Terraform for さくらのクラウド スタートガイド (第四回)〜ネットワークの構築〜

前回は「Terraform for さくらのクラウド」を用いることでTerraformからさくらのクラウド上にインフラ構築を行いました。
今回は中規模~大規模な構成には不可欠なネットワーク関連のリソースについて扱います。
複数台による冗長構成でのサービス提供やスケールイン/アウト(負荷に応じて動的に台数を増減)できる構成にはネットワーク関連のリソースが欠かせませんので、しっかりと扱い方を押さえておきましょう。
目次
前回の補足:データソースのバージョンアップ
前回データソースについて扱いましたが、2017年3月にTerraform for さくらのクラウドのバージョンアップを行い、より簡潔な書き方ができるようになりましたのでご紹介いたします。
前回はディスクのコピー元となるパブリックアーカイブのIDを参照するために、以下のようにデータソースの記述を行なっていました。
# データソース(パブリックアーカイブ:CentOS)
data sakuracloud_archive "centos" {
filter = {
name = "Tags"
values = ["current-stable", "arch-64bit", "distro-centos"]
}
}
Terraform for さくらのクラウドのバージョンアップにより、以下のように記述できるようになりました。
# データソース(パブリックアーカイブ:CentOS)
data sakuracloud_archive "centos" {
os_type = "centos"
}
"os_type"という属性が追加されています。パブリックアーカイブについてはこの"os_type"パラメータを利用することで簡単に参照可能となりました。
"os_type"に指定可能な値については以下のドキュメントを参照ください。
参考:Terraform for さくらのクラウド - データソース
以降の連載ではこの新しい機能を用います。
さくらのクラウドのネットワーク関連リソース
さて、それではネットワーク関連リソースについて扱っていきます。
さくらのクラウドには以下のようなネットワーク関連のリソースがあります。
- パケットフィルタ
- スイッチ
- ルータ+スイッチ
- ブリッジ
- ロードバランサー
- VPCルータ(※次回扱います)
ここに挙げていないリソースとして、DNSやGSLB、シンプル監視といったリソースもあるのですが、これらは次回扱う予定です。
それでは順番に見ていきましょう。
注:以降の当記事内のtfファイルの例示にはパスワードを直接記述している部分があります。試す際には"YOUR_PASSWORD_HERE"となっている部分を各自で置き換えるなどの対応を行なった上でご利用ください。
パケットフィルタ
サーバーの仮想NICに着信するパケットに対し条件を指定してフィルタリングを行うことができます。
参考:さくらインターネット 公式サポートサイト: パケットフィルタ
ここでは例として、
- ICMP(pingなど)を許可
- SSH(tcp/22)ポートへの通信を許可
- それ以外の外部からの通信を拒否
という条件でフィルタリングしてみます。
注:この例は解説のために簡易的な定義にしています。
このままだとサーバー内部から外部への通信ができないため、実際の運用の際は適時必要なルールを追加してご利用ください。
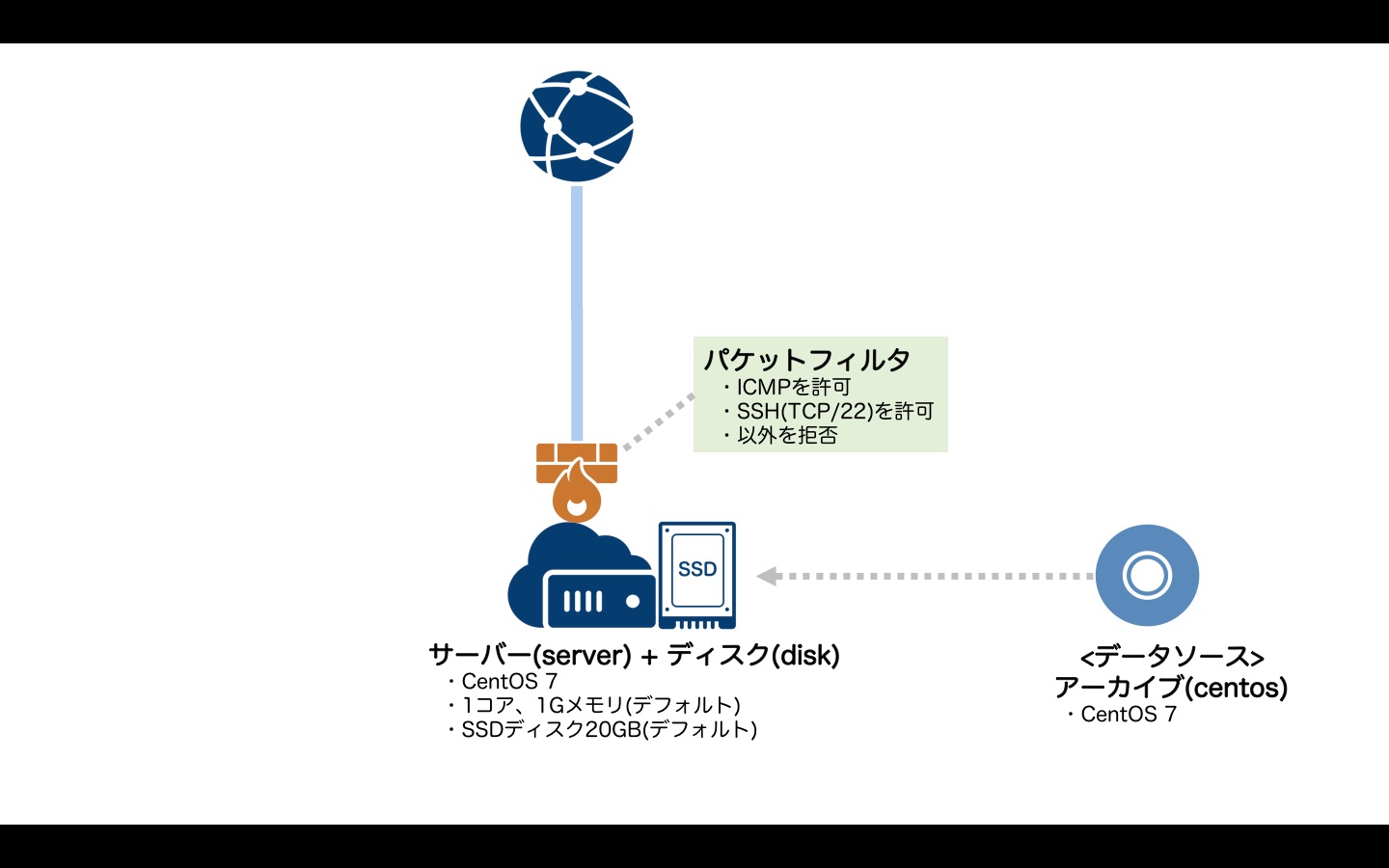
tfファイルは以下のようになります。
# データソース(アーカイブ) data sakuracloud_archive "centos" { os_type="centos" } # ディスク resource "sakuracloud_disk" "disk"{ # ディスク名 name = "disk" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" } # サーバー resource "sakuracloud_server" "server" { # サーバー名 name = "server" # 接続するディスク disks = ["${sakuracloud_disk.disk.id}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # パケットフィルタを接続 packet_filter_ids = ["${sakuracloud_packet_filter.filter.id}"] } # パケットフィルタ resource "sakuracloud_packet_filter" "filter" { name = "filter" # icmpを許可 expressions = { protocol = "icmp" allow = true } # SSH(tcp:22)を許可 expressions = { protocol = "tcp" dest_port = "22" allow = true } # 以外の全通信を拒否 expressions = { protocol = "ip" allow = false } }
詳細を見ていきましょう。
パケットフィルタの定義
パケットフィルタは以下のように定義します。
resource "sakuracloud_packet_filter" "filter" {
name = "filter"
# expressions属性でルールを定義(複数可)
expressions = {
# フィルタリングルールを記載
}
}
expressions属性にてルールと定義していきます。ルールは複数定義できますので、お好みのルールを設定してみてください。
参考:Terraform for さくらのクラウド - 設定リファレンス - パケットフィルタ
なお、さくらのクラウドのパケットフィルタでは、いずれのルールにも合致しなかったパケットについては通信が許可されるようになっています。
必要最低限の通信のみを許可するために、ルールの最後に全ての通信を拒否するためのルールを置いておくのがオススメです。
# 全ての通信を拒否するルール expressions = { protocol = "ip" allow = false }
パケットフィルタとサーバーを接続
