【JANOG57レポート】HPCネットワークの多様化に挑む – マルチベンダー×マルチOSで支えるHPCネットワーク運用の実際


はじめに
さくらインターネットの黒澤です。
2026年2月11-13日(水-金)に大阪にてJANOG57ミーティングが行われました。JANOGでは毎回、さくらのエンジニアがプログラムの募集に応募し、選考に通って発表しています。今回も何件か発表があったのですが、筆者も「HPCネットワークの多様化に挑む – マルチベンダー×マルチOSで支えるHPCネットワーク運用の実際」というタイトルで登壇しました。このセッションではさくらインターネットのマネージドHPCクラスタサービス「さくらONE」を提供するにあたって構築したネットワークインフラ、およびその構築における技術選定について説明し、参加者と議論しました。

さくらONEについて
さくらONEは、NVIDIA H100/H200/B200などのGPUを用いて構築したHPCクラスタをマネージドサービスとして提供するものです。
通常、HPC環境を自社で立ち上げるには、高額なGPUサーバーに加えて、ファシリティ、計算ジョブの管理機能や、障害時の運用体制など、多くのスキルセットや人材を保有する必要があります。さくらONEはこれらをマネージド型サービスとしてさくらインターネットが提供するサービスとなります。私たちはこのサービスによって、お客様が自身の事業に注力した上で、HPCの利用を民主化したいと考えてこのサービスを提供しています。
そして、そのためには、「透明性の高い」「汎用的な技術」によって自社で提供することを重要視しています。
この発表では、「さくらONE」を舞台として、さくらインターネットが行ってきた試行錯誤を共有するとともに、会場の皆様がどのように感じるか議論を致しました。
