さくらのクラウドのコンパネから設定できるオートスケール(オープンβ)を試してみる

オートスケール機能につきましては、2022年7月28日に正式提供を開始いたしました(さくらのクラウドニュース)。オープンβ版では実装されていなかった新たな機能が追加されておりますので、ぜひご活用ください。詳細につきましては「さくらのクラウドドキュメント オートスケール」をご確認ください。
5月26日(木)よりリリースされた、さくらのクラウドのコントロールパネルで設定できる「オートスケール」機能を試してみましょう。
オートスケールとは
さくらのクラウドの「オートスケール」機能とは、サーバーの負荷を監視し、必要に応じて設定した負荷の閾値に到達したときにサーバーのリソースを追加したり、負荷が減った場合はリソースを減らす機能です。 これによって、監視者がパフォーマンスを常に監視してリソースのコントロールをする必要がなくなります。
制御方法
オートスケールのリソースコントロールの考え方は主に2つあります。
垂直スケール
サーバーのスペックを上げたり、下げたりしてコントロールする方法が垂直スケールです。上げることをスケールアップ、下げることをスケールダウンと呼んだりもします。 スペックの変更時にサーバーを停止する必要があるため、ダウンタイムが発生します。アプリケーションの継続稼働を考えると、後述の水平スケールと比較して、採用は少ないでしょう。
水平スケール
サービスを提供するサーバーのグループを構成し、サーバーを新たに追加したり、削除したりしてコントロールする方法が水平スケールです。追加をスケールアウト、削除をスケールインとも呼びます。この機能は一般的に「サーバーなどリソースのグループ」内でサーバー数を自動操作します。そのため、新しいサーバーの追加時、グループ内で既に存在するサーバー上のアプリケーションを停止することなく稼働できます。 一般的なクラウドサービスで単に”オートスケール”として提供される場合はこちらを指すことが多いでしょう。
垂直スケールを試してみる
それではまず、スペックの増減をコントロールする垂直スケールを試してみましょう。
スケールさせるサーバーを作成する
垂直スケールの動作確認には、サーバーは1台あれば良いでしょう。
まず、サーバーを1台作成します。ゾーンは好きなところで良いですが、今回は石狩第1ゾーンにしましょう。
| 名前 | プラン | NIC | OS |
