障害ヲ抱擁セヨ──大規模クラウドサービスをマイクロサービスアーキテクチャで作るNetflixが実践する障害注入テスト(FIT)とは何か

「障害ヲ抱擁セヨ("Embracing Failure")」という言葉を聞いて、読者の皆さんはどのように感じるでしょうか? 深夜や休日に障害対応をしなければならなかった思い出が蘇る方もいるかもしれません。この言葉からメッセージを想像して「なるほど」と思う方もいるかもしれません。
「障害ヲ抱擁セヨ」とは、動画サービス大手のNetflixが「障害注入テスト(FIT :Failure Injection Testing)」の概念を説明する講演のタイトルとして使った言葉です。
よく知られているように、Netflixの配信サービスはクラウド(AWS)上に載っています。同社はクラウド上の巨大システムを健全に動かすために、わざと障害を起こし続けるテスト手法である障害注入テスト(FIT)の手法を採用しています。このテストに使うツールの総称をSimian Army(猿の軍団)と呼んでいます。Simian Armyの最初のツール、そして最も有名なツールが、クラウドのインスタンスを「業務時間内に」ランダムにシャットダウンするChaos Monkeyです。
最初のツールChaos Monkeyが注目される
NetflixがChaos Monkeyの名前を初めて対外的に明らかにしたのは、InfoQの記事によれば2010年12月16日付けの次の記事です。この記事では
「障害を避ける最もよい方法は、常に障害を起こすことである」
という言葉とともに、Chaos Monkeyを紹介しています。
障害は設定した確率に応じてランダムに発生しますが、深夜や休日ではなくビジネスアワーに発生させます。「午前2時に障害が起きるより、午後2時に起こる方がずっとましだろう?」というわけです。
ランダムにインスタンスをシャットダウンさせたとき、何が起きるでしょうか? もしシステムが、障害発生に対応可能なように正しく設計、実装されていれば、他のインスタンスが役割を果たし、結果としてサービス全体は正しく動き続けます。しかし見落とされている問題が顕在化するかもしれません。そうした場合は(深夜や休日ではなく)勤務時間内に問題を解決しよう、というわけです。
このChaos Monkeyは、2012年にオープンソースソフトウェアとして公開されています。いまではChaos Monkeyは有名なツールです。
Chaos Monkey Released Into The Wild
サービス障害を起こさないために、障害を起こし続ける。逆転の発想のツールChaos Monkeyを、Netflixがオープンソースで公開
各種の障害発生ツールを用意、大規模障害への対策も
Netflixは、Chaos Monkeyを筆頭とするFITのためのツール群Simian Armyをオープンソースソフトウェアとして公開しています。Chaos Monkeyは前述したようにシステムをランダムに停止させるツールです。Janitor Monkeyは、未使用のリソースを探してクリーンアップします。Conformity Monkeyは「ベストプラクティスから外れているインスタンス」(例えばオートスケールのグループに所属しないインスタンス)を検出してシャットダウンします。

これ以外にも興味深いツールがあります。Latency Monkeyは通信路でランダムな遅延を発生させます。Doctor MonkeyはCPU負荷などのヘルスサインを監視し、異常を検出するとサービスからインスタンスを切り離して、問題を調べる時間を与えた後にシャットダウンします。Security Monkeyは不適切なセキュリティ設定などを検出すると、そのインスタンスを終了させます。10-18 Monkeyは遠隔地や異なる言語/文字コードを使うインスタンスの設定や実行時障害を検出します(10-18の名称はL10n、i18nから)。
大規模障害を人為的に発生させるという恐ろしげなツールもあります。Chaos GorillaはAWSのアベイラビリティゾーン全体の障害をシミュレートします。Chaos Kongはさらに大規模なリージョン単位の障害をシミュレートするツールです。
障害注入テストの考え方を発表
こうしたツール群が公開された後になって、Netflixは2014年10月23日付けのBlog記事で障害注入テスト(FIT)の概念を提唱しています。
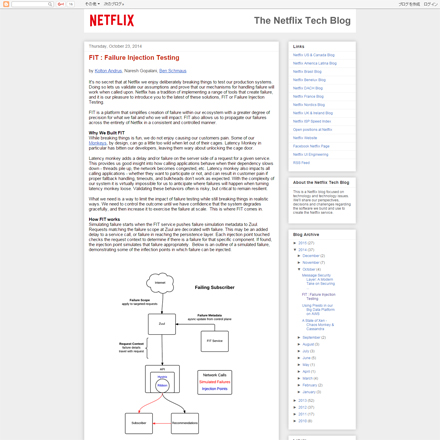
そして2014年11月に開催されたカンファレンス「AWS re:Invent 2014」の講演"Embracing Failure: Fault-Injection and Service Reliability"(スライド)では、さきほど紹介した「障害ヲ抱擁セヨ」というメッセージを前面に出しています。締めくくりの言葉は「猿を恐れるな!(Don't Fear The Monkeys)」です。
「障害ヲ抱擁セヨ」という言葉は、皆さんお気づきのようにXP(eXtreme Programming)の「変化ヲ抱擁セヨ」(Embrace Change)をヒントにしていると考えられます。XPをはじめとするアジャイル開発手法が、システムへの要求が変化し続けることを前提に発展してきたように、巨大なクラウドサービスでは常にどこかで障害が発生し続けることを前提としてシステムを開発運用しよう、というわけです。
ツールによる障害がランダムに発生し、顕在化した問題を業務時間に解決する。このサイクルを繰り返していくことにより、障害を前提とした開発と運用が組織に定着する。このような形で障害に対する経験と対策を積み重ねていくことにより、より深刻な本物の障害──例えばクラウドサービスの大規模リブート、データセンター間の通信遅延、データセンター(アベイラビリティゾーン)単位の障害、リージョン(地域)単位の大規模障害の発生といった事態に対しても、すでに経験済みの問題として対処できるというわけです。
マイクロサービスアーキテクチャと障害注入テストを“合わせ技”で使う
障害注入テストが生まれてきた背景として、もう一つ触れておきたいことがあります。Netflixは以前のコラムで紹介したマイクロサービスアーキテクチャの大規模事例としても知られているのです。
複数のサービスプロセスが協調して動作するマイクロサービスアーキテクチャでは、サービス間の通信が遅延したり、遮断されたりする可能性があります。また、どれか一つのマイクロサービスが障害を起こす可能性があります。異なる言語/文字コードを処理しようとして想定外の事象が発生するかもしれません。
こうした問題を前にしてサービス全体の堅牢さを確保するには、個別の障害に対応できる冗長設計が必要です。つまり、マイクロサービスアーキテクチャでシステムをきちんと作って動かす上でも、Simian Armyのようなツール群は欠かせないと言えるでしょう。