つくってみよう!高火力コンピューティングでオリジナルAIサービス(2) ~Webサービス開発 編~

さくらインターネットの伊東道明です。
本記事は、「つくってみよう!高火力コンピューティングでオリジナルAIサービス」という連載の第2回です。
| 第1回 | 画像識別器をダウンロードして使用する |
|---|---|
| 第2回 | 画像識別器を使用したWebサービスを作成する |
| 第3回 | オリジナルの画像識別器を作成し,Webサービスに組み込む |
前回は、事前にディープラーニングを用いて学習されたモデルを使い、猫の画像を識別させるプログラムを作成しました。
今回は、ブラウザから好きな画像をアップロードして、AIによる画像の識別結果を返答させるWebサービスを作成します。
本記事のソースコードは、https://github.com/palloc/AI-WebService/tree/master/source2にまとまっています。
Webサービスの作成
今回は、Webサービス部分にPythonのWebフレームワークの一つである「Tornado」を使用します。
Tornadoとは
Tornadoは、PythonのWebフレームワークであり、軽量でスケーラブルなフレームワークです。
識別器を使う準備
本記事は、Ubuntu16.04、Python2.7.11を想定しています。CPU環境、GPU環境どちらでも実行できるように両方の手順を示すのでGPUはあってもなくても構いません。GPU環境を使いたいという方は、事前にこちらを参考にセットアップしてください。
ディレクトリ構成
今回は、Tornadoを使い、以下のようなディレクトリ構成でWebサービスを構築します。

