DeepFake使ってみた!? MacでGPUを使った機械学習

こんにちは! テリーです。Apple SiliconのM1チップを搭載した新しいMacは、当初の期待以上の速度が出ているようで、パソコンの新モデルとしては久しぶりに購買意欲をかきたててくれました。16インチのMacBookProが出ればすぐに購入しようと思います。さて、M1はCPUの速度と価格の方に注目されがちですが、GPUも劇的に進化しています。「機械学習といえばNVIDIA」の時代が何年も続いており、TensorflowのGPU版が使えないMacは機械学習トレーニング環境としてあまり使われていませんが、M1の圧倒的な処理能力が使えるならば、多少の文法修正は受け入れられます。ここから勢力図の逆転もありえそうです。
突然ですが、最近映画を見ました。人気小説を原作にした映画で、主演俳優は原作のイメージそのものでしたが、助演の方の顔が原作とまったくイメージが異なっていて台無しだと、娘が怒っていました。じゃあ誰ならよかったのか?と聞くと人気アイドルグループの○○くんだと。その話を聞いた時、自分で考えた忖度なしの最強キャスティングの映画・映像を娘のためだけに作ってみようと思いました。顔を置き換えればできるんじゃないかと。そこで、今回はDeepFakeを機械学習のサンプルアプリとして、MacでGPUを使った機械学習の手順を紹介します。
目次
今回紹介する技術
PlaidMLとは
PlaidMLは、NVIDIA以外のGPUを機械学習に使用できるようにした、Python向けのフレームワークです。
Intelが中心となって開発されており、Intel製GPU、AMD製GPU、OpenCLに対応しています。もちろんNVIDIAも対応しているため、PlaidMLを使って書いたプログラムはMac, Windows, LinuxのどのOSでも、GPUを使った機械学習をすることができます。M1向けにも期待できるでしょう。
DeepFakeとは
DeepFakeは、機械学習を使用して映像の中の顔をまったく別人のものに置き換えるソフトウェアです。
機械学習をMacで行うメリット
クラウドを使わずにクライアントパソコンで機械学習をする一つのメリットとして、途中経過がその場で確認できるということがあります。クラウド上で機械学習をする場合は、学習処理に影響を与えないようにファイルをコピーする必要があり、手間がかかります。学習する画像の中に不適切なデータが含まれていないかどうか、クライアントパソコンであれば数百枚を一覧表示して目視で確認することができます。動画、音声のようなメディアデータの機械学習処理は、クライアントパソコンで前処理したデータを数十分から1時間かけて学習し、ある程度成果の目算をつけ、プログラム・データ・モデルに自信を持ってから、クラウドで一括処理をすると両者のいいとこ取りができます。
環境
本記事の実行環境は下記を使用しています。
- MacBook Pro 16インチ 2019
- GPU AMD Radeon Pro 5500M 4GB
- macOS Big Sur 11.0.1
- PlaidML 0.7.0
- FaceSwap 2.0.0
PlaidMLのセットアップ
ターミナルを新規で開き、下記を順に実行します。
python3 -m venv plaidml-venv source ~/plaidml-venv/bin/activate pip install 'tensorflow>=2.2.0,<2.3.0' 'h5py < 3.0.0' pip install -U plaidml-keras plaidml-setup # "metal_amd_radeon_pro_5500m.0"の「4」を選択 export KERAS_BACKEND=plaidml.keras.backend pip install plaidml-keras plaidbench plaidbench keras mobilenet
