さくらのVPS×Difyでカンタン構築!「現場で回せる」AI契約書レビューシステム ―スタートアップスクリプトで始める専門業務AX―

目次
1. はじめに
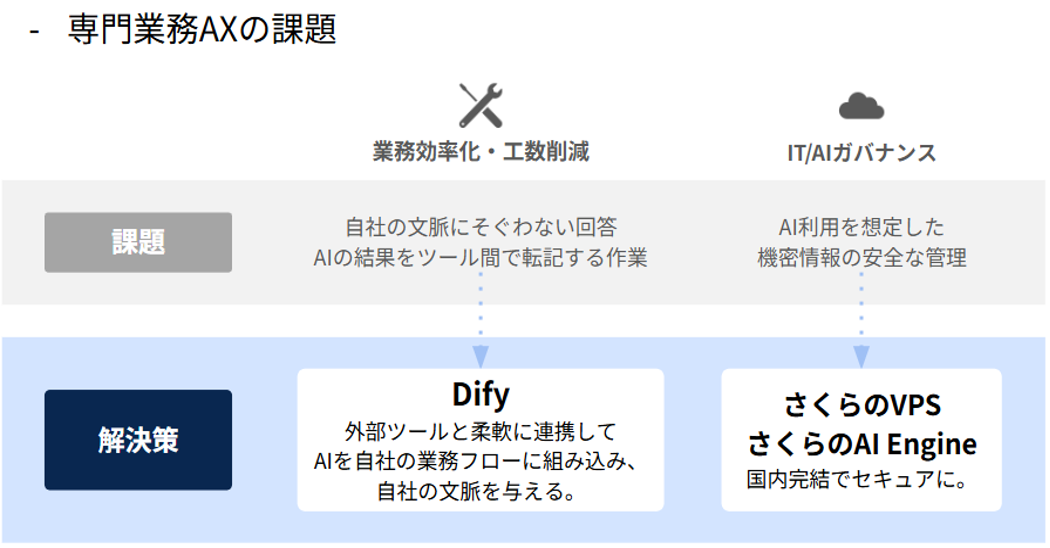
ChatGPTやClaudeのような汎用的なLLMサービスを業務に取り入れる動きが広がる一方、専門業務の現場で本格活用しようとすると、二つの課題にぶつかります。
一つは「生成AIだけでは業務を完遂できず、限定的な工数削減にとどまる」という課題です。例えば、AIチャットに契約書を貼り付けてレビューを指示すると、それらしい回答がチャットで返ってきますが、実務担当者が本当に欲しいのは「自社の文脈・基準・契約背景に沿ったレビュー」と「Wordファイル上で修正履歴付提案・コメント反映まで完遂してくれる存在」です。
もう一つは、IT/AIガバナンスの課題です。再度契約書の例でいくと、契約書には取引条件、価格、知財、係争中の論点といった機微情報が詰まっており、社外のSaaS型AIツールに投入することは依然として抵抗が強いのが実情です。
この二つの課題を解決する現実的な構成が、ノーコードAIプラットフォーム「Dify」をさくらのVPSにセルフホストし、国内提供の「さくらのAI Engine」や外部LLM APIを利用する構成です。本記事では「契約書レビュー」という、ほぼすべての企業で発生する専門業務を題材に、その設計・運用の考え方を中心に解説していきます。
なお、Dify+さくらのAI Engineの基本構築方法や、RAGの基礎的な組み立てについては「「Dify + さくらのAI Engine」を便利に活用!RAGを組み合わせたナレッジ検索環境の作り方」で詳しく解説されていますので、そちらをご参照ください。また本記事ではWord上での編集体験部分にGVA TECHが提供するWordアドインを利用している点を、あらかじめお断りしておきます。
2. システム全体像
今回紹介するシステムは、①Wordアドインを入口に、②さくらのVPS上のDifyワークフローによって生成AIがレビューを実行し、③結果をWordアドインへ返してWordファイルへの反映まで行う、というものです。
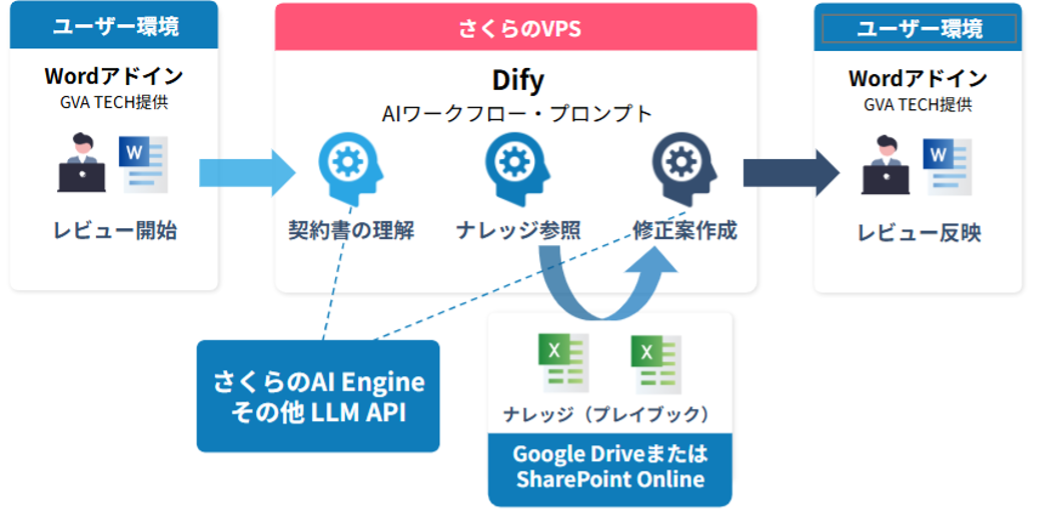
