つくってみよう!高火力コンピューティングでオリジナルAIサービス(1) ~はじめての画像識別器 編~


さくらインターネットの伊東道明です。
近年、AIを用いたサービスがたくさん出始めており、AIを用いたサービス開発をしたいという人も増えてきています。本連載では、機械学習フレームワークである「Chainer」とPythonのWebフレームワーク「Tornado」を使って、ディープラーニングの手法を用いたWebサービスのつくり方を紹介します。
第1回では、Chainerのインストールからディープラーニングの体験をし、以下のような簡単なシステムを作成します。
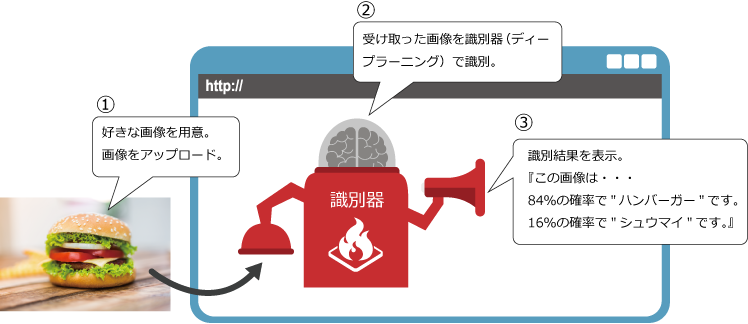

| 第1回 | 画像識別器をダウンロードして使用する |
|---|---|
| 第2回 | 画像識別器を使用したWebサービスを作成する |
| 第3回 | オリジナルの画像識別器を作成し,Webサービスに組み込む |
高火力コンピューティング上で画像識別器を動かすと、より高速に処理できるようになります。本連載では随時その手順についてもご紹介させていただきます。
また、本記事のソースコードは、https://github.com/palloc/AI-WebService/tree/master/source1にまとまっています。
識別器を使う準備
本記事は、Ubuntu16.04、Python2.7.11を想定しています。CPU環境、GPU環境どちらでも実行できるように両方の手順を示すのでGPUはあってもなくても構いません。GPU環境を使いたいという方は、事前にこちらを参考にセットアップしてください。
Chainerのインストール
今回は機械学習フレームワークであるChainerを用いて、出来合いの画像識別器をダウンロードして使用します。
Chainerのインストール自体はとても簡単で、以下のコマンドを打つだけです。
$ sudo pip install chainer
GPU環境の方は、以下のコマンドも打ちましょう。
$ sudo pip install cupy
次に、Chainerの動作確認をするため、サンプルプログラムを動かしてみます。
以下のコマンドでサンプルプログラムの含まれているファイルをダウンロードし、サンプルプログラムのあるディレクトリまで移動します。
$ git clone https://github.com/chainer/chainer.git $ cd chainer/examples/mnist/
では、サンプルプログラムを実行できるか試してみましょう。GPUのないマシンで動かしている方は、以下のコマンドでサンプルプログラムを実行してください。
$ python train_mnist.py
GPU環境が整っているマシンで動かしている方は、以下のコマンドでGPUを使ってサンプルプログラムを実行してください。
$ python train_mnist.py -g 0
しばらく待ってると、以下のように出力するはずです。
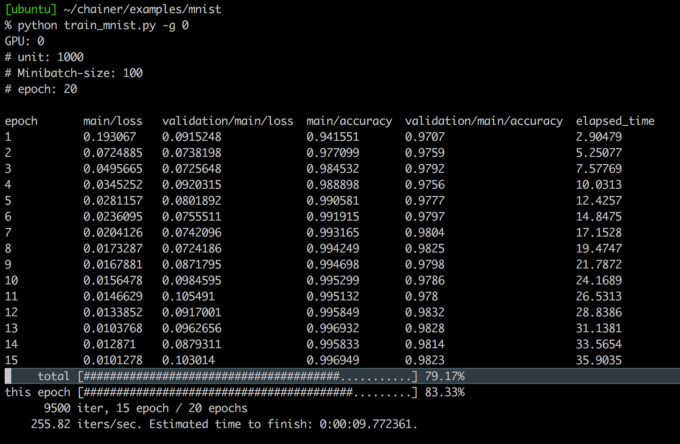

これでChainerが正常に動作していることが確認できました。
学習済みモデルによる画像の識別
では、Chainerを使って画像を識別するプログラムを作りましょう。通常ディープラーニングを用いた画像を識別するプログラムの流れは、以下のようになります。
- コンピュータが学習するための識別器作成用データセットを用意する
- データセットを用いて学習処理を繰り返し、識別器の中核である「モデル」のパラメータを最適な値に近づけていく
- 学習を終えたモデルに、識別したい画像をインプットすると、その画像がなんの画像かを出力する
今回作成するプログラムでは、まずVGG16と呼ばれている学習を既に終えているモデルをダウンロードして使用します。(VGG16は、ImageNetと呼ばれている大量のデータ数を持つ画像データセットを使って学習されたモデルです)
そしてダウンロードしてきたVGG16に自分で用意した画像を入力して画像識別をするという流れになっています。
オリジナルのモデルの作成は、この連載の3回目で行います。
画像処理用の環境セットアップ
まず、画像をPythonで操作するライブラリ「Pillow」をインストールします。
$ sudo pip install pillow
次に、画像とこれから書くプログラムを設置するディレクトリを好きな場所に作成します。作成したディレクトリへ移動したら、作成したプログラムへ入力する画像を事前に取ってきましょう。
今回は、こちらの猫の画像を使用します。