|---|---|---|---|
| auto-scale-server1 | 1仮想コア / 1GB | 共有セグメント インターネット | AlmaLinux 8.4 |
サーバー一覧画面から、次の画面のように作成されたサーバーを確認できます。
垂直スケールの設定をする
さくらのクラウドの「オートスケール」機能をコントロールパネルから利用する場合、事前に「作成・削除」の権限があるAPIキーを作成する必要があります。さくらのクラウドホーム画面よりAPIキーを作成しておきます。 コントロールパネル左のメニューより、オートスケールを選択し、右上の追加ボタンをクリックして設定していきましょう。
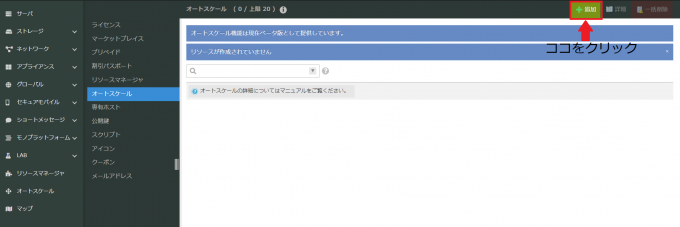
すると、次の画面になります。
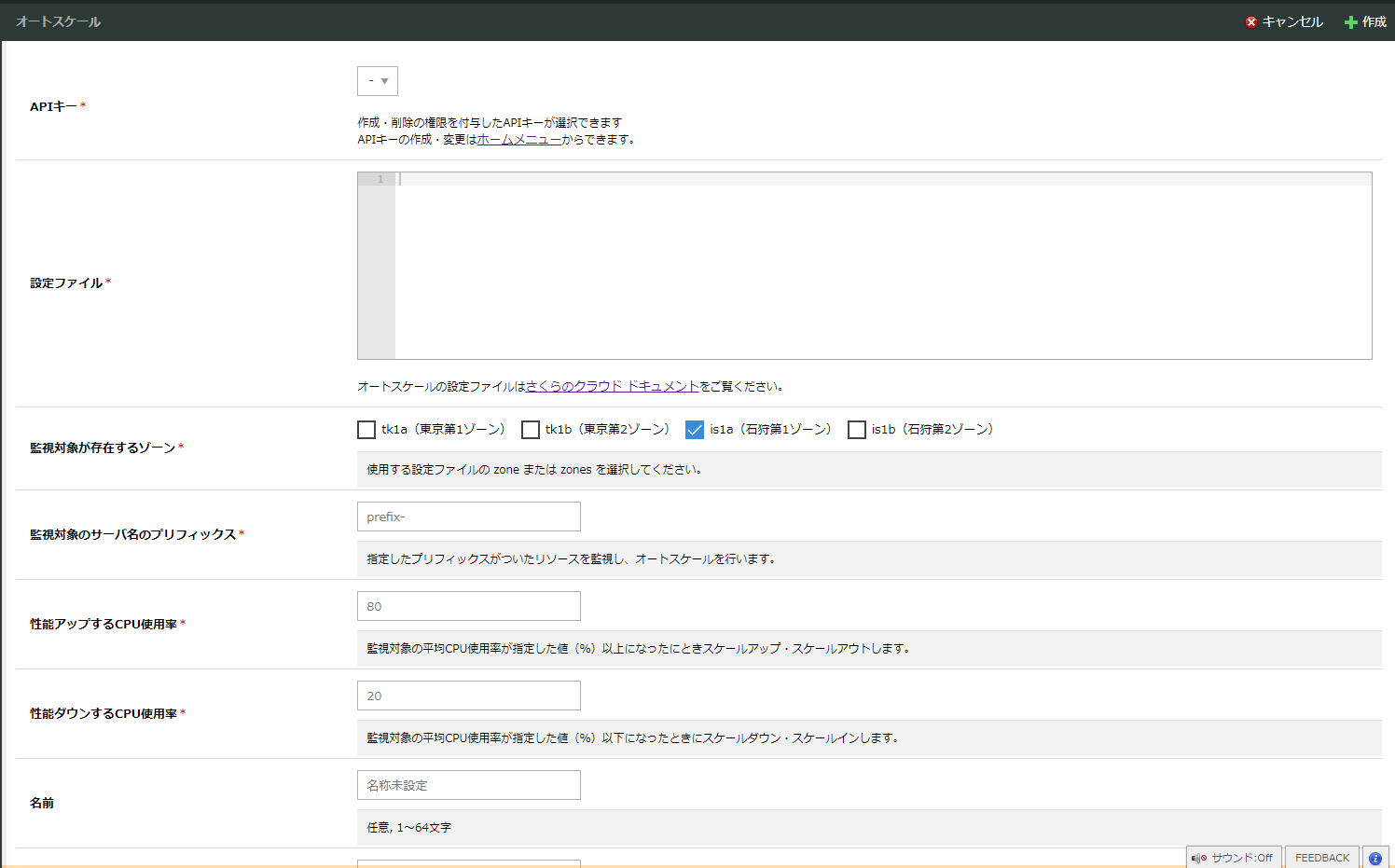
必須の設定項目は以下の項目です。
- APIキー
- 設定ファイル
- 監視対象が存在するゾーン
- 監視対象のサーバー名のプリフィックス
- 性能アップするCPU使用率
- 性能ダウンするCPU使用率
1. APIキー
APIキーはさくらのクラウドホーム画面よりAPIキーを作成しておけば、リストから選択して利用できます。
2. 設定ファイル
今回は次のようにしました。
resources:
- type: Server
selector:
names: ["auto-scale-server"]
zones: ["is1a"]
shutdown_force: false
plans:
- core: 1
memory: 1
- core: 2
memory: 2
- core: 4
memory: 43段階でスケールするようにしています。最小は「1仮想コア / 1GB」、次に「2仮想コア / 2GB」、最大は「4仮想コア / 4GB」となります。
3. 監視対象が存在するゾーン
オートスケールによってコントロールさせたいサーバーがあるゾーンを選択してください。 複数選択も可能なので、他のゾーンも同時にオートスケールの対象にできます。 今回は、サーバーを作成した「is1a(石狩第1ゾーン)」を選択します。
4. 監視対象のサーバ名のプリフィックス
対象が存在するゾーンの接頭辞に合致したサーバーを指定します。 今回、対象にしたいサーバー名は"auto-scale-server1"で、石狩第1ゾーンに他のサーバーはないので、"auto-scale-server"を指定してみましょう。
