Docker 1.12の新機能、ヘルスチェック機能を使ってみる

Docker 1.12では新たにコンテナのヘルスチェック機能が実装されており、コンテナやコンテナ内のサービスが正しく動作しているかをDockerだけで監視することができる。現時点では用途が限られているものの、同じくDocker 1.12で導入されたSwarmモードではこれを使ってサービスの再起動が可能だ。本記事ではこの監視機能について紹介する。
Docker 1.12に実装されたヘルスチェック機能概要
Docker 1.12で実装されたヘルスチェック機能は、一定間隔で指定されたコマンドを実行し、その終了コードが1だった場合が一定回数継続したらコンテナに問題が発生したと判断するものだ(図1)。
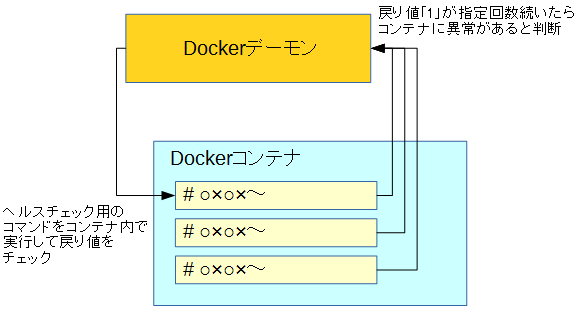
ヘルスチェック機能を利用するよう設定したコンテナでは健康状態(health)というステータスが設定され、問題が発生したコンテナは「unhealthy」、問題が発生していないコンテナには「healthy」が設定される。このステータスは「docker ps」コマンドや「docker inspect」コマンドで外部から取得できる。
ただし、Docker 1.12時点ではコンテナのヘルスステータスが変わっても、それに応じて何か処理を実行するという機能は単独では提供されていない。同じくDocker 1.12で導入されたSwarmモードを利用している場合、コンテナがunhealthyになった場合にそのコンテナが強制停止されて新たなコンテナを立ち上げる機能が用意されているが、Swarmモードを利用していない場合は、コンテナがunhealthyになってもDockerは何も行わない。そのため、たとえば「コンテナがunhealthyになったらそのコンテナを再起動する」といった処理を行いたい場合は、別途Dockerデーモンにアクセスしてコンテナの状態を取得するようなツールを用意する必要がある。
ヘルスチェック機能の設定
ヘルスチェック機能を利用するための設定には2種類の方法がある。一つはあらかじめコンテナイメージの作成時にDockerfileにヘルスチェックのための設定を追加していくというものだ。また、コンテナの起動時に「docker run」コマンドのオプションで設定をおこなうことでも利用できる。ただし、どちらの場合もヘルスチェックの際に実行するコマンドはコンテナ内に用意されている必要がある。ヘルスチェック機能を利用したい場合はあらかじめこの点について留意しておく必要がある。
Dockerfileでの設定
それでは、ヘルスチェック機能を利用するための設定を具体的に紹介しよう。Dockerfile内では、「HEALTHCHECK」コマンドでこの設定を行える。HEALTHCHECKコマンドの書式は以下のようになっている。
HEALTHCHECK [--interval=<実行間隔>] [--timeout=<タイムアウト時間>] [--retries=<リトライ数>] CMD <実行するコマンド>
現時点では「--interval」および「--timeout]、「--retries」の3つのオプションが利用可能で、これらはすべて省略が可能だ。「--interval」オプションは指定したコマンドの実行間隔を秒で指定するもので、たとえば5秒なら「5s」、10秒なら「10s」と指定する。オプション指定を省略した場合、「30s」(30秒)となる。
「--timeout」オプションはタイムアウト時間を秒で指定するもので、コマンドを実行してからコマンドが終了せずにここで指定した時間が経過したら失敗とみなされる。省略時のデフォルト値は「30s」(30秒)だ。
「--retries」オプションでは、コマンドの実行に何回失敗したらunhealthy状態になるかを指定するものだ。省略時のデフォルト値は「3」となっている。ここで指定した回数分連続でコマンドの実行が失敗したら、そのコンテナはunhealthyと判断される。
実行するコマンドはコンテナが正常に稼動していれば終了コード「0」を、そうでなければ「1」を返すようになっている必要がある。これさえ守っていれば、実行するコマンドはバイナリでもスクリプトでも構わない。
また、HEALTHCHECKコマンドでは「HEALTHCHECK NONE」という構文も用意されている。これが指定されていた場合、そのコンテナイメージの親となるコンテナイメージ(「FROM」コマンドで指定されたコンテナイメージ)でヘルスチェックの設定が行われていた場合でも、その設定を無視するようになる。
docker runコマンドで指定
