サービス間通信のための新技術「gRPC」入門
異なるマシン上で動作するサービス間で情報をやり取りする手法にはさまざまなものがあるが、その中でも近年注目されているのが「gRPC」だ。gRPCはGoogleが自社サービス向けに開発して使用していたものをオープンソース化した技術で、さまざまな大規模サービスでの利用実績がある。今回はこのgRPCの概要や、プログラム中で実際に活用する手順などを紹介する。
目次
HTTPベースの既存のRPCを改善する「gRPC」
さまざまな情報システムの設計において、サービス間での情報のやり取りをどのように行うかというのは古くからある課題の1つだ。こういったサービス間での通信技術としてはさまざまなものがあるが、その中でも広く使われている手法の1つに「RPC」(Remote Procedure Call、直訳すると「遠隔手続き呼び出し」)がある。
RPCはいわゆる「クライアント−サーバー」型の通信プロトコルであり、サーバー上で実装されている関数(Procedure、プロシージャ)をクライアントからの呼び出しに応じて実行する技術だ。クライアントはサーバーに対し実行する処理を指定するパラメータや引数として与えるデータを送信し、それに対しサーバーはパラメータに応じた処理を実行してその結果をクライアントに返す、というのがRPCの基本的な流れだ。
RPCは古くからある考え方であり、インターネットが普及する以前より存在していた。一方で、どのようにクライアントからリクエストを送信するかや、どのようなフォーマットでデータをやり取りするかについては時代に応じて変化しており、さまざまな実装が存在する。近年のWebベースのシステムにおいてはHTTP/HTTPSベースでサーバー・クライアント間のやり取りを行い、またその際のデータフォーマートにはXMLを利用する「XML-RPC」や、同じくHTTP/HTTPSベースでデータフォーマットにJSONを利用する「JSON-RPC」といったものが多く使われている。
XML-RPCやJSON-RPCは、広く普及しているHTTP/HTTPSやXML、JSONといった技術を利用するため導入しやすいという利点がある。一方で、これらは基本的にテキストベースで情報をやり取りするためデータの転送効率が悪く、またバイナリデータを扱いにくいという問題があった。また、HTTP/HTTPSを使用しているため比較的長い期間で散発的にデータをやり取りしにくかったり、転送効率の面でもオーバーヘッドが存在したりする。こういった問題を解決するために考案されたのが、今回紹介するgRPCだ(図1)。
gRPCの歴史と特徴
gRPCは、Googleが開発したRPC技術がベースとなっている。Googleでは多数のコンポーネントを組み合わせてサービスを実現する、いわゆる「マイクロサービスアーキテクチャ」でシステムを構築していることで知られるが、これらのサービス間での通信を行うためにgRPCの前身となる「Stubby」と呼ばれる技術が開発された。ただ、このStubbyはGoogleのインフラ以外での利用は想定しておらず、独自の仕様が多かったそうだ。その後Stubbyで使用されていた技術とコンセプトが近いHTTP/2などの技術が登場したことから、GoogleはStubbyにこれらの技術を取り入れてオープン化することを決め、それがgRPCとなった。gRPCはオープンソースで公開されており、現在はLinux Foundation傘下のCloud Native Computing Foundation(CNCF)によって開発が進められている。
2015年に公開されたドキュメントによると、gRPCの基本的なコンセプトとして次のものが挙げられている。
- オブジェクトではなくサービス、リファレンス(参照)ではなくメッセージ
- 適切な適用範囲とシンプルさ
- フリーかつオープン
- 相互運用性があり、一般的なインターネットインフラ内で利用できる
- 汎用性がありながら、専用のものと比べてパフォーマンス面で一般に劣らない
- アプリケーションレイヤーと分離された構造
- ペイロードを問わない
- ストリーミングでの情報伝達に対応
- 同期・非同期の両方に対応
- 通信の中断やタイムアウトをサポート
- 確立された通信を処理しつつ新規接続を止めるようなシャットダウンのサポート
- データ流量のコントロール機能
- デフォルト実装に対して後からさまざまな機能を追加可能
- APIによる機能拡張が可能
- メタデータの交換をサポート
- 標準化されたステータスコード
なお、最初の「サービスはオブジェクトではなく、メッセージはリファレンス(参照)ではない」について補足すると、これはオブジェクトをネットワーク経由で参照・操作できるようにするというコンセプトの「CORBA」や「DCOM」といった分散オブジェクト技術とのコンセプトの違いを説明するものになっている。分散オブジェクトでは、そのオブジェクトにアクセスする側がそのオブジェクトについての知識を事前に十分に知り得ている必要があり、そのためサービス同士が密に結合してしまう。一方、マイクロサービスアーキテクチャではこのようなサービス間での密な結合は避けるべきとされており、そのコンセプトに従ってgRPCは設計されている。
gRPCの技術的概要
gRPCではほかのRPCと同様、クライアントがサーバーに対しリクエストを送信し、サーバーはそれに応じた処理を実行してその結果を返すという、クライアント−サーバーモデルを採用している。そして、gRPCは特定の言語やプラットフォームに依存しないように設計されており、さまざまな言語向けにクライアントやサーバーを実装するためのライブラリが公開されている。そのため、クライアントとサーバーが異なる言語で実装されていても、問題なく通信を行うことができるようになっている。
クライアント・サーバー間の通信に使用するプロトコル(トランスポート)や、やり取りするデータの表現およびシリアライズ方法については置き換えが可能な設計になっているが、デフォルトではトランスポートにHTTP/2が、データのシリアライズにはProtocol Buffersという技術を使用するようになっており、これをそのまま使用するのが一般的だ。Protocol BuffersはGoogleが開発したデータフォーマットで、バイナリデータを含むデータでも効率的に扱えるのが特徴だ。このProtocol Buffersについても、さまざまなプラットフォーム・プログラミング言語から利用できるライブラリが提供されている。
Protocol Buffersではやり取りするデータの型や構造を独自のフォーマットで事前に定義する仕組みが用意されているが、gRPCではこれを使って記述した「サービス定義ファイル」からサーバー/クライアント向けのコードを自動的に生成するツールも同時に提供される。これを利用することで、必要最小限のコードを書くだけでサーバーやクライアントを実装できるようになっている。
gRPCを利用できる言語、環境
gRPCが現在公式にサポートしているプログラミング言語およびプラットフォームは表1の通りだ。
| 言語 | プラットフォーム | サポートされているコンパイラおよびランタイム |
|---|---|---|
| C/C++ | Windows 7以降 | Visual Studio 2015以降 |
| C/C++ | Linux、macOS | GCC 4.9以降、Clang 3.4以降 |
| C# | Windows 7以降 | .NET Core、NET 4.5以降 |
| C# | Linux、macOS | .NET Core、Mono 4以降 |
| Dart | Windows、Linux、macOS | Dart 2.2以降 |
| Go | Windows、Linux、macOS | Go 1.6以降 |
| Java | Windows、Linux、macOS、Android(Gingerbread以降) | JDK 8 |
| Kotlin/JVM (under development) | Windows、Linux、macOS | Kotlin 1.3以降 |
| Node.js | Windows、Linux、macOS | Node.js v4以降 |
| Objective-C | macOS 10.11以降、iOS 7.0以降 | Xcode 7.2以降 |
| PHP (beta) | Linux、macOS | PHP 5.5以降、PHP 7.0以降 |
| Python | Windows、Linux、macOS | Python 2.7以降、Python 3.4以降 |
| Ruby | Windows、Linux、macOS | Ruby 2.3以降 |
また、これ以外の言語でも非公式に作成されたライブラリが用意されている場合がある。ただし、それらは開発やサポートが活発には行われていないものもあるようなので注意が必要だ。
gRPCを使ったアプリケーション開発の流れ
それでは、gRPCを使ったアプリケーション開発を行う場合、実際にどのような手順を踏めば良いかを紹介していこう。この場合の基本的な流れは次のようになる。
- gRPCの利用に必要なツールやライブラリのインストール
- Protocol Buffersを使ったサービスの定義
- サービス定義ファイルからのコードの生成
なお、前述のとおりgRPCはさまざまなプラットフォーム、プログラミング言語で利用できるが、言語ごとに細かい利用法は異なる。本記事はgRPCの雰囲気を掴んでもらうのが目的なので、以降ではPythonおよびNode.jsでの利用を中心に紹介していく。それ以外のプラットフォームや言語で利用する際の細かい手順などは、gRPCのドキュメントなどを参照してほしい。
gRPC利用に必要なツールやライブラリのインストール
gRPCを利用するには、使用するプログラミング言語に対応するライブラリや関連ツールをまず導入する必要がある。ライブラリおよびツール群についてはGitHubのgrpcアカウントで公開されており、ここからソースコードやバイナリなどを入手できる。また、言語によってはパッケージマネージャ経由でもライブラリを入手できる。
なお、PythonやRubyなど多くの言語ではC++で実装されたバイナリを利用してライブラリが実装されているが、Node.jsや.NETなどその言語で実装されたネイティブ実装とC++実装の両方が提供されているものもある(表2)。
| 言語 | パッケージ名 | ライブラリのリポジトリ |