以下のコマンドを実行すると、画像を保存し、保存した画像の名前がcat.jpgになります。
$ wget https://knowledge.sakura.ad.jp/wp-content/uploads/2017/07/cat-1.jpg $ mv cat-1.jpg cat.jpg
この猫の画像をVGG16に入力するのですが、VGG16で識別した後の結果は「1番の確率:10%, 2番の確率:20%...」のように番号で出力されます。そのため、番号が示している画像の種類を知るために「ラベルデータ」と呼ばれる対応表が必要です。
なので、プログラムを作成する前にラベルデータをダウンロードしておきます。
$ wget https://raw.githubusercontent.com/HoldenCaulfieldRye/caffe/master/data/ilsvrc12/synset_words.txt
画像を識別するプログラムの作成
では、プログラムを書いていきます。以下のコードを、「predictor.py」というファイル名で保存して下さい。
# coding: utf-8
import argparse
import time
import chainer
from chainer.links import VGG16Layers
from PIL import Image
model = None
labels = None
def load_model(gpu=-1):
"""
モデルとラベルデータを読み込む関数
"""
global model
global labels
# --gpuオプションの指定状況を得るための引数パーサーを作成
parser = argparse.ArgumentParser(description="識別器")
parser.add_argument("--gpu", "-g", type=int, default=-1)
args = parser.parse_args()
# モデルをロード(初回実行時にダウンロードが発生)
model = VGG16Layers()
# GPUを使う場合の処理
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use()
model.to_gpu()
# ラベルデータの読み込み
label_file = open("synset_words.txt")
labels = map(lambda x: x[10:], label_file.read().split('\n'))[:-1]
def predict_image(image_filename):
"""
画像を識別する関数
"""
load_model()
# 画像とラベルデータの読み込み
img = Image.open(image_filename)
# 画像の識別
pre = model.predict([img])
# 確率トップ5を抽出
pre_data = zip(pre[0].data, labels)
top5 = sorted(pre_data, key=lambda x: -x[0])[:5]
return top5
if __name__ == "__main__":
t1 = time.time()
top5 = predict_image("cat.jpg")
t2 = time.time()
# 結果出力
for i, data in enumerate(top5):
print("{0}。名前:{2} / 確率:{1:.5}%".format(i + 1, data[0] * 100, data[1]))
print("実行時間:{:.3f}秒".format(t2 - t1))
では、実行してみましょう。CPU環境の方は、以下のコマンドを実行してください。
$ python predictor.py
GPU環境の方は、以下のコマンドを実行してください。-gの後の数字は、GPUの番号なので自分の環境にあった数字を入力してください。基本的には0で問題ありません。
$ python predictor.py -g 0
実行すると、入力した画像と似ている分類のトップ5が出力されます。(環境によって結果がやや変わることがあります)
1. 名前:tabby, tabby cat / 確率:58.60% 2. 名前:tiger cat / 確率:24.02% 3. 名前:Egyptian cat / 確率:10.11% 4. 名前:carton / 確率:0.419% 5. 名前:laptop, laptop computer / 確率:0.390%
tabby catの確率が最も高いと言われました。
tabby catと今回入力した猫を比較して見ましょう。


どちらも可愛いですね!
私は猫が大好きですが、あまり詳しくはありません。入力画像の猫がなんの品種なのか、見ただけではわかりませんが・・・tabby catは「トラ猫」のようですね。「トラ猫」で間違いはないと思います。きちんと識別できたということにしましょう。
ということで無事、画像を識別させることができました。ちなみに、この入力した猫は0.39%の確率でlaptop computer(ノートパソコン)らしいです。
実行時間
初回実行時は、モデルをダウンロードしてくるのでCPU, GPUどちらで実行するにも時間がかかります。気長に待ちましょう。ちなみに2回目以降の実行速度を、手持ちのMacBook ProのCPUとさくらの高火力コンピューティングのGPUで比較すると、以下のようになりました。
CPU(Intel Core i5/3.1GHz): 15.8秒 GPU(NVIDIA TITAN X/pascal): 2.8秒
だいぶ差がありますが、何十回も叩かない限りそこまでストレスは感じないレベルですね。最近のCPUはすごいです。
まとめ
今回は、出来合いの画像識別器をダウンロードしてきて、実際に識別させるプログラムを作成しました。次回はこの識別器を使って、画像をアップロードし、なんの画像か識別するWebサービスを作成します。