「docker run」コマンドで設定を行う場合も、指定できるパラメータはDockerfile内で設定する場合と同じだ。以下の4つのオプションで実行するコマンド、実行間隔、タイムアウト時間、リトライ数が指定できる。
--health-cmd <実行するコマンド> --health-interval <実行間隔> --health-timeout <タイムアウト時間> --health-retries <リトライ数>
--health-intervalおよび--health-timeout、--health-retriesはDockerfileのHEALTHCHECKコマンドの--intervalおよび--timeout、--retriesオプションに対応し、設定できる値も同じとなっている。
また、これらに加えてDockerfileで指定されたヘルスチェック機能を無効化する「--no-healthcheck」オプションも用意されている。
ヘルスチェックコマンドの例
Dockerでは、「docker run」コマンドで指定して実行したプロセス(もしくはDockerfile内で「CMD」オプションで指定されたプロセス)が終了するとコンテナが終了する。また、この際の挙動は「docker run」コマンドの「--restart」オプションで指定できる(詳しくは「docker run」コマンドのドキュメントを参照)。そのため、通常はプロセス自体の死活監視を行う必要はない。しかし、何らかの不具合でプロセスが暴走したり、動作異常が発生して外部からの入力を受け付けない状態になる可能性はある。ヘルスチェックは主としてこういった状況を検知するために使われる。
たとえばネットワーク接続を受け付けるサーバーソフトウェアの場合、ヘルスチェックコマンドではそのサーバーへの接続を行い、正常に接続できれば0を返す、というものになるだろう。HTTPサーバー(Webサーバー)の場合、次のようにcurlコマンドを使用することで、サーバーが実際にクライアントからのリクエストを処理できているかを監視できる。
curl -s -S -o /dev/null <監視したいURL>
ここで「-s」オプションは進捗情報の出力を抑制するもの、「-S」オプションは-sオプションと同時に指定することでエラー発生時にエラーメッセージを表示するよう指定するものだ。
<監視したいURL>には、サーバーにアクセスするためのURLを指定する。ここで注意したいのは、ヘルスチェックコマンドとして指定されたコマンドはコンテナ内で実行されることだ。監視したいURLは通常は「http://<コンテナに割り当てられたIPアドレス>」などになる。Dockerではコンテナの実行前にコンテナに割り当てられるIPアドレスを知ることはできないが、その代わりホスト名からIPアドレスを正引きできるように自動的に設定が行われるため、次のようにHOSTNAME環境変数を使用してURLを指定できる。
curl -s -S -o /dev/null http://$HOSTNAME
また、アクセスログでヘルスチェックのためのアクセスを判別できるよう、たとえば「?hc=1」のようなクエリパラメータを指定する、もしくはヘルスチェック専用のURLを用意しておく場合もある。
curl -s -S -o /dev/null http://$HOSTNAME/?hc=1
それでは、これを使って実際に監視を行ってみよう。使用するコンテナとしては、DockerHubで公開されているDocker公式イメージを利用する。このイメージにはcurlは含まれていないので、これをベースにcurlをインストールし、さらにヘルスチェック関連の設定を追加した次のようなDockerfileを用意した。
FROM httpd:2.4 RUN apt-get update && apt-get install -y curl && apt-get clean HEALTHCHECK CMD curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1
ここではcurlコマンドの後に「|| exit 1」というコマンドを追加している。curlコマンドはHTTPでの接続に成功した場合は0を返すが、失敗した場合はその状況によって異なるエラーコードを返すためだ。Dockerのヘルスチェック機能ではエラーコードが0か1かでステータスを判断するため、このようにして0以外のエラーコードが返された場合は1を返すよう設定している。
今回はこのDockerfileを使ってビルドしたコンテナイメージを検証に使用している。ビルドしたイメージには「ht_tec」という名前を付けておいた。
docker build -t hc_test .