サーバーリソースの定義にて接続するパケットフィルタのIDを指定することで接続を行います。
# サーバー resource "sakuracloud_server" "server" { [...] # パケットフィルタを接続 packet_filter_ids = ["${sakuracloud_packet_filter.filter.id}"] }
参考:Terraform for さくらのクラウド - 設定リファレンス - サーバー
パケットフィルタのIDはリストで設定することにご注意ください。
サーバーには複数のNICを装着することが可能なため、パケットフィルタについても各NICに適用できるようにリストとなっています。
スイッチ
スイッチを利用することで、クラウド上にローカルネットワークを構築することができます。スイッチには複数のサーバーやロードバランサー、VPCルータなどを接続することが可能です。
また、後述するブリッジを利用するためにはスイッチが必須となっています。
参考:さくらのクラウドニュース - スイッチ/ルータ+スイッチ
ここでは例としてスイッチを作成し、サーバーと接続してみます。
動作確認のためにサーバーは2台用意し、以下のプライベートIPアドレスを割り当てます。
- サーバー0 : 192.168.2.11/24
- サーバー1 : 192.168.2.12/24
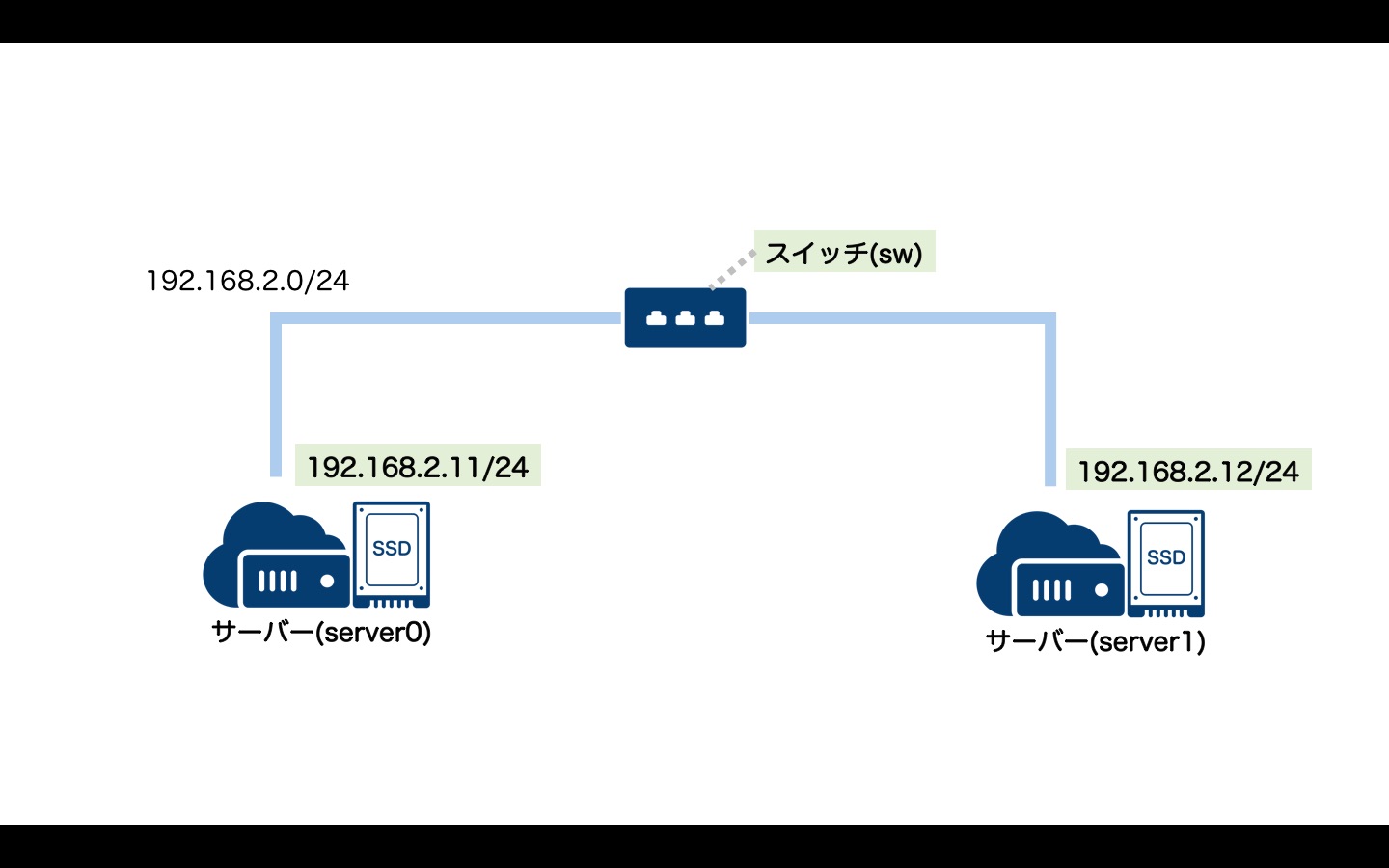
tfファイルは以下のようになります。サーバーを2台定義するのに"count"を使っています(countの詳細は後述します)。
# サーバーに割り当てるIPアドレスをリスト変数として定義 variable "private_ip_addresses" { default = ["192.168.2.11" , "192.168.2.12"] } # データソース(アーカイブ) data sakuracloud_archive "centos" { os_type="centos" } # ディスク resource "sakuracloud_disk" "disks"{ # 2台分 count = 2 # ディスク名 name = "disk${count.index}" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" } # サーバー resource "sakuracloud_server" "servers" { # 2台分 count = 2 # サーバー名 name = "server${count.index}" # 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # スイッチを接続 base_interface = "${sakuracloud_switch.sw.id}" # eth0のIPアドレス/ネットマスク設定 base_nw_ipaddress = "${var.private_ip_addresses[count.index]}" base_nw_mask_len = 24 # デフォルトゲートウェイを設定する場合 # base_nw_gateway = 192.168.2.1 } # スイッチ resource "sakuracloud_switch" "sw" { name = "sw" }
スイッチ
まずはスイッチの定義を見てみましょう。
# スイッチ
resource "sakuracloud_switch" "sw" {
name = "sw"
}
スイッチは設定項目自体が少ないため、定義も簡潔なものになっています。
参考:Terraform for さくらのクラウド - 設定リファレンス - スイッチ
サーバーの定義(countの利用)
続いてサーバーの定義部分を見てみましょう。
今回はほぼ同じ設定のサーバーを2台用意するためにcountという属性を利用しています。まずはサーバーに接続するディスクの定義は以下のようになっています。
# ディスク resource "sakuracloud_disk" "disks"{ # 2台分 count = 2 # ディスク名 name = "disk${count.index}" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" }
count属性には作成するリソースの数量を指定できます。
また、${count.index}とすることで、リソース自身が何番目のリソースであるのかを参照可能になっています。(indexは0開始)
これを利用してディスク名を"disk${count.index}"という風に設定しています。
0番目のディスクは"disk0"、1番目のディスクは"disk1"という名前で作成されます。
続いてサーバーの定義を見てみましょう。
# サーバーに割り当てるIPアドレスをリスト変数として定義 variable "private_ip_addresses" { default = ["192.168.2.11" , "192.168.2.12"] } # サーバー resource "sakuracloud_server" "servers" { # 2台分 count = 2 # サーバー名 name = "server${count.index}" # 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # スイッチを接続 base_interface = "${sakuracloud_switch.sw.id}" # eth0のIPアドレス/ネットマスク設定 base_nw_ipaddress = "${var.private_ip_addresses[count.index]}" base_nw_mask_len = 24 # デフォルトゲートウェイを設定する場合 # base_nw_gateway = 192.168.2.1 }
先頭で"private_ip_addresses"というリスト型の変数を定義しています。
これを先ほどのcount.indexと組み合わせて"${var.private_ip_addresses[count.index]}"とすることで、
- 0番目のサーバーのIPアドレス: 192.168.2.11
- 1番目のサーバーのIPアドレス: 192.168.2.21
と設定しています。
count指定されたリソースの属性を参照するには?