h5pyライブラリの最新バージョン3.xがtensorflowの2.2.xと相性が悪いため、ダウングレードする必要があります。
tensorflowもバージョン未指定の場合は2.3かそれ以降がインストールされ、PlaidML/DeepFakeと相性がよくないため、2.2.xにダウングレードします。
plaidml-setupコマンドを実行すると、下記のように選択肢が示されます。「Enable experimental device support? (y,n)[n]:」のところで「y」キーを押し、その後に出る選択肢の中から「4 : metal_amd_radeon_pro_5500m.0」を選択してください。その後保存するか聞かれますので「y」キーを押して保存します。
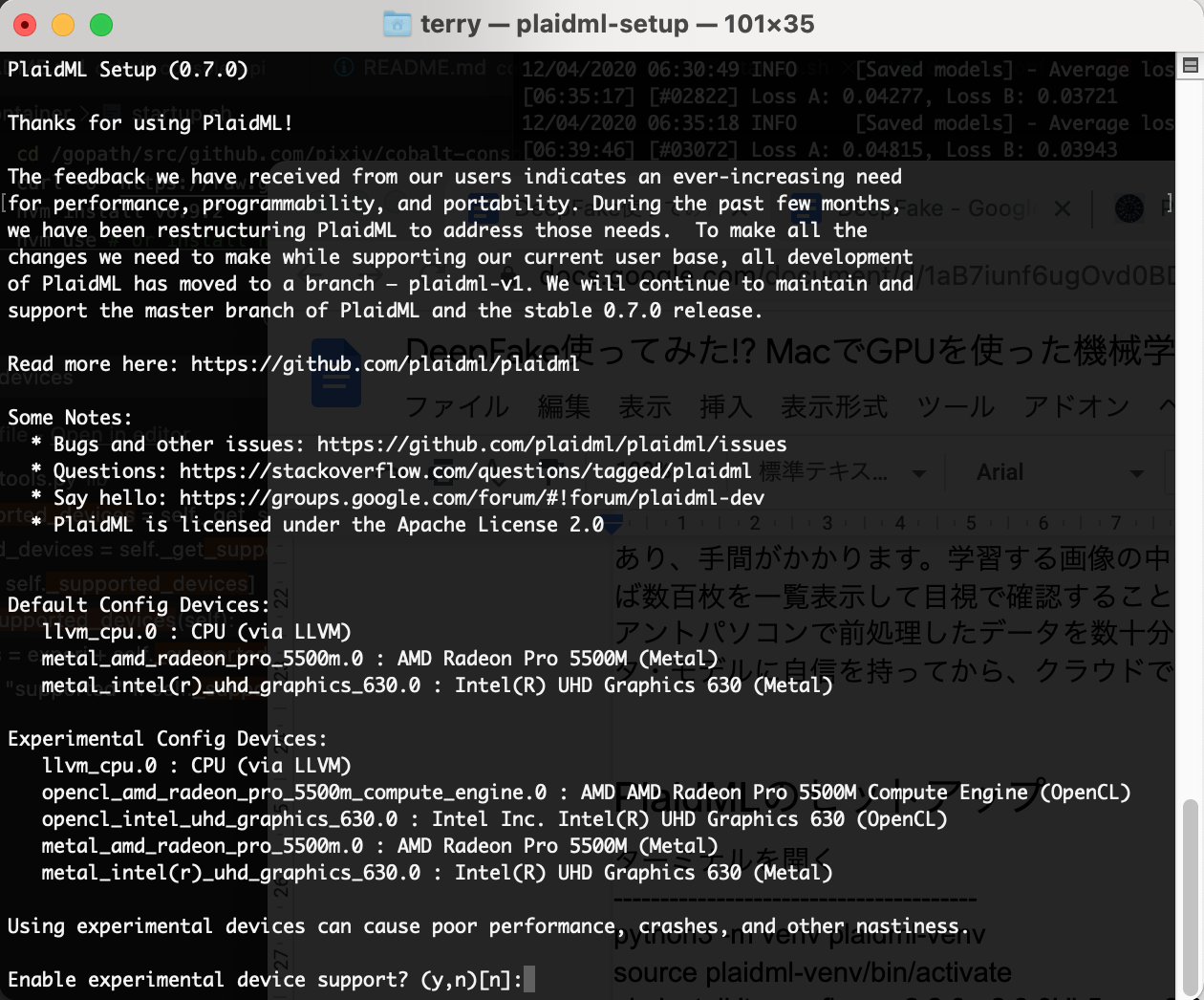
最後にPlaidML公式ベンチマークアプリ「plaidbench keras mobilenet」でGPUが使われるのを確認します。
「Example finished, elapsed: 0.429s (compile), 5.542s (execution)」というように5秒台で終わればGPUが使われています。CPUが使われた場合は9〜11秒台になります。差が小さいのは、ベンチマークに使用しているデータ量が小さいためです。
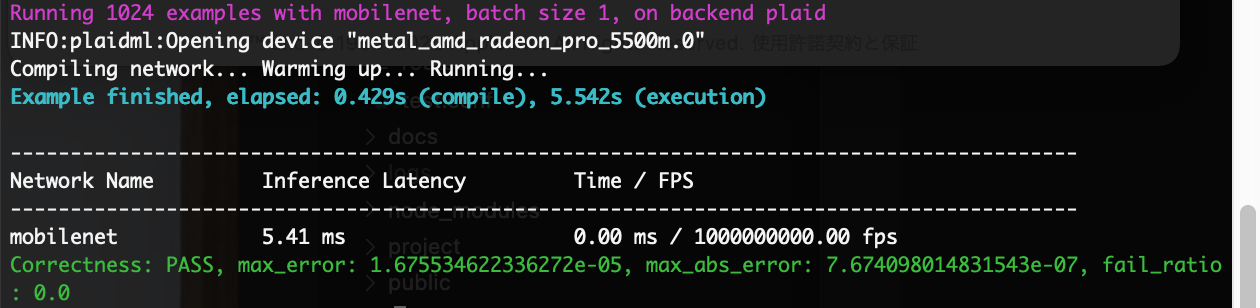
GPU使用率の確認
macOS付属の「アクティビティモニタ」を開くと、GPU使用率を見ることができます。
「CPU」タブの一番上にプロセス名「Python」または「WindowServer」の行で「% GPU」が90%近い数字が書かれていればGPUが使われています。GPUが使われていない場合は「0.0」になります。
またメニューから「ウインドウ」-「GPUの履歴」を選択すると、上図のようなグラフが表示され、5秒に1回更新されます。
グラフでGPUが使われていない場合は、上のplaidml-setupと環境変数KERAS_BACKENDが正しくセットされているか確認してください。
DeepFakeのセットアップ
ターミナルを新規で開き、下記を順に実行します。
python3 -m venv plaidml-venv source ~/plaidml-venv/bin/activate export KERAS_BACKEND=plaidml.keras.backend git clone --depth 1 https://github.com/deepfakes/faceswap.git cd faceswap pip install -r requirements_amd.txt python faceswap.py
最後のコマンド「python faceswap.py」で、
「First time configuration. Please select the required backend 1: AMD, 2: CPU, 3: NVIDIA:」
とfaceswap.pyの初回実行時に聞かれます。ここでは「1: AMD」を選択します。
本記事執筆時点で最新のDeepFake2.0.0とPlaidML0.7.0の組み合わせでは、GPUの検出に失敗します。
「No GPU detected. Switching to CPU mode」と表示され、GPUが使われずにCPU計算となります。