|---|---|---|
| C++ | https://github.com/grpc/grpc | |
| Objective-C | https://github.com/grpc/grpc | |
| Node.js | grpc | https://github.com/grpc/grpc-node |
| Node.js(JavaScript実装) | @grpc/grpc-js | https://github.com/grpc/grpc-node |
| .NET(C#実装) | https://github.com/grpc/grpc-dotnet | |
| .NET | Grpc | https://github.com/grpc/grpc |
| Kotlin | https://github.com/grpc/grpc-kotlin | |
| Java | https://github.com/grpc/grpc-java | |
| JavaScript(Webブラウザ) | grpc-web | https://github.com/grpc/grpc-web |
| Go | google.golang.org/grpc | https://github.com/grpc/grpc-go |
| Swift | https://github.com/grpc/grpc-swift | |
| Dart | grpc | https://github.com/grpc/grpc-dart |
| PHP | grpc | https://github.com/grpc/grpc-php |
| Haskell | https://github.com/grpc/grpc-haskell | |
| Ruby | grpc | https://github.com/grpc/grpc |
| Python | grpcio | https://github.com/grpc/grpc |
ライブラリの導入方法は言語ごとに異なるため、まずはこれらライブラリのリポジトリを確認して欲しいが、たとえばPythonやRuby、Node.jsなどの環境では次のようにそれぞれのパッケージマネージを使ったインストールをおすすめする。
↓Python 3の場合 $ pip3 install grpcio ↓Rubyの場合 $ gem install grpc ↓Node.jsの場合 $ npm install grpc
また、これらの環境ではサービス定義ファイルからコードを自動生成するためのツールが「grpcio-tools」などの別パッケージで提供されているので、必要に応じてこちらもインストールする。
↓Python 3の場合 $ pip3 install grpcio-tools ↓Rubyの場合 $ gem install grpc-tools ↓Node.jsの場合 $ npm install grpc-tools
これ以外のプログラミング言語からgRPCを利用する場合の準備方法については、Quick Startドキュメントを確認してほしい。
プロトコル定義ファイルによるデータ構造とサービスの定義
前述の通り、gRPCの標準的な実装では型付けされたデータや構造化されたデータをネットワーク経由でやり取りできるフォーマットに変換するために「Protocol Buffers」という技術を使用する。なお、このように構造化されたデータをバイト列に変換する処理を「シリアル化」もしくは「シリアライズ」などと呼ぶ。
構造化データをシリアル化する技術としてはJSONやXMLなどもあるが、Protocol Buffersがこれらと異なる点として、事前に扱うデータ構造を型付きで定義しておく必要があることが挙げられる。取り扱うデータの型を厳密に定義しないプログラミング言語では、外部とデータをやり取りする際に数値と文字列を明確に区別しないためにトラブルが発生するようなケースもあるが、Protocol Buffersではやり取りするデータの型を「プロトコル定義ファイル」で事前に定義しておくことで、こういったトラブルを防げるようになっている。
また、Protocol BuffersではRPCのためのサービス記述をサポートする書式も定義されており、gRPCではこれを使って公開する関数(リモートプロシージャ)の名前やそれらが受け取る引数の型、戻り値として返す型を事前に定義するようになっている。
さて、Protocol Buffersのプロトコル定義ファイルは、現在バージョン2(「proto2」)と、バージョン3(「proto3」)の2つのフォーマットがあるが、本記事ではバージョン3(proto3)でのデータ構造について紹介していく。プロトコル定義ファイル中では「syntax = <バージョン>」という形式でどちらのフォーマットで記述されているかを明示しておく必要があるが、バージョン3を利用する場合は次のように記述する。
↓Protocol Buffersバージョン3での記述であることを宣言する syntax = "proto3";
また、Protocol Buffersではやり取りするデータを「メッセージ」と呼び、次のような形式でその型(構造)を定義する。
message <定義するメッセージ型の名前> {
<型> <フィールド名1> = <そのフィールドに紐づけるフィールド番号>;
<型> <フィールド名2> = <そのフィールドに紐づけるフィールド番号>;
<型> <フィールド名3> = <そのフィールドに紐づけるフィールド番号>;
:
:
}
ここで「フィールドに紐づけるフィールド番号」は、各フィールドごとに一意な、1から536,870,911(2の29乗-1)までの間の整数(ID)を指定する。一見値を代入しているようにも見えるが、そうではない点に注意したい。このIDは、メッセージをシリアル化する際にフィールドを識別するために使われる。
たとえば、ユーザー名とメールアドレス、ユーザーIDを含む「User」というメッセージ型を定義する場合、次のようになる。
syntax = "proto3";
message User {
int32 id = 1;
string name = 2;
string email = 3;
}
なお、型名はCamelCase(単語の最初の1文字を大文字にする)、フィールド名はsnake_case(単語はすべて小文字でそれらを「_」で結合する)命名ルールが推奨されている。
Protocol Buffersでは、フィールド名ではなくフィールド番号を使ってそのメッセージの構造を保存する。そのため、あとからフィールド名やその型を変更した場合でも、フィールド番号が一致していれば、そのフィールドは同じものとして認識される。たとえば、先に定義した「User」というメッセージ型の定義を次のように変更しても、変更前のコードとまったく同じようにデータのやり取りを行える。
syntax = "proto3";
message User {
int32 id = 1;
string nickname = 2;
string mail_address = 3;
}
なお、フィールド番号はシリアル化されたデータ内にエンコードされて埋め込まれるが、その際に1〜15までの番号は1バイトに、16〜2047までの番号は2バイトにエンコードされる。そのため、頻繁に利用するデータについてはできるだけ1〜15までの番号を利用することが推奨されている。また、各フィールドに必ずしも連続した番号を割り振る必要はなく、将来の仕様変更に向けて番号を空けておいても問題ない。
Protocol Buffersで使用できる型
各フィールドの型については次の表3のものが利用できる。
| 型名 | 説明 |
|---|---|
| double | 倍精度浮動小数点数(64ビット) |
| float | 単精度浮動小数点数(32ビット) |
| int32 | 符号あり32ビット整数 |
| int64 | 符号あり64ビット整数 |
| uint32 | 符号なし32ビット整数 |
| uint64 | 符号なし64ビット整数 |
| sint32 | 符号あり32ビット整数 |
| sint64 | 符号あり64ビット整数 |
| fixed32 | 符号なし32ビット整数(固定バイト幅) |
| fixed64 | 符号なし64ビット整数(固定バイト幅) |
| sfixed32 | 符号あり32ビット整数(固定バイト幅) |
| sfixed64 | 符号あり64ビット整数(固定バイト幅) |
| bool | ブール型(true/false) |
| string | UTF-8もしくは7ビットASCII文字列 |
| bytes | バイト列 |
doubleとfloatの違いや、bool、string、bytesなどのデータ型についてはC/C++といった一般的なプログラミング言語と同じだが、整数型については32ビット/64ビットおよび符号あり/なしの区別だけでなく、エンコード方法が異なる型が用意されている点が特徴だ。たとえば符号あり32ビット整数型としては「int32」と「sint32」、「sfixed32」の3つがあるが、これらはデータのエンコード方法が異なり、sint32はint32よりも負の数をより効率的にエンコードでき、またsfixed32はint32よりも大きい値をより効率的にエンコードできる、という違いがある。符号なし32ビット整数についても同様で、「fixed32」は「uint32」よりも大きな値を効率的にエンコードできる。64ビット整数についても同様だ。
なお、実用上問題となることは少ないだろうが、「string」および「bytes」型のフィールドには最大で2の32乗(4,294,967,296)バイトまでのデータしか格納できないという制限がある点にも注意したい。そのほかシリアル化やエンコーディングについての詳細な仕様はProtocol Buffersのドキュメントにまとめられているので、興味のある方はそちらを参照すると良いだろう。
表3の型に加えて、列挙型(enum)や別に定義したメッセージ型を型として指定することもできる。まず列挙型だが、これは次のようにして定義できる。なお、列挙型では必ずフィールド番号として「0」が指定されたフィールドを持つ必要がある。フィールド番号として「0」が指定されたフィールドは、このenum型が指定されたフィールドの受け渡し時のデフォルト値として使われる。
enum <定義する列挙型の名前> {