これまでの連載ではリソースの属性を参照する場合は以下のようにしていました。
# リソースID="disks"のディスクリソースのIDを参照
${sakuracloud_disk.disks.id}
count指定されているリソースの場合、以下のようにインデックス(何番目のリソースか?)を指定することで参照可能です。
# リソースID="disk"のディスクリソースの0番目のリソースのIDを参照 ${sakuracloud_disk.disks[0].id} # 以下の書き方でもOK ${sakuracloud_disk.disks.0.id}
これを利用してサーバーリソースの定義内で${count.index}を利用してディスクのIDを参照するには以下のように記述します。
# 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"]
sakuracloud_disk.disks.*.idという記述でリソースID="disk"のディスクリソースのIDをリストにできます。
リストに対し$list[count.index]とすることでcount.index番目の値を参照することができます。
このテクニックはcount指定を行う上でよく利用しますので覚えておきましょう。
スイッチとサーバーの接続
今回はサーバーの最初のNIC(eth0)にスイッチを接続します。
この場合は以下のように記述します。
# サーバー resource "sakuracloud_server" "servers" { # [...] # スイッチを接続 base_interface = "${sakuracloud_switch.sw.id}" # [...] }
さくらのクラウドでは最初のNICは特別扱いされており、「ディスクの修正」機能を用いることでIPアドレスやゲートウェイの指定を行うことが可能になっています。(2番目以降のNICのIPアドレスなどの設定は各自で行う必要があります)
また、最初のNICのみインターネットへの接続(共有セグメント)や後述するルータ+スイッチとの接続が可能です。
詳細は以下のさくらのクラウドのドキュメントを参照してください。
参考:さくらのクラウドニュース - よくある質問(技術的な質問)
もし最初のNICはインターネットに接続し、2番目のNICをスイッチにつなぐ構成を取る場合は以下のように"additional_interfaces"属性に対しスイッチIDを指定すればOKです。
注:2番目のNIC(eth1)のIPアドレスは別途プロビジョニングが必要です
# サーバー(NICを複数にする場合の例) resource "sakuracloud_server" "servers" { # 2台分 count = 2 # サーバー名 name = "server${count.index}" # 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # 最初のNICはインターネットへ接続 # (デフォルトでインターネット接続されるため、省略可能) base_interface = "shared" # 2番目以降のNICは接続するスイッチのIDをリストで設定することで作成される additional_interfaces = ["${sakuracloud_switch.sw.id}"] }
動作確認
terraform applyしたら、さくらのクラウドのコントロールパネルからサーバーのコンソールを開いてログイン、ping(192.168.2.11/192.168.2.12)を打ってみましょう。
2台のサーバー同士がお互いに通信できることが確認できるはずです。
ルータ+スイッチ
先ほどのスイッチはローカルネットワーク(プライベートネットワーク)構築用のものでした。それに対しルータ+スイッチには以下のような機能があります。
- 固定グローバルIPアドレスをサブネット単位で確保
- IPv6アドレス割り当て機能
- 100〜3000Mbpsまでの帯域を利用可能にする広帯域インターネットコネクティビティ
特に帯域の変更ついては通信断することなく変更ができるというさくらのクラウドならではの便利な機能となっています。
参考:さくらのクラウドニュース - スイッチ/ルータ+スイッチ
ここでは例としてルータ+スイッチを作成し、サーバーと接続してみます。
動作確認のためにサーバーは2台用意し、以下のIPアドレスを割り当てます。
- サーバー0 : スイッチ+ルータで確保したグローバルIPアドレス(0番目のIP)
- サーバー1 : スイッチ+ルータで確保したグローバルIPアドレス(1番目のIP)
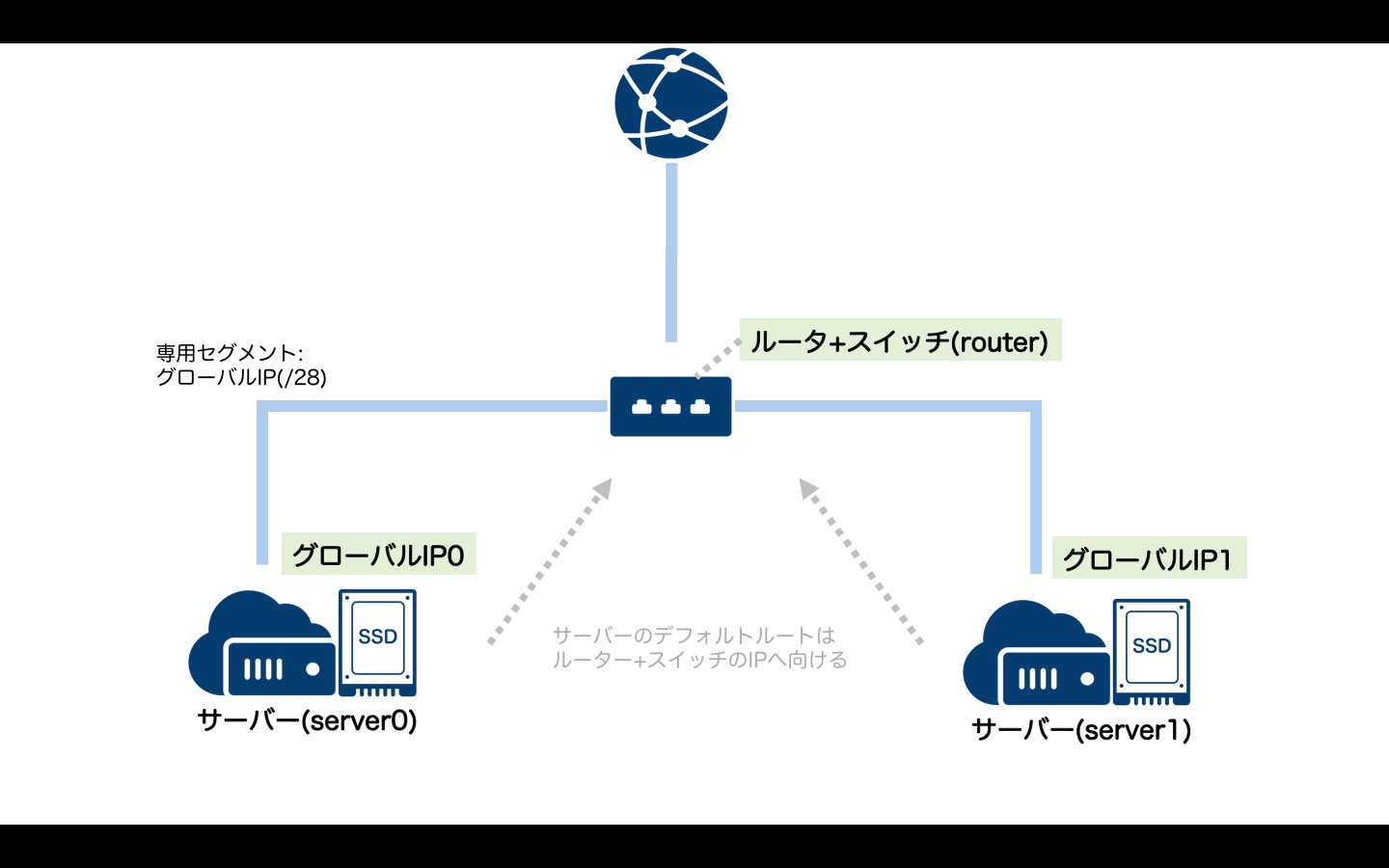
tfファイルは以下のようになります。先ほどのスイッチの例と比べると、サーバーのIPアドレス設定部分に違いがあります。
# データソース(アーカイブ) data sakuracloud_archive "centos" { os_type="centos" } # ディスク resource "sakuracloud_disk" "disks"{ # 2台分 count = 2 # ディスク名 name = "disk${count.index}" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" } # サーバー resource "sakuracloud_server" "servers" { # 2台分 count = 2 # サーバー名 name = "server${count.index}" # 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # ルータ+スイッチを接続 base_interface = "${sakuracloud_internet.router.switch_id}" # eth0のIPアドレス/ネットマスク設定 base_nw_ipaddress = "${sakuracloud_internet.router.nw_ipaddresses[count.index]}" base_nw_mask_len = "${sakuracloud_internet.router.nw_mask_len}" # ゲートウェイ(ルータに割り当てられた値を利用する) base_nw_gateway = "${sakuracloud_internet.router.nw_gateway}" } # ルータ resource "sakuracloud_internet" "router" { name = "router" # 割り当てるグローバルIPのネットマスク、デフォルト/28 # nw_mask_len = 28 # 帯域幅、デフォルト100(Mbps) # band_width = 100 }
ルータ+スイッチの定義
