開発ツール(QEMU)への貢献(前半) 〜自作OSのいまと昔 [第3回]

これまでの記事では、自作OSとそれを取り巻く状況について触れてきましたが、今回と次回は少し視点を変えて、自作OS開発で使うツールのデバッグや、それを通した貢献(contribute)の話をしたいと思います。
自作OSに限らず何かを開発する際には、たいていの場合、他の誰かが作ったツールを利用することになります。たとえば、CコンパイラとしてのClangや、デバッグのためのエミュレータとしてのQEMU, CやC++の標準ライブラリとしてのNewlibやlibc++などを、私の自作OS liumOS では利用しています。これらのソフトウエアは、ソースコードが公開されており、インターネット上の誰もが開発に参加することが可能です。
QEMU上で起動するliumOS
これらの開発ツールは、世界中のたくさんのユーザーに利用されるうちに、バグが見つかったり機能追加のリクエストが来たりすることで、完成度が次第に高まってきます。しかし、多くの人が使う機能に関するバグは気付かれやすい一方、あまり使われない機能に関してはバグが残っていたり、そもそも実装が不足していたりすることがあるのも現状です。
自作OSをしていると、そういった開発ツールの穴を見つけてしまうことが多々あります。というのも、自作OSをしている人は、一般ユーザーがあまり利用しなかったり、仕様書の上では実装されていても、広く使われているソフトウエアでは使われていなかったりするような機能を使ってしまうことが多々あるからです。
そのような穴を見つけた際に、自分の書いているソフトウエアの側でその問題を回避するようにコードを変更することもできますが、せっかく見つけてしまった穴があるなら、それを埋めてあげたいと思うのが開発者としての良心だと私は思っています。
ということで、ここからは私が最近見つけたQEMUのバグについて、それに気づいてからデバッグを行い、コードの修正提案であるパッチを投げるまでの流れをまとめてみました。早速いってみましょう!
面倒はバグのはじまり
それは、いつものliumOS開発中に起きました。QEMUで自分の作ったOSを起動してから、いつも面倒なのでCtrl-Cでqemuを終了させていたのですが、ある日から突然、qemuを終了させた直後に以下のメッセージが表示されるようになってしまいました。
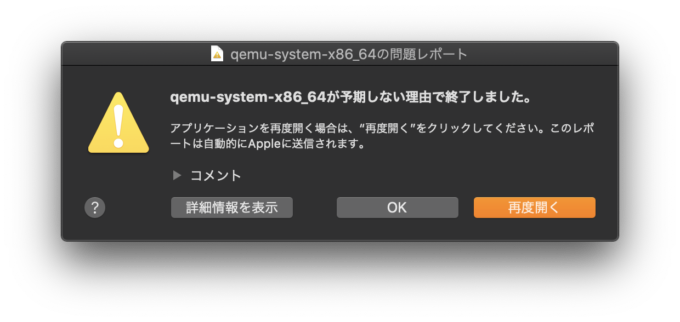
QEMUの異常終了を知らせるメッセージ
このメッセージは、QEMUを終了させる度に毎回出てきて、そのたびに「OK」のボタンを押さないと消すことができません。これを表示しているのはどうやら開発マシンのmacOSのようですが、これを出さないように設定する方法も見つかりませんでした。なんとも鬱陶しいですね。
また、ターミナルのほうにも、以下のようなエラーメッセージが出ていることに気付きました。
make: *** [run] Segmentation fault: 11
私はいつもQEMUの最新版を自分でビルドして使っていたので、きっと誰かが開発中にバグを入れ込んでしまっただけで、そのうち誰かが直してくれるだろうと思い最初は無視していたのですが、どうも治る気配がありません。さすがに毎回このウィンドウを閉じていては自作OS開発に集中できずストレスが溜まりつつありました。
でも、逆に考えればこれはチャンスです。このバグを修正すれば、少なくとも私はとても嬉しいですし、きっと他に自作OS開発でQEMUを使っている人も助かるはずです。それならバグを修正してやろう!という意気込みで、原因調査の旅が始まりました。
バグの原因を特定する
さて、先ほどから私はこの問題をQEMUのバグだ!と言い続けてきたわけですが、この段階ではまだ直感であって、明確な根拠があるわけではありません。もしかすると、QEMUは濡れ衣を着せられていただけであって、OSや、はたまた私の自作OSが悪さをしている可能性だってあります。さらには、どれか一つの要素が悪いというわけではなく、複合的な要因で問題が起きていることも現実には多々あります。そのような状況下で、本当にバグを直したいならば、まずは「正しく動くとき」と「正しく動かないとき」の差をはっきりさせることが大切です。
今回は、以下のような手順を踏んで、このバグの「生態」を調べることにしました。
QEMUを最新の開発版にする
ソフトウエアの世界における時間の流れはとても速いので、もしかするとこのバグの修正コード(パッチ)を、世界のどこかにいる誰かがすでに出しているかもしれません。ということで、まずは最新の開発版を取得してきて、現象が再現するか否かを確かめます。