さくらONEのインフラ
私たちがクラウド事業者としてサービスを提供するにあたって、お客様に対して「高性能」かつ「安全」なインフラをデリバリーする必要があります。非常に高い計算性能を発揮するGPUクラスタをお客様に提供するためには、ネットワークに対しても非常に高度な要件が求められます。
- マルチテナンシー
複数の顧客を収容した際、顧客同士の分離・顧客内の接続性を提供することはサービスの前提となります。 - 広帯域
多数のGPU間で膨大な計算結果を通信するので、GPU同士は400Gbps、それを束ねるスイッチは800Gbpsといった広帯域での接続が必要でした。 - ロスレスネットワーク
従来のEthernetはロスが生じる前提ですが、GPU同士のRDMA(Remote Direct Memory Access)を行うためにはロスの抑制やフロー分散が要求されます。 - 高密度なケーブリング
これらの要件を満たすには、大量のGPUを大量の配線で収容することが必要になります。そして、これらのケーブルを収容するためのラックスペースは有限のため、ケーブルやラックなどのファシリティ設計の難易度が非常に高いものとなります。
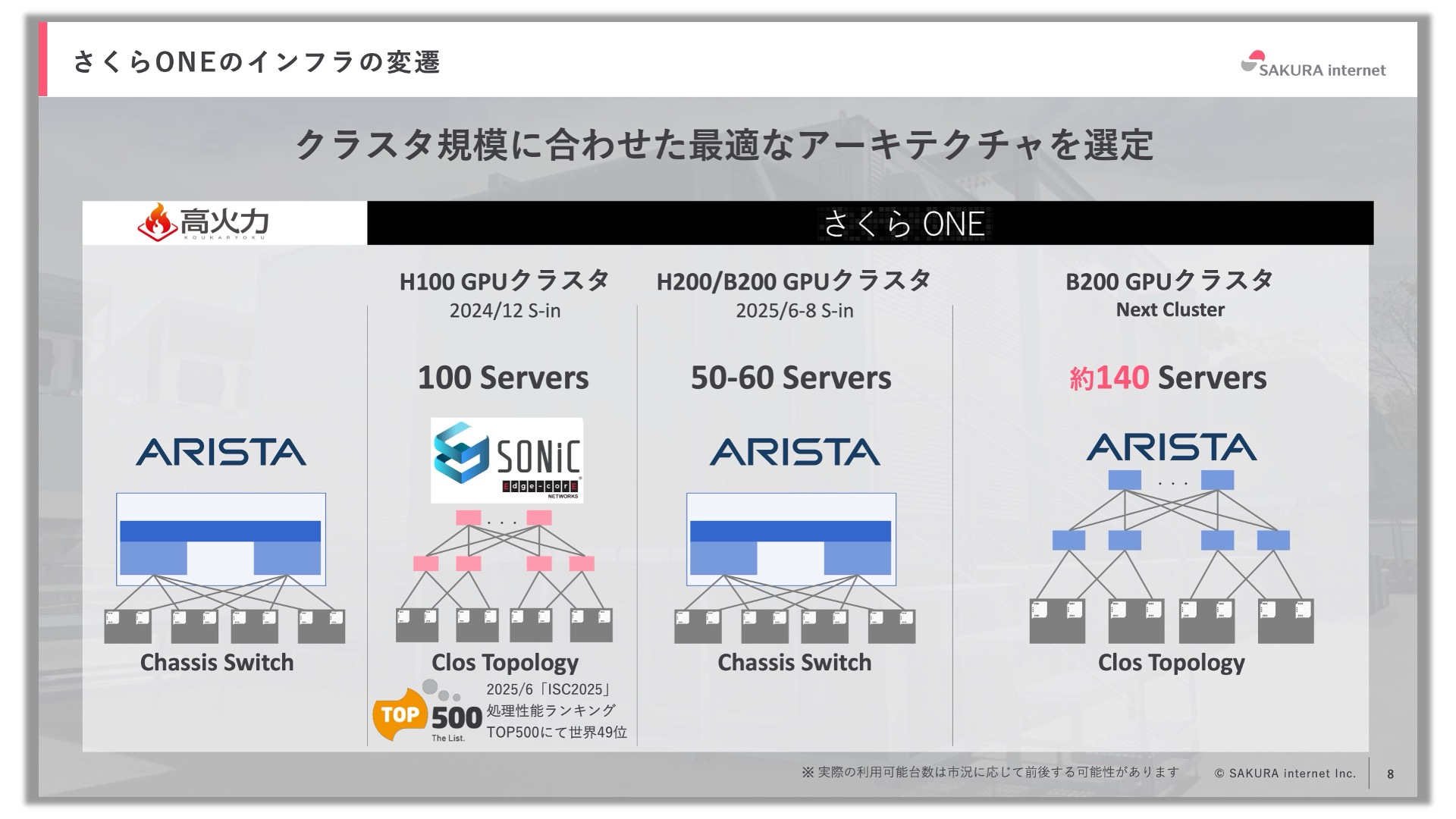
このような要件を満たすために、さくらインターネットではこれまでにいくつかのネットワークアーキテクチャを試行、新しい技術も積極的に導入してきました。上の図はこれまでに構築したさくらONEのネットワークアーキテクチャの変遷です。構築時期が古いものから順に、左から右に並んでいます。なお一番左は、さくらONEよりも前からサービスを提供しているGPU物理サーバ「高火力 PHY」のインフラです。ネットワークアーキテクチャやホワイトボックスの挑戦をはじめ、様々な要素技術を使い分けてきたことが特徴です。