自分の好きなディレクトリ内で以上のような構成で後に解説するソースコードをコピペなどして設置してください。
では、それぞれのファイルの中身を確認しながら、なんの役割をしているか解説していきます。
ファイル解説
images/
ユーザが識別したい画像をアップロードする際の画像の保存先です。jpg画像であればimages/image.jpgとして保存され、png画像であればimages/image.pngとして保存されます。
templates/index.html
<!DOCTYPE html>
<html>
<head>
<title>画像識別サービス</title>
<link rel="stylesheet" href={{ static_url("style.css") }}>
</head>
<body>
<header>
<h1>画像識別サービス</h1>
</header>
<div id="container">
<div id="contents">
<p>画像をアップロードして下さい</p>
<form action="recognize" method="post" enctype="multipart/form-data">
<input type="file" name="image" />
<input type="submit" value="upload" />
</form>
</div>
</div>
</body>
</html>
トップページのhtmlファイルです。
linkタグの中で、テンプレートの機能を使っています。これは、ざっくりいうとPythonのコードで使用している変数をhtmlに渡し、そのまま使用できる機能です。
詳細は、こちらをご覧ください。
templates/predictor.html
<!DOCTYPE html>
<html>
<head>
<title>画像識別サービス</title>
<link rel="stylesheet" href={{ static_url("style.css") }}>
</head>
<body>
<header>
<h1>画像識別サービス</h1>
</header>
<div id="container">
<div id="contents">
<h2>画像の識別結果</h2>
<p>あなたのアップロードした画像を識別した結果、以下のようになりました。</p>
<ul>
{% for prob in probs %}
<li>{{ prob }}</li>
{% end %}
</ul>
</div>
</div>
<footer>
<a href="/">トップページへ戻る</a>
</footer>
</body>
</html>
画像を識別した結果を表示するページになっています。こちらもテンプレートの機能を使っていて、画像識別プログラムから返された確率トップ5の配列をprobsで受け取り、for文でprobに一つずつ格納し、表示しています。
static/style.css
body {
font-family: 'Hiragino Kaku Gothic ProN';
width: 90%;
margin: 0 auto;
}
h1, h2, form {
text-align: center;
}
p {
width: 60%;
margin: 0 auto;
text-align: center;
}
ul {
width: 50%;
margin: 0 auto;
padding-top: 20px;
}
ul li {
list-style-type: none;
text-align: left;
margin: 5px;
}
#container {
width: 100%;
margin: 0 auto;
}
#contents {
width: 100%;
margin: 0 auto;
padding-bottom: 50px;
}
こちらは最低限Webページを整えるCSSファイルです。
predictor.py
こちらのファイルは、連載1本目にて書かれているpredictor.pyと全く同じ内容なので、そのままコピーしてきてください。
server.py
# coding: utf-8
import os
import tornado.ioloop
import tornado.web
import predictor
class MainHandler(tornado.web.RequestHandler):
"""
トップページを返す
"""
def get(self):
self.render("index.html")
class RecognitionHandler(tornado.web.RequestHandler):
"""
画像を受け取り、識別結果を返す
"""
def post(self):
image_path = ""
# 画像データと拡張子を変数に格納
files = self.request.files
image = files['image'][0]['body']
mime = files['image'][0]['content_type']
# jpeg画像の場合
if mime == "image/jpeg":
image_path = "images/image.jpg"
# png画像の場合
elif mime == "image/png":
image_path = "images/image.png"
# サポートされていない形式だった場合
else:
self.redirect('/')
# 一時ファイルに画像を書き込み
f = open(image_path, "wb")
f.write(image)
f.close()
# 画像の識別
top5 = predictor.predict_image(image_path)
probs = []
for i, data in enumerate(top5):
probs.append("{0}. {2} / 確率:{1:.5}%".format(i+1, data[0]*100, data[1]))
self.render("recognition.html", image_path=image_path, probs=probs)
application = tornado.web.Application(
[
(r"/", MainHandler),
(r"/recognize", RecognitionHandler)
],
template_path=os.path.join(os.getcwd(), "templates"),
static_path=os.path.join(os.getcwd(), "static")
)
if __name__ == "__main__":
application.listen(8000)
tornado.ioloop.IOLoop.instance().start()
こちらが、Webサーバの本体となるコードです。Tornadoを使い、8000番ポートで通信を待ち受けています。トップページへアクセスした場合はMainHandlerクラス内の処理が、/recognizeへアクセスした時はRecognitionHandlerクラス内の処理が行われます。
synset_words.txt
こちらは連載1回目の記事で用いたラベルデータと同じファイルです。
Webサーバの起動
では、紹介した構成で実際にWebサーバを起動してみます。
まず、以下のコマンドでWebサーバの起動に必要なパッケージをインストールします。前回の記事を読んでいない方は、そちらでインストールした機械学習フレームワーク「Chainer」のパッケージも合わせてインストールしてください。
$ pip install tornado==4.5.1
パッケージをインストールしたら、実際に Webサーバを起動しましょう。
まず、source2ディレクトリ内へ移動します。
次に、CPU環境の方は以下のコマンドを実行してください。
$ python server.py
GPU環境の方は以下のコマンドを実行してください。
$ python server.py -g 0
これで、Webサーバが起動されたので、ブラウザを起動し、http://WebサーバのIPアドレス:8000/へアクセスして見ましょう。
以下のような画面が表示されれば、Webサーバ起動成功です。
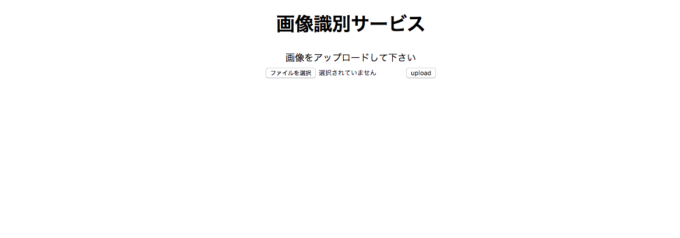
最後に、この記事で最も重要な機能である画像の識別ができるかを確かめて見ましょう。
ファイルを選択し、uploadボタンをクリックしてください。GPUの方は数秒から数十秒、CPUの方は最悪2分くらいかかりますのでのんびりとサーバからの応答をお待ちください。以下のような識別結果画面が表示されれば成功です。

これで、AIを用いたWebサービスが完成しました。
まとめ
今回は、前回の画像識別器をそのまま用いて、Webサービスを開発しました。
次回は、ディープラーニングを用いて自分のオリジナル画像識別器を作成し、差し替える作業を行います。