QEMUはgitを用いてソースコードが管理されているため、その最新版をcloneしてきてビルドします。GitHubにもミラーがあるので、どちらか好きなほうを使うとよいでしょう(私はいつもミラーの方を使っています)。このときの最新のコミットハッシュは42ccca1bd9456568f996d5646b2001faac96944bでしたが、残念ながらこれをビルドしてインストールしてみても、状況は変わりませんでした。
それっぽいバグがすでに報告されていないか調べる
バグが修正されてはいなくても、すでに同じような問題が報告されていて、誰かが解決策の方針を見つけ出していたり、パッチを書き始めているかもしれません。もしそうなら、これからやろうとしている作業が二度手間になってしまうかもしれませんし、もしかするともっと早くパッチを書けるヒントが見つかるかもしれません。
QEMUのバグ報告はlaunchpad.netというサイトで管理されています。というわけで、ここで同じような問題が報告されていないかを、「予期しない理由で終了しました」というメッセージや、OSなどの環境をキーワードとして調べてみます。(ここでは英語で会話が行われているので、エラーメッセージなどは英語にして検索します)
もちろん、ないことの証明は悪魔の証明なので困難ですが、今回の場合数分間調べてみて、どうやらこの問題は誰も報告していなさそうだ、ということがわかりました。残念…。とはいえ、まだ誰も報告していないということは、それはつまり自分でバグを調査し、そしてパッチを書くいい機会だということです!前向きに考えていきましょう。
最小ケースを見つけ出す
自分の手でバグを修正するんだ!と決めたら、次にやることはもう決まっています。それは、バグが再現する最小ケースを見つけ出すことです。現時点では、私のOSでmake runと実行して起動したqemuにおいて、このバグが発生する、ということがわかっていますが、これだけでは情報が大雑把すぎます。まずは、qemuがどのような引数で実行されているのかを知り、その引数をどんどん削っていって、問題が発生しなくなるケースをみつけることができれば、その引数が悪さをしているとわかり、問題解決に一歩近づけます。
makeが実際に実行するコマンド列は、makeに対して-nオプションを与えることで知ることができます。
$ make -n run make -C src make -C app/hello/ make -C app/pi/ make -C src LIUMOS.ELF mkdir -p mnt/ rm -r mnt/* mkdir -p mnt/EFI/BOOT cp src/BOOTX64.EFI mnt/EFI/BOOT/ cp dist/* mnt/ cp app/hello/hello.bin app/pi/pi.bin mnt/ cp src/LIUMOS.ELF mnt/LIUMOS.ELF qemu-system-x86_64 -bios ovmf/bios64.bin -machine q35,nvdimm -cpu qemu64 -smp 4 \ -monitor stdio -monitor telnet:127.0.0.1:1240,server,nowait \ -m 8G,slots=2,maxmem=10G -drive format=raw,file=fat:rw:mnt \ -net none -serial tcp::1234,server,nowait \ -serial tcp::1235,server,nowait \ -device qemu-xhci -device usb-mouse \ -object memory-backend-file,id=mem1,share=on,mem-path=pmem.img,size=2G \ -device nvdimm,id=nvdimm1,memdev=mem1
最後の一行がqemuの引数ですが、とんでもなく長いですね…。(長すぎるので折り返しています)ひとつずつ削っていって試してもよいのですが、まずは引数を全部消した状態で、問題が解決するかどうかを試してみます。
$ qemu-system-x86_64 ; echo $? ^Cqemu-system-x86_64: terminating on signal 2 from pid 8528 (<unknown process>) 0
Ctrl-Cで終了させてみると…お、正常に終了するようですね!あの「予期しない理由で終了しました」という鬱陶しいエラーも出てきません。
ということで、どうやらこのバグは、コマンドライン引数に依存して、発生したりしなかったりする、ということがわかりました。一歩前進です!
