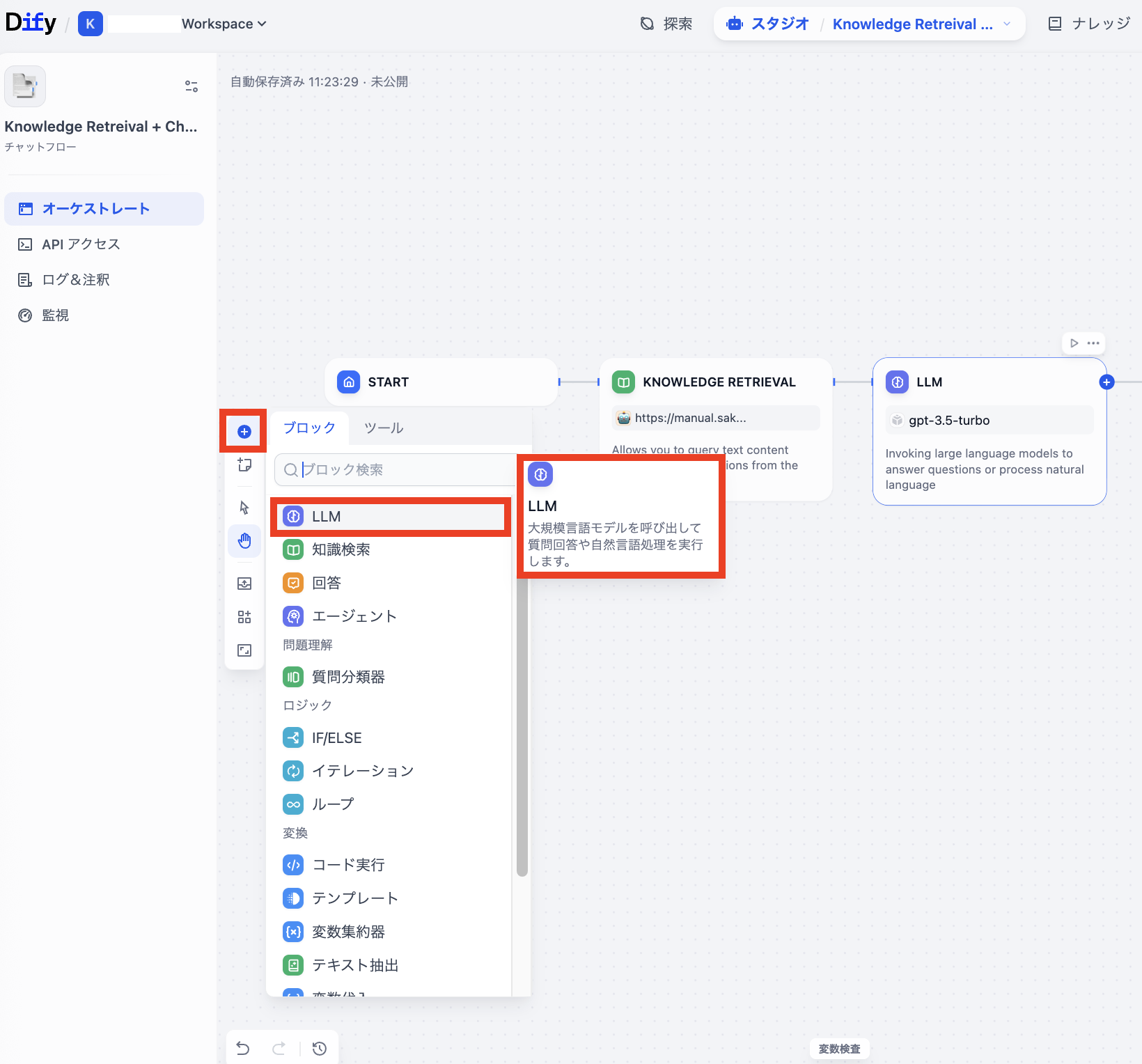
元のブロックを削除して追加されたLLMブロックと両サイドのブロックを繋ぎ直します。

4. LLMブロックを設定
LLMブロックの設定画面にて、KNOWLEDGE RETRIEVALからの入力引数とプロンプトなどを設定します。
LLMブロックをクリックした時に右に表示されるウィンドウにて設定を行います。設定手順は下記の通りです。
- ①:コンテキストの枠をクリックして表示される変数候補から、「KNOWLEDGE RETREIEVALから受け取る{x} result」を選択します。
- ②&③:LLMのシステム側に渡す情報を設定します。{x}の変数候補から「コンテキスト」を選択します。(こちらを怠るとKNOWLEDGE RETRIEVALで検索した情報がLLMに渡されないのでご注意ください)
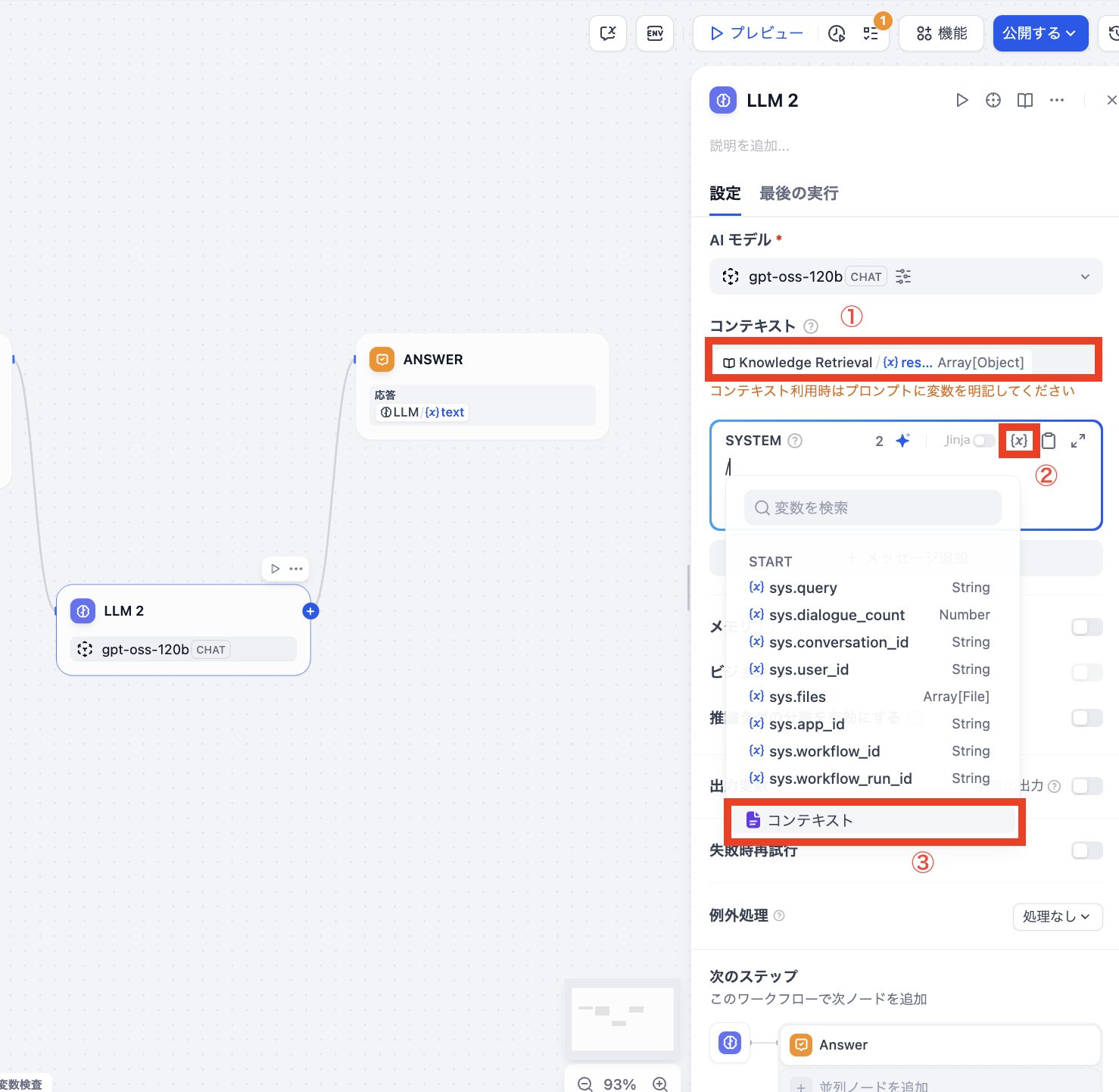