ちなみにcurlコマンドとそれに依存するライブラリ等のインストールによって、コンテナイメージのサイズは約20MBほど増加している。
# docker images REPOSITORY TAG IMAGE ID CREATED SIZE hc_test latest b2640b981295 2 minutes ago 212.8 MB httpd 2.4 50f10ef90911 5 days ago 193.3 MB
続いてこのコンテナを実行してみると、ログからは外部から何もアクセスがない場合も次のようにヘルスチェック用のアクセスがあることが確認できる。
# docker run --rm -ti -p 80:80 hc_test AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.3. Set the 'ServerName' directive globally to suppress this message AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.3. Set the 'ServerName' directive globally to suppress this message [Mon Nov 14 11:02:35.166447 2016] [mpm_event:notice] [pid 1:tid 139731658315648] AH00489: Apache/2.4.23 (Unix) configured -- resuming normal operations [Mon Nov 14 11:02:35.171385 2016] [core:notice] [pid 1:tid 139731658315648] AH00094: Command line: 'httpd -D FOREGROUND' 172.17.0.3 - - [14/Nov/2016:11:03:05 +0000] "GET /?hc=1 HTTP/1.1" 200 45 172.17.0.3 - - [14/Nov/2016:11:03:35 +0000] "GET /?hc=1 HTTP/1.1" 200 45 172.17.0.3 - - [14/Nov/2016:11:04:05 +0000] "GET /?hc=1 HTTP/1.1" 200 45
また、「docker ps」コマンドでコンテナの稼動状態を確認すると、「STATUS」欄の出力に「(healthy)」という情報が追加されていることが分かる。これはそのコンテナが監視されており、状態が「healthy」であるという意味となる。ちなみに、コンテナの起動直後でまだ一度もヘルスチェックコマンドが実行されていない場合は「health: starting」というステータスとなる。
# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 83d69944a4cf hc_test "httpd-foreground" 46 seconds ago Up 45 seconds (healthy) 0.0.0.0:80->80/tcp sick_ride
続いて、コンテナ内で稼動させているHTTPサーバーを停止させ、コンテナがどのような挙動をするか確認してみよう。まず、「docker exec」コマンドを使ってコンテナ内でシェルを起動し、実行されているプロセスを確認する。
# docker exec -ti 83d69944a4cf bash root@83d69944a4cf:/usr/local/apache2# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.1 0.2 77184 2928 ? Ss+ 11:02 0:00 httpd -DFOREGROUND daemon 6 0.0 0.4 366364 4148 ? Sl+ 11:02 0:00 httpd -DFOREGROUND daemon 7 0.0 0.4 366364 4148 ? Sl+ 11:02 0:00 httpd -DFOREGROUND daemon 8 0.0 0.4 366364 4148 ? Sl+ 11:02 0:00 httpd -DFOREGROUND root 90 0.6 0.1 20240 1920 ? Ss 11:02 0:00 bash root 94 0.0 0.1 17492 1152 ? R+ 11:03 0:00 ps aux
ここでは、プロセスIDが1および6、7、8のプロセスがHTTPDのプロセスであることが分かる。続いてこれらプロセスにkillコマンドでSIGSTOPシグナルを送信し、プロセスの活動を一時停止させる。ここで指定している「-s」オプションは送信するシグナルを指定するものだ。
root@83d69944a4cf:/usr/local/apache2# kill -s SIGSTOP 1 6 7 8
この状態で数分経った後に「docker ps」コマンドでコンテナのステータスを確認すると、「STATUS」が「unhealthy」になったことが分かる。ただし、前述のとおりコンテナの状態がunhealthyになっても何もアクションは行われない。
# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 83d69944a4cf hc_test "httpd-foreground" 5 minutes ago Up 5 minutes (unhealthy) 0.0.0.0:80->80/tcp sick_ride
また、ヘルスチェックコマンドの実行結果については「docker ps」コマンドの出力結果中にある「Health」要素で確認できる。ただし、ここでは直近5回分の結果しか確認できない。
# docker inspect 83d69944a4cf
:
:
"State": {
"Status": "running",
"Running": true,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 19325,
"ExitCode": 0,
"Error": "",
"StartedAt": "2016-11-14T11:02:35.147360731Z",