<フィールド1> = <フィールド番号>;
<フィールド2> = <フィールド番号>;
:
:
}
たとえば次のコードは、ユーザーの種別を定義する「UserType」という列挙型の定義と、それをメンバとして使用する例だ。
enum UserType {
NORMAL = 0;
ADMINISTRATOR = 1;
GUEST = 2;
DISABLED = 3;
}
message User {
uint32 id = 1;
string nickname = 2;
string mail_address = 3;
UserType user_type = 4;
}
ここでは、「NORMAL」および「ADMINISTRATOR」、「GUEST」、「DISABLED」という4つの値が定義された列挙型である「UserType」を定義し、その型に対応する「user_type」というフィールドを定義している。
また、独自に宣言したメッセージ型をメンバの型として利用することもできる。次の例は、「Picture」というメッセージ型を定義し、それをUserというメッセージ型で使用している。
enum PictureType {
PNG = 0;
JPEG = 1;
GIF = 2;
}
enum UserType {
NORMAL = 0;
ADMINISTRATOR = 1;
GUEST = 2;
DISABLED = 3;
}
message Picture {
uint32 id = 1;
uint32 width = 2;
uint32 height = 3;
PictureType type = 4;
}
message User {
uint32 id = 1;
string nickname = 2;
string mail_address = 3;
UserType user_type = 4;
Picture user_icon = 5;
}
ちなみに、メッセージ型の定義中に別のメッセージ型を定義したり、列挙型を定義したりするような入れ子型の構造も可能だ。上記の例は、次のように記述することもできる。
message Picture {
uint32 id = 1;
uint32 width = 2;
uint32 height = 3;
enum PictureType {
PNG = 0;
JPEG = 1;
GIF = 2;
}
PictureType type = 4;
}
message User {
uint32 id = 1;
string nickname = 2;
string mail_address = 3;
enum UserType {
NORMAL = 0;
ADMINISTRATOR = 1;
GUEST = 2;
DISABLED = 3;
}
UserType user_type = 4;
Picture user_icon = 5;
}
一般的なプログラミング言語における配列のような、複数の値を格納できるフィールドを用意したい場合、型の前に「repeated」という識別子を付けることで定義できる。たとえば次のように定義した「User」型では、「user_icons」フィールドに複数の値を格納できる。
message User {
uint32 id = 1;
string nickname = 2;
string mail_address = 3;
enum UserType {
NORMAL = 0;
ADMINISTRATOR = 1;
GUEST = 2;
DISABLED = 3;
}
UserType user_type = 4;
repeated Picture user_icons = 5;
uint32 default_picture = 6;
}
複数の型のどれか1つを値として持つフィールドを定義することも可能だ。これは、「oneof」という識別子を使って定義できる。
oneof <フィールド名> {
<型> <フィールド名1> = <フィールド番号>;
<型> <フィールド名2> = <フィールド番号>;
:
:
}
このように定義したフィールドは、{}(中括弧)内で指定した型およびフィールド名のいずれか1つのみを持つ。たとえば次のように定義した「UserQueryResult」型のresultフィールドでは、「User」型の「user」というフィールドか、「Error」型の「error」というフィールドのいずれか1つを持つ。
message UserQueryResult {
oneof result {
User user = 1;
Error error = 2;
}
}
キーと値の組み合わせを保存する、「map」という仕組みも用意されている。これは、一般的なプログラミング言語では「辞書型」(dictionary)や「ハッシュ型」(hash)などと呼ばれるものだ。
map<<キーとして使用する型>, <値として使用する型>> <フィールド名> = <フィールド番号>;
たとえば次の例は、32ビット符号なし整数をキーとして文字列を格納する辞書型を「comments」というフィールドで使用する例だ。なお、キーとして使用できる型はuint32などの整数型もしくは文字列(string)のみとなっている。
message Friends {
uint32 user_id = 1;
map<uint32, string> comments = 2;
}
コメントの記述とインポート機能、モジュール機能
プロトコル定義ファイル内ではC/C++と同様に「//」および「/* */」を使ってコメントを記述でき、「//」から行末までと、「/*」と「*/」で囲まれた部分は無視される。
// 「//」から行末まではコメントとして認識され無視される /* Cスタイルのコメントも利用可能 */
メッセージ型などを定義する際に、別のプロトコル定義ファイル内で定義された型を利用することもできる。その場合、「import」キーワードでそのファイルをインポートすれば良い。
import "<ファイルパス>":
たとえば「foo.proto」というファイル内で定義されているメッセージ型を参照したい場合、次のように記述する。
import "foo.proto";
なお、インポート対象のプロトコル定義ファイル内で定義されているメッセージ型は、デフォルトではインポートしたファイル内でのみ参照が可能になる(図2)。
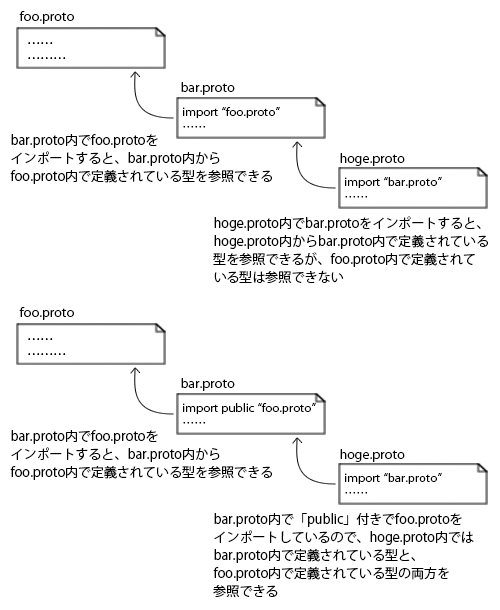
たとえば、「foo.proto」というプロトコル定義ファイルをインポートする「bar.proto」というプロトコル定義ファイルがあったとしよう。このとき、別のプロトコル定義ファイルで「bar.proto」をインポートしても、そのプロトコル定義ファイル内から参照できるのは「bar.proto」ファイルで定義されている型のみで、「foo.proto」で定義されている型は参照できない。
ただ、「bar.proto」ファイルをインポートした場合に、そこでインポートしている「foo.proto」ファイルで定義されているものも一緒にインポートしたい、という場合もある。その場合、「bar.proto」ファイル内で「public」キーワード付きで「foo.proto」をインポートすれば良い。
import public "foo.proto";
このように「import public」でインポートされたプロトコル定義ファイル内の定義は、別のプロトコル定義ファイルからも参照できるようになる。
こういったインポート機能を利用する場合、異なるファイル間で同じ名前の型が定義されていると問題が発生する。そのため、Protocol Buffersでは名前空間を分離するためのパッケージ機構が提供されている。名前空間の定義には、「package」識別子を使用する。
package <パッケージ名>
たとえば次の例では、「foo」というパッケージを定義し、そのパッケージ内で「Comment」というメッセージ型を定義している。
package foo;
message Comment {
uint32 id = 1;
string comment = 2;
}
ここで定義された「Comment」というメッセージ型は、ほかのパッケージからは「foo.Comment」として参照できる。
パッケージ名は階層構造を取ることも可能だ。その場合、パッケージ階層はパッケージ名を「.」で連結することで表現する。たとえば「bar」という階層の下に「baz」というパッケージを定義する場合、次のようになる。
package bar.baz;
message Hoge {
uint32 id = 1;
string title = 2;
}
型定義の互換性
Protocol Buffersでは、一定の条件を満たした上でのメッセージ型定義の変更であれば、互換性を保つことができるような仕組みが備えられている。この条件を満たしていれば、たとえばクライアント側とサーバー側で異なるメッセージ型定義ファイルを使っていても、エラーなく情報をやり取りできる。この条件というのは以下の通りだ。
- フィールド番号を変えない。フィールド名をリネームした場合でも、対応するフィールド番号が同じであれば互換性は保たれる。また、フィールドを追加・削除した場合でも、それと重複するフィールド番号が使われていない限り互換性は保たれる
- データ型としてint32、uint32、int64、uint64、boolを使用していた場合、これらの間であればデータ型を変更しても互換性は保たれる
- 同様にsint32とsint64、fixed32とsfixed32、fixed64とsfixed64には互換性がある
これ以外にも条件付きで互換性が保たれる場合があるので、そういった仕様について詳しくはドキュメントを参照してほしい。
なお、フィールドを削除・追加するような場合に向けて、フィールド番号を「予約済み」にしておく仕組みが用意されている。これは、次のように「reserved」キーワードを利用することで指定できる。
message <メッセージ名> {
reserved <フィールド番号1>, <フィールド番号2>, ...
}
また、それぞれの型にはデフォルト値が決まっており、送受信されたメッセージ内でその値が定義されていなかった場合、そのフィールドの値は次のデフォルト値にセットされる。
- double/floatといった浮動小数点数型やint32、int64などの整数型:0
- bool:false