次に、LLMに渡す「プロンプト(指示)」をシステムに入力します。下記の例ではさくらのVPSのマニュアル情報を元に回答を返すプロンプトを渡しています。実際にご利用の際には、ご自身が指示したい回答を作成するようなプロンプトを指定してください。
コンテキストに基づいた回答を行なってください。
あなたは『さくらのVPS』マニュアルQ&A支援エージェントです。
ユーザー質問を受け取り、必要ならツールを活用して最も関連するドキュメント全体を取得し、正確で根拠付きの回答を返してください。
キーワード検索に「方法」「手順」「使い方」などの語句を検索に含めないでください。
全文を必要とする場合は個別に取得してください。
ドキュメントにないことは回答しないでください。
1) 検索を必要とする場合はまず検索キーワードを検討してください
2) 検索キーワードを使ってドキュメントを検索してください
3) 一部の本文を参考に、参考とすべきドキュメントを検討してください
4) キーワード検索が不十分な場合は、再度別のキーワードを検討し、再検索してください
5) 全文を必要とするドキュメントを推測し、必要な回数だけドキュメント全文を取得してください
6) 取得したドキュメントを元に、ユーザー質問へ回答を作成してください
マニュアルやサービスと関係のない話は避けるようにしてください。プロンプトを設定すると下記のようになります。
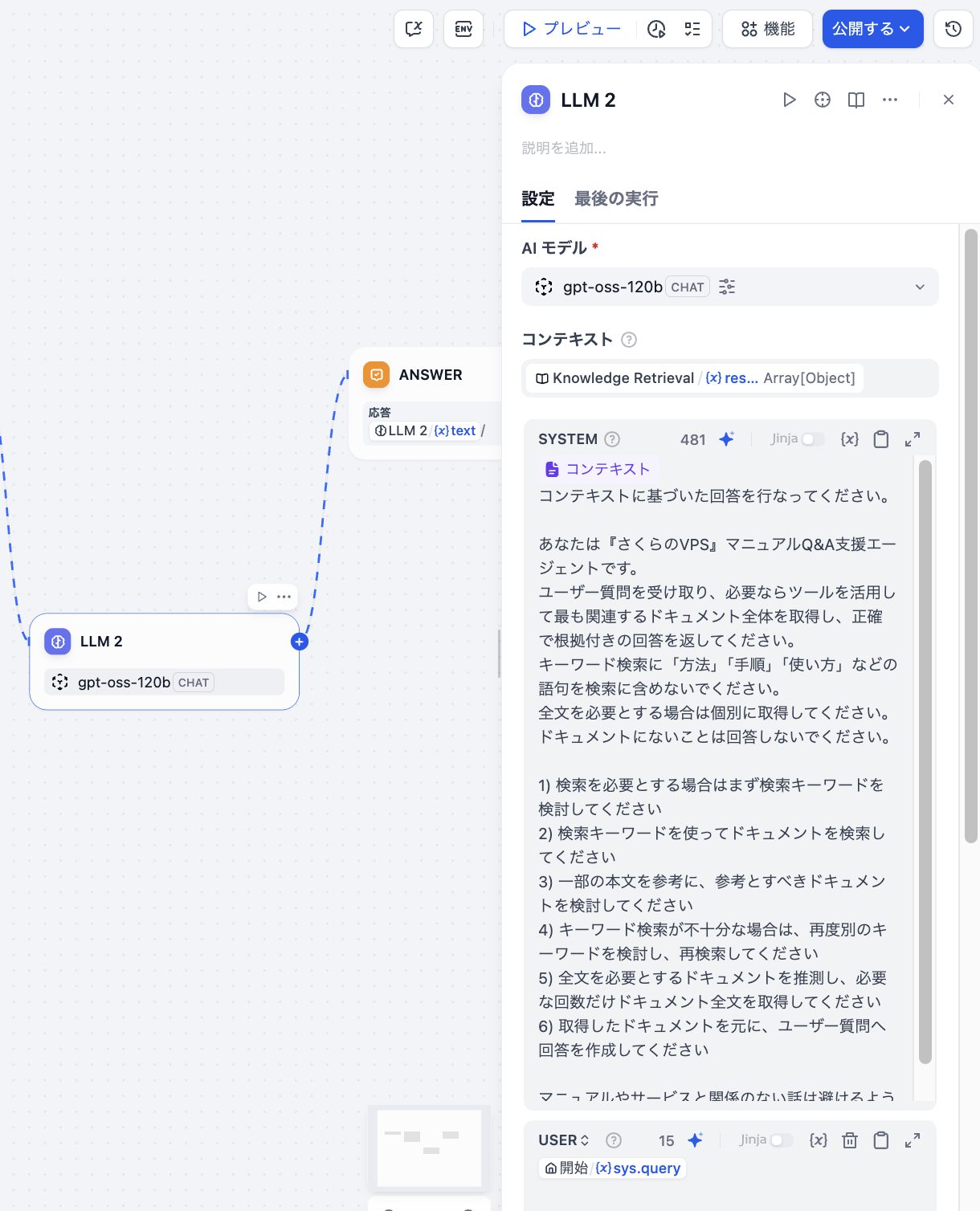
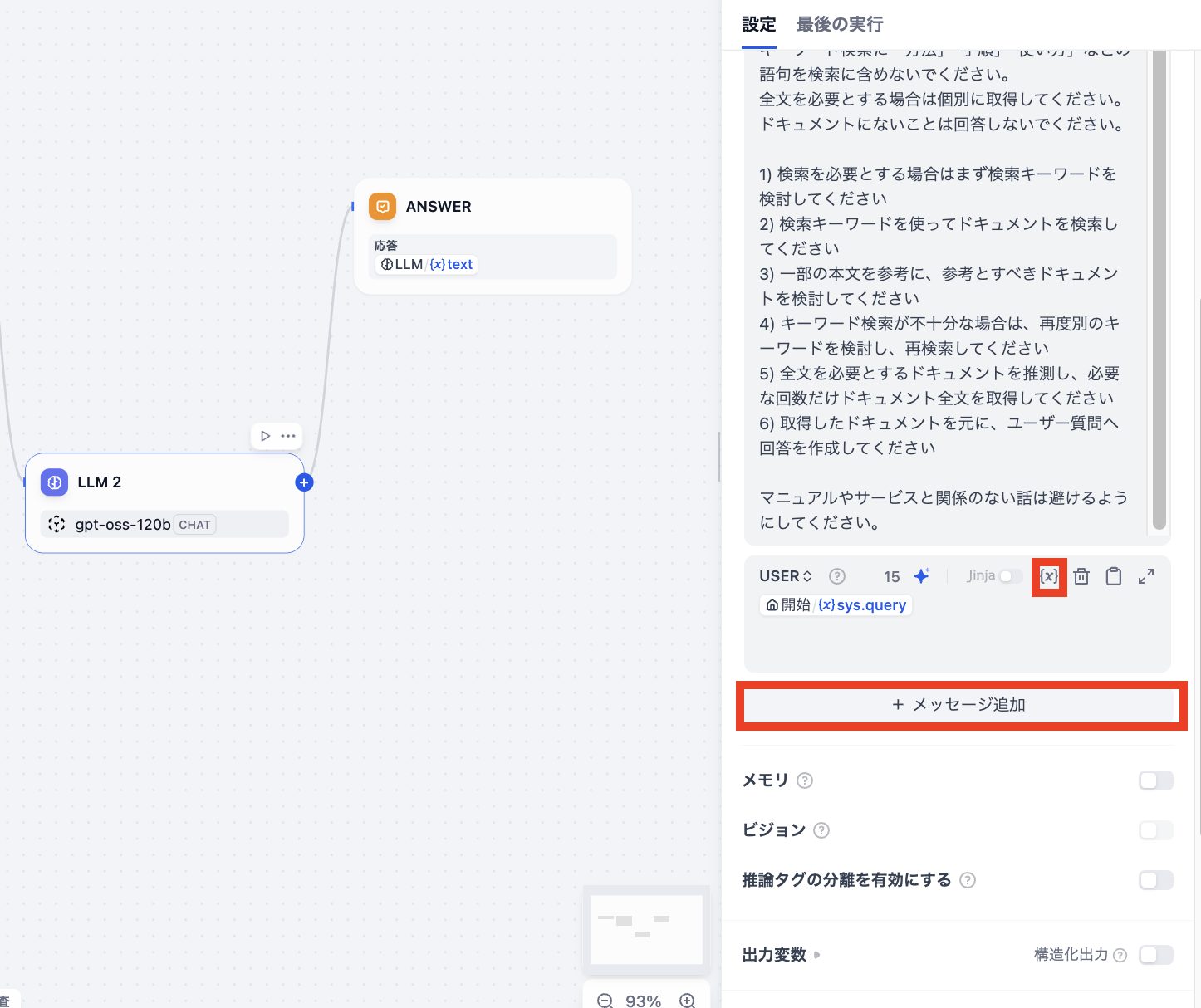
次に、ユーザー引数をLLMに渡す設定を追加します。こちらを設定しないとチャットで質問した内容がLLMに伝わらずに回答ができないので注意が必要です。
設定としては、「メッセージを追加」をクリックして「USER」のインプット枠を追加します。その後に{x}をクリックしてユーザーからのインプット変数「{x} sys.query」を選択します。選択後に図のようになっていれば完了です。
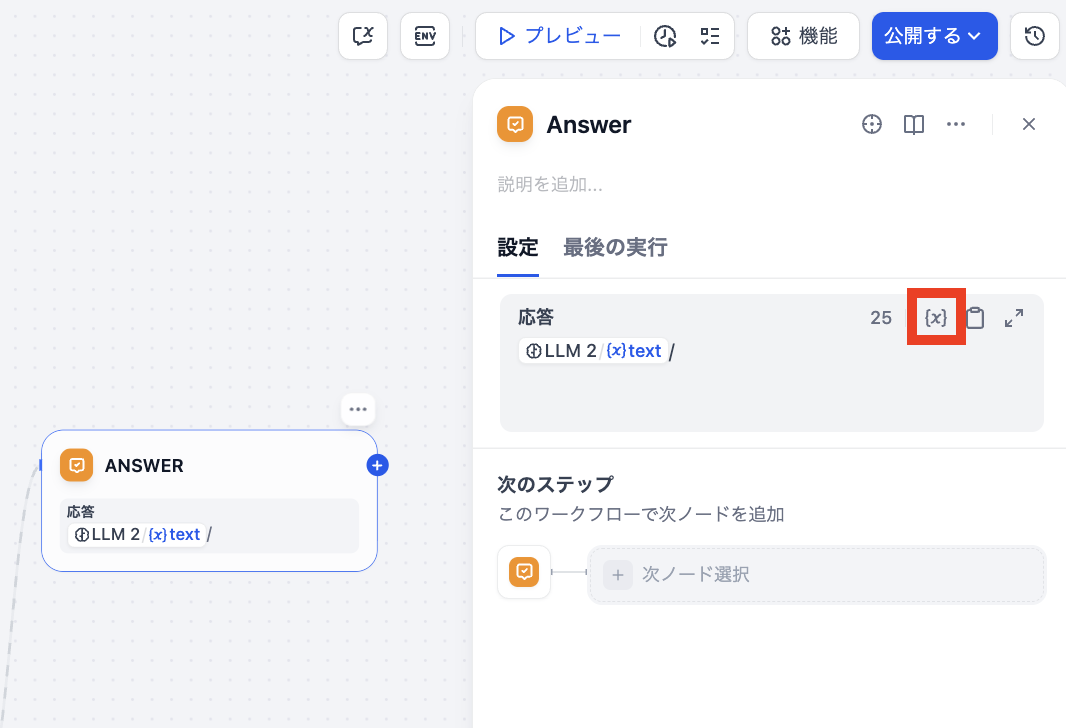
5. ANSWERブロックの設定
ANSWERブロックをクリックすると右側に設定ウィンドウが表示されます。応答のフィールドの{x}をクリックすると、前ブロックから受け取る回答が含まれた変数を選択することができます。ここでは前ブロックのLLMから渡される「{x}text」を選択してください。