この中でもOSSベースのSONiCを活用したインフラにより、スーパーコンピューターの国際性能ランキング「TOP500」の2025年6月のランキングにおいて、世界49位を飾ったのはご存じの方も多くいらっしゃると思います。(関連記事:AIスパコン「さくらONE」で挑むLLM・HPCベンチマーク (3) 「さくらONE」で挑戦するTOP500)
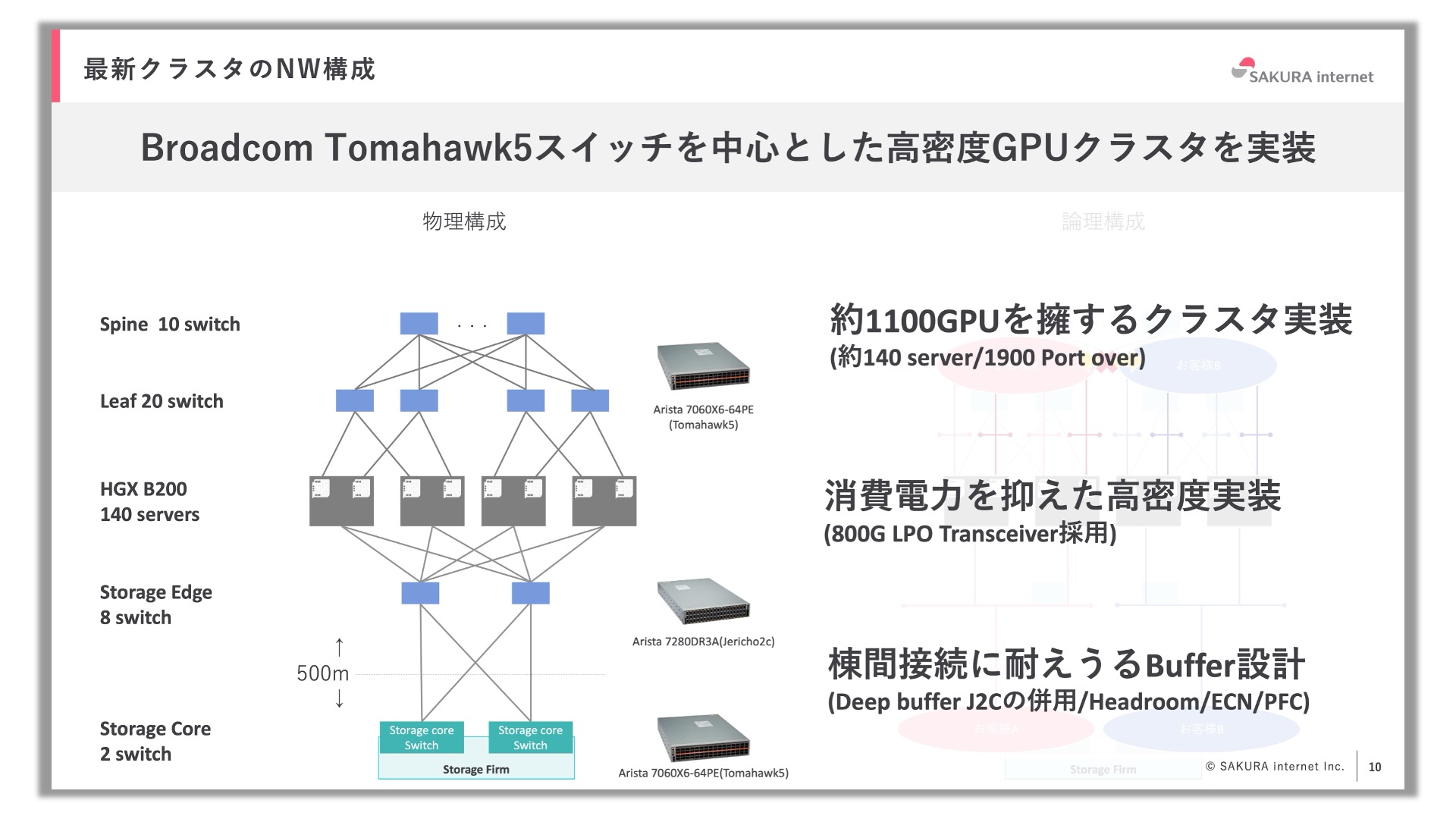
そして、上の図が最新のGPUクラスタです。このクラスタは約140台のサーバで構成されており、サーバ1台あたり8個のGPUを搭載しているので、約1100個のGPUを収容しています。
この最新クラスタを立ち上げるに至るまで、ネットワークアーキテクチャにおけるClos Topologyの試行、ネットワークOSにおけるホワイトボックススイッチとSONiCの採用という二軸で挑戦し、現在も使い分けて運用をしています。この後はこれらの詳細について解説します。
Clos Topologyの試行
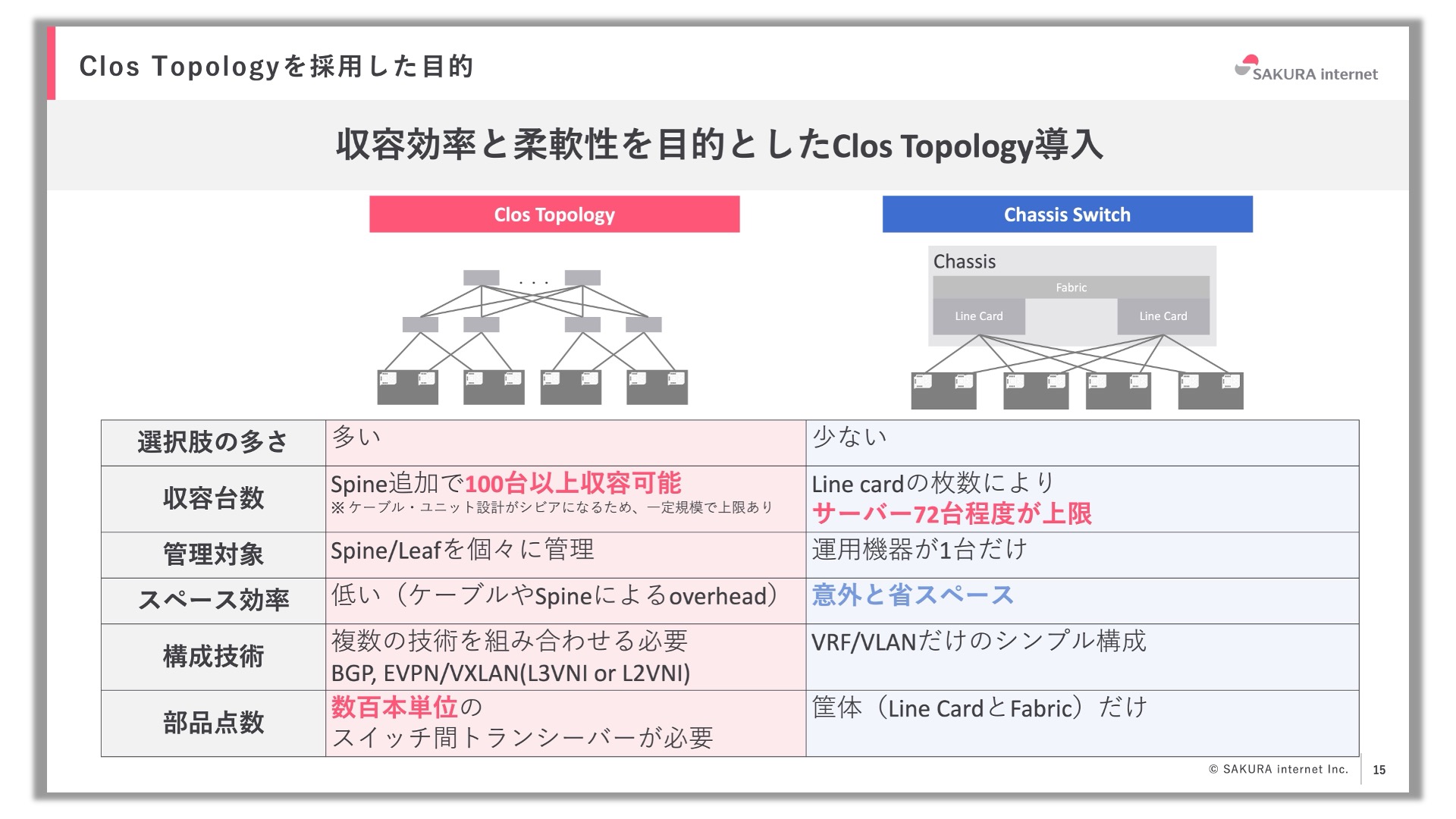
従来、さくらインターネットでは、シャーシと呼ばれるLineCard搭載可能なキャリアグレードスイッチを用いる構成が主流でした。1台の巨大なスイッチに全てのサーバーを収容するため、設計をシンプルにできること、Line Cardを搭載するだけでポート追加が可能などのメリットがあります。半面、ネックになってくるのが、筐体に差せるLine Cardの枚数は物理的な上限があることです。
昨今では各所のご協力もあり、最新のセンターでは、GPUサーバーを100台規模で収容できる設備が整っています。この収容規模はシャーシ1台に収容できるLine Cardひいてはポート数を超える規模になっています。ポート不足によりセンターの設備を余らせてしまう状況は防ぐ必要があります。そのため、今回ポート収容の上限を突破すべくClos Topologyを採用しました。