ルータ+スイッチは以下のように定義されています。
# ルータ resource "sakuracloud_internet" "router" { name = "router" # 割り当てるグローバルIPのネットマスク、デフォルト/28 # nw_mask_len = 28 # 帯域幅、デフォルト100(Mbps) # band_width = 100 }
参考:Terraform for さくらのクラウド - 設定リファレンス - ルータ+スイッチ
スイッチと比較すると、グローバルIPのネットマスク長や帯域幅などの設定項目が増えています。
注:ルータ+スイッチには作成時に確保したグローバルIPアドレスとは別に追加でサブネット単位のグローバルIPを割り当てる機能がありますが、執筆時点のTerraform for さくらのクラウド(v0.7.2)では未実装です。近日中の対応を予定しております。
サーバーの設定(アドレス設定部分)
ルータ+スイッチをサーバーに接続する場合、サーバーのIPアドレスにはルータ+スイッチで確保したグローバルIP/ネットマスクを設定する必要があります。また、デフォルトゲートウェイについてはルータ+スイッチの作成時に割り当てられたグローバルIPの中から自動的に割り当てられるようになっています。サーバーのデフォルトゲートウェイにはこの割り当てられたアドレスを指定します。
# サーバー resource "sakuracloud_server" "servers" { # [...] # ルータ+スイッチを接続 base_interface = "${sakuracloud_internet.router.switch_id}" # eth0のIPアドレス/ネットマスク設定 base_nw_ipaddress = "${sakuracloud_internet.router.nw_ipaddresses[count.index]}" base_nw_mask_len = "${sakuracloud_internet.router.nw_mask_len}" # ゲートウェイ(ルータに割り当てられた値を利用する) base_nw_gateway = "${sakuracloud_internet.router.nw_gateway}" }
ここでは"base_interface"に指定するスイッチのIDの記述に注意してください。
ルータ+スイッチは自身のID("sakuracloud_internet.router.id")とは別に内部的にスイッチのIDを保持している("sakuracloud_internet.router.switch_id")ためそちらを指定します。
ブリッジ
ブリッジとは、異なるリージョン・ゾーンに存在するスイッチをL2接続するサービスです。石狩〜東京など異なるゾーンのサーバー同士をL2で接続できます。
ここでは例として2台のサーバーを石狩第2ゾーン("is1b")と東京第1ゾーン("tk1a")に配置し、それぞれのゾーンに配置したスイッチ同士をブリッジ接続してみます。
- サーバー0: 192.168.2.11 : 石狩第2ゾーン
- サーバー1: 192.168.2.12 : 東京第1ゾーン
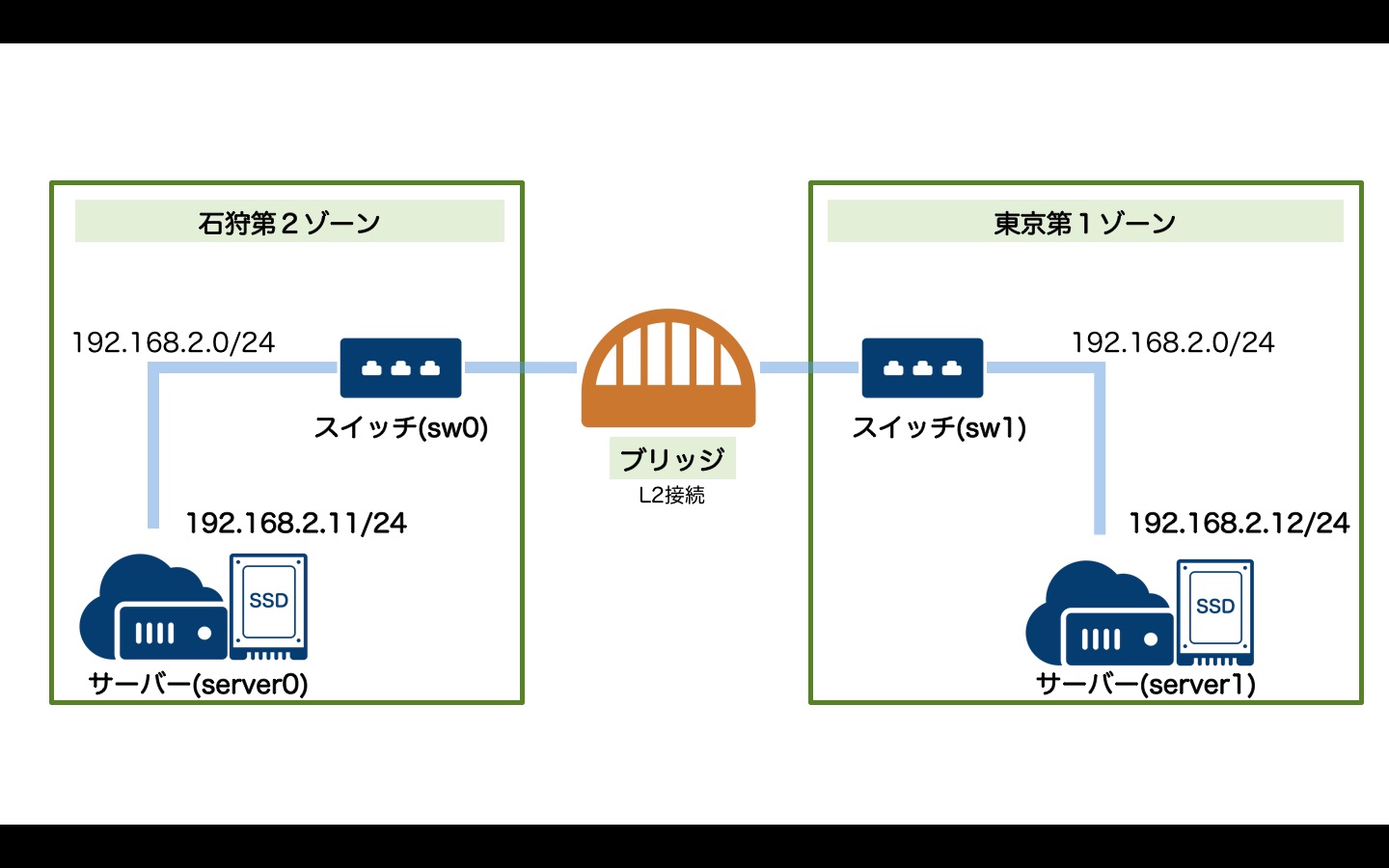
tfファイルは以下のようになります。
# サーバーに割り当てるIPアドレスの定義 variable "private_ip_addresses" { default = ["192.168.2.11" , "192.168.2.12"] } # リソースを作成する対象ゾーンの定義 variable "target_zones" { default = ["is1b" , "tk1a"] } # データソース(アーカイブ) data sakuracloud_archive "centos" { count = 2 # ゾーンごとにIDは異なるため、データソースはゾーンごとに作成する os_type="centos" zone = "${var.target_zones[count.index]}" } # ディスク resource "sakuracloud_disk" "disks"{ # 各ゾーンに1つ count = 2 # ディスク名 name = "disk${count.index}" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.*.id[count.index]}" # パスワード password = "YOUR_PASSWORD_HERE" # ゾーン zone = "${var.target_zones[count.index]}" } # サーバー resource "sakuracloud_server" "servers" { # 各ゾーンに1台 count = 2 # サーバー名 name = "server${count.index}" # 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # スイッチを接続 base_interface = "${sakuracloud_switch.sw.*.id[count.index]}" # eth0のIPアドレス/ネットマスク設定 base_nw_ipaddress = "${var.private_ip_addresses[count.index]}" base_nw_mask_len = 24 # ゾーン zone = "${var.target_zones[count.index]}" } # スイッチ resource "sakuracloud_switch" "sw" { name = "sw${count.index}" # 各ゾーンに1つ作成 count = 2 # ゾーン zone = "${var.target_zones[count.index]}" # ブリッジとの接続 bridge_id = "${sakuracloud_bridge.bridge.id}" } # ブリッジ resource "sakuracloud_bridge" "bridge" { name = "bridge" }
ブリッジの定義