"FinishedAt": "0001-01-01T00:00:00Z",
"Health": {
"Status": "unhealthy",
"FailingStreak": 3,
"Log": [
{
"Start": "2016-11-14T20:04:05.28209063+09:00",
"End": "2016-11-14T20:04:05.332752167+09:00",
"ExitCode": 0,
"Output": ""
},
{
"Start": "2016-11-14T20:04:35.33293433+09:00",
"End": "2016-11-14T20:04:35.388510875+09:00",
"ExitCode": 0,
"Output": ""
},
{
"Start": "2016-11-14T20:05:05.388719973+09:00",
"End": "2016-11-14T20:05:35.389123388+09:00",
"ExitCode": -1,
"Output": "Health check exceeded timeout (30s)"
},
{
"Start": "2016-11-14T20:06:05.392861965+09:00",
"End": "2016-11-14T20:06:35.393130022+09:00",
"ExitCode": -1,
"Output": "Health check exceeded timeout (30s)"
},
{
"Start": "2016-11-14T20:07:05.39387514+09:00",
"End": "2016-11-14T20:07:35.394250448+09:00",
"ExitCode": -1,
"Output": "Health check exceeded timeout (30s)"
}
]
}
},
:
:
コンテナ内で停止させていたプロセスに対しSIGCONTシグナルを送信して活動を再開させると、次にヘルスチェックコマンドが実行された時点でコンテナの状態が「healthy」に回復する。
root@83d69944a4cf:/usr/local/apache2# kill -s SIGCONT 1 6 7 8
# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 83d69944a4cf hc_test "httpd-foreground" 8 minutes ago Up 8 minutes (healthy) 0.0.0.0:80->80/tcp sick_ride
「docker events」コマンドでコンテナのヘルスステータスの変化を確認する
コンテナのヘルスステータスについては先に例示したように、「docker ps」コマンドや「docker inspect」コマンドで確認できる。また、「docker events」コマンドを使ってヘルスステータスの変化を確認することも可能だ。
「docker events」コマンドは、Dockerデーモンが検知したDockerに関するさまざまなイベントをリアルタイムで標準出力に出力するものだ。たとえばヘルスチェックを行うよう設定したコンテナを稼動させた状態でコマンドラインで「docker events」コマンドを実行すると、次のようにヘルスチェックコマンドが実行されたタイミングで標準出力にその旨が出力される。
# docker events 2016-11-14T20:33:22.239172006+09:00 container exec_create: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 8756d766dbe527081d123a04ec354713b08107e71d959e086982e2805298f768 (image=hc_test, name=naughty_almeida) 2016-11-14T20:33:22.239205376+09:00 container exec_start: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 8756d766dbe527081d123a04ec354713b08107e71d959e086982e2805298f768 (image=hc_test, name=naughty_almeida) 2016-11-14T20:33:52.287807609+09:00 container exec_create: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 8756d766dbe527081d123a04ec354713b08107e71d959e086982e2805298f768 (image=hc_test, name=naughty_almeida) 2016-11-14T20:33:52.287834223+09:00 container exec_start: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 8756d766dbe527081d123a04ec354713b08107e71d959e086982e2805298f768 (image=hc_test, name=naughty_almeida) : :
また、コンテナのヘルスステータスが変更された場合は次のようにその旨が出力される。
(↓ヘルスステータスがunhealthyになった場合) 2016-11-14T20:36:22.289993127+09:00 container health_status: unhealthy 8756d766dbe527081d123a04ec354713b08107e71d959e086982e2805298f768 (image=hc_test, name=naughty_almeida) (↓ヘルスステータスがhealthyになった場合) 2016-11-14T20:38:01.246163066+09:00 container health_status: healthy 8756d766dbe527081d123a04ec354713b08107e71d959e086982e2805298f768 (image=hc_test, name=naughty_almeida)