5. 性能アップするCPU使用率
今回はオートスケール機能を試したいだけですので、閾値は低めに設定します。「60」を指定します。
6. 性能ダウンするCPU使用率
サーバーで特定のアプリケーションを動かさなければ20%を下回ると思われますので、「20」を指定します。
垂直スケールの動作を確認する
それでは、サーバー「auto-scale-server1」にログインして、負荷をかけてみましょう。 世の中には様々なベンチマークツールや、負荷を計測するツールがありますが、CPUに負荷がかかればよいので、さくらのクラウドのAlmaLinux 8.4で最初から使えるyesコマンドの出力を/dev/nullに捨てることで大きく負荷をかけ、topコマンドでチェックしましょう。
yes > /dev/null &このようにしてバックグラウンドで実行できます。その後、topコマンドで負荷の状況を確認してみます。 topコマンドで大きな負荷がかかっていると確認できます。しかし、実際のところ、オートスケール機能がトリガーとするのは、アクティビティグラフ の「CPU TIME」であることに注意してください。 負荷が足らない場合、前述のコマンドを追加で動かせば更に負荷をかけられます。
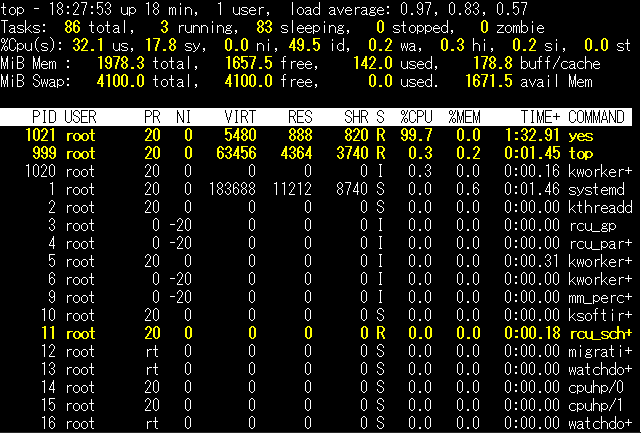
さくらのクラウドのドキュメントによると10分間隔で検知するようですので、少し待ちます。
スケールアップが始まると、サーバーは一度、シャットダウンされます。コントロールパネルでサーバーのスペックが変更されているか確認してみましょう。
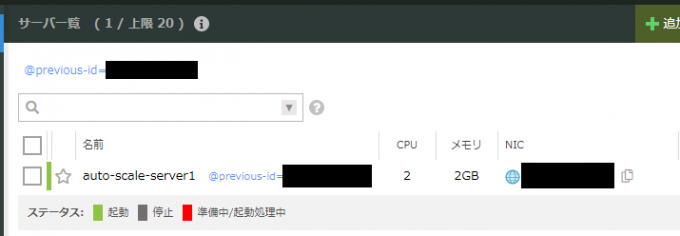
2仮想コア / 2GB のスペックに変更されているのが確認できると思います。
この時のログをコントロールパネルから確認できます。オートスケールの画面から、対象のオートスケール設定を選択し「詳細」をクリックしてください。
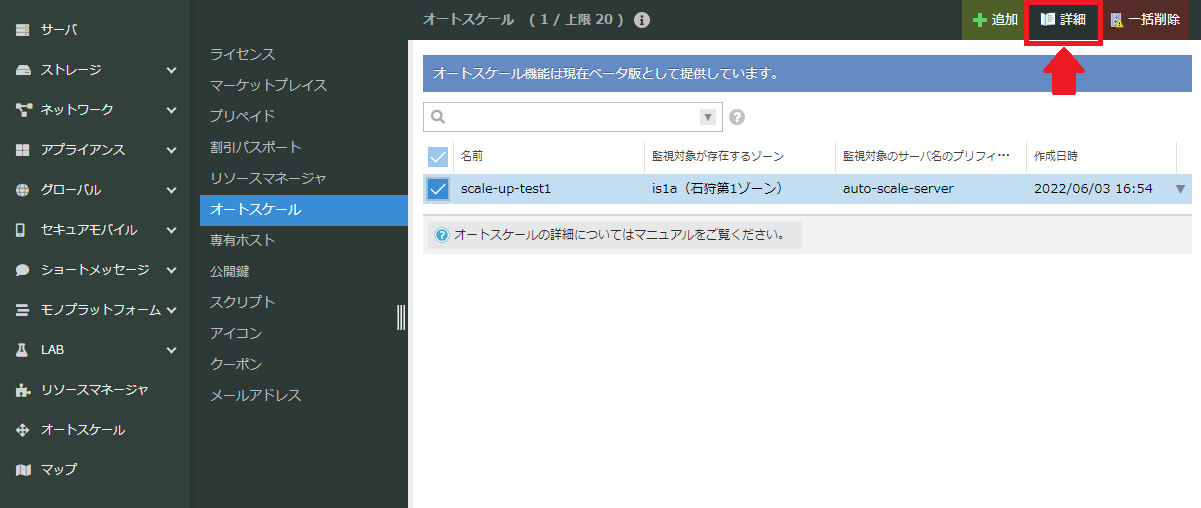
この時の該当のログは次のように表示されていました。
Jun 06 17:55:43 prod1 systemd[1]: Started SakuraCloud AutoScaler Input for XXXXXXXXXXXX.