その後、引数をどんどん削っては実行してみて、ついに以下のようなケースでバグが発生する、というところまで最小化することに成功しました!
$ qemu-system-x86_64 -drive format=raw,file=fat:rw:mnt ; echo $? ^Cqemu-system-x86_64: terminating on signal 2 from pid 8528 (<unknown process>) Segmentation fault: 11 139
つまるところ、この-drive format=raw,file=fat:rw:mntという引数がついていると、QEMUの終了時に何かバグが発生するようです。だんだん怪しいところが絞れてきましたね!
ちなみにこのオプションがどのような働きをするかというと、カレントディレクトリにあるmntディレクトリの内容を、FATファイルシステムでフォーマットされたドライブとしてゲストに見せるよう、QEMUに指示しています。UEFIはFATフォーマットされたドライブの内容を読んでOSのローダを起動してくれるので、この仮想FATドライブ機能を使うことにより、毎回ディスクイメージを作成しなくてもliumOSのデバッグができて便利なため、この機能を使っているのでした。
Segmentation faultが発生した場所をデバッガで調べる
これまでの異常終了時に出ていたメッセージをよく見てみると、どうやらSegmentation faultが発生してプログラムが落ちているようだ、ということがわかります。
先ほどまで「鬱陶しい」と言っていたあのエラーメッセージでも、詳細情報を開いてみるとEXC_BAD_ACCESS (SIGSEGV)と出ていることが確認できます。(SIGSEGVは、Segmentation faultが発生した際にOSがアプリケーションに送るシグナルの名前です)
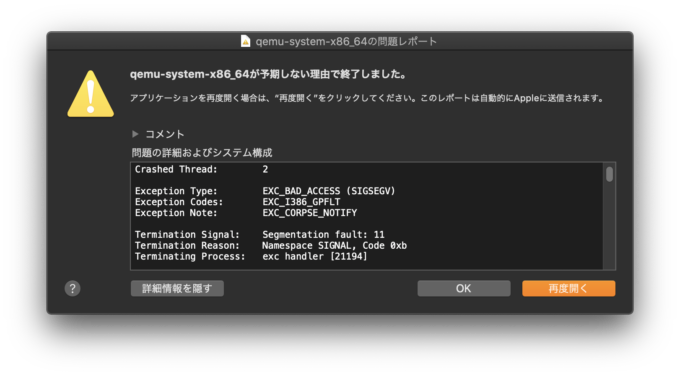
エラーメッセージの詳細情報
Segmentation faultというのは、OSがアプリケーションの不正なメモリアクセスを検出した、というエラーです。「不正なメモリアクセス」といっても実際には色々あるのですが、少なくともアプリケーションがOSの許していない挙動をしたので止めたよ、ということを意味しています。
そう考えると、少なくともアプリケーションのどこかの命令が、変なメモリアクセスを起こしてSEGVを起こしている、ということがわかります。ということで、まずはこの命令が何なのかを特定しましょう。
というわけで、早速デバッガをつないで…とやってもよいのですが、現在実行しているQEMUはデバッグ情報なしでビルドしたものになっているので、デバッガをつないでSEGVを起こした箇所を特定しても、その地点の逆アセンブルした結果はみることができますが、ソースコード上の対応した位置を知ることはできません。みなさんの多くはアセンブリ言語よりもC言語のほうが読みやすいと思うので、まずはqemuをデバッグ情報つきでビルドしなおします。以下のようにconfigureしてから make && make install しなおせば、デバッグ情報付きのQEMUができあがります。
./configure --target-list=x86_64-softmmu --enable-debug
それでは、このデバッグ情報つきのQEMUで先ほどの最小ケースを実行してみて、そこにデバッガをつないでみましょう。今回はmacOS上で作業しているので、LLVMツールチェインのデバッガ lldb を使用します。
まずは、先ほど特定した、バグの発生する最小ケースを実行してみます。
qemu-system-x86_64 -drive format=raw,file=fat:rw:mnt
次に、別のターミナルを開いて、デバッガを起動します。
$ lldb (lldb)
そして、すでに起動してあるQEMUにデバッガを接続(attach)します。attachする対象はプロセスID(pid)でも名前でも指定できますが、今回は簡単なので名前で指定します。(他にqemuを同時に走らせている場合は、pidを調べて指定しましょう)
(lldb) attach --name qemu-system-x86_64 Process 27815 stopped * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGSTOP frame #0: 0x00007fff738b725a libsystem_kernel.dylib`mach_msg_trap + 10 libsystem_kernel.dylib`mach_msg_trap: -> 0x7fff738b725a <+10>: retq 0x7fff738b725b <+11>: nop libsystem_kernel.dylib`mach_msg_overwrite_trap: 0x7fff738b725c <+0>: movq %rcx, %r10 0x7fff738b725f <+3>: movl $0x1000020, %eax ; imm = 0x1000020 Target 0: (qemu-system-x86_64) stopped. Executable module set to "/usr/local/bin/qemu-system-x86_64". Architecture set to: x86_64h-apple-macosx-.
