クラウドGPU体験記 〜人工衛星の画像で機械学習をやってみた〜

この記事は、2023年2月に行われたさくらインターネットの社内勉強会における発表を編集部にて記事化したものです。
目次
はじめに
さくらインターネットの養王田(よおだ)です。主に衛星データプラットフォーム「Tellus」のフロントエンドの開発をしています。
今日は、さくらのクラウドの高火力プラン(GPUサーバ)を借りて、そこで機械学習をやってみたよという話を共有したいと思います。ただ、僕自身は機械学習に関しては専門家ではなくあくまで素人ですので、その辺はちょっと手加減しながら聞いていただければと思います。
人工衛星の画像を使って機械学習をしてみよう
やったこと

まず何をやったかと言いますと、人工衛星の画像を使って機械学習をしてみました。
こちらにお見せしているのがAVNIR−2という衛星センサーのデータなんですけど、大体分解能が10mぐらいあります。Tellusにはこういった衛星データが、これ以外にもっと高精細なものもありますが、全部で数万シーン以上を無料で公開してますので、興味あったらちょっと見てみてください。
学習方法

学習方法としては、アーキテクチャにStyleGAN3を採用しました。これの利点は、オープンソースなので論文などの情報が豊富にあることと、1024px(ピクセル)の画像を出力できることが結構魅力的でした。2022年時点では機械学習のライブラリで扱える画像サイズは256pxか512pxがほとんどで、大きな画像サイズで学習しようとすると使えるアーキテクチャが結構限られます。でもこのStyleGAN3はそれができるっていうところですね。ただその分デメリットもありまして、かなりメモリサイズを食います。僕も個人でGPUを持っているんですが、家庭用GPUだとちょっと動かないな、ということがたまにあります。
なお、StyleGAN3の環境構築はREADMEに従ってAnacondaを使えば一発で終わります。また、その前準備としてのCUDAのドライバやらGPU周りの環境構築は「CUDA Toolkit/GPUカードドライバーの導入手順を知りたい(高火力サーバー)」を参考にするとスムーズに行えます(バージョンが上がったりしているので若干の修正は必要ですが)。
AVNIR-2を教師データにして学習する

前処理としては、AVNIR−2というセンサーのデータを画像にしたものを1024×1024pxのサイズで切り取っていって、10万枚の画像を集めます。で、それをStyleGANに食わせます。このときパラメータは全部、基本的にデフォルト値をそのまま使ってます。まずはやってみるの精神ですね。

