CoreOS + etcd + fleetによるクラスタリング事始め
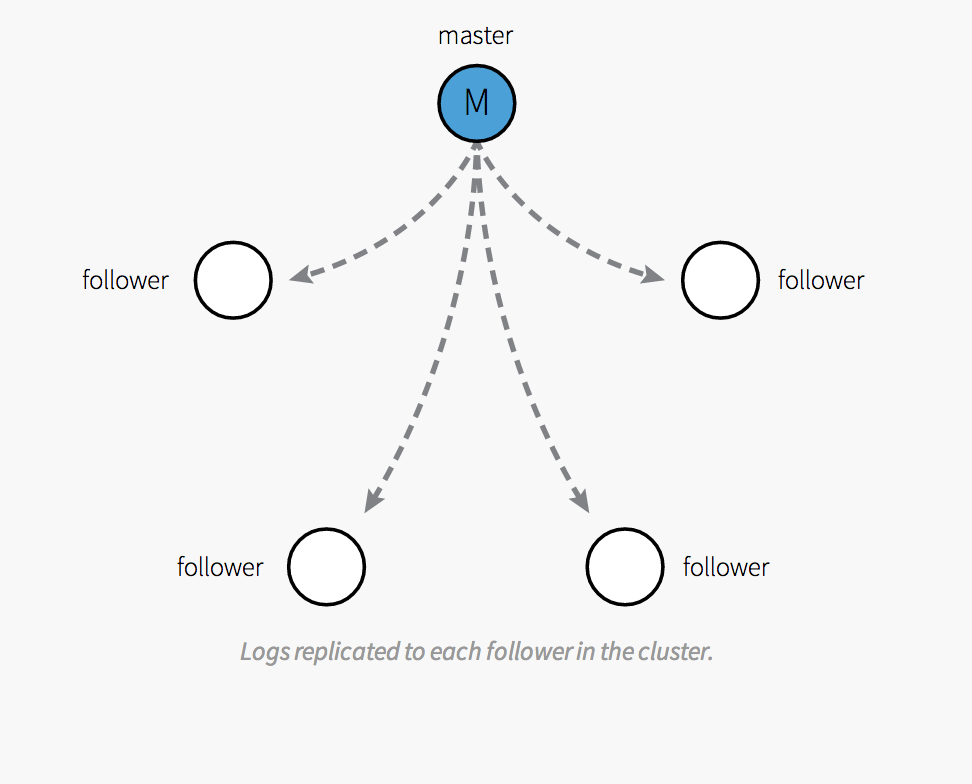
CoreOSはDocker用に作られたとても小さなLinuxディストリビューションです。その中で提供されている大きな3つの機能として、Docker/etcd/fleetが知られています。この3つを組み合わせるとクラスタリング構成がとても簡単に実現できるようになります。
ということでさくらのクラウドを使ってフェイルオーバーする所までをトライしてみます。
目次
サーバを立てる
今回は3台のサーバを立てます。OSは全てCoreOSになります。サーバの追加を行う際にアーカイブ選択で CoreOS 367.1.0 (stable) #112600559854 を選択します。後、今回は管理ユーザのパスワードを入力しています(理由は後述)。複数台のサーバを使いますのでホスト名を忘れずに設定しておきます。
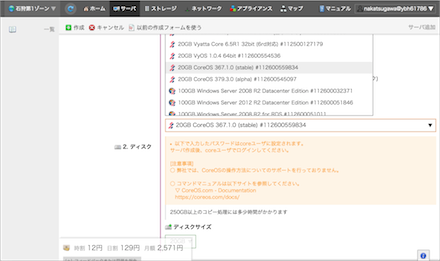
CoreOSの設定
CoreOSはとてもシンプルな作りになっていて、設定ファイルはYAMLで書かれています。パスは /usr/share/oem/cloud-config.yml になります。ファイルを開くと次のように書かれています。
$ cat /usr/share/oem/cloud-config.yml.orig
#cloud-config
coreos:
units:
-
command: restart
name: coreos-setup-environment.service
-
command: restart
name: systemd-networkd.service
-
command: start
content: "[Unit]\nDescription=timezone\n[Service]\nType=oneshot\nRemainAfterExit=yes\nExecStart=/usr/bin/ln -sf ../usr/share/zoneinfo/Japan /etc/localtime\n"
name: timezone.service
hostname: server5
users:
-
name: core
passwd: パスワード
write_files:
-
content: "[Match]\nName=en*\n\n[Network]\nAddress=133.242.241.8/28\nGateway=133.242.241.1\nDNS=133.242.0.3\nDNS=133.242.0.4\n"
path: /etc/systemd/network/10-static.network
公開鍵認証が簡単なのですが、サーバをリブートするタイミングでNICの名前がens3からeth0になってしまう時がありました。そうなるとWebコンソールからでもログインできなくなってしまうので、今回はパスワード認証にしてあります。パスワード認証があればWebコンソールが使えます。
etcdの設定追加
coreos: の下に次のように追記します。
coreos: # ↓ここから追記
etcd:
discovery: https://discovery.etcd.io/<トークン文字列>
addr: 133.242.241.8:4001
peer-addr: 133.242.241.8:7001
このdiscovery/addr/peer-addrというのはコマンドオプションで、
$ sudo etcd -discovery=https://discovery.etcd.io/<トークン文字列> -addr=133.242.241.8:4001 -peer-addr=133.242.241.8:7001
と同じ意味になります。133.242.241.8というのは自分のサーバのIPアドレス、discoveryというのはピア(マシン)を管理するためのURLになります。etcdではディスカバー用のアドレスを発行してくれるサービスがあり、
$ curl https://discovery.etcd.io/new https://discovery.etcd.io/a78dfb4150b64533e0d88e742fe601cf
このように発行されます。自前で立てることもできますが、楽する場合はこちらを使うと良いでしょう。さらに起動時にサービスを開始するための記述をします。
units:
:
-
name: etcd.service
command: start
-
name: fleet.service
command: start
-
name: docker.service
command: start
このように units: 以下に etcd/fleet/dockerの3つのサービスを立ち上げるように記述します。筆者の場合、最終的に次のようになりました。
$ cat /usr/share/oem/cloud-config.yml
#cloud-config
coreos:
etcd:
discovery: https://discovery.etcd.io/<トークン文字列>
addr: 133.242.241.8:4001
peer-addr: 133.242.241.8:7001
units:
-
command: restart
name: coreos-setup-environment.service
-
command: restart
name: systemd-networkd.service
-
command: start
content: "[Unit]\nDescription=timezone\n[Service]\nType=oneshot\nRemainAfterExit=yes\nExecStart=/usr/bin/ln -sf ../usr/share/zoneinfo/Japan /etc/localtime\n"
name: timezone.service
-
name: etcd.service
command: start
-
name: fleet.service
command: start
-
name: docker.service
command: start
hostname: server5
users:
-
name: core
passwd: PASSWORD
write_files:
-