そのほか、コンテナの起動時には「container start」、「docker stop」コマンドでコンテナを終了させた場合は「container kill」といったイベントが記録される。そのほか確認できるイベントはオンラインマニュアルを参照して欲しい。
Swarmモードでのヘルスチェック
前述のとおり、Dockerのデフォルト設定ではコンテナがunhealthy状態になってもコンテナの停止や再起動と言った処理は行われない。ただしDocker 1.12の新機能であるSwarmモードでサービスとしてコンテナを稼動させていた場合は、そのコンテナがunhealthy状態になると自動的に再起動が行われる。
次の例は、Swarmモードで稼動させていたコンテナがunhealthyになった場合の動きを「docker events」コマンドを使って追ったものだ。ヘルスステータスがunhealthyになった直後、コンテナが強制終了されていることが分かる。
# docker events (↓コンテナが作成される) 2016-11-14T21:11:52.355652487+09:00 container create b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) 2016-11-14T21:11:52.413260200+09:00 network connect b78f8b7b88817ebbd7deefbbfc8a05dab4e3a122b347f91fe3be47c8ba051f59 (container=b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f, name=bridge, type=bridge) 2016-11-14T21:11:52.538916671+09:00 container start b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) (↓ヘルスチェックコマンドが実行される) 2016-11-14T21:12:22.539201711+09:00 container exec_create: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) 2016-11-14T21:12:22.539318435+09:00 container exec_start: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) (↓ヘルスステータスがhealthyと認識される) 2016-11-14T21:12:22.603915424+09:00 container health_status: healthy b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) : : (↓ヘルスチェックコマンドが実行される) 2016-11-14T21:14:52.606142120+09:00 container exec_create: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) 2016-11-14T21:14:52.606203999+09:00 container exec_start: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) (↓ヘルスステータスがunhealthyと認識される) 2016-11-14T21:15:22.606415677+09:00 container health_status: unhealthy b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) (↓コンテナが強制終了される) 2016-11-14T21:15:22.607370703+09:00 container kill b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f, signal=15) 2016-11-14T21:15:32.608100120+09:00 container kill b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f, signal=9) (↓コンテナが終了する) 2016-11-14T21:15:32.627421324+09:00 container die b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, exitCode=137, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f) 2016-11-14T21:15:32.668464327+09:00 network disconnect b78f8b7b88817ebbd7deefbbfc8a05dab4e3a122b347f91fe3be47c8ba051f59 (container=b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f, name=bridge, type=bridge) 2016-11-14T21:15:32.693017469+09:00 container stop b180fd26b4d60e70b2d2e49f9fb4590c749c0cf0f1bc71661dc6fb734635eb1f (com.docker.swarm.node.id=bv1u11pex3qr53pwtg24wdazn, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=123i58ppyw7mp8hsz1pplqz8f, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.123i58ppyw7mp8hsz1pplqz8f)
Dockerクラスタのデフォルト設定では、強制終了されたコンテナは別のノードで再起動される。新たにコンテナが起動されるノード上でのイベントを見ると、コンテナが強制終了された直後に新たなコンテナが作成されていることが分かる。