ブリッジは以下のように定義されています。
# ブリッジ
resource "sakuracloud_bridge" "bridge" {
name = "bridge"
}
スイッチと同じく設定項目は少ないです。
参考:Terraform for さくらのクラウド - 設定リファレンス - ブリッジ
ブリッジは「グローバルリソース」と呼ばれる、全ゾーンをまたいで利用するリソースとなっています。
ブリッジとスイッチの接続
ブリッジとスイッチを接続するには、スイッチの定義にて接続先ブリッジのIDを指定する必要があります。
以下の定義で各ゾーンにスイッチを作成し、ブリッジに接続します。
# スイッチ resource "sakuracloud_switch" "sw" { name = "sw${count.index}" # 各ゾーンに1つ作成 count = 2 # ゾーン zone = "${var.target_zones[count.index]}" # ブリッジとの接続 bridge_id = "${sakuracloud_bridge.bridge.id}" }
スイッチだけでなく、アーカイブデータソース、ディスク、サーバーについて各ゾーンにほぼ同じ設定のリソースを作成するためにcountを利用している点に注目してください。
サーバーに割り当てるIPアドレスなどと同じように、ゾーンについても以下のようにリスト型変数として定義して参照しています。
# リソースを作成する対象ゾーンの定義
variable "target_zones" {
default = ["is1b" , "tk1a"]
}
terraform apply実行後、ゾーンをまたいで配置されたサーバー同士が通信できることをpingなどで確認してみましょう。
ちょっと寄り道:スタートアップスクリプト
さて、ここまでで基本的なネットワーク構成要素となるリソースについて扱ってきました。
この後は応用的なリソースであるロードバランサーについて扱いますが、ロードバランサーを利用する場合、サーバー側で通信設定などのプロビジョニングが必要となります。
Terrafromのプロビジョナー
Terraformでプロビジョニングを行う場合、プロビジョナーという仕組みが用意されており、chefを利用したり、SSH/WinRMでサーバーに接続した上でコマンドやファイルを投入するという方法が利用できます。
参考: Terraformドキュメント : Provisioners
各プロバイダーが用意しているプロビジョニングの仕組み
この他にも、AWSでのcloud_init(user_data)のように、各プロバイダー側でプロビジョニングの仕組みを提供している場合もあります。
これらのプロビジョニングの仕組みは併用することもできますので、状況に応じて使い分けると良いでしょう。
さくらのクラウドでのプロビジョニング
さくらのクラウドでも独自のプロビジョニングの仕組みとして「スタートアップスクリプト」という、シェルスクリプトでプロビジョニングを行うための仕組みが用意されています。
参考:さくらのクラウドニュース - スタートアップスクリプト
利用できるOS/アーカイブが限定される(windowsでは使えない)などの制約はありますが、起動時に1回だけ実行するといった便利な補助機能も付いています。以下では実際にスタートアップスクリプトを用いてプロビジョニングを行ってみます。
スタートアップスクリプト
それではterraform for さくらのクラウドでスタートアップを扱う方法を見てみましょう。
ここでは例として以下のような構成にしてみます。
- CentOS7ベースのサーバーを作成
- yumでapache(httpd)をインストール
- インストール後、http(tcp:80)への通信を許可するようにファイアウォールを設定
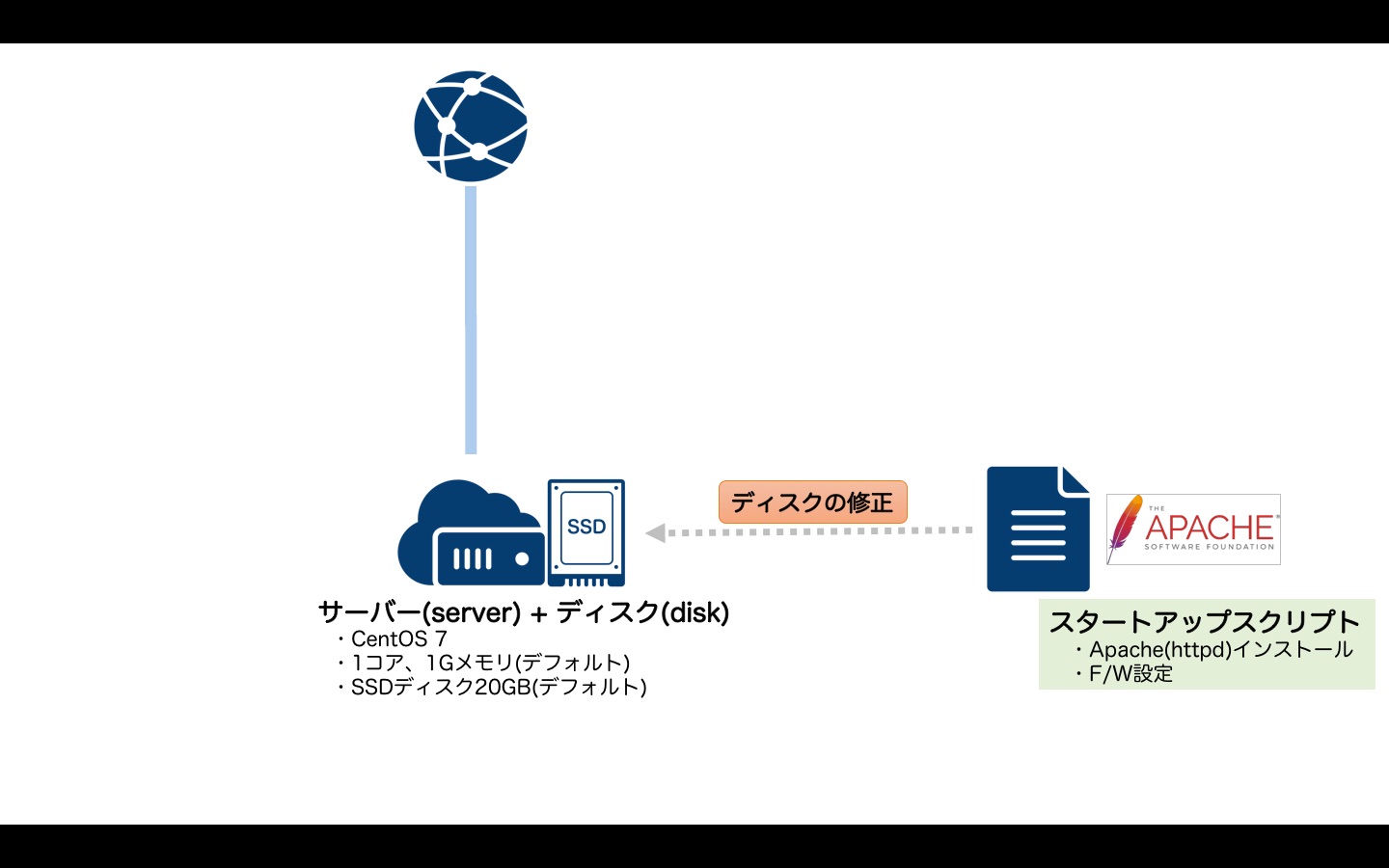
tfファイルは以下のようになります。
# データソース(アーカイブ) data sakuracloud_archive "centos" { os_type="centos" } # ディスク resource "sakuracloud_disk" "disk"{ # ディスク名 name = "disk" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" # スタートアップスクリプトの登録 note_ids = ["${sakuracloud_note.install_httpd.id}"] } # サーバー resource "sakuracloud_server" "server" { # サーバー名 name = "server" # 接続するディスク disks = ["${sakuracloud_disk.disk.id}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] } # スタートアップスクリプト resource "sakuracloud_note" "install_httpd" { name = "install_httpd" content = "${file("install_httpd.sh")}" }
スタートアップスクリプトの定義
スタートアップスクリプトは以下のように定義されています。