content: "[Match]\nName=et*\n\n[Network]\nAddress=133.242.241.8/28\nGateway=133.242.241.1\nDNS=133.242.0.3\nDNS=133.242.0.4\n"
path: /etc/systemd/network/10-static.network
サーバのIPアドレスなどは読み替えてください。ここまで終わったら、サーバを再起動します。
etcdの状態確認
サーバが再起動するとetcdも自動的に立ち上がっているはずです。fleetでステータスを確認します。
$ fleetctl list-machines -l MACHINE IP METADATA bf3eeb0cd6fa4de5b8ed2a048fb726d4 133.242.241.8 -
他のサーバも立ち上げると、最終的に次のようになります。
$ fleetctl list-machines -l MACHINE IP METADATA 0a16ef2f474d4b7a8e4b44ac8d39b0db 133.242.241.7 - 1fc7499209c64de397aa8e4fdf0c2f0e 133.242.241.9 - bf3eeb0cd6fa4de5b8ed2a048fb726d4 133.242.241.8 -
これで準備は完了です。
ssh-agentの設定
fleetではssh-agentを使って他のマシンに接続します。各マシンに対して公開鍵でSSHログインできるようになっている必要があります。これは通常のsshコマンドで使う秘密鍵のパス(/.ssh/id_rsa)とは別なので注意してください。
$ ssh-agent SSH_AUTH_SOCK=/tmp/ssh-epaP3bSVfXl4/agent.802; export SSH_AUTH_SOCK; SSH_AGENT_PID=803; export SSH_AGENT_PID; echo Agent pid 803;
この出力された内容をそのまま実行します。
$ SSH_AUTH_SOCK=/tmp/ssh-epaP3bSVfXl4/agent.802; export SSH_AUTH_SOCK; $ SSH_AGENT_PID=803; export SSH_AGENT_PID; $ echo Agent pid 803;
そして秘密鍵を登録します。
$ ssh-add ~/.ssh/id_rsa
各サーバに公開鍵が登録してあると、fleetでsshが使えるようになります。ここで接続できない場合は公開鍵が登録されていない可能性があります。
$ fleetctl ssh 1fc7499209c64de397aa8e4fdf0c2f0e Last login: Fri Sep 19 16:53:08 2014 from 133.242.241.7 CoreOS (stable) core@server6 ~ $
これで各サーバ間でサービスが送受信できるようになります。
サービスの登録
fleetは処理内容をサービスという単位で管理します。 /run/fleet/units/ 以下に配置します。下にあるのは例です。まずは初期状態の表示です。
$ fleetctl list-units UNIT LOAD ACTIVE SUB DESC MACHINE
といった感じで何もありません。次にファイルを作成します。この例は一秒毎にHello worldを出力します。
$ cat /run/fleet/units/hello.service [Unit] Description=Hello World [Service] ExecStart=/bin/bash -c "while true; do echo \"Hello, world\"; sleep 1; done"
そしてこれをfleetに登録します。
$ fleetctl submit hello.service
登録が終わるとステータスも変化しています。
$ fleetctl list-units UNIT DSTATE TMACHINE STATE MACHINE ACTIVE hello.service loaded 0a16ef2f.../133.242.241.7 loaded 0a16ef2f.../133.242.241.7 inactive
開始する場合はstart、停止する場合はstopを指定します。
$ fleetctl start hello.service Job hello.service launched on 0a16ef2f.../133.242.241.7 $ fleetctl list-units UNIT DSTATE TMACHINE STATE MACHINE ACTIVE hello.service launched 0a16ef2f.../133.242.241.7 launched 0a16ef2f.../133.242.241.7 active
サービスが開始されたところでステータスを見てみます。
$ fleetctl status hello.service
● hello.service - Hello World
Loaded: loaded (/run/fleet/units/hello.service; linked-runtime)
Active: active (running) since Fri 2014-09-19 11:28:54 JST; 2min 19s ago
Main PID: 667 (bash)
CGroup: /system.slice/hello.service
├─667 /bin/bash -c while true; do echo "Hello, world"; sleep 1; done
└─809 sleep 1
Sep 19 11:31:04 server4 bash[667]: Hello, world
Sep 19 11:31:05 server4 bash[667]: Hello, world
:
Sep 19 11:31:13 server4 bash[667]: Hello, world
ここで、server4とhostnameが出ているのが分かります。
フェイルオーバーを試す
では最後にフェイルオーバーを試してみます。先ほど、サービスを実行していたサーバを落とします。
$ sudo shutdown -h now Connection to 133.242.241.7 closed by remote host. Connection to 133.242.241.7 closed.