attachすると対象のアプリケーションは一時停止されてしまいますが、とりあえず実行を再開したいのでcontinueコマンドで実行を再開します。(cと短縮して入力することができます)
(lldb) c Process 27815 resuming
さて、これでQEMUにデバッガがつながりました。早速最初のターミナルに戻ってCtrl-Cでqemuを終了してみましょう。すると、lldbの画面に変化が起きます。
Process 27815 stopped * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGINT frame #0: 0x00007fff738b725a libsystem_kernel.dylib`mach_msg_trap + 10 libsystem_kernel.dylib`mach_msg_trap: -> 0x7fff738b725a <+10>: retq 0x7fff738b725b <+11>: nop libsystem_kernel.dylib`mach_msg_overwrite_trap: 0x7fff738b725c <+0>: movq %rcx, %r10 0x7fff738b725f <+3>: movl $0x1000020, %eax ; imm = 0x1000020 Target 0: (qemu-system-x86_64) stopped.
これがエラーの起きた箇所か!?と思うかもしれませんが、残念ながら違います。というのも、上の方にstop reason = signal SIGINTと出ているからです。SIGINTは、Ctrl-Cなどでアプリケーションを終了させようとしたときにアプリケーションに送信されるシグナルの名前です。というわけで、これはCtrl-Cを押したからSIGINTが発生したのをデバッガが捕まえてしまっただけです。(デバッガはアプリケーションがシグナルを受け取った時も停止してくれるのです)
ではこのままcontinueすればよいかというと、なんとlldbはシグナルを握り潰してアプリケーションに伝えずに再開してしまいます。ですから、以下のようにしてLLDBに「SIGINTを受信した際は、デバッガを止めずに(-s false)直接アプリケーションに渡してあげてくださいね(-p true)」と指定してからcontinueします。
(lldb) process handle SIGINT -s false -p true NAME PASS STOP NOTIFY =========== ===== ===== ====== SIGINT true true true (lldb) c Process 27815 resuming
するとまたまたアプリケーションが停止します。
Process 27815 stopped * thread #3, stop reason = signal SIGUSR2 frame #0: 0x00007fff738d73b2 libsystem_kernel.dylib`__sigsuspend + 10 libsystem_kernel.dylib`__sigsuspend: -> 0x7fff738d73b2 <+10>: jae 0x7fff738d73bc ; <+20> 0x7fff738d73b4 <+12>: movq %rax, %rdi 0x7fff738d73b7 <+15>: jmp 0x7fff738b868d ; cerror 0x7fff738d73bc <+20>: retq Target 0: (qemu-system-x86_64) stopped.
今度はSIGUSR2ですね。SIGUSR1とSIGUSR2はアプリケーションが自由に使えるシグナルなので、これもバグには関係なさそうです。また無視するように設定してcontinueしましょう。
(lldb) process handle SIGUSR2 -s false -p true (lldb) c
するとまたもや停止しますが、おやおや、stop reason = EXC_BAD_ACCESSですね。どうやらこの行が「不正なアクセス」を発生させているようです!