Jun 06 17:55:44 prod1 cpu_threshold_scaling.sh[1923568]: 2022/06/06 17:55:44 auto-scale-server1 zone:is1a cores:1 cpu:1.030000 time:2022-06-06 17:50:00 +0900 JST
Jun 06 17:55:44 prod1 cpu_threshold_scaling.sh[1923568]: 2022/06/06 17:55:44 auto-scale-server1 avg:103.000000
Jun 06 17:55:44 prod1 cpu_threshold_scaling.sh[1923568]: Do Up
Jun 06 17:55:44 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:55:44+09:00 level=info request=Up message="request received"
Jun 06 17:55:44 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:55:44+09:00 level=info request=Up source=default resource= status=JOB_ACCEPTED
Jun 06 17:55:44 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:55:44+09:00 level=info request=Up source=default resource= status=JOB_RUNNING
Jun 06 17:55:44 prod1 cpu_threshold_scaling.sh[1923568]: status: JOB_ACCEPTED, job-id:
Jun 06 17:55:44 prod1 systemd[1]: autoscaler_113401014571_input.service: Succeeded.
Jun 06 17:55:44 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:55:44+09:00 level=info request=Up source=default resource= status=ACCEPTED
Jun 06 17:55:44 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:55:44+09:00 level=info request=Up source=default resource= status=RUNNING
Jun 06 17:55:44 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:55:44+09:00 level=info request=Up source=default resource= status=RUNNING log="shutting down..."
Jun 06 17:56:16 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:56:16+09:00 level=info request=Up source=default resource= status=RUNNING log="shut down"
Jun 06 17:56:16 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:56:16+09:00 level=info request=Up source=default resource= status=RUNNING log="plan changing: {Core:2, Memory:2}"
Jun 06 17:56:17 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:56:17+09:00 level=info request=Up source=default resource= status=RUNNING log="plan changed: {ServerIDFrom:XXXXXXXXXXXX, ServerIDTo:113401032293}"
Jun 06 17:56:17 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:56:17+09:00 level=info request=Up source=default resource= status=RUNNING log=starting...