# スタートアップスクリプト resource "sakuracloud_note" "install_httpd" { name = "install_httpd" content = "${file("install_httpd.sh")}" }
連載第三回で扱ったfile関数を用いて"content"属性にスクリプトを設定しています。
参考:Terraform for さくらのクラウド - 設定リファレンス - スタートアップスクリプト
読み込んでいる"install_httpd.sh"の内容は以下の通りです。
#!/bin/sh # # @sacloud-once # httpdのインストール yum install -y httpd || exit 1 # 確認用ページ echo 'This is a TestPage!!' >> /var/www/html/index.html || exit1 # サービス起動設定 systemctl enable httpd.service || exit 1 systemctl start httpd.service || exit 1 # ファイアウォール設定 firewall-cmd --add-service=http --zone=public --permanent || exit 1 firewall-cmd --reload || exit 1 exit 0
このスクリプトはCentOS7用となっていますので、CentOS7以外を利用する際は適宜調整してください。
スタートアップスクリプトの適用
スタートアップスクリプトはディスクと紐付けることで適用されます。
(内部の処理としては、ディスク作成時にスタートアップスクリプトの指定があった場合、「ディスクの修正」機能を用いてディスク内にスクリプトを書き込むようになっています)
ディスクとスタートアップスクリプトの紐付けは以下のように記述します。
# ディスク resource "sakuracloud_disk" "disk"{ # [...] # スタートアップスクリプトの紐付け note_ids = ["${sakuracloud_note.install_httpd.id}"] }
terraform applyを実行したのちに、"http://サーバーのグローバルIPアドレス"宛にブラウザでアクセスするとテストページが表示されるのが確認できるはずです。
ロードバランサー
続いて応用的なリソースとしてロードバランサーを扱います。
さくらのクラウドでのロードバランサーはDSR(Direct Server Return)方式で動作する仮想的なアプライアンスとして提供されています。
あらかじめロードバランサーの配下にサーバーを登録しておくことで、ロードバランサーに割り当てた仮想IP宛の通信をサーバーに分散してくれます。配下のサーバーに対しpingやhttpなどで死活監視を行うことで、現在活動していることが確認できているサーバーのみに通信を振り分けてくれます。
ロードバランサーを使うためにはサーバー側の設定も必要
導入する上の注意として、DSR方式で動作するためにサーバー側でも通信の設定が必要になる点があります。
具体的には以下の設定が必要です。
- ロードバランサーに割り当てた仮想IP宛の通信に対して応答できるようにすること
- 仮想IP宛のarpに応答しないようにすること(arp応答はロードバランサーが行うため)
今回はこれらの設定はスタートアップスクリプトを利用してterraformから行うようにします。
例として以下の構成で構築します。
- ルータ+スイッチでグローバルIPを確保
- ロードバランサーにグローバルIPを2つ割り当て(ロードバランサー本体 + 仮想IP)
- ロードバランサーの配下に2台のサーバーを配置(+グローバルIP割り当て)
- サーバーではWebサーバーとしてapache(httpd)を稼働させる
- サーバーの死活監視はhttpで"/"へのリクエストに対しステータスコード200の応答があることを確認する
ルータ+スイッチで確保したグローバルIPは以下のように割り当てます。
- 1番目のグローバルIP(index = 0) : サーバー0のIPアドレス
- 2番目のグローバルIP(index = 1) : サーバー1のIPアドレス
- 3番目のグローバルIP(index = 2) : ロードバランサーのIP#1
- 4番目のグローバルIP(index = 3) : ロードバランサーの仮想IP(VIP)
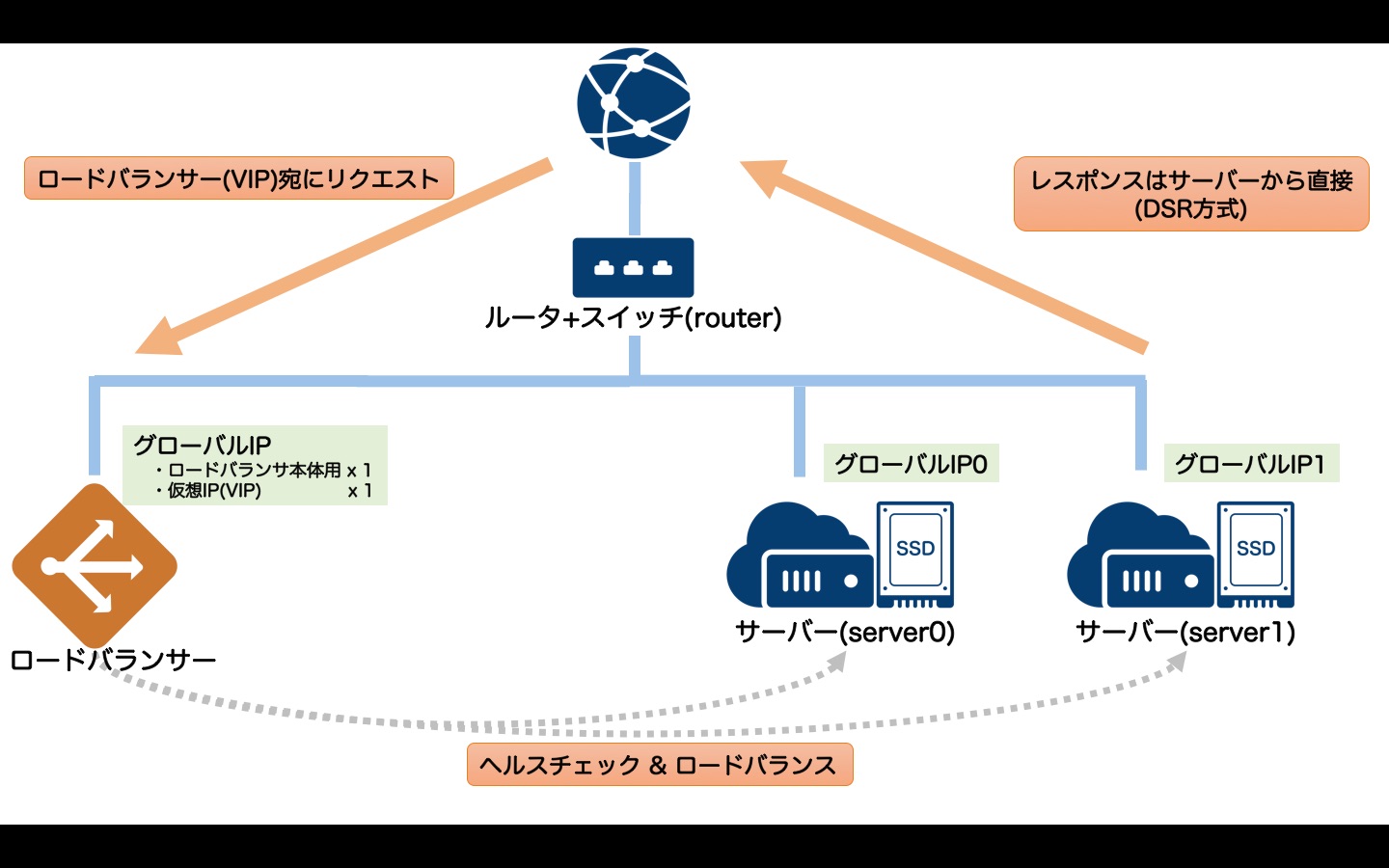
tfファイルは以下のようになります。
# データソース(アーカイブ) data sakuracloud_archive "centos" { os_type="centos" } # ディスク resource "sakuracloud_disk" "disks"{ # 2台分 count = 2 # ディスク名 name = "disk${count.index}" # コピー元アーカイブ(CentOS7を利用) source_archive_id = "${data.sakuracloud_archive.centos.id}" # パスワード password = "YOUR_PASSWORD_HERE" # スタートアップスクリプトと紐付け note_ids = ["${sakuracloud_note.setup_lb_dsr.id}","${sakuracloud_note.install_httpd.id}"] } # サーバー resource "sakuracloud_server" "servers" { # 2台分 count = 2 # サーバー名 name = "server${count.index}" # 接続するディスク disks = ["${sakuracloud_disk.disks.