テキストエディタで「lib/plaidml_tools.py」ファイルを開き、194行目付近、214行目付近を下記のように書き換えてください。修正後「python faceswap.py」を実行すると、「No GPU detected. Switching to CPU mode」が表示されなくなります。
supported = devices
# supported = [device for device in devices
# if device.details
# and json.loads(device.details.decode()).get("type", "cpu").lower() == "gpu"]
experi = devices
# experi = [device for device in devices
# if device.details
# and json.loads(device.details.decode()).get("type", "cpu").lower() == "gpu"]
学習処理開始手順
- 学習用の2つの映像を手配
- 動画から静止画を出力
- 顔抽出
- 不要顔画像削除
- トレーニング
- 顔置換
- 静止画から動画を生成
これらを一連のシェルスクリプトにまとめると次のようになります。順に説明します。
# 定数定義
A=taro
B=jiro
Aface=${A}face
Bface=${B}face
Aout=${A}out
A2B=${A}2${B}
INPUT_A=${A}.mp4
INPUT_B=${B}.mp4
AUDIO_A=${Aout}.aac
OUTPUT_A=${Aout}.mp4
rm -rf $A && mkdir $A && ffmpeg -i $INPUT_A -vf fps=25 -t 10 $A/%06d.png
rm -rf $B && mkdir $B && ffmpeg -i $INPUT_B -vf fps=25 -t 10 $B/%06d.png
rm -rf $Aface && python faceswap.py extract -i $A -o $Aface
rm -rf $Bface && python faceswap.py extract -i $B -o $Bface
***ここで人力作業 不要画像除外***
python tools.py alignments -j remove-faces -fc $Aface -a $A/alignments.fsa
python tools.py alignments -j remove-faces -fc $Bface -a $B/alignments.fsa
python faceswap.py train -A $Aface -B $Bface -m $A2B -ala $A/alignments.fsa -alb $B/alignments.fsa -p
rm -rf $Aout && python faceswap.py convert -i $A -o $Aout -m $A2B
ffmpeg -i $INPUTMOVIE_A -t 10 -y -acodec copy -y $AUDIO_A
ffmpeg -i $Aout/%06d.png -i $AUDIO_A -c:v libx264 -pix_fmt yuv420p -acodec copy -y $OUTPUT_A
1.学習用の2つの動画素材の手配
2つの映像を用意してください。
ffmpegで読み込める形式ならばmp4でもmovでもwebmでも構いません。
最低10秒。最初は短めにして、使い慣れてから尺を伸ばすのがオススメです。
同じ秒数や解像度である必要はありません。
注意点
- 1人でカメラに向かってしゃべっている映像が望ましいです