Jun 06 17:57:09 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:57:09+09:00 level=info request=Up source=default resource= status=RUNNING log=started
Jun 06 17:57:09 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:57:09+09:00 level=info request=Up source=default resource= status=RUNNING log="waiting for setup to complete: setup_grace_period=60"
Jun 06 17:58:09 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:58:09+09:00 level=info request=Up source=default resource= status=DONE
Jun 06 17:58:10 prod1 autoscaler[1918713]: timestamp=2022-06-06T17:58:10+09:00 level=info request=Up source=default resource= status=JOB_DONE
「AutoScaler」や「cpu_threshold_scaling.sh」のログから、確かに自動でサーバーのスペックが上がっている様子ですね。
もちろん、このサーバーが「2仮想コア / 2GB」のスペックに対して設定した負荷の閾値を超えれば、「4仮想コア / 4GB」になります。
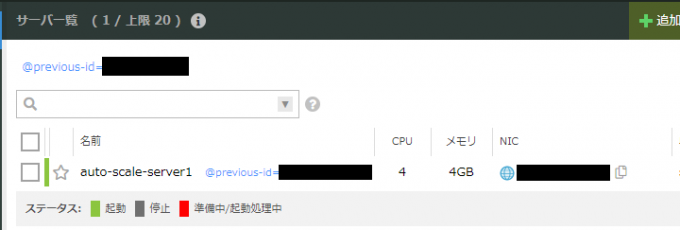
そして、負荷をかけずに放置すれば、「4仮想コア / 4GB」→ 「2仮想コア / 2GB」 → 「1仮想コア / 1GB」と設定した最小のスペックである、「1仮想コア / 1GB」まで段階的にスケールダウンしていきます。
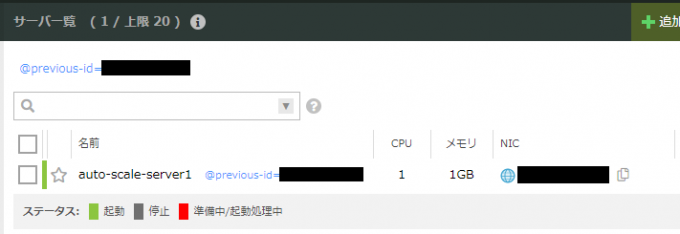
サーバーのスケールダウンのログも確認できますね。
Jun 06 18:51:43 prod1 systemd[1]: Started SakuraCloud AutoScaler Input for XXXXXXXXXXXX.
Jun 06 18:51:44 prod1 cpu_threshold_scaling.sh[1927281]: 2022/06/06 18:51:44 auto-scale-server1 zone:is1a cores:2 cpu:0.050000 time:2022-06-06 18:45:00 +0900 JST
Jun 06 18:51:44 prod1 cpu_threshold_scaling.sh[1927281]: 2022/06/06 18:51:44 auto-scale-server1 avg:2.500000
Jun 06 18:51:44 prod1 cpu_threshold_scaling.sh[1927281]: Do Down
Jun 06 18:51:45 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:51:45+09:00 level=info request=Down message="request received"
Jun 06 18:51:45 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:51:45+09:00 level=info request=Down source=default resource= status=JOB_ACCEPTED
Jun 06 18:51:45 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:51:45+09:00 level=info request=Down source=default resource= status=JOB_RUNNING
Jun 06 18:51:45 prod1 cpu_threshold_scaling.sh[1927281]: status: JOB_ACCEPTED, job-id:
Jun 06 18:51:45 prod1 systemd[1]: autoscaler_113401014571_input.service: Succeeded.
Jun 06 18:51:45 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:51:45+09:00 level=info request=Down source=default resource= status=ACCEPTED
Jun 06 18:51:45 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:51:45+09:00 level=info request=Down source=default resource= status=RUNNING
Jun 06 18:51:45 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:51:45+09:00 level=info request=Down source=default resource= status=RUNNING log="shutting down..."
Jun 06 18:52:16 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:52:16+09:00 level=info request=Down source=default resource= status=RUNNING log="shut down"
Jun 06 18:52:16 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:52:16+09:00 level=info request=Down source=default resource= status=RUNNING log="plan changing: {Core:1, Memory:1}"
Jun 06 18:52:18 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:52:18+09:00 level=info request=Down source=default resource= status=RUNNING log="plan changed: {ServerIDFrom:XXXXXXXXXXXX, ServerIDTo:XXXXXXXXXXXX}"
Jun 06 18:52:18 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:52:18+09:00 level=info request=Down source=default resource= status=RUNNING log=starting...