Process 27815 stopped
* thread #3, stop reason = EXC_BAD_ACCESS (code=1, address=0x1178)
frame #0: 0x00000001061873d7 qemu-system-x86_64`bdrv_unset_inherits_from(root=0x00007f88e1874600, child=0x00007f88e1525bc0) at block.c:2530:20
2527 {
2528 BdrvChild *c;
2529
-> 2530 if (child->bs->inherits_from == root) {
2531 /*
2532 * Remove inherits_from only when the last reference between root and
2533 * child->bs goes away.
Target 0: (qemu-system-x86_64) stopped.
やった!ついにEXC_BAD_ACCESSを引き起こす直接の原因を見つけることができましたね。…「直接」の原因は、ですが。
なぜSEGVが起きているのかを調べる
ではもう少し詳しく、先ほどのデバッガの出力をみてみましょう。どうやら怪しい行はここのようです。デバッグ情報つきなのでソースコードが出ていて、人間にやさしいですね。
-> 2530 if (child->bs->inherits_from == root) {
ちなみにこの行がどの関数の中身で、どのような引数で呼ばれているのかは、ここに書かれています。
frame #0: 0x00000001061873d7 qemu-system-x86_64`bdrv_unset_inherits_from(root=0x00007f88e1874600, child=0x00007f88e1525bc0) at block.c:2530:20
これによれば、SEGVが起きたのはblock.cの2530行目で、bdrv_unset_inherits_fromという関数の中のようです。
さらに、この行の情報も重要です。
* thread #3, stop reason = EXC_BAD_ACCESS (code=1, address=0x1178)
ここに出ているEXC_BAD_ACCESSというのは、先ほども説明した通り、アプケーションが「不正なメモリアクセス」をしたことを意味しています。その後ろのcodeは、より詳しい原因を示しており、addressはその「不正なメモリアクセス」で参照しようとしたアドレスの値を示しています。
codeの番号とその内容の対応については、macOSのSDKがインストールされている場合、バージョンによって異なりますが以下のようなパスにヘッダファイルとして記載されています。
/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Kernel.framework/Versions/A/Headers/mach/kern_return.h
また、macOSのカーネルXNUのソースコードはWeb上で公開されているため、そこから参照することも可能です。ということで見てみると、code=1は以下のような説明になっています。
#define KERN_INVALID_ADDRESS 1 /* Specified address is not currently valid. */
…はい、まあ「無効なアドレス」にアクセスしたってことですね。要するに、ふつうのSEGVのようです。
codeのほうはこれ以上の情報はなさそうなので、アドレスのほうも見てみましょう。address=0x1178…たしかに、なんともアクセスできなさそうな、低位のアドレスですね。では、どのようにしてこの謎のアドレスが生成されているのか確認してみましょう。
デバッガのprintコマンド(ここではpと省略しています)を使うと、通常のC言語のような書き方で、アプリケーションの実際の値を表示してみることができます。child->bs->inherits_fromという参照がいかにも怪しいですから、これを表示させてみましょう。
(lldb) p child (BdrvChild *) $0 = 0x00007f88e1525bc0 (lldb) p child->bs (BlockDriverState *) $1 = 0x0000000000000000 (lldb) p child->bs->inherits_from error: Couldn't apply expression side effects : Couldn't dematerialize a result variable: couldn't read its memory (lldb) p &child->bs->inherits_from (BlockDriverState **) $3 = 0x0000000000001178
なるほど、child->bsがNULLポインタになっていて、そのメンバinherits_fromにアクセスしようとした結果、先ほどのアドレスが生成されたようです。つまるところ、child->bsがNULLポインタになっているのが元凶のようです。
再現性があるかを確認する
ここまでで
- block.cの2530行目、bdrv_unset_inherits_fromという関数の中で
- child->bsがNULLポインタとなっているために
- child->bs->inherits_fromへのアクセスがSEGVを引き起こしている
ということがわかりました。しかし、これは「今回の実行では偶然こうだった」という一例でしかありません。アプリケーションの規模が大きくなるほど、メモリの確保や解放、さまざまなタイミングの問題、同期処理などの兼ね合いで、実行するごとにバグの発生する箇所が違ったりする場合は多々あります。ということで、何度か先ほどの手順を繰り返してみて、本当にここまでの解釈が正しいかどうかを確認してみましょう。