ユーザーがWord上の契約書からアドインのレビュー実行ボタンを押すと、契約書データがさくらのVPS上のDifyに送られます。その後、Difyのオーケストレートで、大きく二段階のAI処理が行われます。
- 契約書を分析し、契約書の種類や状態を把握して、次の処理のために成型した情報を渡す。下準備にあたる処理。
- 受け取った情報をもとに、適切なナレッジを参照して契約書のリスク判定を実行する。このリスク判定ロジックとして、弁護士や企業法務が実際に契約書レビューする際の思考プロセスをプロンプト化することが重要になる。
3. 適材適所でLLMを使い分ける
DifyをさくらのVPSのスタートアップスクリプトで立ち上げると、さくらのAI Engineは「OpenAI-API-compatible」プロバイダとしてすでに接続済みとなっています。本記事ではこれに加え、より優れた推論能力・言語能力、コンテキストサイズを有するClaudeを利用するためにAnthropicプロバイダも追加します。契約書やそのナレッジであるプレイブック、それらを再現性高く指示通りレビューするための長大なプロンプトをすべて漏れなくコンテキストとして保持し処理するためには、まだクラウドLLMが必要な印象です。
用途に応じた構成
一口に「AI契約書レビューシステム」と言っても、用途・目的によって設計は大きく変わります。
例えば、自社ひな型を相手方に提示し、特定の空欄だけ記入してもらう運用であれば、チェック観点は限定的で、必要なLLMスペックも高くありません。

このようなLLM処理範囲・判断要素を限定的にできるケースでは、さくらのAI Engineのgpt-oss-120bだけで構築して、トークン費用を抑えつつ、十分な品質も担保できることがあります。
相手方が指定の空欄箇所以外の本文に修正をかけてきた場合は、イレギュラー対応として人の判断を要する箇所としてもよいでしょう。このとき、契約書対応フローとして「想定外修正の検知 → 自動で法務へエスカレーション」という分岐を組み込んでおくことで、ビジネスサイドも自信をもって「ここまでは自己解決、ここからは法務へ依頼」と判断できるようになります。
このように、専門業務を効率化するLLMシステムは、エスカレーション設計とワンセットで考えると、トークン費の節約だけでなく、業務フローを含めた現場での運用がスムーズになります。