1つの映像の中に2人以上写っている映像を使用すると、置換したい顔だけを残し、それ以外を削除する作業が必要になります。 - メガネをしていない人が望ましいです
メガネをしている人は顔検出や横向きしたときに相性が悪く、きれいに変換できません。
例として、taro.mp4とjiro.mp4を用意したとします。faceswapと同じフォルダに動画をコピーしてください。
以降、1つ目の動画を動画A, 2つ目の動画を動画Bと呼びます。動画Aの出演者の顔を、動画Bの顔に置き換えます。
2.動画から静止画を出力
ffmpegを使用し、動画A,Bから静止画フレームをPNGで保存します。「-t 10」は「10秒分の動画を出力」という意味になります。
ffmpeg -i $INPUT_A -vf fps=25 -t 10 $A/%06d.png ffmpeg -i $INPUT_B -vf fps=25 -t 10 $B/%06d.png
3. 顔抽出
切り出した画像フレームA,Bから顔を抽出し、別フォルダに顔画像だけが保存されます。
顔抽出情報ファイルalignments.fsaというファイルが元の画像フレームのフォルダに出力されます。
少し時間がかかります。2分〜5分程度です。
本コマンド完了時に出てくるログの中で、「Images found」の値と「Faces detected」の値が異なっている場合、目的の顔以外のものが顔として検出されたことを示しています。次のセクションで不要なデータを削除します。
rm -rf $Aface && python faceswap.py extract -i $A -o $Aface rm -rf $Bface && python faceswap.py extract -i $B -o $Bface
4. 不要顔画像削除
手や植物など肌色・土色のものを顔と誤検出することがあります。それらを削除していきます。作業としては、顔を抽出したフォルダをファインダーで開き、画像一覧を表示しながら誤検出したものを目視で一つずつ手動で選択し、フォルダから削除します。
また横を向いたり、下を向いたりするシーンなどで、画像が崩れてしまっているものも削除してください。
複数人が登場しているシーンや、Tシャツ、壁紙、ポスターなどに顔が書かれている場合も同様に削除してください。
その後、下記コマンドで顔抽出情報ファイルalignments.fsaを更新します。
python tools.py alignments -j remove-faces -fc $Aface -a $A/alignments.fsa python tools.py alignments -j remove-faces -fc $Bface -a $B/alignments.fsa
5. トレーニング
下記のコマンドで、抽出した顔画像データを機械学習します。めちゃめちゃ時間がかかります。
コマンドに「-p」をつけると、250回(約5分)ごとに1回プレビューを作成して画面に表示します。プレビューが不要な場合は「-p」を削除します。
python faceswap.py train -A $Aface -B $Bface -m $A2B -ala $A/alignments.fsa -alb $B/alignments.fsa -p
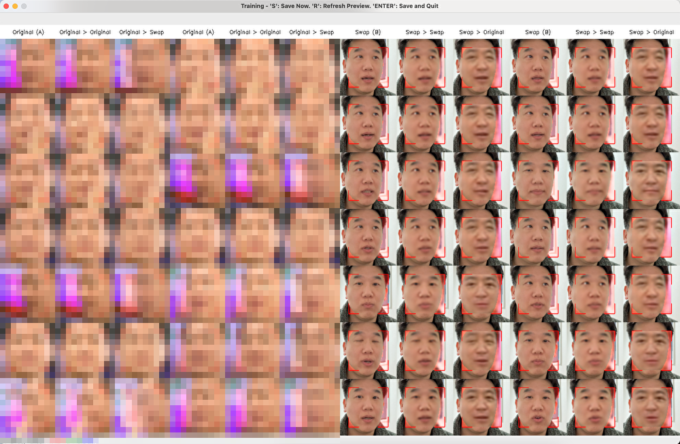
ターミナルの画面に「[#00123]」という情報と「Loss A: 0.54321, Loss B: 0.54321」という情報が表示・更新されます。[#00123]はただのカウンタです。Lossは学習結果がどの程度信用できるかを数値で表しています。ゼロに近づくほどよい結果ですが、0.03台で長く停滞します。0.02台になってくるとかなりもっともらしいモデルになります。カウンタは私の環境では1秒に1ずつくらい増えていきます。カウンタが3万くらいになると、そろそろ止めてもいいかな?という感じになります。3万は約9時間です。夜寝る前に実行し、朝起きたときにはできあがっています。