一般的なClos Topologyとの違い

通常はClos Topologyといえば、下記のような期待を持たれることが多いと思います。
- SpineやTierを増やすことによるスケーラビリティ
- N+1台構成など柔軟な構成
しかし、GPU基盤においてはこのような利点は必ずしも享受できるものではありませんでした。これは、GPUやスイッチが高価なため余剰を持たせることが難しい性質が挙げられます。ここでいう、余剰を用意するということは、ポート、ケーブル、電源、空調、全ての余剰を持たせるということです。これら全てを余剰させる体力はサービスの経済性にも影響します。
そして、シャーシ構成からClos Topologyに移行するという点で言えば、Spine/Leaf間のトランシーバーやケーブルを自前で用意する必要がある点も注意が必要です。増大するパーツの適切な選定、部材手配の管理など管理コストが大きくなることを念頭に置く必要があります。
それでも、用意されたセンターのリソースを適切に使い切ること、引いてはセンターの規模にインフラが追随するために必要な構成だったことから、Clos Topologyを採用することになりました。また、シャーシ型スイッチは限られたベンダーからの供給であることもあり、当社が重んじている技術的な「中立性」のためにも、新しい挑戦が必要なタイミングであると考えました。
ホワイトボックスへの挑戦
アーキテクチャの見直しと併せてスイッチのOSについても新たな挑戦を行いました。