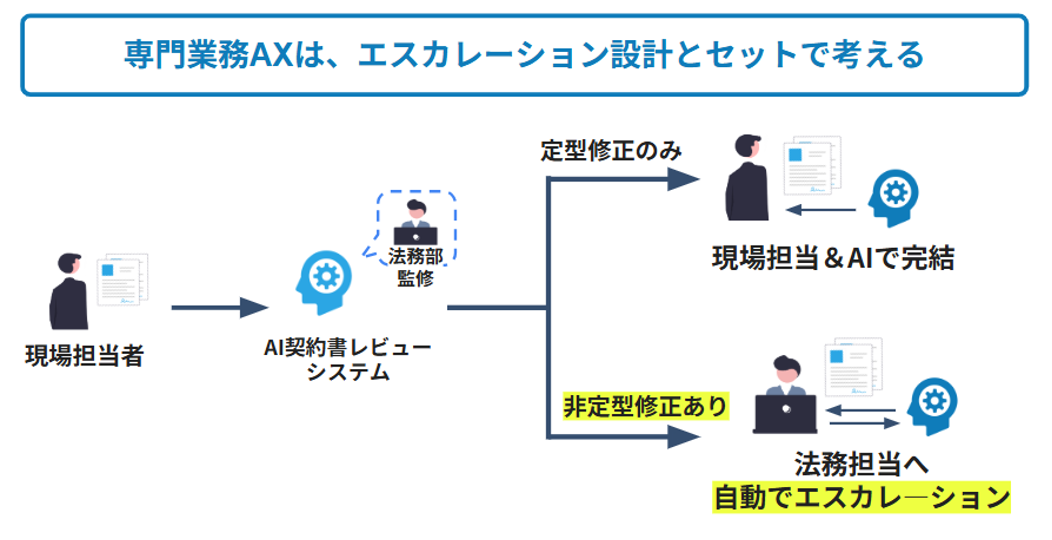
ワークフロー内でのLLM使い分け
一方、相手方から提示されたひな型に対しては、全文レビューする必要があります。判定要素・出力量が大きいケースでは、より緻密で長大なプロンプトやオーケストレートの設計、参照ナレッジの整備が求められます。この場合、gpt-oss-120bでは性能不足のためClaudeなどのクラウドモデルを利用します。ここではClaude Sonnet 4.0を利用します。
ただし、オーケストレート内のすべての処理にClaude sonnet 4.0を利用する必要はありません。今回のオーケストレートでは、第2章で述べた二段階のAI処理それぞれに、異なるモデルを割り当てています。

一つ目の「下準備」ノード(契約書を分析して契約類型と既存の修正状態を把握する処理)は、「契約書の分類」に近いタスクで、入出力量も限定的なため、さくらのAI Engineのgpt-oss-120bで十分対応できます。二つ目の「本処理」ノード(契約書本文を全条項にわたって分析し、修正判断・修正案・コメント案・論点解説を生成する処理)は、アプリ全体のトークン入出力量の大半を占め、ここの精度が成果物の質を決定づけるため、Claude Sonnet 4.0で動作させます。
Wordアドインによる「業務完遂」
最終的に、DifyでのLLM処理結果はWordアドインへ返されます。アドインの機能により、レビュー結果は変更履歴とコメントとしてWord文書に直接書き込まれます。
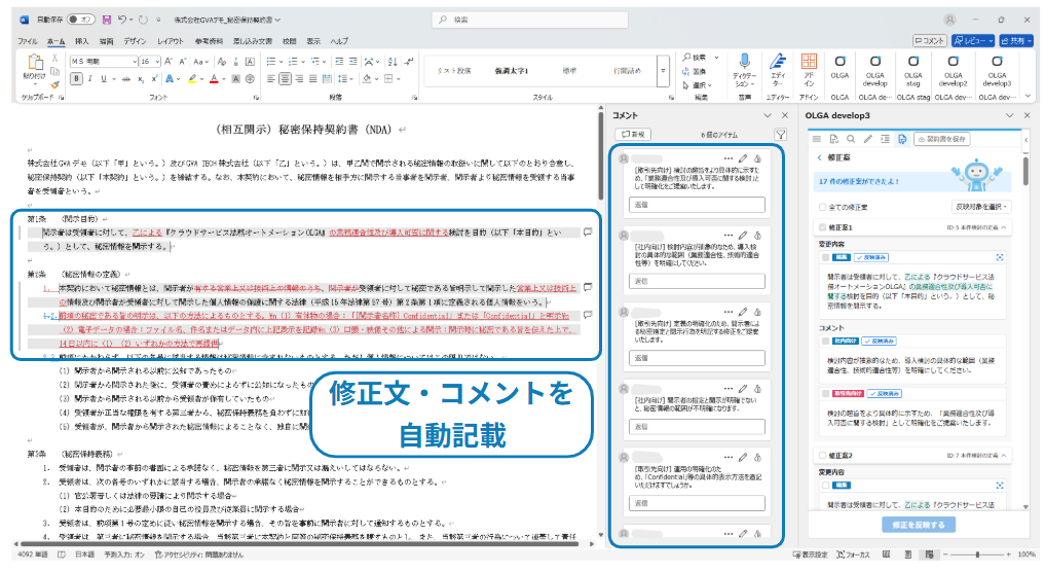
つまり、ユーザーは使い慣れたWord上で処理が完結するため、ツール間のコピー&ペーストや形式変換に煩わされません。「生成AIだけでは業務を完遂できない」という第1章で挙げた課題を越えるための、地味ですが決定的な要素です。
4. 自社ナレッジで精度を上げる
生成AIを法務実務で活用する上で最も重要なのは、AIに参照させる「ナレッジベース」だと言っても過言ではありません。どれほど高性能なLLMを用い、プロンプトを磨き込んだところで、自社の法務基準やサービス情報を何も知らなければ、AIには一般論によるレビューしかできません。
法務での生成AI活用における「ナレッジ」は大きく以下の3つが挙げられます。