- string:空文字列
- bytes:空バイト列
- enumで定義された列挙型:フィールド番号が0に相当する値
- メッセージ型:値はセットされない(実装依存)
プロトコル定義ファイルからのクラスの生成
Protocol Buffersでは、プロトコル定義ファイルから各プログラミング言語に定義されたクラス定義ファイルを生成する「protoc」というツールが用意されている。gRPCを利用する場合は「grpc-tools」などのgRPC向けのツールでこの処理を実行できるようになっており、その場合protoc単体を導入する必要はないが、Protocol Buffersを単体で利用したい場合はこのツールを利用することとなるので、簡単にその使い方についても説明しておこう。
protocはGitHubで公開されており、そのリリースページからダウンロードできる。ダウンロードしたアーカイブのbinディレクトリ内に「protoc」という名前でprotocのバイナリが格納されているので、これをパスの通った適当なディレクトリにコピーしておこう(もしくは直接実行しても構わない)。
$ ./bin/protoc --version libprotoc 3.11.4
オプションでプロトコル定義ファイルとコードを生成したいプログラミング言語を指定してprotocコマンドを実行すると、指定した出力先ディレクトリにその言語向けのソースコードが出力される(表4)。
| プログラミング言語 | 指定するオプション |
|---|---|
| C++ | --cpp_out=<出力先ディレクトリ> |
| C# | --csharp_out=<出力先ディレクトリ> |
| Java | --java_out=<出力先ディレクトリ> |
| JavaScript | --js_out=<出力先ディレクトリ> |
| Objective-C | --objc_out=<出力先ディレクトリ> |
| PHP | --php_out=<出力先ディレクトリ> |
| Python | --python_out=<出力先ディレクトリ> |
| Ruby | --ruby_out=<出力先ディレクトリ> |
たとえば次のような「user.proto」というプロトコル定義ファイルを用意し、これを変換する例を見てみよう。
syntax = "proto3";
message Picture {
uint32 id = 1;
uint32 width = 2;
uint32 height = 3;
enum PictureType {
PNG = 0;
JPEG = 1;
GIF = 2;
}
PictureType type = 4;
}
message User {
uint32 id = 1;
string nickname = 2;
string mail_address = 3;
enum UserType {
NORMAL = 0;
ADMINISTRATOR = 1;
GUEST = 2;
DISABLED = 3;
}
UserType user_type = 4;
repeated Picture user_icon = 5;
uint32 default_picture = 6;
}
ここからJavaScriptコードを生成して「foo」というディレクトリに出力する場合、次のように実行する。
$ protoc --js_out=foo user.proto
これを実行すると、PB_JSディレクトリ内にプロトコル定義ファイル内で定義した「Picture」と「User」というメッセージ型に対応した型が定義されたソースコードが出力される。
$ ls foo picture.js user.js
また、Python向けのコードを出力する場合、次のように実行すれば良い。
$ protoc --python_out=bar user.proto $ ls bar user_pb2.py
なお、これらは機械的に生成されたコードとなっており、人間が修正を加えることを想定した構造にはなっていない。また、出力されたコードを利用するには、各言語向けのProtocol Buffersランタイムライブラリが必要だ。これらはGitHubのリリースページで公開されている。gRPCで利用する場合、gRPCライブラリを導入することで基本的に同時にインストールされるが、Protocol Buffersを単体で利用したい場合については、インストール方法などをドキュメントなどで確認してほしい。
サービスの定義
Protocol Buffersでは、プロトコル定義ファイル内でサービスを定義する機能も用意されている。gRPCではこの機能を使い、プロトコル定義ファイル内で定義されたサービスに対応するコードを生成するようになっている。サービスは次のように定義できる。
service <サービス名> {
rpc <プロシージャ名1> (<引数として受け取るメッセージ型>) returns (<戻り値として返すメッセージ型>) {}
rpc <プロシージャ名2> (<引数として受け取るメッセージ型>) returns (<戻り値として返すメッセージ型>) {}
:
:
}
プロシージャ名は実行する処理(リモートプロシージャ)を識別するための文字列で、いわゆる関数名に相当する。また、1つのサービスに対し複数のリモートプロシージャが定義可能だ。
サービス定義ファイルからのコード生成
gRPCではProtocol Buffersのサービス定義ファイルからサーバーおよびクライアント向けのコードを自動的に生成するツールが提供されており、これを利用することで簡単にサーバーおよびクライアントを実装できるようになっている。続いては、これらを使って実際にサーバーやクライアントを実装する例を紹介しよう。
以下で紹介するサンプルコードは、「ユーザーの詳細情報を取得する」という処理をイメージしたものだ。ユーザーはユーザーIDで管理されており、クライアントがサーバーにユーザーIDを送信すると、サーバーはそのユーザーIDに該当するユーザーの情報をクライアントに返す、という処理を実行する。
gRPCではまずプロトコル定義ファイルを作成してやり取りに使用するメッセージ型やサービスを定義する必要があるが、これは次のように「user.proto」というファイルで定義した。
ここではユーザー情報を格納するメッセージ型「User」と、クライアントがサーバーにリクエストを送信する際に使うメッセージ型「UserRequest」、そしてサーバーがクライアントに結果を送信する際に使うメッセージ型「UserResponse」を定義している。また、サーバーが提供するサービスとして「UserManager」サービスを定義し、そこでUserRequest型を引数として受け取り、結果としてUserResponseを返すリモートプロシージャである「get」を定義した。
syntax = "proto3";
// ユーザー情報を表すメッセージ型
message User {
uint32 id = 1;
string nickname = 2;
string mail_address = 3;
enum UserType {
NORMAL = 0;
ADMINISTRATOR = 1;
GUEST = 2;
DISABLED = 3;
}
UserType user_type = 4;
}
// ユーザー情報のリクエストに使用するメッセージ型
message UserRequest {
uint32 id = 1;
}
// ユーザー情報を返す際に使用するメッセージ型
message UserResponse {
bool error = 1;
string message = 2;
User user = 3;
}
// ユーザー管理を行うサービス
service UserManager {
// ユーザー情報を取得する
rpc get (UserRequest) returns (UserResponse) {}
}
なお、一般的にこういったサーバーでは情報の保存や取得にデータベースを使用するが、今回はサンプルコードということで、次のようなJSON形式でユーザー情報を作成した「users.json」というファイルを用意し、適宜ここから情報を取り出して利用する。
{ "1": { "id": 1,
"nickname": "admin",
"mail_address": "admin@example.com",
"user_type": "ADMINISTRATOR" },
"2": { "id": 2,
"nickname": "guest",
"mail_address": "guest@example.com",
"user_type": "GUEST" },
"3": { "id": 3,
"nickname": "foo",
"mail_address": "foo@example.com",
"user_type": "NORMAL" },
"4": { "id": 4,
"nickname": "troll",
"mail_address": "troll@example.com",
"user_type": "DISABLED" }
}
Pythonでのサーバー/クライアント実装
Pythonでは、プロトコル定義ファイルからコードを生成するツールが「grpcio-tools」という名称のパッケージで提供されているので、これをpipコマンドでインストールしておく。
# pip3 install grpcio grpcio-tools
なお、Python 3.6以降ではローカルなPython環境を構築するための「venv」という機能が導入されており、「python3 -m venv <venv環境を構築するディレクトリ>」のようにコマンドを実行することで、ルート権限なしにパッケージを指定したディレクトリ内にインストールできるローカル環境を作成できる(venvのドキュメント)。たとえばカレントディレクトリ以下に「venv」ディレクトリを作成してそこにパッケージをインストールしたい場合、次のように実行する。
↓venv環境を作成する $ python3 -m venv venv ↓venv環境を有効にする $ . venv/vin/activate ↓パッケージをインストールする (venv) $ pip3 install grpcio grpcio-tools
grpcio-toolsを使ってプロトコル定義ファイルからコードを生成するには、次のようなコマンドラインオプションを指定してpython3コマンドを実行すれば良い。
