HAクラスタをDRBDとPacemakerで作ってみよう [DRBD編]

はじめまして、さくらインターネット 技術本部の山野です。
サーバは故障したり障害を起こしたりして停止するものですが、ダウンタイムをより短くしなければならないものが有ります。 そこで、ストレージレプリケーションソフトウェアDRBDと、HAクラスタ管理ツールPacemakerを用いて、1台のサーバが故障しても動き続けるアクティブ/スタンバイ形式のZabbix監視サーバの作成方法をご紹介します。 基本的な構成はLAMP構成ですので、WordPressなど他のLAMP環境にも利用することができます。
試してみる環境
2台のうち、アクティブなホストでのみMySQLや仮想IPアドレスを立ち上げ、サービスを提供する構成を構築します。 MySQLが書き込む /var/lib/mysql はDRBDでスタンバイのホストにレプリケーションし、MySQLや仮想IPアドレス等の起動及び停止の制御をPacemakerで行います。 アクティブなホストが停止した場合は、スタンバイのホストがアクティブに切り替わります。
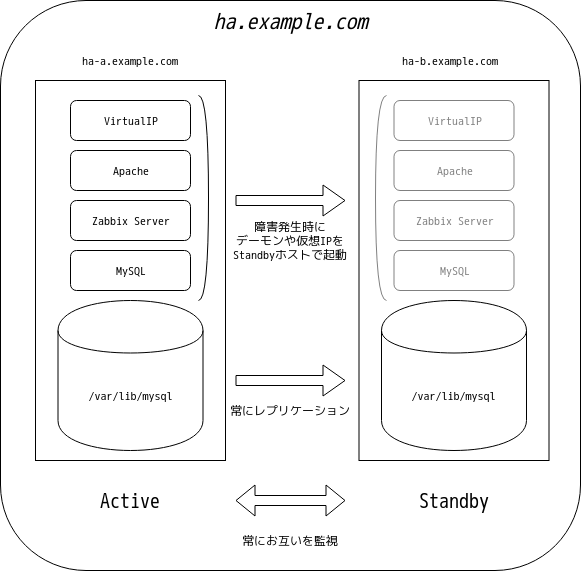
構成するHAクラスタのイメージ
今回は簡単に試せるように、さくらのクラウドと、CentOS7の標準イメージを用いて作成します。 またグローバルIPアドレスはルータ+スイッチの専用セグメントから付与し、DRBDの同期用にスイッチでローカルセグメントを作成します。 IPアドレスやホスト名は、実際の皆さんの環境に合わせて変更してください。
利用するホスト名とIPアドレス
グローバルセグメント ha.example.com a.a.a.a (仮想IPアドレス) ha-a.example.com b.b.b.b ha-b.example.com c.c.c.c ローカルセグメント ha-a-local.example.com 192.168.1.101 ha-b-local.example.com 192.168.1.102

用意するネットワーク
利用するホスト(2VM)
vCPU: 2Core Memory: 4GB OS用Disk: SSDプラン 20GB MySQL用Disk: SSDプラン 100GB グローバルNIC: ルータ+スイッチへ接続 ローカルNIC: スイッチへ接続
なおファイアウォールは、ZabbixのWebUIにアクセスするため 80/TCP を許可し、ローカルセグメントでは全ての通信を許可します。 また今後、特に記載しない限りは、2ホストとも同じ作業を行う必要が有ります。 特定のホストでのみ行う作業は、プロンプトにホスト名を記載します。
# firewall-cmd --permanent --zone public --add-service http success # firewall-cmd --permanent --zone=trusted --change-interface=eth1 The interface is under control of NetworkManager, setting zone to 'internal'. success # firewall-cmd --reload success #
2つ目のディスクである /dev/vdb は、DRBDが利用するパーティションを作成しておきます。
# parted /dev/vdb -s mklabel msdos -s mkpart primary 0% 100%
/etc/hosts を次のとおりに設定しておきます。
# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 a.a.a.a ha ha.example.com b.b.b.b ha-a ha-a.example.com c.c.c.c ha-b ha-b.example.com 192.168.1.101 ha-a-local ha-a-local.example.com 192.168.1.102 ha-b-local ha-b-local.example.com
DRBD
DRBDを利用すると、ネットワーク経由でRAID1のような状態を作成することが可能です。 rsync等のファイルを複製するコマンドとは異なり、DRBDではブロック単位でレプリケーションを行います。 DRBDによって作成されるブロックデバイスにファイルシステムを作成し、読み書きしたいホストでマウントして利用するので、クラスタファイルシステム等を利用しない限り、マウントできるのは1ホストのみとなります。 今回は、MySQLのデータを対向ホストにレプリケーションする用途として利用します。
インストールと設定
kmod-drbd90パッケージをインストールします。
# yum install kmod-drbd90
設定ファイル r0.res でリソースとボリュームを定義します。 リソースはホストやプロトコルなどの設定を行う単位で、実際にレプリケーションされるのがボリュームとなります。 r0(resource0)のvolume0を定義し、DRBDデバイスとして /dev/drbd1 、実際に利用するディスクとして先に作成した /dev/vdb1 を利用するよう設定を行います。 /dev/drbd1に対する書き込みは、ローカルホストの/dev/vdb1と、レプリケーション先のホストの/dev/vdb1に書き込まれることになります。
設定ファイルのホスト名は、uname -nで出力されるものを設定する必要が有りますので、ホスト名とIPアドレス等は適切に書き換えてください。