Jun 06 18:53:10 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:53:10+09:00 level=info request=Down source=default resource= status=RUNNING log=started
Jun 06 18:53:10 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:53:10+09:00 level=info request=Down source=default resource= status=RUNNING log="waiting for setup to complete: setup_grace_period=60"
Jun 06 18:54:10 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:54:10+09:00 level=info request=Down source=default resource= status=DONE
Jun 06 18:54:11 prod1 autoscaler[1918713]: timestamp=2022-06-06T18:54:11+09:00 level=info request=Down source=default resource= status=JOB_DONE
以上で垂直スケールの動作を試せました。
水平スケールを試してみる
今度は垂直スケールの場合よりも、少しだけ実際のアプリケーションデプロイ環境を想定した構成で、水平スケールを試してみましょう。
さくらのクラウドドキュメントではエンハンスドロードバランサーを利用し、拠点間を跨いだ構成の例が記載されていますが、今回は分かりやすく試したいので、一つのゾーンのみで構成します。
準備
今回用意する構成は次の図のような構成です。
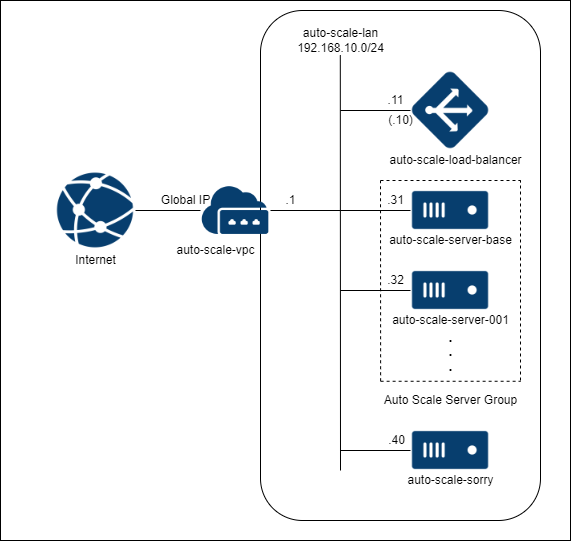
オートスケールの対象とするのは、図中のAuto Scale Server Group です。
負荷がかかると、このサーバーリソースのグループ中でサーバーが増えていくように設定しましょう。
ソーリーサーバーも用意しています。
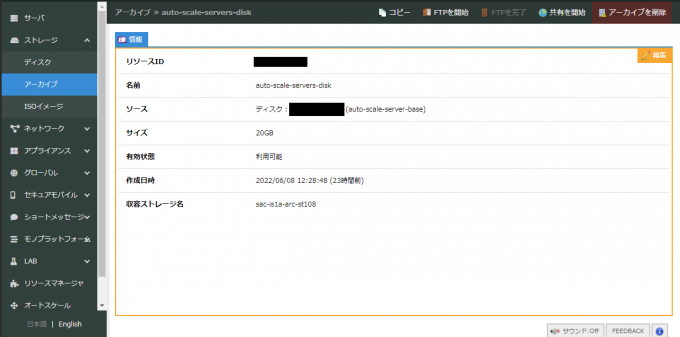
スケールアウトする際に、サーバーが作成されます。そのため、あらかじめ、必要な設定をしているサーバーの元を用意する必要があります。 そのため、元となるサーバーのディスク(今回の場合はauto-scale-server-baseのディスク)をストレージのアーカイブ機能を使って、作っておきましょう。
水平スケールのコントロールパネルにおける設定は、垂直スケールを設定したときと、設定ファイルの記述が異なります。 今回は次のような設定にしています。
resources:
- type: "ServerGroup"
name: "AutoScaleServerGroup"
server_name_prefix: "auto-scale-server"
zone: "is1a"
min_size: 1 # 最小1台
max_size: 5 # 最大5台
template: # 「仮想1コア / 1GB」のスペックのサーバーが追加されます。
plan:
core: 1
memory: 1
dedicated_cpu: false
disks:
- source_archive: "auto-scale-servers-disk" # ディスクは予めアーカイブに用意していたものを使います。
edit_parameter:
disabled: false
host_name_prefix: "auto-scale-server"
password: "totemohimitu"
startup_scripts: # Apacheでサーバーを公開しているので、公開するコンテンツを作っておきます。
- |
#!/bin/bash
cat <<EOL > /var/www/html/index.html
<!DOCTYPE html>
<html>
<title>AUTO SCALE TEST SERVER</title>
<body>
<p>This is {{ .Name }}</p>
</body>
</html>
EOL
network_interfaces:
- upstream:
names: ["auto-scale-lan"]
default_route: "192.168.10.1"
assign_cidr_block: "192.168.10.31/24" # NICに割り当てられるIPの範囲を設定することができます。
assign_netmask_len: 24スケールの変更を観測しやすくするため、「仮想1コア / 1GB」にしてます。実際にサービスを提供する場合であれば、「仮想1コア / 1GB」が適切な選択であるとは限りませんので、スペック選択には注意してください。
今回のロードバランサーはアプライアンスの「ロードバランサー」です。バランシングの設定を事前にしておく必要があります。
エンハンスドロードバランサー(エンハンスドLB)であれば、この設定は必要ありません。
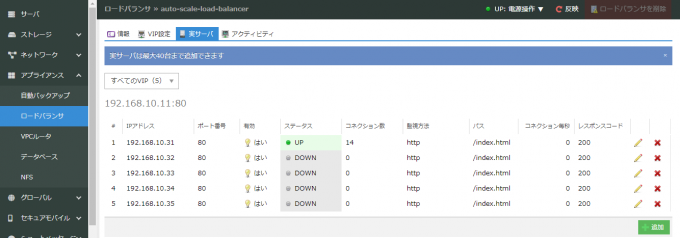
最小の構成であれば、1台のサーバーのみがAuto Scale Server Groupに存在します。
この構成を構築する詳細な方法は割愛します。詳しくは、さくらのクラウドのドキュメントの「ロードバランサー」を参照してください。
試してみる
HTMLのbody中に設定したサーバー名も含めていますので、curlコマンドでサーバーに対してリクエストを実行し、応答を確認しましょう。
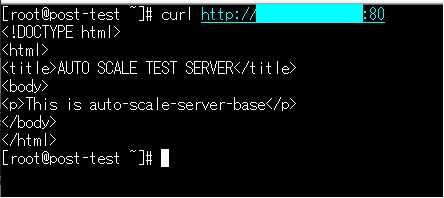
レスポンスが返ってくることが確認できました。