やってみると、最初はこんな、何かわかんないようなモザイク画像なんですが、

最終的にはこんな感じで、なんかいい感じの出力をするようになりました。
学習結果

で、この中から特に良かったもの一つを見せしてるんですけども、結構きれいな地形が出てるんじゃないかなと思っております。なんか下の方に雲とか街が見えると思います。山の中なのかなみたいな感じですね。
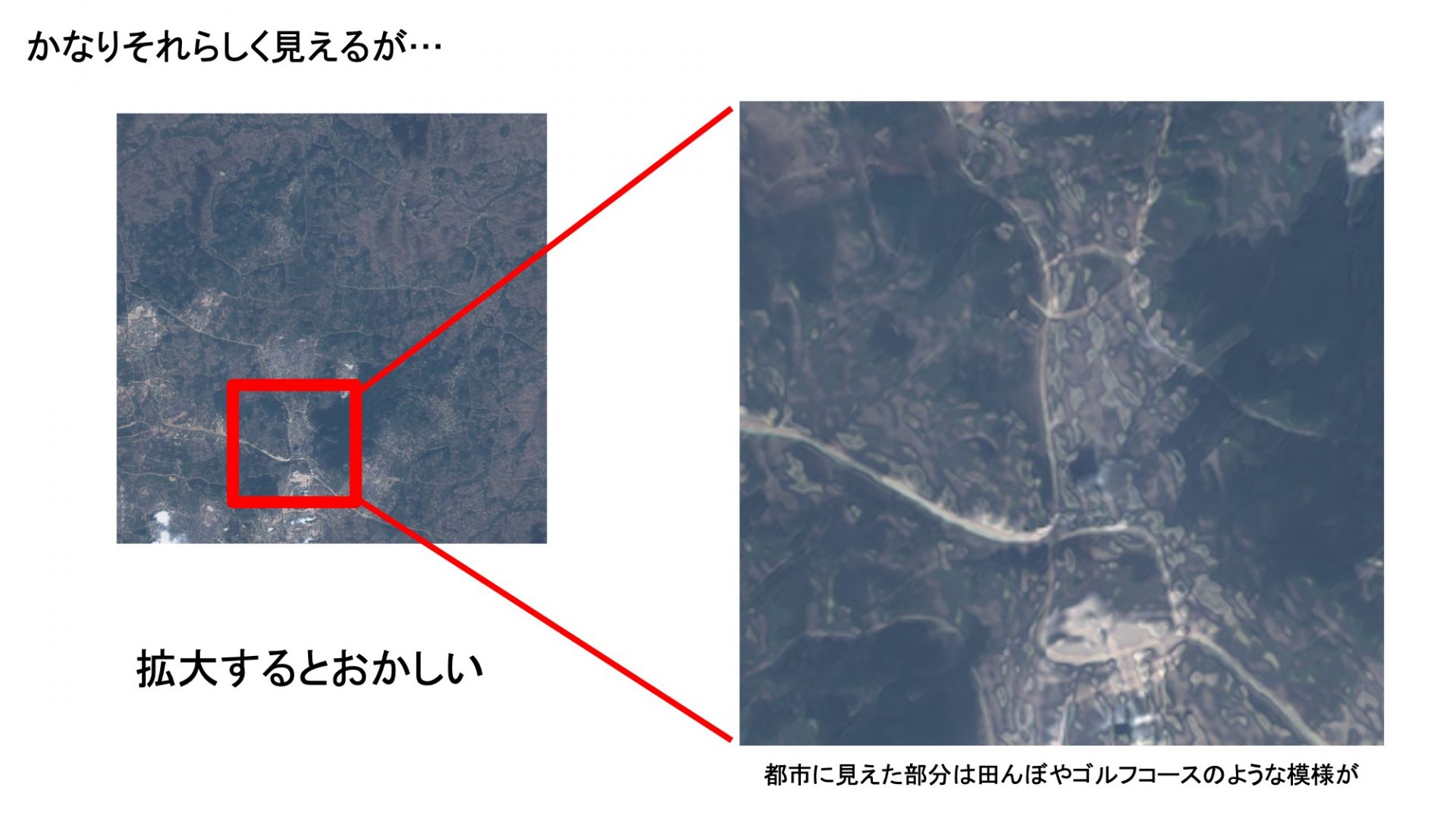
とはいえ、実は拡大すると結構おかしいです。街っぽいところを拡大してみると、なんか田んぼみたいな、奇妙な形が見えてます。やっぱり細かい部分はまだまだだなっていうところではありました。
ただ、複雑でない地形、海とか砂漠とかですね、こういう単調な地形は、かなりそれっぽくできていると思います(いくつか出力した中には衛星の専門家でもニセモノとはわからない出来映えの画像もありました)。なので、架空のSFで出てくるような、人がいないような惑星を見たいなら、結構それっぽくできるかもしれません。
学習させてみた所感
ここまでお見せしたところの所感としましては、かなりそれらしい画像の出力はできました。パラメータチューニングは何もしてないんですけど、それでもこれだけできたのはかなり驚異的かなと思ってます。