python3 -m grpc_tools.protoc -I<プロトコル定義ファイルが格納されているディレクトリ> --python_out=<コード出力先ディレクトリ> --grpc_python_out=<コード出力先ディレクトリ> <プロトコル定義ファイルのパス名>
ここで、「--python_out」は型定義に対応するPythonコードを出力するディレクトリを、「--grpc_python_out」はサービス定義に対応するPythonコードを出力するディレクトリを指定するオプションだ。同じディレクトリを指定しても問題ない。たとえば「../protos/user.proto」というプロトコル定義ファイルを元に、カレントディレクトリ内にコードを生成する場合、次のように実行する。
$ python3 -m grpc_tools.protoc -I../protos --python_out=. --grpc_python_out=. ../protos/user.proto
このように実行すると、次のように「_pb2.py」で終わるファイルと、「_pb2_grpc.py」で終わるファイルの2つが作成される。
$ ls user_pb2.py user_pb2_grpc.py
このうち「_pb2.py」で終わるファイル(今回の例では「user_pb2.py」)では、プロトコル定義ファイル内でのメッセージ型定義に対応したクラスが実装されている。
# -*- coding: utf-8 -*-
# Generated by the protocol buffer compiler. DO NOT EDIT!
# source: user.proto
from google.protobuf import descriptor as _descriptor
from google.protobuf import message as _message
from google.protobuf import reflection as _reflection
from google.protobuf import symbol_database as _symbol_database
# @@protoc_insertion_point(imports)
_sym_db = _symbol_database.Default()
:
:
_USER = _descriptor.Descriptor(
name='User',
full_name='User',
filename=None,
file=DESCRIPTOR,
containing_type=None,
fields=[
_descriptor.FieldDescriptor(
name='id', full_name='User.id', index=0,
number=1, type=13, cpp_type=3, label=1,
has_default_value=False, default_value=0,
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
serialized_options=None, file=DESCRIPTOR),
:
:
また、「_pb2_grpc.py」で終わるファイル(今回の例では「user_pb2_grpc.py」)はサービス定義に対応するコードで、サービスを実装するための基底クラスや、gRPCのサーバークラスにサービスを追加するために使用する関数などが定義されている。
# Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT!
import grpc
import user_pb2 as user__pb2
class UserManagerStub(object):
"""ユーザー管理を行うサービス
"""
:
:
class UserManagerServicer(object):
"""ユーザー管理を行うサービス
"""
def get(self, request, context):
"""ユーザー情報を取得する
"""
:
:
サーバーの実装
まずはサーバーの実装だが、gRPCのPython向けライブラリでは、サービス定義を元に生成されたクラス(デフォルトでは「<サービス名>Servicer」というクラス)を継承したクラスを実装することで、リモートプロシージャに対応するメソッドを実装していく。今回の例ではuser_bp2_grpc.pyで実装されている「UserManagerServicer」がその継承元のクラスとなる。このクラスではサービス定義内で定義した「get」というリモートプロシージャに対応する同名のメソッドが定義されているので、継承先クラスではこのメソッドをオーバーライドする。
# サービス定義から生成されたUserManagerServicerクラスを継承して、
# 定義したリモートプロシージャに対応するメソッドを実装する
class UserManager(user_pb2_grpc.UserManagerServicer):
def get(self, request, context):
"""ユーザー情報を取得する
"""
# クライアントが送信した引数はrequest引数に格納され、
# このオブジェクトに対しては一般的なPythonオブジェクトと
# 同様の形でプロパティにアクセスできる
user_id = request.id
リモートプロシージャに対応する各メソッドは「request」と「context」という2つの引数を取る。request引数にはクライアントが引数として与えたメッセージに対応するオブジェクトが、context引数にはRPCに関する情報を含むオブジェクトが渡される。また、このメソッドの戻り値として渡したオブジェクトがクライアントに戻り値として返される仕組みになっている。たとえば今回の「get」リモートプロシージャの定義では引数として「UserRequest」型、戻り値として「UserResponse」型を使用するよう定義している。そのため、request引数で渡されたオブジェクトはこのUserRequest型のものとなり、またreturnで返すオブジェクトはUserResponse型のものでなければならない。
なお、プロトコル定義ファイルで定義した型に対応するオブジェクトに対しては、一般的なPythonのオブジェクトと同様の方法でそのプロパティにアクセスできる。たとえば、UserRequest型の「request」オブジェクトの「id」プロパティには、「request.id」のようにしてアクセスできる。
プロトコル定義ファイルで定義した型に対応するオブジェクトを作成するには、一般的なPythonクラスと同様にコンストラクタを呼び出せば良い。たとえばUser型のオブジェクトを作成し、その「id」プロパティに値を代入するコードは次のようになる。
# 戻り値として返すUserオブジェクトを作成する result = user_pb2.User() result.id = user["id"] result.nickname = user["nickname"] result.mail_address = user["mail_address"]
列挙型については定数として定義されており、こちらもPythonのクラスのメンバにアクセスするのと同様にアクセスできる。たとえば次のようにすることで、user_typeプロパティに「UserType」列挙型の「NORMAL」という値を代入できる。
result.user_type = user_pb2.User.UserType.NORMAL
また、列挙型には「Value()」というメソッドが定義されており、これを利用すると文字列を対応する列挙型の値に変換できる
# user["user_type"]には「NORMAL」などの文字列が格納されている result.user_type = user_pb2.User.UserType.Value(user["user_type"])
コンストラクタに「<プロパティ名>=<値>」という形で値を渡すことで、プロパティに値が代入されたオブジェクトを作成することもできる。次の例では、「error」というプロパティにFalseが、「user」というプロパティにresultオブジェクトが代入されたUserResponse型オブジェクトを作成している。
# UserResponseオブジェクトを返す
return user_pb2.UserResponse(error=False,
user=result)
grpcパッケージではgRPCのサーバーを実装したgrpc.Serverというクラスが用意されている。サーバーを立ち上げるには、まずこのクラスのインスタンスを作成するgrpc.server()メソッドを実行してServerオブジェクトを作成する。
server = grpc.server(ThreadPoolExecutor(max_workers=2))
なお、gRPCのサーバー実装ではThreadPoolを利用するので、そのためのモジュールを事前にimportしておく。
from concurrent.futures import ThreadPoolExecutor
サービス定義に対応して出力されたコード(今回は「user_pb2_grpc.py」)では「add_<サービス名>Servicer_to_server」というメソッドが用意されており、「<サービス名>Servicer」クラスを継承したクラス(今回は「UserManager」クラス)のオブジェクトとServerオブジェクトを引数としてこのメソッドを実行することで、Serverオブジェクトにサービスを登録できる。
user_pb2_grpc.add_UserManagerServicer_to_server(UserManager(), server)
あとはServerクラスのadd_insecure_port()メソッドで待ち受けを行うアドレスおよびポートを指定し、start()メソッドを実行すると待ち受けが開始される。
server.add_insecure_port('[::]:1234')
server.start()
なお、add_insecure_port()メソッドはその名前の通り平文でのやり取りを行うアドレスおよびポート番号を指定するものだ。SSL/TLSを使って暗号化された経路を利用したい場合は、代わりにadd_secure_portを使用する。