それでは、この構成で作ったサービスのWebサイト(ロードバランサーのIPアドレス)にApachBenchで負荷をかけてみましょう。 ※注意:やっていることはDoS攻撃とほぼ変わりませんので、実行時は注意してください。
$ watch "ab -n 200 -c 20 -t 600 http://XXX.XXX.XXX.XXX:80/"topコマンドで確認すると、Load averageの値が高く、確かに負荷はかかっている様子です。
![水平スケールtop確認画面]](https://knowledge.sakura.ad.jp/wp-content/uploads/2022/06/scale-out-micro-top-680x510.png)
しばらくすると、auto-scale-server-001という名前が付いたサーバーが立ち上がってきました。
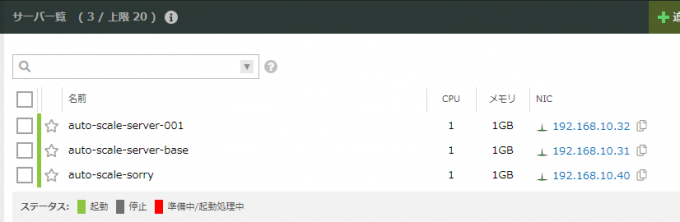
ログでも確認してみましょう。
Jun 09 12:08:43 prod1 systemd[1]: Started SakuraCloud AutoScaler Input for XXXXXXXXXXXX.
Jun 09 12:08:44 prod1 cpu_threshold_scaling.sh[2224242]: 2022/06/09 12:08:44 auto-scale-server-base zone:is1a cores:1 cpu:0.806667 time:2022-06-09 12:05:00 +0900 JST
Jun 09 12:08:44 prod1 cpu_threshold_scaling.sh[2224242]: 2022/06/09 12:08:44 auto-scale-server-base avg:80.666667
Jun 09 12:08:44 prod1 cpu_threshold_scaling.sh[2224242]: Do Up
Jun 09 12:08:44 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:44+09:00 level=info request=Up message="request received"
Jun 09 12:08:44 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:44+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=JOB_ACCEPTED
Jun 09 12:08:44 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:44+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=JOB_RUNNING
Jun 09 12:08:44 prod1 cpu_threshold_scaling.sh[2224242]: status: JOB_ACCEPTED, job-id: AutoScaleServerGroup
Jun 09 12:08:44 prod1 systemd[1]: autoscaler_XXXXXXXXXXXX_input.service: Succeeded.
Jun 09 12:08:44 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:44+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=ACCEPTED
Jun 09 12:08:44 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:44+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=RUNNING
Jun 09 12:08:44 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:44+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=RUNNING log=creating...
Jun 09 12:08:47 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:47+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=RUNNING log="created: {ID:XXXXXXXXXXXX, Name:auto-scale-server-001}"
Jun 09 12:08:47 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:08:47+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=RUNNING log="creating disk[0]..."
Jun 09 12:10:21 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:10:21+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=RUNNING log="created disk[0]: {ID:113401057143, Name:auto-scale-server-001-disk001, ServerID:XXXXXXXXXXXX}"
Jun 09 12:10:21 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:10:21+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=RUNNING log=starting...