さきほどは説明の意味も込めて、デバッガでのプロセスへのattachやシグナルの無視を行う設定を逐一行いましたが、何度も繰り返す際は面倒なのでスクリプト化しておくと楽です。まず、以下のような内容のテキストファイルlldb_cmd.txtを作成します。
process launch --tty -s -- -drive format=raw,file=fat:rw:mnt process handle -s false -p true SIGINT process handle -s false -p true SIGUSR2 process handle -s false -p true SIGHUP process handle -s false -p true SIGCONT c
最初のprocess launchは、起動時の引数などを設定するコマンドです。また、いくつかのシグナル(SIGHUPとSIGCONT)も追加で無視するコマンドを書き足しています。そして、このファイルをlldbの起動時に-sオプションで渡してあげれば、今度はlldbを起動するだけでqemuも自動的に起動し、デバッガがアタッチされた状態になります。
lldb -s lldb_cmd.txt qemu-system-x86_64
実際にこのコマンドを実行してみた状況がこちらです。左側のターミナルがデバッガの画面、右上のターミナルと右下のウィンドウはデバッグ対象としてlldbによって自動的に起動されたものです。

lldbからQEMUを起動してみた図
さて、ここでデバッグ対象のターミナルを選択してから、Ctrl-CでQEMUを終了させてみましょう。すると…?
* thread #3, stop reason = EXC_BAD_ACCESS (code=EXC_I386_GPFLT)
frame #0: 0x0000000109b443d7 qemu-system-x86_64`bdrv_unset_inherits_from(root=0x00007f8058875600, child=0x00007f8058600e40) at block.c:2530:20
2527 {
2528 BdrvChild *c;
2529
-> 2530 if (child->bs->inherits_from == root) {
2531 /*
2532 * Remove inherits_from only when the last reference between root and
2533 * child->bs goes away.
Target 0: (qemu-system-x86_64) stopped.
また同じ場所で止まりましたね…ってあれ?この行をよく見てください。
* thread #3, stop reason = EXC_BAD_ACCESS (code=EXC_I386_GPFLT)
さきほどはcode=1だったのに、今度はcode=EXC_I386_GPFLTになってますね。しかもアドレスが表示されていません。一体どういうことでしょうか。`child->bs`の値も確認してみましょう。
(lldb) p child->bs (BlockDriverState *) $0 = 0x400007f805860037
おやおや、今度はchild->bsがNULLではなく、謎の値になっています。しかもこの値は…Non-canonicalですね。
Non-canonical address
x86_64 CPUの64bitモードにおいては、実はすべての64bit整数値がアドレスとして有効なわけではありません。Intel SDMのVol.1には、以下のように書かれています。
3.3.7.1 Canonical Addressing
In 64-bit mode, an address is considered to be in canonical form if address bits 63 through to the most-significant implemented bit by the microarchitecture are set to either all ones or all zeros.
これだけ言われても何が何だかわかりませんね。とりあえず、アドレスにはcanonicalなものと、そうでないものがあるようです。(canonicalというのは、なんらかの規則に沿ったものである、という意味の形容詞です)
次のところを読んでみましょう。
Intel 64 architecture defines a 64-bit linear address. Implementations can support less. The first implementation of IA-32 processors with Intel 64 architecture supports a 48-bit linear address. This means a canonical address must have bits 63 through 48 set to zeros or ones (depending on whether bit 47 is a zero or one).
具体例が出てきました。なるほど、Intel64アーキテクチャ(x86_64)は、64bitのリニアアドレスを定義しているが、実装としてはもっと少ないビット数でもよく、たとえば初期のIntel64アーキテクチャでは48bitのリニアアドレスをサポートしているので、canonicalなアドレスはbit63からbit48までが、bit47の値に従って、すべて0か1である必要がある、と言っているようです。
If a linear-memory reference is not in canonical form, the implementation should generate an exception. In most cases, a general-protection exception (#GP) is generated.