# cat /etc/drbd.d/r0.res
resource r0 {
volume 0 {
device /dev/drbd1;
disk /dev/vdb1;
meta-disk internal;
}
on ha-a.example.com {
node-id 0;
address ipv4 192.168.1.101:7789;
}
on ha-b.example.com {
node-id 1;
address ipv4 192.168.1.102:7789;
}
}
続いて、DRBDが利用するメタデータを作成し、DRBDを起動させます。
# drbdadm create-md r0 # systemctl start drbd
ha-aとha-bでDRBDを起動させたら、初期同期を実施しておきます。 DRBDはロールを持っており、Primaryロールで読み書きができ、Secondaryロールでは読み込みすら受け付けず、基本的には1つのホストのみがプライマリとして動作します。 設定直後は2ホストともSecondaryですが、特定のホストをPrimaryに昇格することで初期同期を実施することができるので、今回はPrimaryにしたいha-aで次のコマンドを実施します。 drbdadm status コマンドで、ロールやディスクの状態が確認できます。
[root@ha-a ~]# drbdadm primary --force r0
[root@ha-a ~]# drbdadm status r0
r0 role:Primary <- ロール
disk:UpToDate <- ディスク状態
ha-b.example.com role:Secondary <- 対向のロール
replication:SyncSource peer-disk:Inconsistent done:23.80 <- レプリケーション状態, 対向のディスク状態, 同期の完了率
ローカルホストがPrimaryで対向のha-bがSecondaryであること、ローカルホストがSyncSourceであること等がわかります。 またここで表示されるディスク状態は、UpToDateが最新の正常な状態、Inconsistentは不一致の状態です。 初期同期が完了すると、ha-bのディスク状態もUpToDateになります。 これらの詳細な状態は、ドキュメントを参照してください。
DRBD9 と LINSTOR のユーザーズガイド:
https://blog.3ware.co.jp/drbd-users-guide-9.0/ch-admin-manual.html#s-check-status
Primaryロールであるha-aでは、DRBDデバイスのデバイスファイル /dev/drbd1 が作成されるので、このブロックデバイスを利用できます。 通常の外付けHDD等を利用するのと同様に、ファイルシステムを作成しマウントしてみます。
[root@ha-a ~]# mkfs.ext4 /dev/drbd1
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
6553600 inodes, 26213335 blocks
1310666 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2174746624
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
[root@ha-a ~]# mount /dev/drbd1 /mnt
[root@ha-a ~]# touch /mnt/file
[root@ha-a ~]# ls -l /mnt/file
-rw-r--r-- 1 root root 0 9月 11 17:54 /mnt/file
[root@ha-a ~]#
手動でのフェイルオーバー
実際にレプリケーションが行われていることを確かめるため、先ほどha-aで書き込んだファイルがha-bで読めることを確認してみましょう。 ha-aをSecondaryにしなければha-bをPrimaryに変更できないので、アンマウントしてからロールを変更します。
[root@ha-a ~]# umount /dev/drbd1 [root@ha-a ~]# drbdadm secondary r0
続いてha-bでロールをPrimaryに変更しマウントを行い、ファイルが読めることを確認します。 しかし、ha-bのロールをPrimaryに変更する前に、先ほど実施した初期同期が完了している必要が有るので、drbdadm statusコマンドで初期同期の完了を確認してからPrimaryへの昇格を実施します。
同期が実施中の場合
ローカルホストも対向ホストもSecondaryですが、ローカルホストがSyncTargetで同期途中であり、またUpToDateではなくInconsistentのため、まだPrimaryへの変更はできません。
[root@ha-b ~]# drbdadm status r0
r0 role:Secondary <- ロール
disk:Inconsistent <- ディスク状態
ha-a.example.com role:Secondary <- 対向のロール
replication:SyncTarget peer-disk:UpToDate done:21.48 <- レプリケーション状態, 対向のディスク状態, 同期の完了率
[root@ha-b ~]#
同期が完了している場合
ロールの変更とマウントを実施し、ファイルを確認してみます。
[root@ha-b ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