従来のさくらONEでは、アリスタのスイッチに標準搭載されているArista EOSを使ってネットワークを運用してきました。これは、ハードウェアと一体になっているからこその安定性や、手厚いサポートの実績が、当社のように少人数でこの数のクラスタを運用するに際して、大きなメリットだからです。
しかし、私たちは異なる期待感から、ホワイトボックススイッチとSONiCの適用に挑戦しました。具体的には長年Linuxサーバーと共に歩んできた当社のノウハウを活用することで、迅速なデリバリーを実現したいという思いがありました。OSSが主導で開発しているSONiCを当社が活用することにより、この考えに即した、自由度の高い実装ができると考えました。
実際にホワイトボックススイッチを導入した結果、実装の自由度と迅速なデリバリーを実現できたと思います。その時の経験は別のイベントでもご紹介しているので併せて参考にしてください。
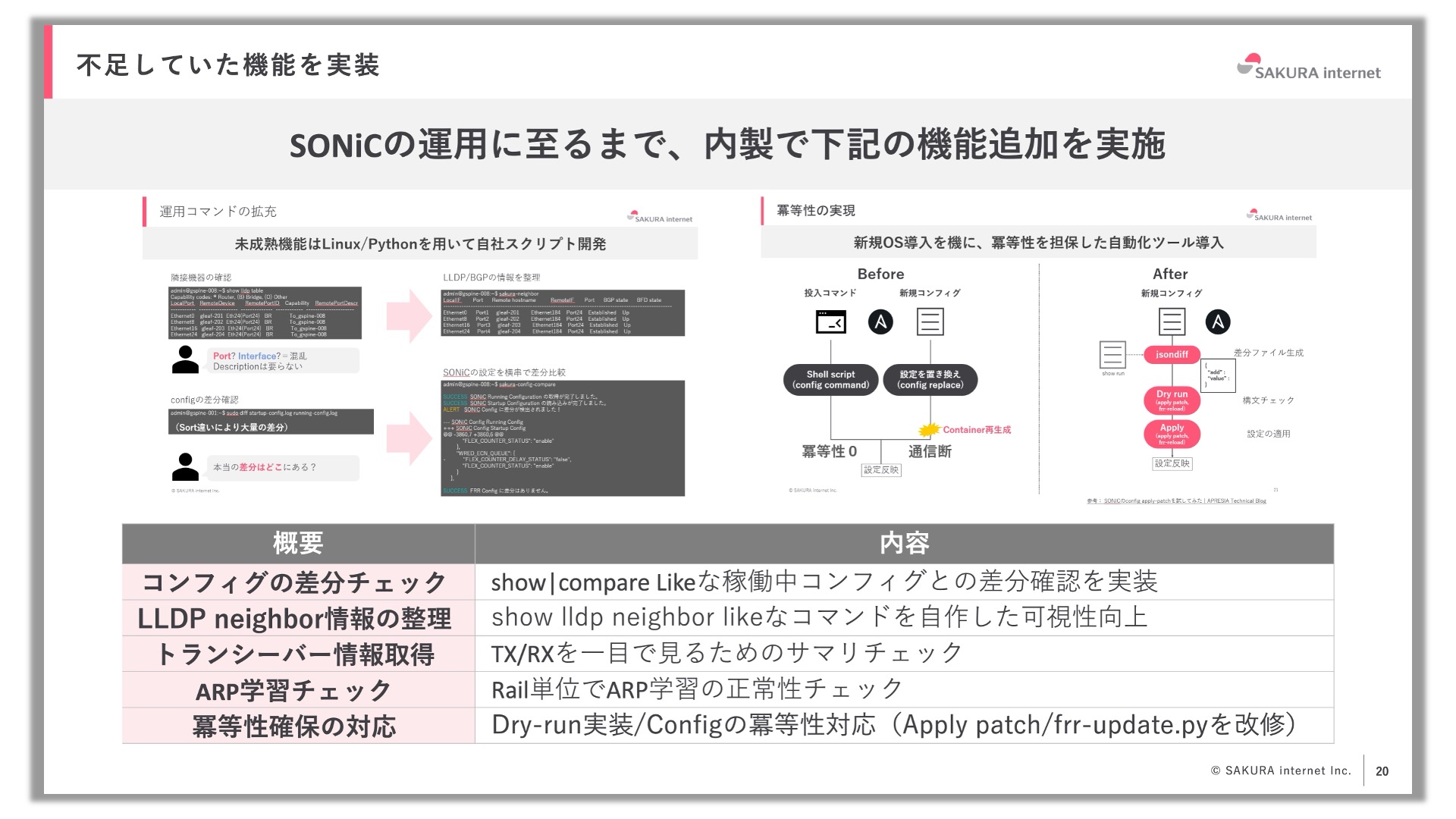
その反面、発展途上のコマンドを自分たちで補完したり、ソースコードレベルのより深いOS理解が求められるため、運用に至るまでの道のりは簡単なものではありませんでした。具体的にはコンフィグの差分チェック、LLDP neighbor情報の整理、トランシーバー情報の取得などの機能を、自分たちにとって使いやすい形で実装しました。幸いなことに当社にはOSSを活用してコードを書けるエンジニアがそろっていたので、このような改善に取り組めたと感じています。
反面、興味深かった事象としては、SONiCでソースコードレベルの理解に努めた結果、従来のArista製品を自動化するライブラリがOSSで公開されていることに目が向くようになったことが挙げられます。この教訓をふまえて、OS内部の理解はSONiCの運用に留まらず、必要なスキルセットであるということを強く感じています。