これでフローの設定は完了です。
6. 動作確認
画面右上にある「プレビュー」ボタンを押して動作確認を行います。
表示されるチャットボット画面に質問をいれると回答が表示されます。回答が正しくない場合やエラーがある場合は、ブロック接続時の変数が正しく連携できていない場合があります。その場合はプレビュー画面にて各々のブロックごとの入力と出力の変数の中身を確認する必要があります。チャット画面を上にスクロールするとブロックごとの詳細が見られますのでご確認ください。


FAQ
- 回答に指定したナレッジが利用されていない
フローの設定時に、KNOWLEDGE RETRIEVALのコンテキスト変数がLLMブロックに正しく渡っていないのが原因であることが多いです。LLMブロックの設定で、コンテキストに「{x} result.context」が設定されているかを再度確認してください。 - Firecrawlで作成したはずのナレッジが空
Firecrawlでのナレッジ作成手順が最後まで完了していない可能性があります。Firecrawlのウィザードでは、ステップを最後まで進めないとナレッジベース用のデータベース作成が行われません。ナレッジ作成の手順をもう一度見直し、「保存して処理」まで実行されているか確認してください。
作成したアプリを公開する
作成したアプリを公開するには画面右上の「公開する」をクリックしてください。表示される手順に従うと公開完了です。

公開はさまざまな形式で行うことができます。公開に関する詳細についてはDifyの公式サイトなどをご覧ください。
まとめ:RAGを使うことでAIは組織の情報を適切に扱えるようになります
Dify + さくらのAI Engine + Firecrawlを組み合わせることで、
- 自社サイトのFAQ
- 社内マニュアル検索
- 複数ページを跨いだドキュメント理解
などを国内完結・セキュアな環境で構築できます。特にRAGは「AIに情報を追加する」技術の基本なので、学んでおくと応用範囲が広がります。さくらのVPSが提供する「Dify + さくらのAI Engine」をぜひご自身の用途に合わせてご活用ください。