*.id[count.index]}"] # タグ(NICの準仮想化モード有効化) tags = ["@virtio-net-pci"] # ルータ+スイッチを接続 base_interface = "${sakuracloud_internet.router.switch_id}" # eth0のIPアドレス/ネットマスク/ゲートウェイ設定 base_nw_ipaddress = "${sakuracloud_internet.router.nw_ipaddresses[count.index]}" base_nw_mask_len = "${sakuracloud_internet.router.nw_mask_len}" base_nw_gateway = "${sakuracloud_internet.router.nw_gateway}" } # ルータ+スイッチ resource "sakuracloud_internet" "router" { name = "router" } #--------------------------------------- # スタートアップスクリプト #--------------------------------------- # DSR方式に対応するための通信設定用スタートアップスクリプト resource "sakuracloud_note" "setup_lb_dsr" { name = "setup_lb_dsr" # VIPを反映したテンプレートの値を参照する content = "${data.template_file.lb_dsr_tmpl.rendered}" } # 割り当てられたVIPをスタートアップスクリプトに反映するためのテンプレート data "template_file" "lb_dsr_tmpl" { template = "${file("setup_lb_dsr.sh")}" vars { # ルータ+スイッチのグローバルIPを参照しテンプレートに渡す vip = "${sakuracloud_internet.router.nw_ipaddresses[3]}" } } # apache(httpd)をインストールするためのスタートアップスクリプト resource "sakuracloud_note" "install_httpd" { name = "install_httpd" content = "${file("install_httpd.sh")}" } #--------------------------------------- # ロードバランサー #--------------------------------------- # ロードバランサー本体 resource "sakuracloud_load_balancer" "lb" { name = "load_balancer" # 接続するルータ+スイッチのID switch_id = "${sakuracloud_internet.router.switch_id}" # VRID(複数のロードバランサーを利用する場合、一意になる値を指定すること) VRID = 1 # IPv4アドレス#1 / ネットマスク / ゲートウェイ ipaddress1 = "${sakuracloud_internet.router.nw_ipaddresses[2]}" nw_mask_len = "${sakuracloud_internet.router.nw_mask_len}" default_route = "${sakuracloud_internet.router.nw_gateway}" } # ロードバランサーのVIP resource "sakuracloud_load_balancer_vip" "vip" { # VIPが紐づくロードバランサのID load_balancer_id = "${sakuracloud_load_balancer.lb.id}" # VIP vip = "${sakuracloud_internet.router.nw_ipaddresses[3]}" # 監視ポート port = 80 } # ロードバランサー配下にサーバーを登録 resource "sakuracloud_load_balancer_server" "servers"{ # 2台分 count = 2 # VIPリソースのID load_balancer_vip_id = "${sakuracloud_load_balancer_vip.vip.id}" # 実サーバーのIPアドレス ipaddress = "${sakuracloud_server.servers.*.base_nw_ipaddress[count.index]}" # 監視設定 check_protocol = "http" check_path = "/" check_status = "200" }
ちょっと複雑になってきましたね。順番に各要素を見てみましょう。
ロードバランサーの定義
ロードバランサーの定義は以下の3つのリソースから構成されています。
- ロードバランサー本体
- VIP
- VIP配下の実サーバー
# ロードバランサー本体 resource "sakuracloud_load_balancer" "lb" { name = "load_balancer" # 接続するルータ+スイッチのID switch_id = "${sakuracloud_internet.router.switch_id}" # VRID(複数のロードバランサーを利用する場合、一意になる値を指定すること) VRID = 1 # IPv4アドレス#1 / ネットマスク / ゲートウェイ ipaddress1 = "${sakuracloud_internet.router.nw_ipaddresses[2]}" nw_mask_len = "${sakuracloud_internet.router.nw_mask_len}" default_route = "${sakuracloud_internet.router.nw_gateway}" } # ロードバランサーのVIP resource "sakuracloud_load_balancer_vip" "vip" { # VIPが紐づくロードバランサのID load_balancer_id = "${sakuracloud_load_balancer.lb.id}" # VIP vip = "${sakuracloud_internet.router.nw_ipaddresses[3]}" # 監視ポート port = 80 } # ロードバランサー配下にサーバーを登録 resource "sakuracloud_load_balancer_server" "servers"{ # 2台分 count = 2 # VIPリソースのID load_balancer_vip_id = "${sakuracloud_load_balancer_vip.vip.id}" # 実サーバーのIPアドレス ipaddress = "${sakuracloud_server.servers.*.base_nw_ipaddress[count.index]}" # 監視設定 check_protocol = "http" check_path = "/" check_status = "200" }
ポイントは、ロードバランサー本体〜VIP〜実サーバーを紐づける部分です。