また、ネットワークOSの選択は単にスイッチやネットワークの実装だけに影響するわけではなく、運用や監視を始めとした、周辺のシステムにも影響することを考慮して、選択する必要があります。Arista EOSを使っているときはArista純正のツールを採用しており、SONiCを使ったネットワークは監視基盤も内製をしています。これは、そのネットワークOSに対して最も適切な監視基盤を検討した結果、これが最も効果的であると判断をしたためですが、監視精度向上など改善の余地も残されているため、今後改善も検討したいと考えています。
自動化への取り組み
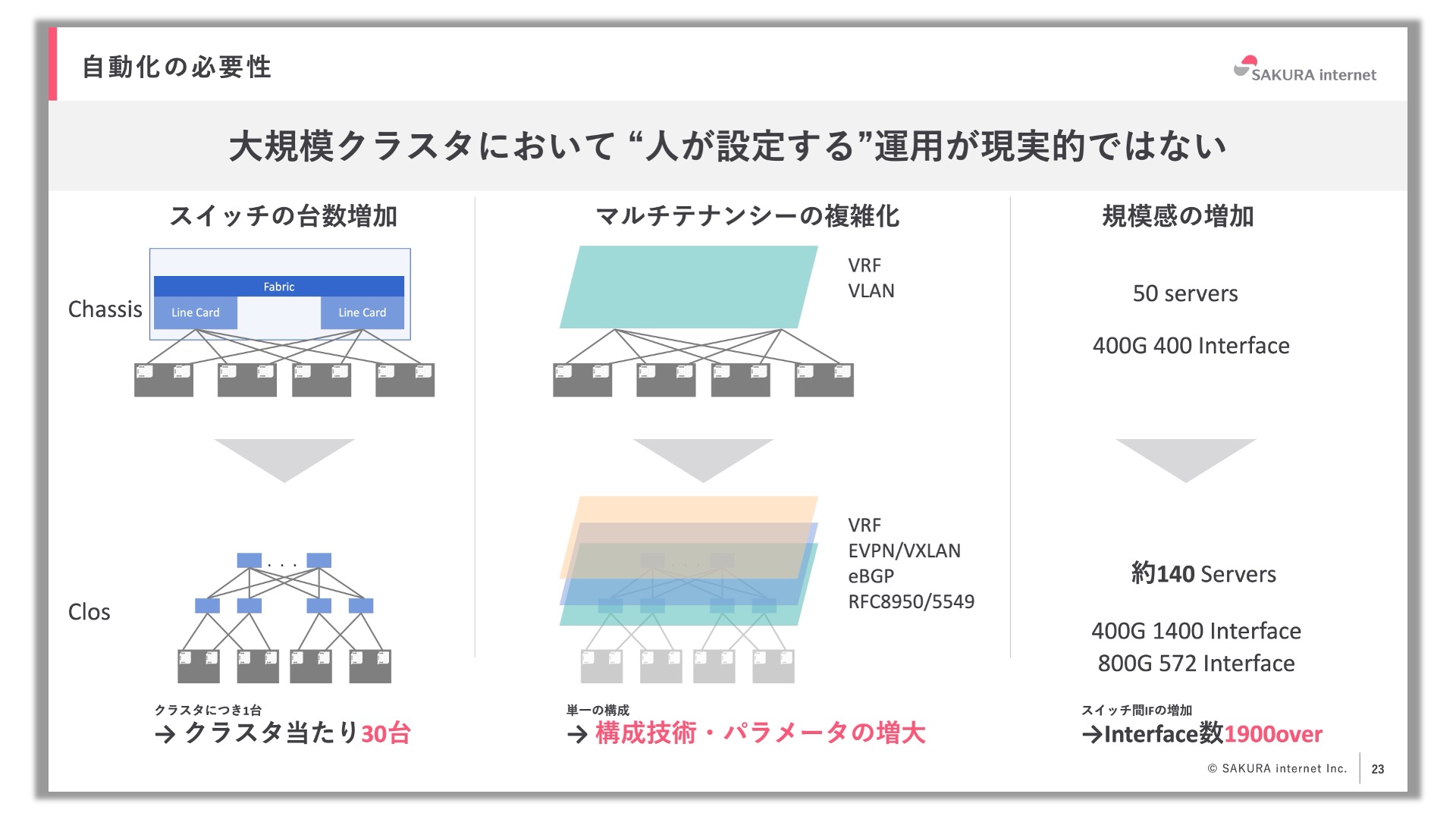
大規模クラスタの構築において、自動化の仕組みは欠かせないものです。さくらONEの構築においても、シャーシ型スイッチを使用しているときは1台のスイッチで済んでいたものがClos Topologyを採用することでスイッチが30台になり、インターフェース数も400から1900超に増えました。そして、その構成技術も非常に複雑化しています。結果として、設定項目やパラメータの数が増大しています。このような規模になると人力での設定は現実的ではないため、自動化が必須になってきます。自動化の仕組み作りとして実際に取り組んだことからいくつか紹介します。
Ansibleを用いた設定の自動化
まずはAnsibleを用いた設定の自動化です。情報源となるのはスイッチとサーバのパラメータです。スイッチのパラメータとしてはモデルやホスト名、OSのバージョンなどがあり、サーバの方はインベントリ情報(NICやどのテナントに入るかなど)があります。これらに加えてBGPの情報も考慮し、各スイッチのConfigを自動的に生成します。Configの全長は約4万行にもなります。
GitHubによる構成管理とテストの自動化