ただ、やはり細部がおかしいですね。人工物が特におかしかったです。しかし、パラメータチェックをしてないので、チューニングをもっとしたり、教師データもたったの10万枚ですので、もっと枚数を増やしたり、もっと質を上げていったりすると、もっと良くできるだろうなっていう手応えを得られたので、1回目の挑戦としては結構うまくいったなと個人的には思っています。
学習に何日かかったか
さて、今回の学習、何日ぐらいかかったと思いますか? 1日とか3日とか1ヶ月とか…。
ここはじらしてもしょうがないのですぐに答えを言ってしまうと、65日かかりました。だから2回目はやってないです。さすがにやってられないなと…。
AIの動向
ここからちょっと、2022年のAI関連の動向を振り返ってみます。
2022年前半まで
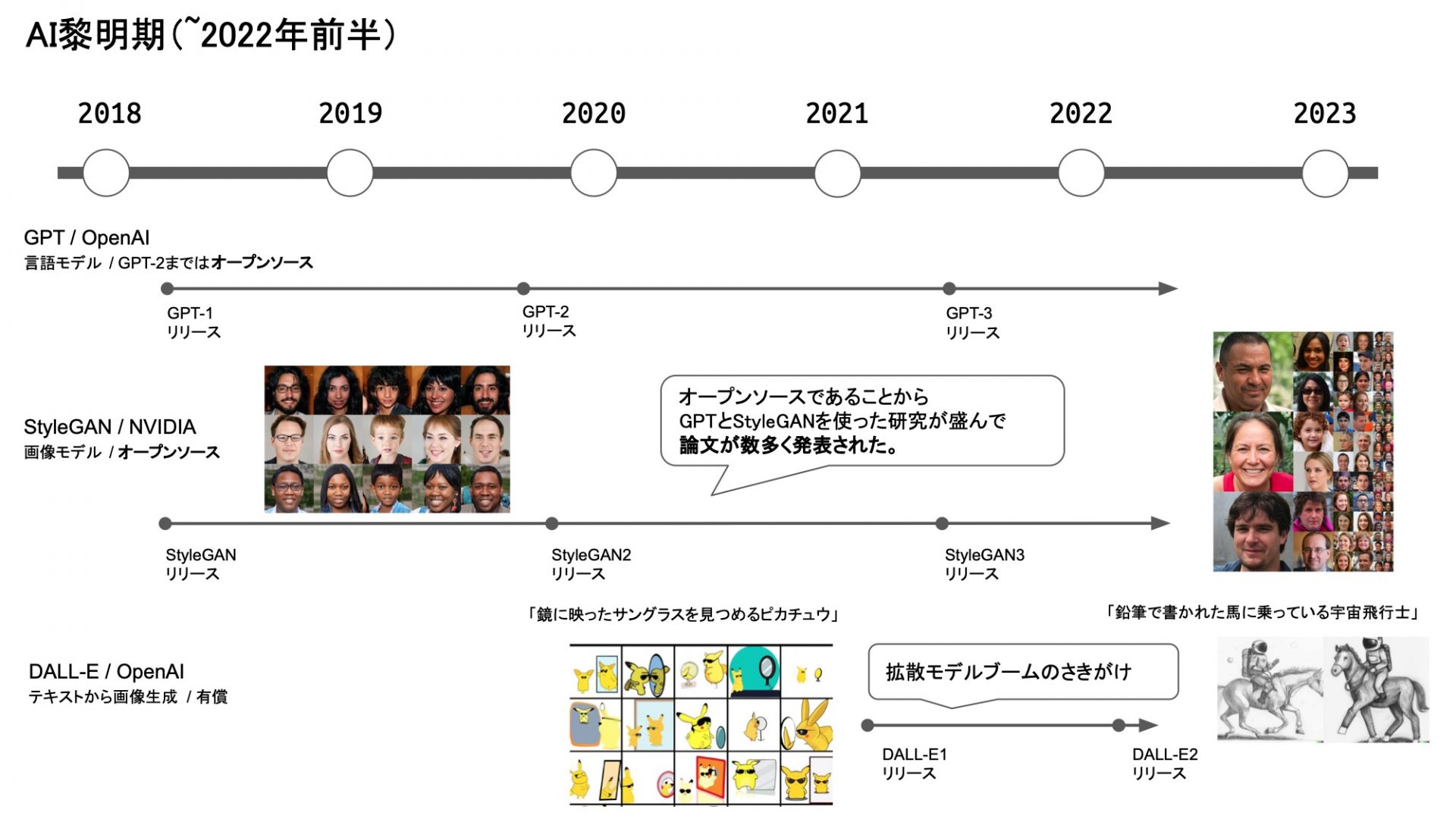
ご存じの方も多いと思いますが、去年は機械学習の、特に画像まわりはすごい年でした。
2022年の前半よりも前は、GPTとかStyleGANとか、オープンソースのアーキテクチャがすごく流行ってました。そこにDALL-Eが登場して、拡散モデルのブームの予兆が見られたのが2022年の春頃でした。
2022年後半の動き

