1時間で試す!さくらの高火力コンピューティングで深層学習(後編:深層学習実践)

高火力コンピューティングを使って深層学習をできるようになるまでの連載の2回目の記事です。
前編では、プログラムを動かすための様々な環境構築を行いました。
今回は、前回作成した環境で実際に深層学習を行なって、機械学習の"hello world"と呼ばれている手書き文字分類を行います。
手書き文字分類では、下記のような手書き文字の画像データをそれぞれ0から9のどれに該当するかを分類します。

(http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf より引用)
サンプルコードのダウンロードと実行
Kerasのサンプルコードを取得してきます。
$ wget https://raw.githubusercontent.com/fchollet/keras/master/examples/mnist_mlp.py
上のコマンドでダウンロードしたコードは、深層学習の中でもっとも単純な多層パーセプトロンというものを用いて、mnistと呼ばれる0~9の数字を手書きで書いた画像を分類します。
では、とりあえず実際にこのソースコードを実行してみましょう。
$ python mnist_mlp.py
すると、まず、今回使用するネットワークが表示されます。
このテストコードのネットワーク構成は以下のような3層の全結合層のみとなっています。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 512) 401920 _________________________________________________________________ dropout_1 (Dropout) (None, 512) 0 _________________________________________________________________ dense_2 (Dense) (None, 512) 262656 _________________________________________________________________ dropout_2 (Dropout) (None, 512) 0 _________________________________________________________________ dense_3 (Dense) (None, 10) 5130 =================================================================
次に、GPUに関する情報などが出力された後、学習が始まります。
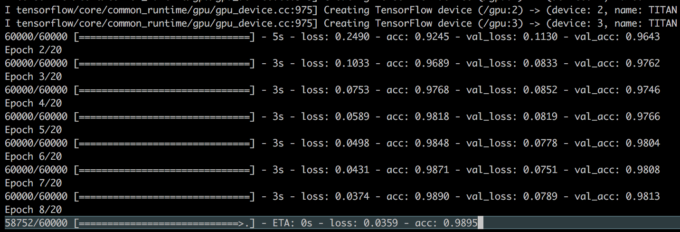
数秒待つと、学習が終わり、最後に精度が出力されます。
私の環境では、以下のようになりました。
Test loss: 0.116450698975 Test accuracy: 0.9839
無事、98%の精度で手書き文字分類できるモデルができました。
サンプルコードの解説
では、実際にこのサンプルコードが何をしているかを見ていきます。
3つのパラメータを定義
batch_size = 128 num_classes = 10 epochs = 20
学習に使うパラメータを定義しています。
- batch_size…1回のミニバッチで学習に使用するデータの数。
- num_classes…クラス数。今回は0~9の10種類の数字を分類するため10。
- epochs…学習を繰り返す回数。
データの読みこみ
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_trainに訓練データ、y_trainにテストデータを、そしてラベルをx_testとy_testに格納します。
データの整形
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
学習に用いるために、データのサイズや型などを揃えています。
ポイントとしては、Kerasでは入力値を0~1の範囲で正規化するので、各RGB値の最大値である255で割っています。
ラベルのベクトル化
y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes)
Kerasでは、ラベルを0~10の数値ではなく、One-hot vectorで表現します。
例えば、3を表したい時は、
[0,0,0,1,0,0,0,0,0,0]
となります。
ここでは、その変換を行う関数を呼び出してラベルを変換しています。
モデルの定義
model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax'))
深層学習を行うネットワークモデルの定義を行なっています。
今回は、多層パーセプトロンですので全結合層のみとなっています。
ちなみに、このコードの次にあるmodel.summary()は、定義したネットワークを出力する関数なので特に深い意味はありません。
モデルの設定
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
ここで、損失関数や最適化アルゴリズムなどを指定して、モデルの設定を完了させています。
学習
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
最後に、fit関数で学習を行います。
終了後、scoreに結果を格納しています。
以上でテストコードの解説は終わりです。
詳細な情報に関しては、Keras公式ページを参照していただければと思います。
速度比較
CPUで実行した場合と高火力コンピューティング環境で実行した場合の実行速度はおおよそ以下のようになっています。
- CPU[corei5 - 2.8GHz]…4分20秒
- GPU[TitanX(Pascal) - 1枚]…1分10秒
今回は、高火力コンピューティング環境のTitanX(Pascal)が4枚搭載されている中で、とりあえず1枚のみを使用しました。
さらに、とても単純な学習で実行時間がもともと長くなかったにも関わらず3分以上の差が出ています。より複雑な深層学習を行うと実行時間にものすごく大きな差が生まれるでしょう。
また、複数枚のGPUを用いて分散処理を行えば、さらなる高速化が可能です。
最後に
2回に渡って行なった高火力コンピューティングのGPUを用いた深層学習はいかがでしたでしょうか。この記事を読んでいただいて、少しでもGPUを用いた深層学習を始めたい方のお役に立てれば幸いです。