より下流(子供側)のリソースが上流(親)のIDを持つという形になっています。
各リソースに指定できる値などの詳細は以下のドキュメントを参照してください。
参考:Terraform for さくらのクラウド - 設定リファレンス - ロードバランサー
動的な値を利用できるtemplate_fileリソース
続いて通信設定用のスタートアップスクリプトの定義を見てみましょう。
# DSR方式に対応するための通信設定用スタートアップスクリプト resource "sakuracloud_note" "setup_lb_dsr" { name = "setup_lb_dsr" # VIPを反映したテンプレートの値を参照する content = "${data.template_file.lb_dsr_tmpl.rendered}" } # 割り当てられたVIPをスタートアップスクリプトに反映するためのテンプレート data "template_file" "lb_dsr_tmpl" { template = "${file("setup_lb_dsr.sh")}" vars { # ルータ+スイッチのグローバルIPを参照しテンプレートに渡す vip = "${sakuracloud_internet.router.nw_ipaddresses[3]}" } }
ここではカレントディレクトリに置いた"setup_lb_dsr.sh"というシェルスクリプトをスタートアップスクリプトとして登録する定義を行っています。
"setup_lb_dsr.sh"の中身は以下の通りです。
#!/bin/sh # # @sacloud-once # template_fileリソースの"vars"属性からvip変数を受け取る VIP="${vip}" # VIPに対するARP応答の無効化 echo "net.ipv4.conf.all.arp_ignore = 1" >> /etc/sysctl.conf echo "net.ipv4.conf.all.arp_announce = 2" >> /etc/sysctl.conf sysctl -p 1>/dev/null # VIPをループバックのエイリアスに設定 touch /etc/sysconfig/network-scripts/ifcfg-lo:0 echo "DEVICE=lo:0" > /etc/sysconfig/network-scripts/ifcfg-lo:0 echo "IPADDR=$VIP" >> /etc/sysconfig/network-scripts/ifcfg-lo:0 echo "NETMASK=255.255.255.255" >> /etc/sysconfig/network-scripts/ifcfg-lo:0 ifup lo:0 || exit 1 exit 0
ロードバランサーに割り当てたVIPをサーバー側のループバックのエイリアスに設定する処理を行っています。VIPはルータ+スイッチ作成時に動的に割り当てられるため、template_fileリソースを利用して値の埋め込み/展開を行っています。
参考:Terraform ドキュメント - TEMPLATE PROVIDER
template_fileを利用して動的な値を埋め込むテクニックは色々応用が効きますので是非覚えておきましょう。
まとめ
今回はさくらのクラウド上のネットワーク関連のリソースとして以下のものを扱いました。
- パケットフィルタ
- スイッチ
- ルータ+スイッチ
- ブリッジ
- ロードバランサー
本番運用に耐える高い可用性をもたせつつ柔軟なインフラを構成するために、これらのリソースは大いに役立つと思います。一度手を動かして感覚を掴んでしまえば、あとは設定リファレンスを参考に色々と応用していけると思います。当記事の後は是非設定リファレンスもご一読ください。
参考:Terraform for さくらのクラウド - 設定リファレンス
また、プロビジョニングを行うために以下のリソースについても扱いました。
- スタートアップスクリプト
- template_fileリソース(terraform組み込みリソース)
シェルスクリプトによるサーバーのプロビジョニングに加え、インフラ構築時に動的に割り当てられる値の利用方法についても扱いました。
次回は残りのリソースについて扱った上で、応用編として複数のリージョンにまたがった冗長構成について扱います。お楽しみに!
関連情報: TerraformがArukasに標準対応しました!!

2017年2月のTerraformのリリースでDockerホスティングサービス「Arukas」用のプロバイダーがTerraform本体に組み込まれました!
参考:Terraformドキュメント - Arukas Provider
Arukasについては以下の記事にて紹介されています。
さくらの新サービス??Dockerコンテナホスティングサービス Arukas(アルカス)をご紹介!
このプロバイダーは元々は拙作「Terraform for Arukas」としてリリースしていたものです。Terraform本体への組み込みの際に若干コードの修正を行いましたが、基本的な使い方は「Terraform for Arukas」と同様です。
Terraform + Arukasについても是非お試しください!!
以上です。