- ひな型・過去契約書
- Q&Aや過去の案件交渉ログ
- プレイブック
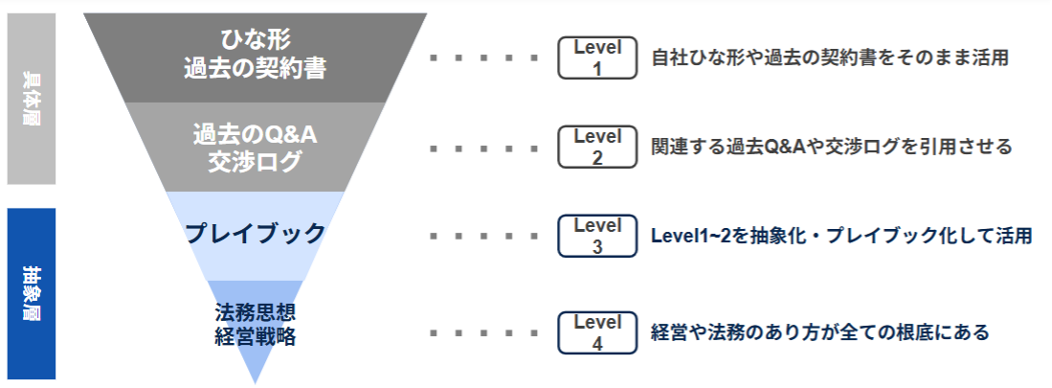
イメージとしては、具体性・個別性の高い、生の情報としてのナレッジである「ひな型・過去契約書」や「過去のQ&A」などがあり、これらを一般化・体系化して、より広く活用できるようにしたものとして「プレイブック」があります。プレイブックとは、契約類型ごとに各条項の判断基準や修正方針を整理したものです。粒度の異なるこれら三層を使い分けてAIに参照させることで、実務運用に耐えるシステムが組み上がっていきます。
DifyにはRAGを簡単に構築できる「ナレッジ」機能があり、過去契約書や社内ひな型を取り込んでLLMノードから参照させることができます。
参照:「Dify + さくらのAI Engine」を便利に活用!RAGを組み合わせたナレッジ検索環境の作り方
ただし、法務業務においては、Difyのナレッジ機能によるRAGは「使える領域」と「使えない領域」がはっきり分かれます。RAGは過去の一対一対応する質問回答や、単一条項・単一論点について検索・参照するといった用途には有用です。一方で、契約書全体を理解した上で「自社基準」という複雑なコンテキストに沿って全条項をレビューし、修正案・コメント案までを生成するタスクには、構造的に向いていません。理由は大きく三点あります。
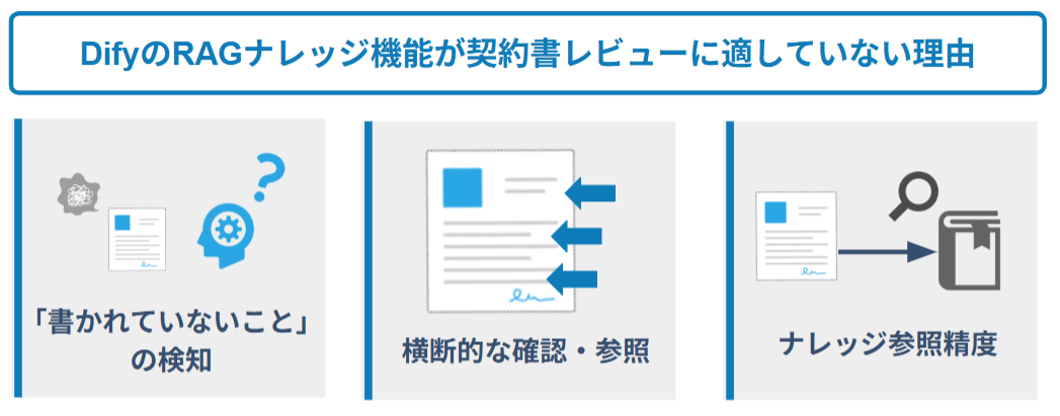
第一に、「書かれていないこと」を検知できません。今回の契約書レビューにおいてRAGを構築する場合、契約書本文をクエリとしてナレッジ側を検索することになり、契約書側に該当語句がない項目はそもそも検索にヒットせず、レビュー対象から脱落してしまいます。例えば「残存義務条項の有無」「法令遵守条項の有無」といった不存在の指摘を要するチェック観点をナレッジに格納していても、契約書本文に対応ワードがなければ、AIはその知識を引き出すきっかけを持てません。
第二に、項目間の横断整合をチェックできません。RAGはチャンク単位でナレッジを取得することが基本のため、「秘密情報の定義」と「目的外使用の限定範囲」、「残存義務」と「秘密保持期間」のように、複数項目を突き合わせて初めて成立するレビュー観点が構造的に扱いづらくなります。