また、待ち受けの終了後にはwait_for_termination()メソッドを使って後処理を実行しておく。
server.wait_for_termination()
これらを実装したソースコード全文は次のようになる。
#!/usr/bin/env python3
# gRPCのサーバー実装ではThreadPoolを利用するので、そのためのモジュールをimportしておく
from concurrent.futures import ThreadPoolExecutor
import json
# 「grpc」パッケージと、grpc_tools.protocによって生成したパッケージをimportする
import grpc
import user_pb2
import user_pb2_grpc
# ユーザー情報の読み込み
with open("../users.json") as fp:
users = json.load(fp)
# サービス定義から生成されたクラスを継承して、定義したリモートプロシージャに対応するメソッドを実装する
class UserManager(user_pb2_grpc.UserManagerServicer):
def get(self, request, context):
"""ユーザー情報を取得する
"""
# クライアントが送信した引数はrequest引数に格納され、
# このオブジェクトに対しては一般的なPythonオブジェクトと
# 同様の形でプロパティにアクセスできる
user_id = request.id
# ユーザー情報はユーザーIDを文字列に変換したものをキーとする辞書型データ
# なので、適宜文字列型に変換して使用している
if str(user_id) not in users:
# 該当するユーザーが存在しない場合エラーを返す
return user_pb2.UserResponse(error=True,
message="not found")
user = users[str(user_id)]
# 戻り値として返すUserオブジェクトを作成する
result = user_pb2.User()
result.id = user["id"]
result.nickname = user["nickname"]
result.mail_address = user["mail_address"]
result.user_type = user_pb2.User.UserType.Value(user["user_type"])
# UserResponseオブジェクトを返す
return user_pb2.UserResponse(error=False,
user=result)
def main():
# Serverオブジェクトを作成する
server = grpc.server(ThreadPoolExecutor(max_workers=2))
# Serverオブジェクトに定義したServicerクラスを登録する
user_pb2_grpc.add_UserManagerServicer_to_server(UserManager(), server)
# 1234番ポートで待ち受けするよう指定する
server.add_insecure_port('[::]:1234')
# 待ち受けを開始する
server.start()
# 待ち受け終了後の後処理を実行する
server.wait_for_termination()
if __name__ == '__main__':
main()
クライアントの実装
続いてはサーバーにアクセスするクライアントだが、こちらは非常にシンプルだ。まず、リクエストに使用するオブジェクト(ここでは「UserRequest」型オブジェクト)を作成する。
req = user_pb2.UserRequest(id=user_id)
次に、接続先のURLを引数として与えてgrpc.insecure_channel()メソッドを実行してgrpc.Channelクラスのオブジェクトを作成する。
with grpc.insecure_channel("localhost:1234") as channel:
自動生成されたコードには「<サービス名>Stub」というクラス名でサービスにアクセスするための「Stub」クラスが定義されているので、grpc.insecure_channel()メソッドの戻り値として得られたChannel型オブジェクトを引数としてこのクラスのコンストラクタを実行し、オブジェクトを作成する。
stub = user_pb2_grpc.UserManagerStub(channel)
このstubに対し、リモートプロシージャ名に対応するメソッド(今回の例では「get」)を実行することで、サーバーに対しリクエストが送信され、その結果が戻り値として返される。
response = stub.get(req)
これらを実装したコード全文は次のようになる。
import pprint
import sys
# 「grpc」パッケージと、protocによって生成したパッケージをimportする
import grpc
import user_pb2
import user_pb2_grpc
def main():
# 引数をチェックする
if (len(sys.argv) < 2):
print("usage: {} <user_id>".format(sys.argv[0]))
sys.exit(-1)
try:
user_id = int(sys.argv[1])
except ValueError:
print("error: invalid user_id `{}'".format(sys.argv[1]))
print("usage: {} <user_id>".format(sys.argv[0]))
sys.exit(-1)
# リクエストを作成する
req = user_pb2.UserRequest(id=user_id)
# サーバーに接続する
with grpc.insecure_channel("localhost:1234") as channel:
# 送信先の「stub」を作成する
stub = user_pb2_grpc.UserManagerStub(channel)
# リクエストを送信する
response = stub.get(req)
# 取得したレスポンスの表示
pprint.pprint(response)
if __name__ == '__main__':
main()
サーバーを起動した状態でこのコードを実行すると、次のように対応するユーザー情報を取得できることが確認できる。
(venv) $ python3 client.py 1
user {
id: 1
nickname: "admin"
mail_address: "admin@example.com"
user_type: ADMINISTRATOR
}
(venv) $ python3 client.py 2
user {
id: 2
nickname: "guest"
mail_address: "guest@example.com"
user_type: GUEST
}
(venv) $ python client.py 0
error: true
message: "not found"
Node.jsでのサーバー/クライアント実装
Node.jsでは、「grpc-tools」というパッケージ名でプロトコル定義ファイルからコードを生成するモジュールが提供されている。また、生成されたコードの利用には「grpc」や「google-protobuf」といったパッケージも必要なので、合わせてインストールしておく。
$ npm install grpc grpc-tools google-protobuf
grpc-toolsをインストールすると、node_modules/.binディレクトリに「grpc_tools_node_protoc」という名前でコードを生成ツールがインストールされる。このツールを使ってNode.js向けのコードを生成するには、次のように実行する。
./node_modules/.bin/grpc_tools_node_protoc -I<プロトコル定義ファイルが格納されているディレクトリ> --js_out=<オプション>,binary:<コード出力先ディレクトリ>. --grpc_out=<コード出力先ディレクトリ> <プロトコル定義ファイルのパス名>
なお、JavaScriptコードを生成する際には、「--js_out」オプションでファイルの出力先に加えて使用するライブラリやパッケージのインポート方法を指定する必要がある。Node.jsで使われている「CommonJS」形式を利用する場合は、このオプションとして「import_style=commonjs」を指定すれば良い。詳しくはProtocol Buffersのドキュメントで解説されているので、そちらを参照してほしい。
さて、今回の例では「../protos」というディレクトリ内にプロトコル定義ファイルが格納されているので、次のように実行するとカレントディレクトリ内にJavaScriptコードが生成される。
$ ./node_modules/.bin/grpc_tools_node_protoc -I../protos/ --js_out=import_style=commonjs,binary:./ --grpc_out=./ ../protos/user.proto $ ls node_modules package-lock.json user_grpc_pb.js user_pb.js
ここで、ファイル名が「_pb.js」で終わるもの(今回の例では「user_pb.js」)がメッセージ型に対応するオブジェクトのプロトタイプが定義されているファイルだ。
/**
* @fileoverview
* @enhanceable
* @suppress {messageConventions} JS Compiler reports an error if a variable or
* field starts with 'MSG_' and isn't a translatable message.