マシンの状態を見ても1台、確かになくなっています。
$ fleetctl list-machines -l MACHINE IP METADATA 1fc7499209c64de397aa8e4fdf0c2f0e 133.242.241.9 - bf3eeb0cd6fa4de5b8ed2a048fb726d4 133.242.241.8 -
ではサービスの方はどうかというと、
$ fleetctl status hello.service
● hello.service - Hello World
Loaded: loaded (/run/fleet/units/hello.service; linked-runtime)
Active: active (running) since Fri 2014-09-19 15:22:43 JST; 1min 45s ago
Main PID: 3552 (bash)
CGroup: /system.slice/hello.service
├─3552 /bin/bash -c while true; do echo "Hello, world"; sleep 1; done
└─3668 sleep 1
Sep 19 15:24:19 server6 bash[3552]: Hello, world
:
Sep 19 15:24:28 server6 bash[3552]: Hello, world
となっており、server6に自動的に移って(フェイルオーバーして)継続されているのが分かります。
細かく見てみる
もう少し段階を踏んでみてみます。まずステータスを追いかけるとよく分かります。まずサーバを落とした直後にはそのサービスが一旦消えます。
$ fleetctl status hello.service Job hello.service does not appear to be running.
次に別なサーバで読み込まれます。まだ実行はされていません。
$ fleetctl status hello.service ● hello.service - Hello World Loaded: loaded (/run/fleet/units/hello.service; linked-runtime) Active: inactive (dead)
最後に実行が開始されます。フェイルオーバーが開始してから10秒くらいでサービスが再開するようです。
$ fleetctl status hello.service
● hello.service - Hello World
Loaded: loaded (/run/fleet/units/hello.service; linked-runtime)
Active: active (running) since Fri 2014-09-19 15:26:15 JST; 1s ago
Main PID: 4362 (bash)
CGroup: /system.slice/hello.service
├─4362 /bin/bash -c while true; do echo "Hello, world"; sleep 1; done
└─4368 sleep 1
Sep 19 15:26:15 server5 systemd[1]: Starting Hello World...
Sep 19 15:26:15 server5 systemd[1]: Started Hello World.
Sep 19 15:26:15 server5 bash[4362]: Hello, world
Sep 19 15:26:16 server5 bash[4362]: Hello, world
なお、サーバが復旧した場合でもサービスの実行サーバは移りませんでした。つまり何らかの障害が発生しない限り移譲しないようです。
etcd/fleetがCoreOSに良いわけ
クラスタリングで問題になると思われるのがサーバの環境依存ではないでしょうか。設定がちょっとでも違うと他のサーバに委譲してもうまく動かない可能性があります。その点、CoreOSでDockerを使っている場合、runしたコンテナイメージがなければダウンロードして実行されますので環境を整える必要がほぼありません。
なのでCoreOS上でコマンドを実行すると言うよりも、Dockerコンテナをクラスター環境で使うためにetcd/fleetを使うのが良いのではないでしょうか。
注意点
Dockerコンテナは共通になりますが、コンテナ内で作成したファイルやデータベースなどのデータは個々のコンテナに依存してしまいます。そうならないためにはCoreOS上のボリュームを使って永続化したり、別途クラウドストレージにデータを保存して全てのコンテナで共有する必要があるでしょう。
参考にしたサイト
今回の記事で参考にしたブログなどです。ありがとうございます!
- CoreOS on EC2でDockerコンテナをクラスタリングする | Developers.IO
- coreos/etcd
- fleet で CoreOS + Vagrant の Cluster でフェイルオーバーを確認する - Qiita
- CoreOS + Vagrant に etcd を使ってクラスタを構築する - Qiita
- Panic when running fleetctl status or journal on vagrant coreos · Issue #143 · coreos/fleet
- CoreOS etcd のクラスタとその応用性 - Jedipunkz’s Blog
おしらせ