さらに、もしこの規則に沿っていない、つまりnon-canonicalなメモリアドレスに対する参照が行われた場合は、例外が発生し、多くのケースではそれはgeneral-protection exceptionを引き起こす(先ほどのEXC_I386_GPFLTがこれにあたる)と言っています。
ちょっと図を用いて整理してみましょう。例に示されている通り、48bitのリニアアドレスが実装されている場合を考えます。
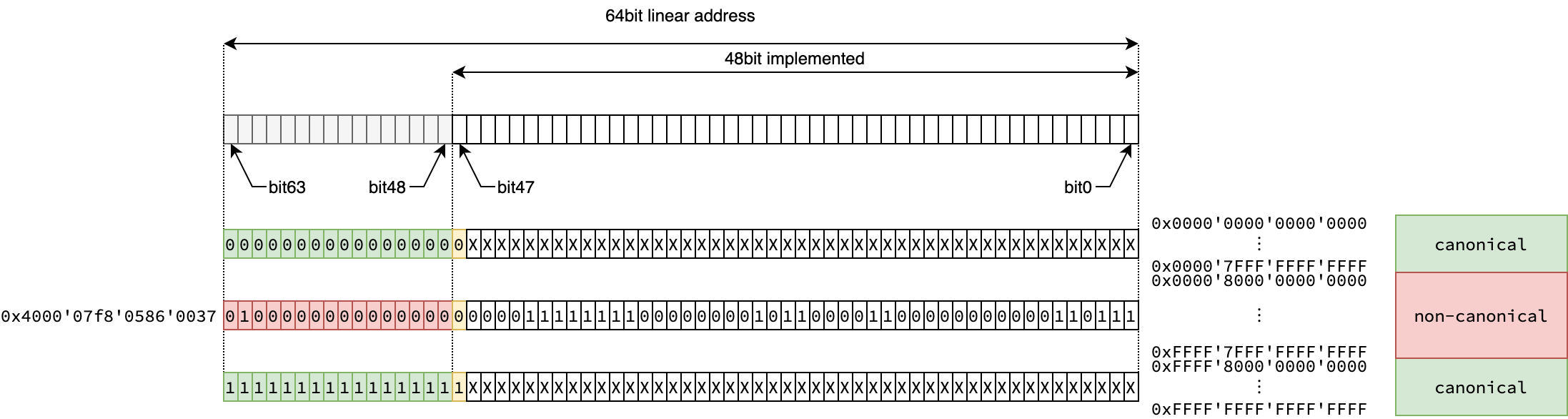
Canonical address
リニアアドレスとしては64bitの幅がありますが、実際に実装されているのはbit0からbit47までの48ビットだけです。そのため、実装されているアドレスの最上位のビット(bit47)で、実装されていないビット(bit48から63)が埋めてあれば、それはcanonicalなアドレス(緑色)であり、そうでない場合(赤色)はnon-canonicalなアドレスである、ということがこの説明の主旨です。具体的にいえば、0x0000'0000'0000'0000以上0x0000'7FFF'FFFF'FFFF以下、もしくは0xFFFF'8000'0000'0000以上0xFFFF'FFFF'FFFF'FFFF以下のアドレスはcanonicalですが、それ以外のアドレス、たとえばさきほどの0x400007f805860037などは、non-canonicalなアドレスとなり、アクセスしようとするとCPUが例外を発生させます。
さて、本来ポインタが入っているはずのchild->bsに対して、NULLポインタならまだしも、non-canonicalなアドレスが入っているということは通常ありえません。そう考えると、child->bsの値は、プログラムの想定していない挙動によって書き換えられたと考えるのが自然です。一体誰がこんなことをしたのでしょうか…。
次はメモリ破壊の犯人探し
どうやら、最初に考えていたよりも状況は複雑なようです。再度整理してみましょう。
block.cの2530行目、bdrv_unset_inherits_fromという関数においてEXC_BAD_ACCESSが発生するのは
- child->bsの値が「何らかの理由で破壊されていた」結果
- child->bs->inherits_fromへのアクセスがSEGVもしくはGPFLTを引き起こす
ためである、と考えられます。
それならば、child->bsの値を、どこのコードがなぜ無効な値に書き換えたのか、それを特定できればバグを修正できそうです。だんだん核心に近づいてきましたね!
次回は、このメモリ破壊を行った犯人を見つけ出し、そしてこのバグを修正するパッチを書くところの話をしたいと思います。お楽しみに!