* @public
*/
// GENERATED CODE -- DO NOT EDIT!
var jspb = require('google-protobuf');
var goog = jspb;
var global = Function('return this')();
goog.exportSymbol('proto.User', null, global);
goog.exportSymbol('proto.User.UserType', null, global);
goog.exportSymbol('proto.UserRequest', null, global);
goog.exportSymbol('proto.UserResponse', null, global);
:
:
また、ファイル名が「_grpc_pb.js」で終わるもの(今回の例では「user_grpc_pb.js」)にはサービスに対応するオブジェクトのプロトタイプが定義されている。
// GENERATED CODE -- DO NOT EDIT!
'use strict';
var grpc = require('grpc');
var user_pb = require('./user_pb.js');
:
:
// ユーザー管理を行うサービス
var UserManagerService = exports.UserManagerService = {
// ユーザー情報を取得する
get: {
path: '/UserManager/get',
requestStream: false,
responseStream: false,
requestType: user_pb.UserRequest,
responseType: user_pb.UserResponse,
requestSerialize: serialize_UserRequest,
requestDeserialize: deserialize_UserRequest,
responseSerialize: serialize_UserResponse,
responseDeserialize: deserialize_UserResponse,
},
};
exports.UserManagerClient = grpc.makeGenericClientConstructor(UserManagerService);
サーバーの実装
まずはサーバーの実装だが、Node.js向けのgrpcライブラリではリモートプロシージャに対応するハンドラ関数を実装し、それをServerオブジェクトのaddService()メソッドの引数として与えることでリモートプロシージャとハンドラ関数を紐付けるようになっている。ここで、addService()メソッドの第2引数ではリモートプロシージャ名をキー、対応する関数を値として持つオブジェクトを指定する。
const services = require('./user_grpc_pb');
:
:
// Serverオブジェクトを作成する
const server = new grpc.Server();
// Serverオブジェクトに定義したServicerクラスを登録する
server.addService(services.UserManagerService, { get: get });
ここでは「get」というリモートプロシージャに対し、get()というハンドラ関数を紐づけている。このハンドラ関数は「call」と「callback」の2つの引数を取る。前者はgRPCに関連する情報や引数を格納するServerUnaryCall型のオブジェクト、後者は処理の完了後に実行結果を返すための関数オブジェクトだ。
function get(call, callback) {
// リクエストの「id」プロパティを取得
const userId = call.request.getId();
:
:
リモートプロシージャの呼び出し時にクライアントが引数として指定したメッセージは、callオブジェクトのrequestプロパティに格納されている。JavaScript版のgRPCランタイムではメッセージの各プロパティにgetter/setterメソッド経由でアクセスするようになっており、たとえば「id」というプロパティに対するgetterは「getId」、setterは「setId」というメソッドになっている。Protocol Buffersでのプロパティ名はsnake_caseルールでの命名が推奨されているが、JavaScriptでのプロパティ名は先頭の単語は小文字で始め、それ以外の単語は大文字で始めるlowerCamelCaseルールが推奨されているため、これに沿った形でgetter/setterが用意される。
また、オブジェクトの作成は、一般的なJavaScriptのクラスと同様にnewキーワード付きでコンストラクタを実行することで行える。
const messages = require('./user_pb');
:
:
const target = new messages.User();
target.setId(user.id);
target.setNickname(user.nickname);
:
:
ハンドラ関数内でクライアントに対する戻り値を送信するには、その引数として与えられたcallbackメソッドを使用する。このメソッドには「error」、「value」、「trailer」、「flags」という4つの引数を与えることができ、第1引数にはエラーオブジェクト、第2引数に戻り値として返す値を与える。第3引数、第4引数はそれぞれ省略可能で、メタデータおよび振る舞いを指定するフラグを指定する。
// UserResponseオブジェクトを作成する const response = new messages.UserResponse(); response.setError(false); response.setUser(target); // UserResponseオブジェクトを返す callback(null, response);
Serverオブジェクトの準備が完了したら、bind()メソッドで待ち受けするIPアドレスやポート番号を指定し、その後start()メソッドを実行すると待ち受けが開始される。
// 1234番ポートで待ち受けするよう指定する
server.bind('0.0.0.0:1234', grpc.ServerCredentials.createInsecure());
// 待ち受けを開始する
server.start();
これらを使って実装した基本的なサーバーコードの全文は次の通りだ。
// モジュールの読み込み
const grpc = require('grpc');
const messages = require('./user_pb');
const services = require('./user_grpc_pb');
// ユーザー情報の読み込み
const users = require('../users.json');
// 「get」プロシージャを実装する
function get(call, callback) {
// リクエストの「id」プロパティを取得
const userId = call.request.getId();
const user = users[userId];
if (!user) {
// 該当するユーザーが存在しないのでエラーを返す
const response = new messages.UserResponse();
response.setError(true);
response.setMessage("not found");
callback(null, response);
return;
}
// 戻り値として返すUserオブジェクトを作成する
const target = new messages.User();
target.setId(user.id);
target.setNickname(user.nickname);
target.setMailAddress(user.mail_address);
target.setUserType(messages.User.UserType[user.user_type]);
// UserResponseオブジェクトを作成する
const response = new messages.UserResponse();
response.setError(false);
response.setUser(target);
// UserResponseオブジェクトを返す
callback(null, response);
}
function main() {
// Serverオブジェクトを作成する
const server = new grpc.Server();
// Serverオブジェクトに定義したServicerクラスを登録する
server.addService(services.UserManagerService, { get: get });
// 1234番ポートで待ち受けするよう指定する
server.bind('0.0.0.0:1234', grpc.ServerCredentials.createInsecure());
// 待ち受けを開始する
server.start();
}
main();
クライアントの実装
続いてクライアントだが、こちらではまずプロトコル定義ファイルで定義したメッセージに対応するクラスを使ってリクエストに与えるメッセージを作成する。
const messages = require('./user_pb');
:
:
const request = new messages.UserRequest();
request.setId(userId);
続いてサービスに対応する「<サービス名>Client」クラス(今回は「UserManagerClient」クラス)を使ってクライアントオブジェクトを作成する。
const client = new services.UserManagerClient('localhost:1234',
grpc.credentials.createInsecure());
このクライアントオブジェクトにはリモートプロシージャに対応するメソッドが実装されているので、送信するメッセージに対応するオブジェクトを引数として与えてそれを実行すれば良い。
client.get(request, function(err, response) {
// 取得したレスポンスの表示
// toObject()メソッドでJavaScriptのオブジェクトに変換できる
console.log(response.toObject());
});
}
リモートプロシージャの実行結果は引数で指定したコールバック関数の第2引数として与えられるようになっている。また、エラー発生時には第1引数にその情報が格納される。なお、プロトコル定義ファイルで定義したメッセージ型に対応するオブジェクトは、toObject()メソッドでJavaScriptのオブジェクトに変換できる。
これらを実装したクライアントコード全文は次のようになる。
// モジュールの読み込み
const grpc = require('grpc');