それから、生成したConfigが正しいかどうかのテストも重要です。最新のクラスタ構築においては、設定を変更するたびに自動的にテストする仕組みを導入しました。設定変更を行いたい人がプルリクエストを送ると、GitHub Actionsとcontainerlabの連携により仮想的な環境が作られ、更新されたConfigによるテストが実行されます。テスト結果が問題なければその環境を破壊してOKという通知を返します。このような仕組みを作ったことで5分程度でテストが行えるようになり、また何度でもテストを実行できるようになりました。
このような仕組みを構築したことにより、今回のクラスタ構築においては、最初のOSインストール開始から全体の正常確認が終わるまで、約2週間程度でセットアップを済ませることができました。
まとめ
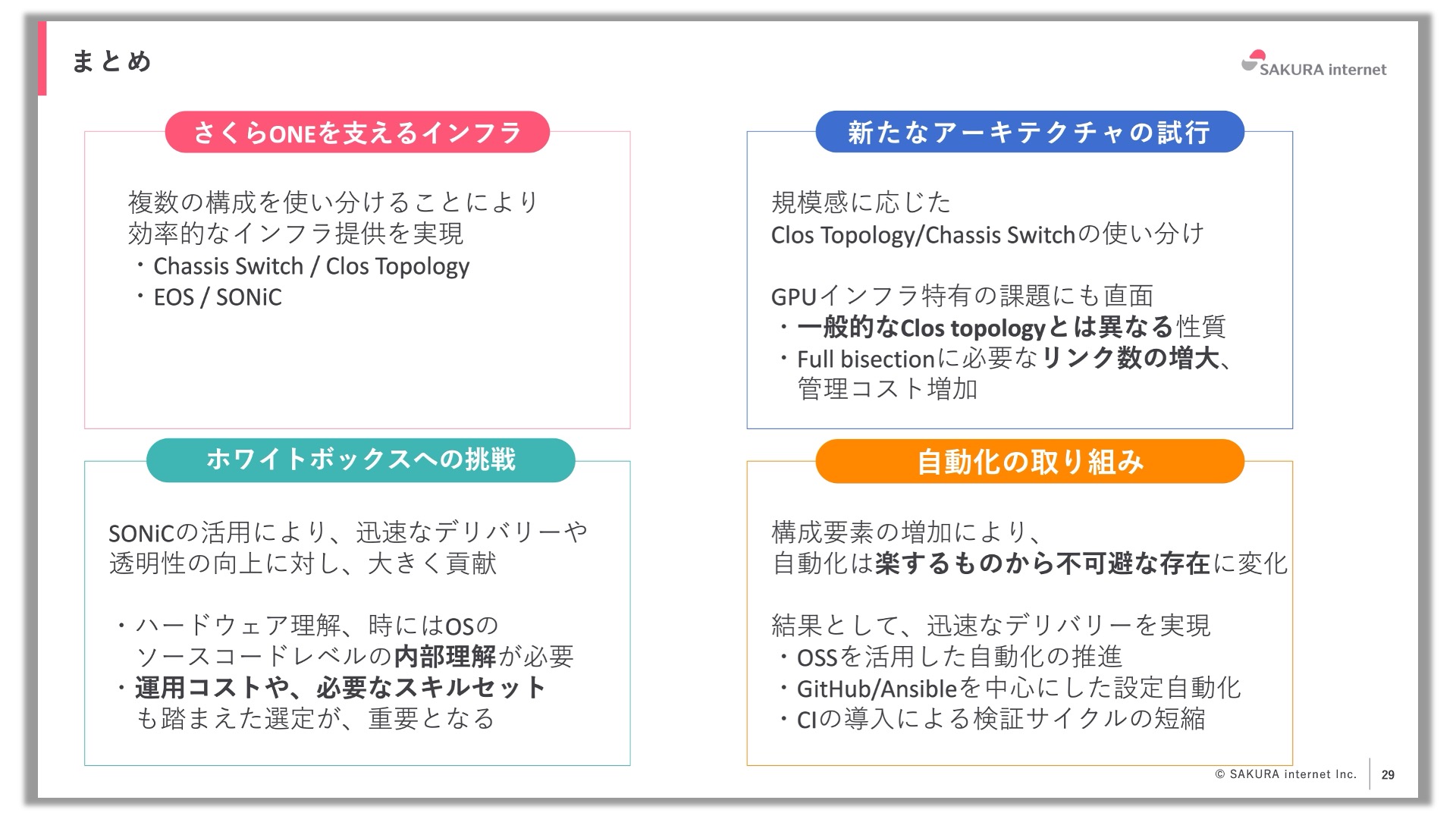
発表のまとめとして、さくらONEでは複数の構成を使い分けることで効率的なインフラ提供を実現していること、Clos Topologyなど新たなアーキテクチャも積極的に試行しているがGPUインフラや大規模インフラならではの課題にも直面していること、ホワイトボックスやSONiCの導入にも挑戦し大きな成果を得たが、コスト削減になるかどうかは自社の開発コストやエンジニアの技量にもよるので適切な判断が必要なこと、インフラの規模が大きくなったことで設定の自動化は不可避の存在になったこと、などを挙げました。
質疑応答

JANOGは単なる発表の場ではなく、参加者と議論することが大きな目的です。このセッションでも多くの参加者から質問や意見をいただきました。その中からいくつかを紹介します。
質問者: マルチテナントで運用するときに、Closとシャーシで違いはありますか?