これがその年の後半とか夏ごろから、ちょっと人間のプロとも争えるんじゃないかと思えるAIモデルがいくつか立て続けに登場しましたね。Midjourney、Stable Diffusion、ChatGPTなどですね。要は拡散モデルの時代に突入して、環境が劇的に変わりました。すごいスピードで変わりましたよね。
象徴的なのが、NovelAIが10月3日に画像系のサービスを開始したんですけど、3日でモデルが流出して、すぐ改造モデルが出回るっていう事件がありました。なかなか象徴的な出来事だったと思ってます。
あと、もう一つ、大きく流れが変わったこととしては、2022年より前だとみんなオープンソースのモデルだったのが、この頃になるとみんな有償モデルになりましたね。APIを公開してお金を取るというようなモデルがほとんどになったのが去年の後半からでした。
個人でイチから学習させることの限界
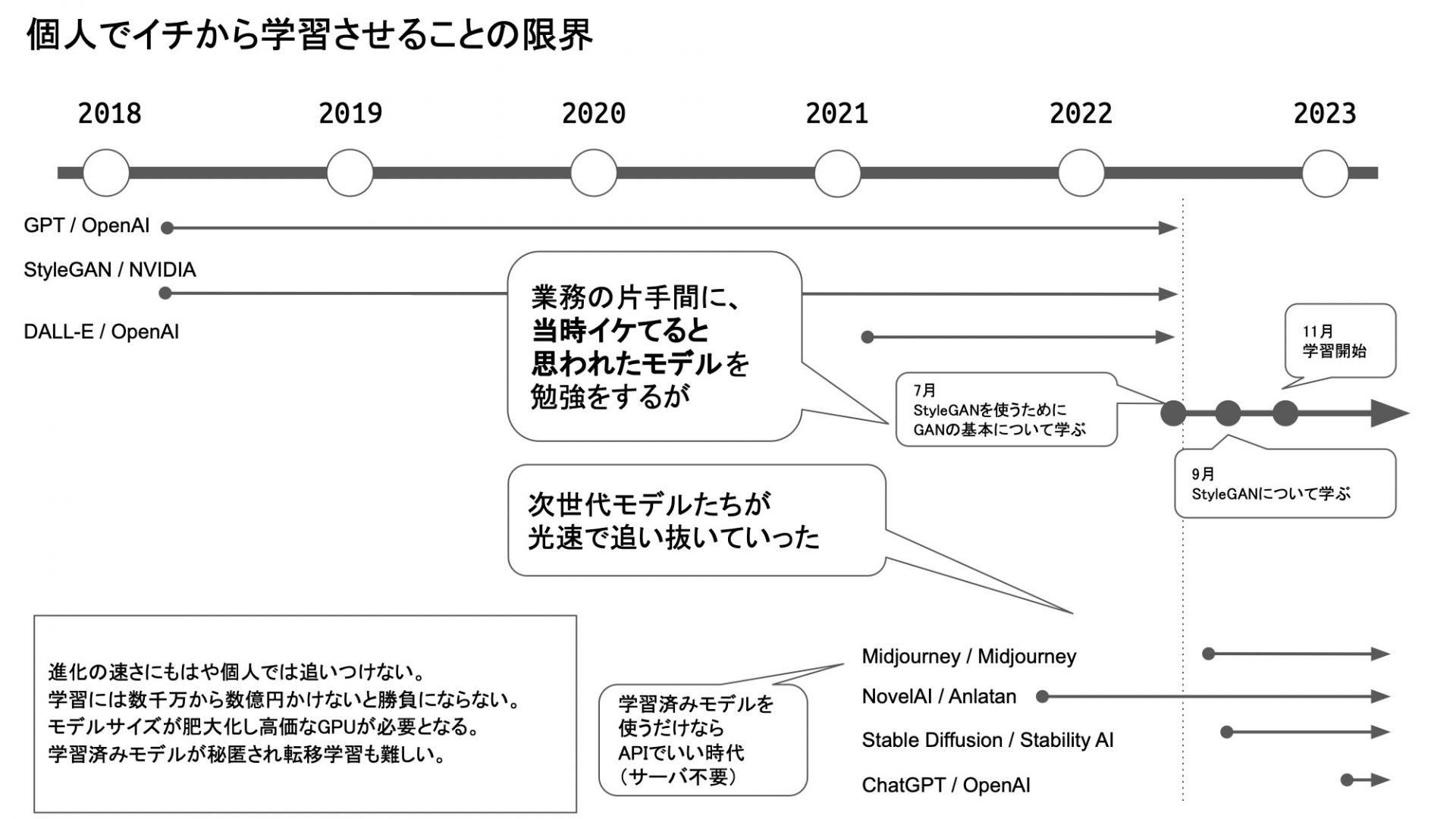
実は僕、2022年の7月ぐらいからこの勉強を始めました。ちょっとやってみようかと思って、GANっていうものを勉強して、9月にStyleGANをどう使うかを勉強して、11月からGPUサーバーを借りて、という感じでやってました。
これは業務ではないので、その片手間にやった割には良いスピード感でできたなと個人的には思っていたんですけども、その横を次世代モデルが爆速で駆け抜けていきまして、もうすっかり置いてかれました。僕が長々とやってる間に、あっという間に抜かれていきました。
今回勉強するにあたって、当初はこんなことを目論んでいました。
- StyleGANで学習した衛星画像モデルを公開する
- ユーザも転移学習すれば、自分がイメージしたような地域の衛星画像を出せるようになる
- それを動かすにはそれなりのGPUリソースが必要だが、そこでさくらのクラウドの高火力プランを使ってもらえるように、簡単に導入できる記事や動作例などの情報を公開する