const messages = require('./user_pb');
const services = require('./user_grpc_pb');
function main() {
// 引数をチェックする
if (process.argv.length < 3) {
console.log(`usage: node ${process.argv[1]} <user_id>`);
return;
}
const userId = Number(process.argv[2]);
if (isNaN(userId)) {
console.log(`error: invalid user_id \`${process.argv[2]}'`);
console.log(`usage: node ${process.argv[1]} <user_id>`);
return;
}
// リクエストオブジェクトを作成する
const request = new messages.UserRequest();
request.setId(userId);
// クライアントオブジェクトを作成する
const client = new services.UserManagerClient('localhost:1234',
grpc.credentials.createInsecure());
// リクエストを送信する
client.get(request, function(err, response) {
// 取得したレスポンスの表示
console.log(response);
console.log(response.toObject());
});
}
main();
サーバーを起動した状態でクライアントを実行すると、次のように結果が表示される。
$ node client.js 1
{ error: false,
message: '',
user:
{ id: 1,
nickname: 'admin',
mailAddress: 'admin@example.com',
userType: 1 } }
$ node client.js 0
{ error: true, message: 'not found', user: undefined }
プロトコル定義ファイルからの動的なサービス/メッセージ作成
Node.jsではあらかじめプロトコル定義ファイルからコードを生成するのではなく、サーバーもしくはクライアントの実行時に動的にプロトコル定義ファイルからオブジェクトのプロトタイプを生成する仕組みも用意されている。この仕組みは「@grpc/proto-loader」というパッケージで提供されており、こちらを利用する場合は事前にこのパッケージをインストールしておく必要がある。
こちらを利用して実装したサーバーのコードは次のようになる。
// モジュールの読み込み
const grpc = require('grpc');
const protoLoader = require('@grpc/proto-loader');
// プロトコル定義ファイルの読み込み
const PROTO_PATH = __dirname + '/../protos/user.proto';
const packageDefinition = protoLoader.loadSync(PROTO_PATH);
// プロトコル定義からオブジェクトのプロトタイプを構築する
const proto = grpc.loadPackageDefinition(packageDefinition);
// ユーザー情報の読み込み
const users = require('../users.json');
// 「get」プロシージャを実装する
function get(call, callback) {
// リクエストの「id」プロパティを取得
const userId = call.request.id;
const user = users[userId];
if (!user) {
// 該当するユーザーが存在しないのでエラーを返す
const response = { error: true, message: "not found" };
callback(null, response);
return;
}
// 戻り値として返すUserオブジェクトを作成する
// このとき、自動的にlowerCamelCaseからsnake_caseへの
// プロパティ名の変換が行われる点を考慮する必要がある
const response = { error: false,
user: { id: user.id,
nickname: user.nickname,
mailAddress: user.mail_address,
userType: user.user_type },
};
callback(null, response);
}
function main() {
// Serverオブジェクトを作成する
const server = new grpc.Server();
// Serverオブジェクトに定義したServicerクラスを登録する
server.addService(proto.UserManager.service, {get: get});
// 1234番ポートで待ち受けするよう指定する
server.bind('0.0.0.0:1234', grpc.ServerCredentials.createInsecure());
// 待ち受けを開始する
server.start();
}
main();
コードの基本的な流れは事前にプロトコル定義ファイルからコードを生成する場合と同じだが、こちらでは「@grpc/proto-loader」モジュールのloadSync()関数でプロトコル定義ファイルを読み込み、さらにgrpcモジュールのloadPackageDefinition()関数を使ってここで定義されているメッセージ型やサービスのプロトタイプを生成している。
const grpc = require('grpc');
const protoLoader = require('@grpc/proto-loader');
// プロトコル定義ファイルの読み込み
const PROTO_PATH = __dirname + '/../protos/user.proto';
const packageDefinition = protoLoader.loadSync(PROTO_PATH);
// プロトコル定義からオブジェクトのプロトタイプを構築する
const proto = grpc.loadPackageDefinition(packageDefinition);
また、この方法ではプロトコル定義ファイルで定義されたメッセージ型ではなく、JavaScriptのオブジェクトをそのままリモートプロシージャの引数として受け渡しできる点も異なる。なお、その際に自動的にlowerCamelCaseとsnake_caseとの変換が行われる点に注意したい。
同様に、クライアント側のコードは次のようになる。こちらでも、JavaScriptのオブジェクトをそのまま受け渡していることが分かる。
// モジュールの読み込み
const grpc = require('grpc');
const protoLoader = require('@grpc/proto-loader');
// プロトコル定義ファイルの読み込み
const PROTO_PATH = __dirname + '/../protos/user.proto';
const packageDefinition = protoLoader.loadSync(PROTO_PATH);
// プロトコル定義からオブジェクトのプロトタイプを構築する
const proto = grpc.loadPackageDefinition(packageDefinition);
function main() {
// 引数をチェックする
if (process.argv.length < 3) {
if (process.argv.length < 3) {
console.log(`usage: node ${process.argv[1]} <user_id>`);
return;
}
const userId = Number(process.argv[2]);
if (isNaN(userId)) {
console.log(`error: invalid user_id \`${process.argv[2]}'`);
console.log(`usage: node ${process.argv[1]} <user_id>`);
return;
}
// クライアントオブジェクトを作成する
const client = new proto.UserManager('localhost:1234',
grpc.credentials.createInsecure());
// リクエストを送信する
client.get({id: userId}, function(err, response) {
console.log(response);
});
}
main();
このように実装されたクライアントを実行すると、サーバーから受け取ったオブジェクトのプロパティがsnake_caseスタイルからlowerCamelCaseスタイルに変換されていることが分かる。
$ node client.js 0
{ error: true, message: 'not found' }
$ node client.js 1
{ user:
{ id: 1,
nickname: 'admin',
mailAddress: 'admin@example.com',
userType: 1 } }
なお、このようなsnake_caseルールとlowerCamelCaseなどの変換をどのように行うかや、Protocol Buffersのメッセージ型をJavaScriptのオブジェクトにどのように変換するかはloadSync()関数のオプションで指定できるようになっている。これについて詳しくはドキュメントを参照してほしい。
容易に異なる言語間での通信が行えるサーバー/クライアントを実装可能
このように、gRPCではプロトコル定義ファイルから簡単にサーバー/クライアントのコードを生成する仕組みが用意されており、利用者は定義されたリモートプロシージャに対応する関数やメソッドを実装するだけで簡単にサーバーを実装できるようになっている。また、クライアントからのリモートプロシージャ呼び出しも容易に行える。また、前述の通り、gRPCではサーバー/クライアントが異なる言語で実装されていても、同一のプロトコル定義ファイルからコードが生成されていれば問題なく通信が行えるようになっている。
今回は紹介していないが、gRPCではこれ以外にもサーバーのヘルスチェックを行う仕組みや、メタデータを扱う仕組みなど、より高度な仕組みも用意されている。こういった機能を活用することで、より複雑な処理を実装することも可能だ。
なお、gRPCは現在公式にサポートされているプログラミング言語向けにおいては活発に開発が行われている。また、技術面でもHTTP/2などの最新技術が採用されており、サポートやメンテナンスの面でもしばらくは不安なしに利用できるだろう。