黒澤: トポロジーによる有意な差は確認されていない認識です。ただしそれとは別に、ハードウェア特性による違いがあると感じています。今後継続運用して適切なパラメータを検討していく必要があると考えています。
質問者: ネットワークの物理構成図を見ると、ストレージネットワークの片側がJerichoでもう片方がTomahawk5になっているのですが、チップを合わせなかった理由はありますか?
黒澤: ストレージのコアスイッチ(Tomahawk5)は他のクラスタと共用のためポート数が必要なこと、またバッファに関してはエッジの方で吸収するという考え方で設計しているためチップの差分が生じています。コアスイッチの方もHeadroomバッファの拡張などの対策をすることで、経済性との両立を図っています。
質問者: SONiCはテレメトリーへの本格対応が必要という話がありましたが、これはgNMIで取れるパラメータが足りないという意味なのか、それともgNMIではなくOpenTelemetryで取得するような、アーキテクチャ的にも違うレベルが必要なのか、どちらですか? また、今後そうした必要な機能をアップストリームしていく予定はありますか?
黒澤: イメージとしてはgNMIを考えています。導入した時点ではgNMIの機能すべてを確認できなかったことや、1秒未満の高精度な監視は内部のSDKレベルでの対応が必要で、現状はまだ対応できていません。この点は新しいOSで対応できればと考えています。アップストリームに関しては、ソースコードレベルでの公開は検討の余地ありですが、成果を公開することで業界に貢献できればと思います。
質問者: GitHub Actionsとcontainerlabを活用してCIを行っているとのことですが、実際にはどのレベルまでチェックしているのですか? また実機もCIに使っているのかも知りたいです。
黒澤: 確認のレベルに関しては、Configの適用とBGPの成立など基本的な項目を見る形になっています。L1レベルの話やハードウェアに依存する部分はコンテナでは確認できないので、ここでテストに通ったものを実際の予備機に適用して確認し、それから本番環境に展開するデリバリーを行っています。本来はそこも自動化したいのですが、デリバリーまでの自動化は解決すべき課題が難しく、現状は手が付けられていません。今後取り組みたいポイントです。ちなみにSONiCでもCIを実現しており、こちらはコンテナは使わず予備機を全面的に活用する構成をとっています。
質問者: ユーザーが投げるジョブは、最近はAIや大規模言語モデル(LLM)などに関するものが多いかと思います。それに関して、どの程度の規模のモデルを扱うか、またそれに応じてクラスタをどのような構成にするか、そういったことはどれぐらい考えて構築しましたか?
黒澤: 利用サイドの観測はまだ十分ではなく、これから強化すべき点と考えています。現状ではどういう用途の利用が来るかわからないという前提で設計しています。今後は学習や推論などの用途に適した構成も作っていけたらと考えています。
質問者: Ansibleによる設定管理を検討中とのことですが、OpenConfigを利用した自動化の取り組みへのモチベーションがあるかをお聞かせください。
黒澤: その点については現状まだ検討段階で、具体的な自動化は今後の課題と考えています。
質問者: テストの自動化を1000項目実装されたとのことですが、ANTAのGitHubを見るといくつかのシナリオが実装されています。これらを利用したのか、それとも全項目を内製で開発したのかを教えてください。
黒澤: 内製の割合はすぐに出せませんが、GitHubで公開されているモジュールを活用しつつ、一部を我々で内製しました。具体的には結線チェックの部分などを内製しています。1900本の線をたどるのは大変ですが、LLDPとANTAを元にした拡張により、我々の検査基準に達するテストケースになるように自分たちで追加モジュールを書いています。
質問者: AristaのEOSでも柔軟な自動化は実現できると思うのですが、そのような中でもSONiCを選んだ理由を教えてください。
黒澤: 我々はLinuxを扱うのが得意なので、Linuxベースで管理できることに非常に魅力を感じました。その上で導入効果も期待できるという見込みが立ったのでSONiCを選択しました。また、中立的な技術を重視し、複数ベンダーを選択可能な状態にしておくことも重要と考えています。その点もSONiCを採用した理由の一つです。
質問者: SONiCを動かしているハードウェアは何ですか?
黒澤: SONiCに関してはEdgecore Networksのハードウェアを使って動かしています。
おわりに
私たちは、さくらONEのサービス提供を通じて、「アーキテクチャ」と「OS」の二軸の元、選択を重ねてきました。その過程における、複数の技術を適材適所で使い分け、運用まで見据えた自動化が、価値あるサービスを届けるために必要なことであったと実感しています。ここで共有した私たちの試行錯誤が、少しでも、皆さま自身の選択の材料や考えるきっかけになりましたら幸いです。