はじめてDeepFakeに触る場合はカウンタが250を超えたあたりで、ターミナルでエンターキーを押して停止して、次のコマンドに進んでください。学習回数・時間が少ない場合でも、全体の作業工程はまったく変わりません。変わるのは顔の品質だけです。
エンターキーで中断したあと、再度同じコマンドを打つと、中断したところから再開されますので、何度でも自信を持って停止してください。
python faceswap.py train -A $Aface -B $Bface -m $A2B -ala $A/alignments.fsa -alb $B/alignments.fsa -p
6. 顔置換
学習したモデルを元に、画像フレームAの顔をBの顔に置き換えて出力します。数十秒〜1分程度ですぐに終わります。
rm -rf $Aout && python faceswap.py convert -i $A -o $Aout -m $A2B
7. 静止画から動画を生成
動画Aから音声データを10秒切り出します。
静止画と音声を合成し、動画ファイルとして出力します。
出力された動画はQuickTimeやffplayで再生して確認できます。
確認後に(5)に戻り、納得が行くまでトレーニングを続けます。
ffmpeg -i $INPUTMOVIE_A -t 10 -y -acodec copy -y $AUDIO_A ffmpeg -i $Aout/%06d.png -i $AUDIO_A -c:v libx264 -pix_fmt yuv420p -acodec copy -y $OUTPUT_A
元動画と顔置換した動画を並べて比較したい場合は、下記のコマンドを実行してください。上半分が元動画、下半分が生成した動画になります。
ffmpeg -i $A/%06d.png -i $Aout/%06d.png -filter_complex "vstack" -i $AUDIO_A -c:v libx264 -pix_fmt yuv420p -acodec copy -y $OUTPUT_A
DeepFake成果物取り扱いの注意
DeepFakeの出力する映像は、顔が置き換わっているかどうかよく見ないと判断が付きません。他人の映像を元に生成したDeepFake動画をネットに公開すると、著作権・肖像権・人格権の侵害とされ、厳しく罰せられます。アメリカの大統領選では候補者の顔を使って、差別的な発言の映像が作られました。日本でもアダルトビデオに人気女優の顔を適用・公開して警察沙汰になっています。自分以外の顔を使う場合は、個人的な利用の範囲で楽しみましょう。
さらに挑戦したい方へ
この手順で学習したモデルを使って、学習していない長い映像に対しても適用可能です。上記工程のうち「5.トレーニング」だけ除外すれば、数十分の動画の全部の顔を置き換えることができます。またこのモデルをカメラ画像に適用すれば、リアルタイム顔変換が可能です。ぜひ挑戦してみてください。
有料サービスのご紹介
WebRTCを利用した会員制ライブ配信サービスを短期間で導入したい方、大規模配信のためのサーバ構築・インフラ運用を専門家に任せたい方は「ImageFlux Live Streaming」をご検討下さい。ポスプロ会社様向けに動画編集のコラボレーションシステムとして利用された実績があります。WebRTC SFUという技術を用いて、配信映像をサーバに中継させる仕組みです。1対多の会員制映像配信に特に強みがあり、初期の利用コストが低価格に抑えられます。