第三に、検索ミスマッチが起こります。ベクトル類似度は「意味的に近いもの」を引き寄せる仕組みであって、「適用すべきルール」を特定する仕組みではありません。似た言い回しの別ルールが優先的にヒットすれば、誤った基準でレビューが進んでしまいます。
RAGは、ナレッジ総量がコンテキストウィンドウに収まりきらない場合に特に有効な手段ではあるものの、収まる規模のナレッジに対してRAGを介在させると、不要な情報損失を招くことがあります。加えて運用面でも、ナレッジ更新のたびに再アップロード・再インデックスが必要となり、現場での更新作業が迅速に行えない課題もあります。
5. 本格運用への発展:プレイブック × Googleスプレッドシートで「現場が回せる」運用へ
では、どのようなナレッジ参照機構を組めばよいのでしょうか。
答えはシンプルで、ナレッジ全文をコンテキストとしてLLMに直接渡す方法です。Claude Sonnet 4.0をはじめとするクラウドLLMのコンテキストウィンドウは飛躍的に拡大しており、契約書全文と構造化された自社プレイブックを丸ごと載せ、緻密なプロンプトに従って読解・レビューを実行することが十分可能です。
今回の構成では、プレイブックを複数のGoogleスプレッドシート上で管理し、Difyの外部ナレッジ取得ノード(Google Drive/スプレッドシート連携)を介して取得する設計としました。
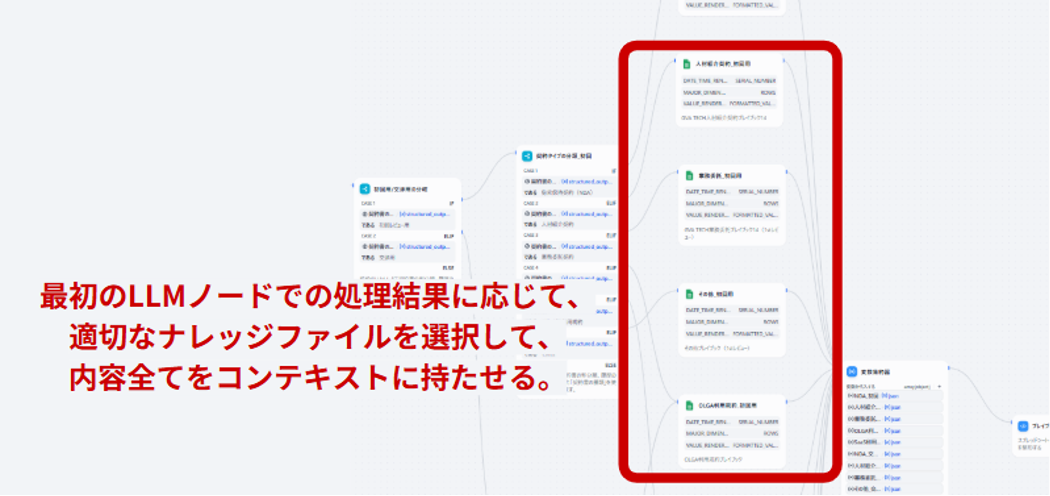
ワークフローの流れは、まず下準備ノードで契約類型を判定し、その結果に応じて参照すべきスプレッドシート(例えば「業務委託契約用プレイブック」「秘密保持契約用プレイブック」など)を選択、該当シートを全文取得して本処理ノードのコンテキストに載せる、というものです。
この設計の大きな利点は、ナレッジとして参照されるファイルをいつでも直感的に確認・更新できる状態に置けることです。プレイブックは一度作って終わりではありません。実運用の中で、要交渉基準を緩めて締結速度を上げたい、過去案件で生じた新パターンを反映したい、といった改善要望が生まれます。更新のしやすさは、ナレッジ運用が現場に定着するかどうかを分ける決定的な要素です。