しかし、65日かけて学習が終わった頃には、誰ももうStyleGANの話をしてないんですよね。完全に浦島太郎状態になってしまいました。
そんな感じで、もう個人で画像の機械学習やるには厳しい時代になったなと思います。ちょっとしたことだったらAPIでお金を払った方が、精度もスピードも圧倒的にいい時代になってます。
だから、あえて自分でやるんだったら、データを外に持ち出せないとか、他のサービスにこれを使って学習されちゃ困るというのでもない限りは、なかなか自分でやるモチベーションにはなりにくいのかなって思っています。
それでも個人で画像の機械学習をするなら
それでも個人でやるんだったら、それも僕みたいな物好きな人が対象になりますが、メモリの大きいGPUを使えるのはすごく助かると思います。今回はV100が載ったサーバを借りましたが、大きい画像を出そうとするとまだメモリが必要なので、ここはかなり助かりました。
ただ、これはもうすごくありきたりすぎる要求になっちゃうんですけど、もっと並列化して高速化したいなというのは、本当に強く思いましたね。65日もかかってたんじゃ無理です。もし業務で機械学習やりなさいよって言われた場合、少なくとも2週間で1回試して、また次のパラメータを試して、みたいな2週間サイクルぐらいで回せないとやってられないというのは本当に強く思いました。
おわりに

最後の締めとなりますけども、ぼんやりと半年かけて勉強したら、あっという間に時代遅れになっていたという強烈な体験ができました。時代の変化を身にしみて感じられたのはとても良かったと思っています。
個人的な次の目標としては、次世代というか今やスタンダードになっているStable Diffusionあたりを勉強したり、もしくはパラメータチューニングをして、もうちょっとStyleGANで質を上げていけないかと思っています。それから、この発表から1か月が経過して、いまはViTのようなtransformersを利用した方式に興味が移りつつあります。これもまた時代の変化ですね。
ここまでご覧いただきありがとうございました。