Jun 09 12:10:57 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:10:57+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=DONE log=started
Jun 09 12:10:58 prod1 autoscaler[2223313]: timestamp=2022-06-09T12:10:58+09:00 level=info request=Up source=default resource=AutoScaleServerGroup status=JOB_DONE
この時に、curlコマンドでリクエストを投げると、auto-scale-server-001からレスポンスが返ってくることもあります。
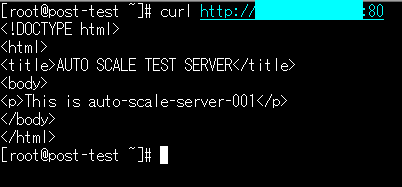
更に負荷をかけてみますと、今回の設定では1台ずつ増え、最大5台になります。 今回は1台ずつスケールアウトをしていますが、このスケールの段階も設定ファイルで変更できます。
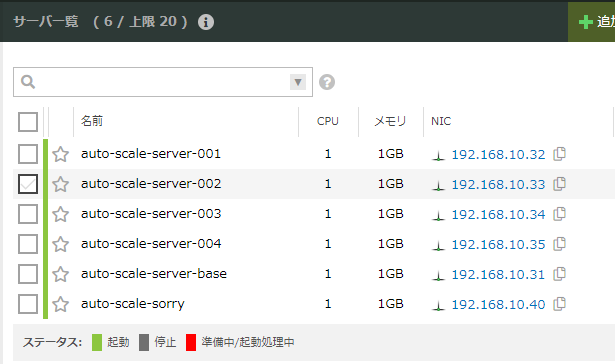
負荷をかけるのをやめ、しばらく放置していると1台に戻ります。
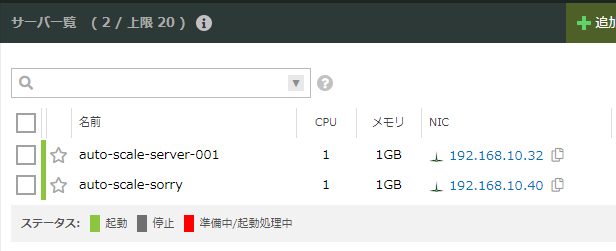
マップから見るとネットワーク構成も確認しやすいですね。
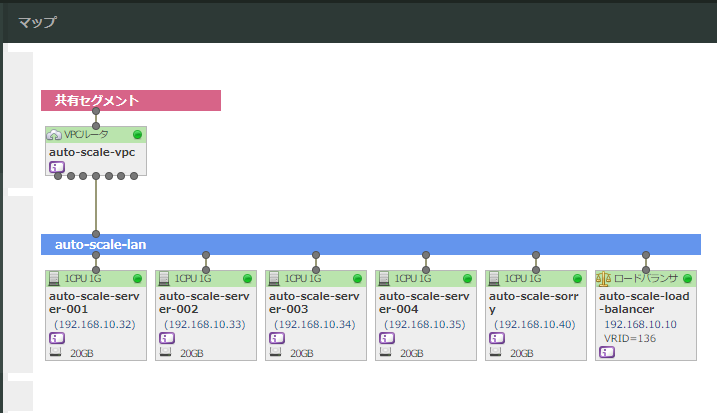
以上で水平スケールの動作を試せました。
まとめ
オートスケールがさくらのクラウドのコントロールパネルから設定ができるので、オートスケールのためのサーバーの準備は必要ありません。基本的な利用方法であれば、コントロールパネルから設定を入れるだけで利用できます。これでオートスケールを導入する難易度が下がるでしょう。
オートスケールが利用できますと、監視者が常にサーバーを監視し、負荷やアラートを受けて手動でスペックを上げる手間や、サーバークラスタにリソースとなるサーバーを追加する作業がなくなります。 また、サービスに必要な時に必要なだけのリソースを自動で調整できるので、サービスダウンのリスクをコストパフォーマンス良く回避できます。
エンハンスドロードバランサーと共にオートスケールの設定を入れると、ディザスタリカバリも考慮しつつ、コストパフォーマンスを活かした構成も作るのも可能になります。
オートスケールは現在(2022年6月)時点ではまだβ版ですので、ご意見やご要望がありましたらさくらのユーザーフィードバックで問い合わせてみましょう!