# docker events (↓コンテナが作成される) 2016-11-14T21:15:36.713064966+09:00 container create a2cb59ba9b2e8c190c416efb0dbf62665b04e2a4ede1f605319a1e9fd6f3335c (com.docker.swarm.node.id=aad8r0mqwdu7w5nuvzxa4t8eg, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=2lgdv9o16ydo9ongmazvduvzf, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.2lgdv9o16ydo9ongmazvduvzf) 2016-11-14T21:15:37.879164563+09:00 network connect 7b0de65987a6b2f6720e5238a7e7c5042d35402259623262dbf2b8064042366d (container=a2cb59ba9b2e8c190c416efb0dbf62665b04e2a4ede1f605319a1e9fd6f3335c, name=bridge, type=bridge) 2016-11-14T21:15:38.023964148+09:00 container start a2cb59ba9b2e8c190c416efb0dbf62665b04e2a4ede1f605319a1e9fd6f3335c (com.docker.swarm.node.id=aad8r0mqwdu7w5nuvzxa4t8eg, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=2lgdv9o16ydo9ongmazvduvzf, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.2lgdv9o16ydo9ongmazvduvzf) (↓ヘルスチェックコマンドが実行される) 2016-11-14T21:16:08.024313487+09:00 container exec_create: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 a2cb59ba9b2e8c190c416efb0dbf62665b04e2a4ede1f605319a1e9fd6f3335c (com.docker.swarm.node.id=aad8r0mqwdu7w5nuvzxa4t8eg, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=2lgdv9o16ydo9ongmazvduvzf, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.2lgdv9o16ydo9ongmazvduvzf) 2016-11-14T21:16:08.024378609+09:00 container exec_start: /bin/sh -c curl -s -S -o /dev/null http://$HOSTNAME/?hc=1 || exit 1 a2cb59ba9b2e8c190c416efb0dbf62665b04e2a4ede1f605319a1e9fd6f3335c (com.docker.swarm.node.id=aad8r0mqwdu7w5nuvzxa4t8eg, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=2lgdv9o16ydo9ongmazvduvzf, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.2lgdv9o16ydo9ongmazvduvzf) (↓ヘルスステータスがhealthyと認識される) 2016-11-14T21:16:08.105457224+09:00 container health_status: healthy a2cb59ba9b2e8c190c416efb0dbf62665b04e2a4ede1f605319a1e9fd6f3335c (com.docker.swarm.node.id=aad8r0mqwdu7w5nuvzxa4t8eg, com.docker.swarm.service.id=cl84itdvdgu8hazx63gydcwzc, com.docker.swarm.service.name=lonely_kilby, com.docker.swarm.task=, com.docker.swarm.task.id=2lgdv9o16ydo9ongmazvduvzf, com.docker.swarm.task.name=lonely_kilby.1, image=hc_test:latest, name=lonely_kilby.1.2lgdv9o16ydo9ongmazvduvzf) : :
なお、これは複数のノードでDockerクラスタが構成されている場合の動作例であるが、1つのノードだけでDockerクラスタを構成した場合でも同様の挙動となり、docker serviceコマンドで作成したコンテナがunhealthy状態になったら同じノード上でコンテナが再起動される。
Swarmモードでのクラスタでは有用
このように、Dockerのヘルスチェック機能は監視という面では問題なく機能するが、ヘルスステータスが変わったときの対応についてはSwarmモードでしか対応されておらず、やや中途半端な印象だ。そのため、Swarmモードを使わずに単独でコンテナを実行している場合はDockerデーモンが出力するイベントを監視してヘルスステータスの変化を検出して再起動を実行するようなスクリプトなどを用意する必要があり、実用的とは言いがたい。
そのためヘルスチェック機能は現時点ではほぼSwarmモード専用の機能といっても良いが、今後はこの機能を使ってコンテナの監視を行うサードパーティ製のツールが登場したり、またDockerのアップデートで何らかの機能追加が行われる可能性がある。もちろん、Swarmモードを利用している環境では現時点でも有用だが、今後の機能強化やサポート環境の広がりに期待したい。