その点、Googleスプレッドシート(あるいはExcel)は法務部やビジネスサイドにとって、最も馴染みのある業務ツールであり、学習コストがゼロです。シートの該当行を直接書き換えるだけで、次のレビュー実行時には変更が反映されるよう構築できます。更新のたびにRAG用ファイルをDifyのナレッジベースへ再アップロード・再インデックス化する運用と比較して、時間的・心理的コストが低くなります。
このように、Difyのモデルプロバイダ切り替え、外部ツール連携、Wordアドインによる完遂体験を組み合わせることで、「AIに何をどこまで任せ、どこから人が引き取るか」「ナレッジを誰がどう育てていくか」という、専門業務AXの本質的な設計課題に正面から応えられます。
6. まとめ:VPSから始める、専門業務のAX
本記事では、さくらのVPS上にDifyをセルフホストし、さくらのAI EngineとClaudeを適材適所で組み合わせ、Googleスプレッドシートで管理する自社プレイブックを参照しながら、契約書レビューを実務レベルでこなすワークフローの構築を見てきました。
今回の構築のポイントは以下三つです。
- 軽量タスクは国内推論基盤のさくらのAI Engineに任せ、本処理はクラウドLLMで行う使い分けがコストと精度の最適点を生むこと。
- RAGはあくまで「コンテキストに収まらない規模のナレッジ」への解であり、収まる規模であればナレッジ全文を直接渡す方が法務実務には適していること。
- ナレッジ更新を現場が自走できる仕組みとして設計すること。
今回の構築は、契約書レビュー専用の話ではなく、稟議書チェック、規程改定レビュー、技術文書のレギュレーション適合性チェックなど、専門知識と自社固有基準が交差するあらゆる業務に応用できます。
さくらのVPS×Difyを基盤に据えれば、国内完結・自社ガバナンス下という安心感の上で、業務ごとに最適化したAIワークフローを段階的に積み上げていけるはずです。
GVA TECHは、本記事で紹介したAI契約書レビューシステムの構築を含む、法務領域のAI活用コンサルティングサービスを提供しています。本記事について、より詳細に情報収集されたい場合や、法務業務における生成AIの活用に悩まれた場合は、ご相談ください。
- ご相談のお打ち合わせはこちらから予約いただけます。
- メール lts.biz@gvatech.co.jp でもお気軽にお問い合わせください。