ha-a.example.com role:Secondary
peer-disk:UpToDate
[root@ha-b ~]# drbdadm primary r0
[root@ha-b ~]# mount /dev/drbd1 /mnt
[root@ha-b ~]# ls -l /mnt/file
-rw-r--r-- 1 root root 0 9月 11 17:54 /mnt/file
[root@ha-b ~]#
電源断でのフェイルオーバー
今度は実際の障害を想定して、ha-bでファイルのタイムスタンプを更新したあと、ha-bを強制停止し、ha-aで状態を確認してみましょう。
[root@ha-b ~]# touch /mnt/file [root@ha-b ~]# ls -l /mnt/file -rw-r--r-- 1 root root 0 9月 18 19:39 /mnt/file [root@ha-b ~]#
この状態で、クラウドのコントロールパネルから、ha-bを強制停止します。 すると、ha-aからha-bの状態が見れなくなるので、ha-aをPrimaryに変更してマウントし、タイムスタンプが変更されていることを確認します。 また不要なファイルを削除しておきます。
[root@ha-a ~]# drbdadm status r0 r0 role:Secondary disk:UpToDate ha-b.example.com connection:Connecting <- 対向と接続しようとしている [root@ha-a ~]# drbdadm primary r0 [root@ha-a ~]# mount /dev/drbd1 /mnt [root@ha-a ~]# ls -l /mnt 合計 16 -rw-r--r-- 1 root root 0 9月 18 19:39 file <- きちんとタイムスタンプが更新されている drwx------ 2 root root 16384 9月 18 19:15 lost+found [root@ha-a ~]# rm /mnt/file rm: 通常の空ファイル `/mnt/file' を削除しますか? y [root@ha-a ~]# rm -rf /mnt/lost+found
正しくDRBDでレプリケーションができていることが確認できたので、ha-bを起動させ、正常な状態に戻しておきます。 またha-bを起動させた直後は、変更が行われていた部分を同期するため、一時的にディスクがInconsistentとなります。
[root@ha-b ~]# systemctl start drbd
[root@ha-b ~]# drbdadm status r0
r0 role:Secondary
disk:Inconsistent
ha-a.example.com role:Primary
replication:SyncTarget peer-disk:UpToDate done:98.94
[root@ha-b ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
ha-a.example.com role:Primary
peer-disk:UpToDate
[root@ha-b ~]#
DRBDのレプリケーションと同期について
これまでの説明の中でレプリケーションと同期(シンク)という言葉を用いてきましたが、この2つは異なる意味を持ちます。 レプリケーションは、プライマリロールのDRBDデバイスに対する書き込み順に、対向ホストに書き込みが実施されます。 同期は、レプリケーションが中断されていた場合に、変更点をリニアに(書き込み順を無視して)対向ホストに書き込みます。 そのため同期は高速に動作しますが、同期先はディスクの一貫性が無いInconsistent状態となり、基本的にはそのまま利用できない状態となります。
つまり、ha-bが障害などから復旧し同期先となる場合、同期中のha-bのディスクはInconsistent状態とるので、この時にha-aが障害を起こした場合は、ha-aの復旧を待つ必要が発生します。 またもちろんですが、ha-aの障害原因がディスク故障などの場合は、ha-bからデータを復旧することが非常に困難になります。 このような事態を避けるためには、DRBDが利用するディスクをLVMとし、DRBDの同期を開始する前に、同期先のha-bでスナップショットを取得しておくなどの工夫が必要です。 スナップショットを取得しておけば、同期中にha-aがディスク故障などでデータを読み取れない状態となっても、ha-bのスナップショットを用いて、ha-bが障害を起こす直前(レプリケーションが途絶えた時点)に復旧させることが可能です。
ここまででできること
今回は、構成の大まかな説明とDRBDの設定を行いました。
ここまでの作業でもホストが故障した際に、IPアドレスやDRBD等を手動で操作することでサービスを継続したり、アクティブなサーバのディスクが故障した際に、スタンバイのサーバからデータを復旧したりすることができます。 ただし、DRBDの扱いを間違えるとデータを消失することにつながるので、ドキュメント等を参考にして十分に注意する必要が有ります。 また今回は、最終的にPacemakerでDRBDの起動を行う予定のため、本記事ではDRBDを自動起動しないようにしていることも注意が必要です。
次回はLAMP構成を構築したうえで、仮想IPアドレス設定とフェイルオーバーを自動化するPacemakerを導入し、自動的に切り替えが行われる構成を構築します。